 返回首页
返回首页
 回到顶部
回到顶部
项目说明
通过行空板的外接设备,用python代码对接百度云语音和图像识别接口,以及运用opencv模块,实现中英文词语语音识别,标准语音转换,图片拍摄,图片识别等功能,可满足学生在学习中英文词语时的自我阅读,听写,检测的过程。
项目架构
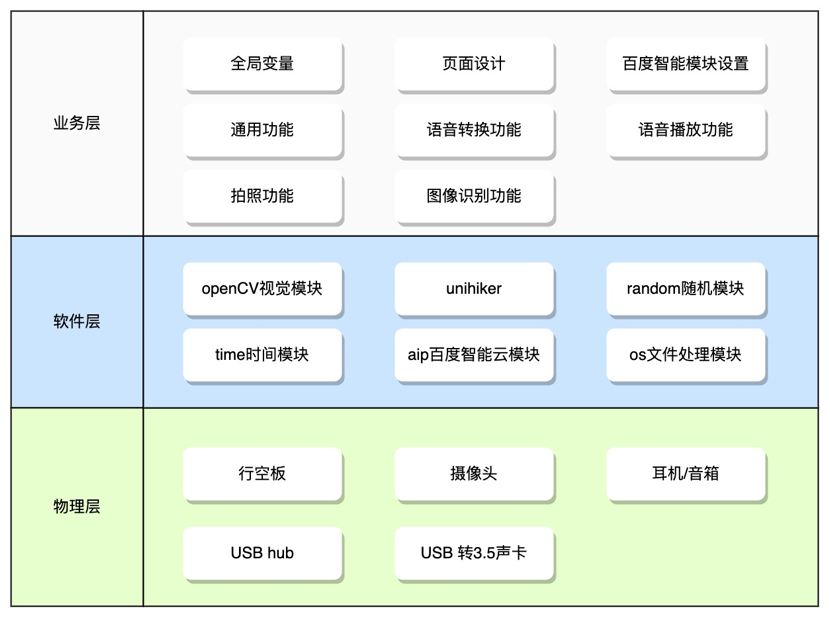
实施步骤
功能设计
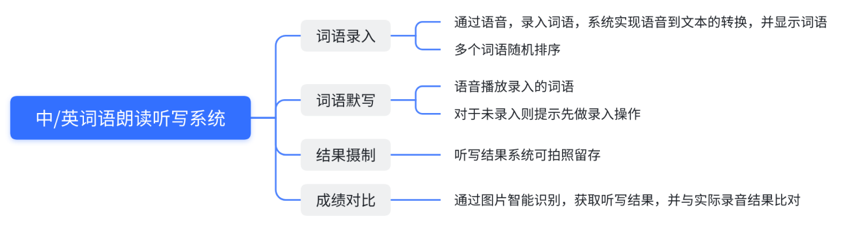
业务流程
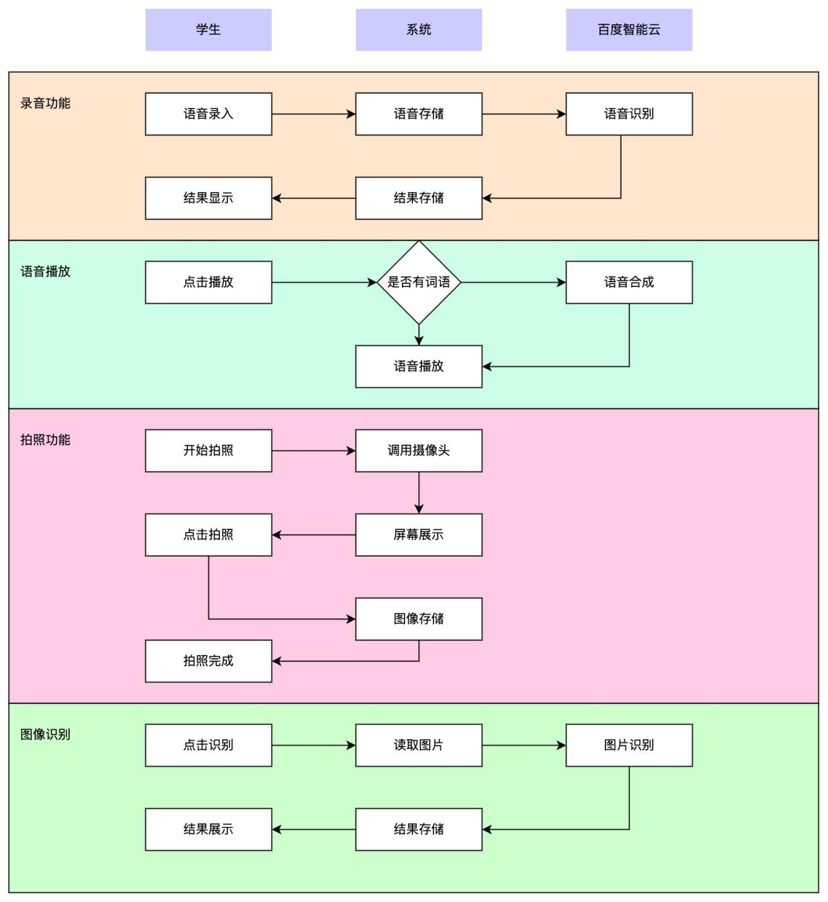
实现流程
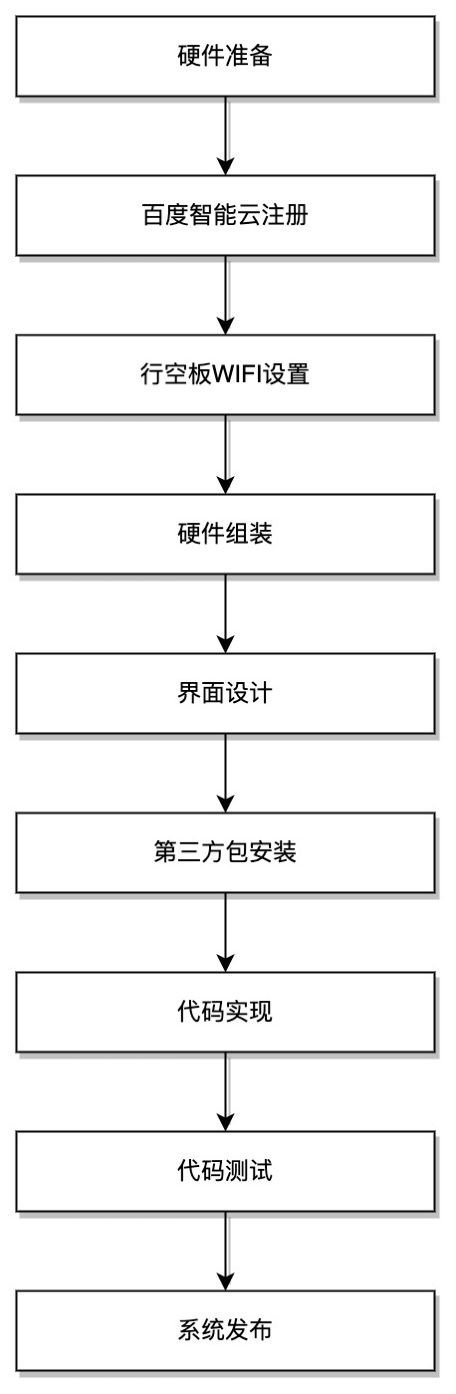
实施过程
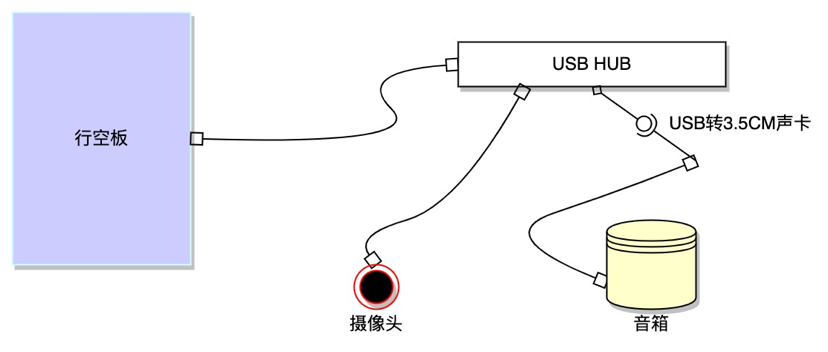
硬件准备
行空板×1
摄像头×1
USB HUB×1
耳机/音箱×1
USB 转 3.5cm 声卡×1
硬件组装
百度智能云注册
• 注册地址: https://bce.baidu.com/
• 注册并实名认证
• 分别进入人工智能引擎中的语音能力引擎和文字识别模块,领取免费额度,并创建应用。
• 记录应用中的 APP ID, API KEY, AECRET KEY.
行空板WIFI设置
• 行空板连接电脑
• Mind+ 页面连接行空板
• 浏览器输入行空板IP地址, 10.1.2.3
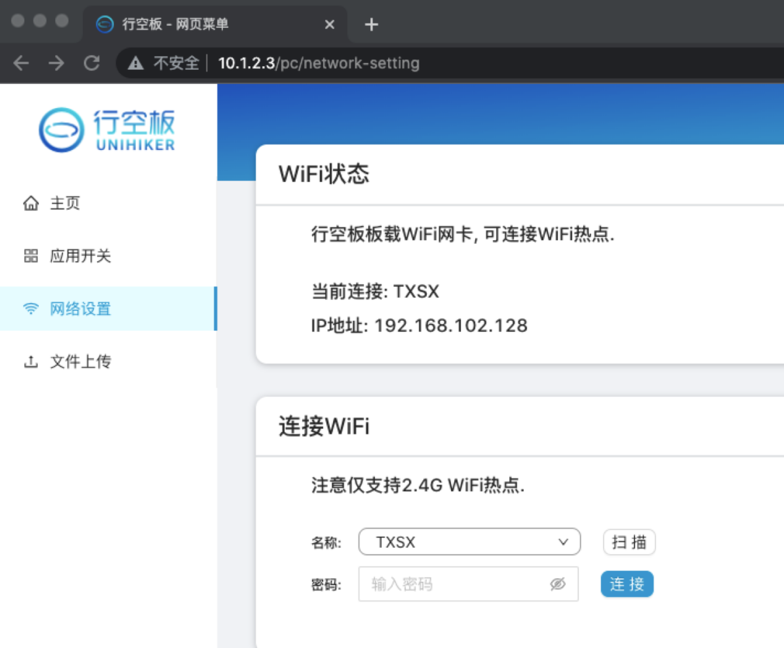
• 左导航点击"网络设置", 进入网络设置页面
• 查看"WIFI状态",检查是否已接入WI-FI
• 如果没有接入,则选择WI-FI名称,并输入密码进行连接(必要时点击"扫描"刷新下WIFI数据再选择)
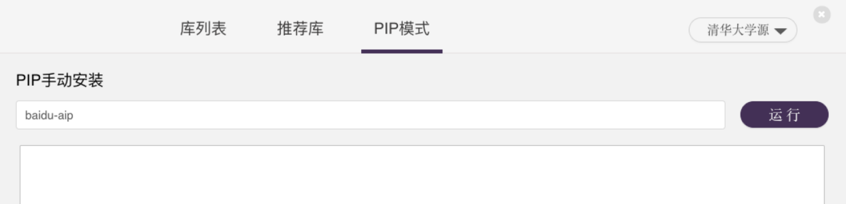
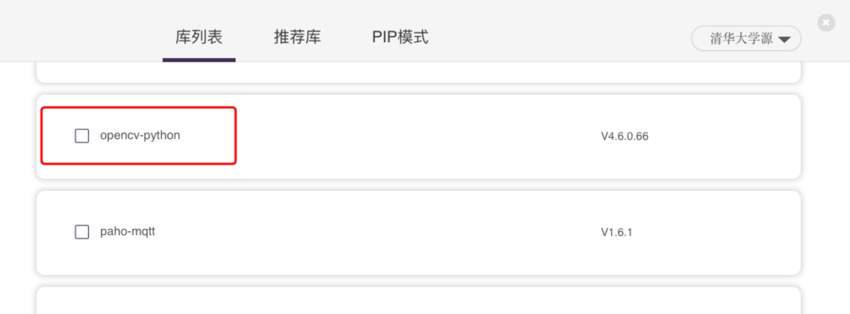
第三方库安装
• 打开Mind+页面
• 点击右上角"库管理", 进入库管理页面

• 点击"PIP模式",选择除 "Python官方源(国外)" 的其它源
• 在输入框中输入 "baidu-aip",点击"运行"安装百度智能云处理库
• 在"库列表"中,查找"opencv-python"库,如果没有找到说明该库没安装,进入"PIP模式",输入"opencv-python"进行安装
实现代码
• Mind+ 中创建项目
• 在"项目中的文件" 中新建文件,自定义文件名称
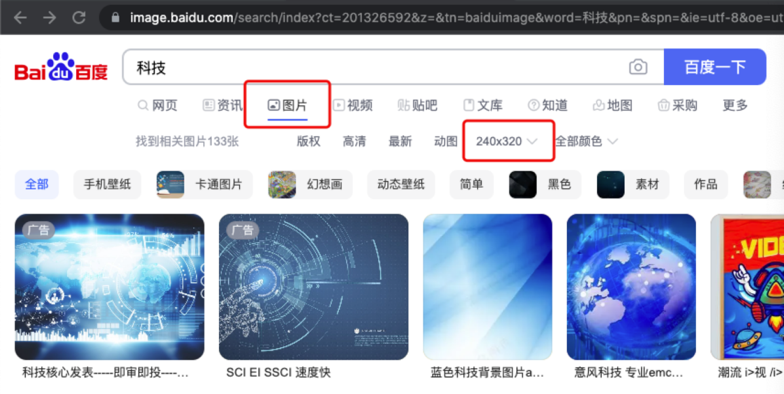
• 素材准备,可以用百度图片搜索,设置尺寸为 240 X 320 的图片。 下载图片到本地并改名。将下载的图片拖入到 "项目中的文件"中
代码浏览(简版)
Python
# python的os文件库,用户进行文件存储,读取,删除等操作
import os
# python时间库, 用于时间延时处理
import time
# python随机数库,用于随机排序词语
import random
# openCV库,用于处理视频和图像
import cv2
# unihiker库,用户行空板屏幕展示和声音处理
from unihiker import GUI, Audio
# 百度aip库,用于声音转文字,文字转声音,图片转文字处理
from aip import AipSpeech, AipOcr
# 实例化GUI类
gui = GUI()
# 实例化Audio类
audio = Audio()
# 用于保存词语数据
WORDS = []
# 定义录音文件存储名称
VOICE_FILE_NAME = 'voice.wav'
# 定义照片文件存储名称
PHOTO_FILE_NAME = 'photo.jpg'
# >>>>>>>>> 界面设计 <<<<<<<<<<
# 设置背景图片
background = gui.draw_image(w=240, h=320, image="bg.jpeg")
# 设置标题
title = gui.draw_text(x=120, y=0, color='red', font_size=12, text='中/英词语朗读听写系统',origin='top')
# 设置中文录音按钮
zh_voice_btn = gui.add_button(x=60, y=40, w=100, h=30, text="中文录音", origin='center', state='normal', onclick=None)
# 设置英文录音按钮
en_voice_btn = gui.add_button(x=180, y=40, w=100, h=30, text="英文录音", origin='center', state='normal', onclick=None)
# 设置录音文本
voice_txt = gui.draw_text(x=60, y=80, color='red', font_size=10, text='', origin='top')
# 设置听写结果文本
ocr_txt = gui.draw_text(x=180, y=80, color='black', font_size=10, text='', origin='top')
# 设置播放按钮
voice_play_btn = gui.add_button(x=120, y=280, w=100, h=30, text='播放', origin='center', state='normal', onclick=None)
# 设置重新开始按钮
again_btn = gui.add_button(x=10, y=320, w=100, h=30, text='重新开始', origin='bottom_left', state='normal', onclick=None)
# 设置查看成绩按钮
result_btn = gui.add_button(x=230, y=320, w=100, h=30, text='查看成绩', origin='bottom_right', state='normal', onclick=None)
# 百度语音识别设置
SPEECH_APP_ID = '27720455'
SPEECH_API_KEY = 'NSXS9gYnRfObgfGrzlplsrNZ'
SPEECH_SECRET_KEY = 'PRVFeohTgT3Fa8nbRjgAYoQnAxrRSUZ0'
# 语音识别类实例化,并赋给变量speech_client。
# 后面代码中需要使用语音识别时,直接使用变量名+.+方法名调用
speech_client = AipSpeech(SPEECH_APP_ID, SPEECH_API_KEY, SPEECH_SECRET_KEY)
# 百度图像识别设置
OCR_APP_ID = '25507845'
OCR_API_KEY = 'wURcKTV4xndQX6xjFM0ncYjl'
OCR_SECRET_KEY = 'n2RPpwEOReUrwnGFQA5QG2aQUQ1z7UaM'
# 图像识别类实例化,并赋给变量ocr_client。
# 后面代码中需要使用语音识别时,直接使用变量名+.+方法名调用
ocr_client = AipOcr(OCR_APP_ID, OCR_API_KEY, OCR_SECRET_KEY)
# ======= 通用方法 ======
# 清空所有文本框
def clear_txt():
# 将朗读的文本框清空
voice_txt.config(text='')
# 将结果的文本框清空
ocr_txt.config(text='')
# 删除文件, 参数filename为变量名,代表要传入的文件名称,文件名称包含后嘴。
# 如:video.wav bg.jpeg
def delete_file(filename):
# 判断文件是否存在
if os.path.exists(filename):
# 如果文件存在,则删除文件
os.remove(filename)
# 读取文件,参数filename为变量名,代表要传入的文件名称,文件名称包含后嘴。
# 如:video.wav bg.jpeg
def read_file(filename):
# 打开文件, rb 代表 read(读取) byte(字节),即按字节读取的方式打开文件
f = open(filename,'rb')
# 将文件读取并赋值给变量 file, file中即有了该文件的内容
file = f.read()
# 将打开的文件关闭
f.close()
# 返回文件内容,以便其它调用的程序能使用文件内容
return file
# 写入/保存文件 ,参数filename代表要写入的文件名称, data 代表要写入的内容
def write_file(filename, data):
# 打开件, wb 代表 write(写入) byte(字节),即按字节写入的方式打开文件
f = open(filename,'wb')
# 将数据data写入到文件中
f.write(data)
# 关闭文件
f.close()
# ======= 语音转文字 ======
# 在录音文本框,显示打乱次序的词语
def draw_voice_txt():
# 引入全局词语存储列表变量
global WORDS
# 将变量列表中的词语随机排序
random.shuffle(WORDS)
# 将列表中的词语拼接,中间用"\n"分割
words_txt = '\n'.join(WORDS)
# 在录音文本框中显示所有词语
voice_txt.config(text=words_txt)
# 语音转文字处理函数,参数dev_pid为百度语音转换的语音标示,
# 不同的值代表识别的语言不一样。1537代表普通话,1737代表英语
def voice_to_str(dev_pid):
# 全局引入语音文件名和词语存储列表
global VOICE_FILE_NAME
global WORDS
# 录音并保存到全局语音文件变量指定的文件名中,录音时间为5秒
audio.record(VOICE_FILE_NAME, 5)
# 播放录入的声音
audio.play(VOICE_FILE_NAME)
# 读取录音文件并赋值给变量voice_file
voice_data = read_file(VOICE_FILE_NAME)
# 调用百度语音识别方法,将语音识别为文字,并赋值给变量 result。
# asr方法中的参数为固定值,暂时可忽略
result = speech_client.asr(voice_data,'wav',16000,{'dev_pid': dev_pid})
# 从识别的结果中,获取识别的文本
# 由于百度语音识别完成后返回的数据比较多,我们只需要提取我们需要的文本即可
word = result.get('result',[])[0]
# 将转换的词语放进全局词语存储列表变量中
WORDS.append(word)
# 显示所有的词语
draw_voice_txt()
# 中文语音处理函数
def zh_voice_to_str():
voice_to_str(1537)
# 将中文语音处理函数绑定到中文录音按钮上,使按钮点击能完成相应操作
zh_voice_btn.config(onclick=zh_voice_to_str)
# 英文语音处理函数
def en_voice_to_str():
voice_to_str(1737)
# 将英文语音处理函数绑定到英文录音按钮上,使按钮点击能完成相应操作
en_voice_btn.config(onclick=en_voice_to_str)
# ======= 文字播放 =======
# 词语语音播放
def word_play():
# 全局引入语音文件名和词语存储列表
global WORDS
global VOICE_FILE_NAME
# 从全局词语存储列表中遍历获取每个词语
for word in WORDS:
# 调用百度语音识别,将文本转换成语音
voice = speech_client.synthesis(word, 'zh', 1, {'vol': 5})
# 判断百度识别的结果是否时声音文件
if not isinstance(voice, dict):
# 将声音文件存入全局语音文件变量中
write_file(VOICE_FILE_NAME, voice)
# 播放存储的声音文件
audio.play(VOICE_FILE_NAME)
# 将播放函数绑定到播放按钮上,使按钮点击能完成相应操作
voice_play_btn.config(onclick=word_play)
# ======= 拍照 =======
def take_photo():
# 引入全局照片文件存储变量
global PHOTO_FILE_NAME
# 使用OPENCV模块识别摄像头,参数为摄像头设备ID,默认为0,需要按实际情况调整
cap = cv2.VideoCapture(1)
# 创建一个名称为"camera"的窗口,用于显示图像
cv2.namedWindow('camera',cv2.WND_PROP_FULLSCREEN) #窗口全屏
# 循环显示摄像头回传的每一帧图像
while True:
# 读取摄像头视频帧图片,success 代表是否读取成功,img代表当前图像
success, img = cap.read()
# 判断是否读取成功,如果没有成功,继续循环并读取
if not success:
print("读入视频帧失败,请更改USB接口ID值")
continue
# 将读取的图像旋转90读,使行空板能正常显示图像
img = cv2.rotate(img, cv2.ROTATE_90_COUNTERCLOCKWISE)
# 将图像显示到窗口
cv2.imshow("camera", img)
# 图像停留1毫秒,该处功能使屏幕能持续保持,不会出现闪退
key = cv2.waitKey(1)
# 判断图像是否闪退,以及是否按了行空板 B 按钮
if key & 0xFF == ord('b'):
# 按了 B 按钮,将当前图像存储到文件变量中
cv2.imwrite(PHOTO_FILE_NAME, img)
# 拍照结束释放摄像头
cap.release()
# 清除所有的视频显示窗口
cv2.destroyAllWindows()
# 中段循环,使屏幕回到系统页面
break
# 将拍照函数绑定到行空板A键上
gui.on_a_click(take_photo)
# >>>>>>>>> 图像识别 <<<<<<<<<<
# 图像识别,并将结果显示到屏幕上
def ocr_handle():
# 引入全局图片存储变量和词语存储变量
global PHOTO_FILE_NAME
global WORDS
# 判断图片文件是否存在,如果不存在,则返回程序,不做图像识别操作
if not os.path.exists(PHOTO_FILE_NAME):
retrun
# 读取图片文件
image = read_file(PHOTO_FILE_NAME)
# 调用百度图像识别,识别图像中文字
res_image = ocr_client.basicAccurate(image)
# 获取识别结果中的多个词语
res_words = [i.get('words') for i in res_image.get('words_result')]
# 将识别的词语拼接成一个字符串,并用'\n'间隔,显示的时候会自动换行
ocr_words_txt = '\n'.join(res_words)
# 将拼接文本更新到结果文本框中
ocr_txt.config(text=ocr_words_txt)
# 将读入的词语拼接成一个字符串,并用'\n'间隔,显示的时候会自动换行
words_txt = '\n'.join(WORDS)
# 将拼接文本更新到录音文本框中
voice_txt.config(text=words_txt)
# 将图像识别函数绑定到显示结果按钮上,使按钮点击能完成相应操作
result_btn.config(onclick=ocr_handle)
# >>>>>>>>> 重新开始 <<<<<<<<<<
# 重新开始
def play_again():
# 调用函数,清空所有文本框
clear_txt()
# 引入全局变量 WORDS
global WORDS
# 将所有存储的朗读文本清除
WORDS = []
# 将重新开始函数绑定到重新开始按钮上,使按钮点击能完成相应操作
again_btn.config(onclick=play_again)
# 保存程序持续运行
while True:
time.sleep(1)
代码浏览(完全版)
Python
# python的os文件库,用户进行文件存储,读取,删除等操作
import os
# python时间库, 用于时间延时处理
import time
# python随机数库,用于随机排序词语
import random
# openCV库,用于处理视频和图像
import cv2
# unihiker库,用户行空板屏幕展示和声音处理
from unihiker import GUI, Audio
# 百度aip库,用于声音转文字,文字转声音,图片转文字处理
from aip import AipSpeech, AipOcr
# 实例化GUI类
gui = GUI()
# 实例化Audio类
audio = Audio()
# 用于保存词语数据
WORDS = []
# 设置词语数量
LENGTH = 7
# 定义录音文件存储名称
VOICE_FILE_NAME = 'voice.wav'
# 定义照片文件存储名称
PHOTO_FILE_NAME = 'photo.jpg'
# 定义语音识别默认语音, 1537代表中文
DEV_PID = 1537
# >>>>>>>>> 界面设计 <<<<<<<<<<
# 设置背景图片
background = gui.draw_image(w=240, h=320, image="bg.jpeg")
# 设置标题
title = gui.draw_text(x=120, y=0, color='red', font_size=12, text='中/英词语朗读听写系统',origin='top')
# 设置中文录音按钮
zh_voice_btn = gui.add_button(x=60, y=40, w=100, h=30, text="中文录音", origin='center', state='normal', onclick=None)
# 设置英文录音按钮
en_voice_btn = gui.add_button(x=180, y=40, w=100, h=30, text="英文录音", origin='center', state='normal', onclick=None)
# 设置消息提示文本
notice_txt = gui.draw_text(x=10, y=60, color='black', font_size=6, text=f'请读出最多{LENGTH}个中/英文词语并进行听写!', origin='top_left')
# 设置录音文本
voice_txt = gui.draw_text(x=60, y=80, color='red', font_size=10, text='', origin='top')
# 设置听写结果文本
ocr_txt = gui.draw_text(x=180, y=80, color='black', font_size=10, text='', origin='top')
# 设置播放按钮
voice_play_btn = gui.add_button(x=120, y=240, w=100, h=30, text='播放', origin='center', state='normal', onclick=None)
# 设置消息提示按钮
msg_txt = gui.draw_text(x=120, y=260, color='red', font_size=10, text='', origin='top')
# 设置重新开始按钮
again_btn = gui.add_button(x=10, y=320, w=100, h=30, text='重新开始', origin='bottom_left', state='normal', onclick=None)
# 设置查看成绩按钮
result_btn = gui.add_button(x=230, y=320, w=100, h=30, text='查看成绩', origin='bottom_right', state='normal', onclick=None)
# 百度语音识别设置
SPEECH_APP_ID = '27720455'
SPEECH_API_KEY = 'NSXS9gYnRfObgfGrzlplsrNZ'
SPEECH_SECRET_KEY = 'PRVFeohTgT3Fa8nbRjgAYoQnAxrRSUZ0'
speech_client = AipSpeech(SPEECH_APP_ID, SPEECH_API_KEY, SPEECH_SECRET_KEY)
# 百度图像识别设置
OCR_APP_ID = '25507845'
OCR_API_KEY = 'wURcKTV4xndQX6xjFM0ncYjl'
OCR_SECRET_KEY = 'n2RPpwEOReUrwnGFQA5QG2aQUQ1z7UaM'
ocr_client = AipOcr(OCR_APP_ID, OCR_API_KEY, OCR_SECRET_KEY)
# >>>>>>>>> 通用功能 <<<<<<<<<<
# 删除所有文本
def clear_words_text():
msg_txt.config(text='')
voice_txt.config(text='')
ocr_txt.config(text='')
time.sleep(0.5)
# 重新开始
def play_again():
global WORDS
WORDS = []
clear_words_text()
# 删除录音文件
def delete_file(file_name):
print('删除文件')
try:
os.remove(file_name)
except:
pass
# 读取文件
def get_file_content(filepath):
print('读取文件')
with open(filepath, 'rb') as f:
return f.read()
# >>>>>>>>> 语音转换功能 <<<<<<<<<<
# 声音转文字
def voice_to_text(voice_file, dev_pid=1537):
print('声音转文字')
res = speech_client.asr(get_file_content(voice_file), 'wav', 16000, {
'dev_pid': dev_pid,
})
print(res)
return res.get('result',[])[0]
def draw_voice_words_txt():
global WORDS
words_txt = '\n'.join(WORDS)
print(words_txt)
voice_txt.config(text=words_txt)
def translate():
global WORDS
global VOICE_FILE_NAME
global DEV_PID
# audio.record(VOICE_FILE_NAME, 5)
# 开始语音识别
msg = voice_to_text(VOICE_FILE_NAME, dev_pid=DEV_PID)
msg = msg.replace('。','')
audio.play(VOICE_FILE_NAME)
WORDS.append(msg + ' ')
print(WORDS)
# 随机排序
random.shuffle(WORDS)
draw_voice_words_txt()
# 录音操作
def voice_handle():
global WORDS
global VOICE_FILE_NAME
print('录音操作')
if len(WORDS) >= LENGTH:
msg_txt.config(text='录音已超出范围')
voice_synth('录音已超出范围', file_name='err_longe_words.wav')
return
audio.record(VOICE_FILE_NAME, 5)
msg_txt.config(text='录音完成')
gui.start_thread(translate)
def zh_voice():
print('点击了中文录音')
global DEV_PID
DEV_PID = 1537
msg_txt.config(text='开始中文录音')
gui.start_thread(voice_handle)
def en_voice():
print('点击了英文录音')
global DEV_PID
DEV_PID = 1737
msg_txt.config(text='开始英文录音')
gui.start_thread(voice_handle)
zh_voice_btn.config(onclick=zh_voice)
en_voice_btn.config(onclick=en_voice)
# >>>>>>>>> 语音播放功能 <<<<<<<<<<
# 语音合成及播放
def voice_synth(text, file_name=None):
print('语音合成及播放')
if os.path.exists(file_name):
audio.play(file_name)
return file_name
result = speech_client.synthesis(text, 'zh', 1, {'vol': 5})
if not isinstance(result, dict):
with open(file_name, 'wb') as f:
f.write(result)
audio.play(file_name)
def play_handle():
global WORDS
if not WORDS:
msg_txt.config(text='请先录入单词或成语')
voice_synth('请先录入单词或成语',file_name='err_no_words.wav')
return
msg_txt.config(text='开始播放录音')
voice_synth("现在开始播放", file_name='play_start_voice.wav')
time.sleep(2)
for i, w in enumerate(WORDS):
msg_txt.config(text=f'现在播放第{i + 1}个录音')
file_name = f'voice_synth_{i}.wav'
voice_synth(w, file_name=file_name)
delete_file(file_name)
time.sleep(2)
msg_txt.config(text='播放完成')
def play():
clear_words_text()
gui.start_thread(play_handle)
voice_play_btn.config(onclick=play)
again_btn.config(onclick=play_again)
# >>>>>>>>> 拍照功能 <<<<<<<<<<
def photo():
print('start photo')
global PHOTO_FILE_NAME
delete_file(PHOTO_FILE_NAME)
#False:不旋转屏幕(竖屏显示,上下会有白边)
#True:旋转屏幕(横屏显示)
screen_rotation = True
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) #设置摄像头图像宽度
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240) #设置摄像头图像高度
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) #设置OpenCV内部的图像缓存,可以极大提高图像的实时性。
cv2.namedWindow('camera',cv2.WND_PROP_FULLSCREEN) #窗口全屏
cv2.setWindowProperty('camera', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) #窗口全屏
status= False
while True:
success, img = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
if screen_rotation: #是否要旋转屏幕
img = cv2.rotate(img, cv2.ROTATE_90_COUNTERCLOCKWISE) #旋转屏幕
cv2.imshow("camera", img)
key = cv2.waitKey(1)
if key & 0xFF == ord('b'):
print('开始拍照')
cv2.imwrite(PHOTO_FILE_NAME, img)
cap.release()
cv2.destroyAllWindows()
msg_txt.config(text='拍照完成')
break
gui.on_a_click(photo)
# >>>>>>>>> 图像识别 <<<<<<<<<<
def ocr_handle():
global PHOTO_FILE_NAME
image = get_file_content(PHOTO_FILE_NAME)
options = {}
options["language_type"] = "CHN_ENG"
res_image = ocr_client.basicAccurate(image, options)
print(res_image)
res_words = [i.get('words') for i in res_image.get('words_result')]
print(res_words)
gui.start_thread(draw_voice_words_txt)
ocr_words_txt = '\n'.join(res_words)
print(ocr_words_txt)
msg_txt.config(text='成绩识别完成')
ocr_txt.config(text=ocr_words_txt)
result_btn.config(onclick=ocr_handle)
while True:
time.sleep(1)
问题及解决
• 行空板不能访问百度智能云
○ 需要查看是否设置好行空板的Wi-Fi
• 行空板只有一个USB接口,如何同时实现摄像头和耳机转换
○ 需要一个USB HUB做转换
• 百度ocr用标准版识别准确度不高,如何解决
○ 换成高精度版。代码由
Python
client.basicGeneral(image)
换成
Python
client.basicAccurate(image)
○ 但也有可能还是会有不准确的情况,这个无法百分百解决
• 有时候函数里的全局变量无法赋值
○ 需要用 global 显式调用一下,函数的作用域会和全局不一样,特别对于行空板已封装了tk的情况下,容易出现问题
• 为什么会有中文录音和英文录音2个按钮
○ 百度云语音识别功能普通话中文和英语时不同的识别方式,可以综合起来判断,但效果可能不好。所以做了显式的选择
• 为什么播放的时候好像没说完就停了
○ 智能语音问题,可以在录音转文字时在文字后面多加几个空格符
• 为什么用的A,B键来拍照
○ 用函数的方式没实现成功
○ 按钮太多,影响页面布局
• 为什么摄像头连接正常,但是运行时会报错
○ 主要问题在于openCV调用摄像头时,会有一个设备连接ID,随着行空板的开关机和USB的插拔,这个ID会变化,导致代码中写入的固定ID与实际摄像头ID不一致,摄像头识别失败导致。
○ 在该行代码中
Python
cap = cv2.VideoCapture(1)
括号中的数字 1, 即为固定的摄像头连接ID。


 他的勋章
他的勋章

评论