 返回首页
返回首页
 回到顶部
回到顶部
一、背景介绍
每天每个人都会扔出许多垃圾,
大部分垃圾会得到卫生填埋、焚烧、堆肥等无害化处理,
大多数人对垃圾分类重视度不高
很多垃圾则常常被简易堆放或填埋,
导致臭气蔓延,并且污染土壤和地下水体。
今天,分享一篇【二哈识图2 】基于自训练模型的垃圾分类
通过垃圾分类大模型,自动识别垃圾,
在源头将垃圾分类投放,
并通过分类的清运和回收使之重新变成资源!

二、工作原理
1.上电后,k10屏幕显示“自训练模型垃圾分类”,正在识别垃圾中
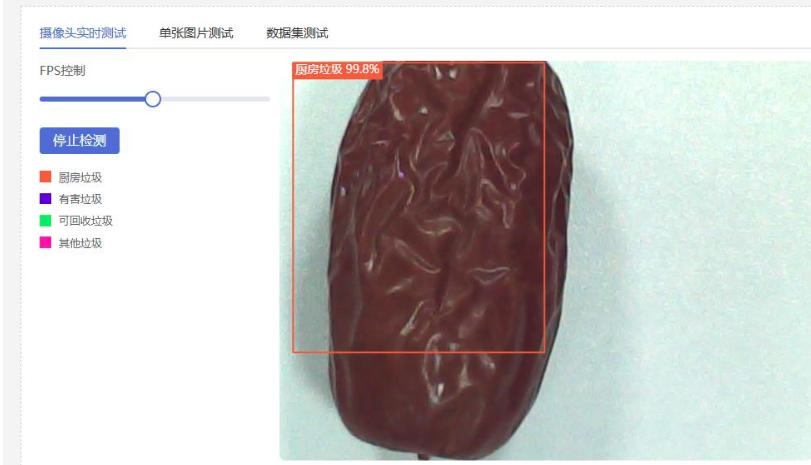
2.当放入红枣,二哈识图2调用垃圾分类模型,识别厨余垃圾,k10播放对应音频、图片和文字信息
3.当放入电池,二哈识图2调用垃圾分类模型,识别有害垃圾,k10播放对应音频、图片和文字信息
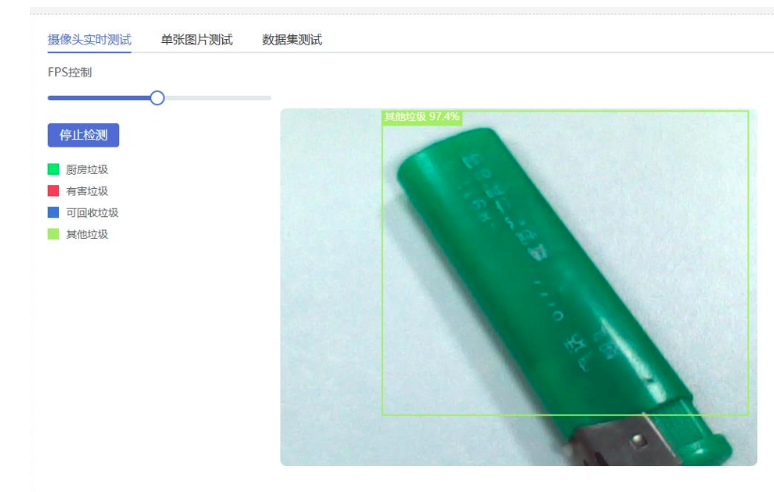
4.当放入火机,二哈识图2调用垃圾分类模型,识别其他垃圾,k10播放对应音频、图片和文字信息
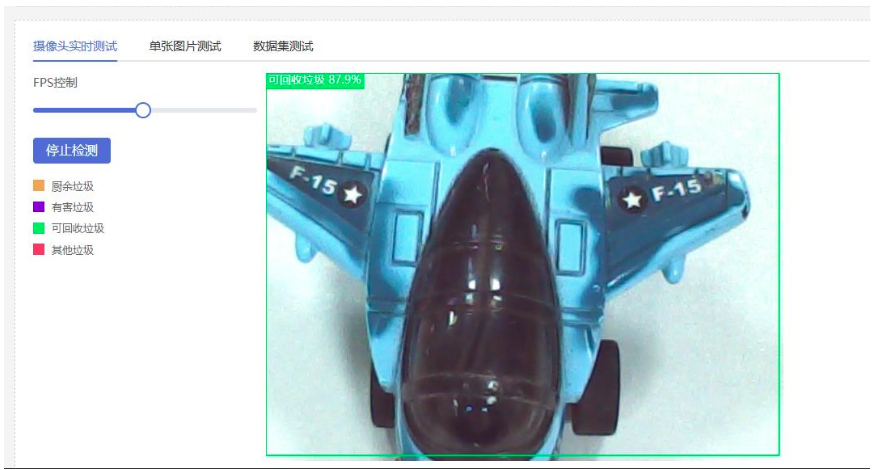
5.当放入飞机,二哈识图2调用垃圾分类模型,识别可回收垃圾,k10播放对应音频、图片和文字信息,
三、、实现步骤
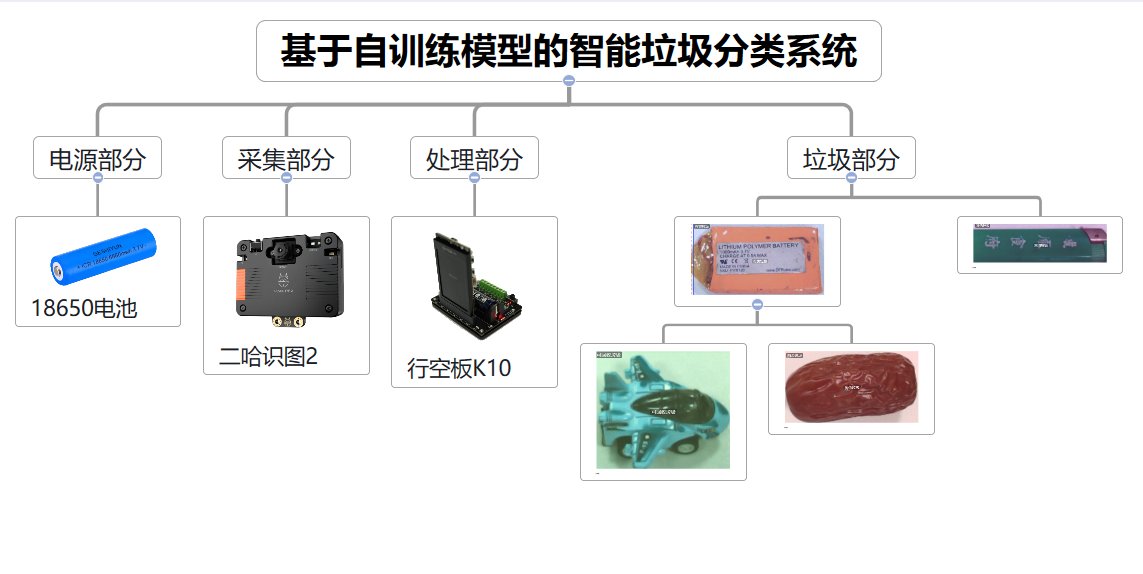
步骤1 打开 Mind+2.0软件,点击模型训练,找到目标检测,点击进入目标检测功能。
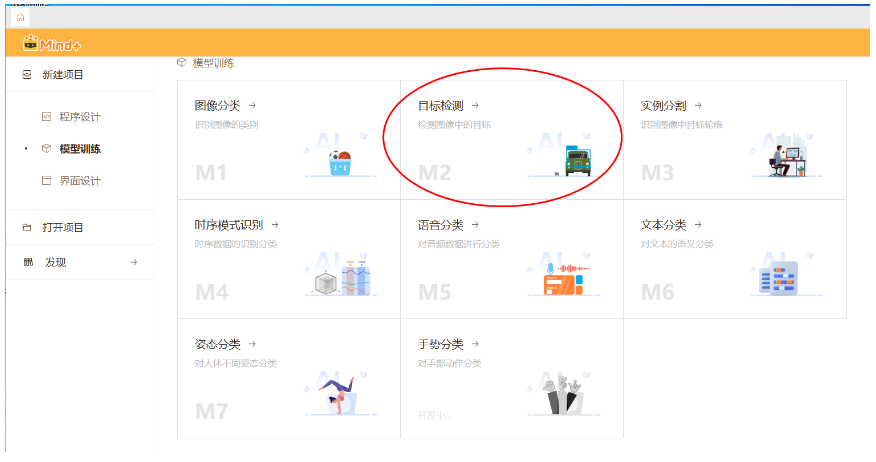
步骤2 通过摄像头采集图片,在线完成数据标注、模型训练和模型安装。
采集垃圾图片
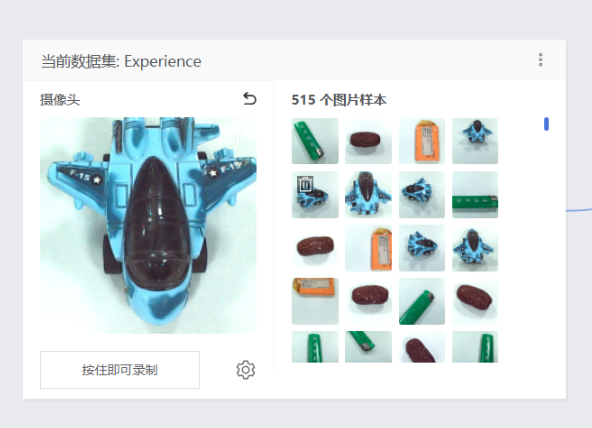
编辑标签

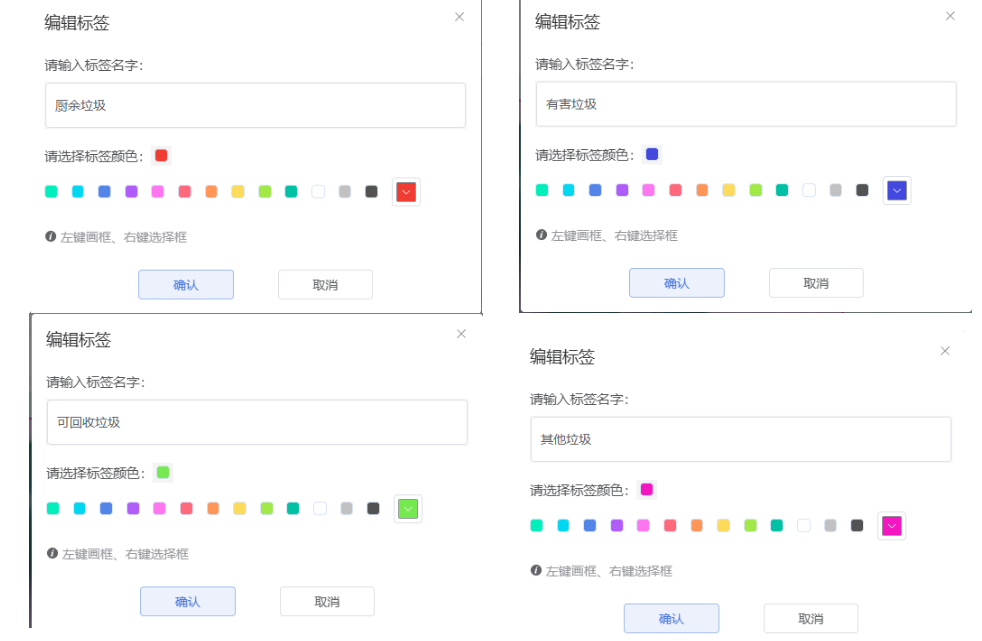
标注可回收垃圾

标注有害垃圾
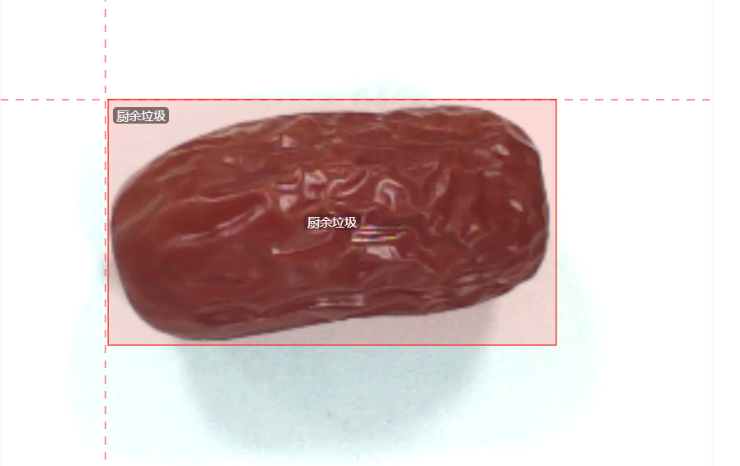
标注厨余垃圾

标注其他垃圾
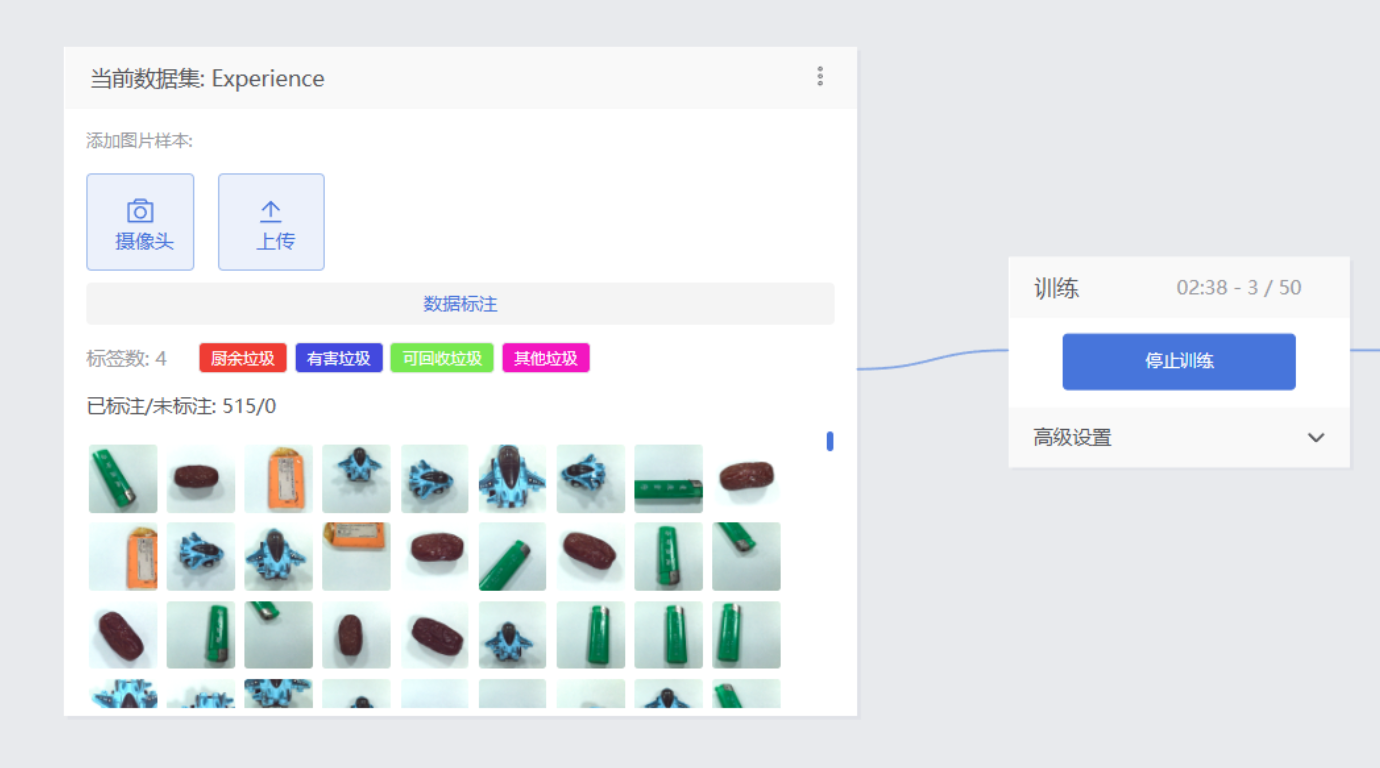
训练模型
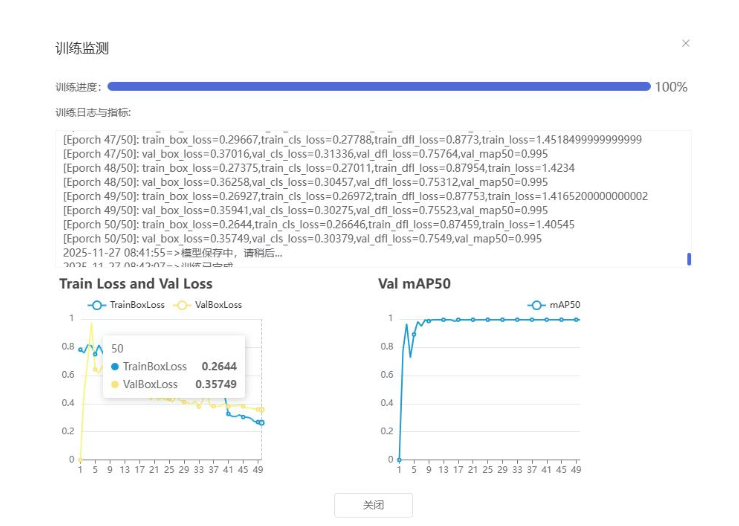
训练检测
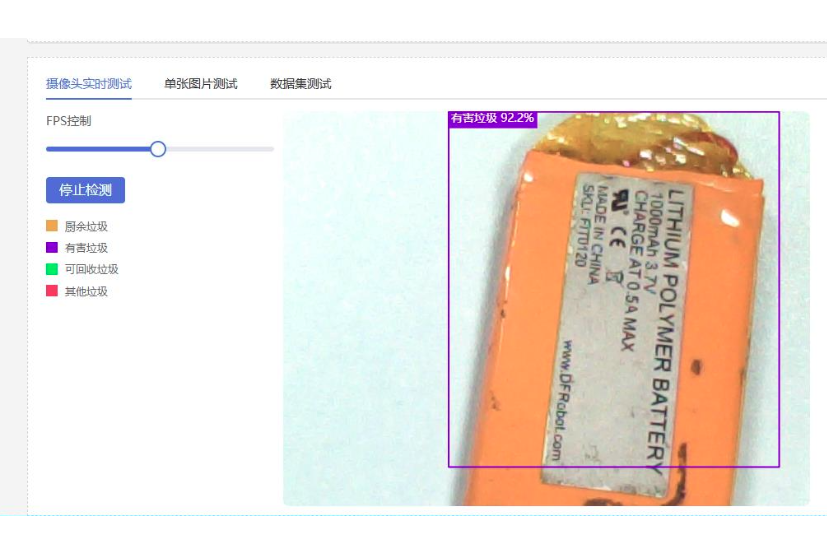
实时测试
部署二哈识图2模型文件
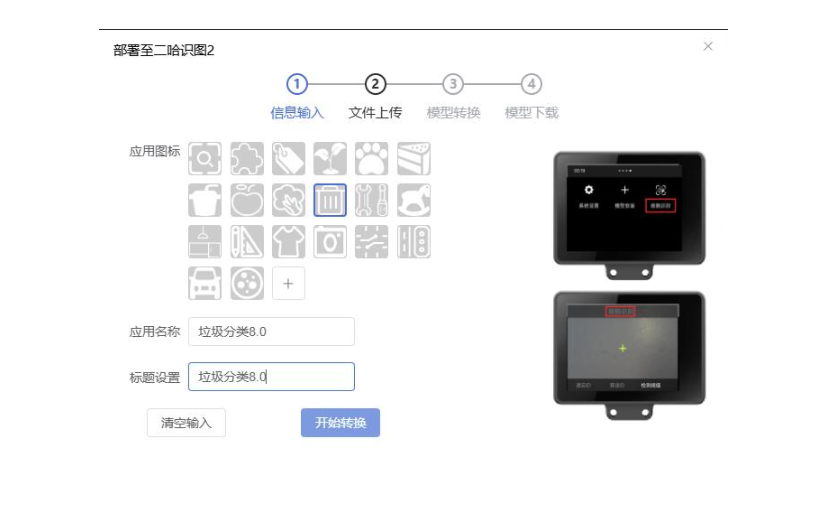
部署二哈识图2模型文件
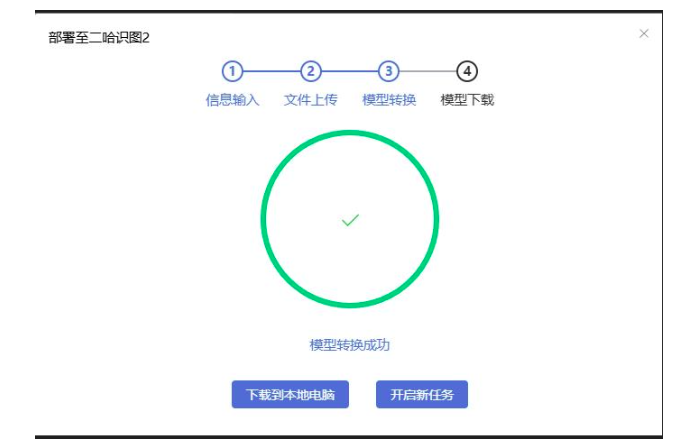
部署二哈识图2模型文件
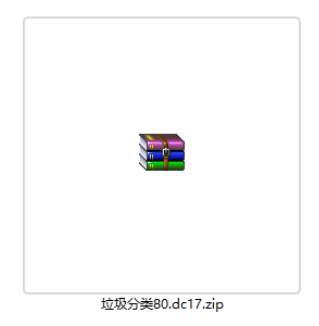
二哈识图2接入电脑,将垃圾分类80.dc17.zip
拷贝Huskylens 的 硬盘的\storage\installation_package目录下

观察自己训练的模型的识别效果




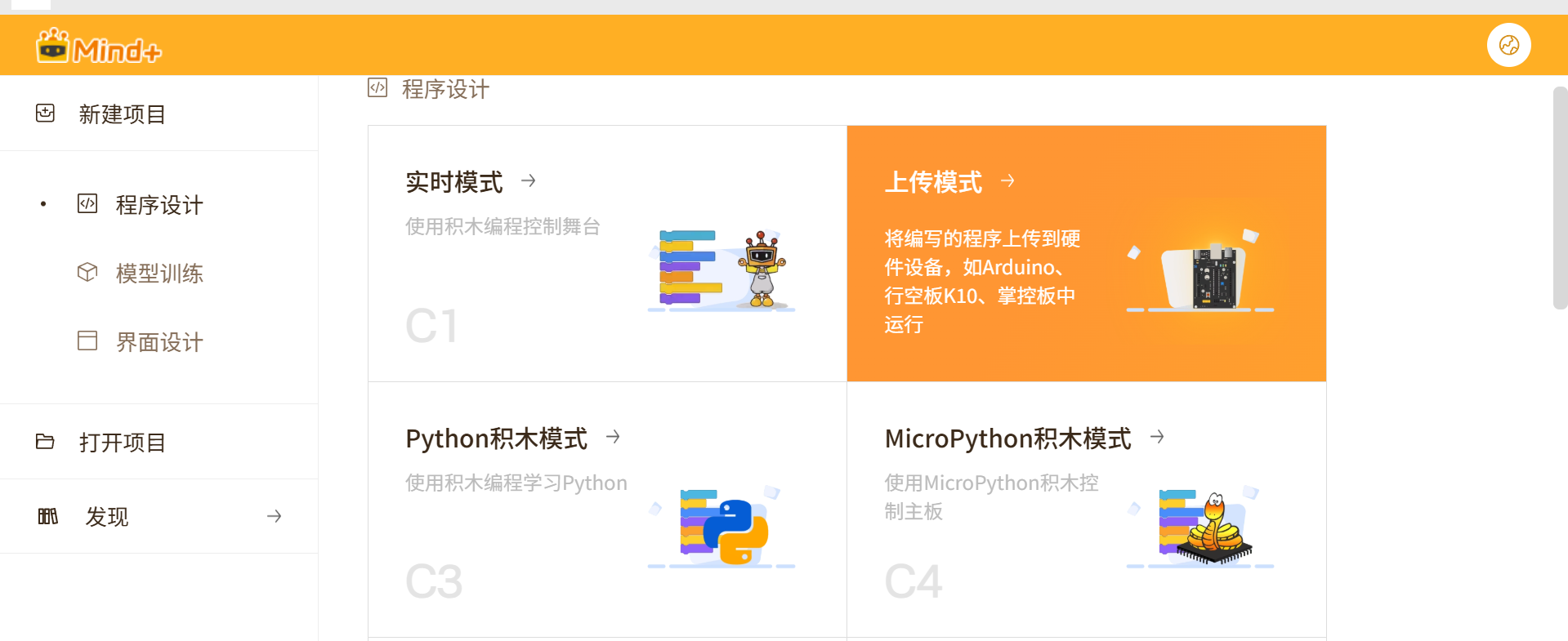
步骤3 打开 mind+,窗口右上角,选择 上传 模式
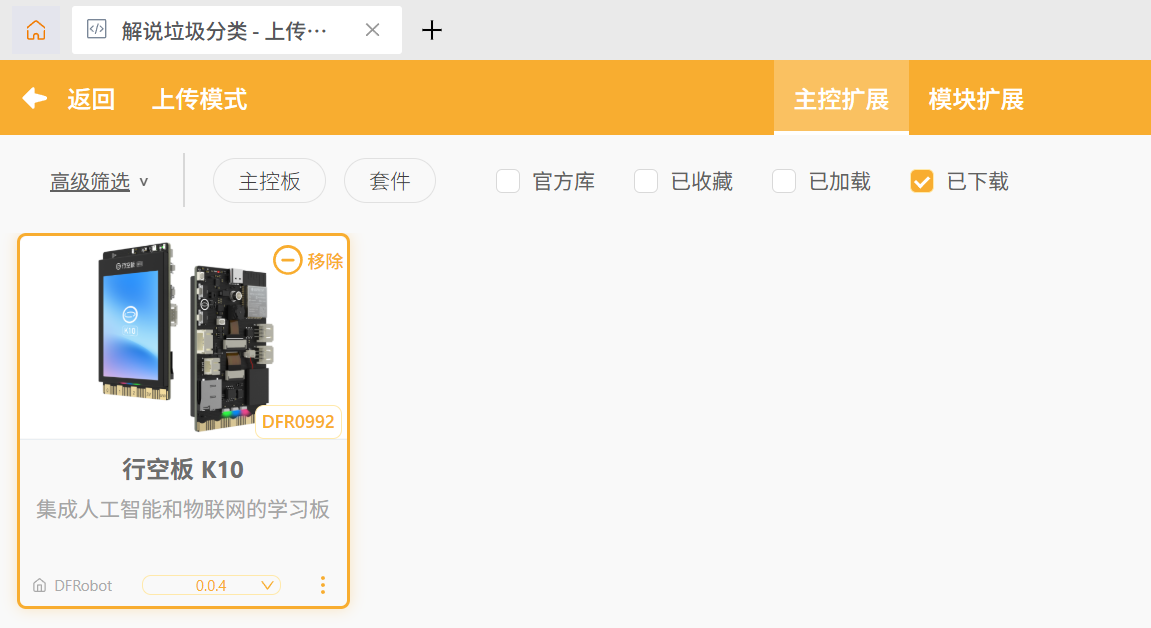
步骤4 打开 Mind+,右下角扩展添加在官方库添加行空板k10,二哈2

步骤5 编写程序
/*!
* MindPlus
* DFRobot, 行空板 K10
*/
#include "unihiker_k10.h"
#include "DFRobot_HuskylensV2.h"
// 动态变量
volatile float mind_n_biaoji;
// 创建对象
UNIHIKER_K10 k10;
uint8_t screen_dir=2;
HuskylensV2 huskylens;
Music music;
// 主程序开始
void setup() {
k10.begin();
k10.initScreen(screen_dir);
k10.creatCanvas();
Wire.begin();
while (!huskylens.begin(Wire)) {
delay(100);
}
k10.initSDFile();
k10.canvas->canvasClear();
k10.setScreenBackground(0xFFFFFF);
k10.canvas->canvasText("二哈识图2", 1, 0x000000);
k10.canvas->canvasText("自训练模型垃圾分类", 3, 0x000000);
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0x000000);
mind_n_biaoji = 0;
huskylens.switchAlgorithm((eAlgorithm_t)131);
}
void loop() {
huskylens.getResult((eAlgorithm_t)131);
if (huskylens.available((eAlgorithm_t)131)) {
if ((RET_ITEM_STR(huskylens.getCachedCenterResult((eAlgorithm_t)131), Result, name)==String("厨余垃圾"))) {
k10.canvas->canvasClear(13);
k10.canvas->canvasText("当前是厨余垃圾", 13, 0x000000);
k10.canvas->canvasDrawImage(0, 96, "S:/厨余垃圾.jpg");
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0x00FF00);
if ((mind_n_biaoji==1)) {
music.playTFCardAudio("S:/厨余垃圾 .wav");
mind_n_biaoji = 0;
}
}
if ((RET_ITEM_STR(huskylens.getCachedCenterResult((eAlgorithm_t)131), Result, name)==String("有害垃圾"))) {
k10.canvas->canvasClear(13);
k10.canvas->canvasText("当前是有害垃圾", 13, 0x000000);
k10.canvas->canvasDrawImage(0, 96, "S:/有害垃圾.jpg");
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0xFF0000);
if ((mind_n_biaoji==1)) {
music.playTFCardAudio("S:/有害垃圾 .wav");
mind_n_biaoji = 0;
}
}
if ((RET_ITEM_STR(huskylens.getCachedCenterResult((eAlgorithm_t)131), Result, name)==String("其他垃圾"))) {
k10.canvas->canvasClear(13);
k10.canvas->canvasText("当前是其他垃圾", 13, 0x000000);
k10.canvas->canvasDrawImage(0, 96, "S:/其他垃圾.jpg");
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0xFFFFFF);
if ((mind_n_biaoji==1)) {
music.playTFCardAudio("S:/其他垃圾.wav");
mind_n_biaoji = 0;
}
}
if ((RET_ITEM_STR(huskylens.getCachedCenterResult((eAlgorithm_t)131), Result, name)==String("可回收垃圾"))) {
k10.canvas->canvasClear(13);
k10.canvas->canvasText("当前是可回收垃圾", 13, 0x000000);
k10.canvas->canvasDrawImage(0, 96, "S:/可回收垃圾.jpg");
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0x0000FF);
if ((mind_n_biaoji==1)) {
music.playTFCardAudio("S:/可回收垃圾.wav");
mind_n_biaoji = 0;
}
}
}
else {
k10.canvas->canvasClear(13);
k10.canvas->canvasText("当前垃圾正在识别.......", 13, 0x000000);
k10.canvas->canvasDrawImage(22, 96, "S:/等待.jpg");
k10.canvas->updateCanvas();
k10.rgb->write(-1, 0x000000);
if ((mind_n_biaoji==0)) {
music.stopPlayAudio();
mind_n_biaoji = 1;
}
}
}
四、迭代过程
问题1:
在程序调试过程中,我发现当二哈识图2(HuskyLens)识别到特定垃圾时,系统会持续不断地重复播放对应的垃圾分类提示音频,无法正常停止。
(1) 解决方案:
为解决此问题,我们在程序中引入了一个状态标志变量 biaoji。该变量的作用如下:
当 biaoji = 0 时,表示系统正在识别垃圾中,中断播放音频文件,等待响应新的垃圾识别指令;
当 biaoji = 1 时,表示系统正在播放当前垃圾的音频,此时暂停新的识别响应;
(2)实现效果:
通过引入标志变量 biaoji ,确保每个垃圾分类提示音频只完整播放一次,防止音频播放过程中的重复触发,提高系统响应效率和用户体验,使系统工作更加稳定可靠。

问题2
在垃圾分类识别系统的初期测试中, 二哈识图2(HuskyLens)在识别时容易误识别两个或多个标签,整体识别精度不高,准确率未达预期,经过测试分析,发现主要存在以下影响因素:
(1)训练样本单一,缺乏多样性;
(2)垃圾物体与背景颜色相似,难以区分;
(3)不同垃圾物体形状特征相似,模型难以辨别;
(4)训练数据量不足,第一次采集数据集图片70张/项,模型泛化能力弱;
(5)标注框绘制不准确,影响模型学习效果

解决方案:
A. 优化垃圾数据采集
(1)颜色差异化:确保采集垃圾的背景颜色与被采集物体颜色有明显区别,增强轮廓识别度;
(2)采集形状要区分:采集时避免物体A形状与被测物体B形状过于相似,提升特征可区分性;
(3)多角度采集:从不同角度、不同光照条件下采集垃圾图片;
(4)多样化背景:在不同场景和背景下采集图片,提高模型环境适应能力;
B. 提升标注质量:
(1)绘制标注框时精确对准物体边缘,提高标注准确性;
(2)对模糊或边界不清的图片进行重新采集;
C.数据集扩充与训练优化:
(1)累计采集515张高质量图片作为训练数据集;
(2)实施8轮次迭代训练,逐步优化模型参数;
(3)每轮训练后评估效果,针对识别困难类别补充相应数据;
效果实现:
通过上述系统化改进,取得了显著成效:识别精度提升,误识别减少,稳定性增强,对未见过的新样本具备良好的识别能力.



 他的勋章
他的勋章

rzegkly2025.12.14
训练模型:采集图片数据,数据标注, 在线训练 建立模型: 训练测试,掌握了垃圾分类的规律 应用模型: 部署二哈识图2 可以忽略在训练模型那些原理。
easy猿2025.12.02
老师你这个二哈的白色支架模型文件有吗,能分享下吗
rzegkly2025.12.01
2025年11月20日 晚上,蘑菇云的Mind+ V2 正式开放,它配备了强大的模型训练工具,“三步训 AI 模型”,无需复杂编程,简单三步即可完成AI模型训练。让我们信息科技教师也能轻松训练属于自己的人工智能模型!无需搭建复杂的模型训练工具,通过在线训练,下载模型,操作效果很好。 亮点一:模型训练工具 “硬件无缝适配”:训练好的模型可直接部署到多种硬件设备,实现端侧智能。 亮点二:底层与扩展库重构 Mind+ V2 按需加载,启动更快,运行更流畅。扩展库也支持按需加载与管理,让软件更轻量、更高效。 亮点三:大模型与智能体 Mind+ V2 正式引入智能体编辑器与 MCP 模型连接协议库。轻松调用与集成各类大模型能力。像搭积木一样编排智能体流程,轻松学习和运用大模型技术。