 返回首页
返回首页
 回到顶部
回到顶部
一、背景
语音识别技术作为人机交互的核心入口,已深度融入现代生活。
从智能手机的语音助手到智能家居的语音控制系统,语音交互以其自然、直观的特性,成为人们获取信息、操控设备的重要方式。
随着深度学习技术的突破,语音识别的准确率与响应速度持续提升,越来越多的应用场景被挖掘和覆盖,语音交互正在重塑人机沟通的边界。
二、面临的问题
2.1 方言识别技术尚未成熟
当前主流语音识别系统(如讯飞、百度、阿里)在标准普通话场景下准确率可达97%以上,但在方言场景下表现断崖式下滑。
据相关研究显示,普通话词错误率(WER)平均仅为2.8%,而粤语达6.5%、吴语达9.2%、闽南语更是高达12.7%。
部分小众方言的识别错误率甚至超过60%,严重制约了智能语音产品在基层政务、老年服务等关键场景的规模化应用。
2.2 老年群体使用智能设备困难
我国60岁以上人口占比已超18%,但仅30%的老年人能独立使用智能手机完成基础操作。在语音交互场景中,65岁以上用户语音指令识别失败率高达42%,是青年群体的3.6倍。
深圳一项调研发现,78%的老人因找不到智能空调的物理开关而放弃使用,部分老人直言"电视语音总听不懂我的话,每次说'请再说一遍',我都觉得自己像个傻子"。
2.3 潮汕话识别的特殊挑战
潮汕话属于闽南语方言的一支,使用人口超千万,但由于以下特性,在ASR开发上面临独特挑战:
· 声调复杂:潮汕话拥有8个声调,远多于普通话的4个声调,连读变调规则繁复
· 方音多样:潮汕三市(汕头、潮州、揭阳)各地区口音差异明显,存在"十里不同音"的现象
· 文白异读:潮汕话存在文读、白读、"普读"三种读音并存的复杂情况
· 语料稀缺:相比普通话和粤语,潮汕话的高质量标注语料严重不足
此外,潮汕话使用者多集中在家庭、乡村等高噪声、低信噪比场景,而现有抗噪技术多针对普通话频谱特性设计,进一步增加了识别难度。
三、数据采集与模型训练
针对上述问题,本项目提出基于自训练模型的潮汕话语音识别方案,采用"采集—训练—部署"三阶段技术路线,实现针对特定用户群体的定制化语音识别系统。
3.1数据采集与标记
首先新建一个分类,在模型部署后,识别过程中可以直接反馈识别的名称
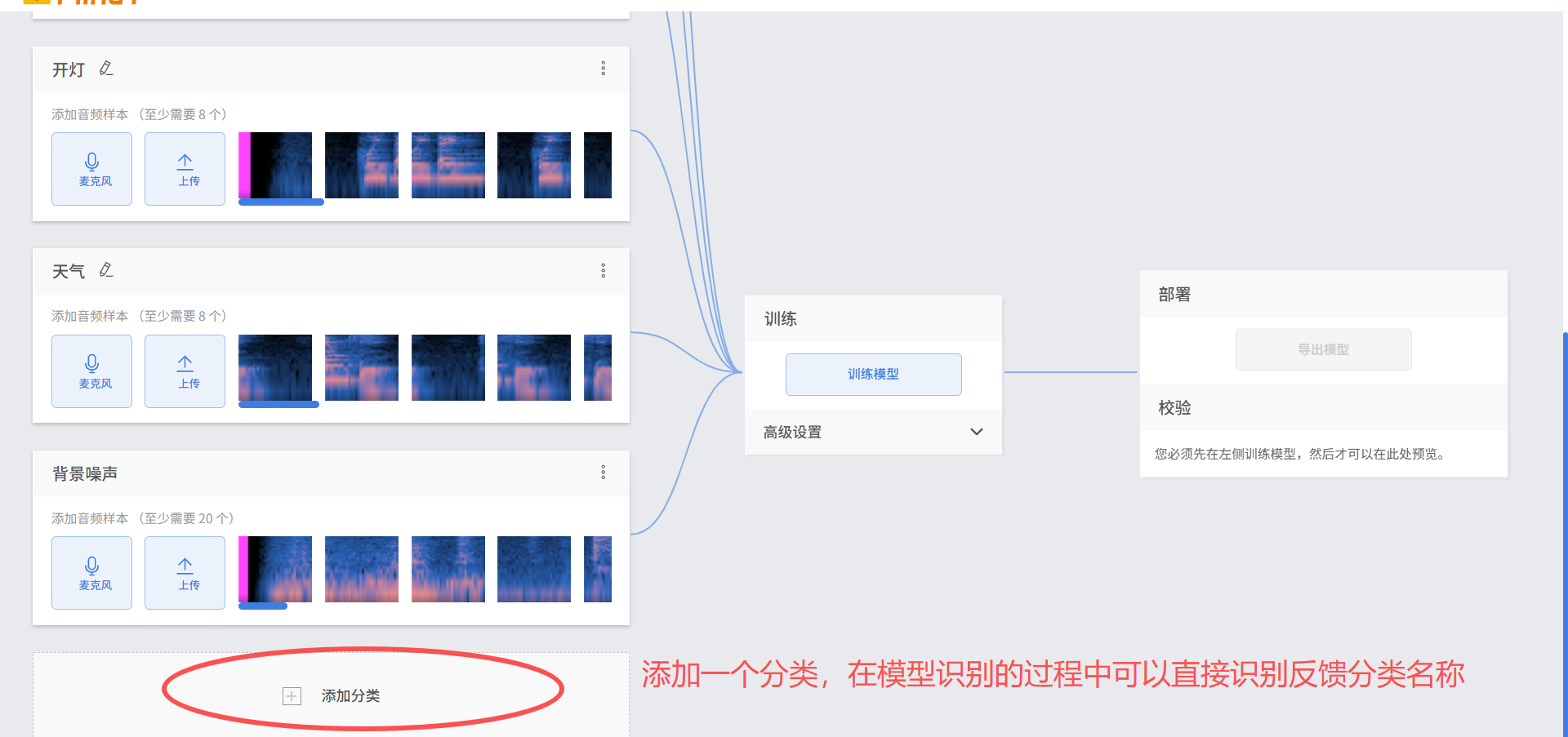
使用自带的录音功能,可以录制音频
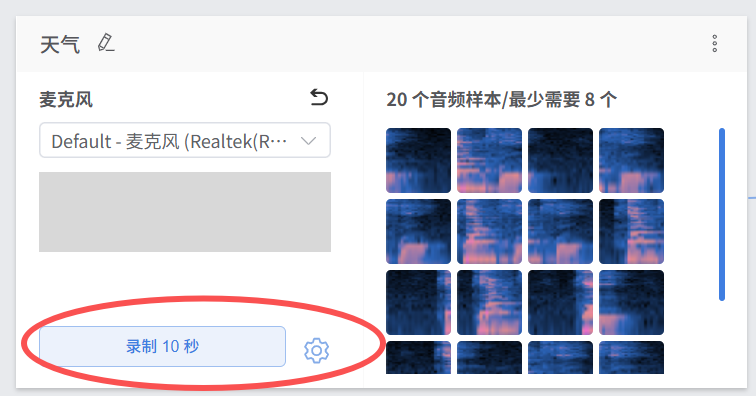
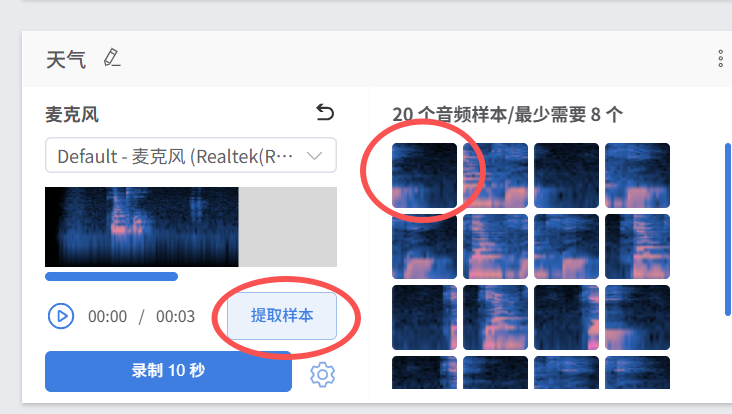
录制完成后,可以提取样本,并且对样本进行筛选
各个分类采集后,可以对模型开始训练,理论上训练的轮数更多,模型准确率更高。
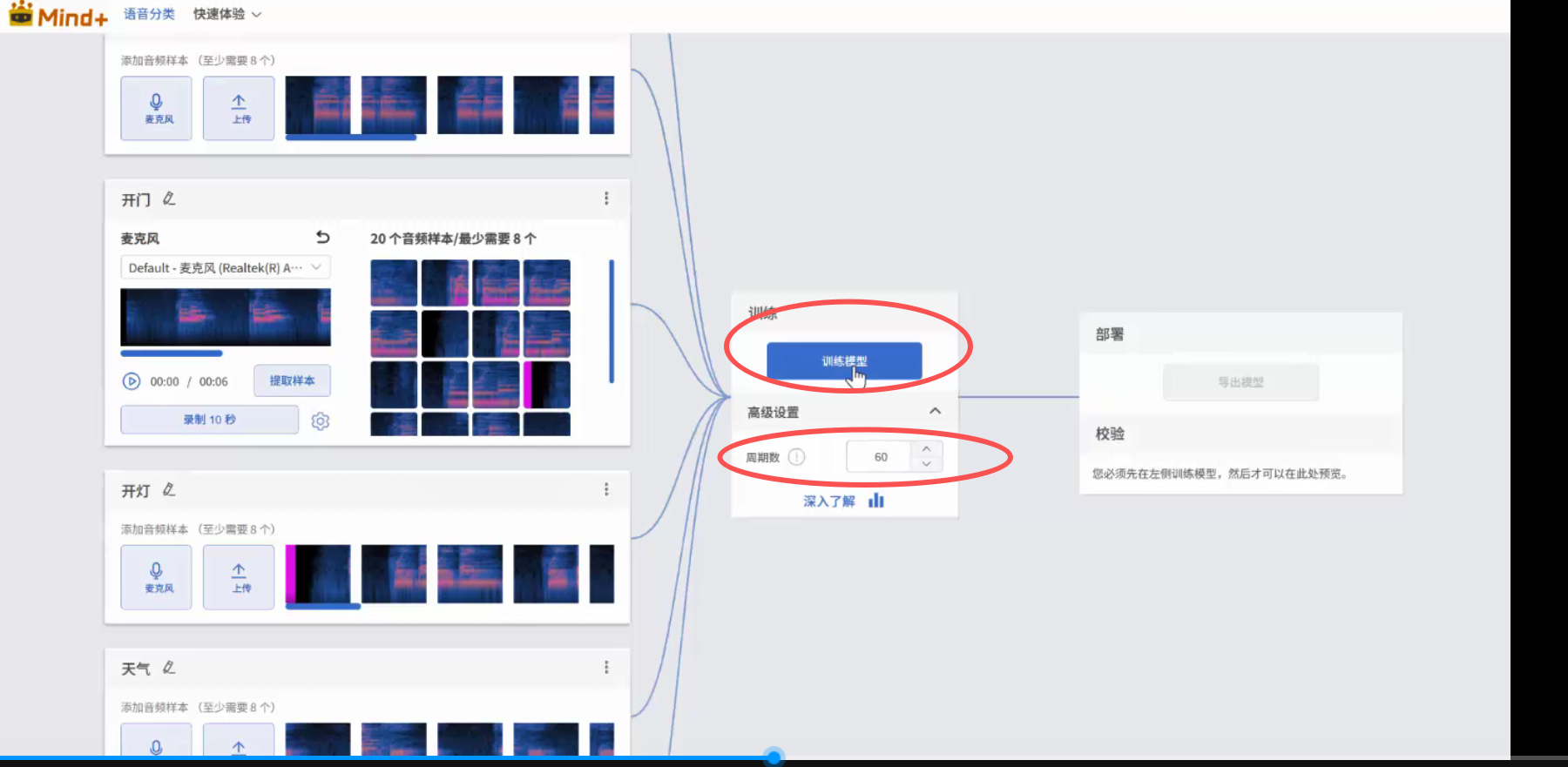
当准确率达到0.8以上,则说明模型训练有效
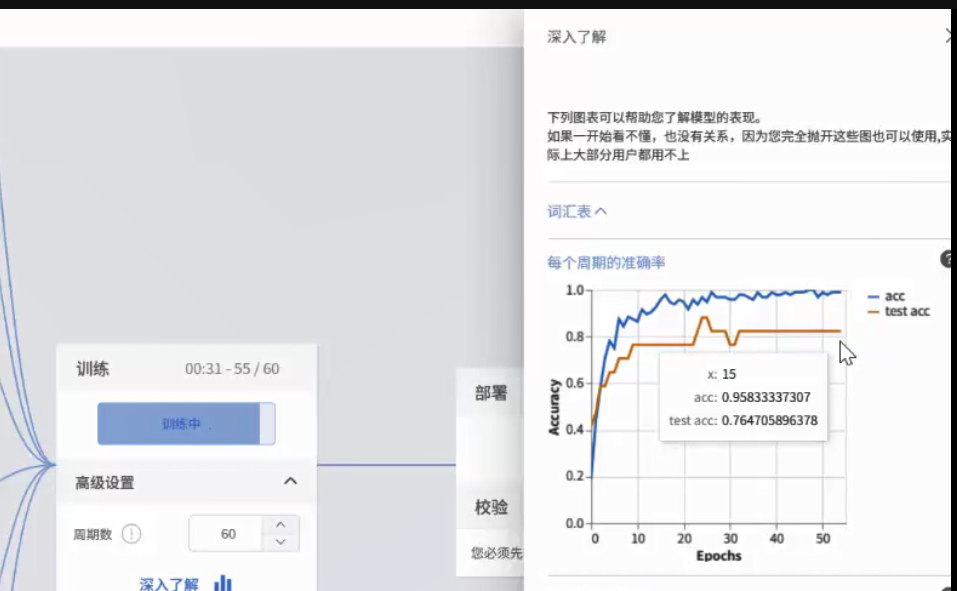
训练完成可以进行校验,没问题可以导出模型或者通过物联网实时推送结果
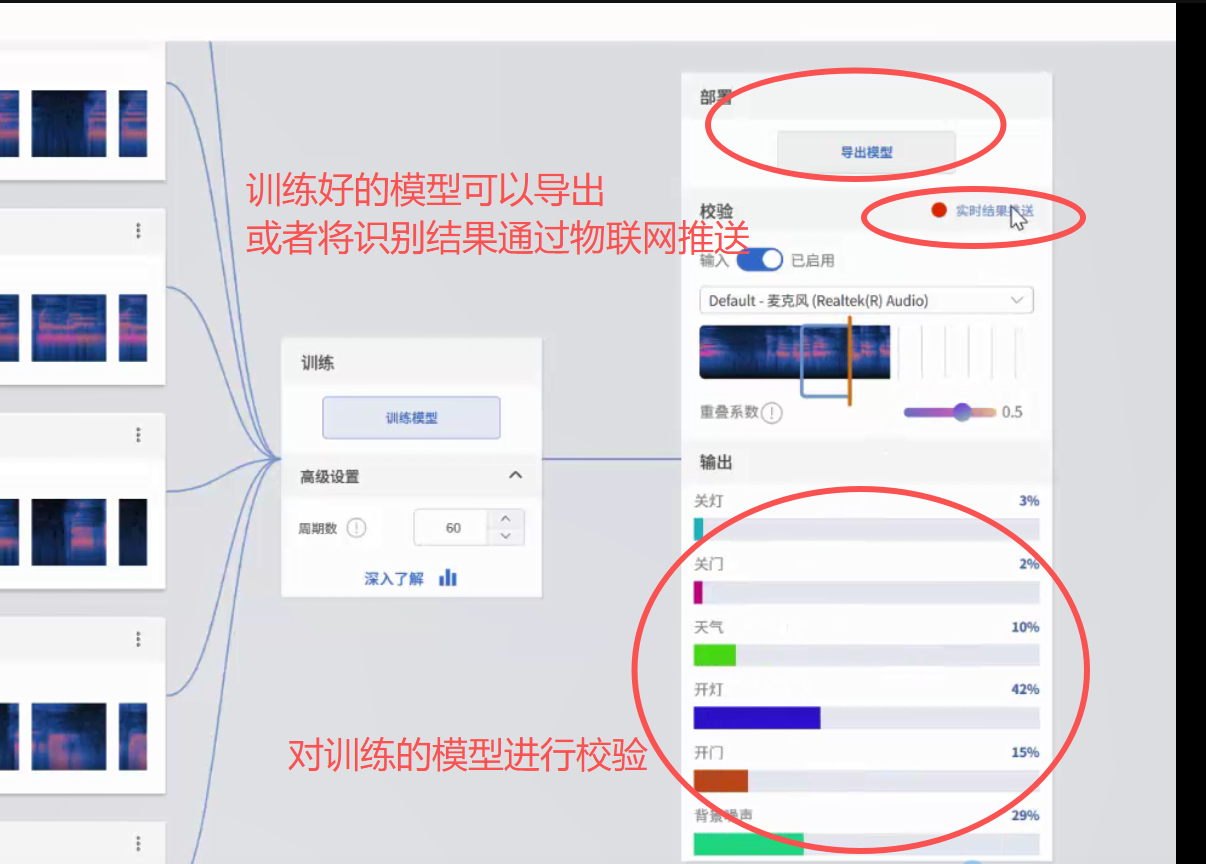
四、硬件部署
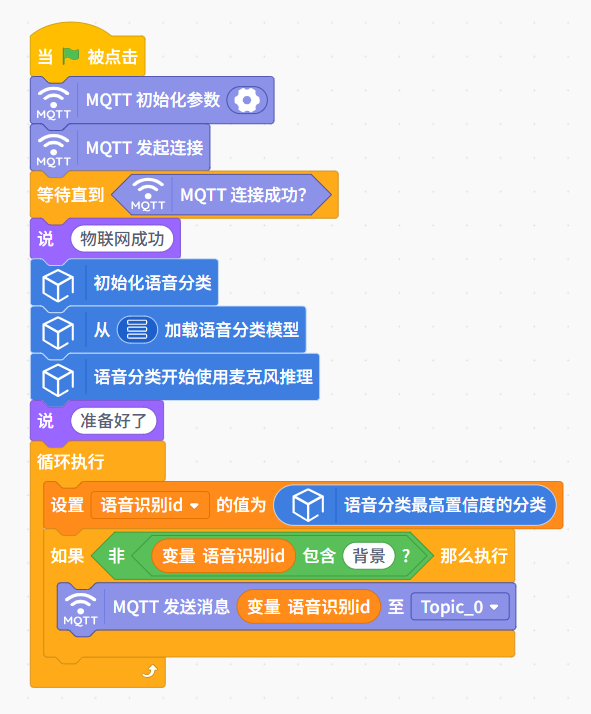
使用训练好的模型对k10实现控制,但是k10无法部署训练好的模型,目前使用实时模式进行识别对k10实现控制。
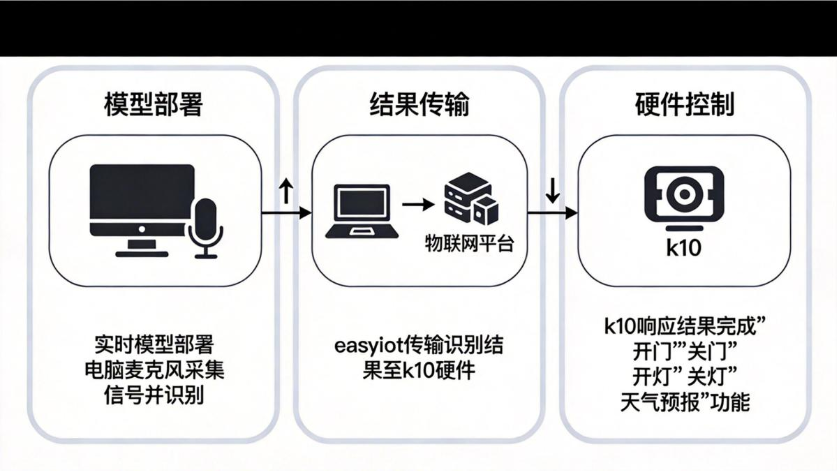
实时模式识别语音
k10完成响应
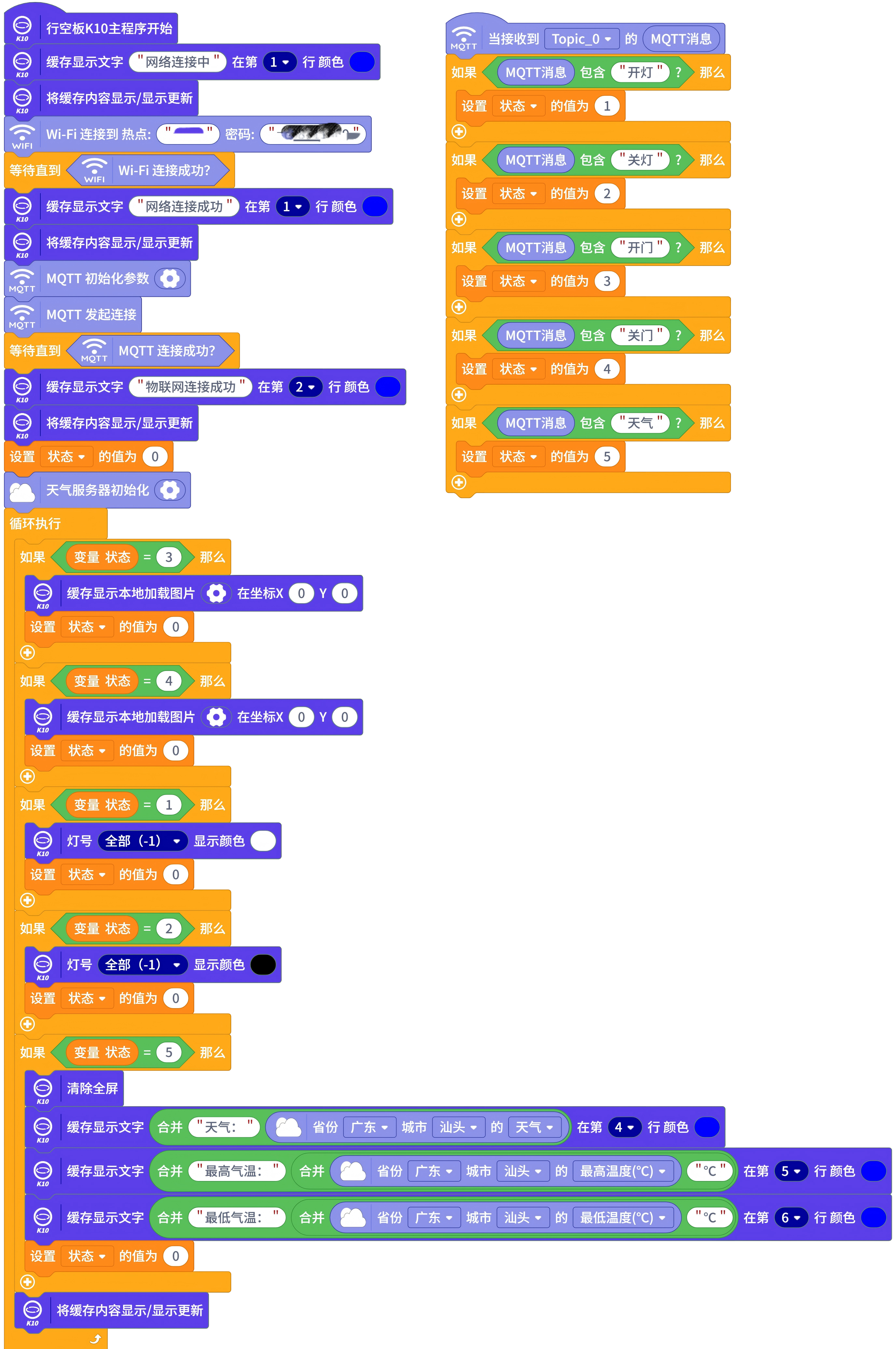
五、效果展示
总结
本项目提供了一种方言识别模型的实践过程,使用mind+开展模型训练与部署很方便也很适合用来开展人工智能教学。
后期探索用m10部署模型,实现统一硬件实现识别与响应。


 他的勋章
他的勋章

评论