 返回首页
返回首页
 回到顶部
回到顶部

科技的发展推动了自动化和智能化在现代物流、仓储和零售业中的广泛应用,其中无人驾驶小车和货物识别技术尤为关键。货物识别技术能够帮助小车准确识别和处理不同货物,从而显著提升自动化和智能化水平。
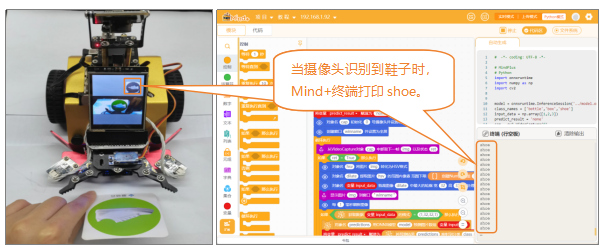
本项目将使用行空板、无人驾驶小车以及USB摄像头,设计一个可以识别鞋子、纸箱以及瓶子的货物识别系统。
任务目标
当摄像头识别到鞋子、纸箱、瓶子这几个物体时,将对应的货物名称在Mind+终端打印出来。
知识点
1. 掌握图像数据集的采集方法
2. 掌握卷积神经网络算法的训练过程
3. 了解卷积神经网络算法的实现过程
材料清单
硬件清单:

软件使用:Mind+编程软件 x1
下载地址:https://mindplus.cc/

课前准备 ——环境设置
在开始正式学习之前,我们需要对行空板进行一些基础准备,确保系统和环境设置都正确。
具体步骤,请参考:行空板无人驾驶系列课程 第一课 课前准备 部分内容。
动手实践
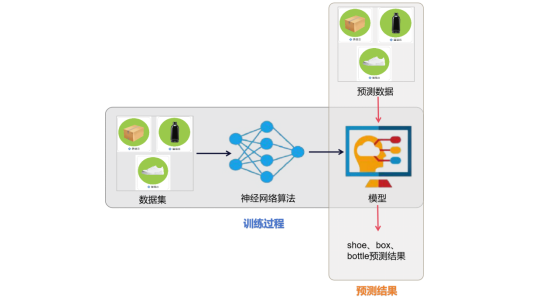
这个项目将重点放在货物识别系统设计部分,我们将收集大量的鞋子、纸箱、瓶子的图片,然后使用深度学习框架TensorFlow来训练物体识别模型。最后,将训练好的模型部署在小车上,配合USB摄像头来进行物体识别。因此,分为以下几个小任务来实现。
任务一:采集物体图像
使用USB摄像头对货物卡纸鞋子、纸箱、瓶子,进行拍照,收集大量的图片数据。
任务二:训练物体识别模型
使用TensorFlow模型,对收集好的图片数据进行模型训练,并将训练好的模型进行保存。
任务三:货物识别
将训练好的识别模型部署在行空板小车上,使用小车可以自动识别并处理不同的货物。
任务一:采集物体图像
1. 硬件连接
使用type-c转A数据线,将USB音频模块与行空板连接,然后再使用type-c转A线将摄像头连接在音频模块上。

2. 软件准备
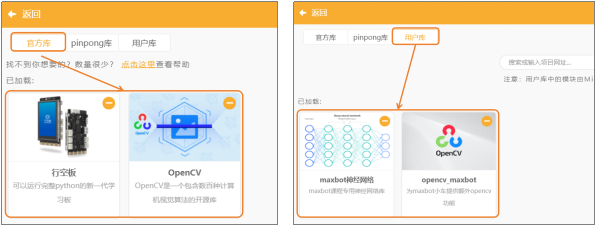
(1)添加官方库:点击“扩展”,在“官方库”中,选择“行空板”与“Opencv”。
(2)添加用户库:选择“maxbot神经网络”、“opencv_maxbot”。
3.编写程序
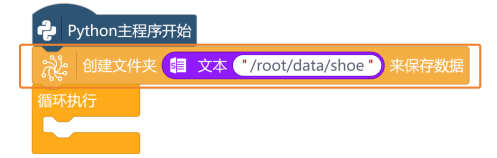
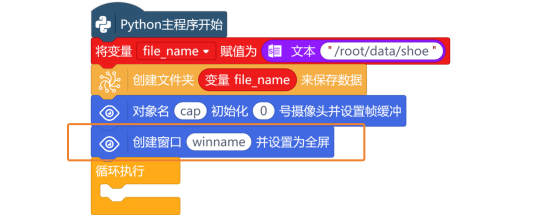
这个任务中,主要是使用USB摄像头,对货物卡纸进行图片拍照。拍好的图片,需要使用“创建文件夹 来保存数据”指令,来对拍好的图片进行保存。

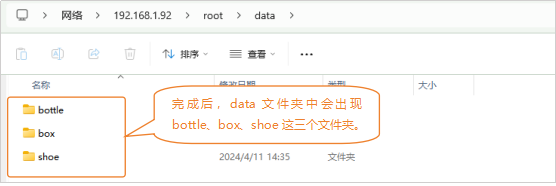
指令中填写的路径“/root/data/shoe”,表示在行空板“root”文件夹中创建一个文件名为“data”的文件夹,然后在data文件夹创建一个名为“shoe”的文件夹。
注意:文件路径是文本型,所以路径需要放入“文本 ”指令中。
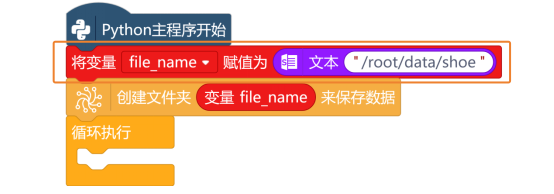
当然,为了方便后面使用,新建变量file_path,并初始化为“/root/data/shoe”,后面要使用这个路径时,直接使用变量名即可。
打开摄像头,使用“对象名 初始化 号摄像头并设置缓冲”指令,创建一个视频捕获对象“cap”,并初始化从第一个摄像头(0号摄像头)捕获到的视频。

要将摄像头中的视频流全屏显示在行空板屏幕上,使用“创建窗口winname并设置为全屏”指令,在屏幕上创建一个名为winname的窗口,并将窗口设置为全屏模式。
接下来,在OpenCV指令区中,使用“从VideoCapture对象vd中抓取下一帧grab以及状态ret”指令,从捕获的视频流中抓取一帧图像。
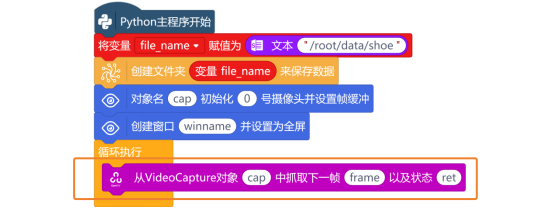
图像捕获成功后,使用“获取图片 的高h 宽w 通道数c”指令,获取帧的形状,以便计算裁剪区域。

裁剪区域的起点和终点坐标可通过图片的高(h)和宽(w)计算得出。具体方法是从图片中心裁剪一个正方形区域。因此,要裁剪的正方形边长已经等于图像的高度(h)。

图像起始坐标x,就为(w-h)//2。新建“变量start_x”,并将变量start_x的值赋值为(w-h)//2。

图像起始坐标y,就为(h-h)//2。新建“变量start_y”,并将变量start_y的值赋值为(h-h)//2。

而终点坐标变量end_x,变量end_y,只需要在起点坐标(start_x,start_y)的基础上加一个高h就可以了。

然后,使用“对象 调整图像 大小为 ”指令,将图像frame根据计算好的坐标进行裁剪。将裁剪后的图像重新命名为crop_frame,图像裁剪的大小为[start_y:end_y, start_x:end_x]。

使用“显示图像 到窗口”指令,将裁剪后的图像显示在行空板屏幕上。但是,我们希望在行空板上看到的图像是镜像的,所以在显示图像指令前,使用“对象名 将图像 水平翻转”指令,对图像进行水平翻转后再显示。要让摄像头的图像是实时的视频流,使用“每 毫秒刷新图像”指令,每隔1毫秒刷新一次图像。

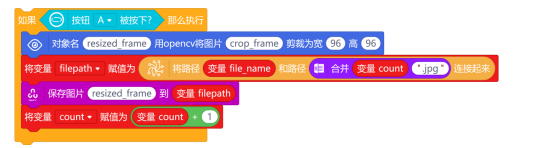
按下A键后,通过条件语句“如果……那么执行”指令,判断按键状态,如果条件为真,则执行“对象名 用opencv将图像 剪裁为宽 高 ”指令。然后,将图像crop_frame裁剪为宽96,高96的图片,并将裁剪后的图片重新创建一个对象名resized_frame。
注意:“对象名 用opencv将图像 剪裁为宽 高 ”指令,是指对图像进行缩放。其中宽96和高96,是将图像缩放到96*96像素,96*96这个尺寸是经常被用于机器学习和深度学习模型的尺寸。

图像缩放后,就需要对图像文件进行保存了。图片保存的格式为“xx.jpg”,保存路径为“/root/data/shoe”。使用“将路径 和路径 连接起来”指令,将路径“/root/data/shoe“和图像文件“xx.jpg”连接起来。

为满足训练需求,需采集至少500张图像并保存至“shoe”文件夹中。因此,图像文件名可以设置为1.jpg、2.jpg……500.jpg这样的形式进行保存。新建变量count,在“Python主程序开始”下,初始化变量值为0。图像文件名使用“合并”指令,将变量count和图像后缀名.jpg合并起来。最后新建变量filepath,用来存储合并后的图像文件路径。

确认好保存路径和图像文件名后,就使用“保存图片 到 ”指令,对缩放后的图片resized_frame,进行保存。保存完成后,使用“将变量count赋值为 ”指令,将变量count+1。
最后,使用“在图片 上绘制文字 位置 大小 颜色”指令,将当前拍摄到的图片名称显示在行空板上。然后使用“打印 ”指令,在Mind+终端增加一些文字提示,完整程序如下:
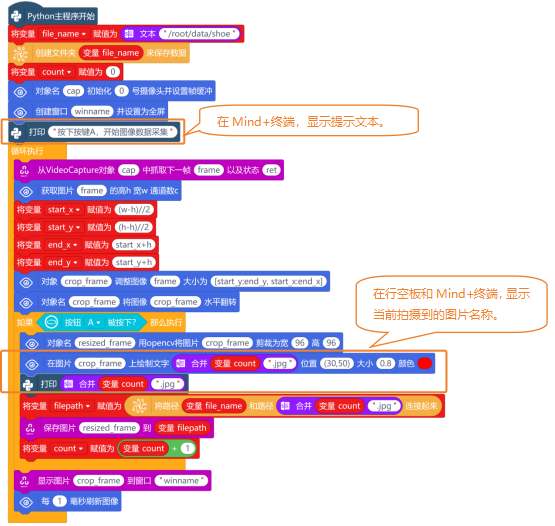
4. 程序运行
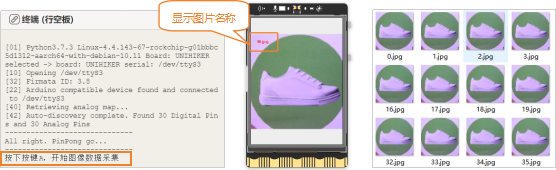
远程连接192.168.1.80,连接成功后,点击运行。程序运行成功后,Mind+终端打印区出现提示“按下A键开始图像数据采集”。图像数据采集操作如下:将USB摄像头,对着货物卡纸鞋子,行空板上出现鞋子的图像后,按下A键不松手,可快速采集图像数据。直到采集到大约500张图像数据后,松开按键。
注意:采集图像过程中,需要调整摄像头角度,多角度采集物体图像,可以提高识别率。
5. 试一试
这个项目中,还需要采集鞋子和纸箱的图片,大家尝试一下,修改程序中的file_name,采集鞋子和纸箱的图片。
提示:任务一的程序中修改file_name中的文件名,再次运行程序后,进行对应的图像采集即可。
任务二:训练物体识别模型
1. 软件准备
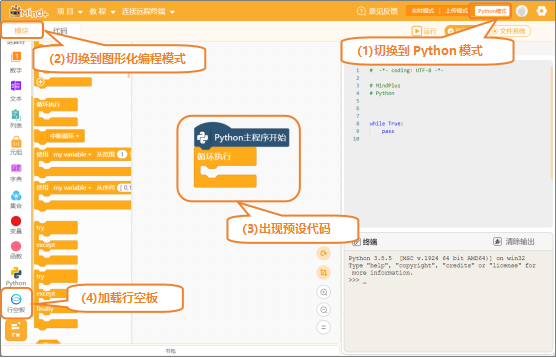
(1)打开Mind+:按照下面的图示完成软件准备工作。
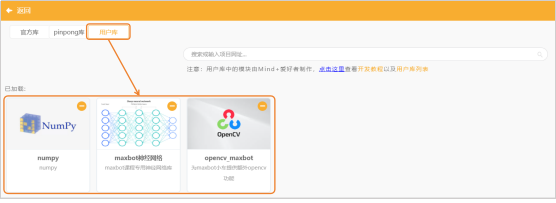
(2)添加用户库:选择“maxbot神经网络”、“opencv_maxbot”、“numpy”。
2. 编写程序
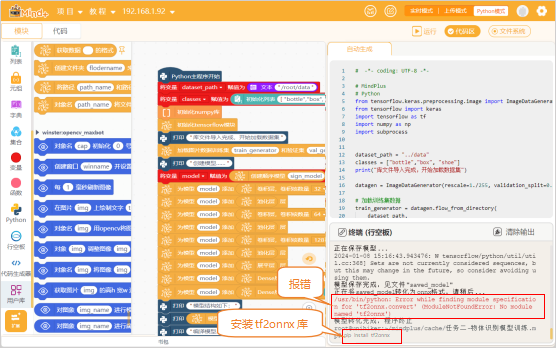
要完成物体识别模型的训练,需要用的卷积神经网络算法,程序主要通过以下5个步骤来完成:导入数据集、数据预处理、创建神经网络、训练模型、保存模型。
注意:关于“神经网络算法”相关知识,见“知识园地”。
1. 导入数据集
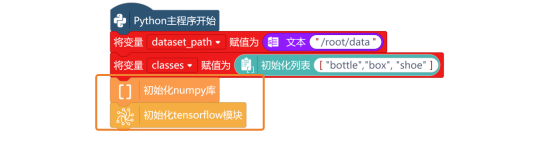
采集好的图片保存在路径“/root/data”这个文件夹中,新建“变量dataset_path”,并初始化变量的值为文本型的“/root/data”。

新建“变量classe”,并使用“初始化列表 ”指令,初始化列表的值为["bottle","box", "shoe"]。需要注意的是,列表中的文件名字符顺序,必须为保存并排序后的图片文件夹名。

这个项目中,要用到numpy库和TensorFlow库。所以,在“Python主程序开始”程序下,使用“初始化numpy库”指令与“初始化tensorflow模块”指令,进行初始化。
2. 数据预处理
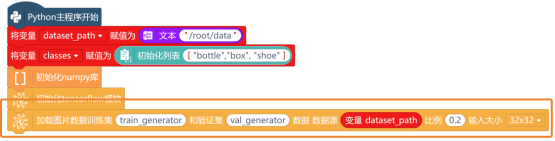
要处理数据,使用“加载图片数据训练集 和验证集 数据 数据源 比例 输入大小 ”指令,从数据集目录中加载图片数据,并创建训练集和验证集。其中,比例为0.2,输入大小选择32x32。
注意:比例0.2是指数据集中20%用于验证集,80%用于训练集。
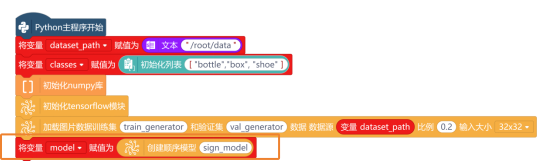
数据集和验证集创建成功后,使用“创建顺序模型 ”指令,创建一个序列模型,并将其命名为“sign_model”。新建“变量model”,用来存储创建好的模型。
3. 创建神经网络
下面,就可以开始构建卷积神经网络模型了,一个卷积神经网络模型,需要包含多个卷积层、最大池化层和全连接层。添加卷积层,使用“为模型 添加 层”指令。

然后,使用“卷积层,卷积核数量 激活函数为 ,输入数据格式 层”指令,对输入的图片数据进行卷积操作,以从局部区域中提取特征。其中,选择卷积核数量32,表示卷积层的滤波器数量,也就是卷积后得到的特征图数量。激活函数为relu,输入数据格式为(32x32x1)。

使用“为模型 添加 层”指令与“池化层”指令,对卷积层进行池化操作,减小特征图的空间维度,保留最重要的特征。

重复添加第二个卷积层和池化层,修改卷积层的卷积和数量为64,激活函数为relu,输入格式为none。

添加第三个卷积层和池化层,修改卷层的卷积核数量为128,激活函数为relu,输入格式为none。

接下来使用“为模型 添加 层”指令和“展平层”指令,添加展平层。展平层的作用是将卷积层提取的特征图展平成一个向量,为全连接层做准备。

然后,使用“为模型 添加 层”指令,和“Dense层,神经元个数为 激活函数 为 层”指令,添加一个全连接层。设置神经元个数为128,激活函数为relu。这一层的作用是连接上一层的所有神经元,实现对特征的组合和分类。

最后,使用“为模型 添加 层”指令,和“Dense层,神经元个数为 激活函数 为 层”指令,再添加一个全连接层。并修改神经元个数为“列表 变量classes 的长度”,修改激活函数为softmax。这一层的作用是将具有类别数目的classes列表,使用softmax函数进行多类别分类。

4. 训练模型
卷积神经网络构建成功后,使用“模型 的结构”和“打印”指令,打印一下模型的结构。

5. 保存模型
使用“设置模型 参数,优化器,损失函数,评价函数”指令,对模型进行编译,并设置优化器为“Adam”,损失函数为“CategoricalCrossentropy”,评价函数为“accuracy”。

模型编译完成后,使用“训练模型 训练数据集 训练次数 验证数据集”指令,进行模型训练。并修改指令中的训练模型为“model”,训练数据集为“train_generator”,训练次数为3,验证数据集为“val_generator”。

模型训练完成后,通过“以saved_model格式保存模型 到 ”指令,将模型保存为TensorFlow SavedModel格式,便于后续部署和使用。

使用“将saved_model模型 转化为ONNX模型 ”指令,将TensorFlow模型转换为ONNX格式。

最后,添加“打印”指令,用于提示当前程序执行的步骤,完整程序如下:

3. 程序运行
远程连接192.168.1.80,连接成功后,点击运行。直到Mind+终端打印“模型转化完成,程序终止”字符串后,模型训练完成,自动退出程序。
注意:由于要加载的图片数据比较多,整个模型训练所花的时间也比较久,需要3-5分钟左右。
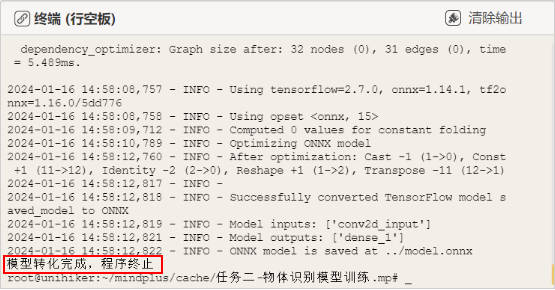
在模型训练过程中,出现了“no module name ‘tf2onnx’”的报错,我们可以在终端中输入指令“pip install tf2onnx”按回车键,进行安装,安装完成后,再次运行程序即可。
4. 试一试
任务二的程序中,我们将提示信息通过“打印”指令,显示在Mind+的终端区,这样我们要观察模型是否训练成功,只能在Mind+的终端打印区进行查看。下面,大家试一下通过“对象名 显示文字 在X Y 字号 颜色”指令与“更新对象名 的文本内容参数为 ”指令,将提示信息显示在行空板的屏幕上。
任务三:货物识别
1. 软件准备
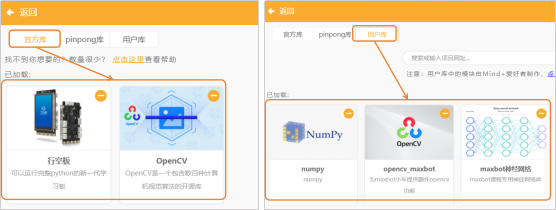
(1)添加官方库:点击“扩展”,在“官方库”中,选择“行空板”与“Opencv”。
(2)添加用户库:选择“numpy”、“opencv_maxbot”、“maxbot神经网络”。
2. 编写程序
使用ONNX模型进行物体识别,需要通过模型加载和预处理、图像处理、图像预测与展示这三个步骤。
1. 模型加载和预处理
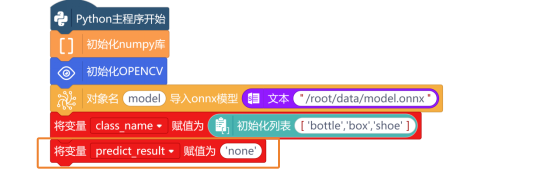
首先,使用“初始化numpy”指令与“初始化OPENCV”指令,进行初始化操作。

使用“对象名 导入onnx模型 ”指令,加载任务二保存好的model.onnx模型,修改模型的路径为“/root/data/model.onnx”。

新建“变量class_names”,并使用“初始化列表 ”指令,设置类别名称列表,并将列表中的内容修改为“['bottle', 'box', 'shoe']”。

然后,新建“变量predict_result”,并将变量赋值为“none”,将初始化预测结果设置为“none”。
2. 图像处理
要从摄像头中读取待识别的图像,使用“对象名 初始化 号摄像头并设置帧缓冲”指令,创建一个视频捕获对象“cap”,并初始化摄像头的编号为0。使用“创建窗口winname并设置为全屏”指令,在屏幕上创建一个名为winname的窗口,并将窗口设置为全屏模式,以便将摄像头中的视频流全屏显示在行空板屏幕上。
新建“变量input_data”,并将该变量复制为“创建Numpy数组[1,2,3]”指令,初始化Numpy数组的输入数据。
接下来,就需要使用“从VideoCapture对象vd中抓取下一帧grab以及状态ret”指令,从捕获的视频流中抓取一帧图像。
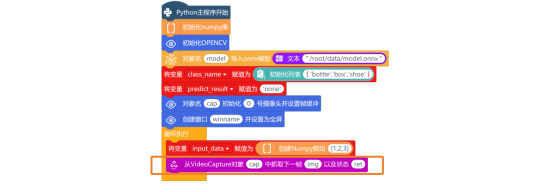
抓取图片后,需要使用“如果……那么执行”指令与“逻辑运算符 =”指令,判断状态ret的值是否True(判断读取帧是否成功)。
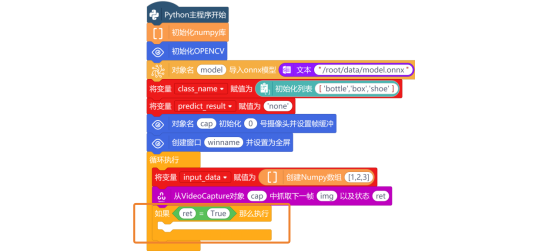
判断条件为真时,说明成功读取了帧,使用“对象名 将图片 转换为HSV格式”指令,将摄像头捕获的图像img从BGR颜色空间转换为HSV颜色空间。

接下来,使用“对象名 提取图片 的范围内像素 范围下限 范围上限 并进行形态学去噪”指令,通过设定范围上限和范围下限的阈值,进行颜色分割,得到我们感兴趣的物体区域。范围下限与范围上限,使用“创建Numpy数组 ”指令,设置下限为“[40,50,50]”,上限为“[100,255,255]”。

图片分割成功后,使用“对象名 剪裁图像 中最大的轮廓 宽 高 并处理数组维度”指令,设置宽为32,高为32,对分割出来的区域进行轮廓检测,来定位可能的物体。
注意:设置宽为32,高为32,是因为要与模型训练的图像尺寸一致。

最后,使用“显示图片img并设置图片名称“Mind+.png””指令,将抓取的图像显示在创建的行空板窗口中,并使用“每1毫秒刷新图像”指令,不断地刷新图像,将摄像头中的视频流显示在行空板上。

3. 图像预测与展示
模型预测前,需要使用“获取数据 的格式”指令,检查提取的图像区域是否符合模型所期望的输入形状。使用条件判断指令“如果……那么执行”,判断“获取数据 变量input_data的格式”是否为(1,32,32,1)。
注意:在条件(1,32,32,1)中,第一个1表示单个样本;两个32分别表示高度和宽度为32像素;最后一个1表示通道参数。

当条件为真时,说明剪裁的图像符合图像预测模型。使用“对象名 用ONNX模型 预测图片数组 ”指令,将变量input_data作为预测图片数组,加载到ONNX模型中,进行预测。

通过“将预测结果 映射到分类 ”指令,从模型输出中提取概率最高的类别标签,并将其名称赋值给变量predict_result。

最后,使用“打印”指令,将预测结果打印出来,完整程序如下:
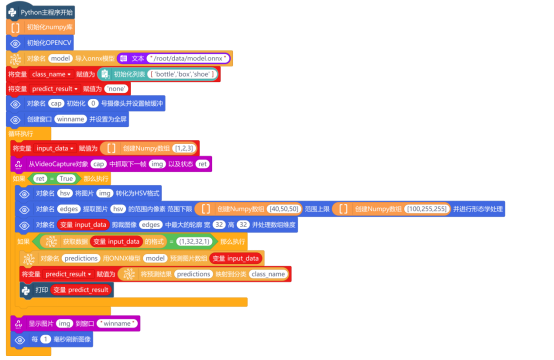
3. 程序运行
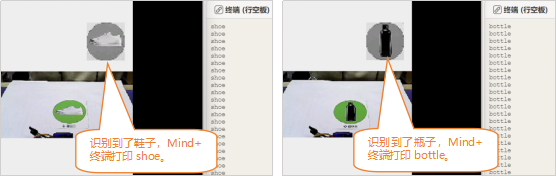
远程连接192.168.1.80,连接成功后,点击运行。程序运行成功后,行空板上显示摄像头检测到的画面,当识别鞋子、纸箱、瓶子卡纸中的物体时,Mind+终端打印出货物名称。
知识园地
1. 卷积神经网络算法的训练过程
使用卷积神经网络算法训练模型,主要是为了解决物体识别问题。而训练模型程序大致分为5个部分:导入数据集、数据预处理、创建神经网络、训练模型、保存模型。
1. 导入数据集:首先需要将准备好的用于训练的图片数据集导入。
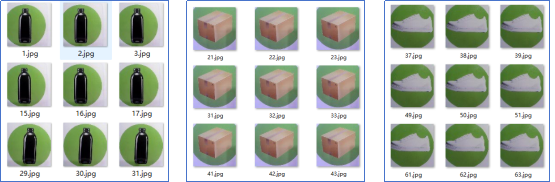
2. 数据预处理:在训练模型之前,需要对数据进行预处理以准备好输入模型。数据预处理包括对图像进行缩放、裁剪、标准化等操作,提高模型的训练效果。

3. 创建神经网络:根据识别要求,设计并创建卷积神经网络。包括合适的网络结构、确定卷积层、池化层、全连接层的数量和大小,以及选择合适的激活函数和优化算法,这个项目就是利用TensorFlow来构建模型。其中,包括3层卷积层、3层池化层、1层展平层、两层dense层。

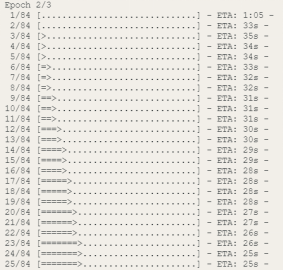
4. 训练模型:将准备好的数据输入到神经网络模型中进行训练。通过迭代的方式,将数据输入到模型中,计算损失函数并更新模型的参数。这个过程通过多次迭代和调整参数来优化模型,使其逐渐收敛到最佳状态。其中Epoch2/3,表示在三个训练周期中的第二个周期。
5. 保存模型:保存模型前,有一个主要的步骤是评估模型。使用独立的验证集或测试集对训练得到的模型进行评估。通过计算模型在验证集或测试集上的准确率、精确率、召回率等指标,来评估模型的性能和泛化能力。根据评估结果,可以调整模型的超参数或进行进一步的优化。

最后,将训练好的模型保存下来,以便后续在应用中的使用。

2. 卷积神经网络算法的实现过程
神经网络算法的实现过程如下,相比传统的机器学习算法,神经网络算法最大的优势是免去了繁琐的特征工程,由算法自动发现数据潜在特征。
3. 指令学习
 | 这条指令用于获取图像的高度、高度和通道数。 |
 | 这条指令主要是用于调整图像的大小,改变图像内容的显示比例。 |
 | 这条指令是将图像进行水平翻转。 |
 | 这条指令主要是用于对图像进行裁剪操作,只保留裁剪区域。 |
 | 这条指令主要是用于在图像上添加文本。 |
 | 这条指令主要是用于将两条路径进行有效合并,确保生成的路径符合操作规范。 |
 | 这条指令主要是用于加载训练集和验证集的图像数据。 |
 | 这条指令主要是用于创建神经网络结构。 |
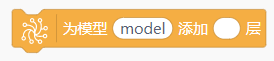 | 这条指令主要是用于根据具体的神经网络需求,为模型添加不同类型的层。 |
 | 这条指令需要与添加层指令一起使用,为结构添加池化层,常用于减少图像尺寸和参数数量,同时保留主要特征。 |
 | 这条指令需要与添加层指令一起使用,为结构添加展平层,将多维的输入数据(如二维的图像数据)展平为一维。这样做的目的是将卷积层或者池化层输出的多维数据展开。 |
 | 这条指令需要与添加层指令一起使用,为结构添加Dense层,接收展平后的特征数据,并在每个神经元上执行加权求和和激活函数操作。 |
 | 这条指令需要与添加层指令一起使用,为结构添加卷积层,对输入的图片数据进行卷积操作,以便从局部区域中提取特征。 |
 | 这条指令用于打印模型的结构。 |
 | 这条指令的作用是为 Keras 模型配置训练过程中的优化器、损失函数和评估指标。 |
 | 这条指令的作用是启动训练过程,通过传入训练数据生成器和验证数据生成器,指定训练的轮数、每个批次的样本数量等参数,来训练神经网络模型。 |
 | 这条指令主要用于将训练好的模型进行保存。 |
 | 这条指令的作用是将保存好的TensorFlow模型转换为ONNX格式。 |
 | 这条指令主要是用于将保存的ONNX模型进行导入。 |
 | 这条指令的作用主要用于获取的图像区域是否符合模型所期望的输入形状。 |
 | 这条指令的作用主要是用于通过ONNX模型,对输入的图像进行预测。 |
 | 这条指令主要的作用是将预测的结果,进行映射,返回识别结果。 |
| 注意:这节课学习到了很多与神经网络相关的指令,因此,挑战自我的任务就是尽可能熟悉这些指令。 | |



 他的勋章
他的勋章

罗罗罗2025.11.17
666