 返回首页
返回首页
 回到顶部
回到顶部

1.项目背景
花亭湖国家湿地公园地处安徽太湖县,是国际濒危和国家级保护鸟类的冬季栖息地。其中有国家一级保护动物中华秋沙鸭,白冠长尾雉。国家二级保护动物鸳鸯、黑鸢、苍鹰、红隼等 4 种,还有 22 种具重要价值的国家保护鸟类,生态保护意义重大。但许多学生对湿地鸟类陌生,缺乏识别与保护意识。为此特设计鸟类识别装置,运用图像识别技术,助学生识别鸟类、了解习性与保护级别,培养其环保意识,为湿地生态保护出力。
2.功能说明
本装置通过深度学习模型和图像识别技术,实现了对花亭湖湿地鸟类的智能识别。用户点击“打开摄像头”按钮后,摄像头被打开,并在主界面实时显示画面。点击“拍照”按钮,系统捕获当前画面并使用模型进行识别,随后弹出一个新窗口展示拍摄的图片和识别结果(包括鸟类名称)。窗口最下方设有“退出”按钮,点击后可返回主界面继续拍照。此外,系统还支持语音播报功能,能够用中文播报识别结果,增强用户体验。
3.制作过程
3.1创作思路

3.2数据准备
步骤一: 花亭湖湿地鸟类众多,从中选取了6种进行数据整理。为此,从网上搜集了中华秋沙鸭、白冠长尾雉、鸳鸯、黑鸢、苍鹰、红隼,每种鸟类各40张图片。
以下部分图片数据展示:




 将图片进行整理
将图片进行整理

步骤二:用BaseDT库制作数据集
设置参数,拆分并标注数据集
默认比例为训练集train_ratio = 0.8, 测试集test_ratio = 0.1, 验证集val_ratio = 0.1
#安装BaseDT
!pip install BaseDT
# 导入库文件
from BaseDT.dataset import DataSet
# 指定为生成数据集的路径
ds = DataSet(r"huatinghu_cls")
# 默认比例为训练集train_ratio = 0.8, 测试集test_ratio = 0.1, 验证集val_ratio = 0.1
# 指定原始数据集的路径,数据集格式选择IMAGENET
ds.make_dataset(r"huatinghu", src_format="IMAGENET",train_ratio = 0.8, test_ratio = 0.1, val_ratio = 0.1)步骤三:数据集检测
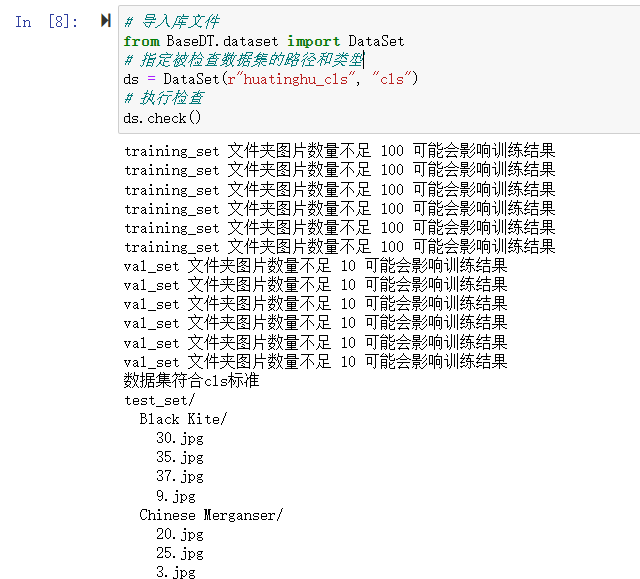
# 导入库文件
from BaseDT.dataset import DataSet
# 指定被检查数据集的路径和类型
ds = DataSet(r"huatinghu_cls", "cls")
# 执行检查
ds.check()3.3模型训练
3.3.1训练的权重文件保存在model.save_fold = 'checkpoints/cls_model/huatinghu'指定的文件夹,分为按照训练轮次生成的权重文件epoch_x.pth和一个best_accuracy_top-5_epoch_2.pth权重文件,best_accuracy_top-5_epoch_2.pth权重文件即目前为止准确率最高的权重。我们可以选择准确率最高的那个权重(best_accuracy_top-5_epoch_2.pth)来进行推理。

from MMEdu import MMClassification as mmeducls# 导入库,从MMEdu导入分类模块,简称cls
model = mmeducls(backbone='ResNet18')# 实例化模型,网络名称为'ResNet18',还可以选择'MobileNet'、'ResNet50'等
model.num_classes = 6 # 指定图片的类别数量,根据自己的数据集填写
model.load_dataset(path='/data/M33KEC/huatinghu_cls') # 指定数据集的路径
model.save_fold = 'checkpoints/cls_model/huatinghu' # 指定保存模型配置文件和权重文件的路径
model.train(epochs=10 ,lr=0.001,batch_size=4, validate=True,device='cpu')#训练轮次,学习率
3.3.2用模型推理的代码测试一下模型效果。
可以用模型推理的代码简单测试一下模型效果。可以上传一张图片验证一下或是直接指定测试集的图片。

from MMEdu import MMClassification as mmeducls# 导入库,从MMEdu导入分类模块,简称cls
# 指定进行推理的一组图片的路径
img = '/data/M33KEC/huatinghu_cls/test_set/Black Kite/33.jpg'
# 实例化MMEdu图像分类模型
model = mmeducls(backbone='ResNet18')
# 指定使用的模型权重文件
checkpoint = 'checkpoints/cls_model/catsdogs/best_accuracy_top-1_epoch_8.pth'
# 在CPU上进行推理
result = model.inference(image=img, show=True, checkpoint=checkpoint)
# 输出结果,可以修改参数show的值来决定是否需要显示结果图片,默认显示结果图片
model.print_result(result) 3.4模型转换及推理
3.4.1模型转换:根据训练好的MobileNetV2网络的权重,利用convert函数将模型转换至ONNX
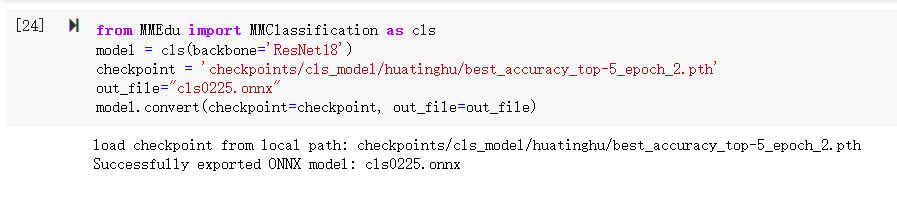
from MMEdu import MMClassification as cls
model = cls(backbone='ResNet18')
checkpoint = 'checkpoints/cls_model/huatinghu/best_accuracy_top-5_epoch_2.pth'
out_file="cls0225.onnx"
model.convert(checkpoint=checkpoint, out_file=out_file)3.4.2模型推理
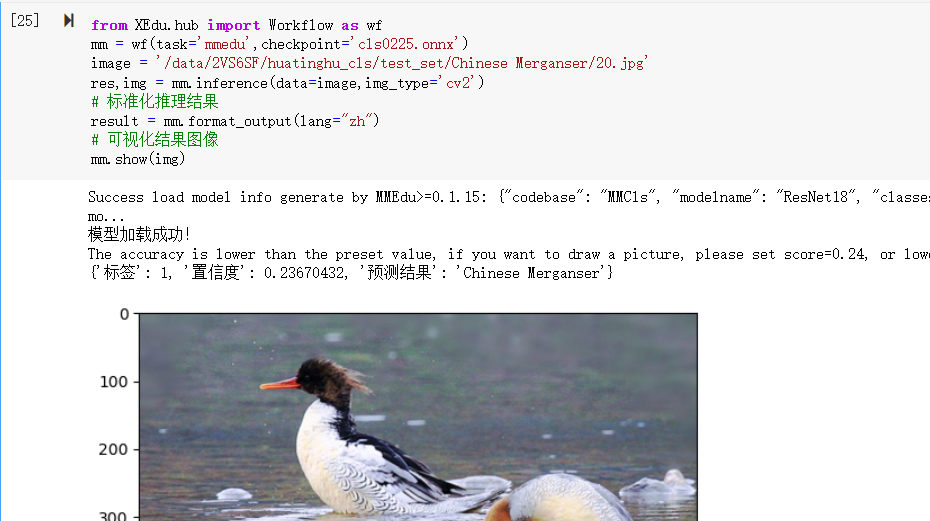
from XEdu.hub import Workflow as wf
mm = wf(task='mmedu',checkpoint='cls0225.onnx')
image = '/data/2VS6SF/huatinghu_cls/test_set/Chinese Merganser/20.jpg'
res,img = mm.inference(data=image,img_type='cv2')
# 标准化推理结果
result = mm.format_output(lang="zh")
# 可视化结果图像
mm.show(img)3.5模型部署
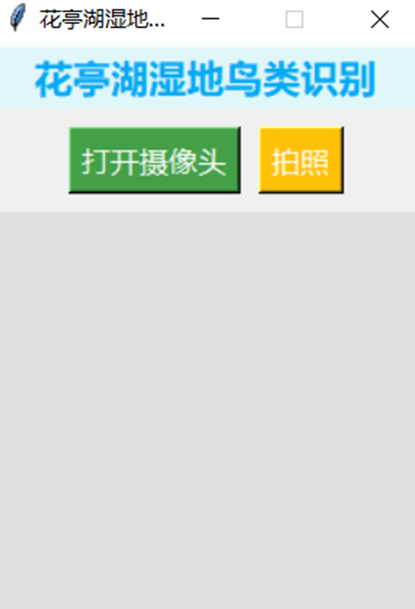
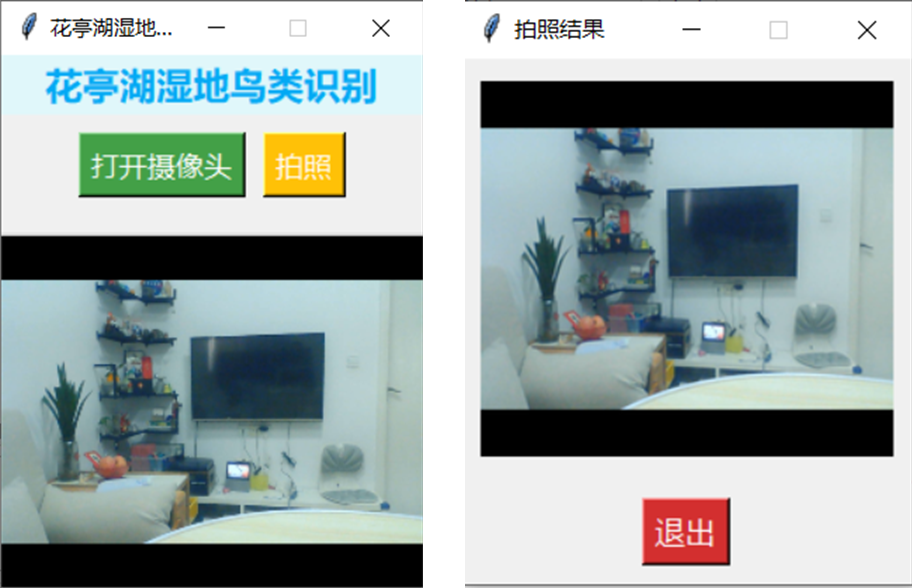
3.5.1设计界面
利用大模型,让其写一个界面的程序。
提示词:帮我设计一个UI界面,这个UI界面显示大小为240*320,第一行是标题,标题内容是花亭湖湿地鸟类识别;第二行有两个按钮,一个打开摄像头,另一个是拍照。第三行是摄像头显示的即时画面,当拍照后,弹出一个显示图片的窗口,图片下面是退出按钮,返回摄像头界面,可以继续拍摄
功能实现描述:
1.打开摄像头:点击“打开摄像头”按钮后,摄像头被打开,并在主界面的指定区域实时显示摄像头画面。
2.拍照功能:点击“拍照”按钮后,系统捕获当前摄像头的画面,并在新窗口中显示拍照结果。
3.显示拍照结果:拍照完成后,系统会弹出一个新窗口,显示拍照的图像,并提供一个“退出”按钮。
4.返回主页面:点击“退出”按钮后,拍照结果窗口关闭,用户可以返回主页面继续拍照或进行其他操作。
import tkinter as tk
from tkinter import messagebox
import cv2
from PIL import Image, ImageTk
class BirdRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("花亭湖湿地鸟类识别")
self.root.geometry("240x320")
self.root.resizable(False, False)
# 标题
self.title_label = tk.Label(root, text="花亭湖湿地鸟类识别", font=("微软雅黑", 16, "bold"), bg="#E0F7FA", fg="#03A9F4")
self.title_label.pack(fill=tk.X)
# 按钮区域
self.button_frame = tk.Frame(root)
self.button_frame.pack(pady=10)
self.open_camera_button = tk.Button(self.button_frame, text="打开摄像头", command=self.open_camera, bg="#43A047", fg="white", font=("微软雅黑", 12))
self.open_camera_button.pack(side=tk.LEFT, padx=5)
self.take_photo_button = tk.Button(self.button_frame, text="拍照", command=self.take_photo, bg="#FFC107", fg="white", font=("微软雅黑", 12))
self.take_photo_button.pack(side=tk.LEFT, padx=5)
# 摄像头显示区域(调整位置到按钮下方)
self.camera_frame = tk.Frame(root, bg="#E0E0E0", width=240, height=200)
self.camera_frame.pack(pady=10)
self.camera_label = tk.Label(self.camera_frame, bg="#E0E0E0")
self.camera_label.pack(fill=tk.BOTH, expand=True)
# 摄像头状态
self.camera_active = False
self.cap = None
def open_camera(self):
if not self.camera_active:
self.cap = cv2.VideoCapture(0)
if self.cap.isOpened():
self.camera_active = True
self.update_camera()
else:
messagebox.showerror("错误", "无法打开摄像头!")
def update_camera(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
frame = cv2.resize(frame, (240, 200))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
self.camera_label.imgtk = imgtk
self.camera_label.configure(image=imgtk)
self.root.after(10, self.update_camera)
def take_photo(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
self.show_photo_window(frame)
def show_photo_window(self, photo):
# 创建一个较大的窗口以显示照片和退出按钮
self.photo_window = tk.Toplevel(self.root)
self.photo_window.title("拍照结果")
self.photo_window.geometry("240x280") # 增大窗口高度
self.photo_window.resizable(False, False)
# 照片显示区域
photo_label = tk.Label(self.photo_window)
photo_label.pack(pady=10)
# 调整照片大小以适应窗口
img = Image.fromarray(cv2.cvtColor(photo, cv2.COLOR_BGR2RGB))
img = img.resize((220, 200), Image.ANTIALIAS) # 调整照片大小
imgtk = ImageTk.PhotoImage(image=img)
photo_label.imgtk = imgtk
photo_label.configure(image=imgtk)
# 退出按钮
exit_button = tk.Button(self.photo_window, text="退出", command=self.photo_window.destroy, bg="#D32F2F", fg="white", font=("微软雅黑", 12))
exit_button.pack(pady=10)
def close_camera(self):
if self.camera_active:
self.camera_active = False
self.cap.release()
self.camera_label.configure(image="")
def on_closing(self):
self.close_camera()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = BirdRecognitionApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
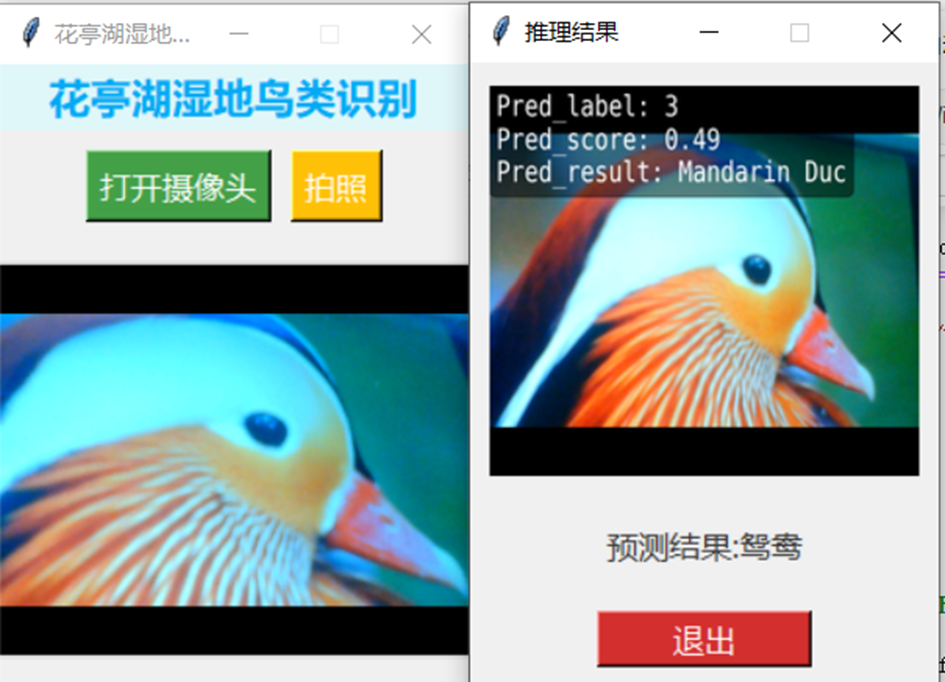
root.mainloop()3.5.2本地部署
(1)将推理代码和界面设计代码结合,进行本地部署。
功能实现描述:
1.打开摄像头并实时显示画面。
2.拍照后,使用提供的模型对照片进行推理。
3.显示推理结果和可视化后的图像并语音播报。
可视化后的图像:
上方:显示拍摄的图片。
中间:显示推理结果为预测结果的内容' ‘(这里的预测结果是Pred_result)的内容。
最下方:显示退出按钮。
import tkinter as tk
from tkinter import messagebox
import cv2
from PIL import Image, ImageTk
from XEdu.hub import Workflow as wf # 导入你的模型推理模块
class BirdRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("花亭湖湿地鸟类识别")
self.root.geometry("240x320")
self.root.resizable(False, False)
# 标题
self.title_label = tk.Label(root, text="花亭湖湿地鸟类识别", font=("微软雅黑", 16, "bold"), bg="#E0F7FA", fg="#03A9F4")
self.title_label.pack(fill=tk.X)
# 按钮区域
self.button_frame = tk.Frame(root)
self.button_frame.pack(pady=10)
self.open_camera_button = tk.Button(self.button_frame, text="打开摄像头", command=self.open_camera, bg="#43A047", fg="white", font=("微软雅黑", 12))
self.open_camera_button.pack(side=tk.LEFT, padx=5)
self.take_photo_button = tk.Button(self.button_frame, text="拍照", command=self.take_photo, bg="#FFC107", fg="white", font=("微软雅黑", 12))
self.take_photo_button.pack(side=tk.LEFT, padx=5)
# 摄像头显示区域
self.camera_frame = tk.Frame(root, bg="#E0E0E0", width=240, height=200)
self.camera_frame.pack(pady=10)
self.camera_label = tk.Label(self.camera_frame, bg="#E0E0E0")
self.camera_label.pack(fill=tk.BOTH, expand=True)
# 摄像头状态
self.camera_active = False
self.cap = None
# 初始化模型
self.model = wf(task='mmedu', checkpoint='cls0212.onnx')
def open_camera(self):
if not self.camera_active:
self.cap = cv2.VideoCapture(0)
if self.cap.isOpened():
self.camera_active = True
self.update_camera()
else:
messagebox.showerror("错误", "无法打开摄像头!")
def update_camera(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
frame = cv2.resize(frame, (240, 200))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
self.camera_label.imgtk = imgtk
self.camera_label.configure(image=imgtk)
self.root.after(10, self.update_camera)
def take_photo(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
self.process_photo(frame)
def process_photo(self, photo):
# 将照片传递给模型进行推理
res, img = self.model.inference(data=photo, img_type='cv2')
# 提取预测结果
if isinstance(res, dict) and '预测结果' in res:
prediction = res['预测结果']
else:
prediction = "未知结果"
self.show_result_window(img, prediction)
def show_result_window(self, img, prediction):
# 创建推理结果窗口
self.result_window = tk.Toplevel(self.root)
self.result_window.title("推理结果")
self.result_window.geometry("240x320") # 调整窗口大小
self.result_window.resizable(False, False)
# 图片显示区域
img_label = tk.Label(self.result_window)
img_label.pack(pady=10)
# 调整图片大小以适应窗口
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
img = img.resize((220, 180), Image.Resampling.LANCZOS)
imgtk = ImageTk.PhotoImage(image=img)
img_label.imgtk = imgtk
img_label.configure(image=imgtk)
# 推理结果显示区域
result_label = tk.Label(self.result_window, text=f"预测结果是:{prediction}", font=("微软雅黑", 12), fg="#333", wraplength=220)
result_label.pack(pady=10)
# 退出按钮
exit_button = tk.Button(self.result_window, text="退出", command=self.result_window.destroy, bg="#D32F2F", fg="white", font=("微软雅黑", 12))
exit_button.pack(pady=20)
def close_camera(self):
if self.camera_active:
self.camera_active = False
self.cap.release()
self.camera_label.configure(image="")
def on_closing(self):
self.close_camera()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = BirdRecognitionApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
root.mainloop()(2)加语音合成:利用 pyttsx实现
import tkinter as tk
from tkinter import messagebox
import cv2
from PIL import Image, ImageTk
# 假设 XEdu.hub 存在,实际使用时请确保该模块可用
from XEdu.hub import Workflow as wf # 导入模型推理模块
import pyttsx3 # 导入语音播报库
class BirdRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("花亭湖湿地鸟类识别")
self.root.geometry("240x320")
self.root.resizable(False, False)
# 初始化语音引擎
self.engine = pyttsx3.init()
self.engine.setProperty('rate', 150) # 设置语音速度
self.engine.setProperty('volume', 1.0) # 设置语音音量
# 标题
self.title_label = tk.Label(root, text="花亭湖湿地鸟类识别", font=("微软雅黑", 16, "bold"), bg="#E0F7FA", fg="#03A9F4")
self.title_label.pack(fill=tk.X)
# 按钮区域
self.button_frame = tk.Frame(root)
self.button_frame.pack(pady=10)
self.open_camera_button = tk.Button(self.button_frame, text="打开摄像头", command=self.open_camera, bg="#43A047", fg="white", font=("微软雅黑", 12))
self.open_camera_button.pack(side=tk.LEFT, padx=5)
self.take_photo_button = tk.Button(self.button_frame, text="拍照", command=self.take_photo, bg="#FFC107", fg="white", font=("微软雅黑", 12))
self.take_photo_button.pack(side=tk.LEFT, padx=5)
# 摄像头显示区域
self.camera_frame = tk.Frame(root, bg="#E0E0E0", width=240, height=200)
self.camera_frame.pack(pady=10)
self.camera_label = tk.Label(self.camera_frame, bg="#E0E0E0")
self.camera_label.pack(fill=tk.BOTH, expand=True)
# 摄像头状态
self.camera_active = False
self.cap = None
# 初始化模型
self.model = wf(task='mmedu', checkpoint='cls0225.onnx')
def open_camera(self):
if not self.camera_active:
self.cap = cv2.VideoCapture(0)
if self.cap.isOpened():
self.camera_active = True
self.update_camera()
else:
messagebox.showerror("错误", "无法打开摄像头!")
def update_camera(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
frame = cv2.resize(frame, (240, 200))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
self.camera_label.imgtk = imgtk
self.camera_label.configure(image=imgtk)
self.root.after(10, self.update_camera)
def take_photo(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
self.process_photo(frame)
def process_photo(self, photo):
try:
# 将照片传递给模型进行推理
res, img = self.model.inference(data=photo, img_type='cv2')
# 标准化推理结果
result = self.model.format_output(lang="zh")
# 提取预测结果
prediction = result.get('预测结果', "未知结果")
# 根据预测结果进行语音播报
self.speak_based_on_prediction(prediction)
# 显示推理结果和照片
self.show_result_window(img, prediction)
except Exception as e:
messagebox.showerror("错误", f"模型推理失败: {str(e)}")
def speak_based_on_prediction(self, prediction):
# 定义预测结果与语音播报内容的映射关系
prediction_to_speech = {
'White-crowned Long-tailed Pheasant': '这是一只白冠长尾雉',
'Northern Goshawk': '这是一只苍鹰',
'Black Kite': '这是一只黑鸢',
'Common Kestrel': '这是一只红隼',
'Mandarin Duck': '这是鸳鸯',
'Chinese Merganser':'这是中华秋沙鸭'
}
# 获取对应的语音内容
speech_content = prediction_to_speech.get(prediction, "未知结果")
# 进行语音播报
self.speak(speech_content)
def show_result_window(self, img, prediction):
try:
# 创建推理结果窗口
self.result_window = tk.Toplevel(self.root)
self.result_window.title("推理结果")
self.result_window.geometry("240x320") # 调整窗口大小
self.result_window.resizable(False, False)
# 照片显示区域
self.photo_label = tk.Label(self.result_window)
self.photo_label.pack(pady=10)
# 调整照片大小以适应窗口
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
img = img.resize((220, 200), Image.Resampling.LANCZOS)
self.imgtk = ImageTk.PhotoImage(image=img)
self.photo_label.configure(image=self.imgtk)
# 根据预测结果获取对应的中文描述
prediction_to_text = {
'White-crowned Long-tailed Pheasant': '预测结果:白冠长尾雉',
'Northern Goshawk': '预测结果:苍鹰',
'Black Kite': '预测结果:黑鸢',
'Common Kestrel': '预测结果:红隼',
'Mandarin Duck': '预测结果:鸳鸯',
'Chinese Merganser': '预测结果:中华秋沙鸭'
}
result_text = prediction_to_text.get(prediction, "未知结果")
# 推理结果显示区域
result_label = tk.Label(self.result_window, text=result_text, font=("微软雅黑", 12), fg="#333", wraplength=220)
result_label.pack(pady=10)
# 修改后的退出按钮
exit_button = tk.Button(self.result_window, text="退出", command=self.result_window.destroy, bg="#D32F2F", fg="white", font=("微软雅黑", 12), width=10, height=30)
exit_button.pack(pady=10)
except Exception as e:
messagebox.showerror("错误", f"显示结果窗口时出错: {str(e)}")
def speak(self, text):
"""语音播报函数"""
self.engine.say(text)
self.engine.runAndWait()
def close_camera(self):
if self.camera_active:
self.camera_active = False
self.cap.release()
self.camera_label.configure(image="")
def on_closing(self):
self.close_camera()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = BirdRecognitionApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
root.mainloop()
由于 pyttsx效果不太好 ,利用在线文字转语音工具,制作了音频文件,导入项目里。
本地部署+语音播报
import tkinter as tk
from tkinter import messagebox
import cv2
from PIL import Image, ImageTk
from XEdu.hub import Workflow as wf # 导入模型推理模块
import os # 导入 os 模块用于调用系统命令
class BirdRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("花亭湖湿地鸟类识别")
self.root.geometry("240x320")
self.root.resizable(False, False)
# 标题
self.title_label = tk.Label(root, text="花亭湖湿地鸟类识别", font=("微软雅黑", 16, "bold"), bg="#E0F7FA", fg="#03A9F4")
self.title_label.pack(fill=tk.X)
# 按钮区域
self.button_frame = tk.Frame(root)
self.button_frame.pack(pady=10)
self.open_camera_button = tk.Button(self.button_frame, text="打开摄像头", command=self.open_camera, bg="#43A047", fg="white", font=("微软雅黑", 12))
self.open_camera_button.pack(side=tk.LEFT, padx=5)
self.take_photo_button = tk.Button(self.button_frame, text="拍照", command=self.take_photo, bg="#FFC107", fg="white", font=("微软雅黑", 12))
self.take_photo_button.pack(side=tk.LEFT, padx=5)
# 摄像头显示区域
self.camera_frame = tk.Frame(root, bg="#E0E0E0", width=240, height=200)
self.camera_frame.pack(pady=10)
self.camera_label = tk.Label(self.camera_frame, bg="#E0E0E0")
self.camera_label.pack(fill=tk.BOTH, expand=True)
# 摄像头状态
self.camera_active = False
self.cap = None
# 初始化模型
self.model = wf(task='mmedu', checkpoint='cls0218.onnx')
# 定义预测结果与音频文件的映射关系
self.prediction_to_audio = {
'White-crowned Long-tailed Pheasant': 'White-crowned_Long-tailed_Pheasant.mp3',
'Northern Goshawk': 'Northern_Goshawk.mp3',
'Black Kite': 'Black_Kite.mp3',
'Common Kestrel': 'Common_Kestrel.mp3',
'Mandarin Duck': 'Mandarin_Duck.mp3',
'Chinese Merganser': 'Chinese_Merganser.mp3'
}
def open_camera(self):
if not self.camera_active:
self.cap = cv2.VideoCapture(0)
if self.cap.isOpened():
self.camera_active = True
self.update_camera()
else:
messagebox.showerror("错误", "无法打开摄像头!")
def update_camera(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
frame = cv2.resize(frame, (240, 200))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
self.camera_label.imgtk = imgtk
self.camera_label.configure(image=imgtk)
self.root.after(10, self.update_camera)
def take_photo(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
self.process_photo(frame)
def process_photo(self, photo):
try:
# 将照片传递给模型进行推理
res, img = self.model.inference(data=photo, img_type='cv2')
# 标准化推理结果
result = self.model.format_output(lang="zh")
# 提取预测结果
prediction = result.get('预测结果', "未知结果")
# 根据预测结果播放对应的音频
self.play_audio_based_on_prediction(prediction)
# 显示推理结果和照片
self.show_result_window(img, prediction)
except Exception as e:
messagebox.showerror("错误", f"模型推理失败: {str(e)}")
def play_audio_based_on_prediction(self, prediction):
"""根据预测结果播放对应的音频"""
audio_file = self.prediction_to_audio.get(prediction)
if audio_file:
try:
# 使用 Windows 系统命令播放 MP3 文件
os.system(f"start {audio_file}")
except Exception as e:
messagebox.showerror("音频播放失败", f"无法播放音频文件: {audio_file}\n错误信息: {e}")
else:
print(f"未找到对应的音频文件: {prediction}")
def show_result_window(self, img, prediction):
try:
# 创建推理结果窗口
self.result_window = tk.Toplevel(self.root)
self.result_window.title("推理结果")
self.result_window.geometry("240x320") # 调整窗口大小
self.result_window.resizable(False, False)
# 照片显示区域
self.photo_label = tk.Label(self.result_window)
self.photo_label.pack(pady=10)
# 调整照片大小以适应窗口
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
img = img.resize((220, 200), Image.Resampling.LANCZOS)
self.imgtk = ImageTk.PhotoImage(image=img)
self.photo_label.configure(image=self.imgtk)
# 根据预测结果获取对应的中文描述
prediction_to_text = {
'White-crowned Long-tailed Pheasant': '预测结果:白冠长尾雉',
'Northern Goshawk': '预测结果:苍鹰',
'Black Kite': '预测结果:黑鸢',
'Common Kestrel': '预测结果:红隼',
'Mandarin Duck': '预测结果:鸳鸯',
'Chinese Merganser': '预测结果:中华秋沙鸭'
}
result_text = prediction_to_text.get(prediction, "未知结果")
# 推理结果显示区域
result_label = tk.Label(self.result_window, text=result_text, font=("微软雅黑", 12), fg="#333", wraplength=220)
result_label.pack(pady=10)
# 修改后的退出按钮
exit_button = tk.Button(self.result_window, text="退出", command=self.result_window.destroy, bg="#D32F2F", fg="white", font=("微软雅黑", 12), width=10, height=30)
exit_button.pack(pady=10)
except Exception as e:
messagebox.showerror("错误", f"显示结果窗口时出错: {str(e)}")
def close_camera(self):
if self.camera_active:
self.camera_active = False
self.cap.release()
self.camera_label.configure(image="")
def on_closing(self):
self.close_camera()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = BirdRecognitionApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
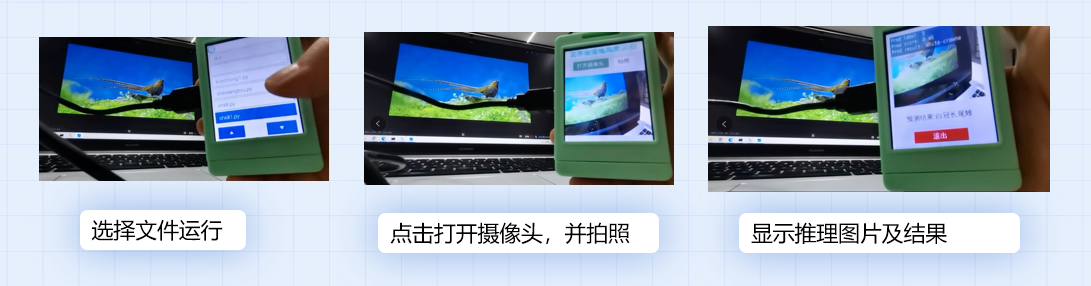
root.mainloop()3.5.3行空板部署
import tkinter as tk
from tkinter import messagebox
import cv2
from PIL import Image, ImageTk
from XEdu.hub import Workflow as wf # 导入模型推理模块
import os # 导入 os 模块用于调用系统命令
class BirdRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("花亭湖湿地鸟类识别")
self.root.geometry("240x320")
self.root.resizable(False, False)
# 标题
self.title_label = tk.Label(root, text="花亭湖湿地鸟类识别", font=("微软雅黑", 16, "bold"), bg="#E0F7FA", fg="#03A9F4")
self.title_label.pack(fill=tk.X)
# 按钮区域
self.button_frame = tk.Frame(root)
self.button_frame.pack(pady=10)
self.open_camera_button = tk.Button(self.button_frame, text="打开摄像头", command=self.open_camera, bg="#43A047", fg="white", font=("微软雅黑", 12))
self.open_camera_button.pack(side=tk.LEFT, padx=5)
self.take_photo_button = tk.Button(self.button_frame, text="拍照", command=self.take_photo, bg="#FFC107", fg="white", font=("微软雅黑", 12))
self.take_photo_button.pack(side=tk.LEFT, padx=5)
# 摄像头显示区域
self.camera_frame = tk.Frame(root, bg="#E0E0E0", width=240, height=200)
self.camera_frame.pack(pady=10)
self.camera_label = tk.Label(self.camera_frame, bg="#E0E0E0")
self.camera_label.pack(fill=tk.BOTH, expand=True)
# 摄像头状态
self.camera_active = False
self.cap = None
# 初始化模型
self.model = wf(task='mmedu', checkpoint='cls0217.onnx')
# 定义预测结果与音频文件的映射关系(使用绝对路径)
self.prediction_to_audio = {
'White-crowned Long-tailed Pheasant': '/root/upload/White-crowned_Long-tailed_Pheasant.mp3',
'Northern Goshawk': '/root/upload/Northern_Goshawk.mp3',
'Black Kite': '/root/upload/Black_Kite.mp3',
'Common Kestrel': '/root/upload/Common_Kestrel.mp3',
'Mandarin Duck': '/root/upload/Mandarin_Duck.mp3',
'Chinese Merganser': '/root/upload/Chinese_Merganser.mp3'
}
def open_camera(self):
if not self.camera_active:
self.cap = cv2.VideoCapture(0)
if self.cap.isOpened():
self.camera_active = True
self.update_camera()
else:
messagebox.showerror("错误", "无法打开摄像头!")
def update_camera(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
frame = cv2.resize(frame, (240, 200))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
self.camera_label.imgtk = imgtk
self.camera_label.configure(image=imgtk)
self.root.after(10, self.update_camera)
def take_photo(self):
if self.camera_active:
ret, frame = self.cap.read()
if ret:
self.process_photo(frame)
def process_photo(self, photo):
try:
# 将照片传递给模型进行推理
res, img = self.model.inference(data=photo, img_type='cv2')
# 标准化推理结果
result = self.model.format_output(lang="zh")
# 提取预测结果
prediction = result.get('预测结果', "未知结果")
# 根据预测结果播放对应的音频
self.play_audio_based_on_prediction(prediction)
# 显示推理结果和照片
self.show_result_window(img, prediction)
except Exception as e:
messagebox.showerror("错误", f"模型推理失败: {str(e)}")
def play_audio_based_on_prediction(self, prediction):
"""根据预测结果播放对应的音频"""
audio_file = self.prediction_to_audio.get(prediction)
if audio_file:
try:
# 使用 Linux 系统命令播放 MP3 文件
os.system(f"mpg321 {audio_file} &") # 使用 mpg321 播放
except Exception as e:
messagebox.showerror("音频播放失败", f"无法播放音频文件: {audio_file}\n错误信息: {e}")
else:
print(f"未找到对应的音频文件: {prediction}")
def show_result_window(self, img, prediction):
try:
# 创建推理结果窗口
self.result_window = tk.Toplevel(self.root)
self.result_window.title("推理结果")
self.result_window.geometry("240x320") # 调整窗口大小
self.result_window.resizable(False, False)
# 照片显示区域
self.photo_label = tk.Label(self.result_window)
self.photo_label.pack(pady=10)
# 调整照片大小以适应窗口
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
img = img.resize((220, 200), Image.Resampling.LANCZOS)
self.imgtk = ImageTk.PhotoImage(image=img)
self.photo_label.configure(image=self.imgtk)
# 根据预测结果获取对应的中文描述
prediction_to_text = {
'White-crowned Long-tailed Pheasant': '预测结果:白冠长尾雉',
'Northern Goshawk': '预测结果:苍鹰',
'Black Kite': '预测结果:黑鸢',
'Common Kestrel': '预测结果:红隼',
'Mandarin Duck': '预测结果:鸳鸯',
'Chinese Merganser': '预测结果:中华秋沙鸭'
}
result_text = prediction_to_text.get(prediction, "未知结果")
# 推理结果显示区域
result_label = tk.Label(self.result_window, text=result_text, font=("微软雅黑", 12), fg="#333", wraplength=220)
result_label.pack(pady=10)
# 修改后的退出按钮
exit_button = tk.Button(self.result_window, text="退出", command=self.result_window.destroy, bg="#D32F2F", fg="white", font=("微软雅黑", 12), width=10, height=30)
exit_button.pack(pady=10)
except Exception as e:
messagebox.showerror("错误", f"显示结果窗口时出错: {str(e)}")
def close_camera(self):
if self.camera_active:
self.camera_active = False
self.cap.release()
self.camera_label.configure(image="")
def on_closing(self):
self.close_camera()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = BirdRecognitionApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
root.mainloop()
深度学习训练参数详解
参数
参数是刻画模型具体形状的一系列数值。可以类比为阅读一本书时需要理解的内容,书中的章节、段落、句子和单词等结构就类比于深度学习中的参数,它们构成了具体的模型形状,需要通过训练来自动调整以优化模型效果。在深度学习的训练过程中,参数是自动形成的。参数训练的好,那么模型效果就好,就像阅读时能够准确理解书中的内容,参数训练不好,那么模型效果就差,就像阅读时理解困难或者无法掌握书中内容,模型效果差包括“欠拟合”、“过拟合”等多种情况。
欠拟合(underfitting)可以类比为对书中内容的理解不够深入,没有完全掌握书中的信息,因此无法准确地回答问题或者表达自己的观点,这就像是阅读时没有完全掌握书中的内容,不能完整地概括或回答问题一样。就像是学生在学习某一门课程时,只是粗略地看了一下书本内容,没有系统地学习,因此无法掌握知识点的精髓。
过拟合(overfitting)可以类比为对书中内容的理解过度深入,导致过度关注细节,无法理解书中的大意,不能准确地理解作者的意图和主旨,这就像阅读时过度关注细节而忽略了整体,不能很好地理解作者的意图和主旨。这种情况就相当于模型无法充分利用训练数据集中的信息,无法表现出较好的性能。就像是学生在学习某一门课程时,为了在考试中获得高分,刻意死记硬背了大量的题目答案,但是对于类似但略有不同的新题目,就可能无法应对。这种情况就相当于模型在训练数据集上表现得很好,但是在测试数据集上表现不佳,泛化能力较差。
超参数
超参数其实才是我们平时习惯说的参数。在非深度学习的算法中,我们通常通过设置参数来刻画模型,而实际上,在深度学习中,参数是自动生成的,我们可以设置的,就是一些对训练策略的约束,这些设置并不直接决定参数,因此我们常把它们称为“超参数”。这可以类比为在阅读一本书时需要做出的一些选择,如阅读速度、阅读顺序等,这些选择会影响我们理解和掌握书中内容的效果。与超参数类似,这些选择需要我们自己做出,并且需要根据我们自己的经验和目的来进行调整以获得最佳的阅读效果。
学习率
学习率(learning rate,lr)又称学习速率、学习步长等。学习率是控制模型在训练过程中参数更新速度的关键参数,学习率可以被视为一个步长,它决定了在优化过程中参数移动向最小化损失函数的目标值的速度。可以用读书的速度来类比学习率。如果学习率高,就好比快速翻阅书籍,能迅速把握大意,但可能错过细节,从而影响理解深度。在模型训练中,这可能导致快速提升精度,但有可能错过更精确的解决方案。另一方面,较低的学习率就像慢慢品读每一页,虽然能深入理解内容,但需要更长时间。在模型训练中,这意味着训练过程会非常缓慢。
在实际的深度学习任务中,我们通常采用各种学习率调整策略,如学习率衰减、自适应学习率算法(例如Adam、RMSprop),以及动量优化等,来帮助找到最合适的学习率。这些策略可以在训练过程中自动调整学习率,以期达到更优的训练效果。
选择合适的学习率和调整策略对于在可接受的时间范围内实现最佳模型性能至关重要。需要注意的是,无论学习率过高还是过低,都可能导致模型无法有效收敛或训练速度过慢。因此,选择最佳学习率通常需要根据具体任务的需求和特性,通过实验和经验判断来确定。
学习轮次
学习轮次(epoch)表示完成多少次训练,指的是在训练神经网络时,我们对整个训练数据集进行完整的一次训练所需的迭代次数。在每一轮中,模型会遍历整个训练集并更新参数,以尽可能减少训练误差。如果以看书做比喻,每轮看完书相当于模型通过一次完整的训练,而重复的轮数就好比我们重复多次看同一本书,可以更深入地理解和记忆书中的内容。在深度学习中,重复的轮数越多,模型对训练数据的学习就越深入,通常会得到更好的性能表现。然而,轮数过多也可能导致过拟合,即模型在训练数据上表现良好,但在测试数据上表现不佳。因此,需要在训练过程中监控模型在验证集上的性能表现,并及时停止训练以避免过拟合。通常,我们会根据实际情况选择合适的轮数,以在保证训练效果的前提下,尽可能减少训练时间和计算资源的消耗。
批量大小
批量大小(batch_size)表示在一次训练中同时处理的样本数量。通常情况下,批量大小越大,模型的收敛速度越快,但内存和计算资源的需求也会相应增加。如果以看书来作比喻,可以把batch_size看做是在看书时每次读取的章节数量。比如,如果batch_size等于1,那么就相当于每次只读取一章,需要不断地翻页才能完成整本书的阅读;而如果batch_size等于10,那么就相当于每次读取10章,可以一次性翻到很远的位置,节省了不少翻页的时间和劳动。如果batch_size很小,就相当于每次只读取很少的一部分内容,需要不断地翻页才能完成阅读,这会增加翻页的时间和劳动。如果batch_size很大,就相当于每次读取很多内容,可以节省不少翻页的时间和劳动,但也可能导致阅读过程中忽略掉了一些细节。因此,选择合适的batch_size是很重要的。
关于batch_size的取值范围,应该大于类别数,小于样本数,且由于GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优。batch_size、iter、 epoch的关系如下:
(1)batch_size:批大小,一次训练所选取的样本数,指每次训练在训练集中取batch_size个样本训练;
(2)iter:1个iter等于使用batch_size个样本训练一次,iter可在训练日志中看到;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
如训练集有240个样本,设置batch_size=6,那么:训练完整个样本集需要:40个iter,1个epoch。
优化器
优化器规定了学习的方向。优化器就像看书时的阅读方式。不同的人可能有不同的阅读偏好,有些人喜欢先阅读整本书的目录和摘要,再选择性地阅读章节,有些人则更喜欢逐字逐句地仔细阅读每一页。在不同的任务中,要根据实际情况来选择优化器。
常见的优化器是SGD和Adam。就像阅读偏好一样,不同的优化器可能会对模型的性能和训练速度产生不同的影响,需要通过实验和经验来选择最佳的优化器。
训练策略
训练策略就像看书时的阅读计划。在阅读一本书时,有些人可能会制定一个阅读计划,比如每天读一定的章节或一页,或者按照某种顺序阅读不同的章节,以达到更好的阅读效果。
训练也是这样,一般先用大的学习率,再转为小的学习率继续训练。尝试使用多种优化器,经过不断尝试,让最终结果达到最优或可用的状态。在深度学习任务中,训练策略也非常重要。训练策略包括数据增强、正则化、早停等技巧,这些技巧都可以帮助我们更好地训练模型,并提高模型的性能。就像阅读计划一样,训练策略需要根据具体任务和数据集的不同来进行选择和调整,以获得最佳的训练效果。



 他的勋章
他的勋章







shzrzxlee2025.03.16
请问模型训练在浦育平台,并不是在mind+
tongtong203362025.03.19
是的,模型训练在浦育