 返回首页
返回首页
 回到顶部
回到顶部

电动车进入电梯充电,如同将一颗“定时炸弹”搬入密闭空间——30秒火焰蔓延,1分钟毒气致命。传统的人力巡查与标语警示,在“打游击”式的违规行为面前常常失效。

为此,我们成功研发并部署了一套 “AI电梯哨兵”系统。它基于二哈识图2(HuskyLens 2)AI视觉传感器与行空板M10边缘计算主控,实现了对电动车入梯行为的毫秒级感知、秒级联动阻断与全过程数字化追溯。
当系统“看见”电动车时,能在1秒内自动完成声光警告、阻止电梯关门、抓拍取证并上传至云端可视化平台,形成“发现-制止-记录”的完整管理闭环。本报告将详解这套低成本、高可靠性智能安防方案的从0到1实现全过程。
一、刻不容缓:为何必须用技术手段根治电动车入梯?
据统计,近年来超半数电动车火灾发生于室内、楼道充电过程,空间狭小密闭,火焰可在30秒内迅速蔓延,释放的有毒气体足以在1分钟内致人窒息,严重威胁居民生命安全。
传统依赖人力看守、张贴标语的管理方式存在监管盲区、响应滞后、成本高昂等痛点,难以实现全天候有效阻截。本系统旨在从源头进行实时识别与干预,用智能化方案彻底解决这一社区治理顽疾。
二、三层智能架构:如何打造一个会思考、能行动的“电梯卫士”?
为实现从“感知”到“干预”再到“管理”的无缝衔接,本系统采用了清晰的三层边缘计算架构,确保每一层都精准高效地完成其核心使命,构建完整的“识别-干预-记录”管理闭环。
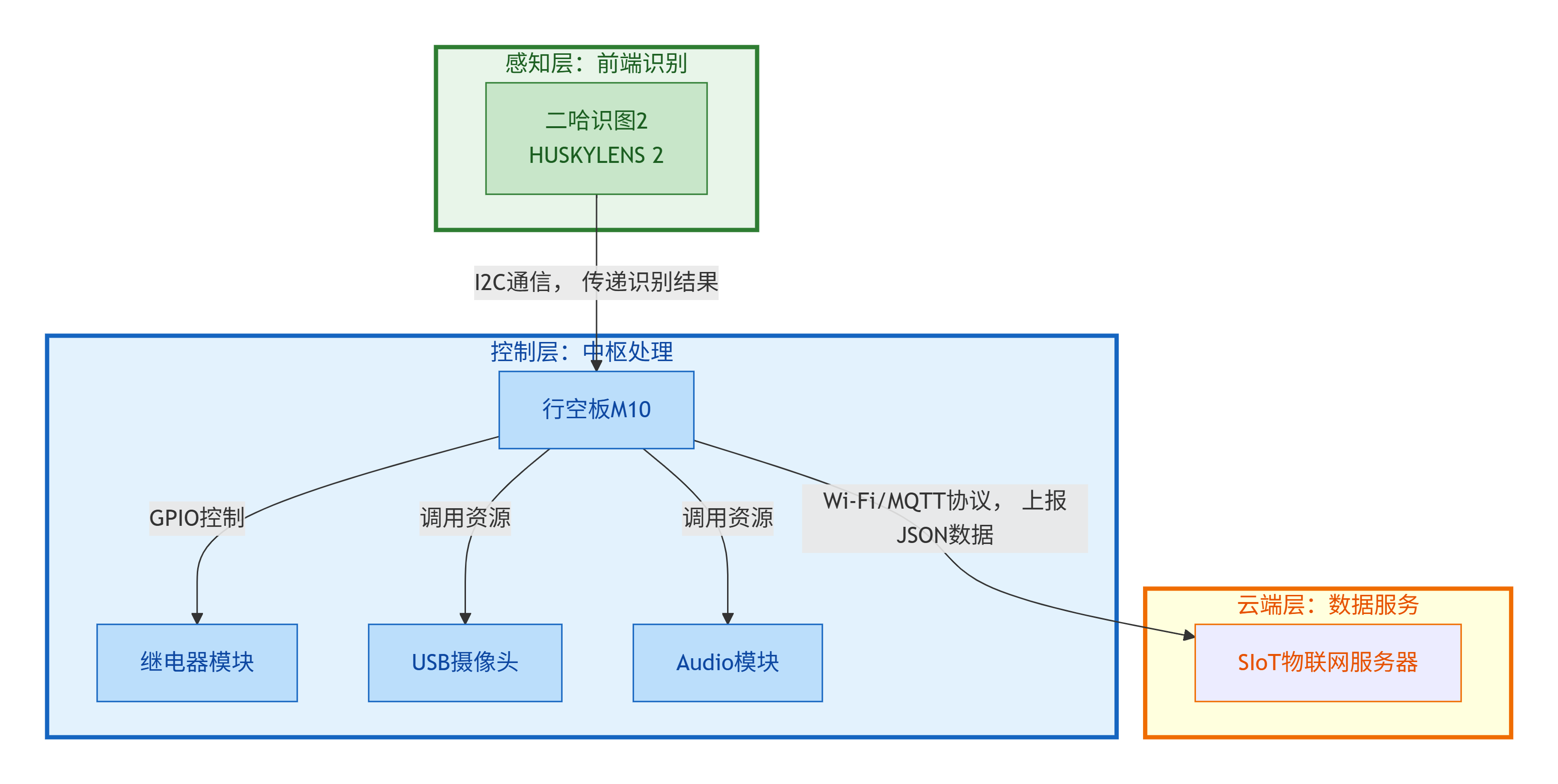
感知层(前端识别):由二哈识图2构成,作为系统的“眼睛”,负责实时采集视频流并进行AI推理,精准识别电动车等目标。
控制层(中枢处理):由行空板M10构成,作为系统的“大脑”。它通过I2C总线接收感知层的识别结果,执行核心逻辑判断。一旦确认违规,则立即调度本级资源:通过GPIO口控制继电器实现电梯开门锁定,调用Audio模块播放告警语音,并驱动USB摄像头抓拍现场照片。最后,它将所有信息整合为结构化JSON数据。
云端层(数据服务):即SIoT物联网平台,作为系统的“档案库”。控制层通过Wi-Fi和MQTT协议,将带有时间戳、设备ID、Base64照片和中文类别标签的JSON数据包上报至此。
三、刻不容缓:为何必须用技术手段根治电动车入梯?
稳定可靠是安防系统的生命线。我们经过充分考量,精选了以下互相配合的硬件“精兵”,在确保功能强大的同时,兼顾了成本与易用性,共同构建起系统坚实的物理基础。
硬件介绍
(1)行空板M10
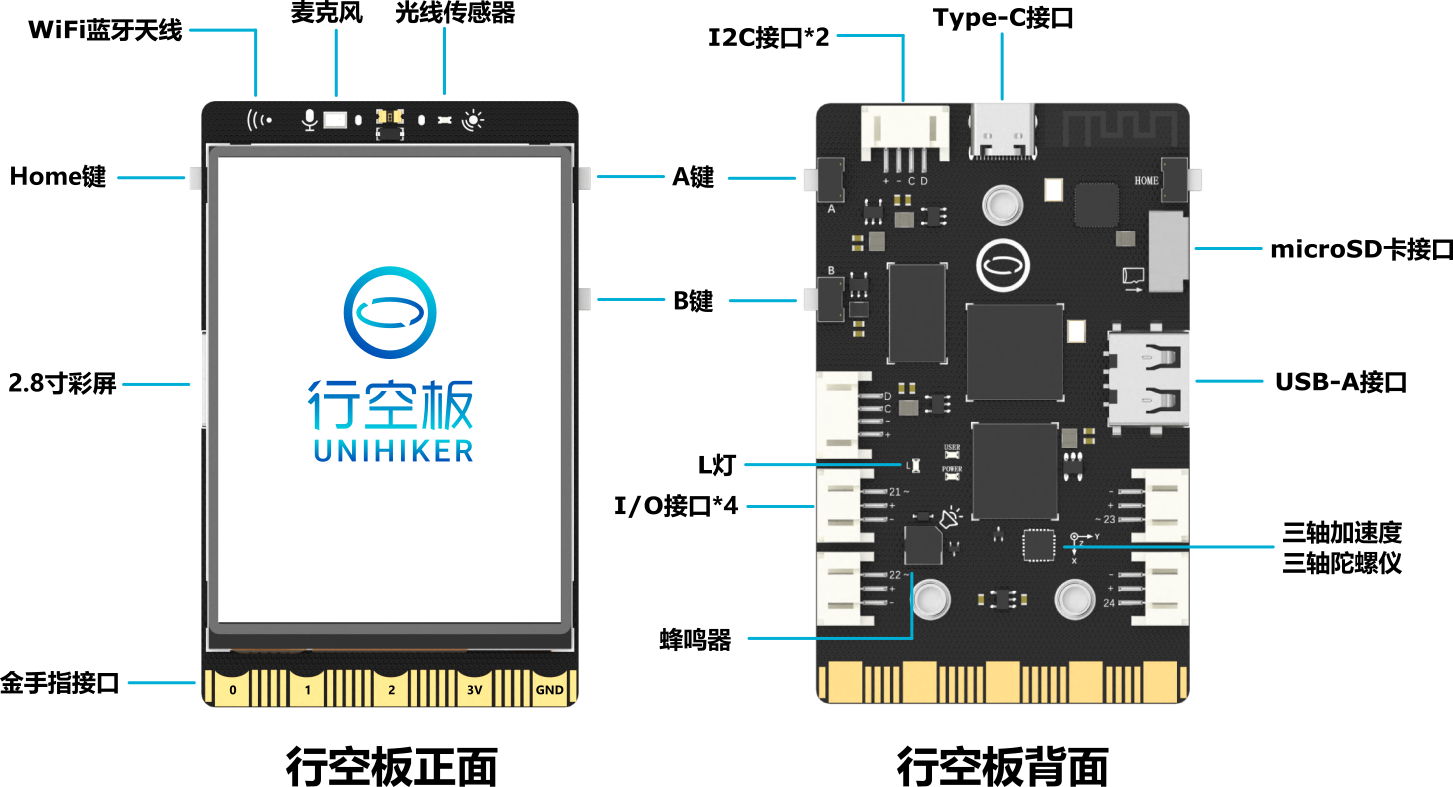
详细信息,见官方WIKI:
https://www.unihiker.com.cn/wiki/m10/jianjie
(2)二哈识图2
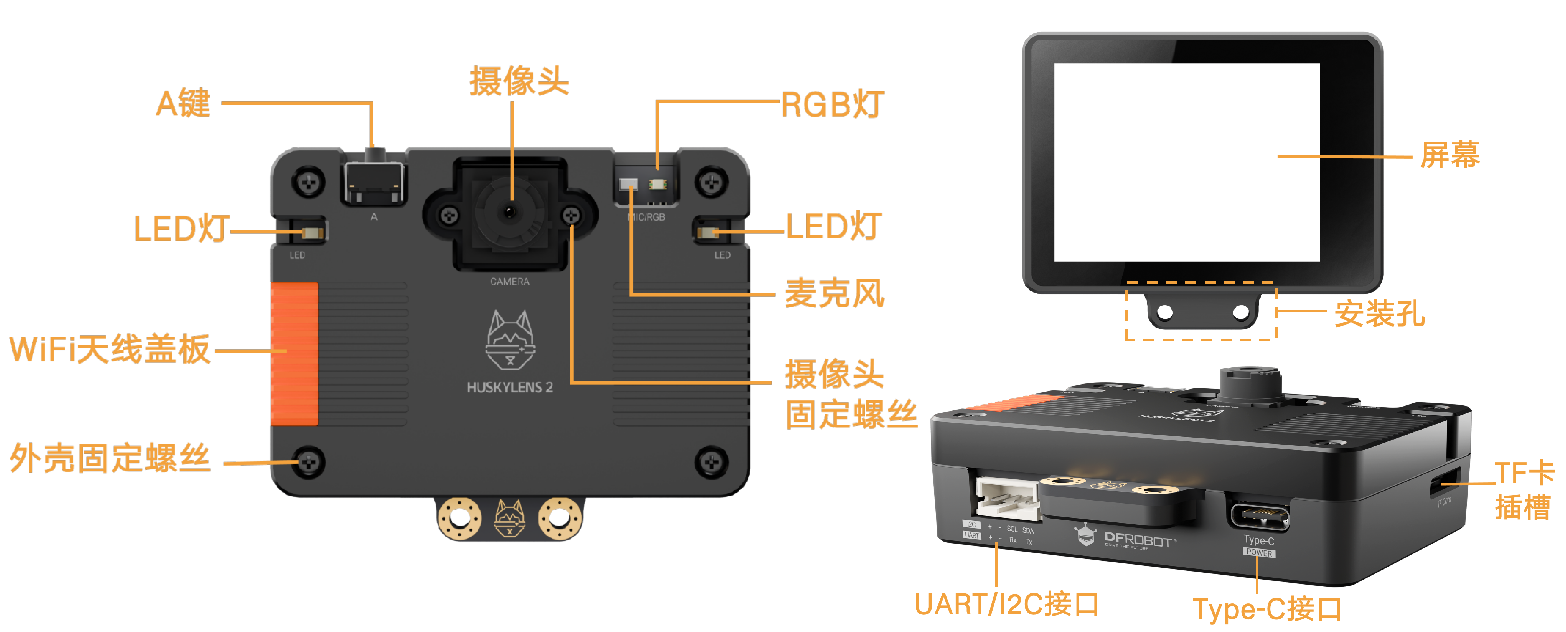
详细信息,见官方WIKI:https://wiki.dfrobot.com.cn/_SKU_SEN0638_Gravity_HUSKYLENS_2_AI_Camera_Vision_Sensor
(3)USB摄像头

(4)继电器

详细信息,见官方WIKI:
(5)USB免驱3W小喇叭

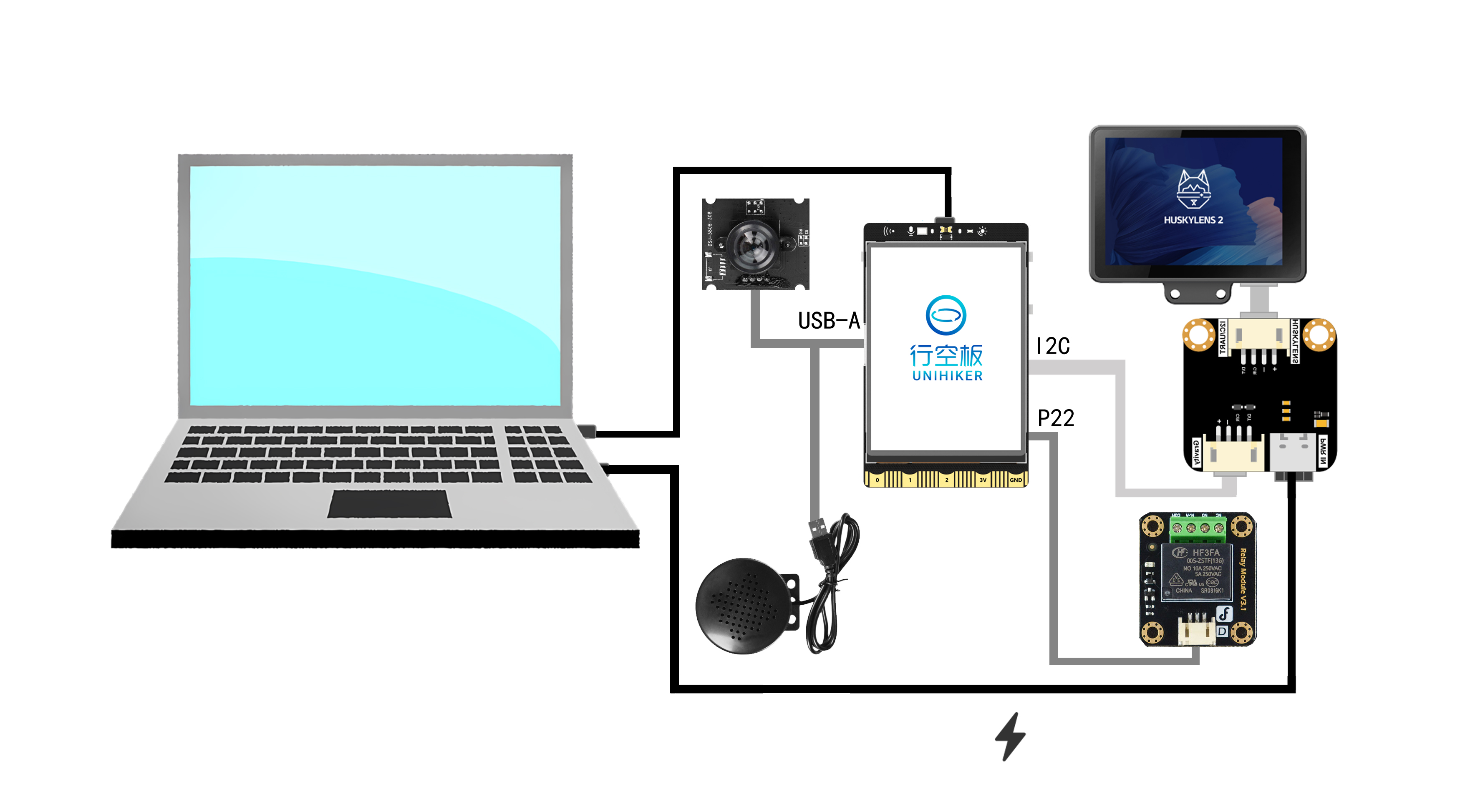
四、一目了然的连接蓝图:如何让所有硬件“对话”与协作?
清晰的连接是系统稳定运行的脉络。下图展示了所有硬件模块如何像齿轮一样精密咬合,确保数据与指令的畅通无阻。
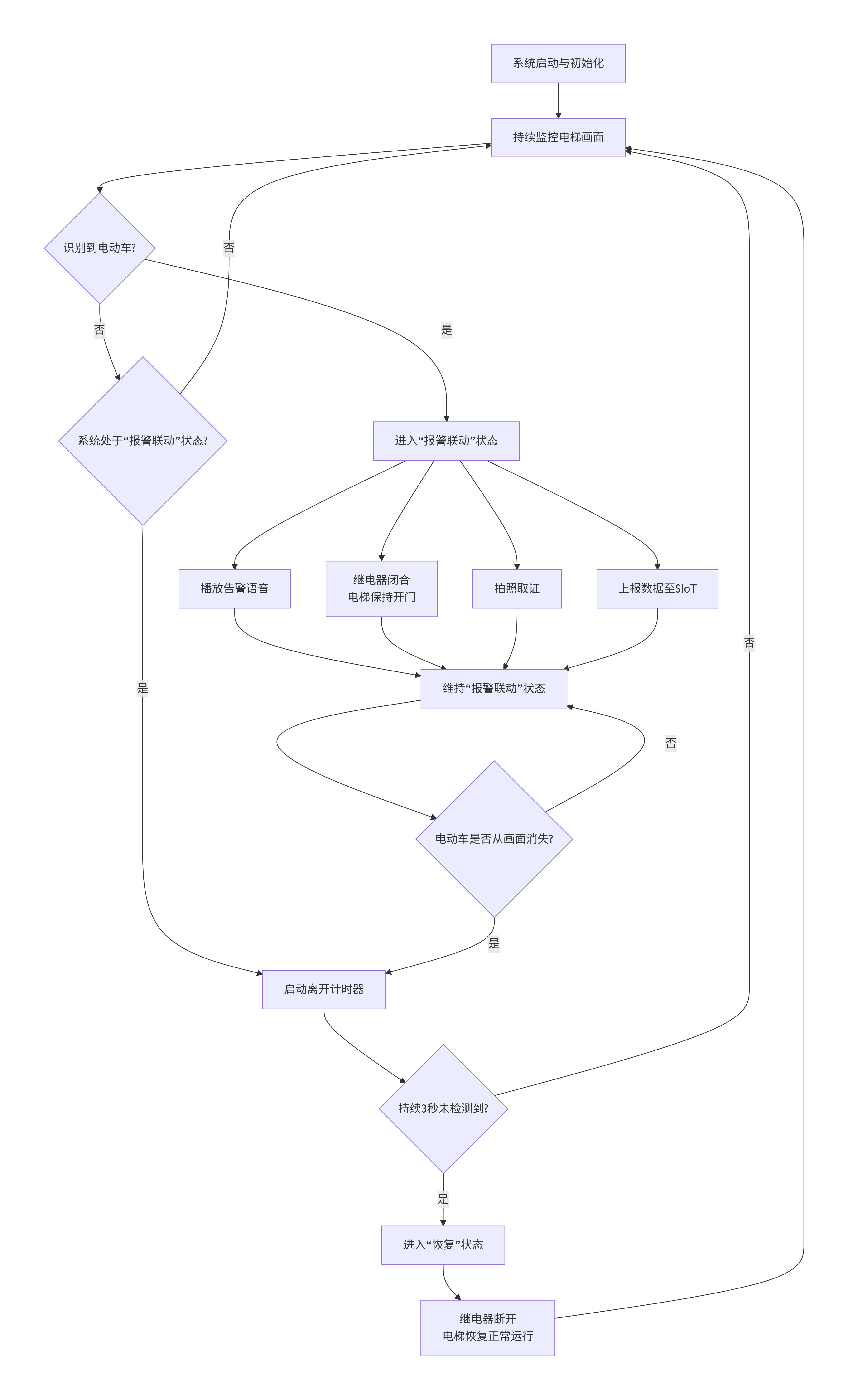
五、从“看见”到“制止”的智能决策流程图
系统的智能不仅在于识别,更在于一系列果断、正确的后续动作。下图清晰地揭示了从触发到恢复常态的完整决策逻辑,展现了系统自动化的魅力。
六、核心实战:手把手教你训练专属的AI“火眼金睛”
让AI准确识别电动车是本项目的核心。本章节将通过数据集准备、模型训练与部署的完整步骤,展示如何赋予二哈识图2这项关键技能,使其能在复杂电梯环境中稳定工作
步骤1 数据集准备与处理
(1)数据集准备。
收集并标注包含'motorcycle'等目标的数据集。我下载到数据集是PASCAL VOC格式,包含三类'person', 'bicycle', 'motorcycle'目标标注。
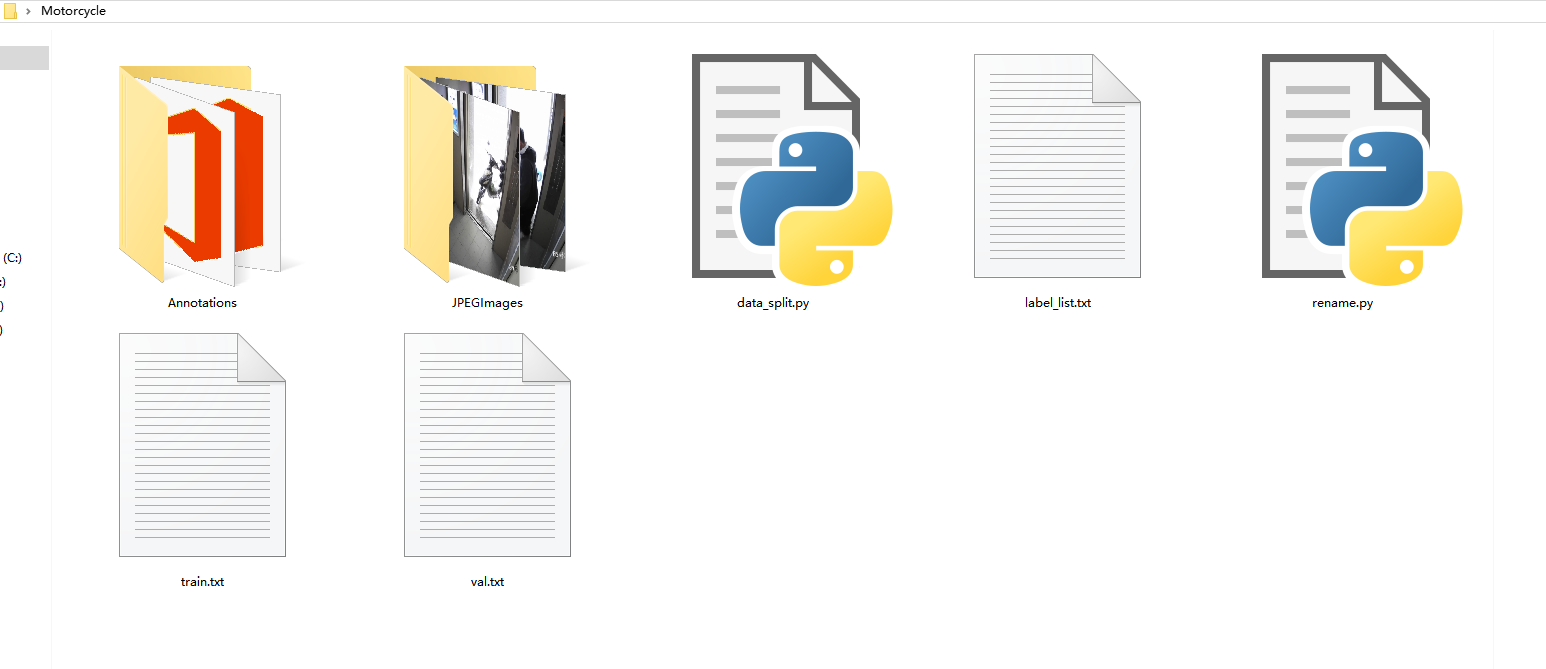
数据集核心结构为:
- Annotations:XML 格式标注文件(记录目标边界框与类别)
- JPEGImages:原始图片文件
- train.txt:训练集文件名列表
- val.txt: 验证集文件名列表
- label_list.txt:类别定义文件(含三类目标名称)
(2)转换数据集。
- 编辑并运行 Python 转换脚本(已优化绝对路径配置,含文件存在性校验),将 PASCAL VOC 格式(XML)转换为 YOLO 格式(txt 标注)。
import os
import shutil
import xml.etree.ElementTree as ET
import yaml
# ===================== 1. 配置参数(按需修改) =====================
XML_DIR = "Annotations" # VOC标注目录
IMG_DIR = "JPEGImages" # 图片目录
LABEL_LIST_PATH = "labels.txt" # 类别文件
TRAIN_LIST_PATH = "train_list.txt" # 训练集文件列表
VAL_LIST_PATH = "val_list.txt" # 验证集文件列表
TEST_LIST_PATH = "test_list.txt" # 测试集文件列表
YOLO_ROOT = "yolo_dataset" # YOLO输出根目录
# YOLO输出目录(自动创建)
YOLO_IMG_TRAIN = os.path.join(YOLO_ROOT, "images", "train")
YOLO_IMG_VAL = os.path.join(YOLO_ROOT, "images", "val")
YOLO_IMG_TEST = os.path.join(YOLO_ROOT, "images", "test")
YOLO_LBL_TRAIN = os.path.join(YOLO_ROOT, "labels", "train")
YOLO_LBL_VAL = os.path.join(YOLO_ROOT, "labels", "val")
YOLO_LBL_TEST = os.path.join(YOLO_ROOT, "labels", "test")
# ===================== 2. 初始化(创建目录+读取类别映射) =====================
# 创建YOLO目录结构
for dir_path in [YOLO_IMG_TRAIN, YOLO_IMG_VAL, YOLO_IMG_TEST,
YOLO_LBL_TRAIN, YOLO_LBL_VAL, YOLO_LBL_TEST]:
os.makedirs(dir_path, exist_ok=True)
# 读取类别并建立ID映射
with open(LABEL_LIST_PATH, "r", encoding="utf-8") as f:
class_names = [line.strip() for line in f if line.strip()]
class_id_map = {name: idx for idx, name in enumerate(class_names)}
print(f"类别ID映射:{class_id_map}")
# 检查motorcycle是否在类别列表中
if "motorcycle" not in class_id_map:
raise ValueError("labels.txt中未找到'motorcycle'类别,请检查类别文件!")
# ===================== 3. 解析文件列表 =====================
def parse_file_list(file_list_path):
"""解析文件列表,提取所有base_name"""
base_names = []
with open(file_list_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
# 拆分每行:JPEGImages\xxx.jpg Annotations\xxx.xml
parts = line.split()
if len(parts) >= 1:
# 提取base_name(去掉路径和后缀)
img_path = parts[0]
base_name = os.path.splitext(os.path.basename(img_path))[0]
base_names.append(base_name)
print(f"从 {file_list_path} 读取到 {len(base_names)} 个文件")
return base_names
# ===================== 4. 核心函数:XML转YOLO TXT =====================
def xml_to_yolo(xml_path, img_width, img_height):
"""解析XML,返回YOLO格式的标注内容(归一化坐标)"""
tree = ET.parse(xml_path)
root = tree.getroot()
yolo_lines = []
for obj in root.findall("object"):
# 获取类别ID(跳过未定义类别)
obj_name = obj.find("name").text.strip()
if obj_name not in class_id_map:
print(f"警告:跳过未定义类别 {obj_name}(XML文件:{xml_path})")
continue
class_id = class_id_map[obj_name]
# 解析VOC边界框(xmin, ymin, xmax, ymax)
bndbox = obj.find("bndbox")
xmin = int(bndbox.find("xmin").text)
ymin = int(bndbox.find("ymin").text)
xmax = int(bndbox.find("xmax").text)
ymax = int(bndbox.find("ymax").text)
# 转换为YOLO格式(归一化中心坐标+宽高)
center_x = (xmin + xmax) / (2 * img_width)
center_y = (ymin + ymax) / (2 * img_height)
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 确保坐标在[0,1]范围内(防止越界)
center_x = max(0.0, min(1.0, center_x))
center_y = max(0.0, min(1.0, center_y))
width = max(0.0, min(1.0, width))
height = max(0.0, min(1.0, height))
# 保留6位小数,拼接成一行
yolo_lines.append(f"{class_id} {center_x:.6f} {center_y:.6f} {width:.6f} {height:.6f}\n")
return yolo_lines
# ===================== 5. 批量处理函数 =====================
def process_files(base_names, yolo_img_dir, yolo_lbl_dir):
"""批量复制图片+生成YOLO标注"""
success_count = 0
fail_count = 0
for base_name in base_names:
try:
# 1. 复制图片到YOLO images目录
img_src = os.path.join(IMG_DIR, f"{base_name}.jpg")
img_dst = os.path.join(yolo_img_dir, f"{base_name}.jpg")
if not os.path.exists(img_src):
print(f"警告:图片不存在 {img_src},跳过")
fail_count += 1
continue
shutil.copyfile(img_src, img_dst)
# 2. 解析XML生成YOLO TXT标注
xml_src = os.path.join(XML_DIR, f"{base_name}.xml")
lbl_dst = os.path.join(yolo_lbl_dir, f"{base_name}.txt")
if not os.path.exists(xml_src):
print(f"警告:标注不存在 {xml_src},跳过")
fail_count += 1
continue
# 获取图片宽高(用于坐标归一化)
tree = ET.parse(xml_src)
size_elem = tree.find("size")
if size_elem is None:
print(f"警告:XML文件 {xml_src} 中未找到size信息,跳过")
fail_count += 1
continue
img_w = int(size_elem.find("width").text)
img_h = int(size_elem.find("height").text)
# 转换并写入YOLO标注
yolo_content = xml_to_yolo(xml_src, img_w, img_h)
with open(lbl_dst, "w", encoding="utf-8") as f:
f.writelines(yolo_content)
success_count += 1
except Exception as e:
print(f"处理文件 {base_name} 时出错: {e}")
fail_count += 1
print(f"成功处理: {success_count} 个, 失败: {fail_count} 个")
return success_count, fail_count
# ===================== 6. 生成YOLO配置文件 =====================
def create_yolo_config(yolo_root, class_names, img_train_dir, img_val_dir, img_test_dir=None):
"""创建YOLO训练配置文件data.yaml"""
config = {
'path': os.path.abspath(yolo_root), # 数据集根目录绝对路径
'train': os.path.relpath(img_train_dir, yolo_root).replace('\\', '/'), # 训练集相对路径
'val': os.path.relpath(img_val_dir, yolo_root).replace('\\', '/'), # 验证集相对路径
'nc': len(class_names), # 类别数量
'names': class_names # 类别名称列表
}
# 如果有测试集,添加测试集路径
if img_test_dir and os.path.exists(img_test_dir):
config['test'] = os.path.relpath(img_test_dir, yolo_root).replace('\\', '/')
# 添加额外的常用配置
config['download'] = None # 可选:数据集下载URL
# 保存为yaml文件
yaml_path = os.path.join(yolo_root, 'data.yaml')
with open(yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(config, f, default_flow_style=False, allow_unicode=True, sort_keys=False)
print(f"\nYOLO配置文件已生成: {yaml_path}")
print("配置文件内容:")
print("=" * 50)
for key, value in config.items():
if key == 'names':
print(f"{key}:")
for i, name in enumerate(value):
print(f" {i}: {name}")
else:
print(f"{key}: {value}")
print("=" * 50)
return yaml_path
# ===================== 7. 主执行流程 =====================
if __name__ == "__main__":
# 解析训练集、验证集、测试集文件列表
print("正在解析文件列表...")
train_names = parse_file_list(TRAIN_LIST_PATH)
val_names = parse_file_list(VAL_LIST_PATH)
test_names = parse_file_list(TEST_LIST_PATH)
total_files = len(train_names) + len(val_names) + len(test_names)
print(f"\n总计: 训练集 {len(train_names)} 个, 验证集 {len(val_names)} 个, "
f"测试集 {len(test_names)} 个, 总共 {total_files} 个文件")
# 处理训练集
print("\n" + "="*50)
print("正在处理训练集...")
train_success, train_fail = process_files(train_names, YOLO_IMG_TRAIN, YOLO_LBL_TRAIN)
# 处理验证集
print("\n" + "="*50)
print("正在处理验证集...")
val_success, val_fail = process_files(val_names, YOLO_IMG_VAL, YOLO_LBL_VAL)
# 处理测试集
print("\n" + "="*50)
print("正在处理测试集...")
test_success, test_fail = process_files(test_names, YOLO_IMG_TEST, YOLO_LBL_TEST)
# 生成YOLO配置文件
print("\n" + "="*50)
print("正在生成YOLO配置文件...")
yaml_path = create_yolo_config(
YOLO_ROOT,
class_names,
YOLO_IMG_TRAIN,
YOLO_IMG_VAL,
YOLO_IMG_TEST
)
print("\n" + "="*50)
print("转换完成!")
print(f"训练集: {train_success} 成功, {train_fail} 失败")
print(f"验证集: {val_success} 成功, {val_fail} 失败")
print(f"测试集: {test_success} 成功, {test_fail} 失败")
print(f"\nYOLO数据集保存至:{YOLO_ROOT}")
print("YOLO目录结构:")
print(f"- {YOLO_ROOT}/images/train:训练集图片")
print(f"- {YOLO_ROOT}/images/val:验证集图片")
print(f"- {YOLO_ROOT}/images/test:测试集图片")
print(f"- {YOLO_ROOT}/labels/train:训练集YOLO标注(.txt)")
print(f"- {YOLO_ROOT}/labels/val:验证集YOLO标注(.txt)")
print(f"- {YOLO_ROOT}/labels/test:测试集YOLO标注(.txt)")
print(f"- {YOLO_ROOT}/data.yaml:YOLO训练配置文件")
# 使用说明
print("\n" + "="*50)
print("使用说明:")
print("1. 使用以下命令进行YOLO训练:")
print(f" yolo task=detect mode=train data={yaml_path} model=yolov8n.pt epochs=100")
print("\n2. 或使用以下Python代码:")
print(f''' from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='{yaml_path}', epochs=100)''')python代码执行后,会生成标注好的YOLO格式的数据集位于yolo_dataset目录下。
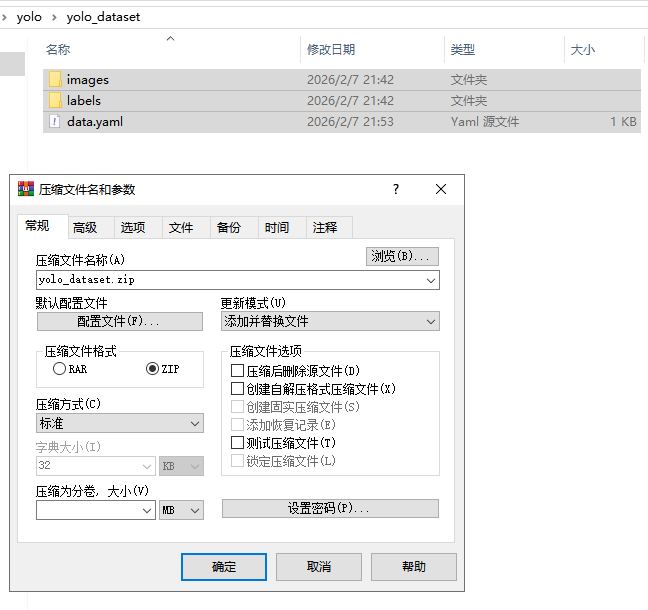
转换后自动生成标准 YOLO 数据集目录yolo_dataset,结构如下:

(3)生成 YOLO 训练配置文件(.yaml)。
在yolo_dataset目录下,新建data.yaml文件,内容如下。

(4)压缩数据集。
将yolo_dataset目录下的images文件夹、labels文件夹、data.yaml文件一起压缩为yolo_dataset.zip。
步骤2 模型训练与部署(基于 Mind+ V2)
(1)模型训练。
打开Mind+ V2,进入“模型训练”->“目标识别”,选择“上传”。
选择“有标注数据(YOLO格式)”,选择刚才压缩得到的yoyo_dataset.zip文件上传。
点击“训练模型”,开始训练。
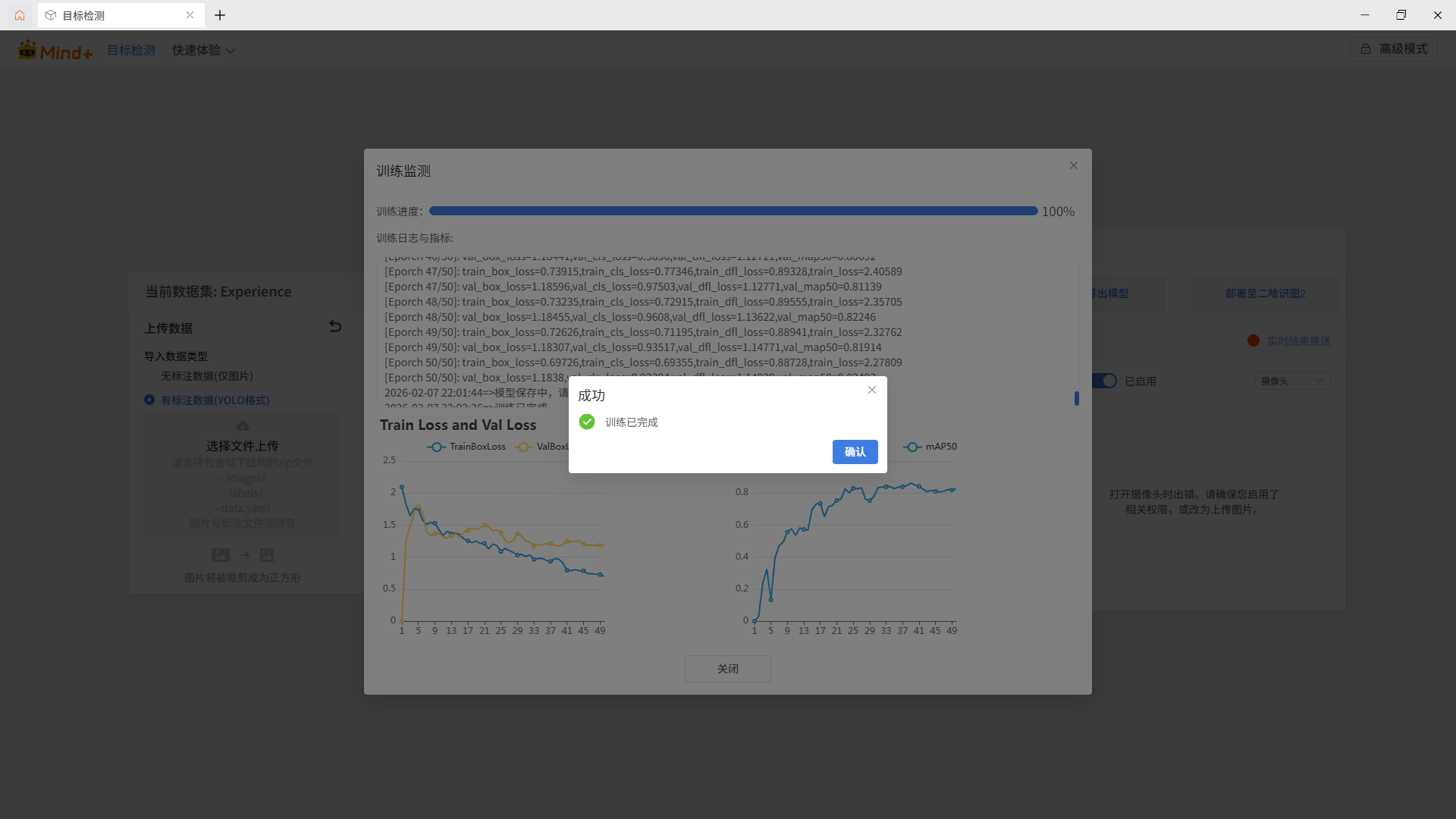
训练完成。
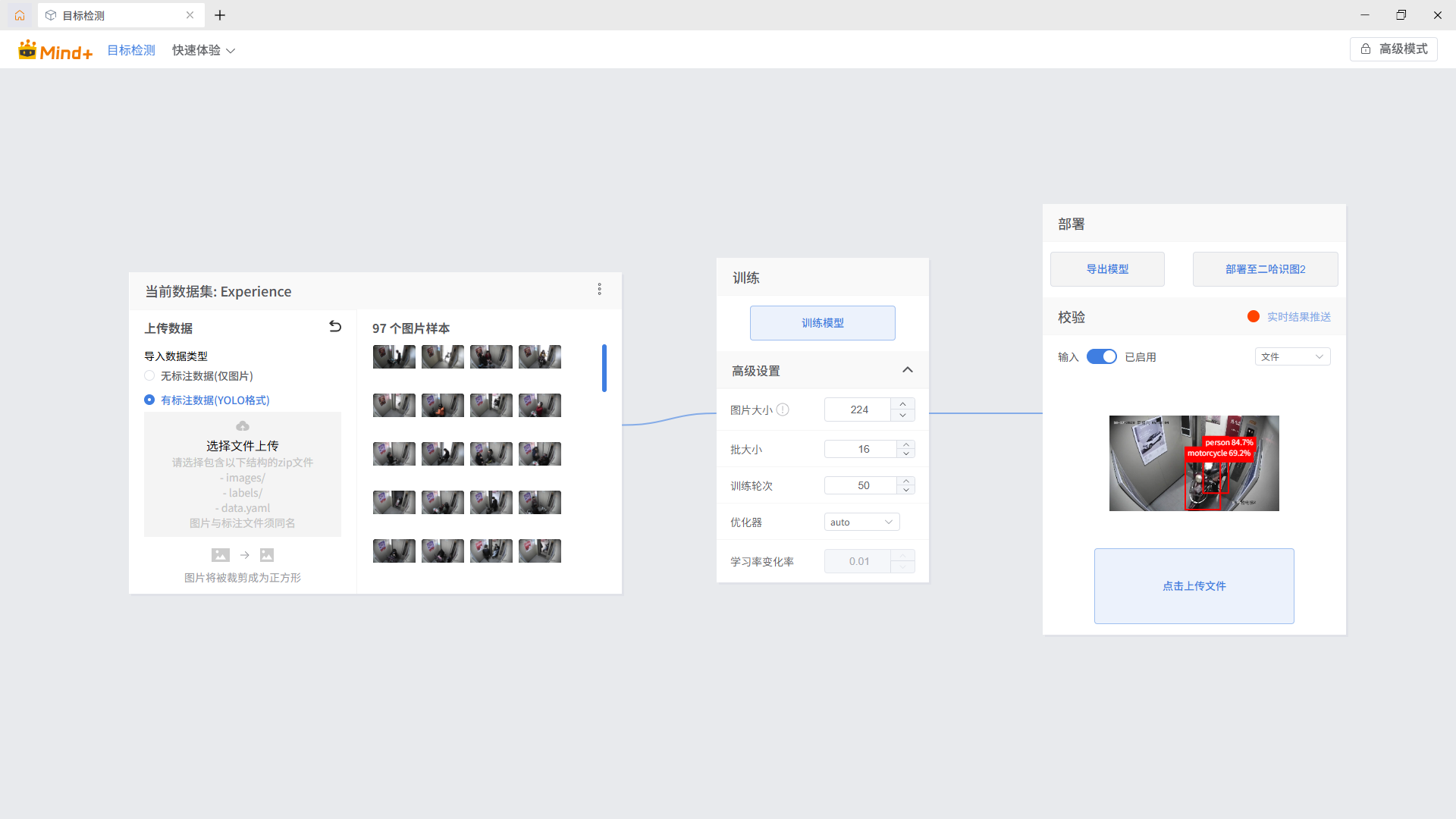
(2)模型校验。
输入选择“文件”,点击“点击上传文件”,选择yolo_dataset\images\val下图片,进行模型校验。

图片能正常标记出人、电动车等,说明校验成功。
(3)模型部署至二哈识图 2
点击“部署至二哈识图2”,选择应用图标,设置应用名称、标题名称。
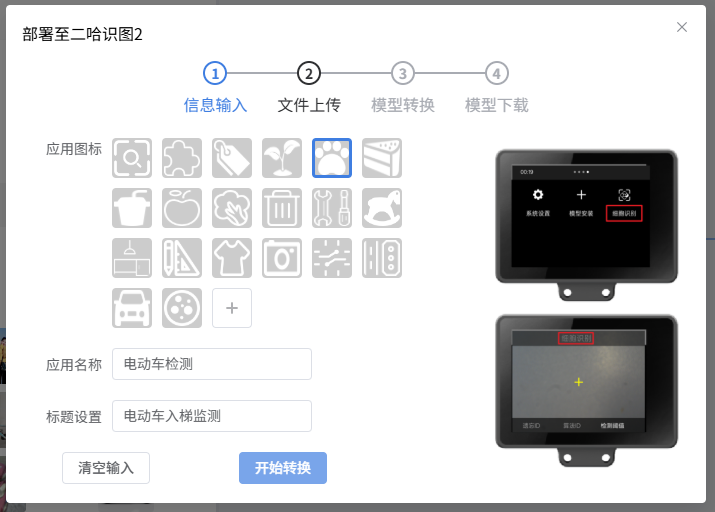
开始“模型转换”,直到“模型转换成功”。
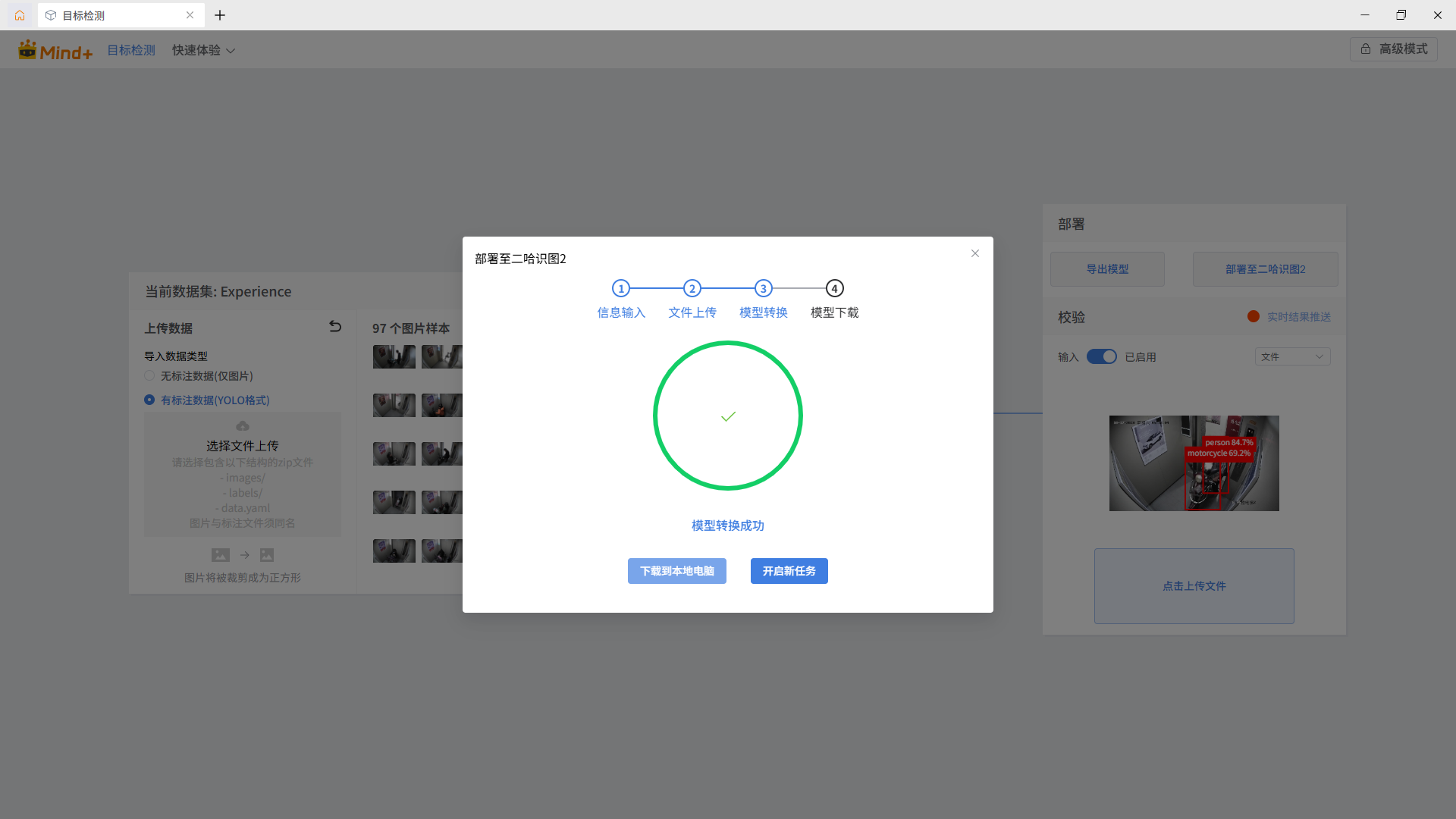
点击“下载到本地电脑”,选择路径进行保存。
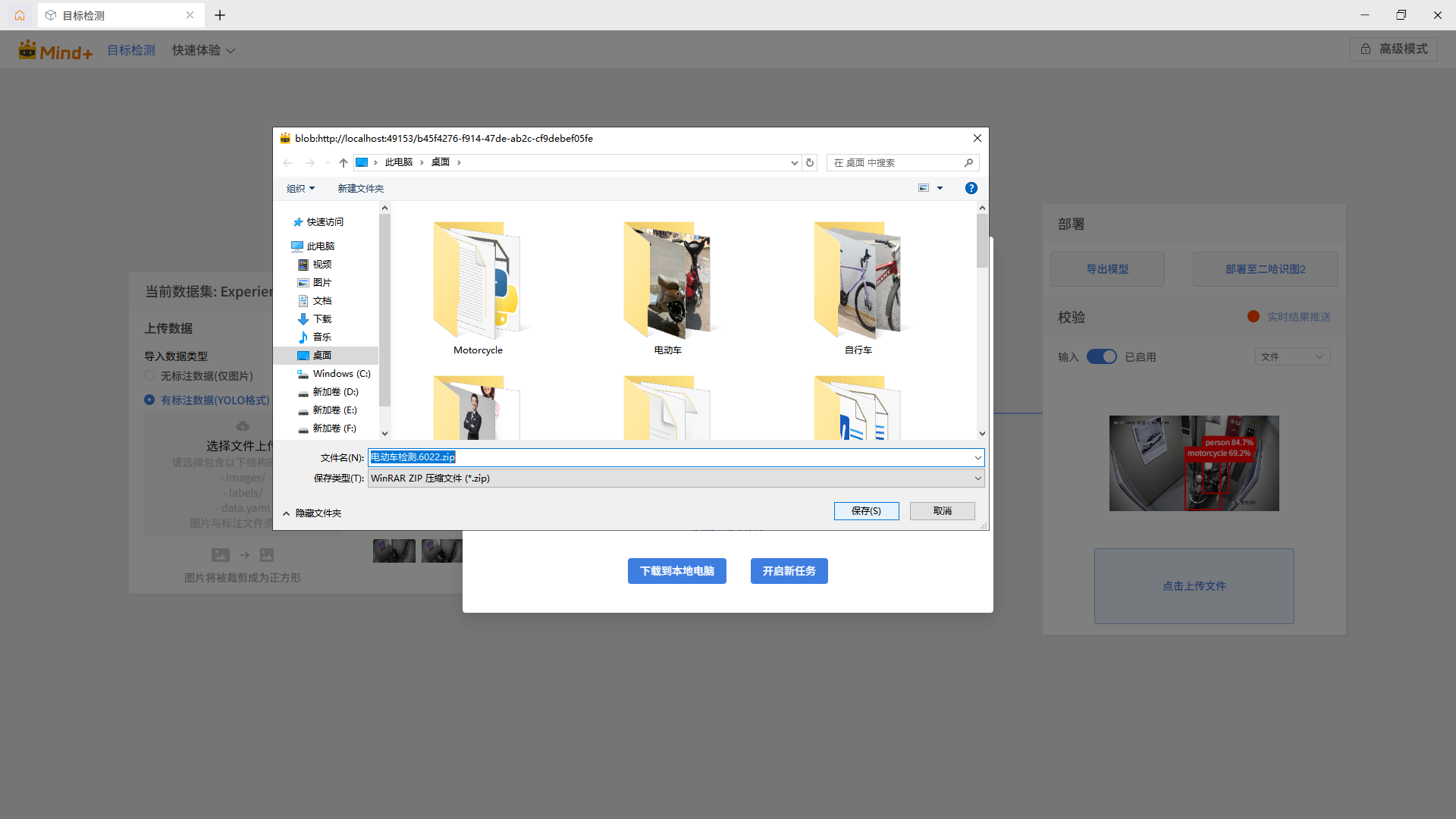
将下载的模型,赋值到二哈识图2的 Huskylens>storage > installation_package目录下。
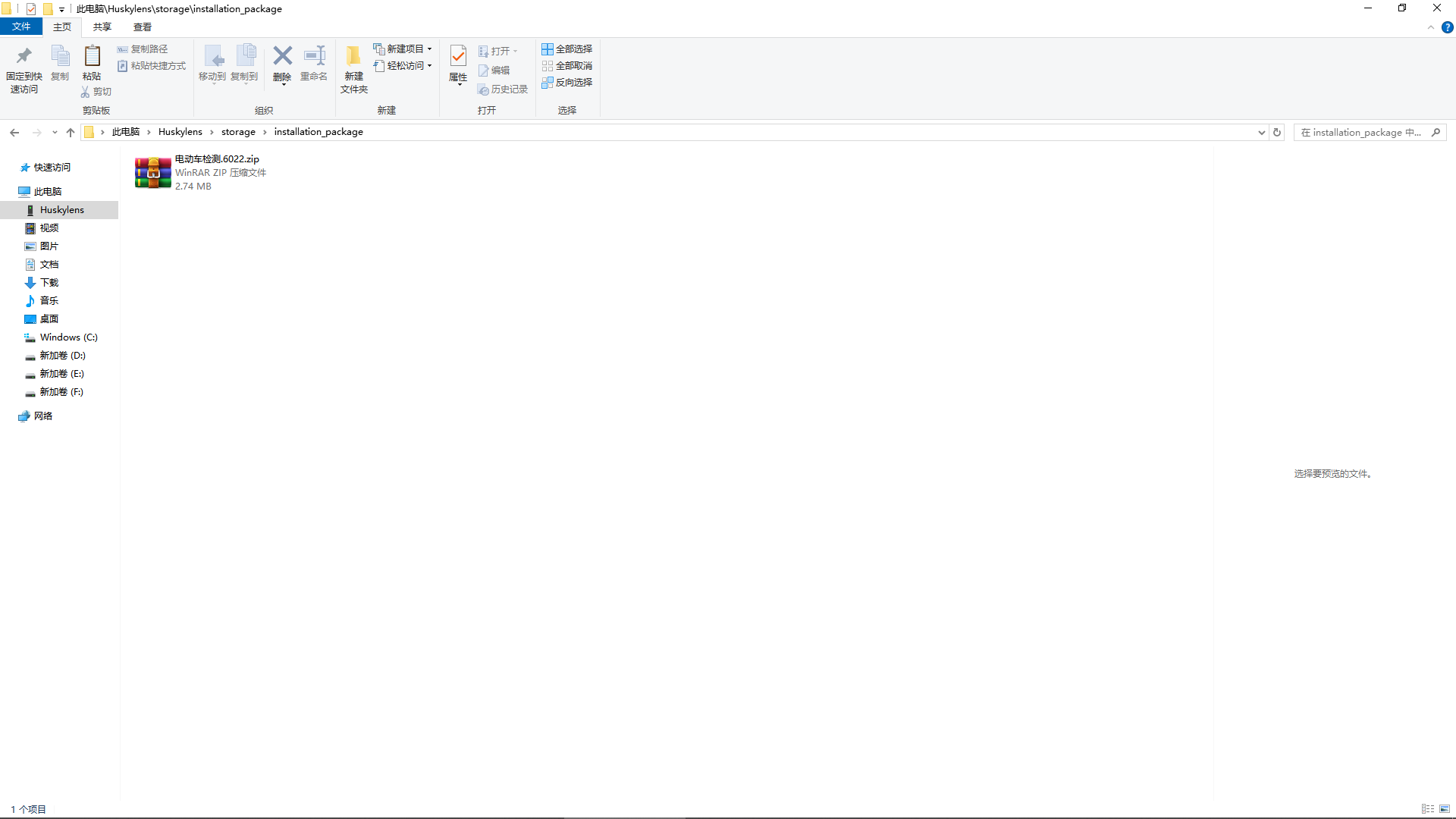
(4)模型安装。
点击二哈识图2屏幕,选择“模型安装”,“本地安装”。
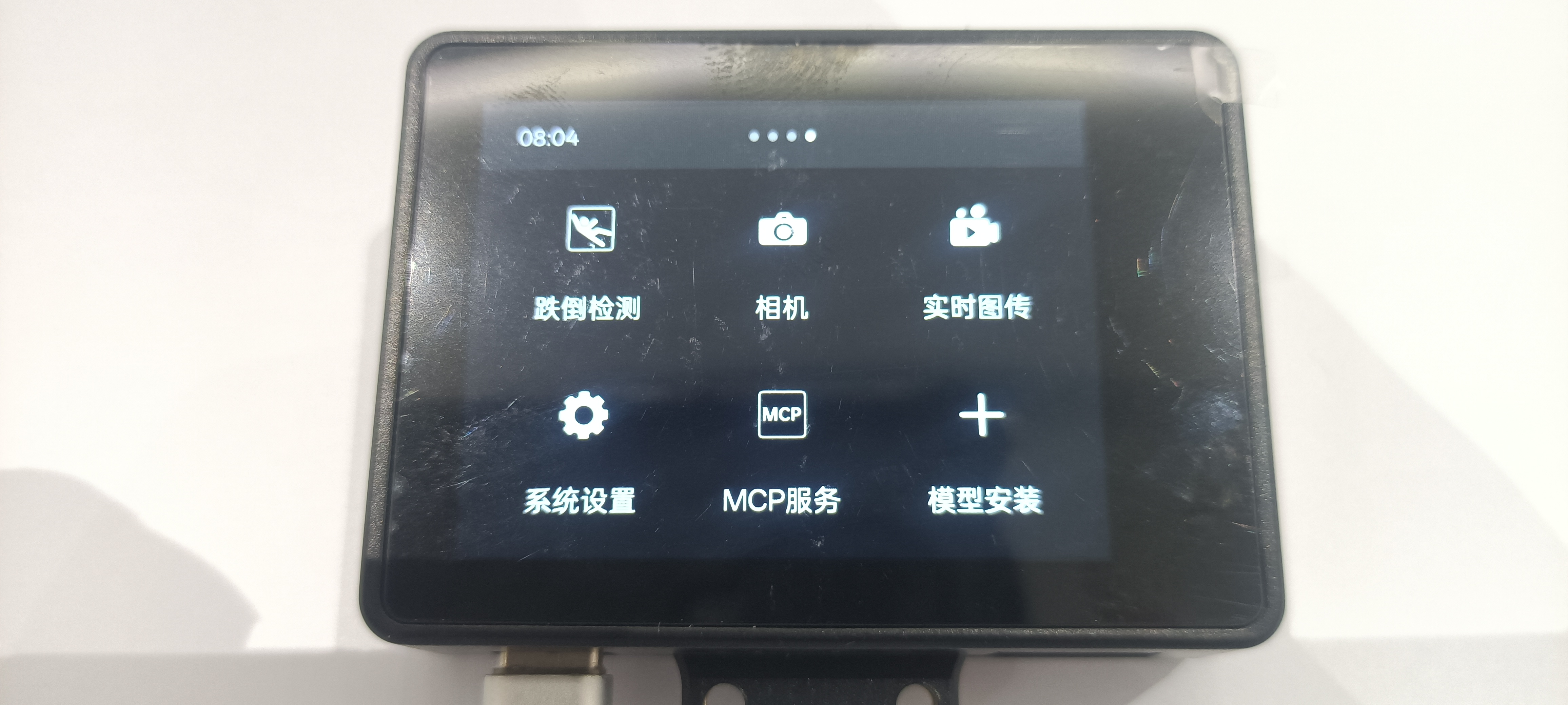
模型安装成功。

在屏幕上选择“电动车检测”模型,即可使用。
步骤3 SIoT 服务器安装与配置
(1)服务器启动。
解压下载的SIoT V2,双击start SIoT.bat即可启动新版SIoT,
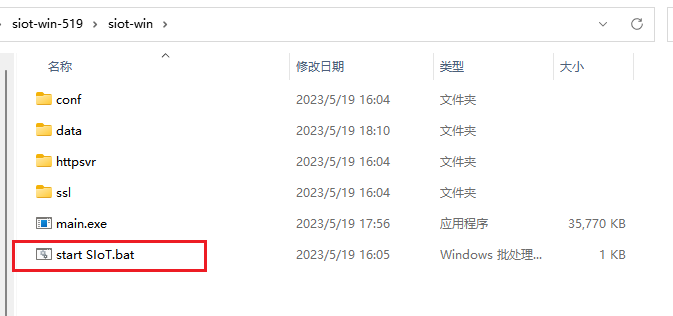
(2)弹出的“Windows安全中心警报”对话框,勾选专用网络和公用网络,否则外部设备可能无法访问。
(3)出现下图所示弹窗,siot服务器运行正常。
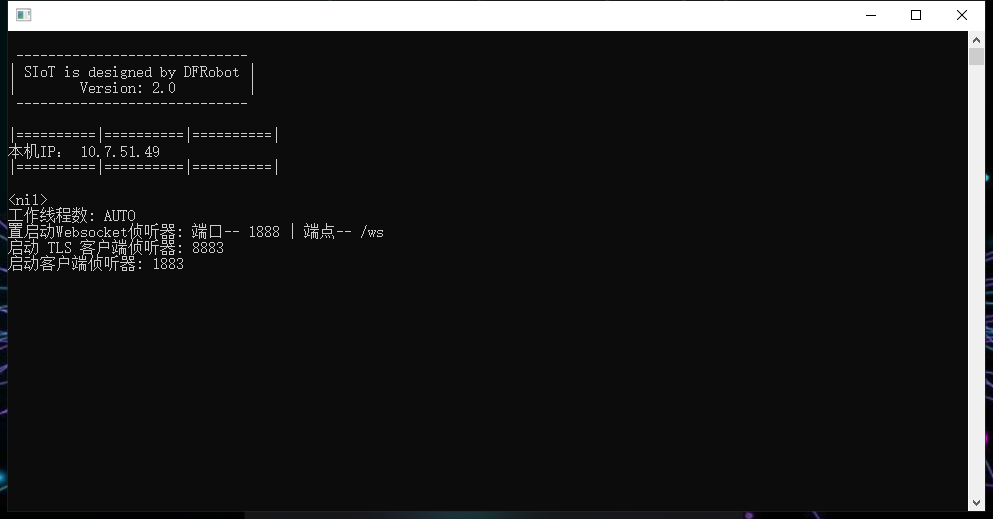
(2)服务器登录
在浏览器地址栏输入http://127.0.1:8080或者http://本机ip地址:8080,输入用户名siot,密码dfrobot登录。
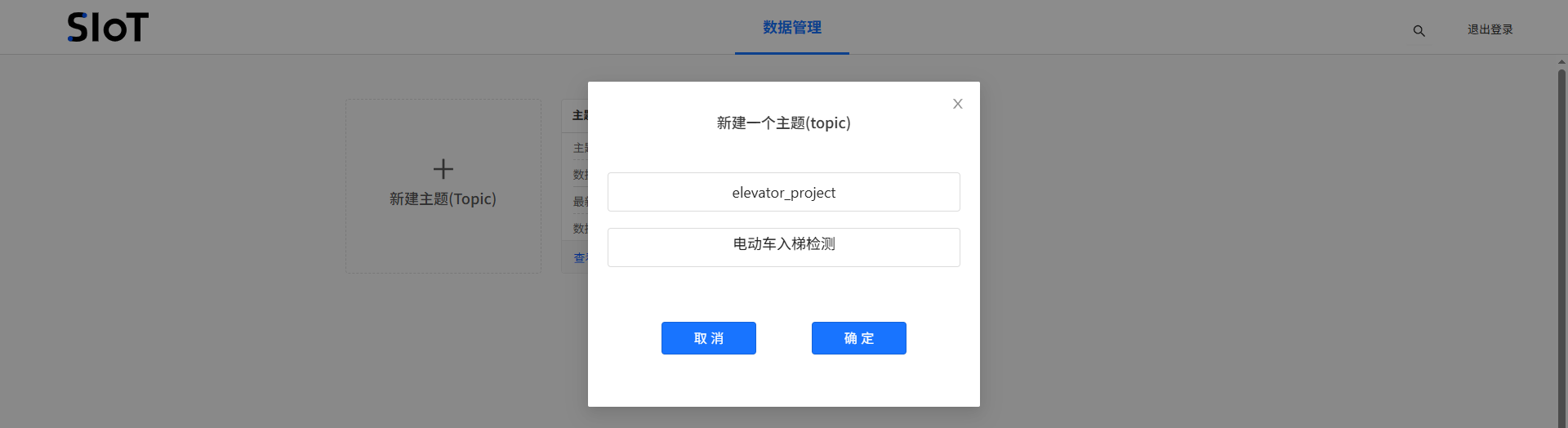
(3)新建MQTT主题。
点击“新建主题(Topic)”,新建elevator_project主题。
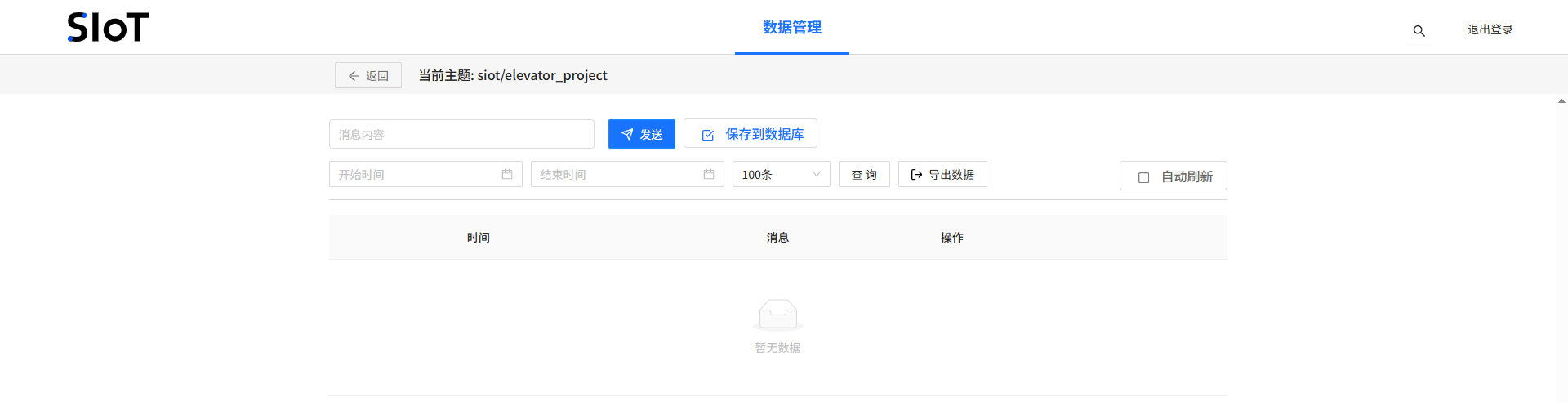
系统自动生成对应的MQTT主题:siot/elevator_project。
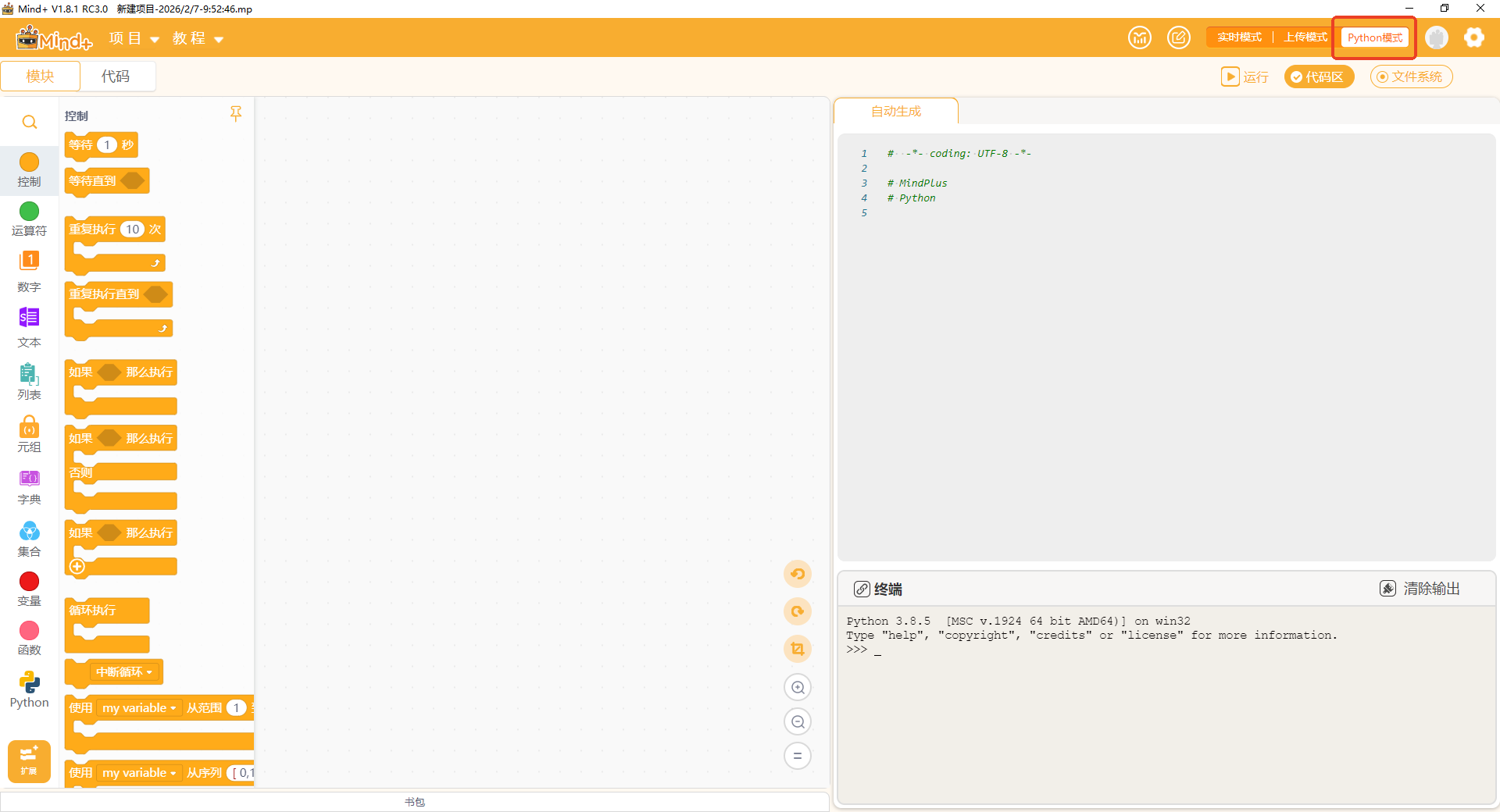
步骤4 Mind+ Python 模式用户库安装与程序编写
(1)软件准备。
在电脑安装Mind+软件(V1.8.2或以上),并切换至 “Python模式”。
(2)官方库安装。
在“扩展”面板中,依次选择官方库 中“行空板M10”、“MQTT-py”、“OpenCV”库,进行安装。
(3)用户库安装。
在用户库中搜索 “HuskyLens 2”,选择进行安装。
同样的方法,搜索“base64”用户库,选择进行安装。

(4)基础功能程序编写。
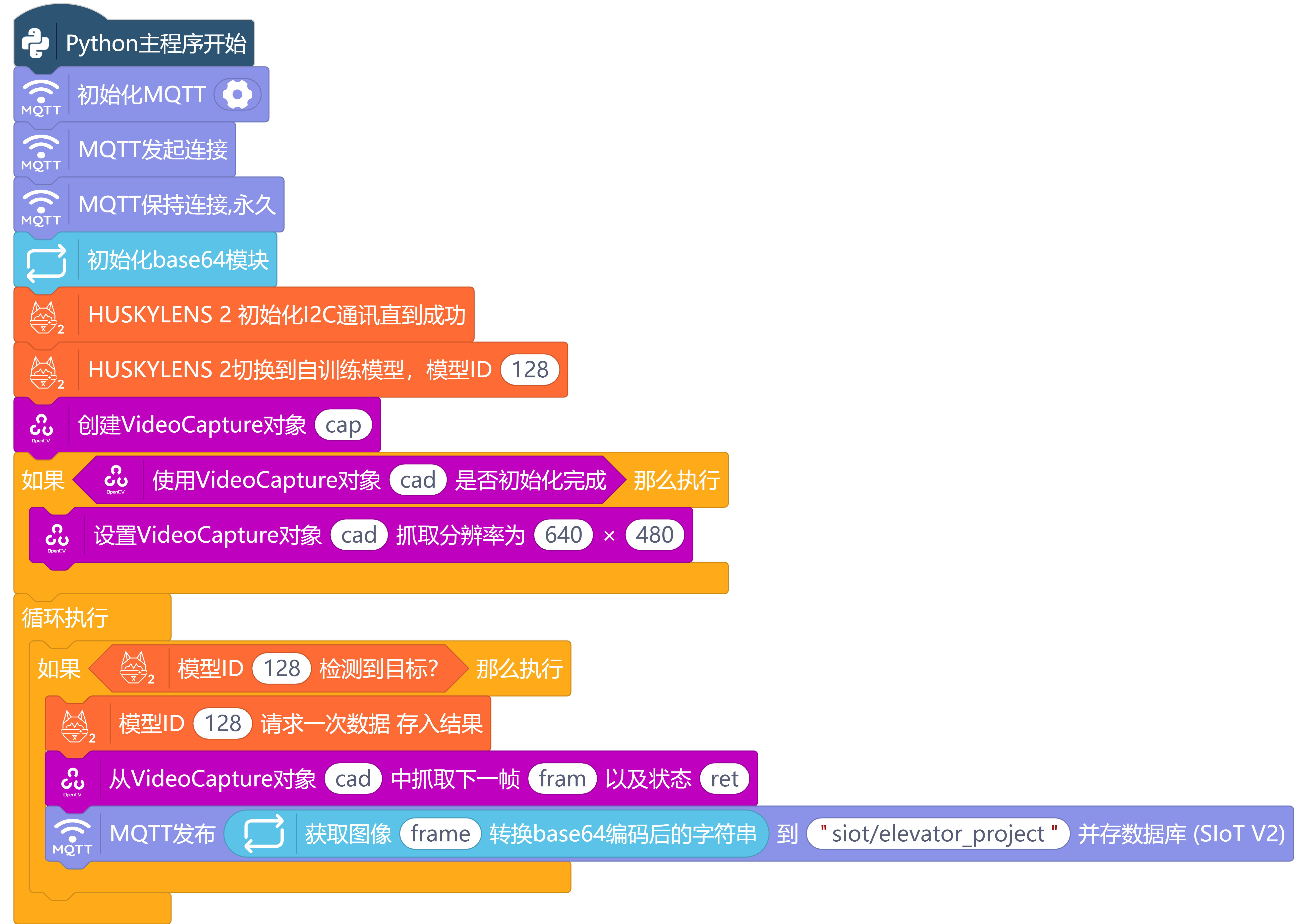
七、“行空板”大脑的程序实现:完整控制逻辑与代码
作为系统的指挥中枢,行空板M10上的控制程序负责调度一切。以下是在前面图像化程序的基础上晚上的能实现精准判断与快速响应的完整代码逻辑。
from unihiker import GUI, Audio
import time
import json
import cv2
import base64
import random
from datetime import datetime
from dfrobot_huskylensv2 import *
from pinpong.board import Board, Pin
import siot
# ---------- 1. 初始化硬件 ----------
Board().begin()
u_gui = GUI()
u_audio = Audio() # 初始化音频播放模块
# 继电器控制引脚初始化
RELAY_PIN = Pin(Pin.P22, Pin.OUT)
RELAY_PIN.write_digital(0)
print("[INFO] 继电器初始化完成,状态:断开")
# ---------- 2. 初始化二哈识图2 (I2C) ----------
huskylens = HuskylensV2_I2C()
huskylens.knock()
ALGORITHM_CUSTOM_MODEL = 129 # 自训练模型算法ID
huskylens.switchAlgorithm(ALGORITHM_CUSTOM_MODEL)
print("[INFO] 二哈识图2初始化完成,自训练模型已加载。")
# ---------- 3. 初始化USB摄像头 ----------
cap = cv2.VideoCapture(0)
if cap.isOpened():
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
print("[INFO] USB摄像头初始化成功。")
else:
print("[ERROR] 摄像头初始化失败!")
cap = None
# ---------- 4. MQTT与标签配置 ----------
SIOT_SERVER = "127.0.0.1" # 改为实际SIoT服务器IP
SIOT_PORT = 1883
SIOT_USER = "siot"
SIOT_PASSWORD = "dfrobot"
DEVICE_ID = "siot"
PROJECT_NAME = "elevator_project"
TOPIC = f"{DEVICE_ID}/{PROJECT_NAME}"
# 标签中英文映射(匹配你的新标签)
LABEL_MAP = {
'person': '人',
'bicycle': '自行车',
'motorcycle': '电动车',
}
# ---------- 5. 屏幕显示初始化 ----------
title = u_gui.draw_text(text="电梯安全联动监控系统", x=10, y=10, font_size=16, color="#0000FF")
status_label = u_gui.draw_text(text="状态:初始化...", x=10, y=50, font_size=12)
relay_label = u_gui.draw_text(text="继电器:断开", x=10, y=80, font_size=12)
count_label = u_gui.draw_text(text="检测目标:0", x=10, y=110, font_size=12)
last_event_label = u_gui.draw_text(text="最后事件:无", x=10, y=140, font_size=10, color="#666666")
# ---------- 6. 连接SIoT服务器 ----------
def connect_siot():
try:
client_id = f"m10_{random.randint(10000, 99999)}"
siot.init(client_id=client_id, server=SIOT_SERVER, port=SIOT_PORT,
user=SIOT_USER, password=SIOT_PASSWORD)
siot.connect()
siot.loop()
print(f"[INFO] SIoT连接成功: {SIOT_SERVER}")
status_label.config(text="状态:已连接,监控中")
status_label.config(color="#008000")
return True
except Exception as e:
print(f"[ERROR] SIoT连接失败: {e}")
status_label.config(text="状态:网络连接失败")
status_label.config(color="red")
return False
siot_connected = connect_siot()
# ---------- 7. 核心功能函数 ----------
def set_relay(state):
"""控制继电器状态 (0:断开/正常, 1:闭合/开门)"""
RELAY_PIN.write_digital(state)
state_text = "闭合" if state else "断开"
color = "red" if state else "green"
relay_label.config(text=f"继电器:{state_text}")
relay_label.config(color=color)
print(f"[RELAY] 状态 -> {state_text}")
def play_alarm():
"""播放告警语音"""
try:
u_audio.start_play("/home/pi/record.wav") # 请确保语音文件路径正确
print("[AUDIO] 播放告警语音")
except Exception as e:
print(f"[ERROR] 播放语音失败: {e}")
def capture_photo():
"""捕获单张现场照片并返回Base64字符串"""
if cap and cap.isOpened():
ret, frame = cap.read()
if ret:
_, buffer = cv2.imencode('.jpg', frame, [cv2.IMWRITE_JPEG_QUALITY, 85])
return base64.b64encode(buffer).decode('utf-8')
return ""
def send_target_data(target_obj, photo_base64, timestamp):
"""为单个目标生成并上报数据到SIoT"""
if not siot_connected:
return False
try:
label_en = target_obj.name
label_cn = LABEL_MAP.get(label_en, label_en)
payload = {
"time": timestamp,
"lng": 116.397129, # 模拟数据,实际项目可接GPS模块
"lat": 39.916527,
"photo": photo_base64,
"deviceId": "1号电梯",
"damageCategory": label_cn
}
siot.publish_save(topic=TOPIC, data=json.dumps(payload, ensure_ascii=False))
print(f"[SIoT] 上报成功: {label_cn}")
return True
except Exception as e:
print(f"[ERROR] 上报失败: {e}")
return False
# ---------- 8. 主状态循环 ----------
print("[INFO] 系统启动,进入监控状态...")
electric_vehicle_present = False
departure_timer = 0
DEPARTURE_CONFIRM_TIME = 3 # 电动车离开确认时间(秒)
last_trigger_time = 0
EVENT_COOLDOWN = 10 # 事件上报冷却时间(秒)
while True:
# 维护MQTT连接
if siot_connected:
siot.loop()
# 获取二哈识图2识别结果
huskylens.getResult(ALGORITHM_CUSTOM_MODEL)
if huskylens.available(ALGORITHM_CUSTOM_MODEL):
target_count = huskylens.getCachedResultNum(ALGORITHM_CUSTOM_MODEL)
count_label.config(text=f"检测目标:{target_count}")
current_ev_detected = False
detected_targets = []
# 遍历所有识别到的目标
for i in range(target_count):
target = huskylens.getCachedResultByIndex(ALGORITHM_CUSTOM_MODEL, i)
if target:
if target.name == 'motorcycle':
current_ev_detected = True
if target.name in LABEL_MAP:
detected_targets.append(target)
current_time = time.time()
# 状态1:检测到电动车进入
if current_ev_detected and not electric_vehicle_present:
print("[ALERT] 电动车进入!触发联动。")
electric_vehicle_present = True
departure_timer = 0
# 执行联动动作
play_alarm()
set_relay(1)
# 拍照并上报
if current_time - last_trigger_time > EVENT_COOLDOWN:
snapshot = capture_photo()
event_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for target in detected_targets:
if target.name == 'motorcycle':
send_target_data(target, snapshot, event_time)
last_trigger_time = current_time
break
status_label.config(text="状态:电动车入梯,电梯已锁定")
status_label.config(color="red")
# 状态2:电动车持续存在
elif current_ev_detected and electric_vehicle_present:
departure_timer = 0 # 重置离开计时器
status_label.config(text="状态:电动车仍在电梯内")
# 状态3:电动车离开(检测中)
elif not current_ev_detected and electric_vehicle_present:
departure_timer += 0.1
if departure_timer >= DEPARTURE_CONFIRM_TIME:
print("[INFO] 电动车已离开,恢复电梯。")
electric_vehicle_present = False
set_relay(0)
status_label.config(text="状态:已恢复,监控中")
status_label.config(color="green")
time.sleep(2)
status_label.config(text="状态:监控中")
status_label.config(color="black")
time.sleep(0.1)
# 资源释放
if cap:
cap.release()
print("[INFO] 系统停止。")八、云端大脑:可视化安防管理平台,让安全一览无余
“本系统的价值不止于现场的自动拦截。通过云端可视化平台,每一次本地事件都转化为可追溯、可分析的数据资产,使安全管理从被动响应迈向主动预警与精准决策。
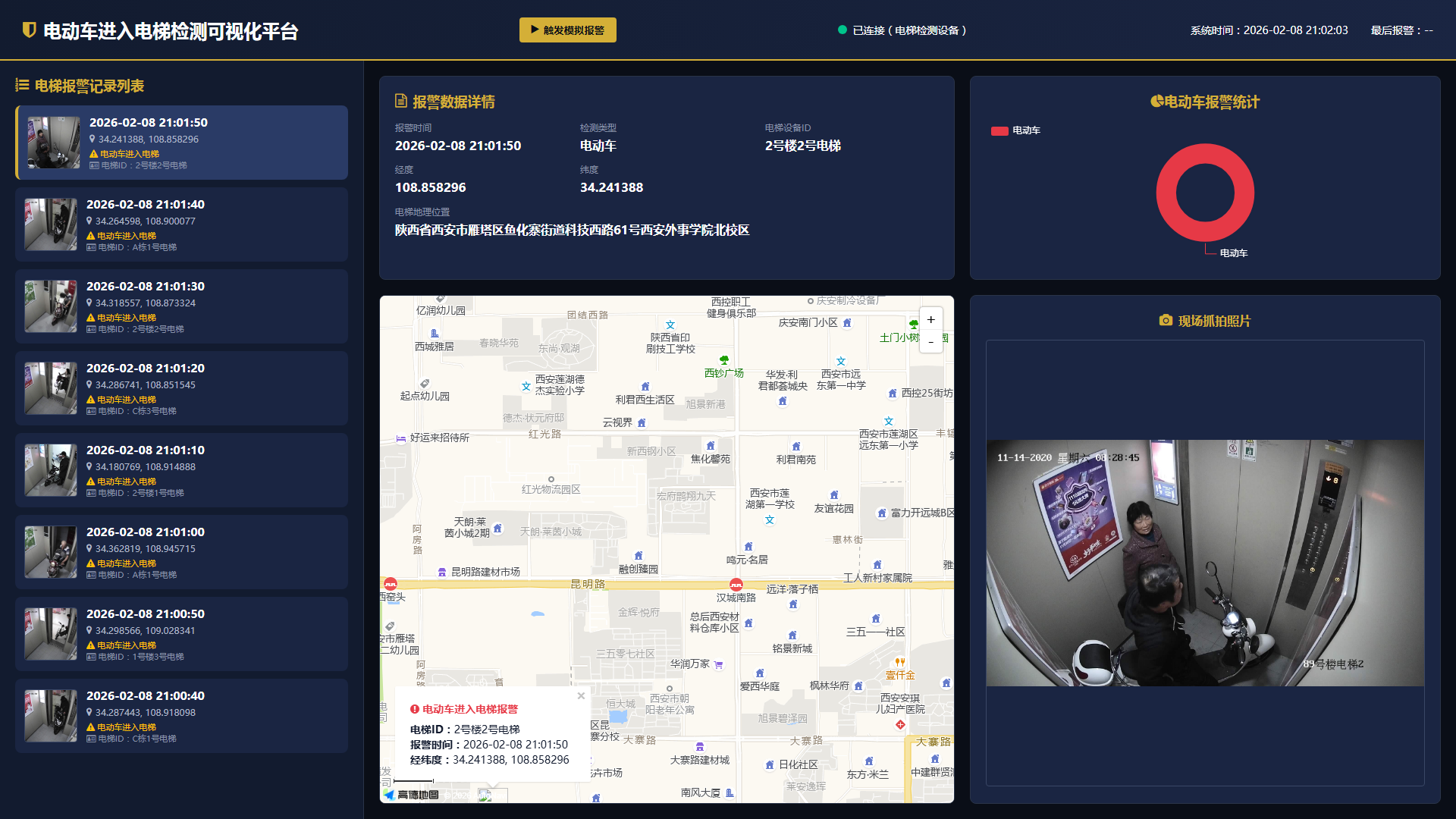
可视化平台分为顶部信息区、电梯报警记录列表区、报警数据详情区、地图定位区、报警类别统计区、现场抓拍照片区6个区域。
(1)顶部信息区
作为平台的“战略指挥台”,此区域用核心数据瞬间定义全局安全状态。

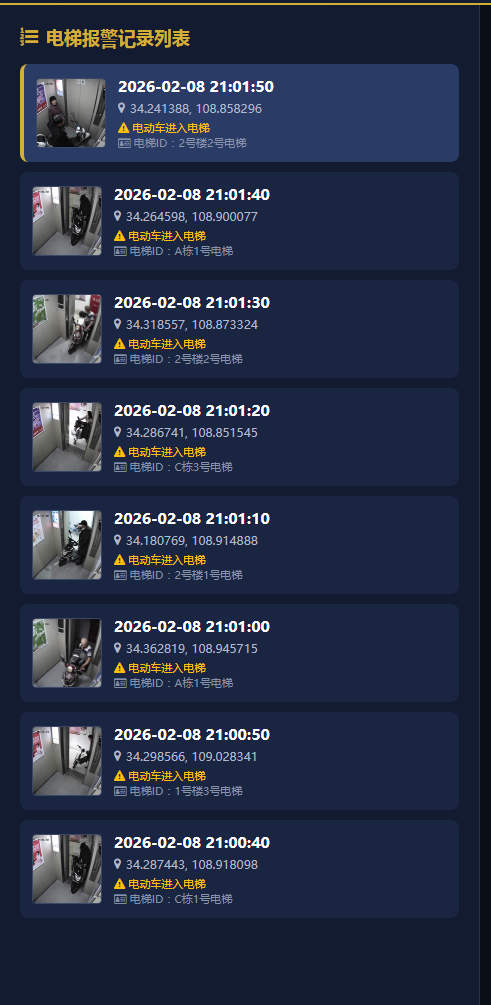
(2)电梯报警记录列表区
这是平台最活跃的“事件脉搏”,如示例所示,它确保了每一起如 “21:01:50 2号楼2号电梯” 的报警都能被实时捕获、有序排列,是运营监控的核心
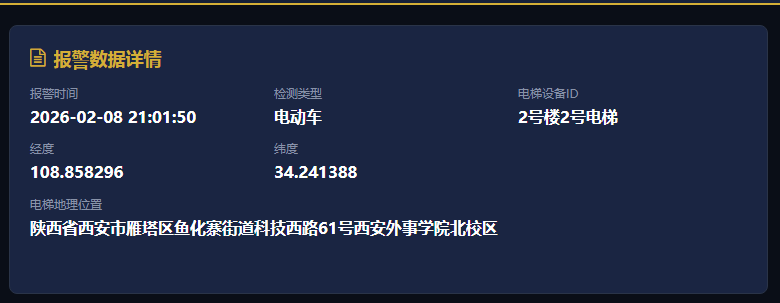
(3)报警数据详情区
将列表中的每一条记录转化为可追溯、可审计的完整“事件档案”,为管理介入提供全部事实依据。
(4)地图定位区
将抽象的报警数据(如坐标34.241388, 108.858296)落位至真实地理空间,实现“从数字到位置”的直观映射,极大提升应急响应效率。

(5)报警类别统计区
从离散的报警事件中提炼规律,将事后处理升级为事前预防的决策支持工具。

(6)现场抓拍照片区
提供无可争议的现场视觉证据,是系统公信力的最终体现,也是进行人员警示、沟通与教育的核心材料。

八、总结与展望:从一部电梯到智慧社区安防网络
本项目验证了利用轻量级AI硬件实现关键场景智能安防的完整路径。系统不仅实现了本地快速响应的刚性拦截,更通过云端可视化平台实现了管理的柔性升级,为物业方提供了有力的技术工具。
未来,系统可沿两个方向拓展:
横向场景扩展:将算法模型适配为“蓄电池”、“轮椅”等,同一套硬件即可应用于“电池入户检测”、“消防通道占用报警”、“特殊人群关怀”等场景。
纵向数据深化:利用可视化平台积累的违规数据,进行时空大数据分析,生成社区安全热力图与风险报告,为管理者提供前瞻性决策支持,最终构建起覆盖整个社区的立体化、智能化安全防护网络。
附件
附件
附件



 他的勋章
他的勋章
王尧坤2026.03.13
太厉害了,学习了,这个可视化界面做的太棒了
孙洪尧19852026.02.10
太好了
easy猿2026.02.09
牛逼