 返回首页
返回首页
 回到顶部
回到顶部

项目背景
中小学生学习开源硬件编程时,传感器认知常成为“拦路虎”。各类传感器功能繁杂,温度、光线、声音等传感器外观相近却用途迥异,抽象的工作原理难以通过文字理解;实际应用中,还需精准匹配引脚、调试参数,初学者易混淆、难上手,极大影响学习积极性。
人工智能为这一难题提供了高效解决方案。借助AI可视化工具,学生可通过3D建模直观观察传感器内部结构;语音交互功能能即时解答“这个传感器能测什么”“如何连接主板”等疑问;AI还可生成模拟实验场景,让学生在虚拟环境中反复调试,快速掌握不同传感器的应用逻辑。AI将抽象知识具象化、复杂操作简单化,帮助学生轻松跨越传感器认知障碍,提升开源硬件学习效率。
亮点与演示
本项目借助Mind+ V2训练各类传感器模型(目标检测),并将模型部署到二哈识图2上进行调用。当二哈识图2将识别的多个传感器数据返回给行空板K10时,行空板K10会通过网络调用Deepseek大语言模型,从基础属性、核心技术及使用注意点等方面介绍每个传感器,并通过语音合成技术将介绍文字朗读出来。
以下是作品演示视频:
项目实施步骤
步骤1 图片收集
因为二哈识别2固件中自带的“物体识别”模型只能识别下图所示的80个类别,因此我们需要自己训练模型。

图1:自带物体识别各类
首先我将手头有的一些传感器拍成照片,可以是单个拍摄,也可以多个一起拍,另外还可以从网上收集一些图片(电商平台上此类图片较多),这些图片是用于模型训练的基础,因此尽可能多地收集图片。另外需要注意,如果拍摄时的环境光线,与识别时最好保持一致,否则两种环境光下要尽可能多地拍照用于训练。当然,我们今后可以不断扩充图片库,用于训练和更新传感器模型。
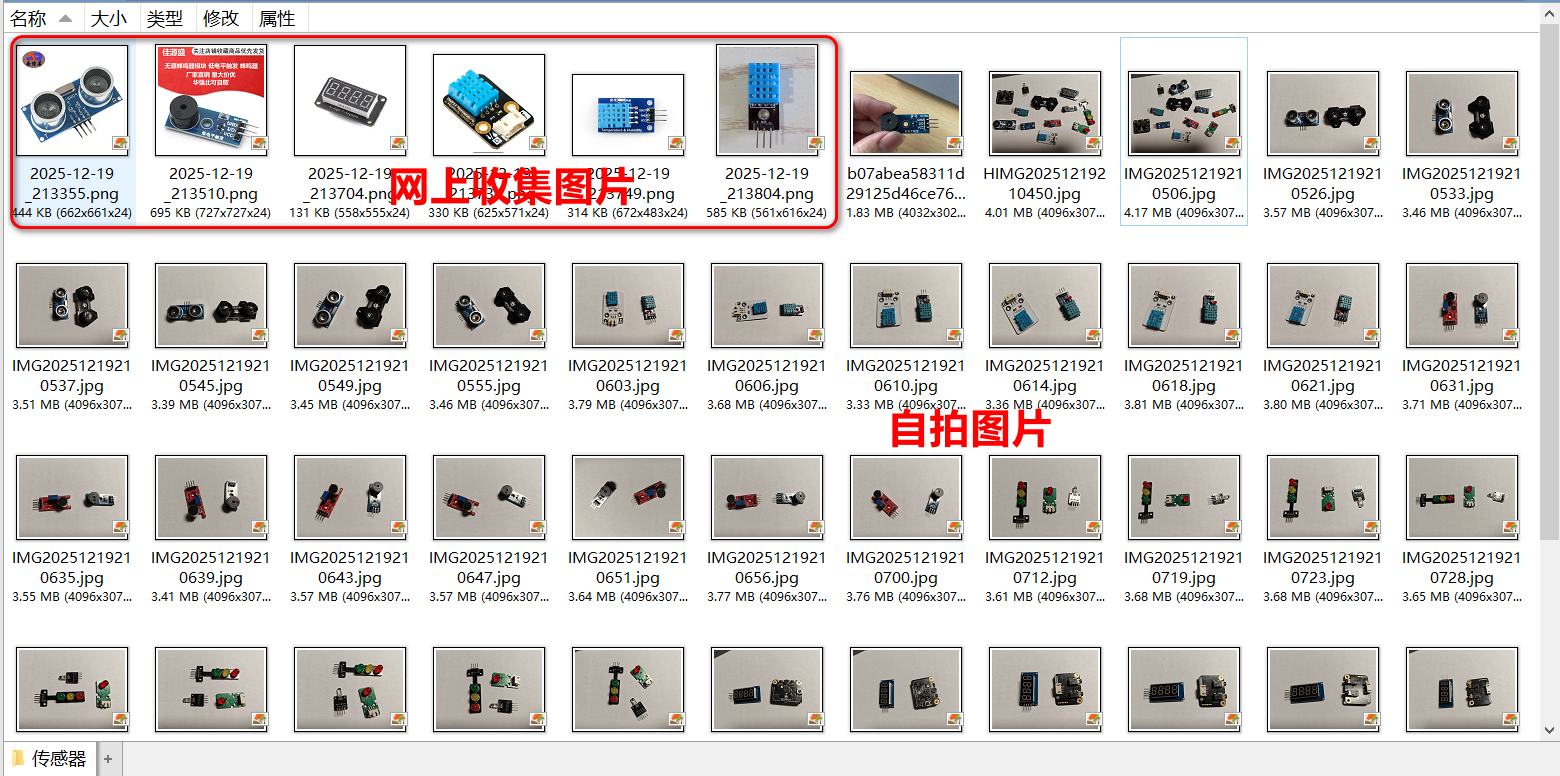
图2:收集图片
步骤2 创建数据集
收集图片完成之后,我们打开Mind+ V2软件,在起始页中单击左侧的“模型训练”项,然后在右侧单击“目标检测”。
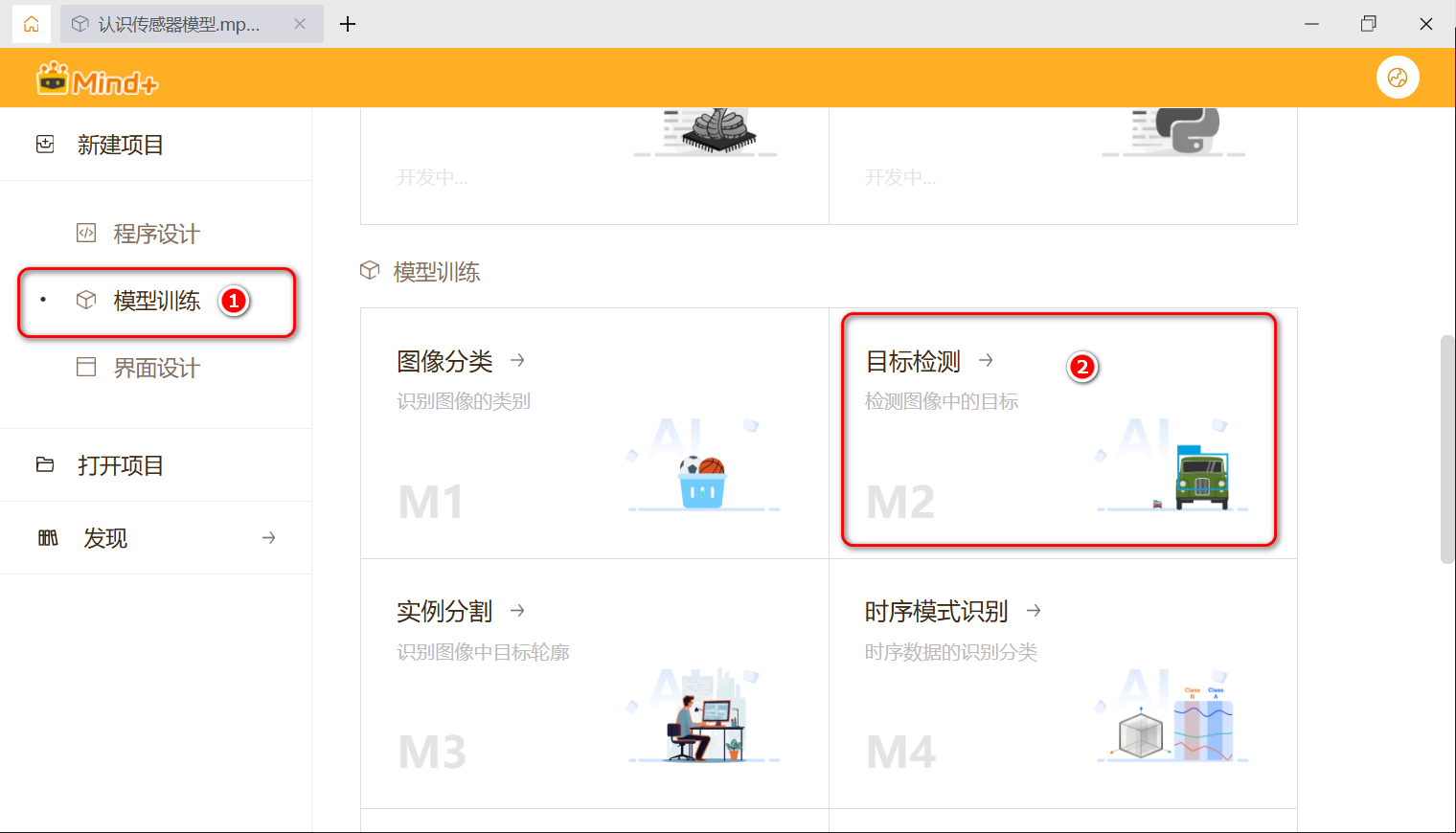
图3:Mind+ V2模型训练
因为目前二哈识图2仅支持目标检测模型的部署(之前训练了图像识别,发现无法在二哈2上部署并使用),所以在这里,我借助目标检测来完成图像识别的功能,毕竟目标检测的功能更加强大一点,因为它不仅可以识别图像类别,还能检测目标的位置,大小等。从以下两个不同模型使用的积木中就可以看出其功能大小。
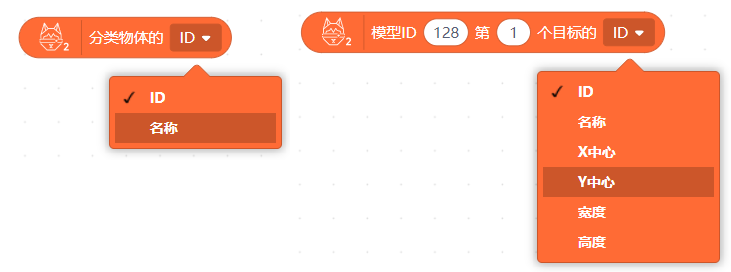
图4:两种识别的积木对比
默认的数据集名称是“Experience”,如果你想创建自己取的名字的数据集,可以单击右上角的“高级模式”,在弹出的工具栏上单击“数据设置”。如下图所示,图片数据我们可以通过摄像头实时采集,也可以先收集图片再上传。
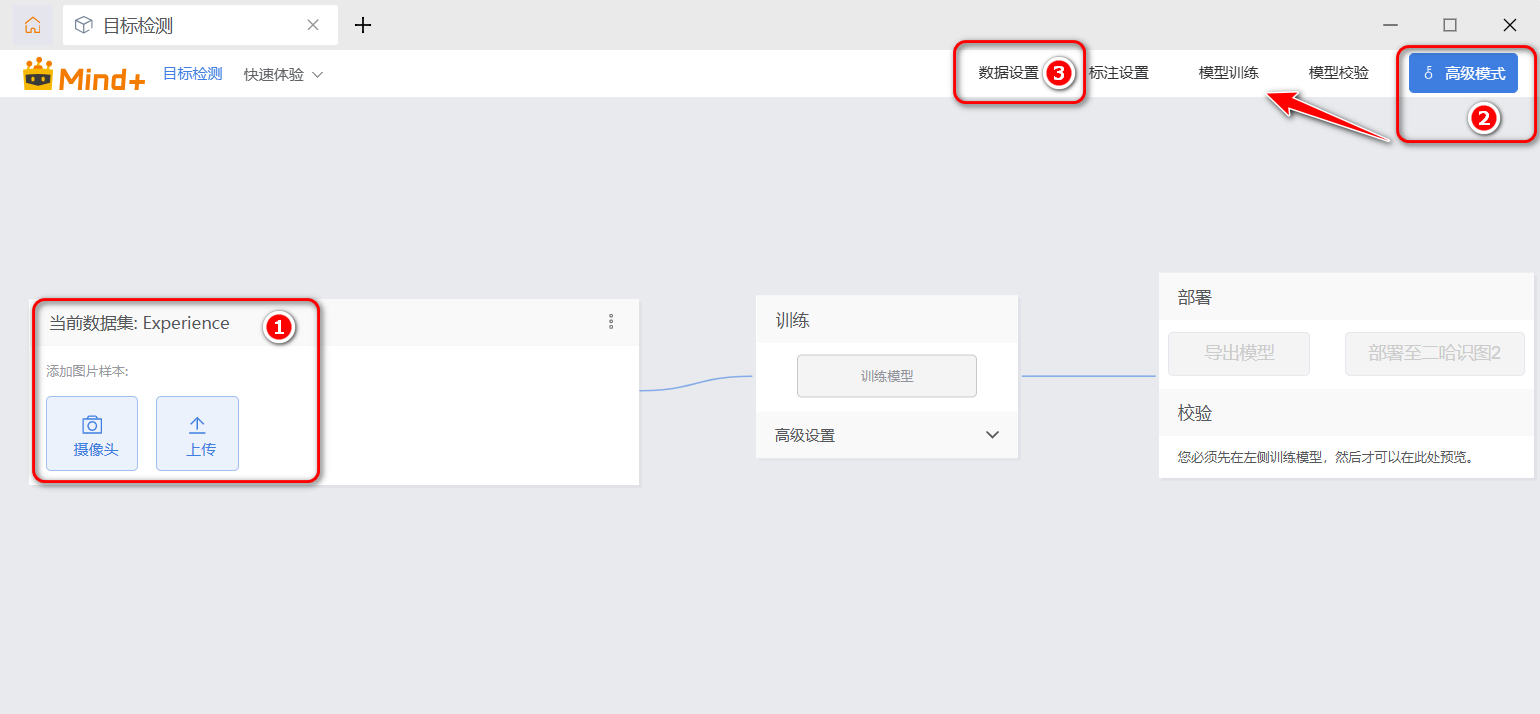
图5:目标检测数据上传
切换到“数据设置”界面之后 ,单击左上角的“创建数据集”按钮,在弹出的“创建数据集”对话框中输入想要创建的名称,如“Sensors”“传感器"等,建议使用英文名称(为什么?因为我也不确定中文能不能使用,就尽量选择英文)。注意默认的”Experience“是不能删除的,而自己创建的数据集是可以删除的。
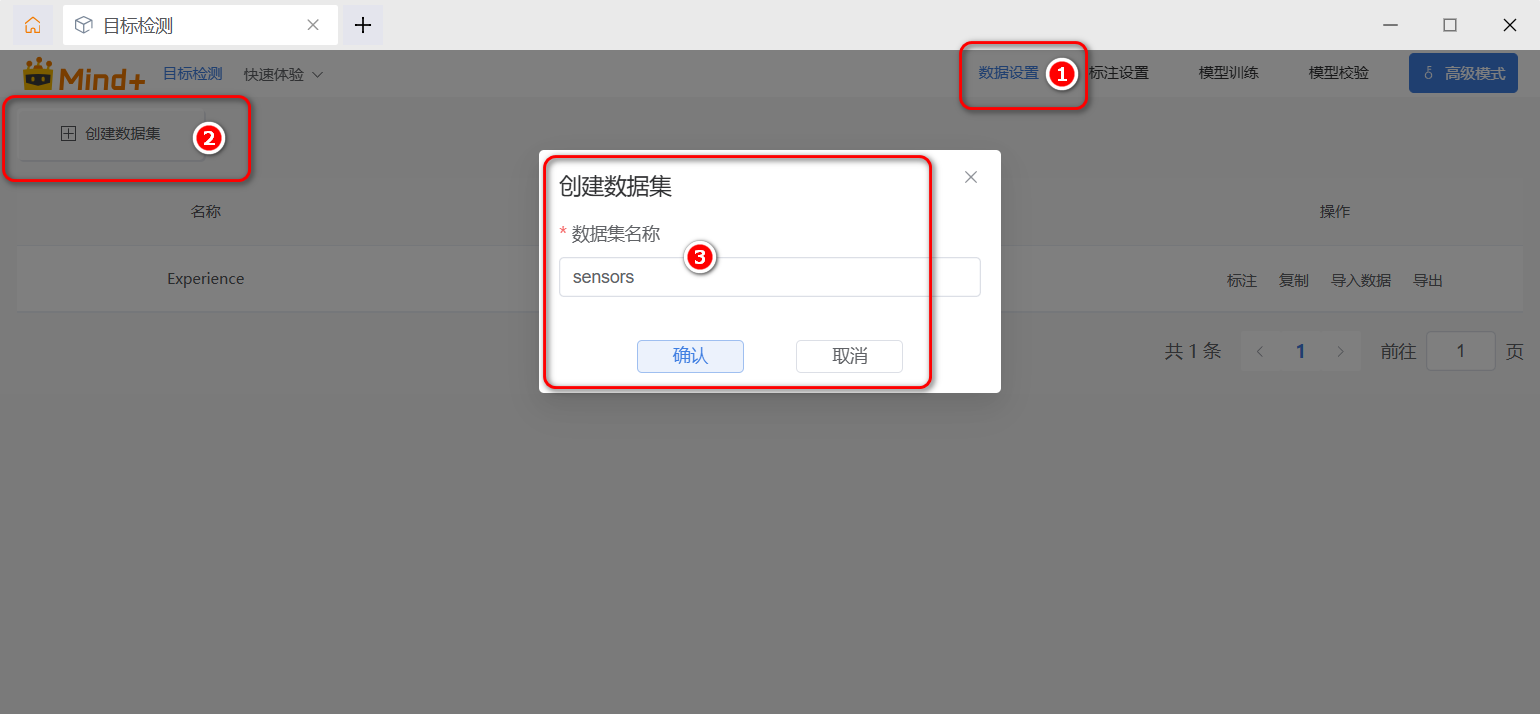
图6:创建数据集
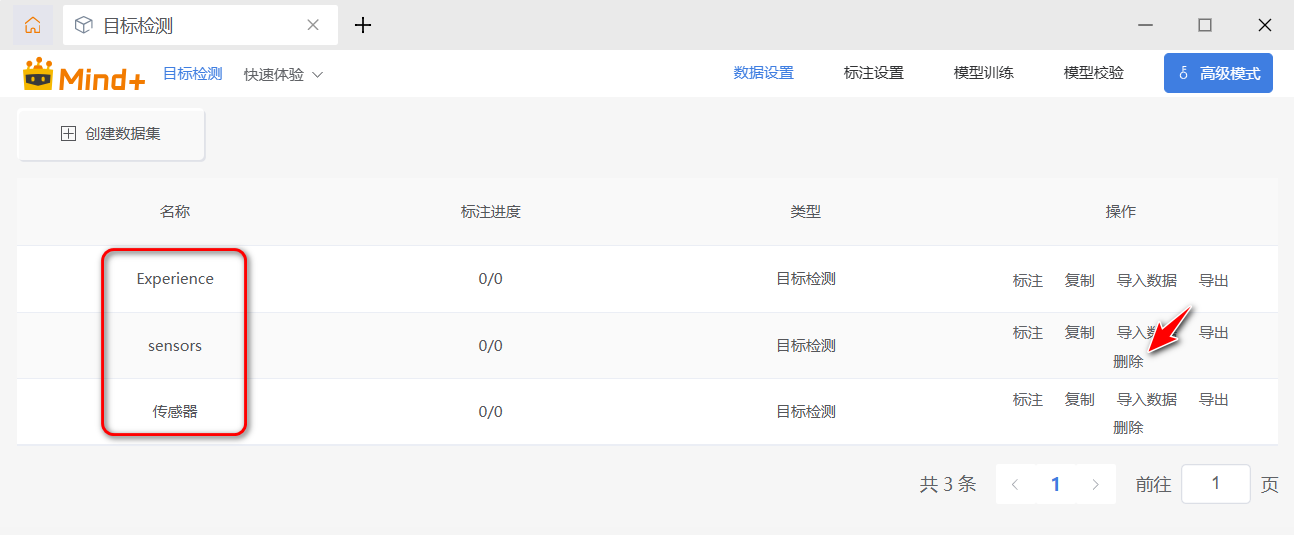
图7:完成数据集创建
单击右侧的”导入数据“链接,在弹出的对话框中单击”无标注数据“单选框,将之前收集的传感器图片全部上传。这里也可以上传”有标注数据的YOLO8格式"的数据,但目前我们手头没有已经标注的可导入的传感器模型数据。
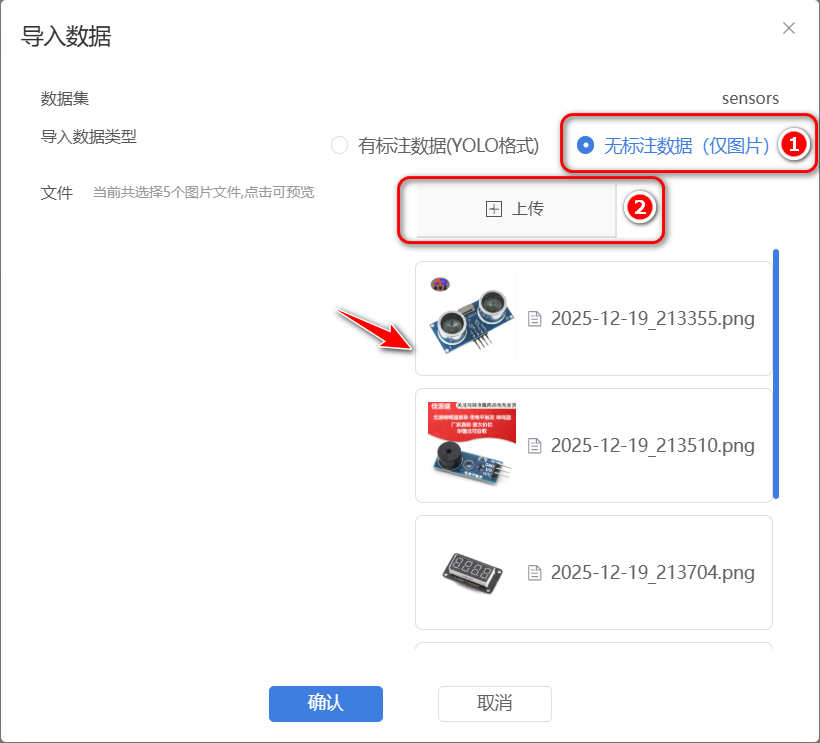
图8:上传图片数据
接下来是对导入的图片数据进行标注,这是一项体力活,怪不得有人说,人工智能的背后,是无数个标注人员的辛苦付出啊。可想而知,成千上万张图片要完成标注,确实挺辛苦的。单击“标注”链接,进入标注页面,第一次进入会提示是否创建标签,我们将按照传感器的名称,创建多个标签,这个标签名称尽量取得完整一点,因为将作为传递给大语言模型的信息来进行介绍。
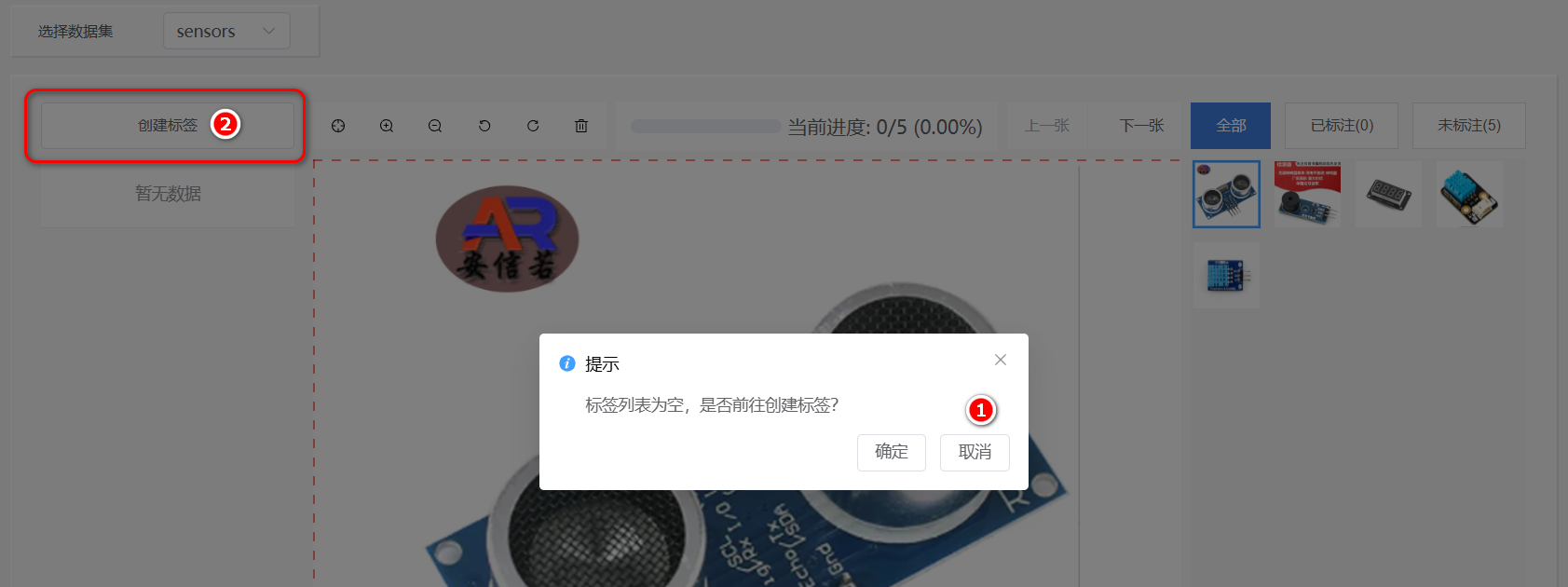
图9:创建第一个标签
我们也可以单击右上角的“创建标签”按钮继续创建其他标签,创建多少个标签,由这个模型将识别多少个传感器决定。一开始我们可以先创建少量标签,然后做成预训练模型,将这个预训练模型分享出去,让更多的人一起维护,这样可以实现协作共赢,否则一个人维护大量的数据,太辛苦啦。
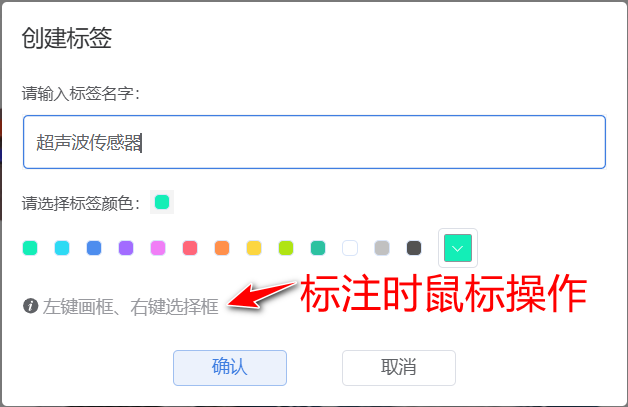
图10:继续创建其他标签
Two thousand years later,我完成了所有图片的标注。
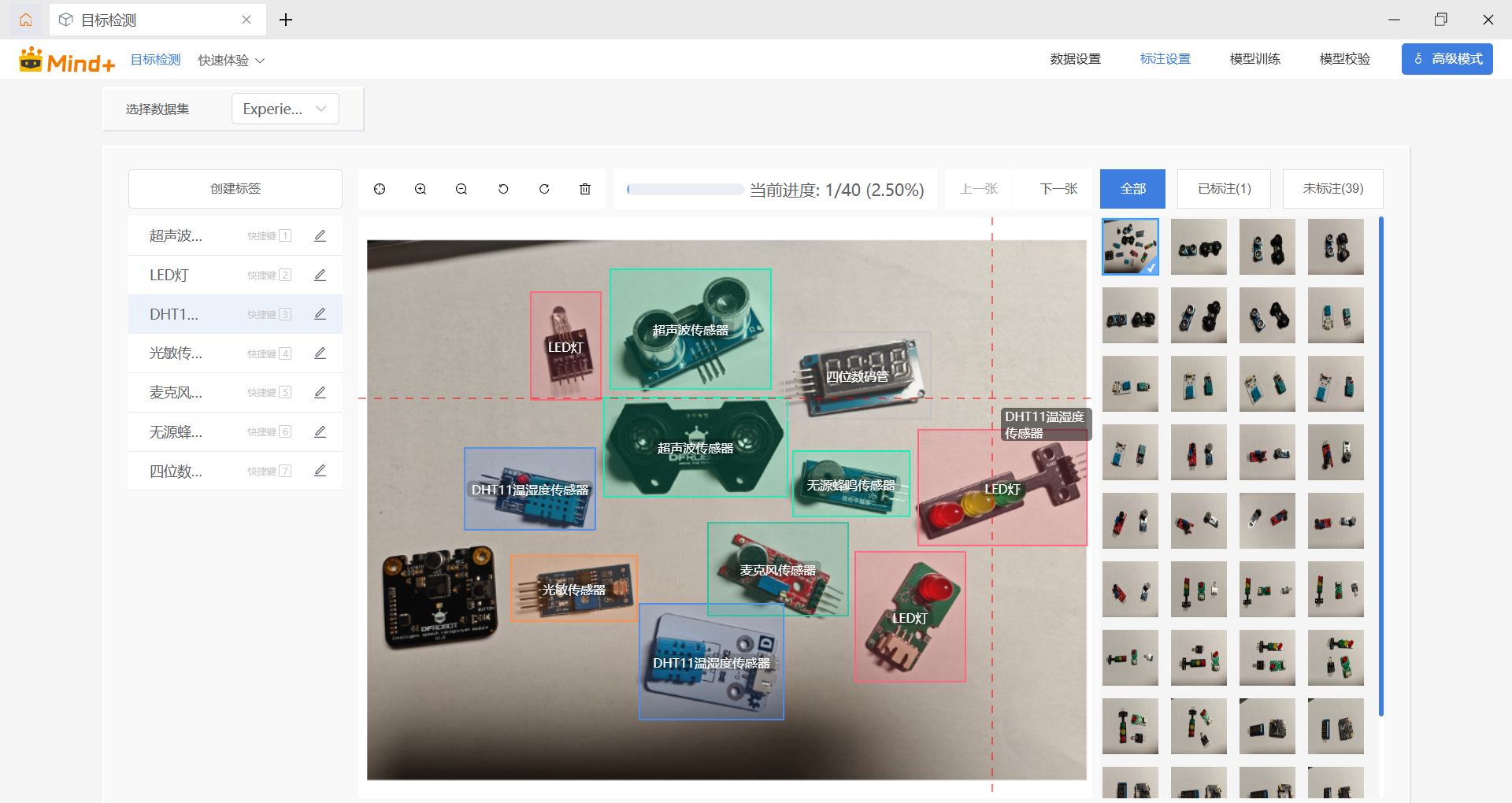
图11:完成数据标注
步骤3 模型训练
万事具备,只欠东风。接下来就要开始进入训练环节。首先说明一点,训练的速度将由你的电脑的硬件配置决定,特别是GPU(通常是显卡)的好坏。
模型训练是个比较长的过程,当出现如下图所示的训练界面时,你可以离开电脑去干其他事情了。
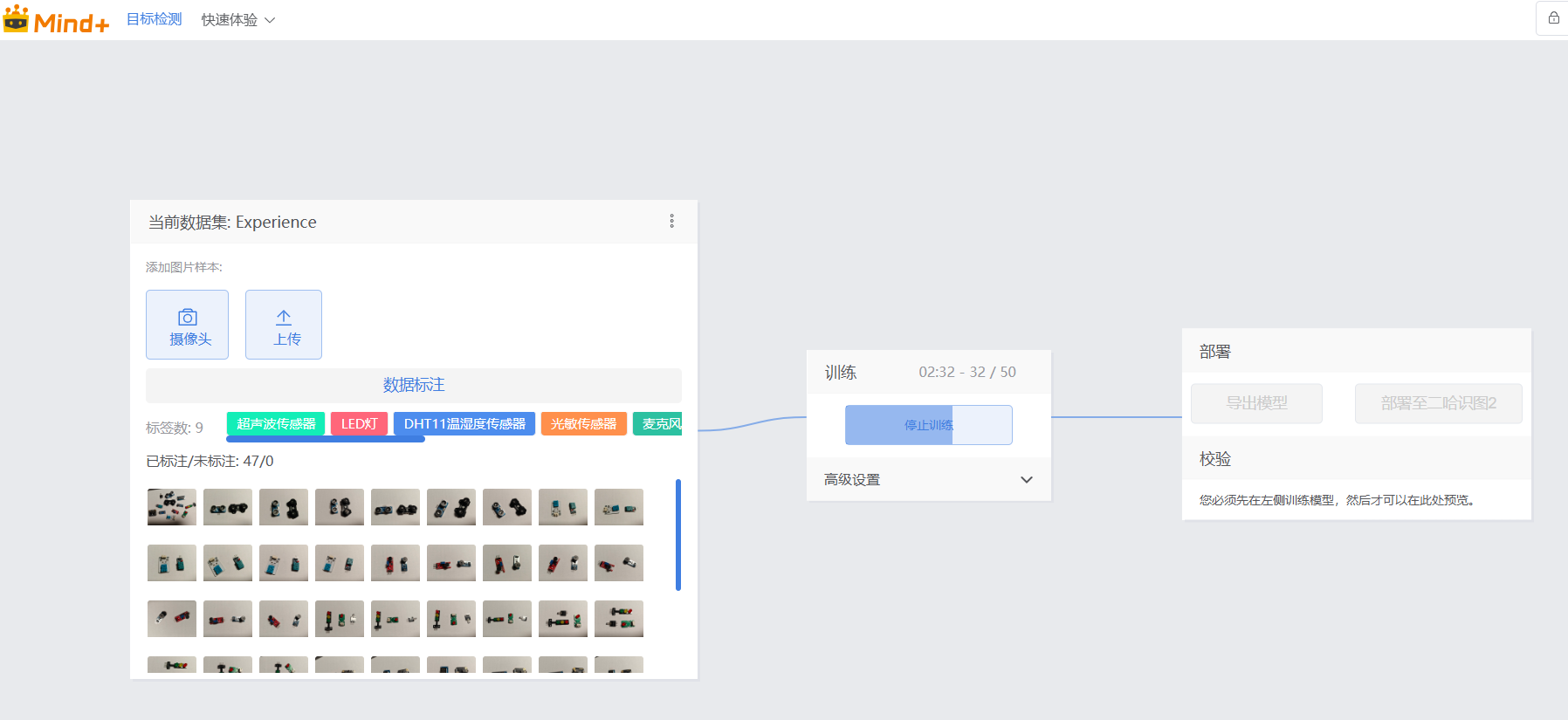
图12:模型训练
完成模型训练之后,我们可以通过电脑外接的摄像头来“校验”一下模型识别传感器的准确度。如果识别效果不满意,请重复上面的步骤,继续扩大图片数据并标注,再训练,直到满意为止。

图13:模型校验
步骤4 模型部署
我们也可以“导出模型”分享给其他小伙伴,当然这次我们要单击“部署至二哈识别2”按钮,生成一个压缩包,然后进行部署。单击按钮后,根据提示进行一些部署设置,如模型名称,选择图标等,最后单击“下载到本地电脑”按钮。
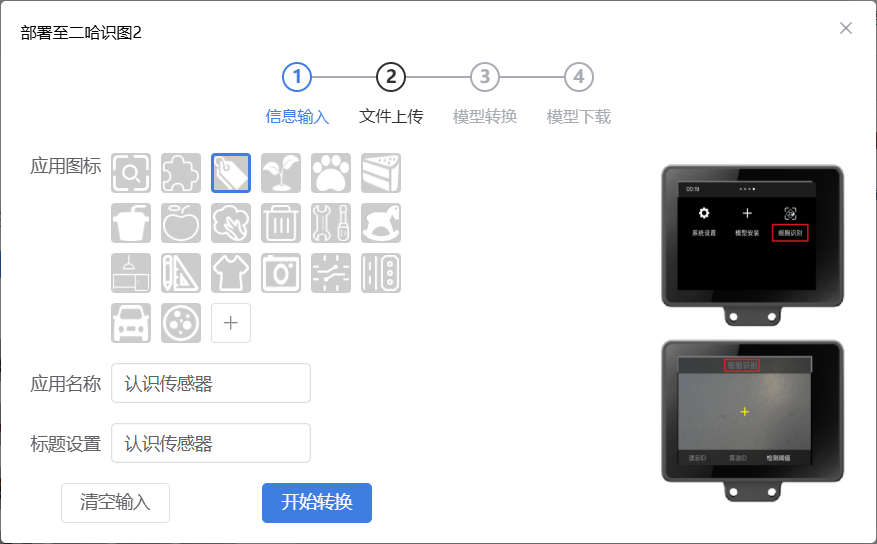
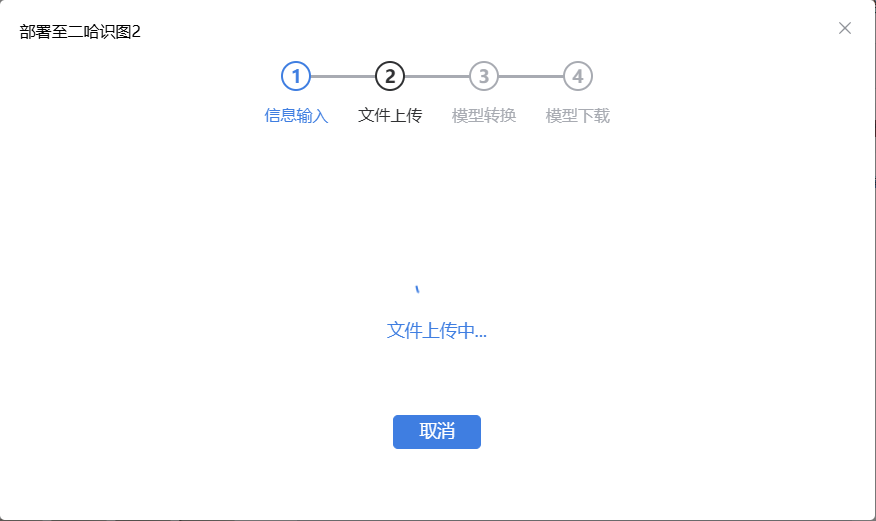
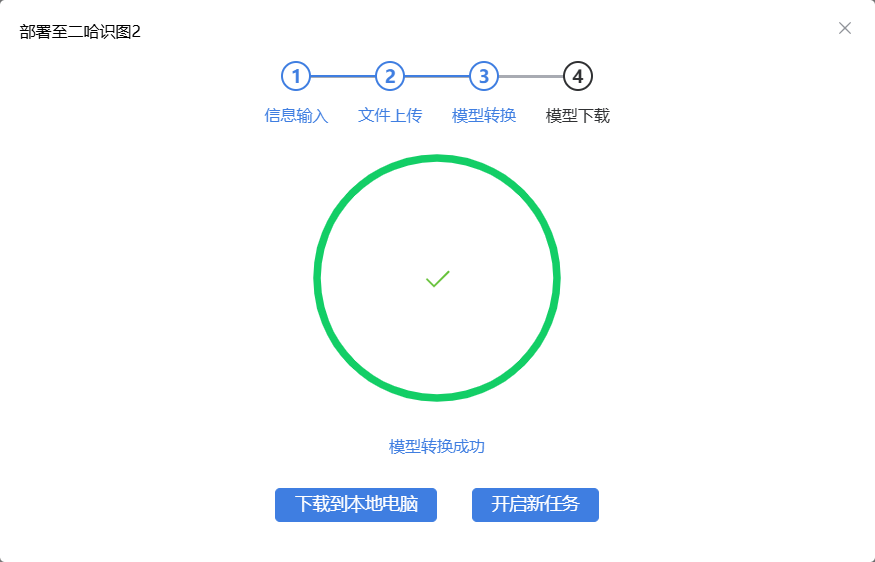
图14:准备模型部署
获得了ZIP压缩包之后,我们用usb数据线将电脑与二哈识别2进行连接,然后将压缩包拷贝到二哈2的“installation_package”文件夹中(压缩包不要解压)。
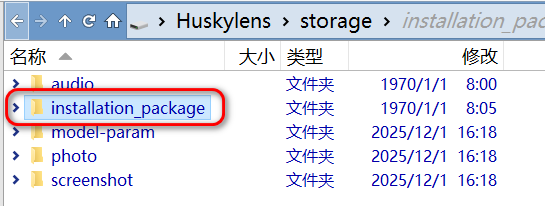
图15:拷贝模型压缩包到二哈2
通过二哈识别2的触摸屏操作安装模型,这里通过本地安装来部署。安装完成之后,新的模型会出现在二哈2屏幕的最右侧,模型图标和名字就是之前我们设置的。
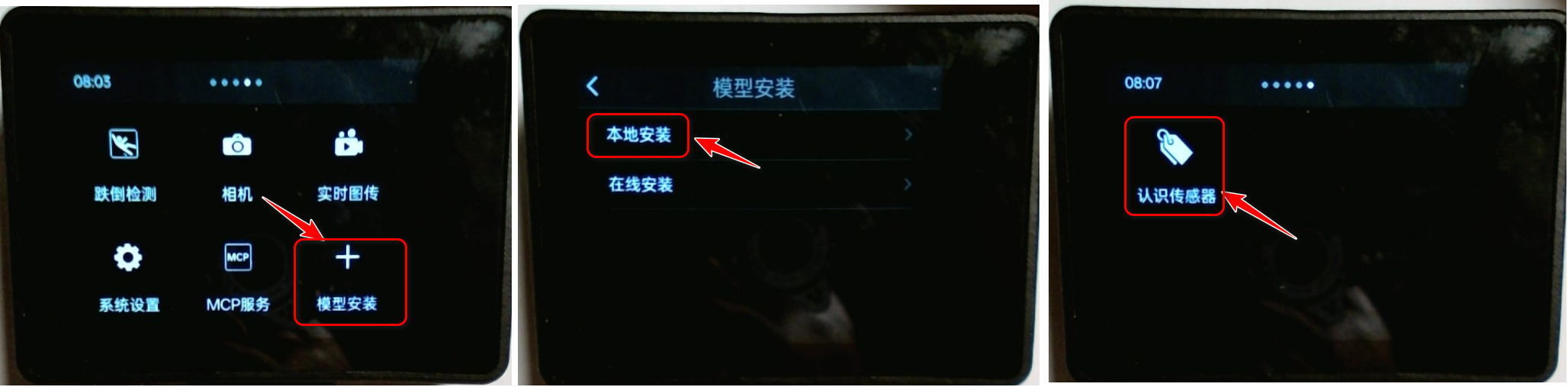
图16:安装模型
我们也可以直接在二哈识别2上校验一下这个模型,看看识别效果如何。

图17:在二哈2上校验模型
在二哈识别2上校验模型,突然发现二哈2的摄像头对焦不准,我试着对二哈2进行了一次对焦操作。下面是我录制的实操视频。
步骤5 程序编写
程序思路参看下图,程序在一系列初始化之后,通过二哈2识别传感器,获取传感器名称传回给行空板,行空板通过网络调用Deepseek获取介绍文字并显示,以及语音合成。
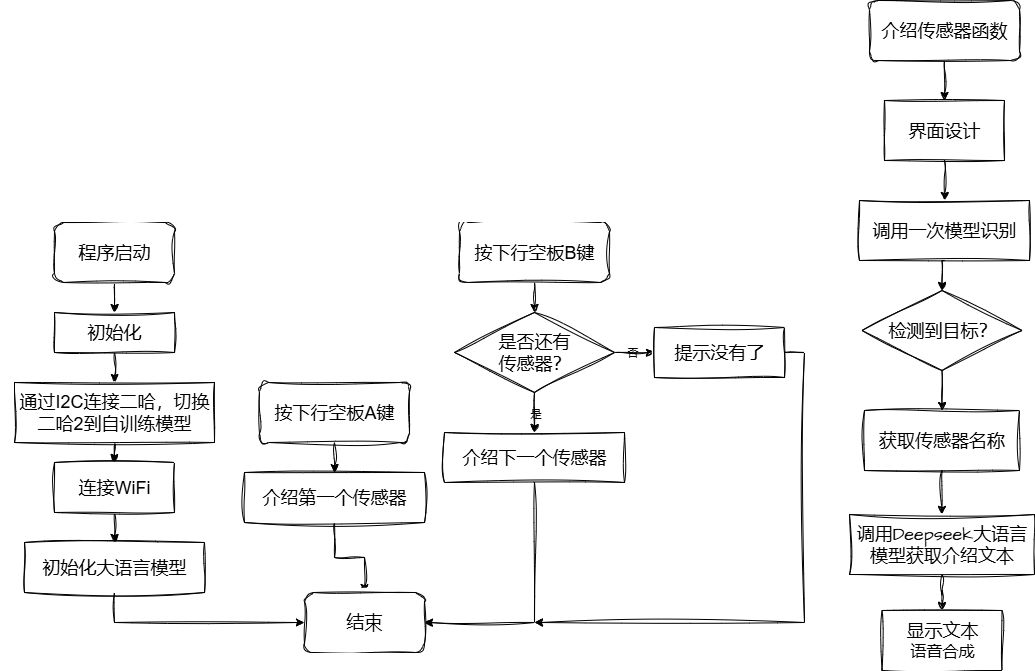
图18:流程图
程序如下图所示。
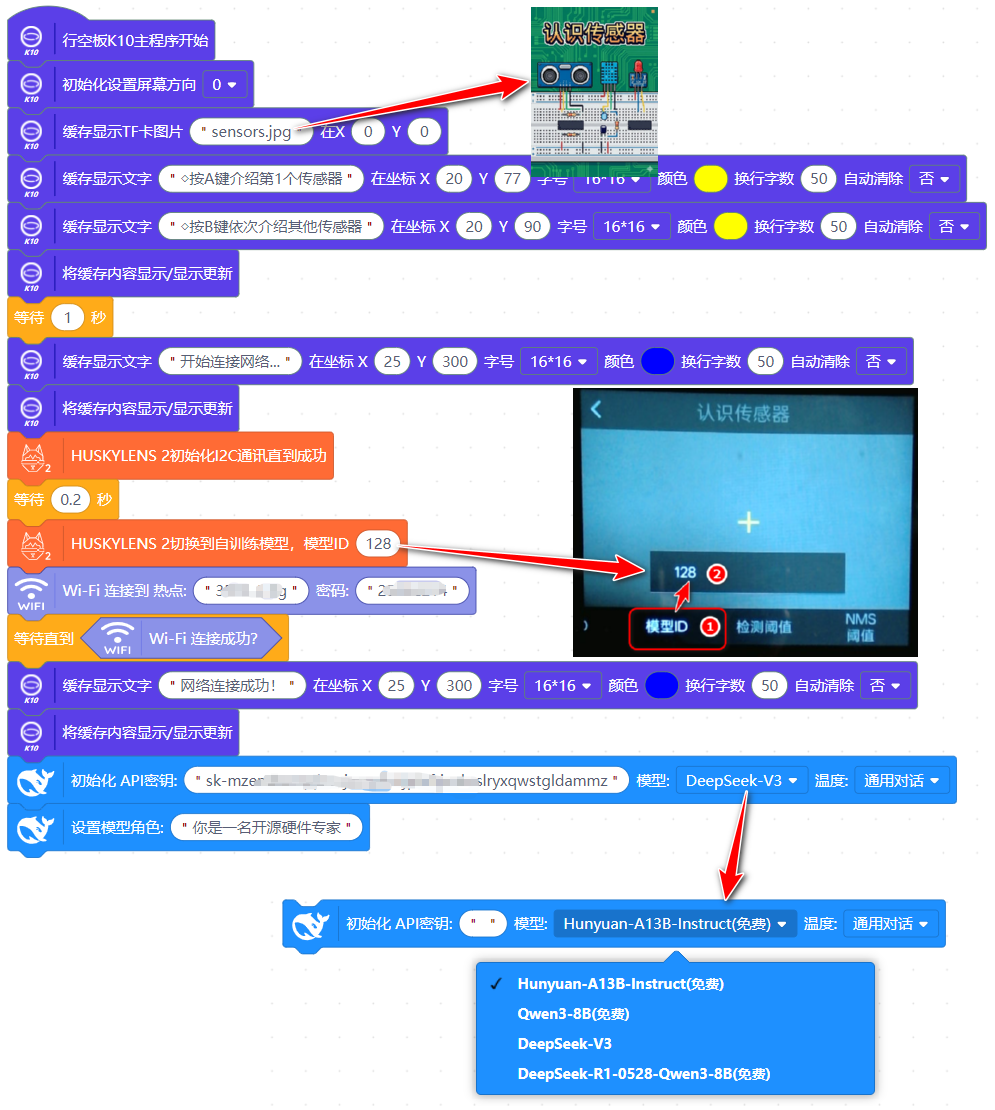
图19:程序
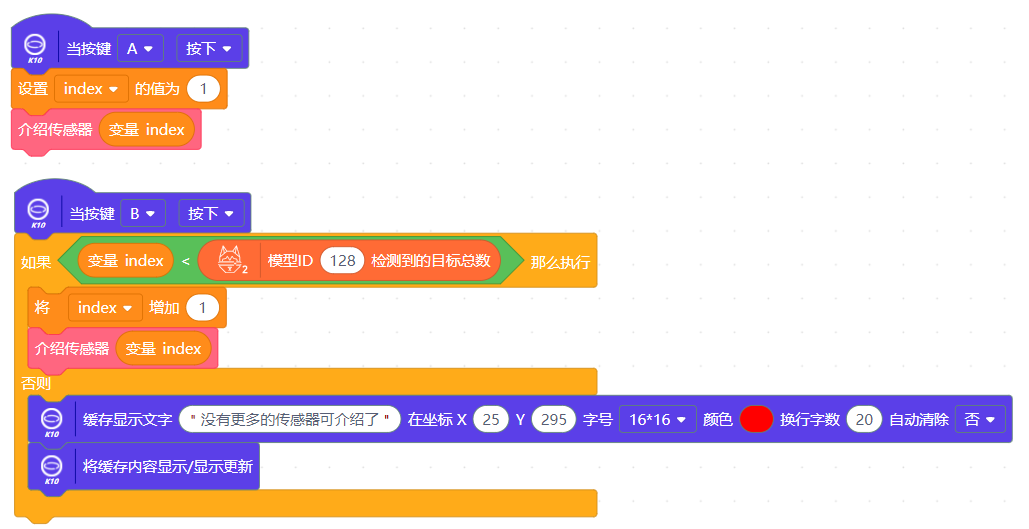
图20:按键程序
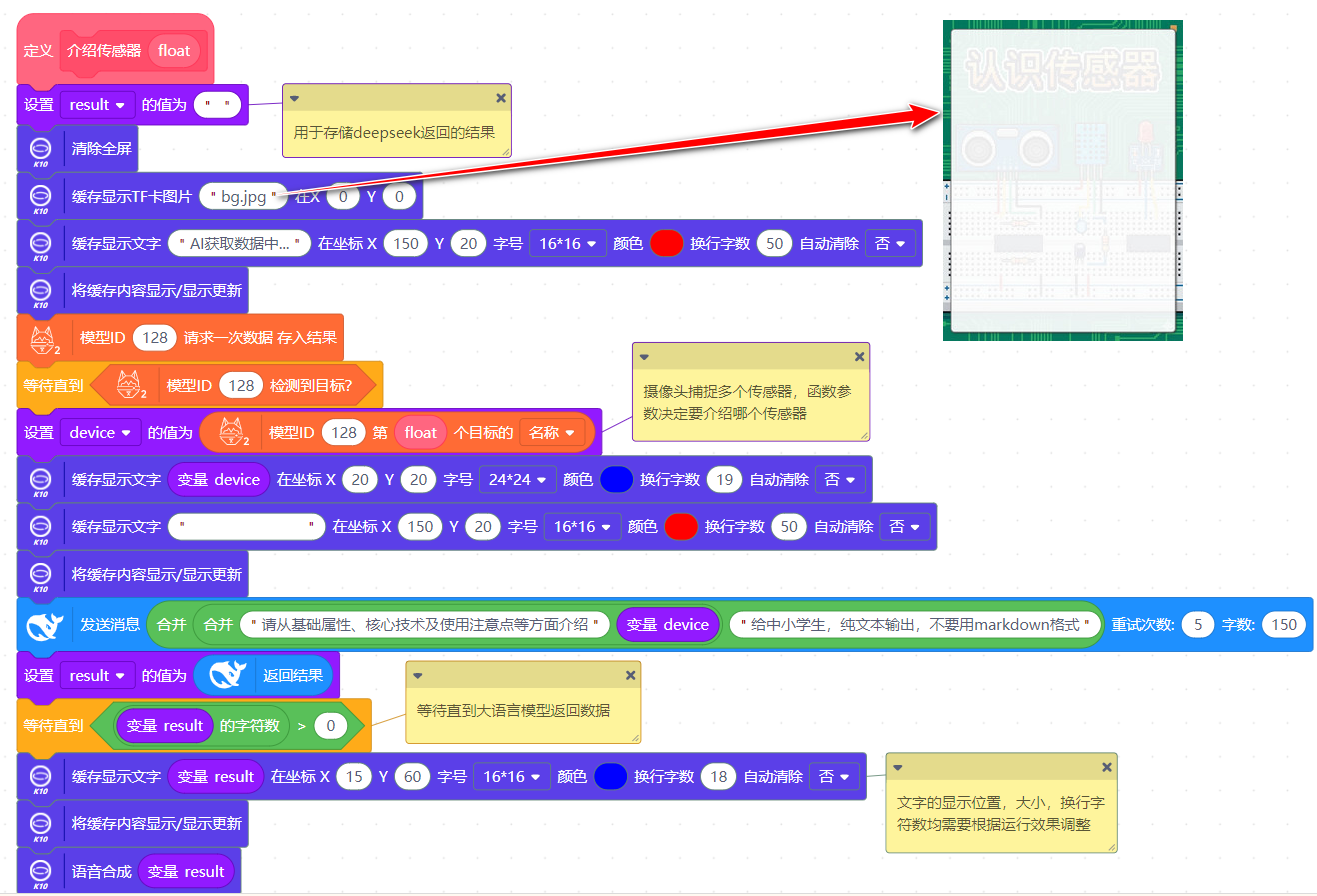
图21:介绍传感器函数
步骤6 调试与修正
程序编写下来,感觉以下几个地方花费时间还是比较多的,
1. UI界面设计。无论是文字显示的位置,还是背景图片的准备(用豆包生成了2张图片并存入TF卡),要达到满意的效果,还是要花费一些时间进行设计的。
2. 大语言模型的选择。我一开始使用Mind+ V2进行编程,发现Deepseek模型无法返回结果,我是自己注册了Deepseek API账号并且充值,发现能调用,也显示了用量,但就是没有在Mind+ V2中返回结果。后来决定暂时放弃Mind+ V2,使用Mind+ 1.8进行编程,幸运的发现,里面默认就提供了Deepseek的API调用,而且不用花钱(估计是Dfrobot出钱)。
图22:Deepseek用量
3. 模型部署后,发现只能获取第一个标签的ID,后来经柳工提示,需要在二哈识图2中对每一个可识别的传感器进行一下学习(对准后按下二哈2的A键),这样每个传感器就会获得一个ID,可用于程序编写。
4. 发送给Deepseek的文字要写明不要输出Markdown格式,否则显示很长,语音合成的结果也很奇怪(Markdown格式中的符合会全部朗读)。
5. 最好能固定二哈识图2,这样识别时会稳一点。另外,发现不能在同一界面中放置过多的传感器(比如不超过3个)为宜。
拓展思路
程序能基本上能实现简单的传感器功能介绍,但语音合成实在太“塑料化”了。由于时间关系,在Deadline到来之前无法实现我的另一个想法,就是结合小智AI来实现介绍,下阶段我将尝试一下这个想法,请各位耐心等待。因为需要重新改写小智AI的固件,需要在Linux上安装配置环境,可能需要花费比较多的时间。
项目资料
我提供的训练好的模型(认识传感器.3b22.zip),有几个传感器识别正确度不高,如光敏传感器,麦克风传感器等,主要是提供的图片不够多。
数据集由于超过10M,我放在百度盘,如果要修改或更新,请自行下载后导入到Mind+ V2中继续维护和训练。
链接: https://pan.baidu.com/s/1Amy0S4BvOE9NgIKTxb2y_g?pwd=tj95 提取码: tj95
附件
附件


 他的勋章
他的勋章
rzegkly2026.02.11
漂亮,二哈识图2好案例
地下铁2025.12.20
这个要点赞,不错不错。