 返回首页
返回首页
 回到顶部
回到顶部

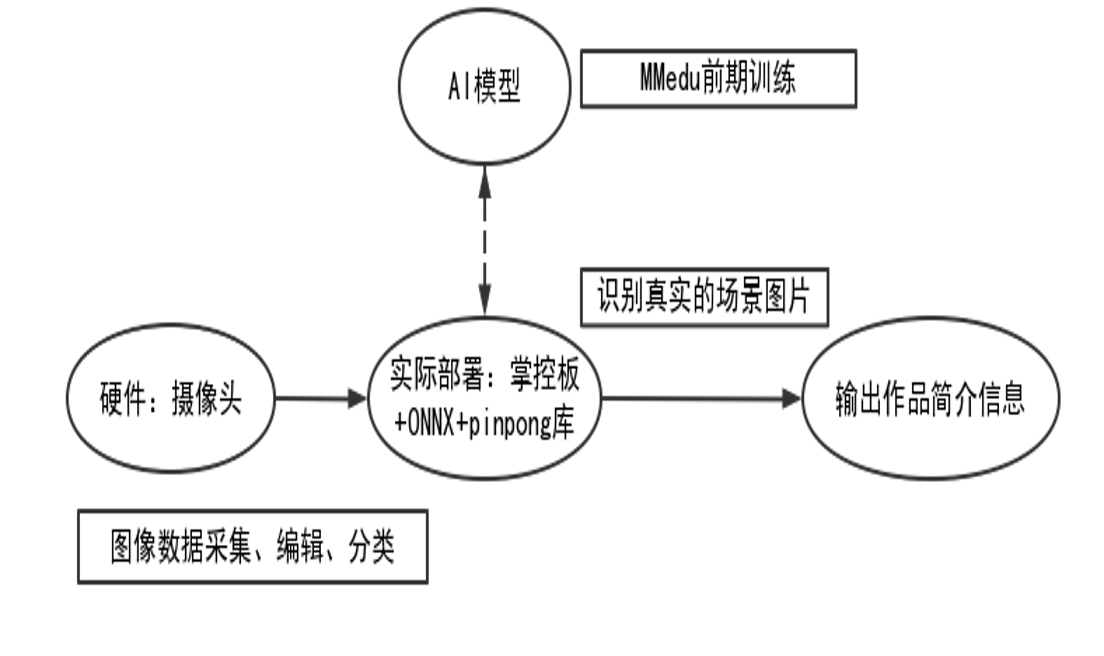
一、选题背景及意义
太湖县五千年文博园景点内有一座根雕馆,根雕馆的展品众多,每件展品看似相同,其实形态各异,让人眼花缭乱,游览过程中需要工作人员解说,假日旅游高峰期解说员工作量十分巨大,所以想设计一款能协助解说员的解说机器人,让解说员的工作可以更加轻松,为游客提供更好地服务,也让游客对展馆印象深刻。
二、项目构思
用MMEdu进行图像分类,对采集的根雕展品进行识别,是否能准确从图片中识别出正确的根雕展品,并将模型部署到硬件,再加上外形结构设计,从而设计一款——根雕馆解说装置。
三、技术实现方法及步骤
技术实现分四步:
1、数据采集
2、模型训练
3、模型转换
4、推理部署
1、数据采集
根雕馆实地拍摄三件展品图片,分别是霸王出击、达摩传法、黄山迎客松,每一件展品都从不同的角度拍摄了260张,并整理为ImageNet格式。
数据集分布均匀,训练集共624张图片,各类别均为208张图片,且配有验证集和测试集,每类图片数量分别是26张和26张。
图片均为RGB彩色JPEG图片
大小均为256*256

2、模型训练&模型测试
2.1模型训练
2.1.1模型训练平台:浦育平台
2.1.2 模型训练
安装基础库
首先安装MMEdu用于模型转换,安装BaseDeploy用于模型部署。
!pip install --upgrade MMEdu --no-deps -i
!pip install BaseDeploy -i
第一步:导入库、实例化模型
第一种方法:从0开始训练
#从0开始训练
!pip install --upgrade MMEdu --no-deps #更新库文件
from MMEdu import MMClassification as cls #实例化模型
model = cls(backbone='MobileNet') #选择网络模型
model.num_classes = 3 #三类根雕图片
model.load_dataset(path='/data/2FFY40/my_dataset') #根雕数据集文件
model.save_fold = 'checkpoints/cls_model/gendiao0' #根雕权重保存路径
model.train(epochs=50 ,lr=0.001, validate=True,device='cuda') #训练轮次第二种方法:使用预训练模型
#使用预训练模型
from MMEdu import MMClassification as cls #实例化模型
model = cls(backbone='MobileNet') #选择网络模型
model.num_classes = 3 #三类根雕图片
model.load_dataset(path='/data/2FFY40/my_dataset') #根雕数据集文件
model.save_fold = 'checkpoints/cls_model/gendiao' #根雕权重保存路径
model.train(epochs=5, checkpoint='checkpoints/cls_model/gendiao0/best_accuracy_top-1_epoch_7.pth' ,lr=0.001, validate=True,device='cuda') #训练轮次,训练已存的权重2.2 模型测试
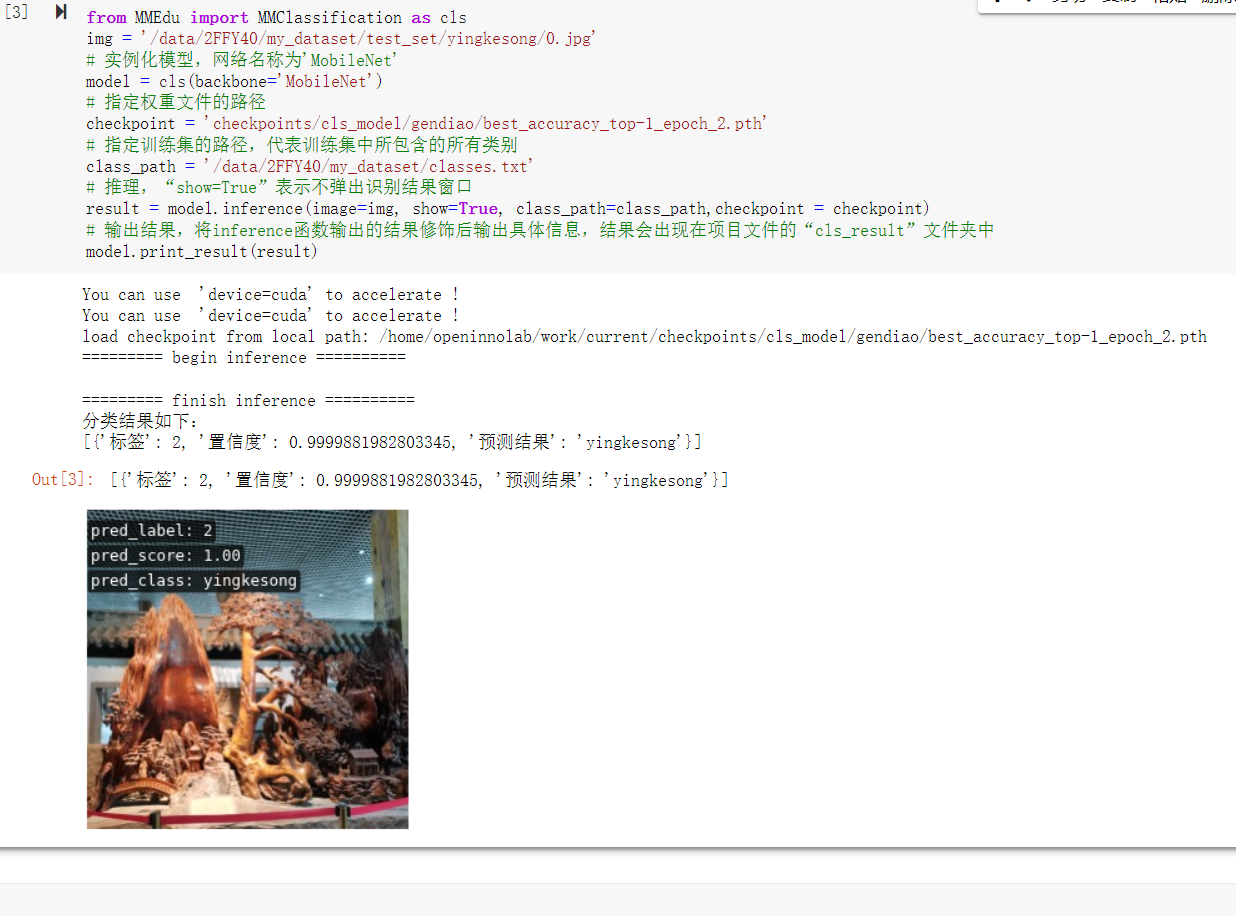
from MMEdu import MMClassification as cls
#模型测试
img = '/data/2FFY40/my_dataset/test_set/yingkesong/0.jpg'
# 实例化模型,网络名称为'MobileNet'
model = cls(backbone='MobileNet')
# 指定权重文件的路径
checkpoint = 'checkpoints/cls_model/gendiao/best_accuracy_top-1_epoch_2.pth'
# 指定训练集的路径,代表训练集中所包含的所有类别
class_path = '/data/2FFY40/my_dataset/classes.txt'
# 推理,“show=True”表示不弹出识别结果窗口
result = model.inference(image=img, show=True, class_path=class_path,checkpoint = checkpoint)
# 输出结果,将inference函数输出的结果修饰后输出具体信息,结果会出现在项目文件的“cls_result”文件夹中
model.print_result(result)测试结果:
3、模型转换&模型转换测试
3.1模型转换
根据训练好的MobileNetV2网络的权重,利用convert函数将模型转换至ONNX
#模型转换
from MMEdu import MMClassification as cls
model = cls(backbone='MobileNet')
model.num_classes = 3
checkpoint = 'checkpoints/cls_model/gendiao/best_accuracy_top-1_epoch_2.pth'
out_file="out_file/gendiao1.onnx"
model.convert(checkpoint=checkpoint, backend="ONNX", out_file=out_file, class_path='/data/2FFY40/my_dataset/classes.txt')
3.2模型转换测试
#模型转换测试
import onnxruntime as rt
import BaseData
import numpy as np
tag = ['bawang', 'damo','yingkesong']
sess = rt.InferenceSession('out_file/gendiao.onnx', None)
input_name = sess.get_inputs()[0].name
out_name = sess.get_outputs()[0].name
dt = BaseData.ImageData('/data/2FFY40/my_dataset/test_set/bawang/0.jpg', backbone='MobileNet')
input_data = dt.to_tensor()
pred_onx = sess.run([out_name], {input_name: input_data})
ort_output = pred_onx[0]
idx = np.argmax(ort_output, axis=1)[0]
if tag[idx] =='bawang':
print('这是霸王出击根雕!')
if tag[idx] =='yingkesong':
print('这是迎客松根雕!')
if tag[idx] =='damo':
print('这是达摩传法根雕!')
4、推理部署
推理部署方法一:掌控板
4.1利用电脑的摄像头和掌控板里的pinpong库进行部署。
当电脑摄像头拍摄一张根雕图片,进行识别后,在掌控板的屏幕上显示此根雕的相关信息。



# mobilenetv2.onnx为根雕分类的数据模型
import onnxruntime as rt
import BaseData
import numpy as np
import pyttsx3
engine = pyttsx3.init()
def get_tag(path):
with open(path, 'r', encoding='utf-8') as f:
tag = [e.rstrip("\n") for e in f.readlines()]
return tag
def infer(img,pth,backbone):
sess = rt.InferenceSession(pth, None)
input_name = sess.get_inputs()[0].name
out_name = sess.get_outputs()[0].name
dt = BaseData.ImageData(img, backbone=backbone)
input_data = dt.to_tensor()
pred_onx = sess.run([out_name], {input_name: input_data})
ort_output = pred_onx[0]
idx = np.argmax(ort_output, axis=1)[0]
return [idx,ort_output[0][idx]]
import cv2
import time
tag = ['damo', 'yingkesong','bawang']
backbone = 'MobileNet'
pth = 'cls/checkpoints/gendiao1.onnx'
cap = cv2.VideoCapture(0)
ret, img = cap.read()
time.sleep(0.1)
ret, img = cap.read()
cv2.imwrite('2.jpg',img)
img = img[:,:,::-1]
idx,acc = infer(img,pth,backbone)
print('result:' + tag[idx] + ' , and acc:' + str(acc))
cap.release()
import matplotlib.pyplot as plt
plt.imshow(img)
plt.show()
import time
from pinpong.board import Board
from pinpong.extension.handpy import *
Board("handpy").begin()
if tag[idx] =='yingkesong':
engine.say('这是迎客松根雕!')
print('这是迎客松根雕!')
oled.DispChar('这是迎客松根雕', 2, 0) #先写入缓存区,在(2,0)处显示'这是迎客松根雕'
oled.DispChar('是用红豆杉根雕刻而成', 2, 16) #先写入缓存区,在(2,16)处显示'是用红豆杉根雕刻而成'
oled.DispChar('对根材稍加装饰', 2, 32) #先写入缓存区,在(2,32)处显示'对根材稍加装饰'
oled.DispChar('体现迎客松秀丽之美', 2, 48) #先写入缓存区,在(2,48)处显示'体现迎客松秀丽之美'
oled.show()
rgb[0] = (255, 0, 0) # 设置为红色,全亮度
rgb[1] = (0, 128, 0) # 设定为绿色,一半亮度
rgb[2] = (0, 0, 64) # 设置为蓝色,四分之一亮度
rgb.write()
tune = ["C4:4", "D4:4", "E4:4"]
music.play(tune) #播放自编乐谱
if tag[idx] =='bawang':
engine.say('这是霸王出击根雕!')
print('这是霸王出击根雕!')
oled.DispChar('这是霸王出击根雕,', 2, 0)
oled.DispChar('是用缅甸黄金樟雕刻而成', 2, 16)
oled.DispChar('对根材稍加装饰。', 2, 32)
oled.DispChar('体现阳刚之美', 2, 48)
oled.show()
rgb[0] = (0, 255, 0)
rgb[1] = (128, 0, 0)
rgb[2] = (64, 0, 0)
rgb.write()
tune = ["D4:4","C4:4","E4:4"]
music.play(tune)
if tag[idx] =='damo':
engine.say('这是达摩传法根雕!')
print('这是达摩传法根雕!')
oled.DispChar('这是达摩传法根雕,', 2, 0)
oled.DispChar('是用楠木雕刻而成', 2, 16)
oled.DispChar('对根材稍加装饰', 2, 32)
oled.DispChar('展现达摩神韵', 2, 48)
oled.show()
rgb[0] = (0, 0, 255)
rgb[1] = (0, 0, 128)
rgb[2] = (0, 64, 0)
rgb.write()
tune = ["E4:4","C4:4","D4:4"]
music.play(tune)
部署优化
目标最终实现的效果:根雕图片识别后,能有文字解说+语音播报的功能。由于硬件有限,所以用pyttsx3语音合成,在本地Jupyter完成模型仿真部署。
实现效果视频如下:
推理部署方法二:行空板部署
方案一:在Mind+里的Python模式下,用Mind+里的用户库ONNX进行部署
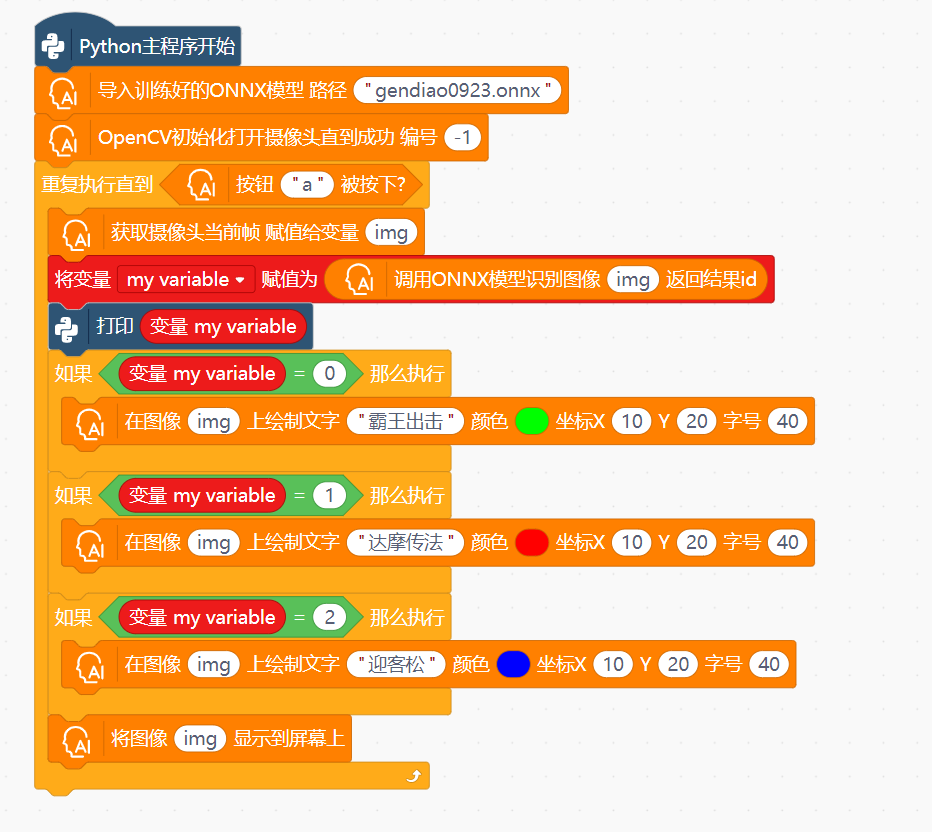
方案二:在Mind+里的Python模式下,写代码部署到行空板
实现的效果是:按下A开始拍照,识别,识别结果显示在行空板上
import onnxruntime as rt #用于使用onnx模型
import BaseData #即项目文件夹下的BaseData.py文件
import numpy as np
import cv2 #opencv-python模块,用于使用摄像头
import time
import matplotlib.pyplot as plt #matplotlib是一个2D绘图库,用来显示摄像头采集的照片
from unihiker import GUI #行空板unihiker库,用来显示文字
from pinpong.board import Board,Pin #行空板pinpong库,用来侦测按键
from pinpong.extension.unihiker import *
gui=GUI() #初始化两个行空板的模块
Board().begin()
def get_tag(path): #获取识别后的标签,即对应Imagenet1000中的某个序号
with open(path,'r',encoding='utf-8') as f:
tag=[e.rstrip("\n") for e in f.readlines()]
return tag
def infer(img,pth,backbone): #使用权重文件pth和网络backbone对img图像进行推理
sess=rt.InferenceSession(pth,None)
input_name=sess.get_inputs()[0].name
out_name=sess.get_outputs()[0].name
dt=BaseData.ImageData(img,backbone=backbone)
input_data=dt.to_tensor()
pred_onx=sess.run([out_name],{input_name:input_data})
ort_output=pred_onx[0]
print(ort_output)
idx=np.argmax(ort_output,axis=1)[0]
return [idx,ort_output[0][idx]]
tag=('bawang','damo','yingkesong') #标签文件
backbone='MobileNet' #使用网络
pth='gendiao0923.onnx' #模型文件
txt_show=gui.draw_text(x=0,y=0,text="请按A键开始识别",font_size=20)
while True:
if button_a.is_pressed(): #当按下行空板上的A键触发
cap=cv2.VideoCapture(0) #调用外接USB摄像头
#cap.set(3,240)
#cap.set(4,280)
#cap.set(10,100)
ret,img=cap.read() #拍一张照片
idx,acc=infer(img,pth,backbone)#进行一次推理
print('result:'+tag[idx]+',and acc:'+str(acc))
cap.release() #释放摄像头资源
txt_show.config(text=tag[idx])
plt.imshow(img) #显示图片
plt.show()
time.sleep(1)行空板实现效果视频如下:
项目测试结果:
识别率不是很高,存在的原因有如下几个:一是数据的质量,二是模型训练的过程
项目待完善部分:
外型未完善
最初设想是设计一款轮式解说机器人,但考虑到轮式机器人采集图像可能会存在很多不确定因素,所以欲设计为手持式解说装置,这样采集的图像效率更高。造型设计方面,可用激光切割完成。
多模态交互不够
在今后的完善过程中,还可以添加语音交互



 他的勋章
他的勋章







罗罗罗2024.04.14
学习了
tongtong203362024.04.14
谢谢~
無2024.02.20
有沒有簡單点訓練onnx模型的方法?
tongtong203362024.02.21
有的,可以去浦育平台的项目里学习一些
DeadWalking2023.12.28
学习一下!
tongtong203362024.01.21
感谢老铁支持~
_深蓝_2023.12.28
学习啦,感觉好繁琐
_深蓝_2023.12.28
喜欢用图形化的编程,哈哈
tongtong203362024.01.21
嗯嗯,是有点繁琐呢
JOVI2023.12.27
学习学习
tongtong203362024.01.21
相互交流