 返回首页
返回首页
 回到顶部
回到顶部
用行空板实现文字识别纠错
一、创作背景
有这样一个任务:机器人首先实时拍照识别1张知识卡片上的信息内容,判断其中的错别字及所在位置,然后按照规定格式显示并播报指定内容。
如下格式:有一个错别字,显示与播报内容的格式:“第X个字有误,请更正为X”。
二、 作品原理
本项目我们给行空板接上摄像头和喇叭,利用Python pytesseract库制作一个文字识别装置,实现拍照识别并输出纸上的文字,在实现语音播报。将纸上识别到的文字传给Kimi大语言模型,通过大语言模型来判断文字内容对错并按“第X个字有误,请更正为X”的格式输出文字,并将输出内容转换成语音播报出来。
三、硬件清单
行空板 1个
语音合成模块 1个
摄像头 1个
四、制作过程
1.安装插件和必要的程序文件。
安装pytesseract库将其添加到项目文件中,再上传到行空板中与mindplas文件夹的平行文件夹位置。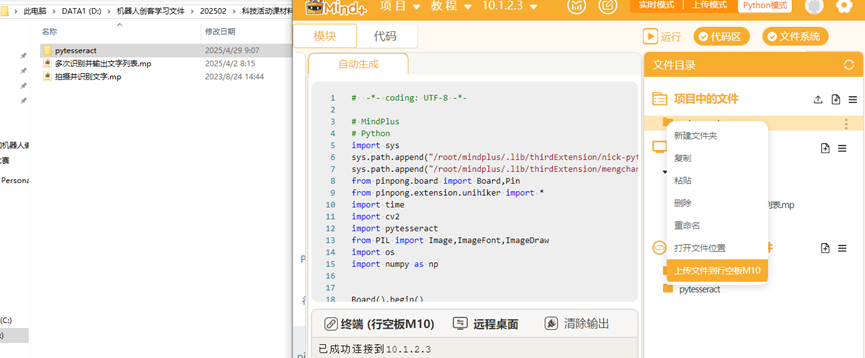
结果下如图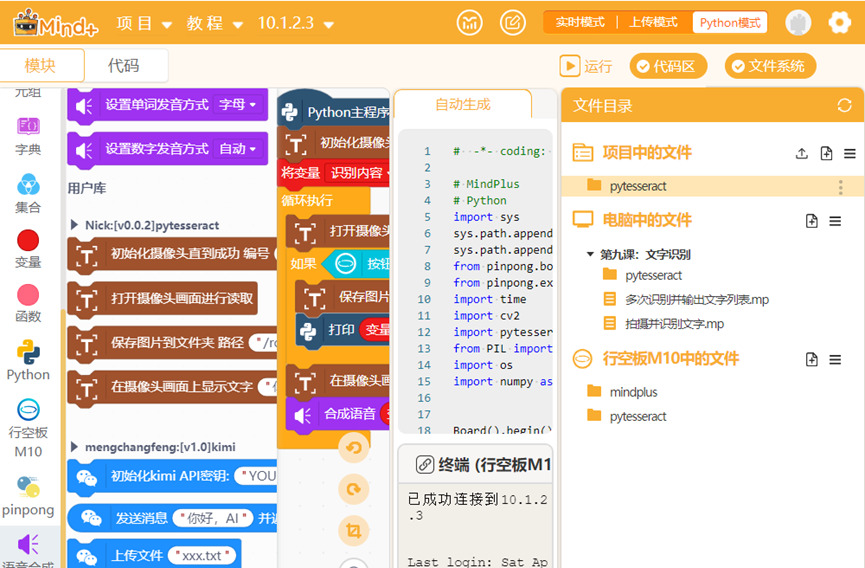
安装pytesseract库,将编程模式切换为代码模式,双击打开“1-Install_dependency.py”文件,出现安装代码,点击运行,自动安装依赖库。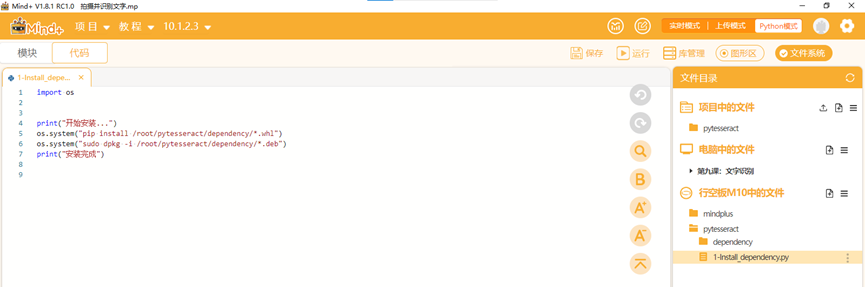
安装完成: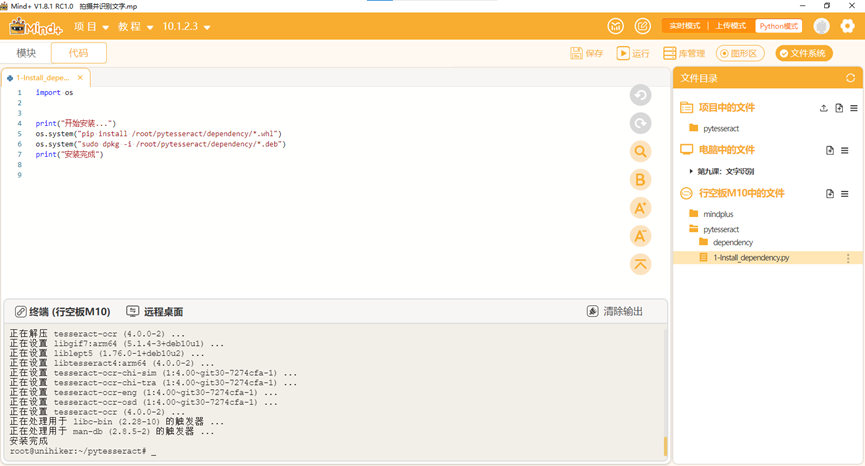
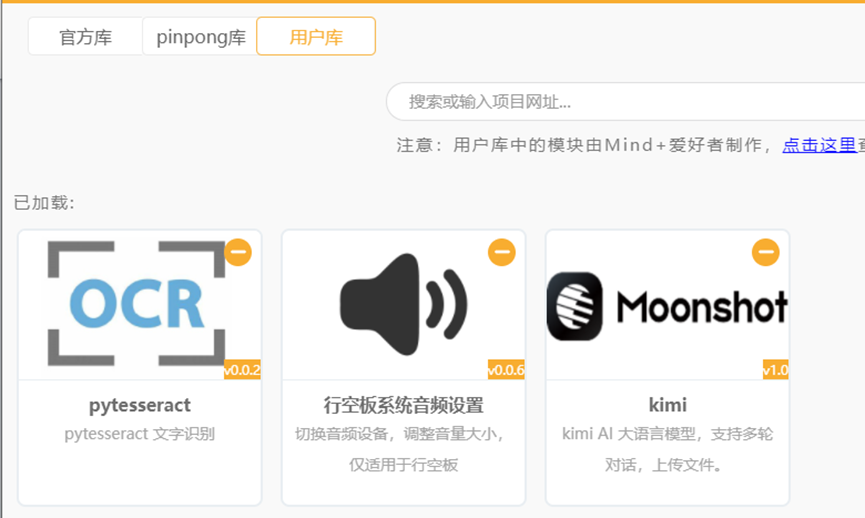
切换回图形化模式,加载文字识别图形化库。通过“扩展库”中的“用户库”检索获得“文字识别”图形化库——“pytesseract”(检索网址为https://gitee.com/chenqi1233/ext-pytesseract)。
利用查找网址安装扩展插件https://gitee.com/chenqi1233/ext-pytesseract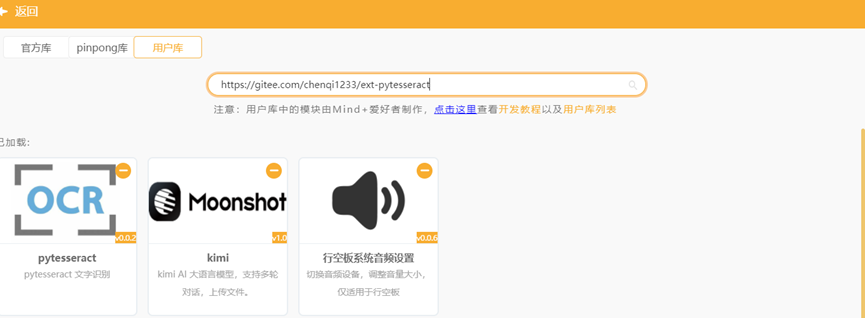
2.编写程序如下
首先安装必要的库和插件
初步实现文字的识别并显示在屏幕上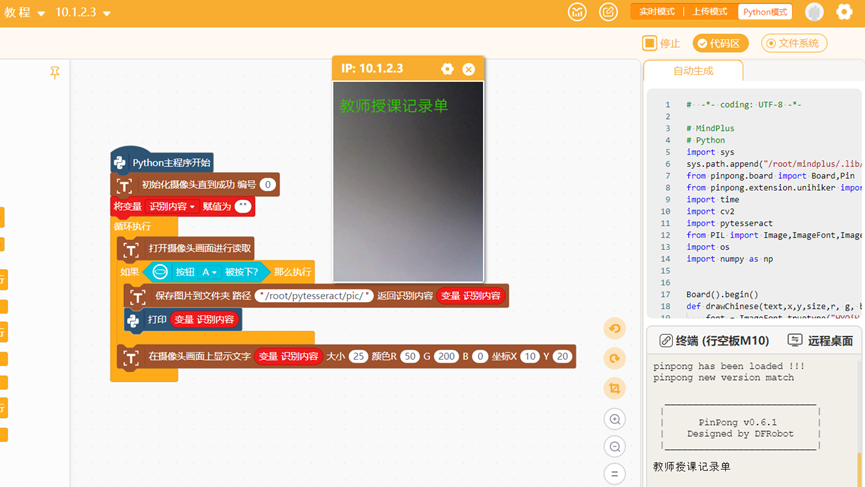
按完A键识别,文字显示在屏幕上,再按B键结束,文字在屏幕上消失。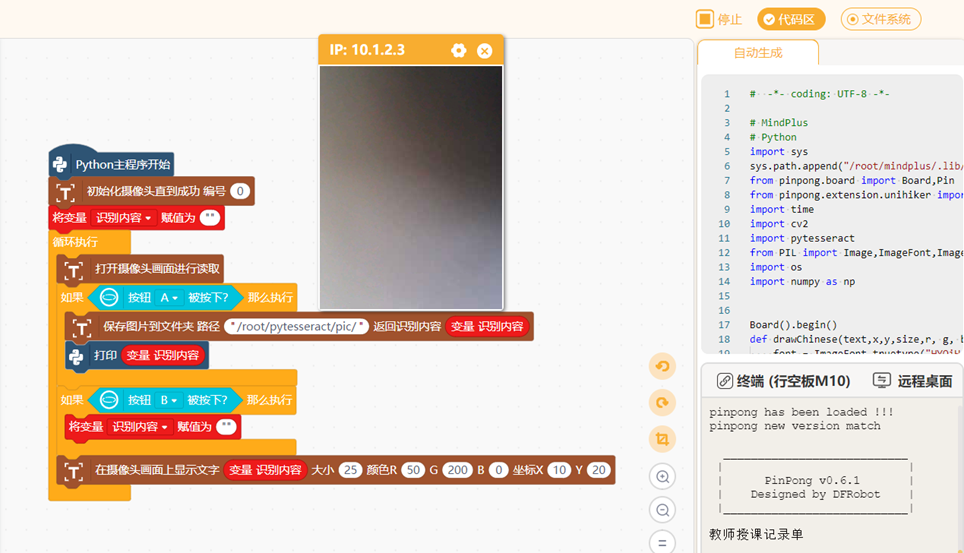
3.通过百度语音识别播报声音
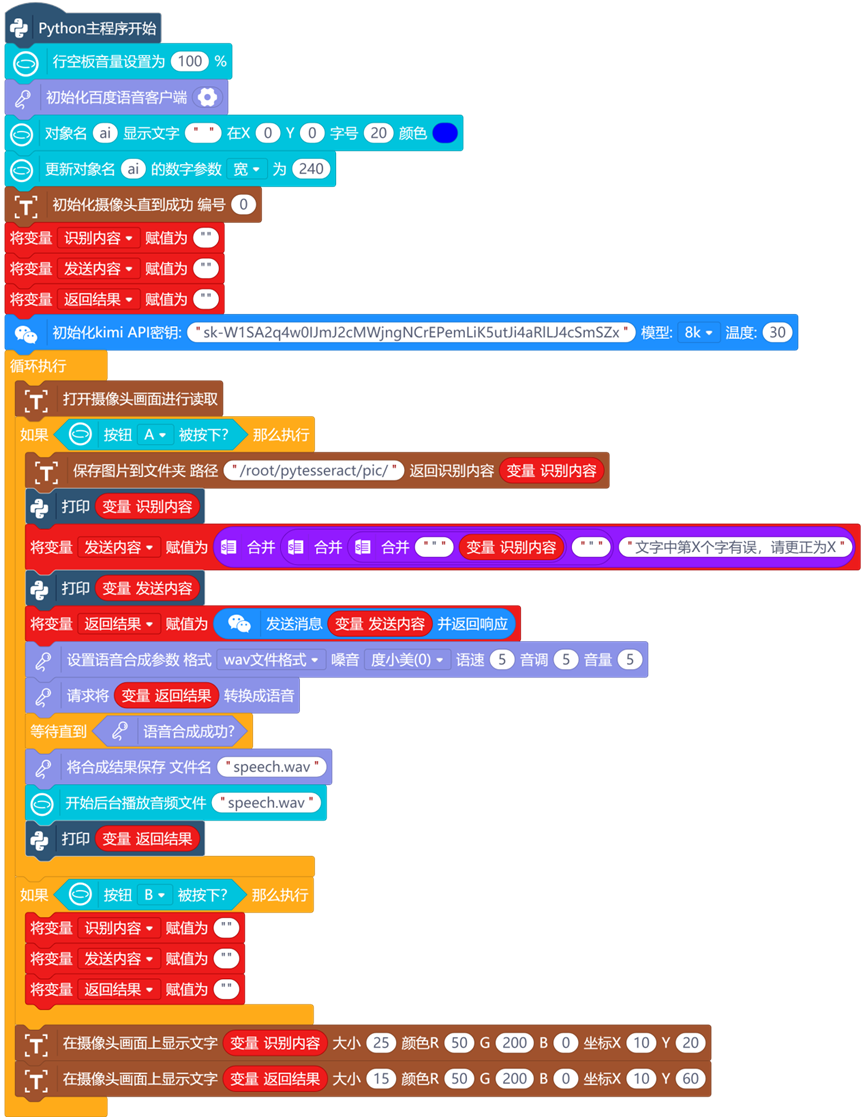
4.通过DF语音合成模块识别播报语音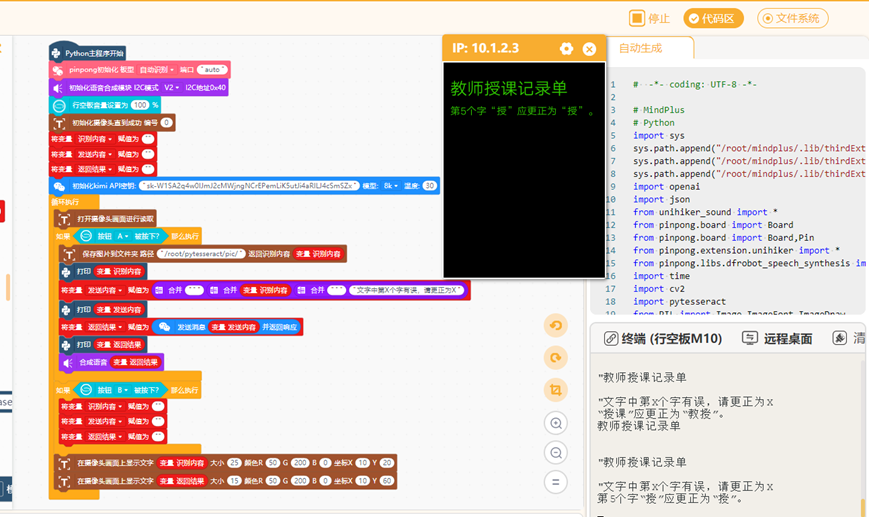
五、总结反思
通过本作品对行空板实用性进一步开发应用,又是一次新领域的尝试,有些不足之处还有待改进,换行功能还存在一定的局限性,大语言模型的应用识别能力还有进一步开发进步。


 他的勋章
他的勋章








1398142032281422025.08.21
能不能提供一下用户库
孙洪尧19852025.07.06
老师的作品很厉害