 返回首页
返回首页
 回到顶部
回到顶部

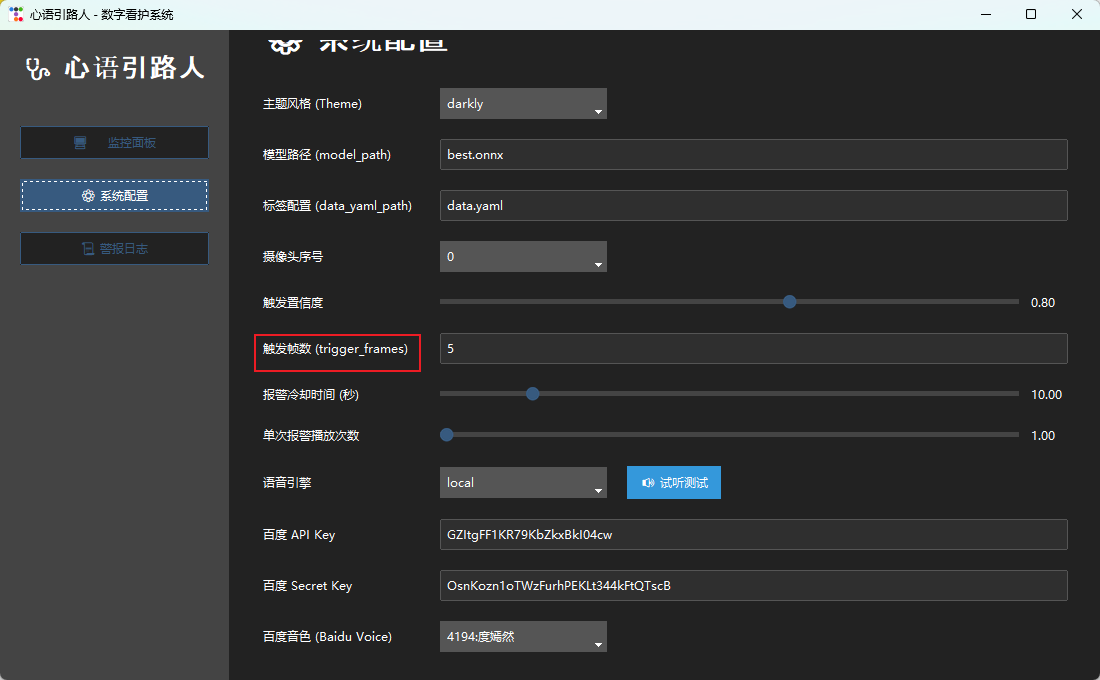
一、 项目背景与创意初衷
在我们的生活中,有一群常被忽视的“失语者”——可能是早期的渐冻症(ALS)患者、中风偏瘫导致言语障碍的长者,亦或是重症监护室里气管插管的病人。他们大脑清醒,却因为失去语言能力或严重的肢体无力,连最基本的“我想喝水”、“我哪里痛”都无法表达。传统的按键式呼叫器他们按不动,而专业的眼动仪设备又极其昂贵,难以进入普通家庭。
“心语引路人”项目应运而生。它旨在将AI技术平民化、温情化。通过电脑摄像头,捕捉患者仅存的微小动作(如眨眼、转头),将其转化为清晰的语音提醒和全屏大字报,不仅让失语者“说”出心声,更让看护者重获安心。
二、 系统架构与工作原理
本项目基于 Python 开发,高度集成 Mind+ V2 的 AI 训练能力,构建了一套高效、低时延的端侧推理系统。本项目为纯软件项目,零硬件门槛,易于普通家庭部署。
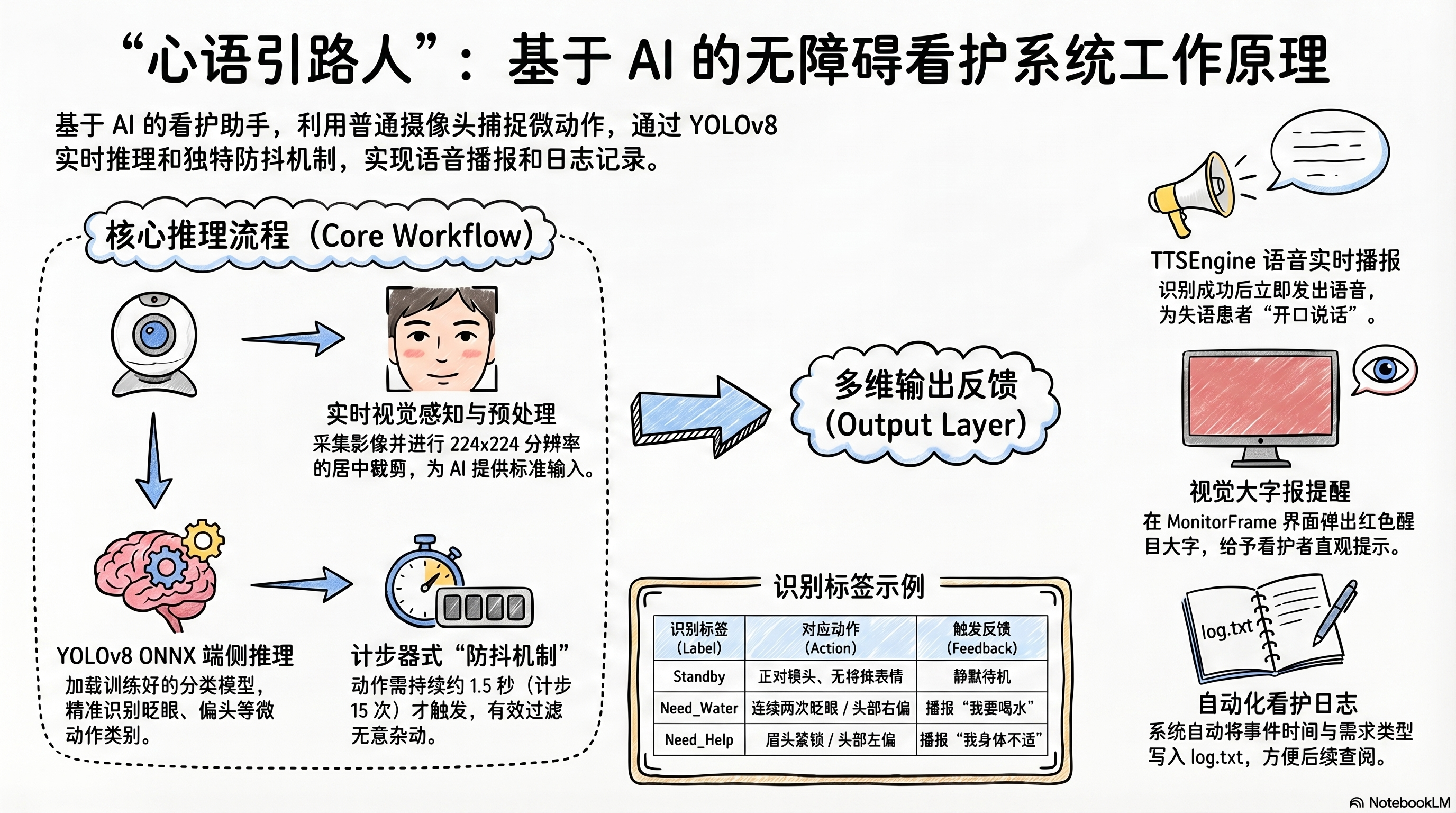
通过分层设计和多线程隔离,实现了UI响应、视频处理和AI推理的并行执行,避免了相互阻塞,确保系统"丝滑"运行。

核心工作流
整个流水线实现了从图像采集→AI推理→逻辑判断→用户反馈的闭环,确保端侧实时响应的毫秒级性能。
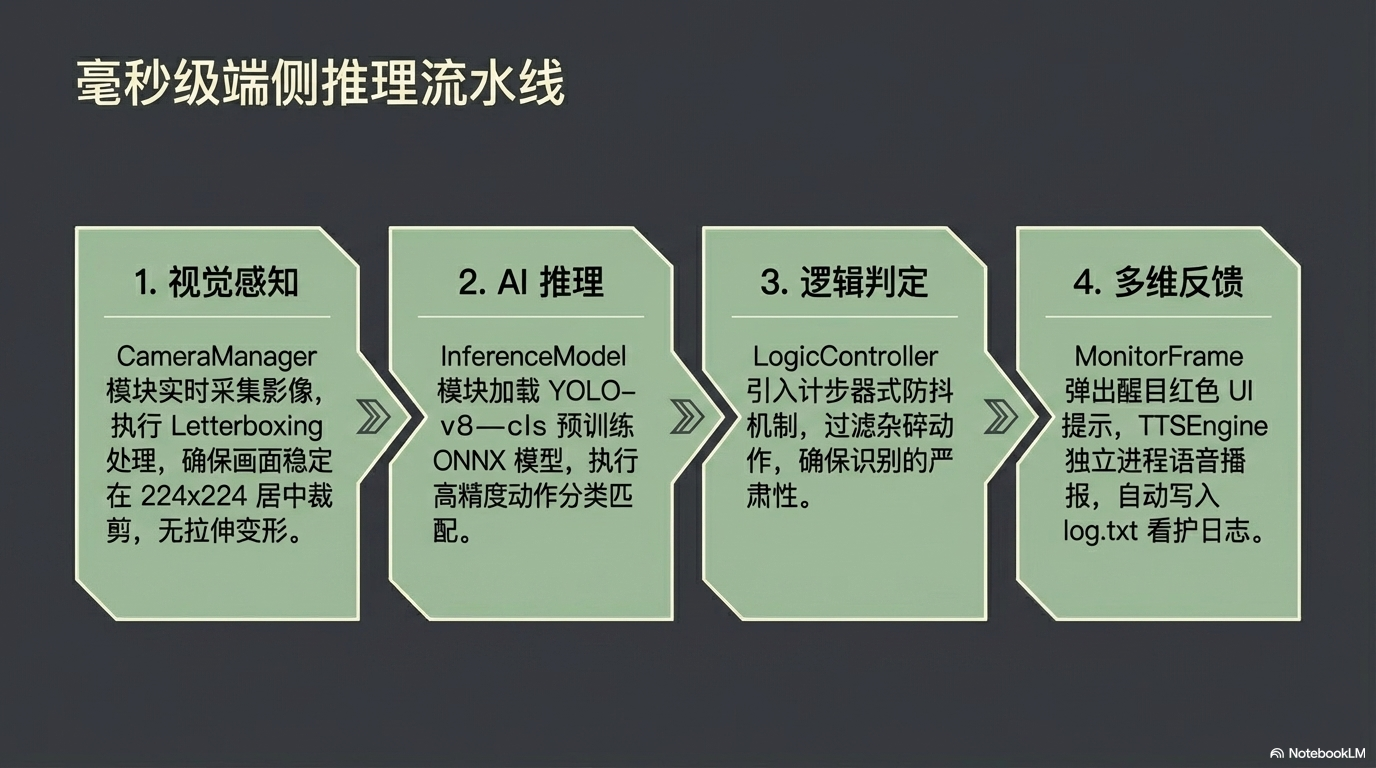
系统架构图
三、 软硬件清单
硬件:
- 1. 普通 Windows 电脑 / 平板(需带摄像头)。
- 2. 外置 USB 摄像头(支持 DirectShow 协议效果更佳)。
软件与库:
- 1. Mind+ V2.0:项目核心开发环境。
- 2. Python 3.10+。
- 3. ttkbootstrap:构建高颜值的深色模式 GUI 界面。
- 4. ONNX Runtime:高性能端侧推理引擎。
- 5. OpenCV & Pillow:图像处理引擎。
四、 AI 模型训练过程
本项目采用了 Mind+ V2 内置的“图像分类”训练工具。
步骤1 标签设计与定义
为了确保准确率并适应卧床患者的微小动作,我设计了 4 个分类标签:
Standby (平静待机):脸部正对镜头,无特殊表情。
Need_Water (需要喝水):连续两次明显的眨眼(或头部向右偏转)。
Need_Help (身体不适/需要翻身):眉头紧锁(或头部向左偏转)。
Blank (无人状态):镜头内无患者。
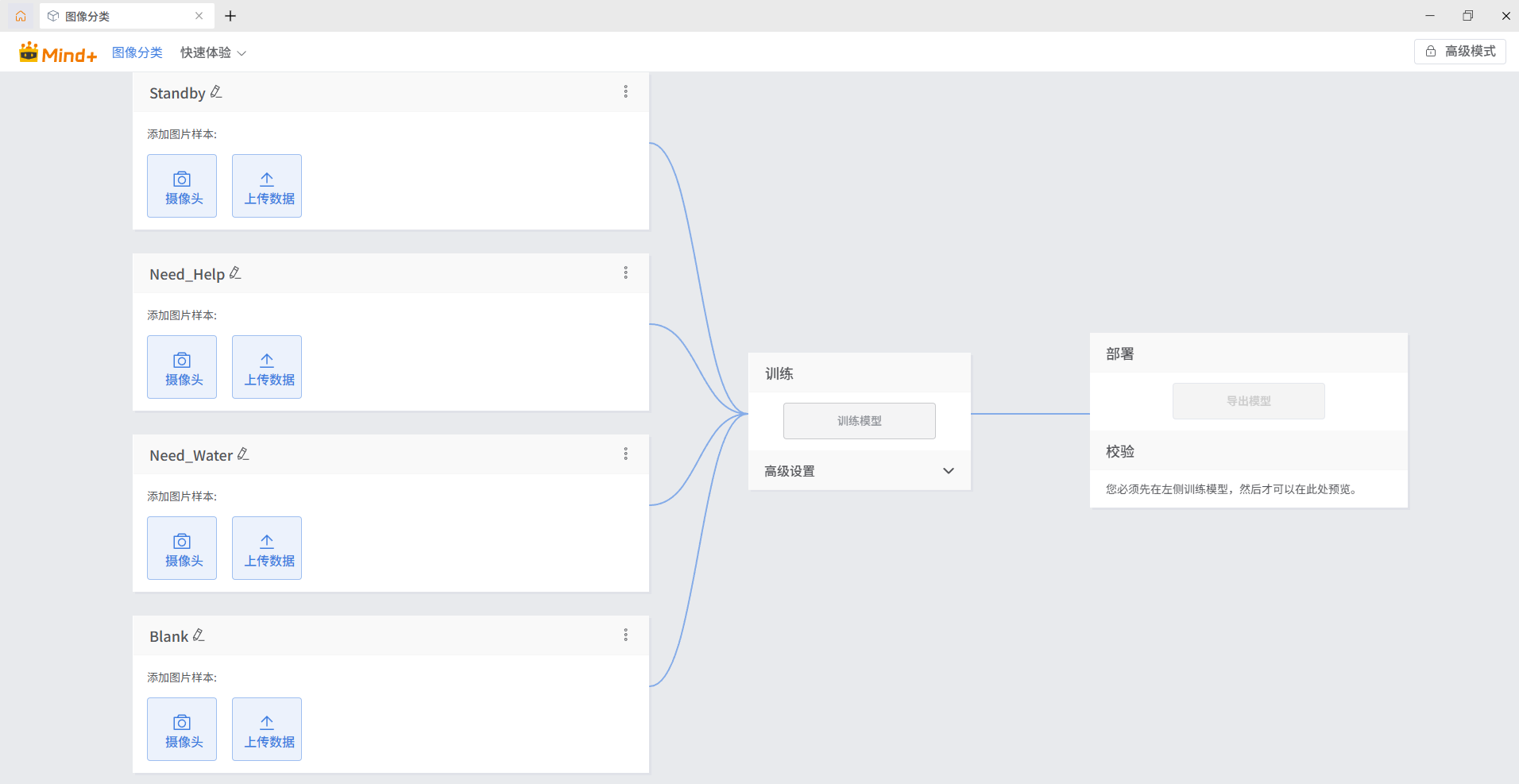
步骤2 样本采集策略
为了保护患者隐私并获取极端视角下的高质量样本,本项目创新地采用了基于 Prompt 驱动的 豆包AI文生图功能生成四种状态的患者图片来训练模型。
考虑到患者一般处于卧床状态,样本采集时特意模拟了仰卧视角的摄像头角度。每个动作标签录入至少 200 张图片。引入了光线变化(开灯、关灯、自然光)以增强模型的泛化能力,防止傍晚时分识别率下降。
步骤3 模型训练与参数设置
在 Mind+ V2 模型训练界面,选择“图像分类”算法。训练轮数(Epochs):设置为 30(避免过拟合)。学习率(Learning Rate):保持默认设置。
点击训练后,观察 Loss 曲线平滑下降并收敛,最终模型验证准确率达到 95% 以上。
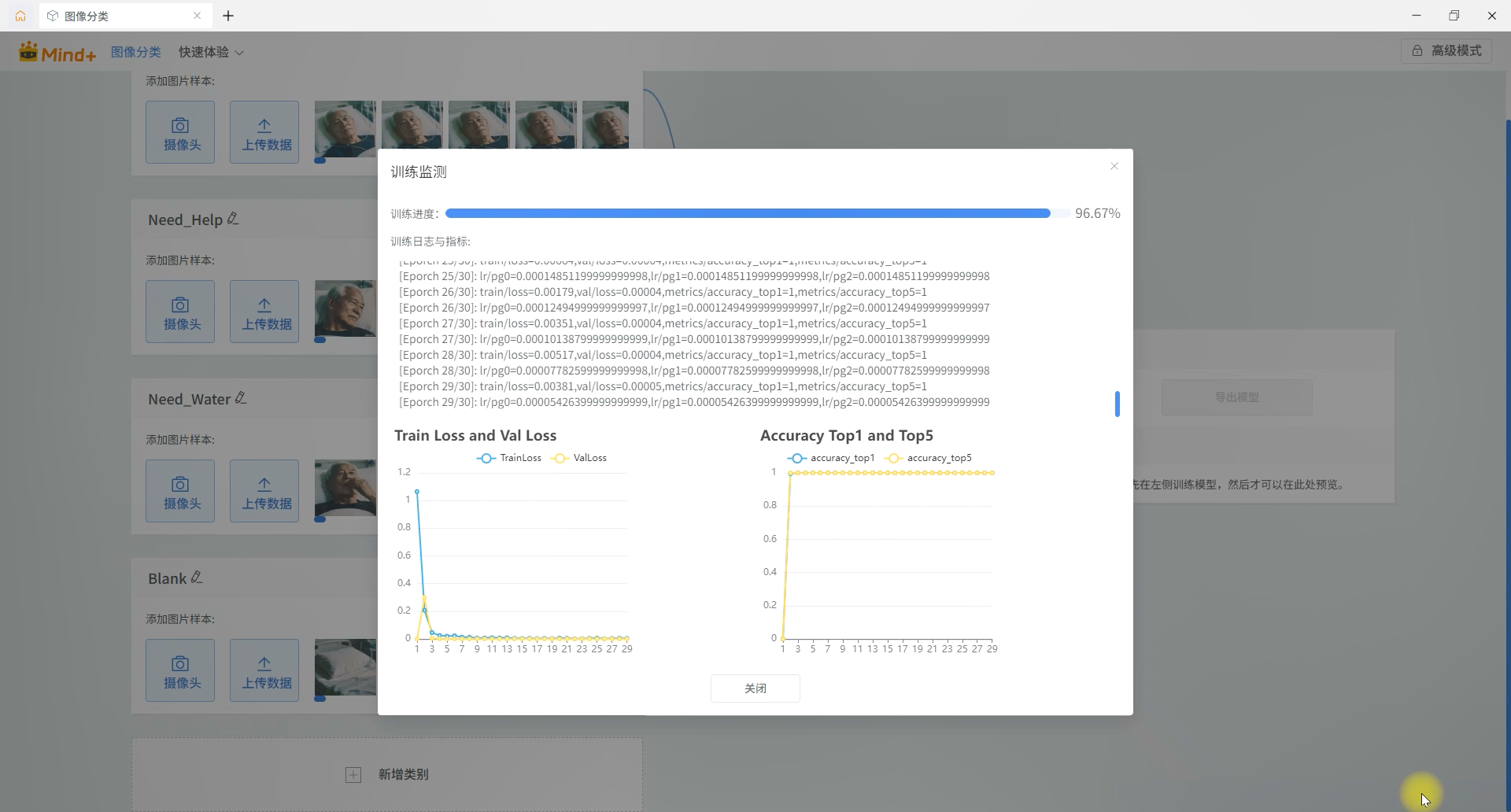
随后校验模型准确率,并导出模型文件 Experience_model.zip,准备在主程序中调用。
五、 核心逻辑与代码实现
(一)逻辑流设计
初始化:开启摄像头,加载训练好的模型,加载 TTS(文字转语音)和文件读写扩展库。
实时循环:每隔 0.1 秒进行一次画面推理。
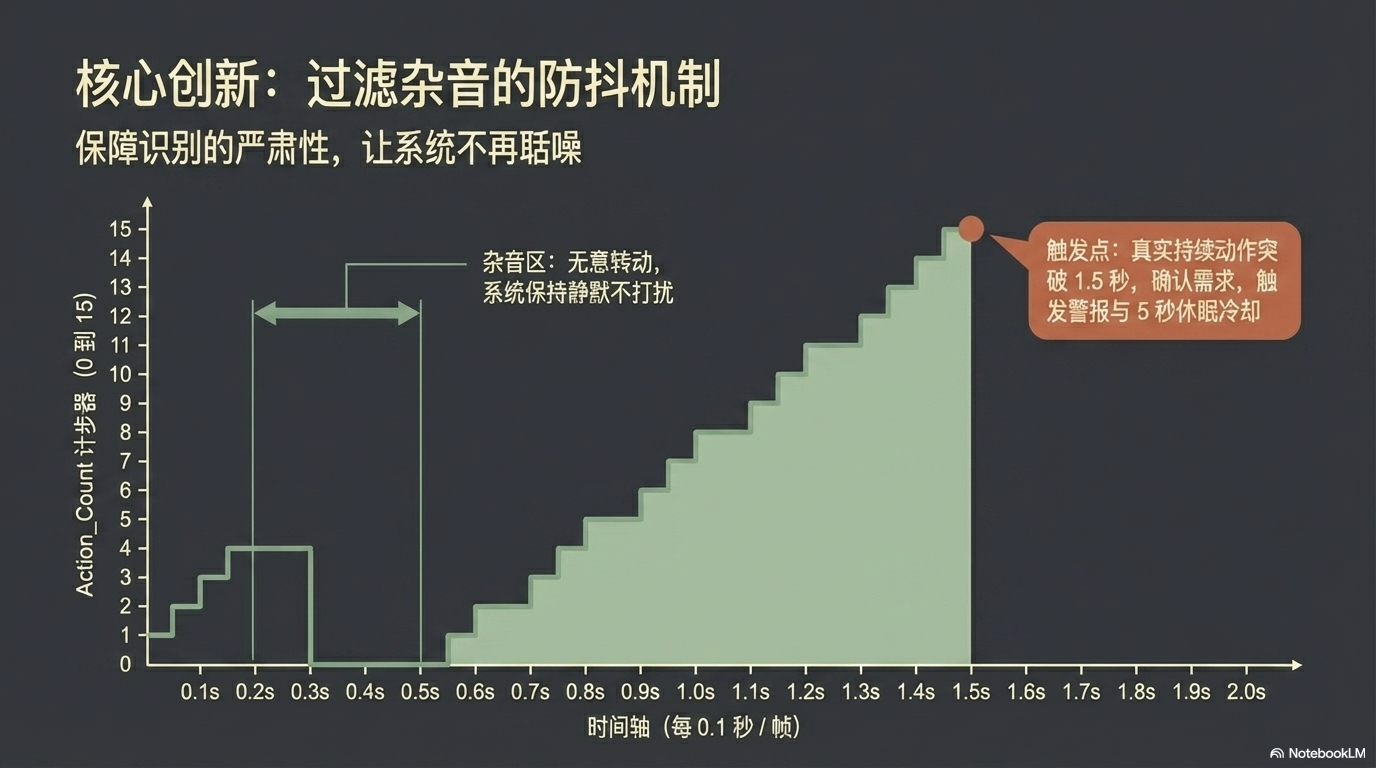
计步器防抖(关键):
设置一个变量 Action_Count。
当识别到 Need_Water 且置信度 > 80% 时,Action_Count 增加 1。
若识别回 Standby,Action_Count 清零。
只有当 Action_Count 连续达到 5 次(即动作持续一定帧数) 时,才真正触发播报逻辑。
执行输出:
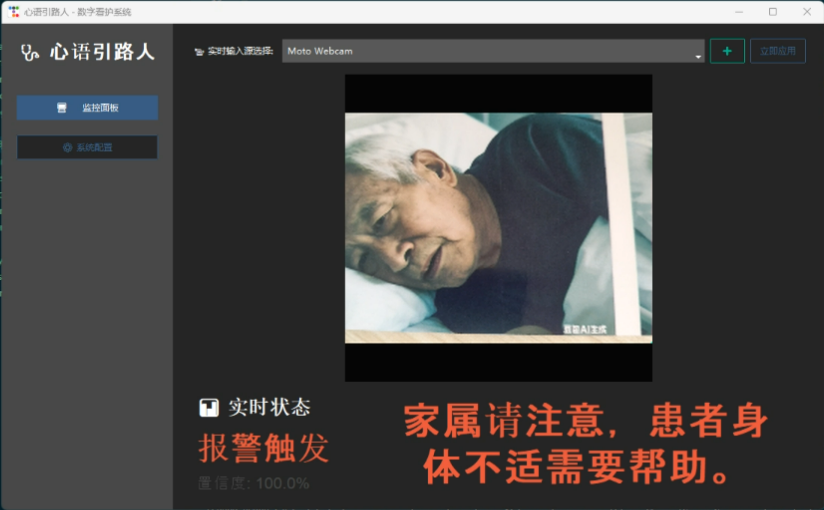
语音播报:“家属请注意,患者需要喝水。”
屏幕全屏显示醒目红色大字:“我要喝水”。
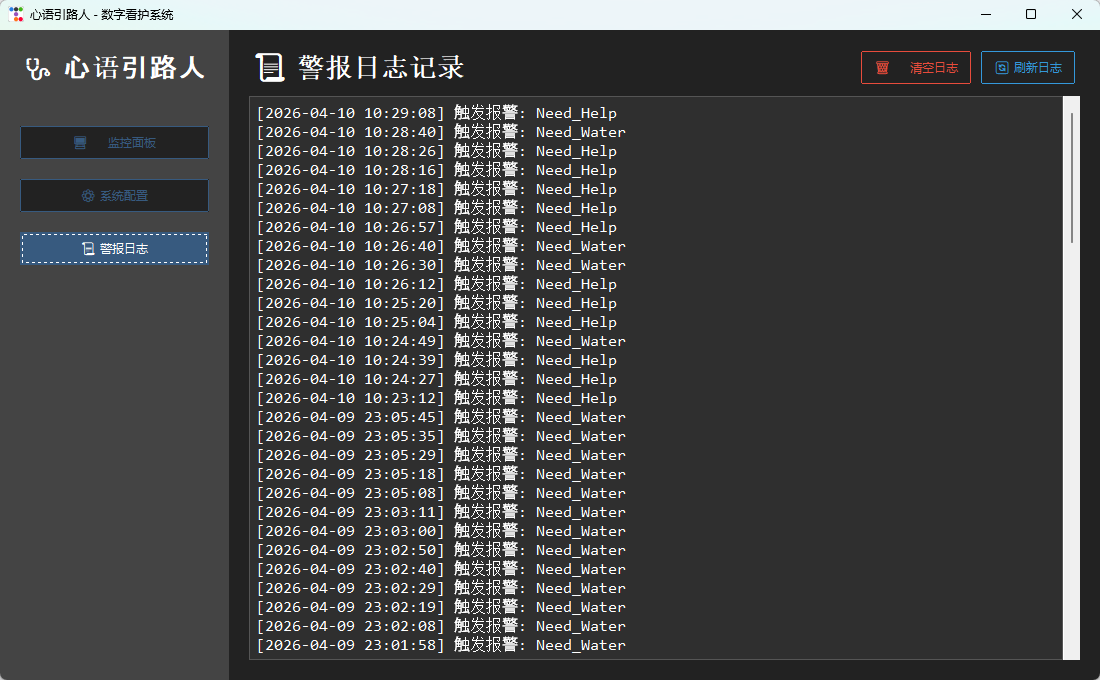
利用文件操作模块,将 [系统时间] + [需求类型] 写入本地 log.txt 中。
执行完毕后,强制系统休眠 5 秒(冷却时间),防止重复触发。
(二)代码实现
为了提高作品的“鲁棒性”,我在代码中实现了以下技术细节:
1. 稳定的图像预处理
为了不让图像拉伸变形影响 AI 识别,系统会自动进行 Letterboxing 处理,将画面维持在 224x224。
# inference.py 代码片段 保持高宽比缩放
if frame is not None:
try:
# 保持高宽比缩放 (Letterboxing)
h, w = frame.shape[:2]
target_w, target_h = self.target_size
scale = min(target_w / w, target_h / h)
nw, nh = int(w * scale), int(h * scale)
# 缩放图像
resized = cv2.resize(frame, (nw, nh))
# 创建黑色画布
canvas = np.zeros((target_h, target_w, 3), dtype=np.uint8)
# 居中放置
dx = (target_w - nw) // 2
dy = (target_h - nh) // 2
canvas[dy:dy+nh, dx:dx+nw] = resized
frame_rgb = cv2.cvtColor(canvas, cv2.COLOR_BGR2RGB)
with self.lock:
self.current_frame = frame_rgb
except Exception as e:
print(f"帧处理失败: {e}")
time.sleep(0.01)2. 精准的防抖逻辑
本项目的核心难点在于“防误触机制(防抖)”。患者可能会无意间转头或眨眼,如果一识别到就播报,会让系统变得极其聒噪。
# logic_controller.py 核心片段
if confidence >= threshold and label != "Standby":
if label == self.last_label:
self.action_count += 1
else:
self.action_count = 1
self.last_label = label
# 连续 15 帧(约1.5秒)稳定识别才触发,避免误报
if self.action_count >= trigger_frames:
self._trigger_alarm(label)3. 多线程安全
通过多线程分离视频流读取与 AI 推理,确保 GUI 界面丝滑不卡顿,操作体验流畅。
六、 作品演示
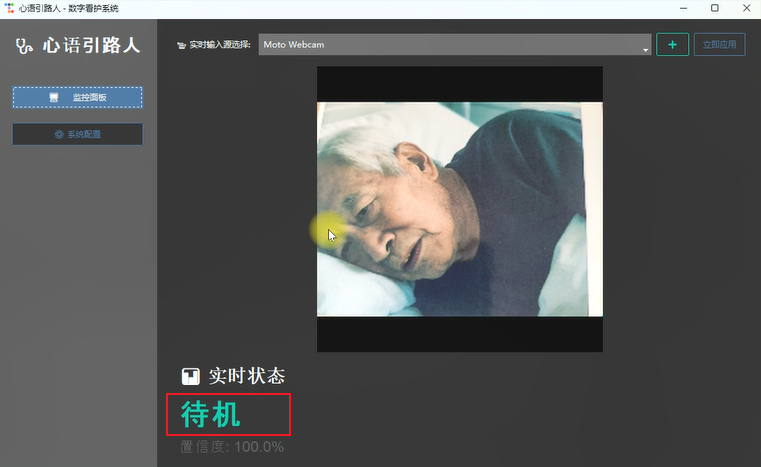
场景 1:日常待机。
场景 2:需求触发。
场景 3:数据记录。
七、 项目总结与未来扩展
项目总结:
本项目没有堆砌复杂的硬件,而是将力气花在了对“卧床看护”这一痛点场景的深度挖掘上。借助 Mind+ V2 极低门槛的模型训练能力,让原本只有高阶程序员才能完成的定制化 AI 辅助沟通系统,变成了人人皆可快速部署的数字看护助手。
未来扩展思考:
1.接入物联网:下一步可加入 SIoT 模块,将呼叫信息直接推送到家属手机或智能手表,突破空间的限制。
2.结合姿态检测:未来可叠加 Mind+ 的“人体骨骼关键点检测”模型,用于监测患者是否发生坠床等意外,进一步提升看护全面性。


 他的勋章
他的勋章
木子哦2026.04.14
很棒!
火星涛2026.04.15
谢谢大佬肯定!🤝 谢谢您的鼓励