 返回首页
返回首页
 回到顶部
回到顶部
作为一名一线老师确实有点忙,虽然二哈首发的当晚就下单了,但是一直没有去认真试用一下。购买二哈二代的主要原因是看中了它可以部署自训练模型,但是由于软件生态没有跟上,过去较长一段时间,部署自训练模型的功能还没有实现,后面参与了此次活动,发现已经可以部署自训练模型了,就赶紧试试。下面以生鲜识别为例,分享一下我的试用历程。
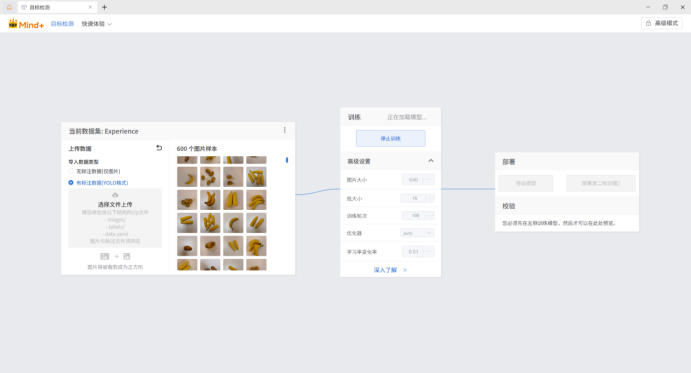
1.制作生鲜数据集。我采集了600张土豆、香蕉、玉米的图片,每类各200张,按照80%训练集,20%验证集的比例进行划分。然后导入Mind+2.0二代进行标注,当然由于Mind+2.0的目标检测功能基于YOLOv8n实现,所以也可以使用labelimg这样的软件来制作YOLO格式数据集。使用Mind+2.0标注感觉还是非常方便的,做完数据集后可以导出,方便以后在其它场景下使用。

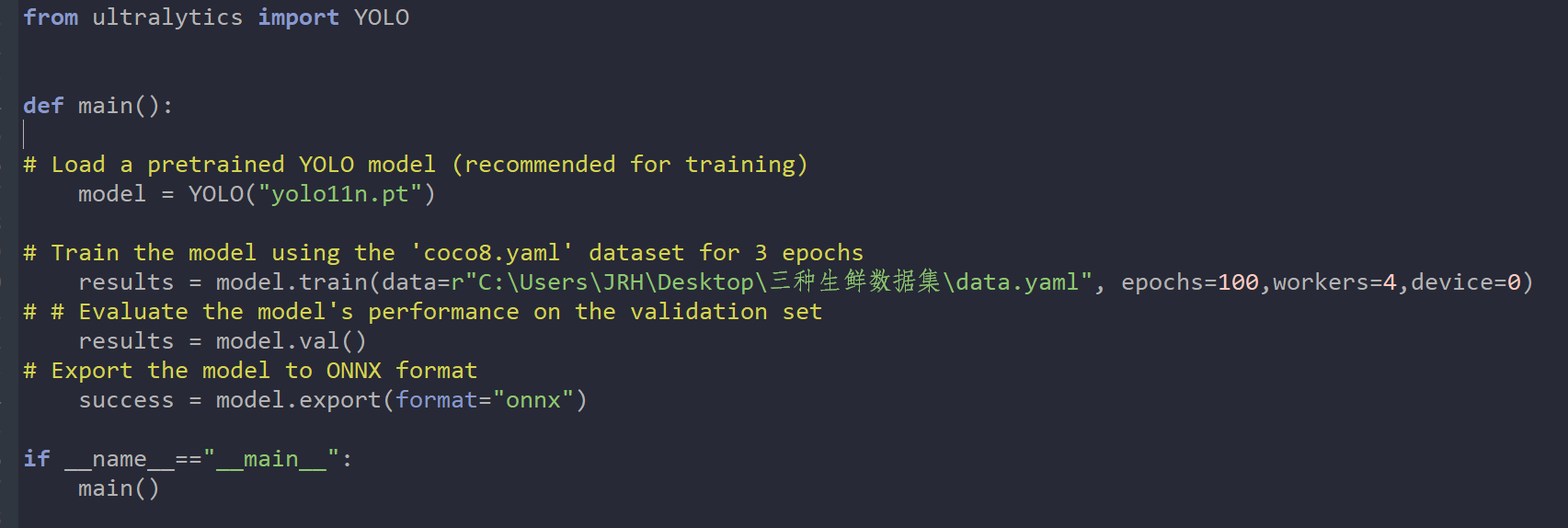
2.进行生鲜识别模型训练。将做好的数据集导入,然后设置好参数就可以开始训练了。这里将尺寸设为640,因为图片预处理为640X640。但是显然Mind+2.0是不支持GPU训练的,因为这依赖于CUDA、cuDNN和相应GPU版本的Pytorch,用户的电脑显卡五花八门,甚至很多都没有显卡,最好的方式自然就是默认使用纯CPU进行训练,但这样带来的问题就是速度太慢了。在我的办公老电脑上试了一下,600张图片的数据集训练100轮次需要训练4个多小时(CPU为古董级锐龙2200G),所以建议还是果断使用GPU进行训练。
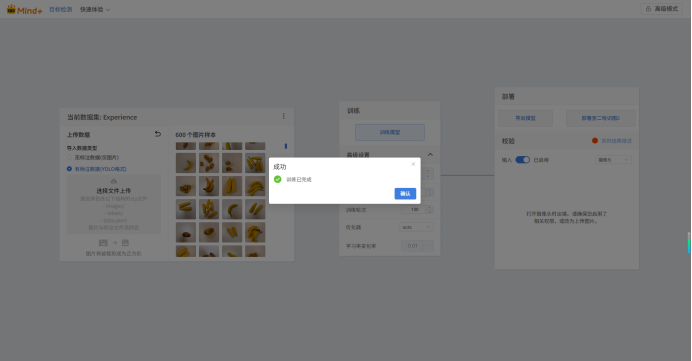
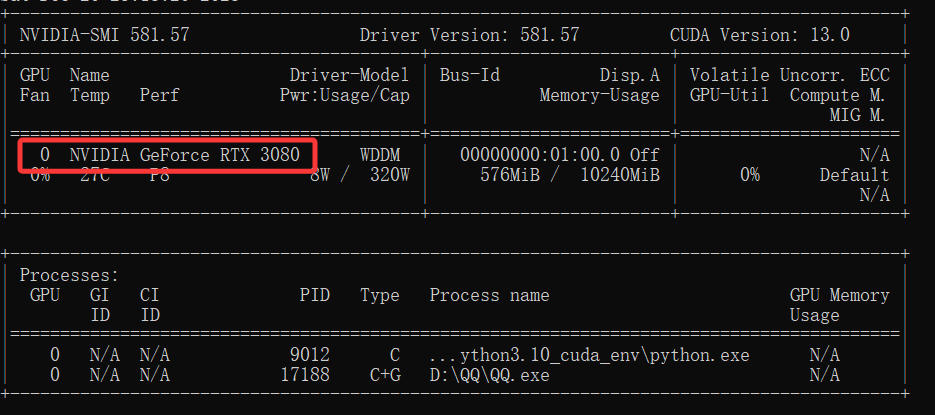
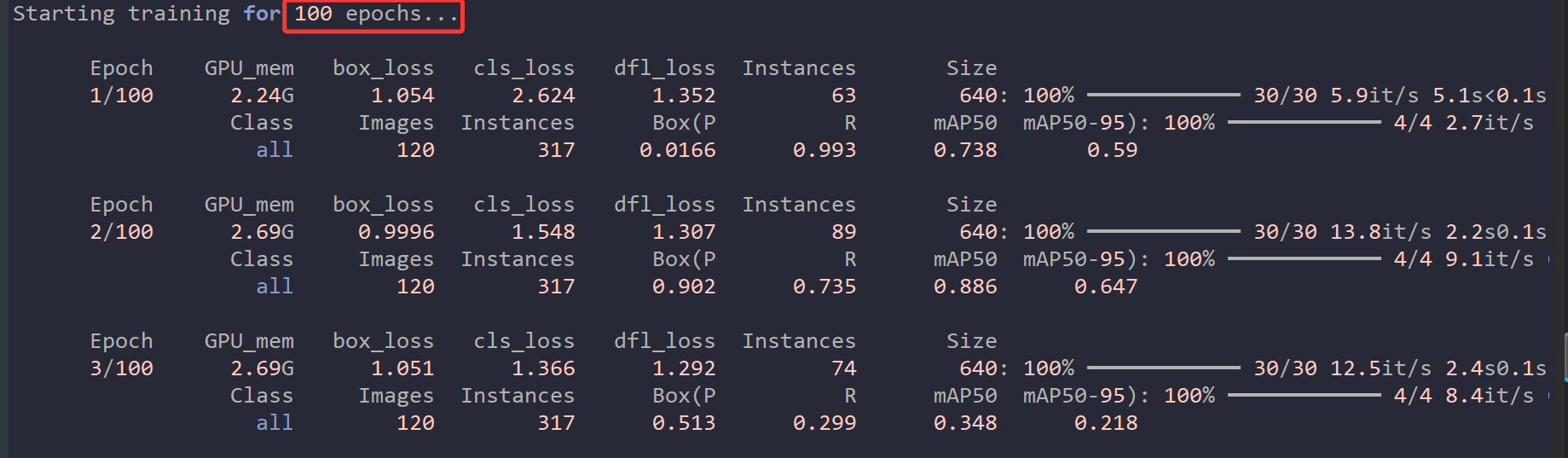
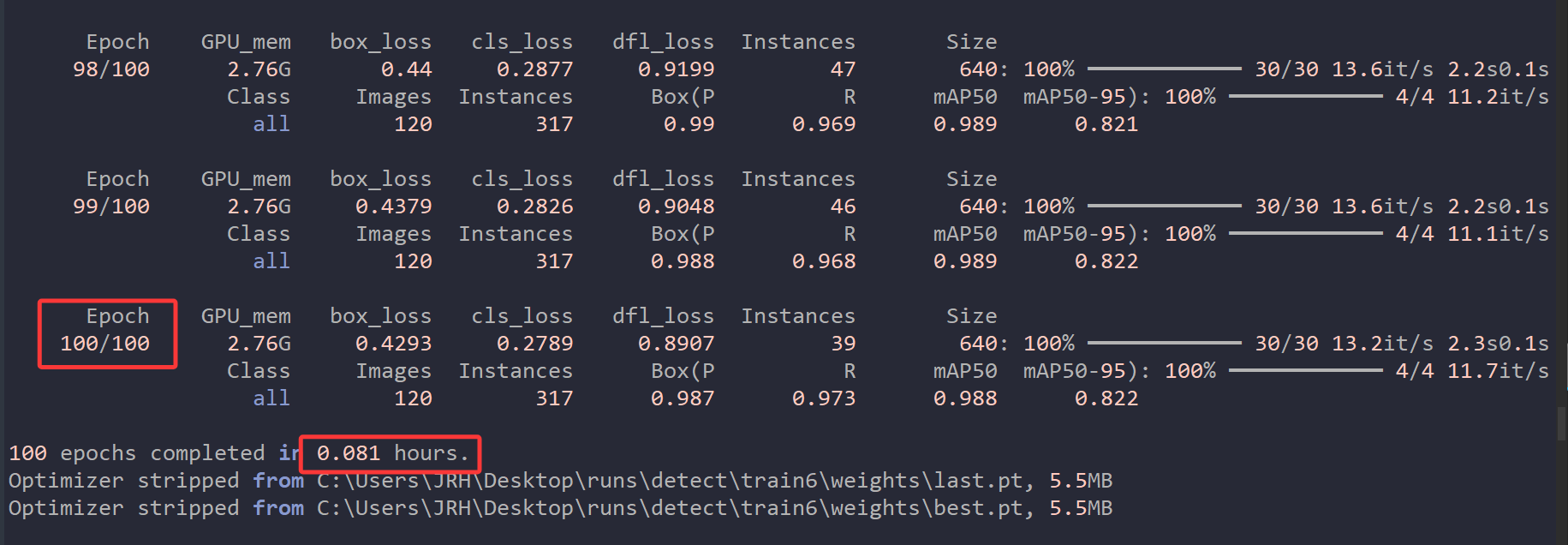
我的显卡为RTX3080,有8700多个CUDA核心,AI算力(INT8)大约为238,亲测训练600张图片的数据集100轮次只需要4分多钟。
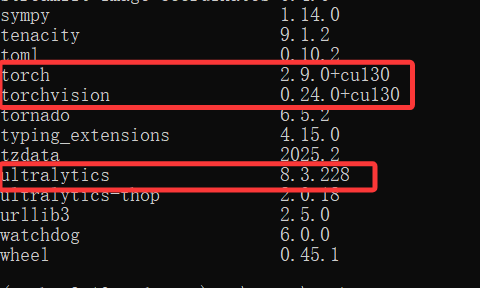
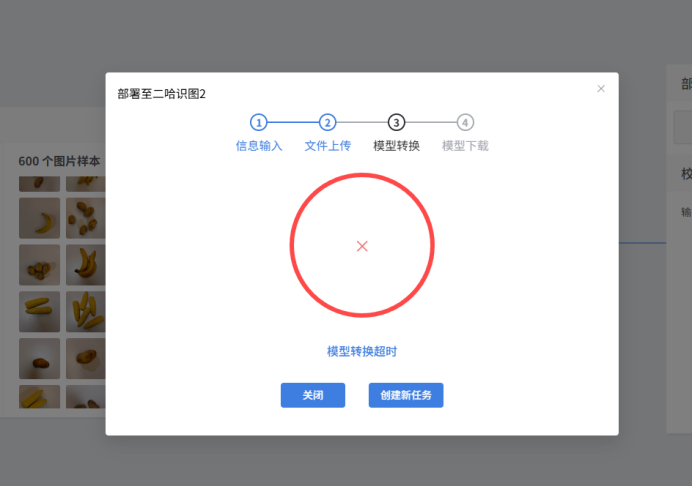
之后在Mind+2.0中可以点击导出模型按钮进行导出格式转为ONNX的最佳权重文件best.onnx,或者直接点击部署至二哈识图,该步骤我试了一下不行,不知道是怎么回事,然后本地化导出发现也不行,最后只能求助官方帮助,柳工给我发了一个他帮我导出的模型文件,谢谢。希望官方能够尽快解决模型导出问题。
3.生鲜识别模型部署应用。只需要将转换之后的压缩包文件复制到二哈中,然后安装即可。实际效果只能说还行,准确率不错,但是会有较为明显的误识。



下面就是明显的误识了。


下面简单制作一个生鲜识别的应用,用到的材料有Arduino UNO单片机、二哈二代、IPS彩色屏幕和语音合成模块,这三个都使用IIC接口连接至UNO。图形化代码块如下:
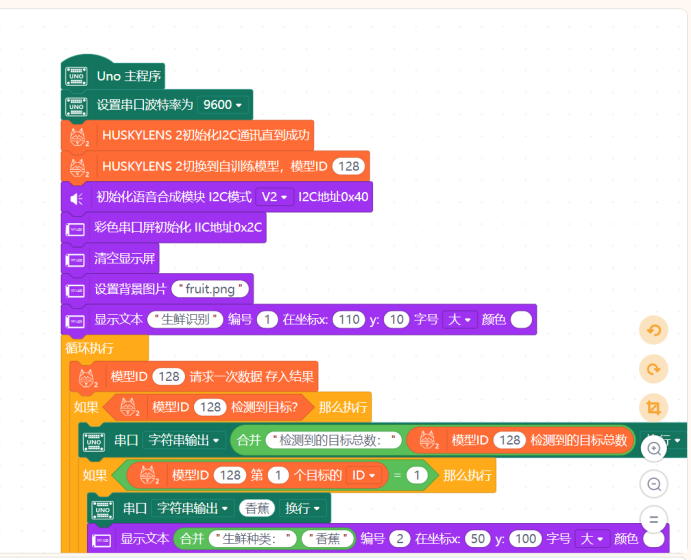
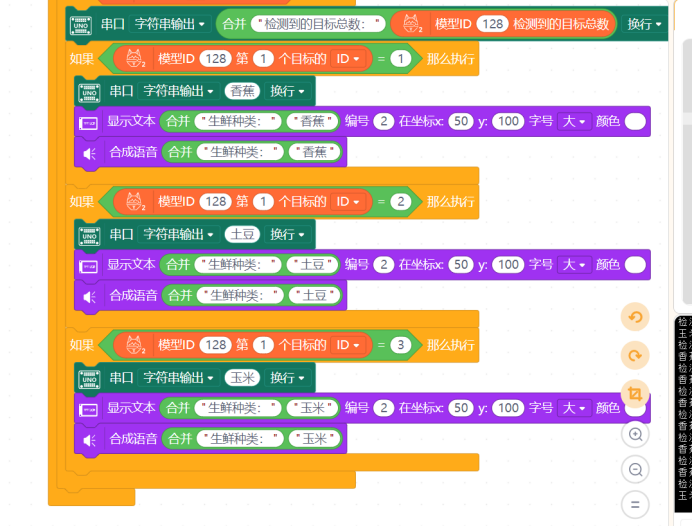
串口输出:
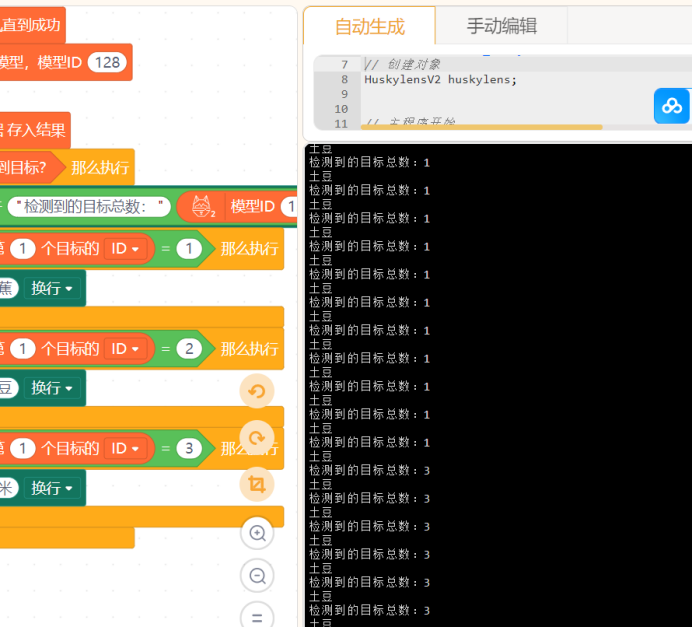
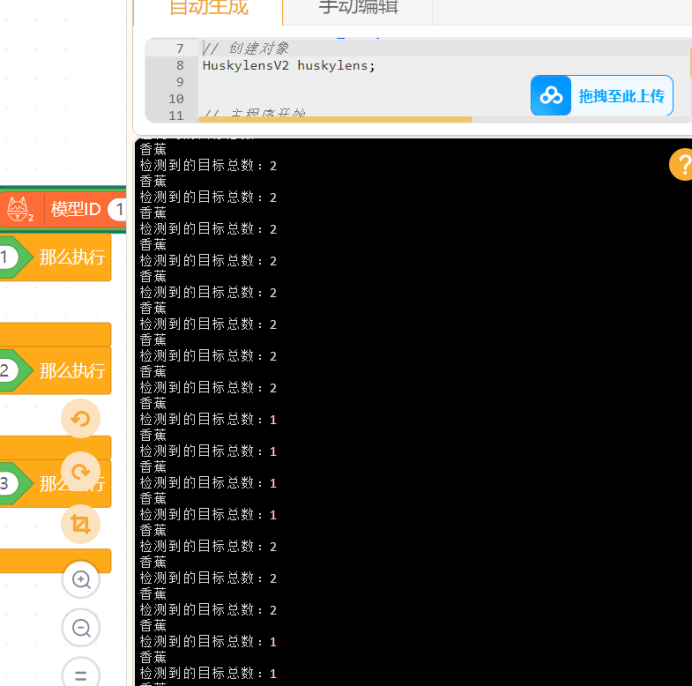
实际输出效果:



乍一看感觉还可以,但是实际上还是存在将玉米认作香蕉的问题,说明模型转为kmodel格式,被优化的太多了!毕竟算力比较有限。
如果直接使用导出的pt格式权重文件进行推理效果就非常好。
下面是在lattepanda IOTA 的实时推理效果。另附代码。

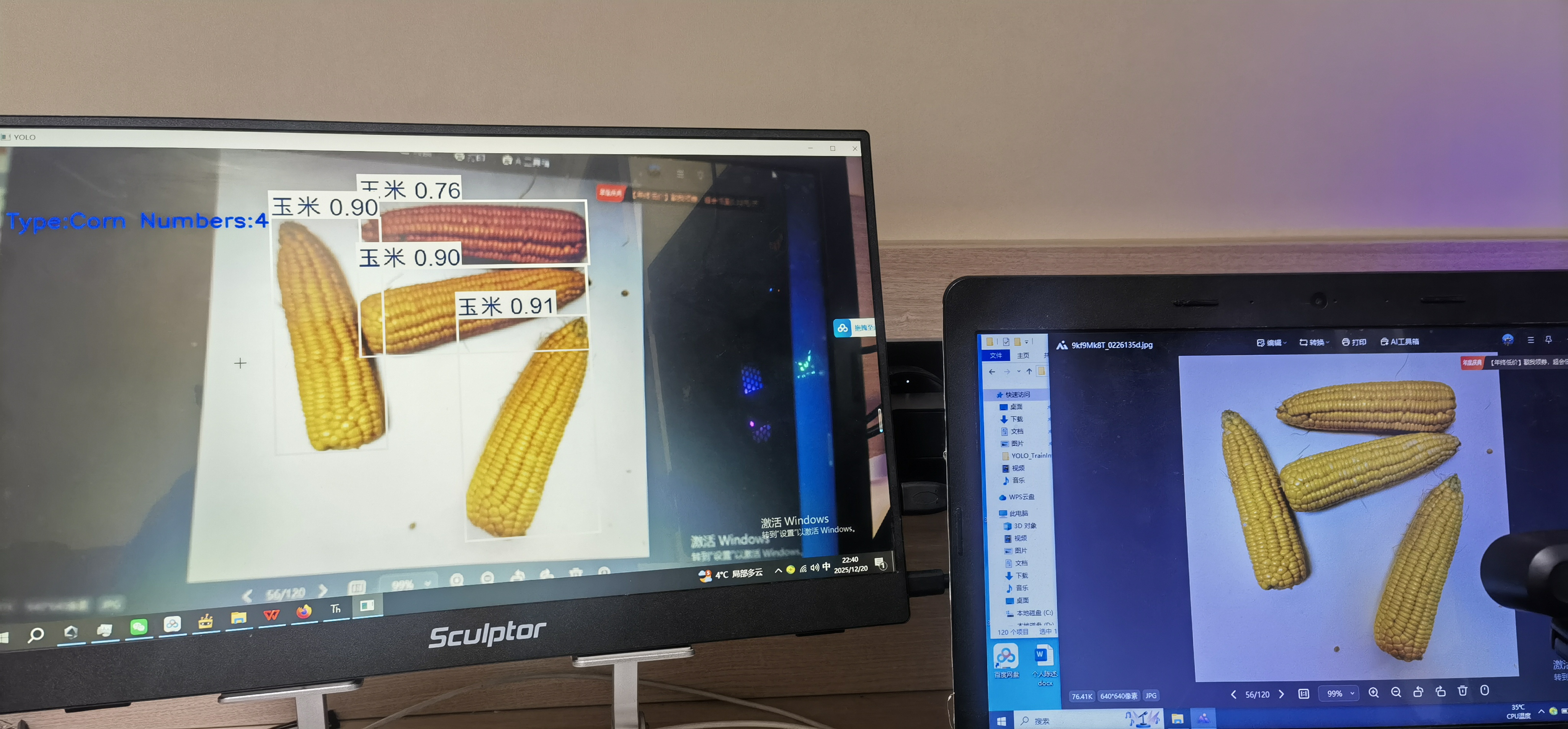
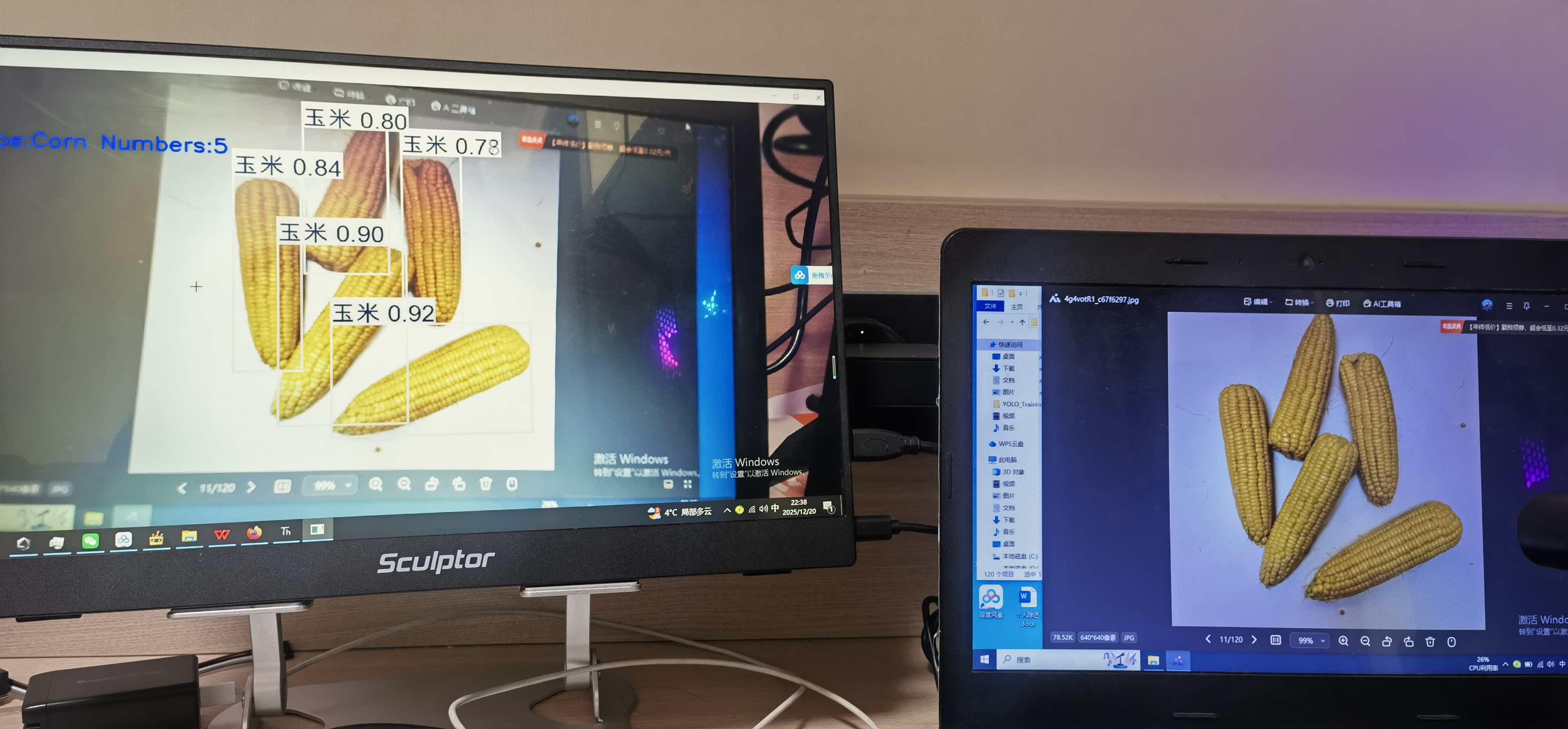
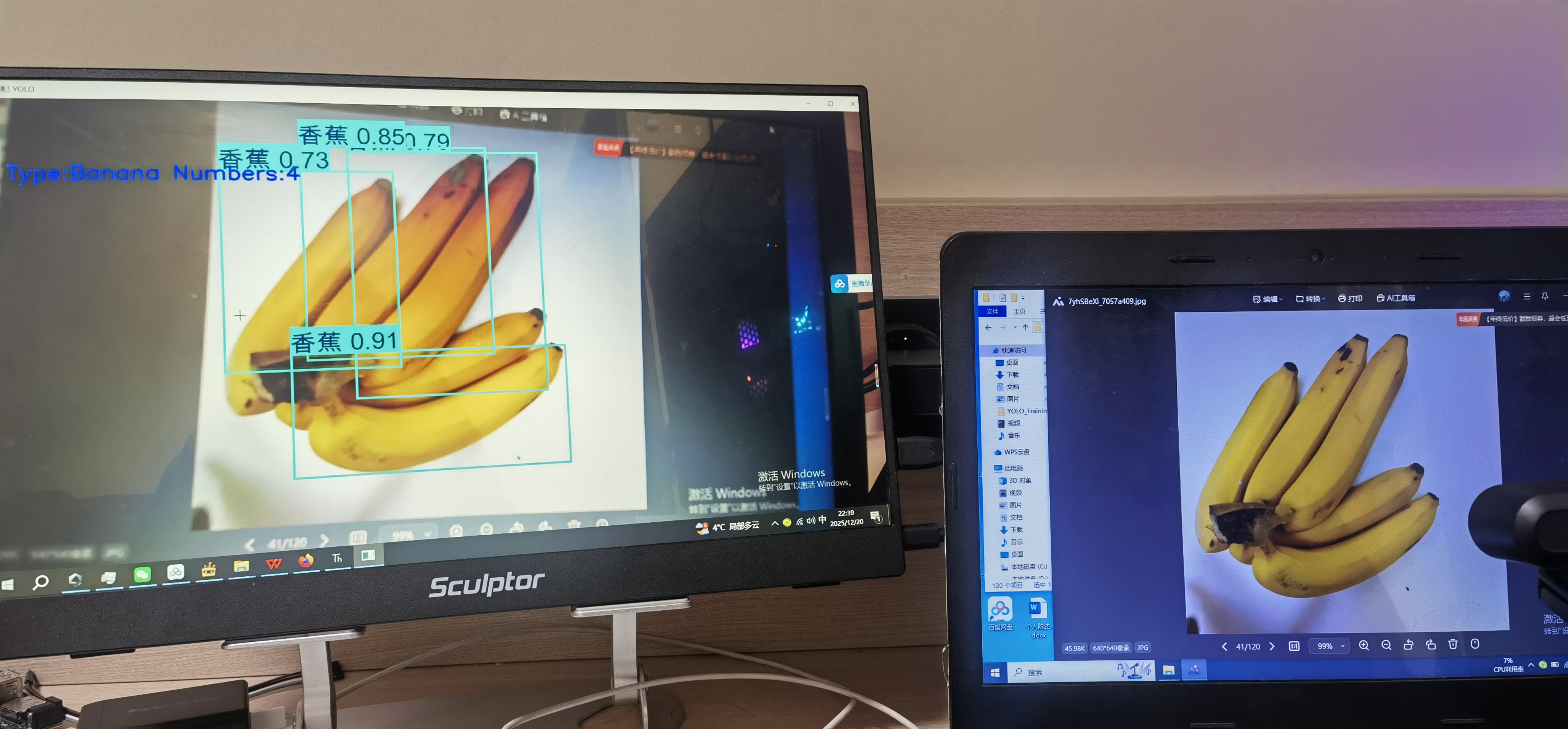
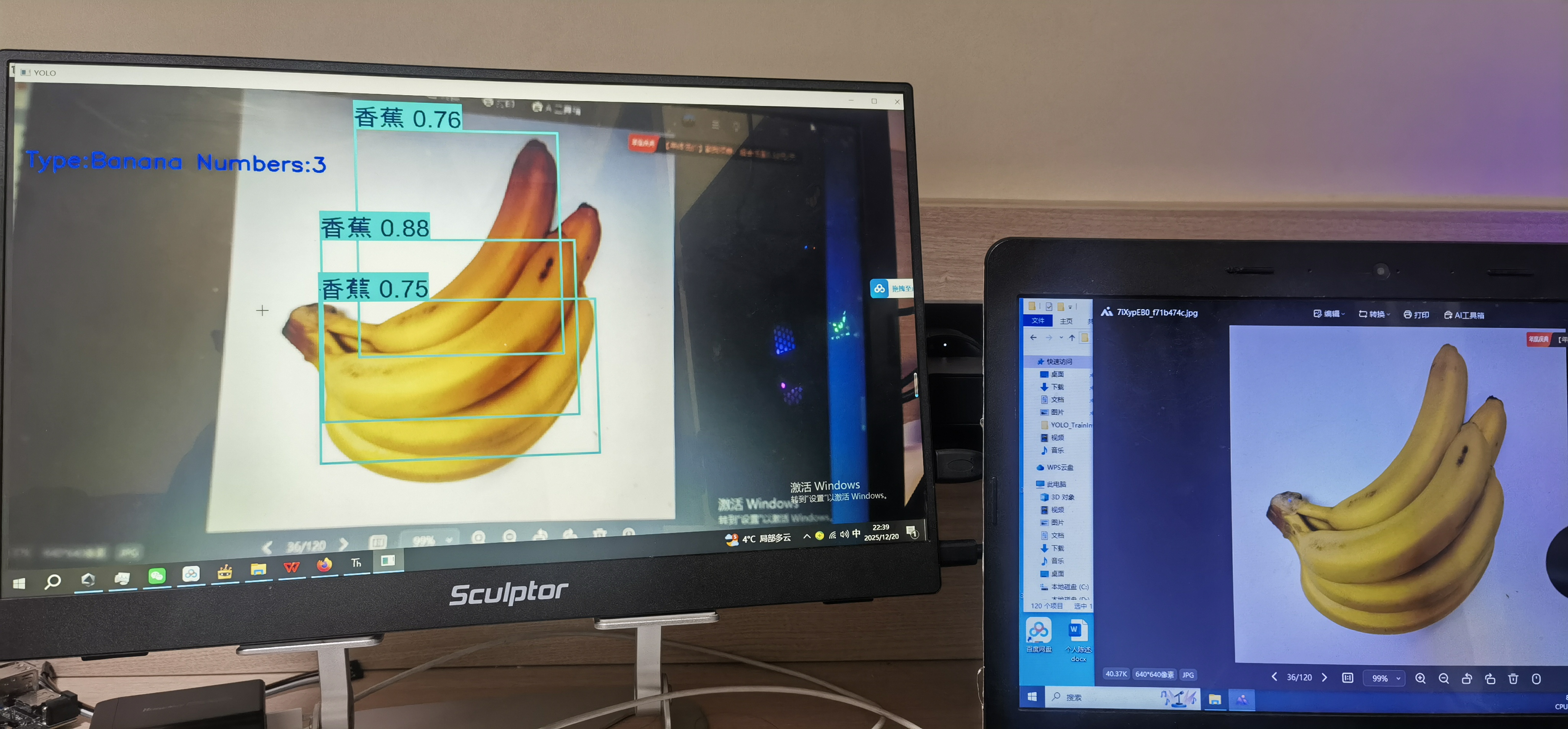
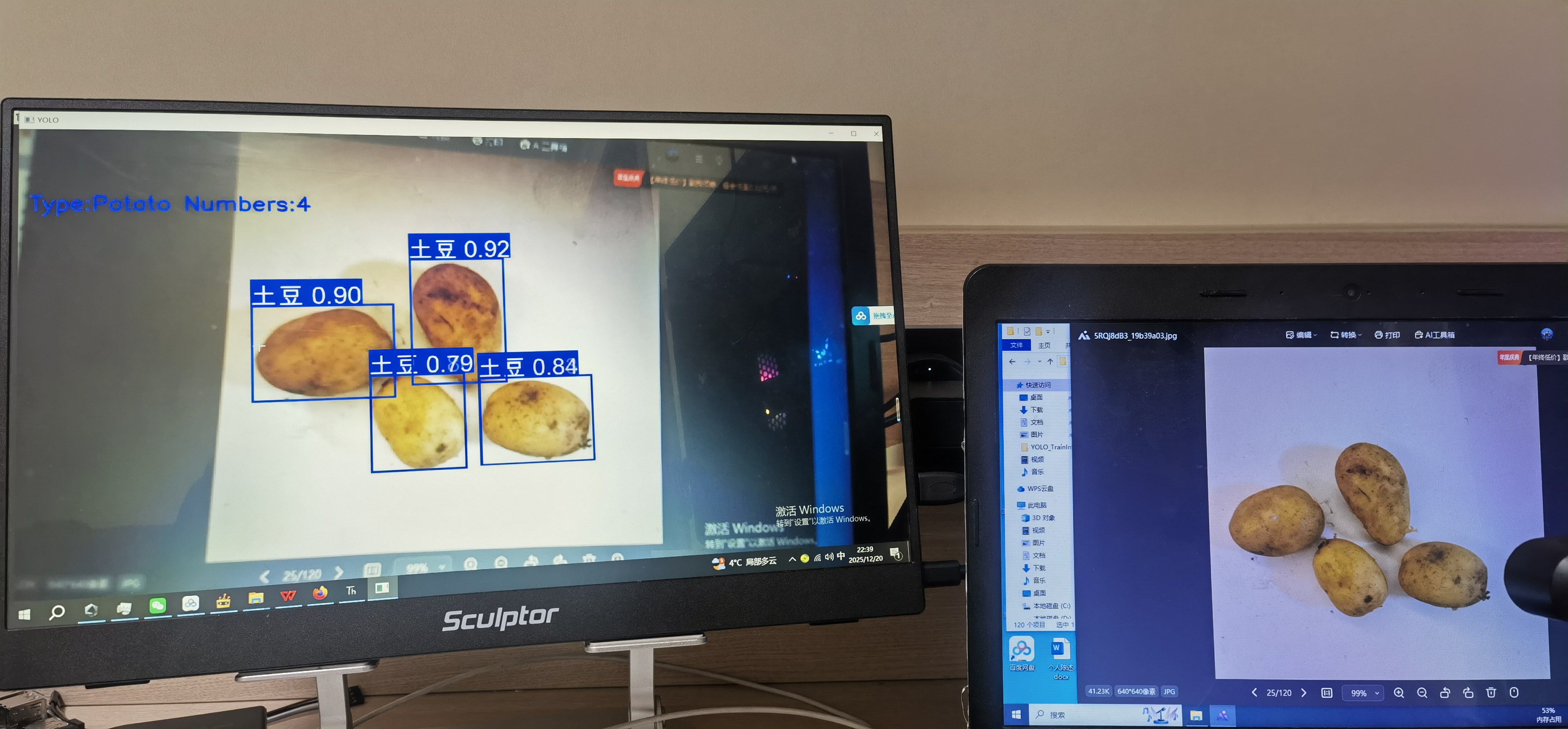
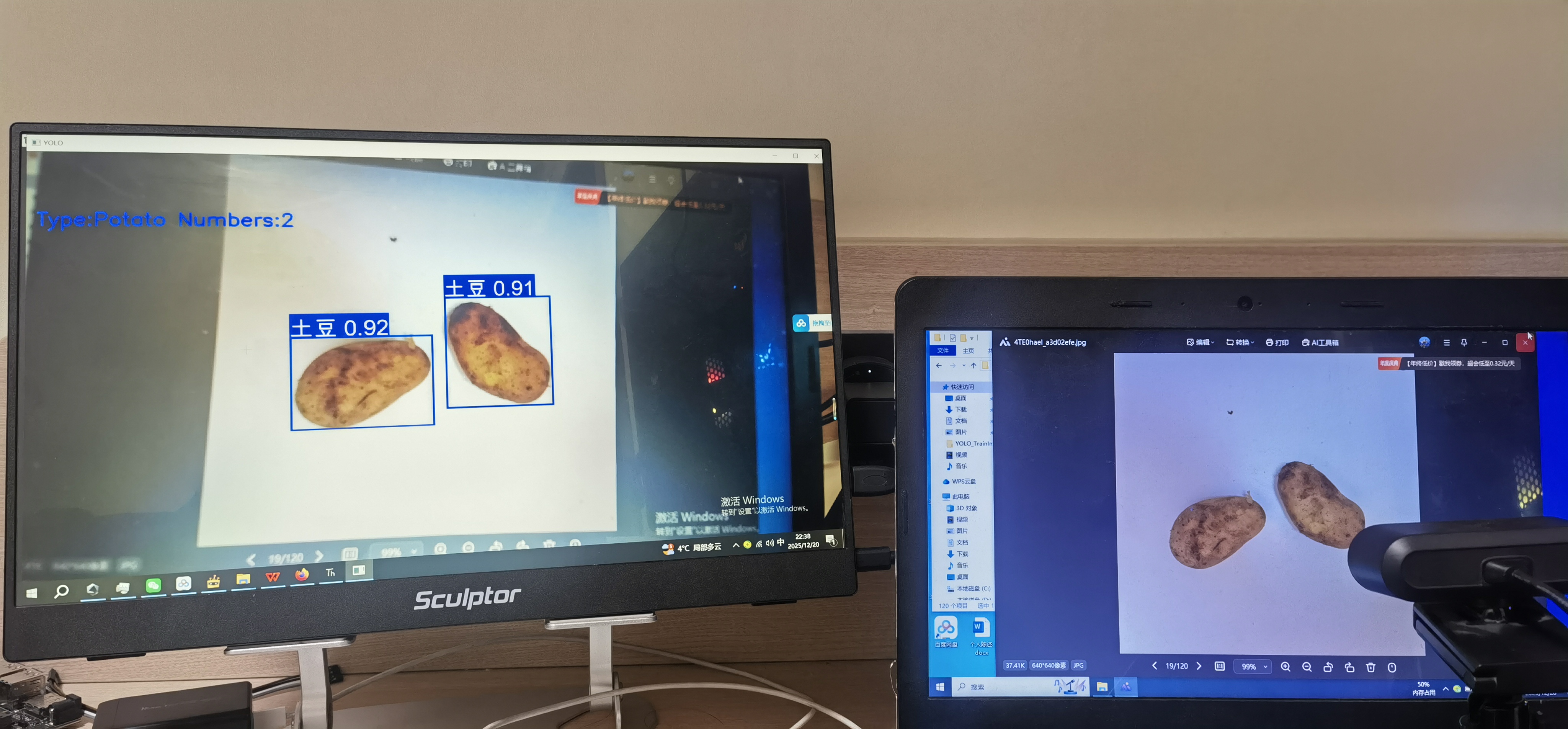
最后希望二哈的软件和Mind+2.0的软件能够更加优化,使用起来更加方便!
lattepanda电脑端推理代码:
import cv2
import numpy as np
from ultralytics import YOLO
def main():
# 配置视频画面大小
CAMERA_WIDTH = 1920
CAMERA_HEIGHT = 1080
try:
# 打开摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("无法打开摄像头")
cleanup()
return
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAMERA_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAMERA_HEIGHT)
# 创建显示窗口
cv2.namedWindow('YOLO', cv2.WINDOW_NORMAL)
cv2.resizeWindow('YOLO', CAMERA_WIDTH, CAMERA_HEIGHT)
while True:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头画面")
break
frame = cv2.resize(frame, (CAMERA_WIDTH, CAMERA_HEIGHT))
# YOLO 推理
model = YOLO("best.pt")
results = model.predict(frame, conf=0.5, iou=0.7)
annotated_frame = results[0].plot()
annotated_frame = np.array(annotated_frame, copy=True)
if results[0].boxes is not None and len(results[0].boxes) > 0:
boxes = results[0].boxes
num_detections = len(boxes)
# 获取类别信息
class_ids = boxes.cls.int().cpu().numpy()
class_names = [results[0].names[int(cls_id)] for cls_id in class_ids]
print(f"检测到的类别: {class_names}")
list_num = [0, 0, 0]
list_num[0] = class_names.count("土豆")
list_num[1] = class_names.count("玉米")
list_num[2] = class_names.count("香蕉")
idx, val = max(enumerate(list_num), key=lambda x: x[1])
if idx == 0:
det_type = "Potato"
elif idx == 1:
det_type = "Corn"
elif idx == 2:
det_type = "Banana"
cv2.putText(annotated_frame, f"Type:{det_type} Numbers:{val}",
(20, 180), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (255, 0, 0), 3)
else:
num_detections = 0
cv2.putText(annotated_frame, 'Total Detections: 0',
(20, 60), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 255, 0), 3)
cv2.imshow('YOLO', annotated_frame)
# 检测按键 - 支持多种退出方式
key = cv2.waitKey(1) & 0xFF
if key == ord('q') or key == 27: # 'q' 或 ESC 键
print("用户请求退出")
break
except KeyboardInterrupt:
print("程序被用户中断")
except Exception as e:
print(f"程序运行异常: {e}")
finally:
# 释放摄像头
if 'cap' in locals():
cap.release()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
print("程序已退出")
if __name__ == "__main__":
main()

 他的勋章
他的勋章

wzhzs2026.04.26
可以提供训练所用的图片吗
晟2026.02.24
厉害
铁皮屋12025.12.20
大神啊!!!