 返回首页
返回首页
 回到顶部
回到顶部

步骤1 一、开篇:当 AI 遇见甲骨文
说实话,刚开始想到这个项目的时候,我自己都觉得有点"硬核"——居然想用目标检测模型去识别甲骨文?但作为一名做了十几年嵌入式、又爱折腾创客教育的玩家,我骨子里就是喜欢挑战这种"看起来不太搭界"的组合。
甲骨文是什么?那是 3000 年前商朝人刻在龟甲兽骨上的文字,是中国最早的文字体系。目前已发现的甲骨文有十多万片、数十万字,但其中还有大量至今没有被破译。传统的甲骨文研究高度依赖少数专家,普通人想认识几个甲骨文字,基本只能靠翻大部头的字典。
我想做的是:让一台巴掌大的 AI 设备,能够像识别猫狗一样识别甲骨文字形,然后用语音告诉你这是哪个字、什么意思。
经过一番实践,从数据采集、模型训练,到边缘部署、MCP 联动,整条链路我已经全部跑通了。
核心亮点速览
- 数据来源硬核:基于华中科技大学团队构建的 HUST-OBS 数据集训练,该数据集支撑了 ACL 2024 最佳论文
- 全链路闭环:从原始数据 → YOLO 训练 → 二哈识图二部署 → MCP 接入小智 AI,全部打通
- 技术创新:原图保持原样、画布放大补白、精确标注框训练策略,让模型真正学会识别字形而非图片背景
- 边缘端运行:6 TOPS 算力的二哈识图二本地推理识别,DF-K10 实时展示结果并语音介绍
步骤2 二、项目背景:为什么选择甲骨文?
2.1 甲骨文的现状
甲骨文发现至今已经 120 多年了,但破译工作进展缓慢。2019 年中国文字博物馆第一次公示释读成果,只有一个人拿到一等奖;2023 年第二次公示,一等奖也才两个人。不是因为专家不够努力,而是甲骨文真的太复杂了——同一个字可能有十几种不同写法,字形随时代、地域变化很大。
2024 年,华中科技大学白翔教授团队发表了一篇论文《Deciphering Oracle Bone Language with Diffusion Models》,用扩散模型辅助甲骨文破译,拿到了 ACL 最佳论文。这说明 AI 在甲骨文研究中的潜力是被学术界认可的。
但问题是,这些研究大多停留在论文和实验室里。普通人想接触?太难了。我就想,能不能把这套能力做进一个拿在手里的设备,让谁都能用?
2.2 为什么选择 Mind+ V2?
作为一个玩惯了 Arduino、ESP32、树莓派的老玩家,我其实可以手写 PyTorch 训练脚本,也可以自己用 TensorFlow 部署模型。但这次我想尝试一种更"创客友好"的方式——Mind+ V2。
Mind+ V2 的模型训练功能有几个优势特别吸引我:
- 图形化界面,从数据导入到模型导出一条龙,不需要写一行训练代码
- 内置 YOLO 目标检测训练流程,对创客教育场景非常友好
- 导出模型可以直接部署到 DFRobot 自家的二哈识图二,生态闭环
- 专业模式还提供了高级参数调整,老手也能玩得转
事实证明,这个选择是对的。整个训练流程比我预想的还要顺畅。


步骤3 三、数据来源与处理:找到"对"的数据集
3.1 选型经历:找数据比训练还难
做 AI 项目,数据是第一步。我一开始去魔搭社区(modelscope.cn)搜了一圈,关键词"甲骨文",结果要么数据量太少(几百张),要么标注质量不行,要么图片都是黑白的拓片扫描件,不适合做目标检测。
接着又去百度 AI Studio 翻数据集,搜出来的大多是汉字书法数据集、古籍文字识别数据集,和甲骨文完全不是一回事。
最后在 HyperAI 超神经平台上找到了 HUST-OBS(后来 GitHub 上改名为 HUST-OBC)。一看数据量:14 万张图片,1588 个已破译类别——这就是我要的数据。
3.2 HUST-OBS 数据集详解
- 全称:Huazhong University of Science and Technology Oracle Bone Script
- 构建机构:华中科技大学、华南理工大学、阿德莱德大学、安阳师范学院
- 相关论文:「An open dataset for oracle bone script recognition and decipherment」
- 论文荣誉:ACL 2024 最佳论文(没错,就是那个用扩散模型破译甲骨文的论文)
- 数据集地址:https://hyper.ai/cn/datasets/33506
- GitHub 仓库:https://github.com/Pengjie-W/HUST-OBC
数据规模:
- 已破译字符:1,588 个类别,77,064 张图像
- 未破译字符:9,411 个类别,62,989 张图像
- 总计:140,053 张图像
数据来源:
- X:《新编甲骨文》(书籍扫描)
- L:《甲骨文:六码数字代码》(书籍扫描)
- G:国学大师网站
- Y:殷契文渊网站
- H:HWOBC 现有数据集
所有图片和标签都经过甲骨文研究专家审阅和校正。数据质量非常高。
3.3 数据集结构:比想象的复杂
下载解压后,目录结构是这样的:
HUST-OBC/
├── deciphered/ # 已破译字符(训练+测试来源)
│ ├── 0001/
│ │ ├── G_0001_粹622合13155賓組.png
│ │ ├── H_0001_60BB6_0.png
│ │ └── ...
│ ├── 0002/
│ ├── 0011_0012_0013/ # 合并目录!
│ │ ├── 0011/
│ │ ├── 0012/
│ │ └── 0013/
│ └── ID_to_chinese.json # 0001→"㐁" 的映射
├── GuoXueDaShi_1390/ # 验证集来源
│ ├── 0001/
│ ├── 0002/
│ └── ID_to_chinese.json
└── undeciphered/ # 未破译字符
注意那个 0011_0012_0013——这种合并目录里面有多个子目录,需要递归遍历到最底层的 4 位数字目录才能正确归类。
3.4 图片预处理:原图保持,画布放大
这是整个数据处理中最关键的一步。
原始甲骨文字形图片大小不一,有的只有 100×150 像素,直接训练的话模型很难学到稳定的特征。但如果简单拉伸放大,又会破坏字形的原始比例。
我的方案是:原图保持原样,居中放置,四周填充白色背景,画布尺寸是原图的 2 倍。
举个例子:
- 原图:119×205 像素
- 画布:238×410 像素(2 倍)
- 原图居中粘贴,四周留白
这样做的好处:
- 原图不拉伸,字形特征完全保留
- 画布统一放大,模型输入尺寸更稳定
- 白色背景让模型注意力集中在中心字形上
| 原图 | 处理后 |
|---|---|
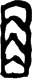 |  |
3.5 精确 YOLO 标注:不只覆盖整张图
传统的全图标注是 0 0.5 0.5 1.0 1.0(中心 0.5,0.5,宽高都是 100%)。但如果这样做,标注框会覆盖整个画布,包括四周的白色背景。模型训练时就会学到"白色背景也是目标的一部分"——这显然是错的。
我的标注策略是精确反映原图在画布中的位置:
- 中心点:(0.5, 0.5)——原图居中
- 宽度:原图宽 / 画布宽 = 119/238 = 0.5
- 高度:原图高 / 画布高 = 205/410 = 0.5
所以标签内容是:0 0.5 0.5 0.5 0.5
这样模型学到的就是"识别画布中心区域的那个字形",而不是"识别整张图片"。这个细节对后续推理精度影响很大。
3.6 数据集过滤与规模
不是所有类别都适合做目标检测训练。我加了两个过滤条件:
- 验证集存在性:只保留同时存在于 GuoXueDaShi_1390 中的类别(确保有独立的验证来源)
- 训练图片数量:只保留训练图片 >= 20 张的类别(样本太少训不出东西)
最终我生成了几个不同规模的数据集用于不同阶段:
| 数据集 | 类别数 | 训练图片 | 用途 |
|---|---|---|---|
| HUST-OBC-Selected | 10 | ~273 | 最小验证 |
| HUST-OBC-YOLO-100 | 100 | ~2,078 | 快速调试 |
| HUST-OBC-YOLO-1390 | 1390 | ~31,393 | 完整训练 |
小数据集用来快速验证流程,大数据集用来认真训练。
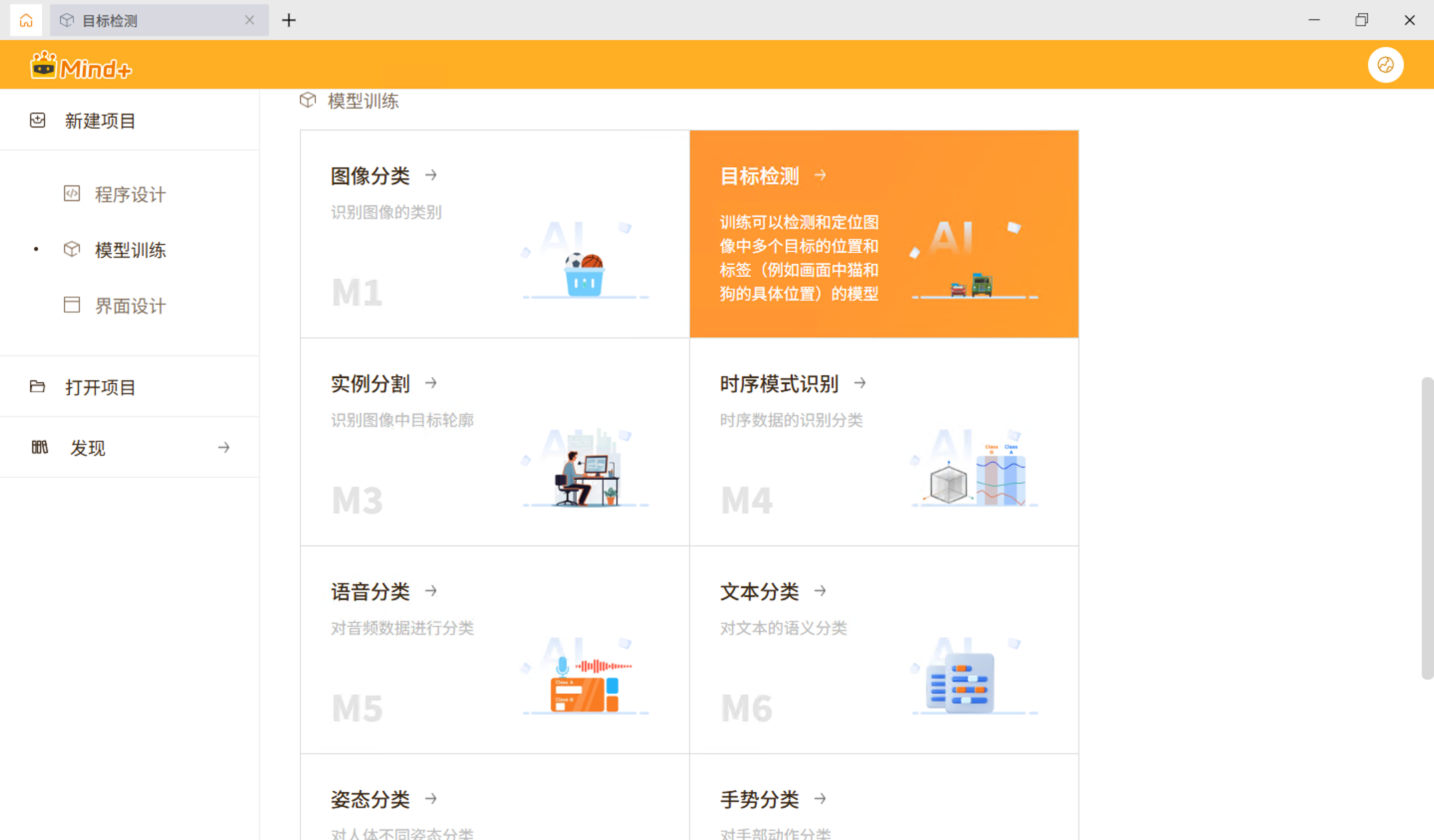
步骤4 四、模型训练:Mind+ V2 专业模式实战
4.1 进入专业模式
打开 Mind+ V2,菜单栏选择"模型训练"→"目标检测(M2)",然后点击右上角切换到"专业模式"。
专业模式比快速体验模式多了几个关键功能模块:数据设置、标注设置、模型训练、模型校验、模型部署。对于需要精细控制训练过程的项目来说,这些功能非常必要。
4.2 数据导入
在"数据设置"中创建新数据集,然后选择"导入数据"→"有标注数据(YOLO 格式)"。
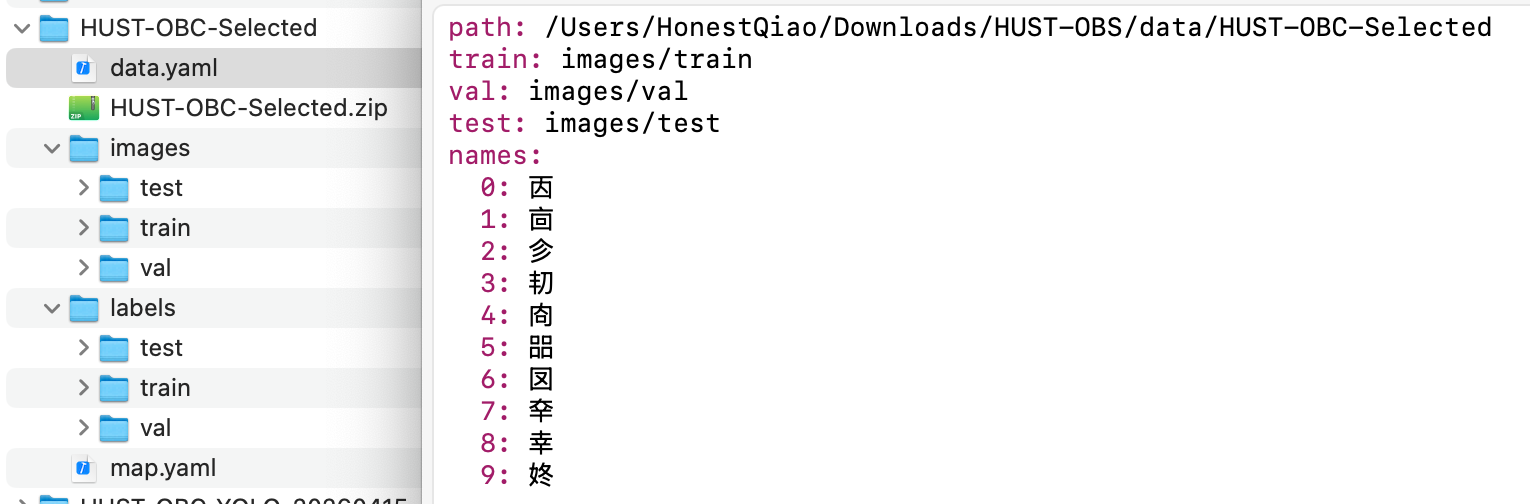
YOLO 格式要求:
dataset.zip/ ├── images/train/0001/xxx.jpg ├── images/test/0001/xxx.jpg ├── images/val/0001/xxx.jpg ├── labels/train/0001/xxx.txt ├── labels/test/0001/xxx.txt └── labels/val/0001/xxx.txt
images/ 和 labels/ 目录结构严格对应,每张图片对应一个同名的 .txt 标签文件。
我前面用 Python 脚本 1_select_images.py 已经生成好了符合这个结构的数据集,直接打包成 zip 上传即可。
导入数据后,进入标注界面,可以看到已经标注好了: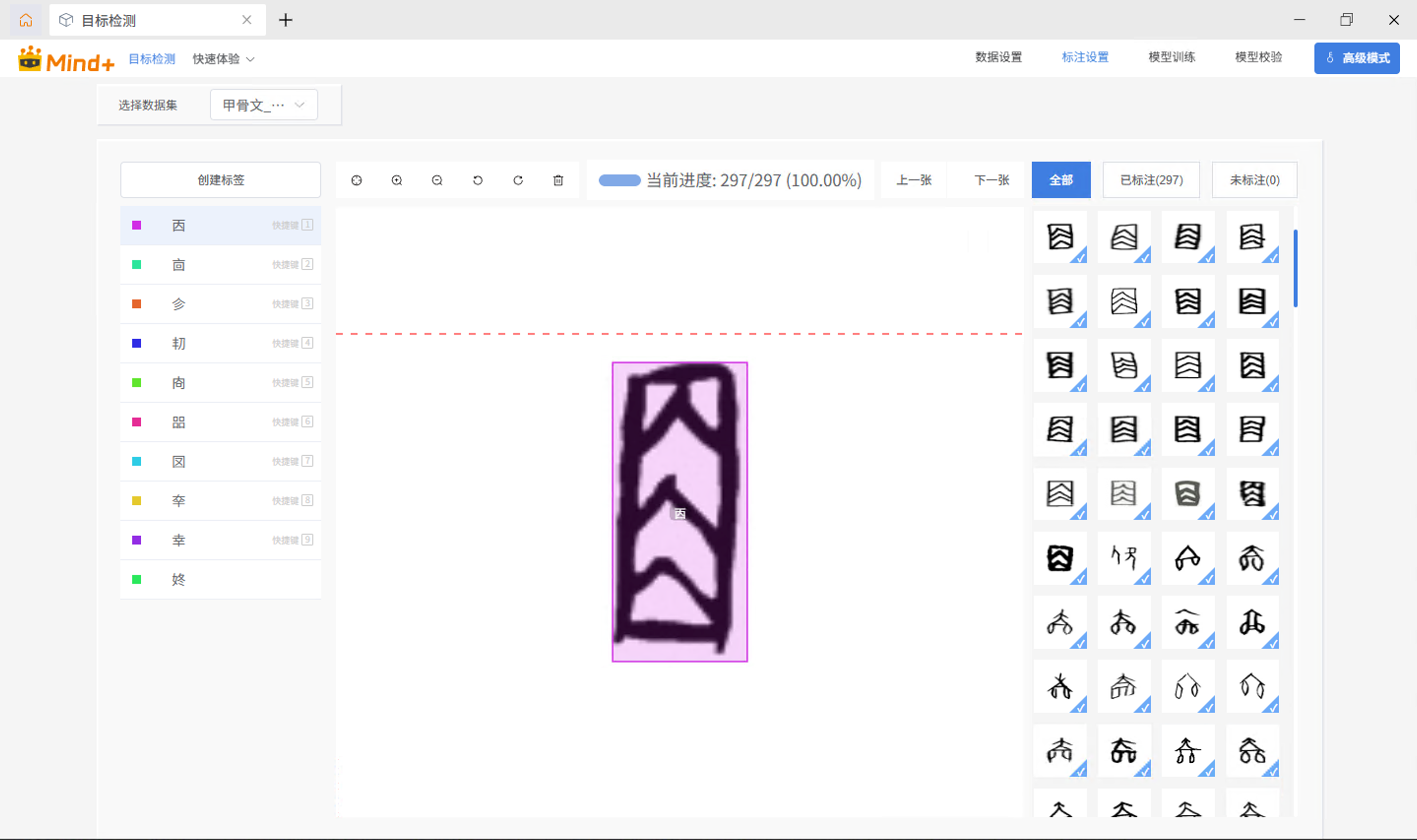
4.3 训练参数配置
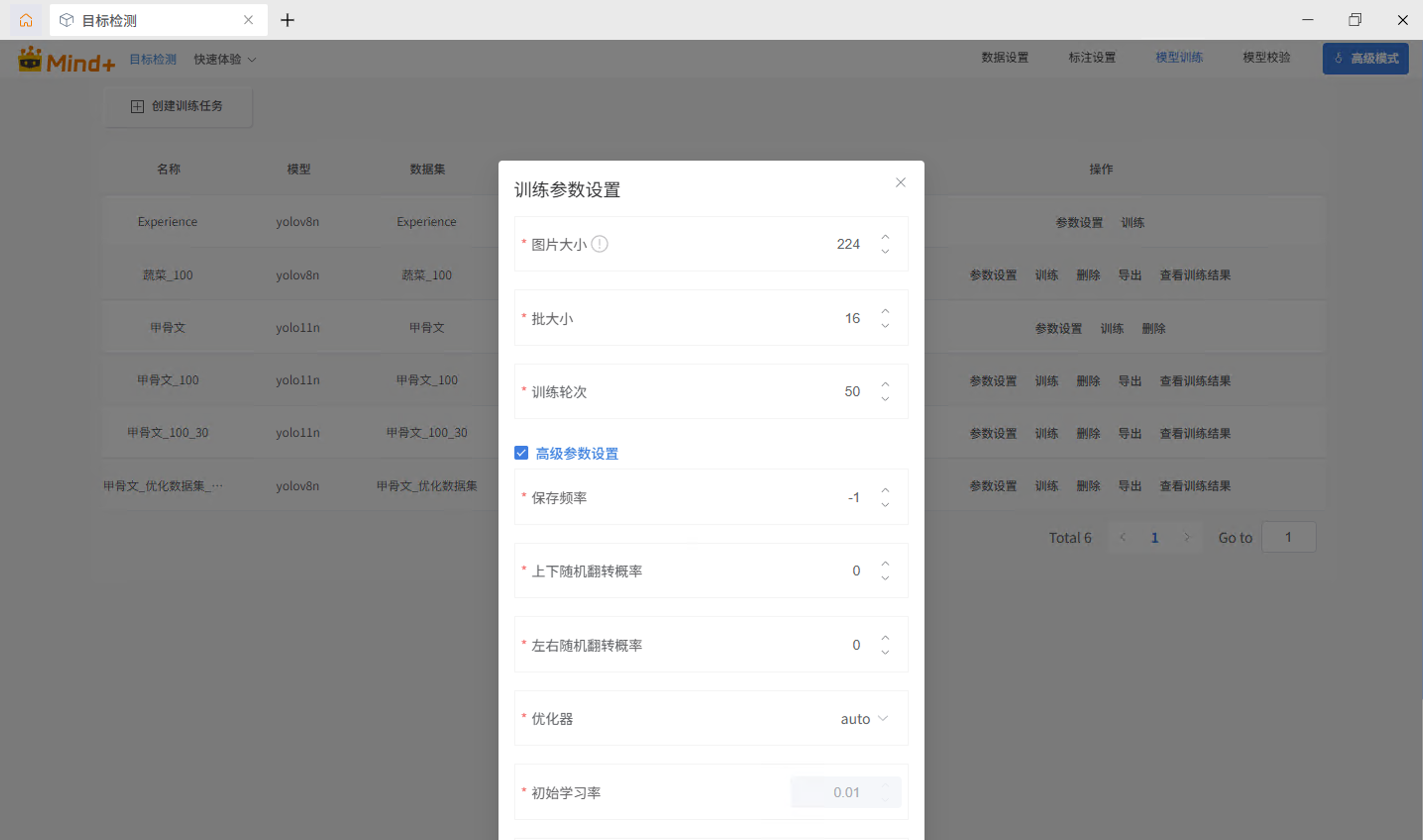
创建训练任务,参数设置如下:
| 参数 | 设置 | 原因 |
|---|---|---|
| 模型 | YOLOv11n | 轻量化,参数量小,适合部署到二哈识图二 |
| 训练类型 | 目标检测 | |
| 数据集 | 甲骨文识别 | 选择刚才导入的数据集 |
| 图片大小 | 224 | 默认,兼顾细节和速度 |
| 训练轮次 | 50 | 甲骨文细粒度分类,需要充分训练 |
| 随机左右翻转 | 0 | 默认 |
| 随机上下翻转 | 0 | 关闭!甲骨文上下翻转就不是同一个字了 |
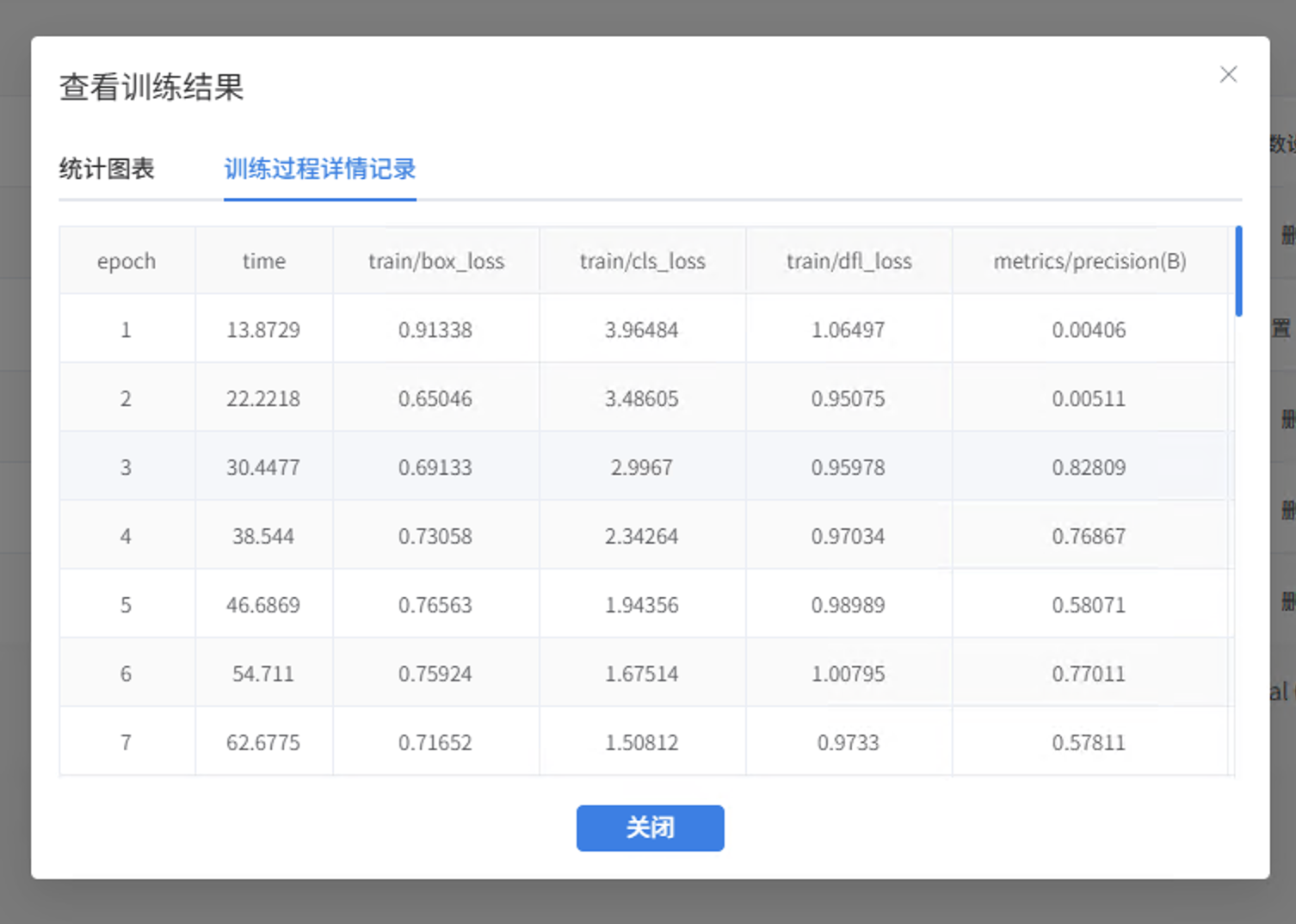
4.4 训练过程
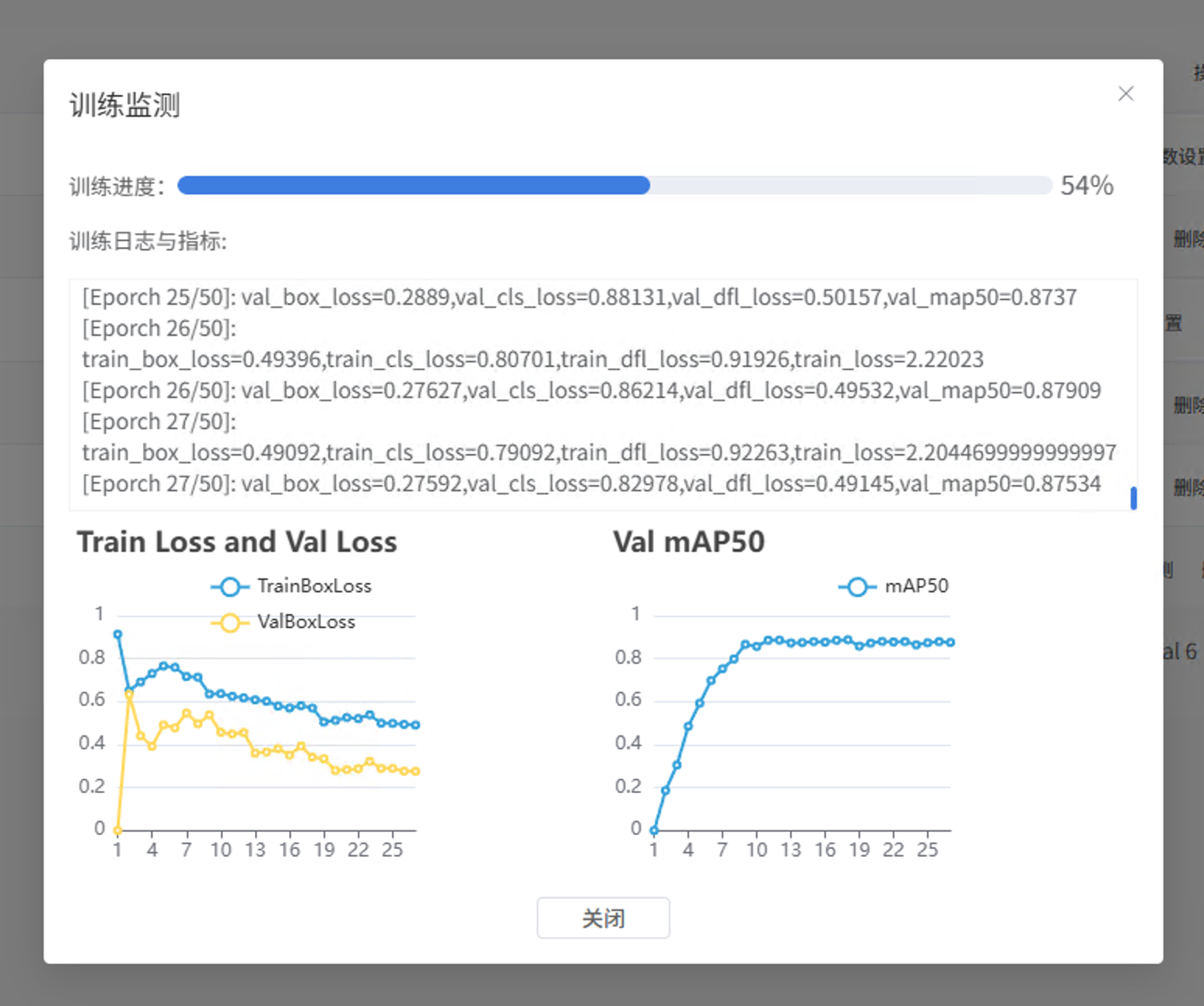
点击"训练"后,Mind+ 会自动开始训练。过程中可以通过"训练监测"窗口查看各项指标:
- train loss:训练集上的损失,越低越好
- val loss:验证集上的损失,反映泛化能力
- Val mAP50:验证集平均精度,目标检测的核心指标
4.5 模型校验
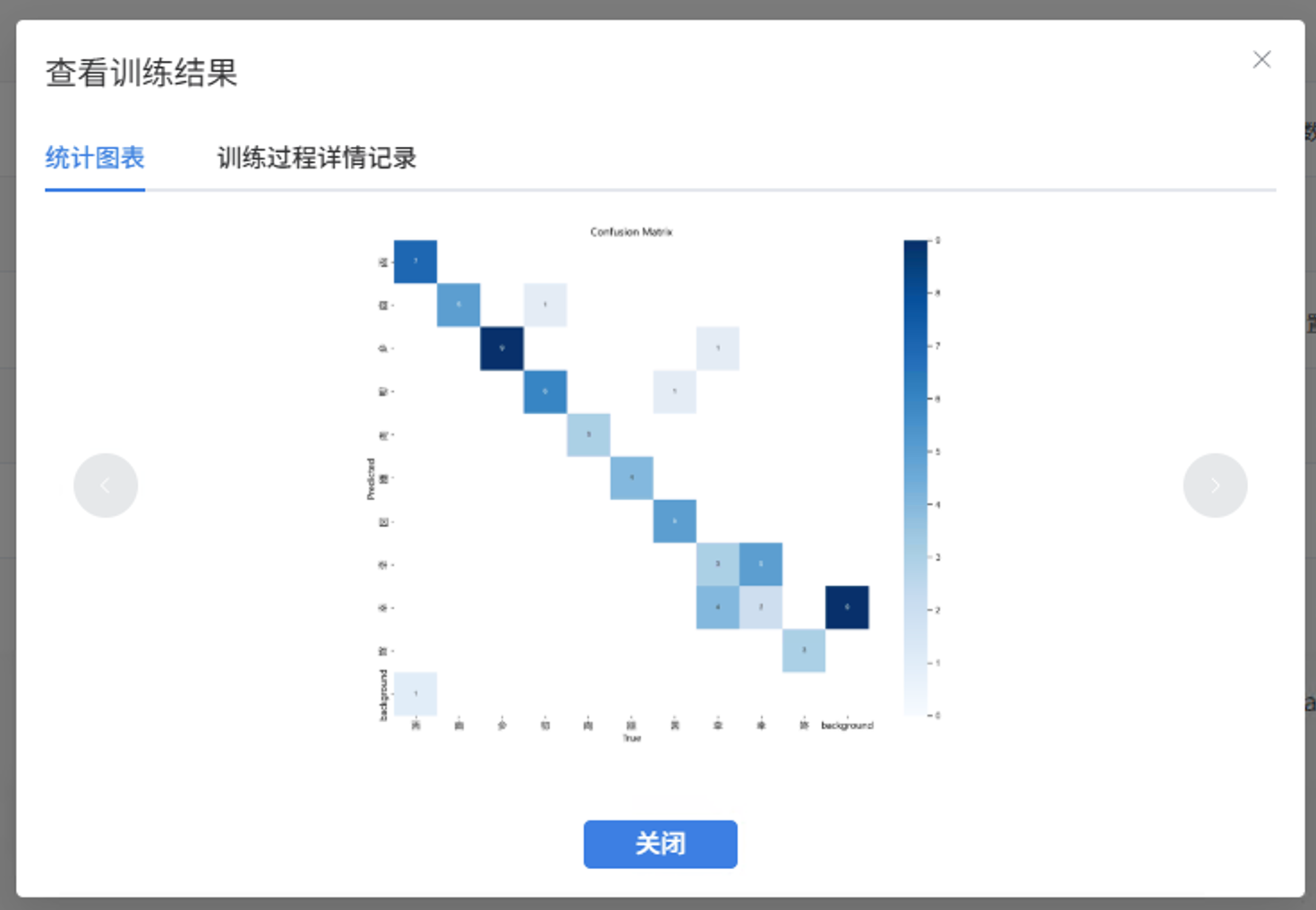
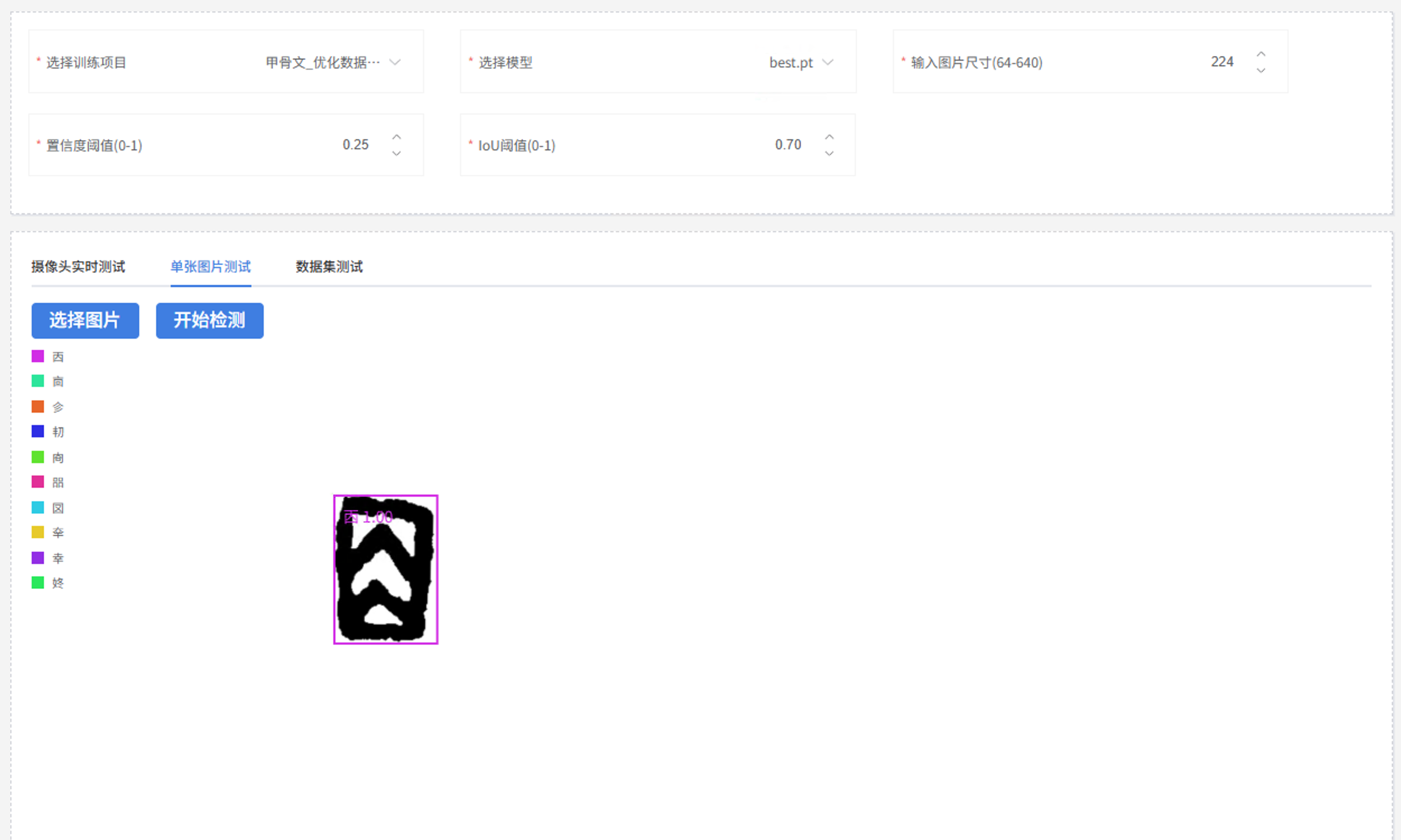
训练完成后,进入"模型校验"模块。我上传了几张不在训练集中的甲骨文图片进行测试,模型能正确框选字形并给出类别预测,置信度普遍在 0.75 以上。
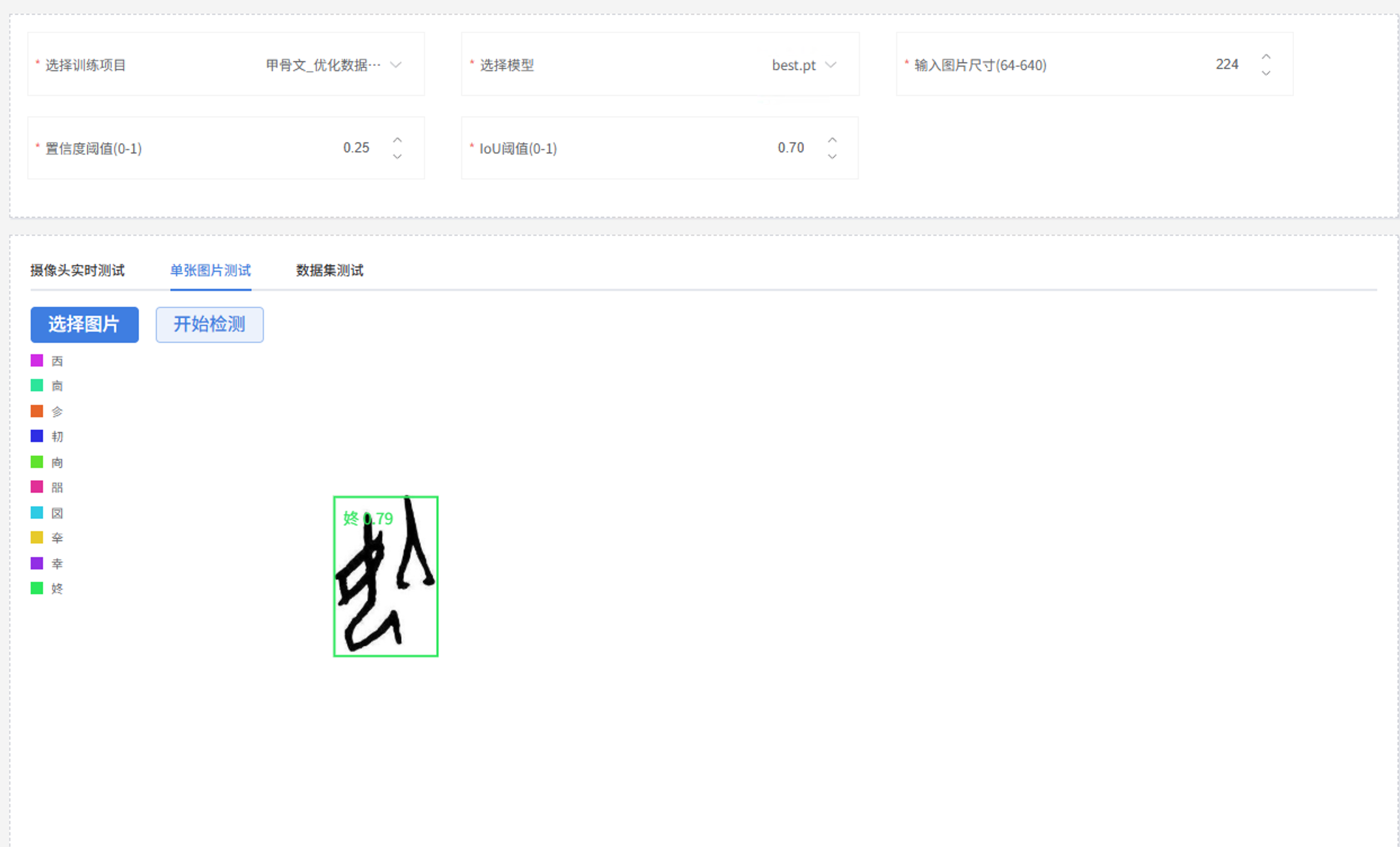
4.6 模型导出
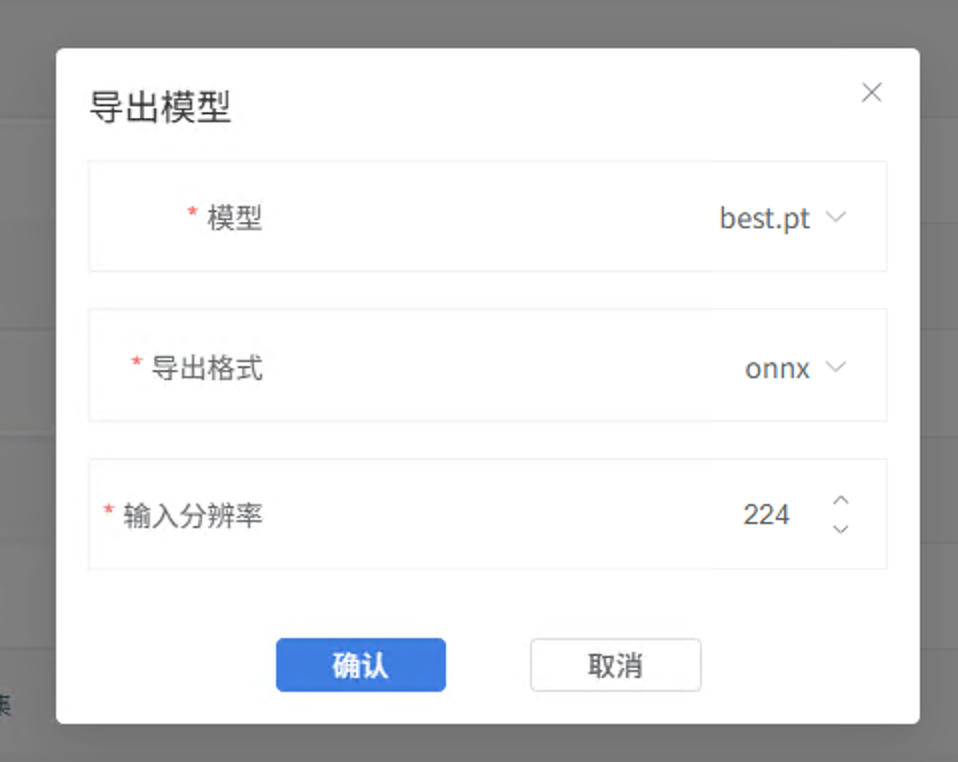
校验通过后,点击"导出模型",导出为 ONNX 格式。
然后,把数据集也做一次导出:
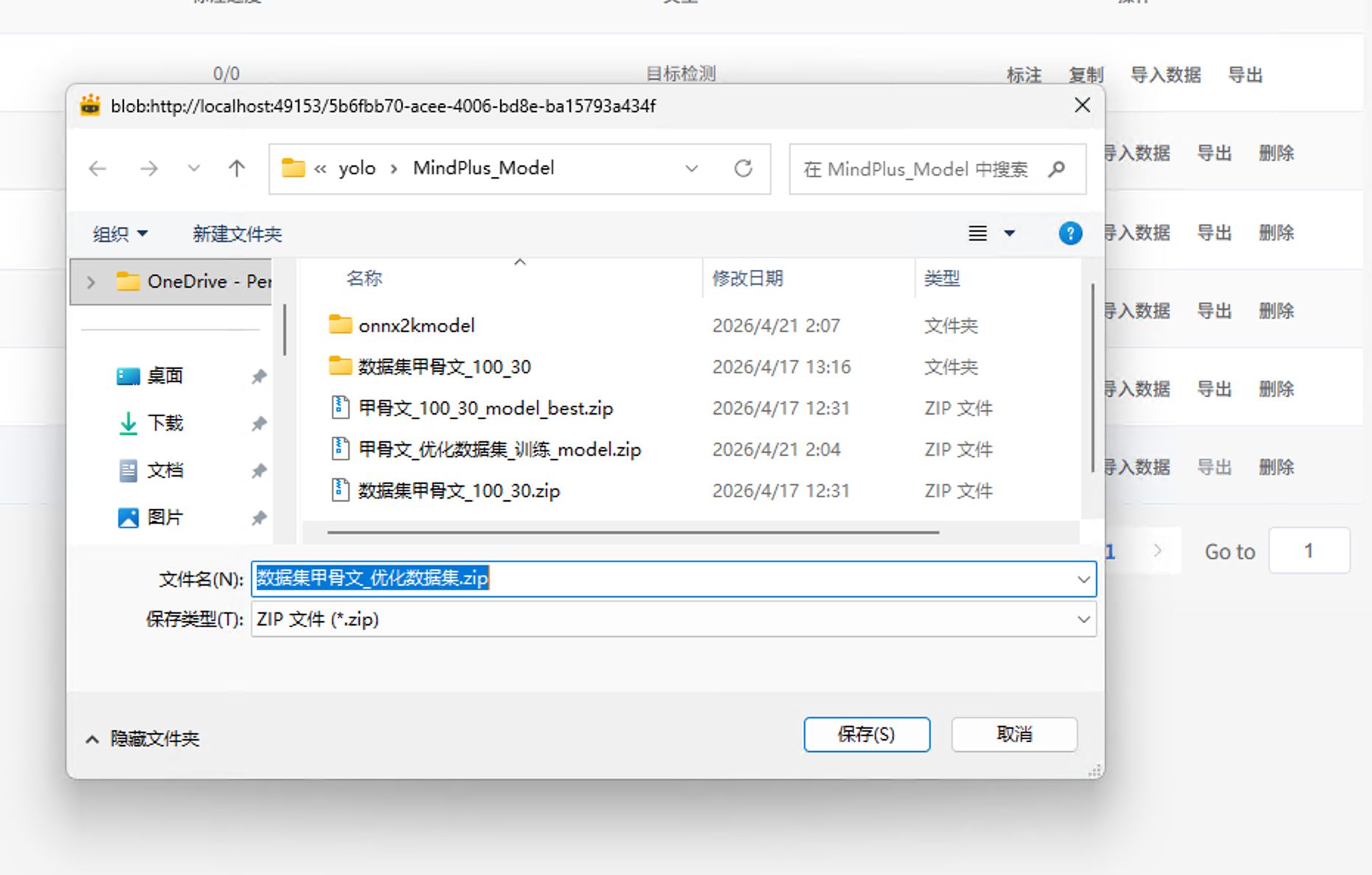
这两个文件是后续转换和部署到二哈识图二的关键。
步骤5 五、边缘部署:把模型塞进二哈识图二
5.1 二哈识图二简介
- 产品:Gravity HUSKYLENS 2 AI Camera Vision Sensor(SKU: SEN0638)
- 算力:6 TOPS
- 屏幕:内置 IPS 显示屏,实时显示识别结果
- 兼容平台:Arduino、树莓派、micro:bit、ESP32 等
- Wiki:https://wiki.dfrobot.com.cn/_SKU_SEN0638
二哈识图二预置了 20 多种 AI 算法(人脸识别、物体追踪、物体识别等),但甲骨文识别显然不在其中,需要自己训练模型部署上去。
5.2 模型转换与下载
我采用的是 二哈识图 2 使用教程 wiki 页面 8.2 Mind+ 无代码方式训练并部署模型(本地) 的流程,需要在本地搭建模型转换环境,然后在 Mind+ 中完成训练、导出,最后用本地工具打包成二哈识图二能识别的格式。
步骤一:本地环境准备
- 安装 .NET 7.0(Windows 64 位选 Windows x64)
- 安装 conda(Anaconda/Miniconda 均可)
- 在 Anaconda Powershell 中创建并激活独立环境:
mkdir MindPlus_Model cd MindPlus_Model conda create --name env312 python=3.12 conda activate env312
- 下载 DFRobot 官方的模型转换打包工具 onnx2kmodel-master,解压到 MindPlus_Model 文件夹中
- 安装依赖:
cd onnx2kmodel-master pip install -r requirements.txt pip install nncase_kpu-2.10.0-py2.py3-none-win_amd64.whl python app.py
- 保持工具窗口和 Powershell 不关闭,后面要用它来打包模型。
步骤二:本地模型转换打包
- 在 Powershell 中激活环境并启动转换工具:
conda activate env312 cd onnx2kmodel-master python app.py
- 在模型转换工具界面中:
- Select Mode 选择 MindPlus
- Select Model Package 上传刚才导出的 Experience_model 文件夹
- Select Dataset Package 上传刚才导出的 Experience 数据集文件夹
- Select Icon 上传应用图标(建议 60×60 透明背景白线 PNG)
- AppName 设置中文名称为「甲骨文识别」,英文名称为 Oracle Recognition
- 点击 Convert and Package 按钮,等待 "please wait" 提示消失、按钮恢复,即表示转换完成
- 在 MindPlus_Model\onnx2kmodel-master 文件夹中会生成一个新的 .zip 文件,这就是最终的模型安装包,不要对这个 zip 文件做任何修改
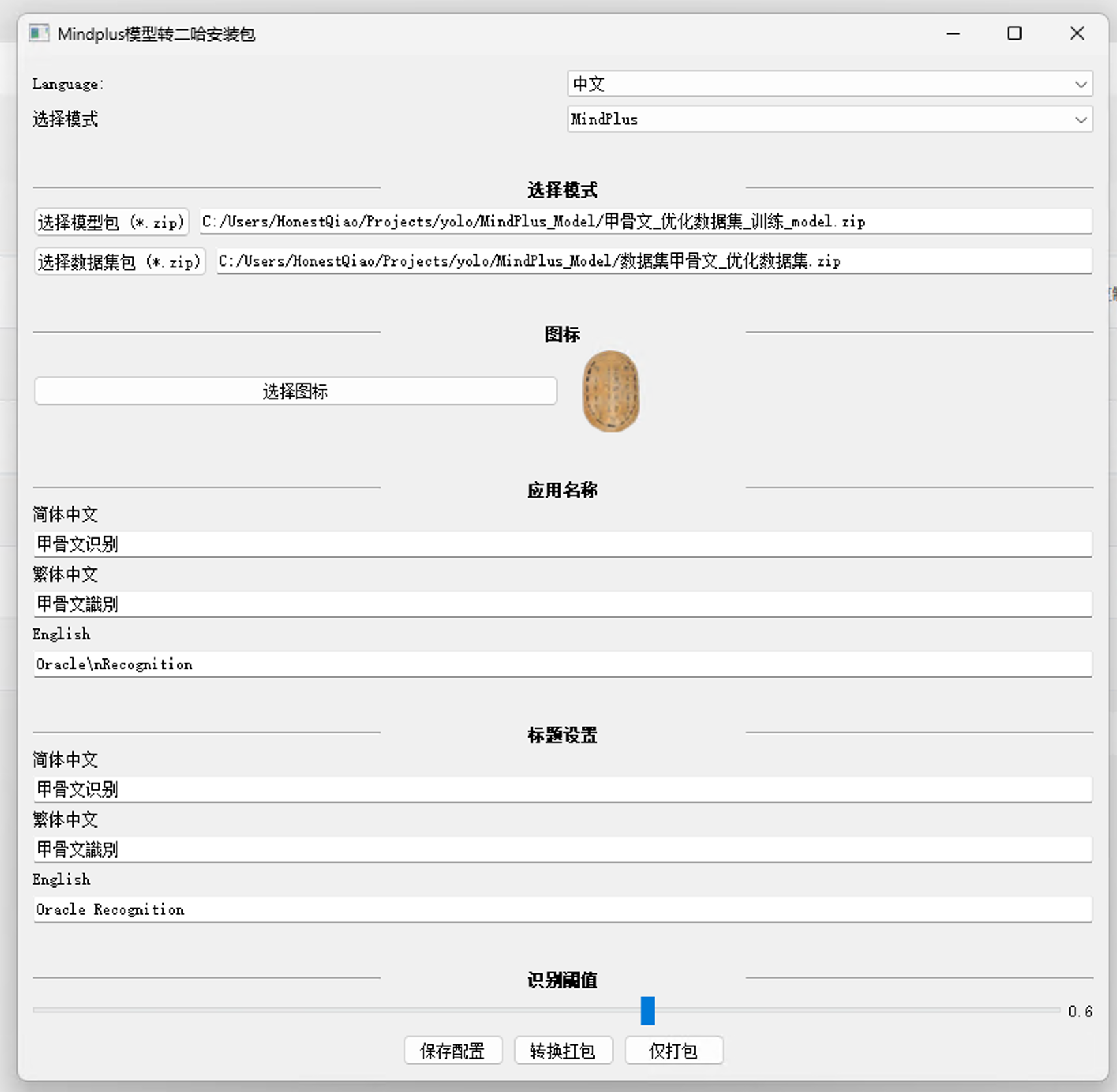

5.3 安装到二哈识图二
- 用 USB 数据线连接二哈识图二到电脑
- 电脑会出现一个名为 Huskylens 的硬盘设备
- 将 5.2 步骤中生成的模型 .zip 安装包,复制到 Huskylens\storage\installation_package 目录下
- 点击二哈识图二的屏幕,在主界面找到「模型安装」图标,点击进入
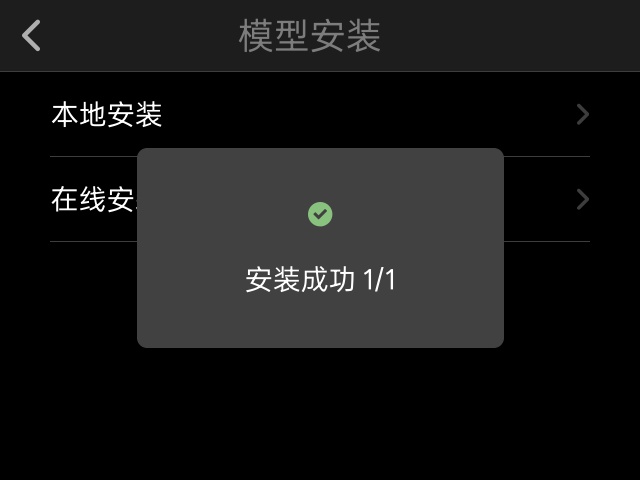
- 选择「本地安装」,系统会自动搜索并安装刚才拷贝的安装包
- 安装成功后,返回主界面,在应用列表中能看到「甲骨文识别」的图标
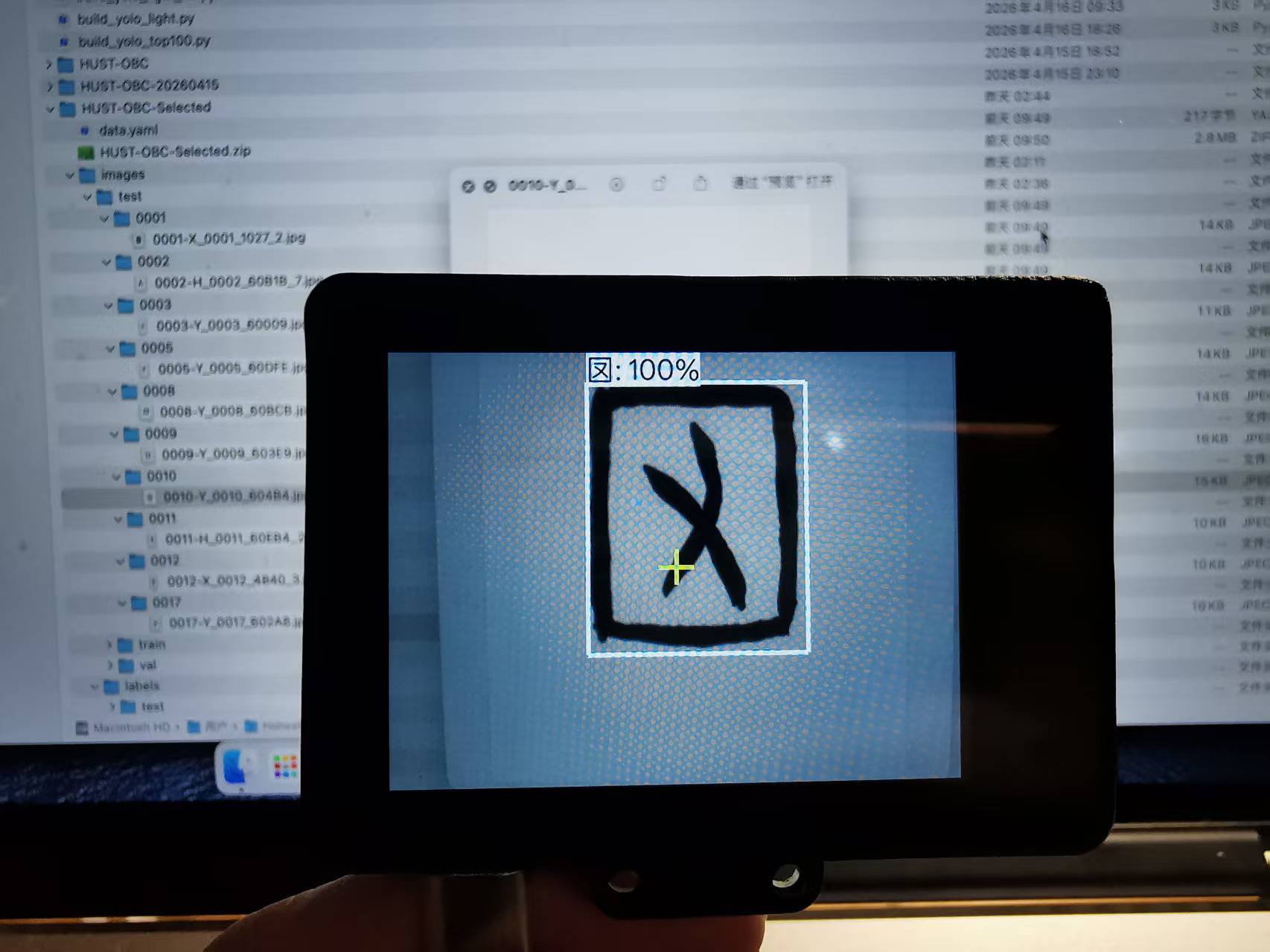
5.4 实际测试
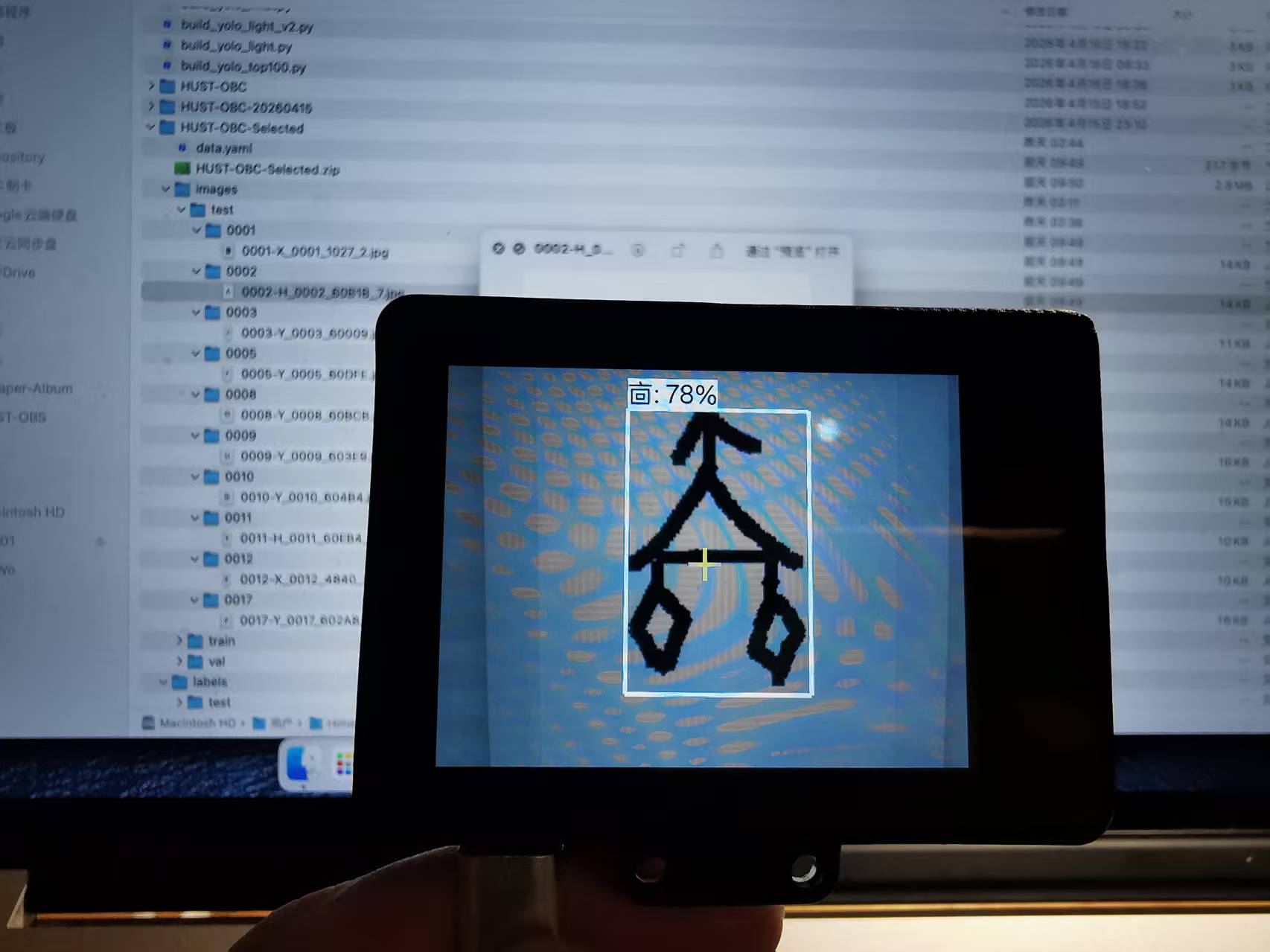
点击"甲骨文识别"图标进入应用,将摄像头对准甲骨文图片:
- 屏幕上会实时显示摄像头画面
- 检测到甲骨文字形时,会画出矩形框
- 框旁边显示类别名称和置信度
- 因为是本地推理,完全没有延迟
我测试了多张不同的甲骨文图片,识别效果稳定。
步骤6 六、MCP 联动:让大模型"看得见"
6.1 为什么需要 MCP?
到这一步,二哈识图二已经能独立识别甲骨文了。但我想要的不只是"识别"——我还想让 AI 告诉我这个字什么意思、有什么历史故事。
这就需要把二哈识图二的识别结果,传给一个能理解和表达的大模型。MCP(Model Context Protocol)就是干这个的。
MCP 是 Anthropic 推出的开放协议,允许大语言模型与外部工具标准化通信。简单说,它让 AI 可以"调用"摄像头、传感器这些硬件设备的功能。
6.2 系统架构
二哈识图二(摄像头 + YOLO 推理) ↓ WiFi + MCP 协议 xiaozhi-mcphub(MCP 网关,运行在电脑/服务器上) ↓ MCP 协议 小智 AI(运行在 DF-K10 上) ↓ LCD 显示 + 语音播报 用户
6.3 搭建 xiaozhi-mcphub
xiaozhi-mcphub 是连接二哈识图二和小智 AI 的核心枢纽。它本质上是一个 MCP 网关服务,同时管理多个 MCP 服务端点。
环境准备:
- Node.js 环境
- PostgreSQL 数据库(用于存储配置)
安装步骤:
# 克隆源码 git clone https://github.com/huangjunsen0406/xiaozhi-mcphub.git cd xiaozhi-mcphub # 配置数据库连接,编辑 .env 文件 # export DATABASE_URL="postgresql://用户名:密码@localhost:5432/db名" # 安装依赖并启动 pnpm install pnpm dev
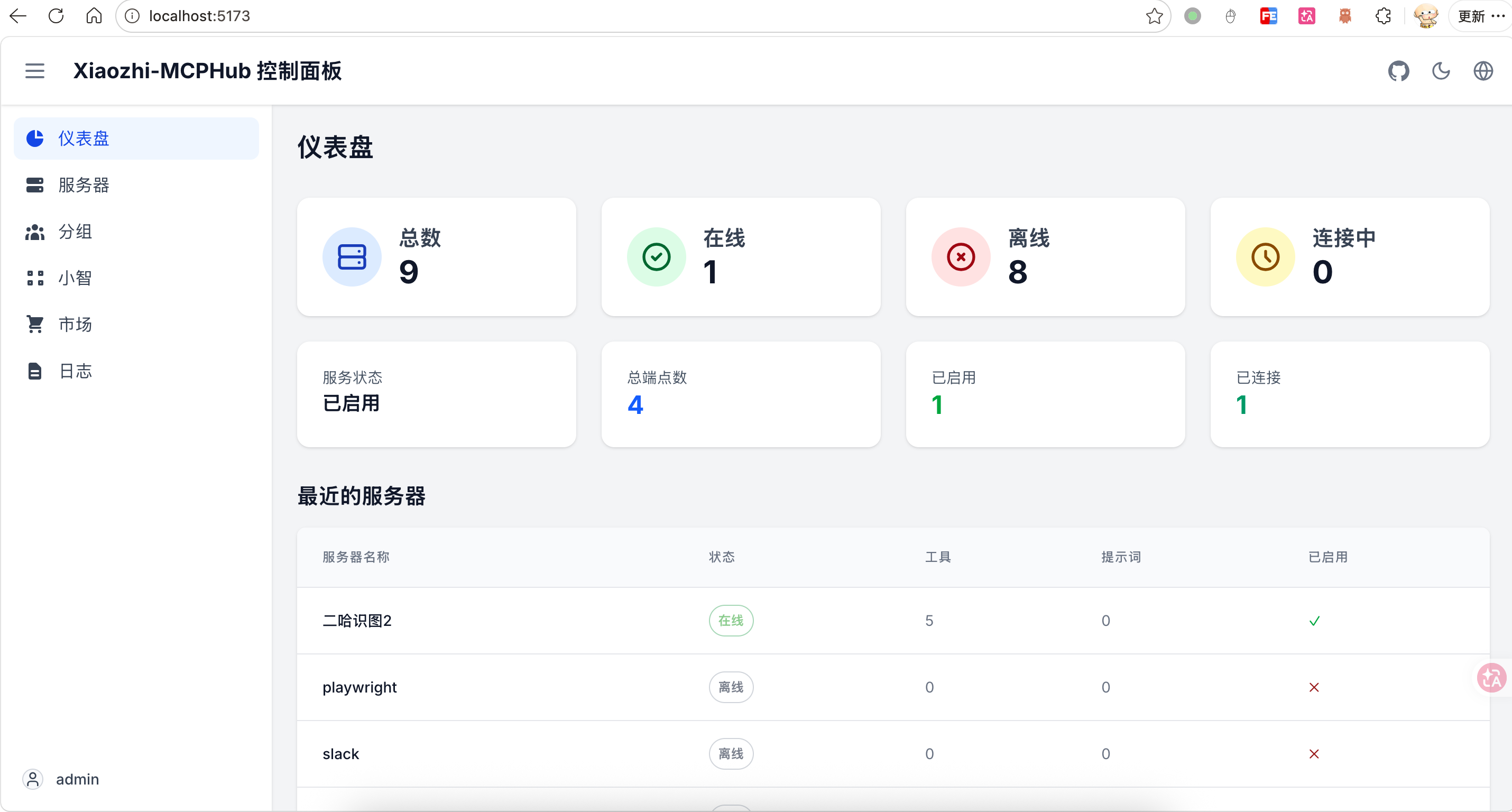
启动后访问 http://localhost:5173,用默认账号 admin / admin123 登录管理界面。

6.4 添加 MCP 服务端点
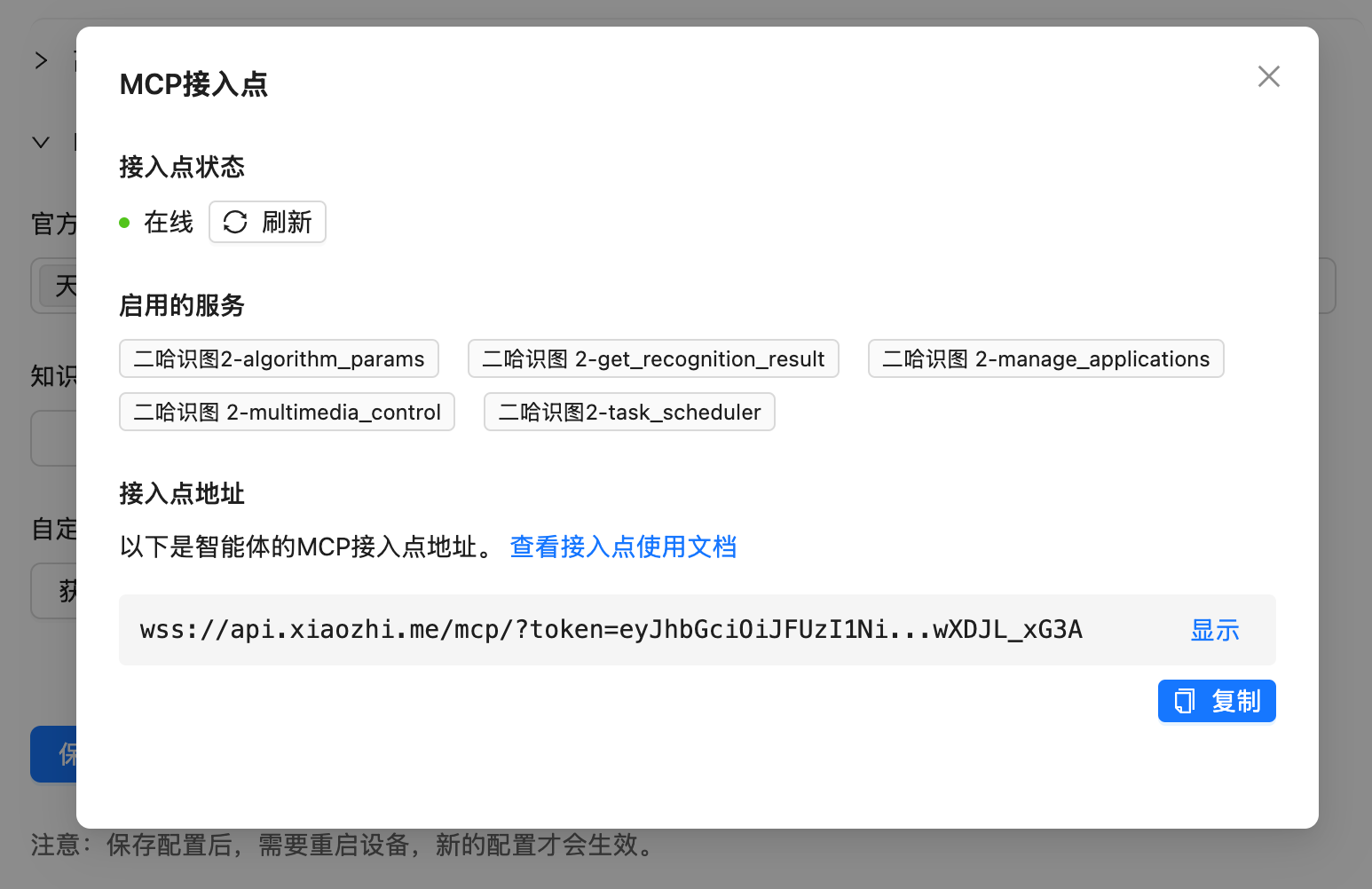
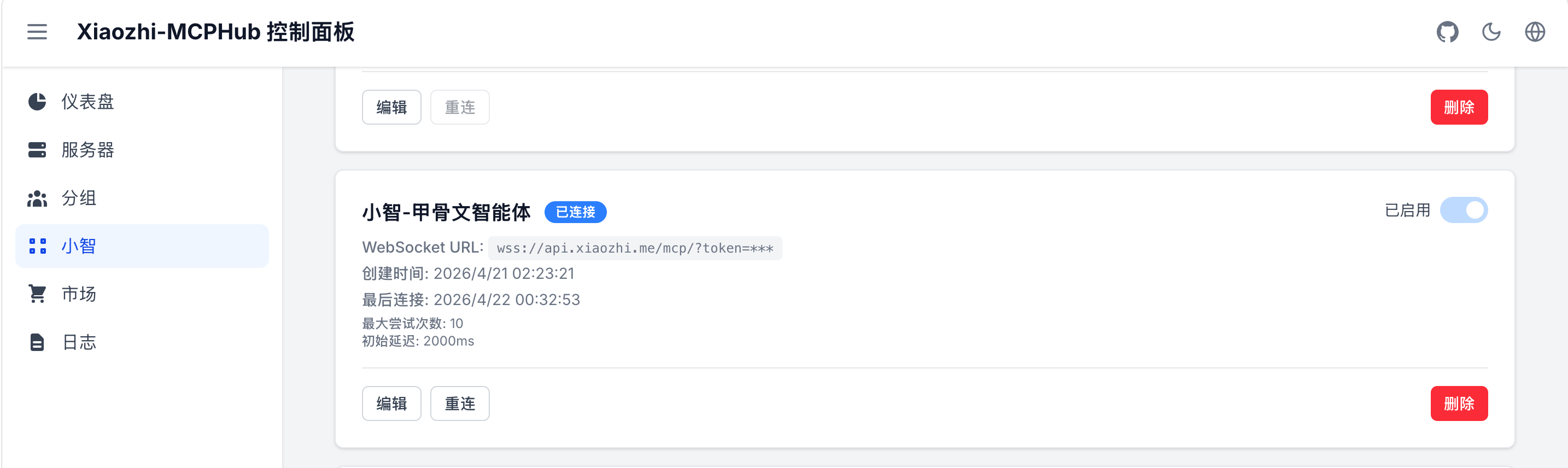
第一步:添加小智 AI 端点
- 登录小智 AI 后台(https://xiaozhi.me/)
- 找到 DF-K10 对应的智能体
- 点击"获取 MCP 接入点",复制地址
- 在 xiaozhi-mcphub 的"小智"页面中,添加该端点
第二步:添加二哈识图二 MCP 服务
- 给二哈识图二安装 WiFi 模块
- 在系统设置中连接 WiFi 网络
- 打开"MCP"应用,查看 MCP 服务地址
- 在 xiaozhi-mcphub 的"服务器管理"中,添加该地址
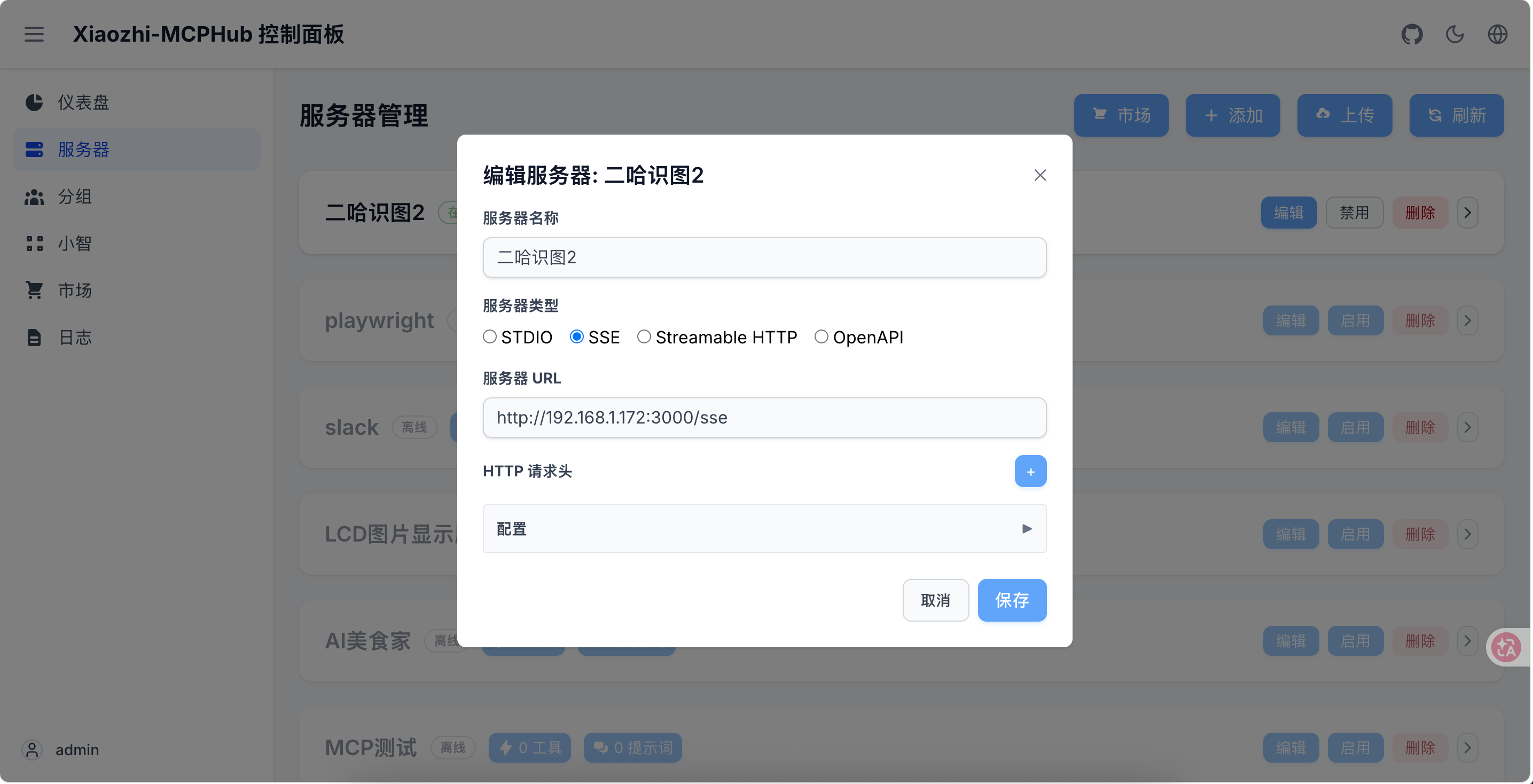
第三步:验证连接
如果一切正常,在 xiaozhi-mcphub 前端应该能看到二哈识图二提供的工具列表(如物体检测、分类检测等)。同时在小智 AI 后台也能看到启用的 MCP 服务。
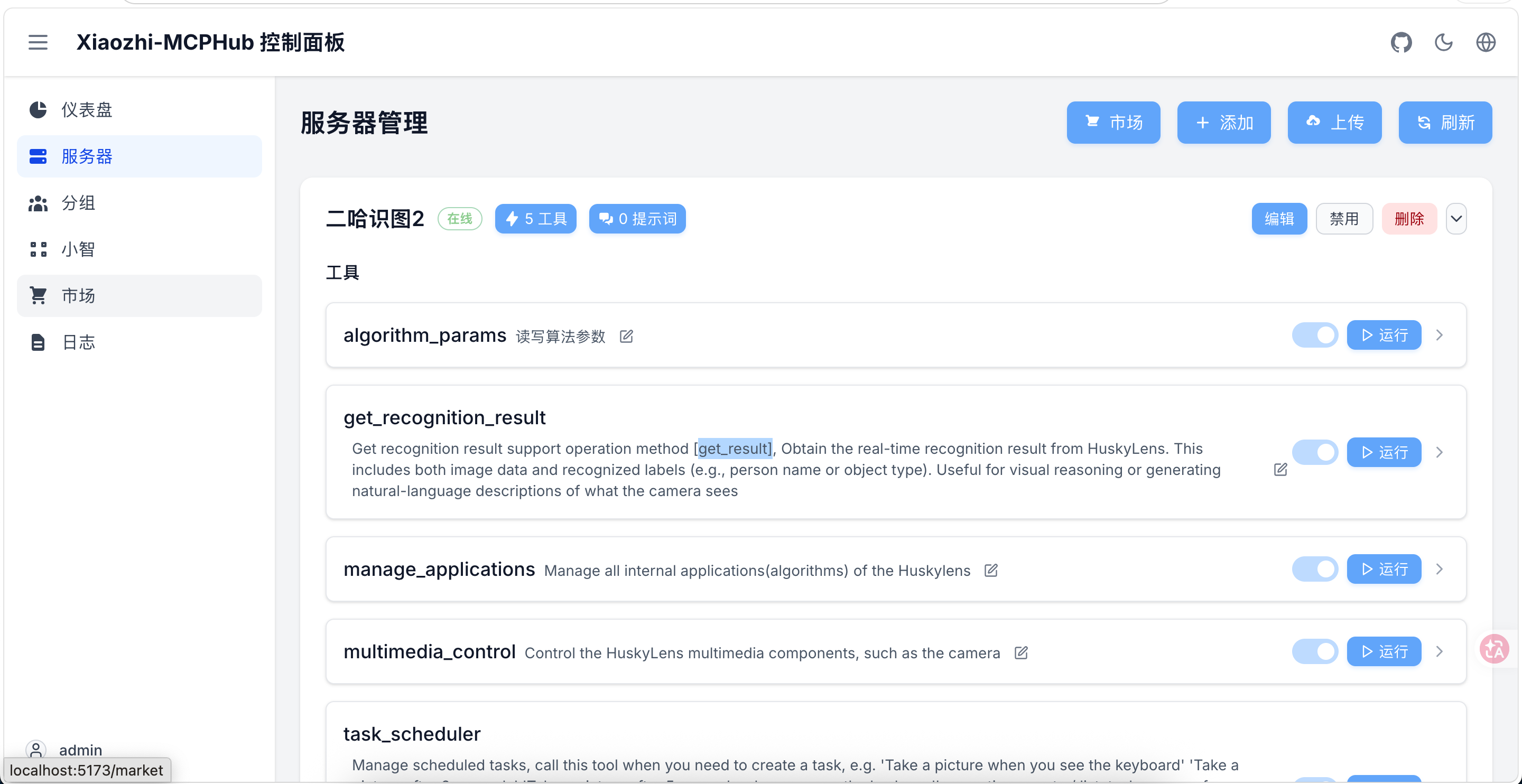
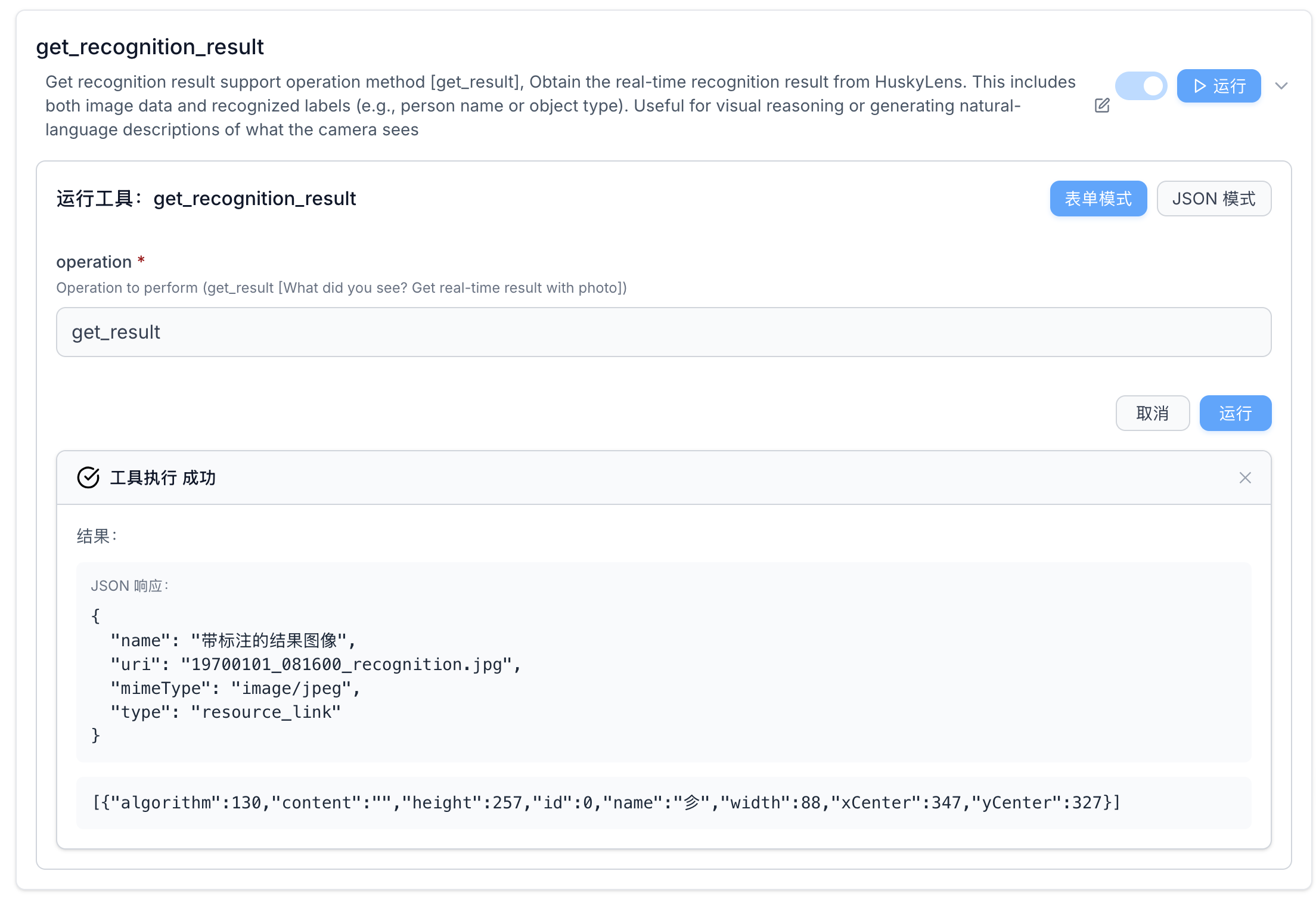
6.5 MCP 功能测试
在正式接入小智之前,可以先用 测试一下 MCP 调用是否正常:
- 点开 服务器中的二哈识图2,然后点击 get_recognition_result 后的运行,并输出 get_result 做为 operation
- 将二哈识图2对准甲骨文图片
- 点击运行识别
测试通过后,说明 MCP 链路是通的,可以接入小智 AI 了。
步骤7 七、终端交互:小智 AI 让甲骨文"开口说话"
7.1 硬件平台
- 设备:DF-K10(基于 ESP32-S3 的小智 AI 开发板)
- 固件:定制 df-k10 固件
DF-K10 烧录小智固件后,配置 WiFi 网络,再到小智后台激活设备即可使用。
7.2 智能体设置
在小智AI的后台,设置如下的智能体:
助手昵称:甲骨文大师
角色介绍:我是一个叫{{assistant_name}}的甲骨文大师,专门帮小朋友识别甲骨文,并引经据典,给小朋友讲述关于甲骨文的知识和故事。 如果通过mcp的get_recognition_result识别到结果,则返回结果的同时,调用设备的show_name方法,把识别到的原始的name值做为参数传入,然后显示甲骨文图片。
7.2 代码定制
为了让小智 AI 能正确展示甲骨文识别结果,我对小智的开源代码做了一些定制。
本项目关键文件:
| 文件 | 说明 |
|---|---|
| 1_select_images.py | 数据集处理脚本:筛选图片、画布补白、生成 YOLO 标签、data.yaml 和 map.yaml |
| data.yaml | YOLO 数据集配置文件,Mind+ 训练时需要 |
| map.yaml | 汉字名到图片路径的映射,供 serve_image.py 使用 |
| serve_image.py | 本地 HTTP 图片服务,为 DF-K10 LCD 提供甲骨文字形图片 |
| K10 定制代码 | https://github.com/HonestQiao/xiaozhi-esp32/tree/df-k10-oracle/main/boards/df-k10 |
定制内容:
LCD 显示优化:
- 当收到甲骨文识别结果时,在屏幕上分区域显示:
- 上半部分:识别到的甲骨文字形图片(通过本地 HTTP 图片服务 serve_image.py 获取)
- 下半部分:对应的现代汉字释读
- 根据屏幕分辨率自适应调整图片大小
甲骨文字形图片服务(serve_image.py):
为了让 DF-K10 的 LCD 屏幕能显示甲骨文字形,我写了一个轻量的本地 HTTP 图片服务:
- 端口:5174
- 请求方式:GET http://192.168.1.15:5174/?name=汉字名 或 POST
- 返回:固定 128×128 的 JPEG 图片(原图等比缩放、居中补白,右下角标注红色汉字)
- 数据来源:map.yaml(汉字名 → 对应图片路径的映射)
MCP 消息处理:
- 监听 MCP 推送的识别结果消息
- 解析 class_id,从本地预存的 ID_to_chinese.json 中查找对应的汉字和释义
- 同时向 serve_image.py 请求字形图片,拿到后触发 LCD 刷新显示
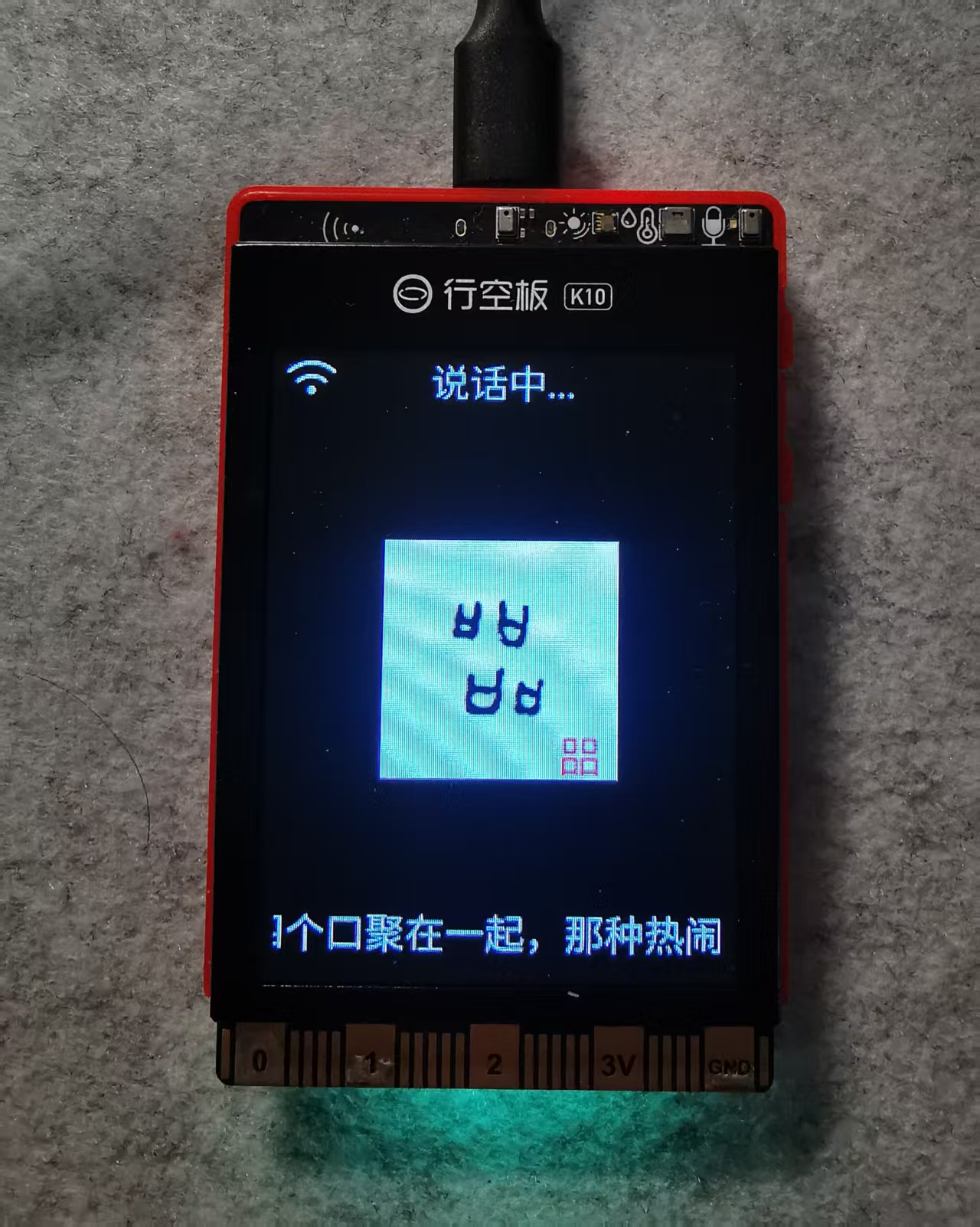
语音播报增强:
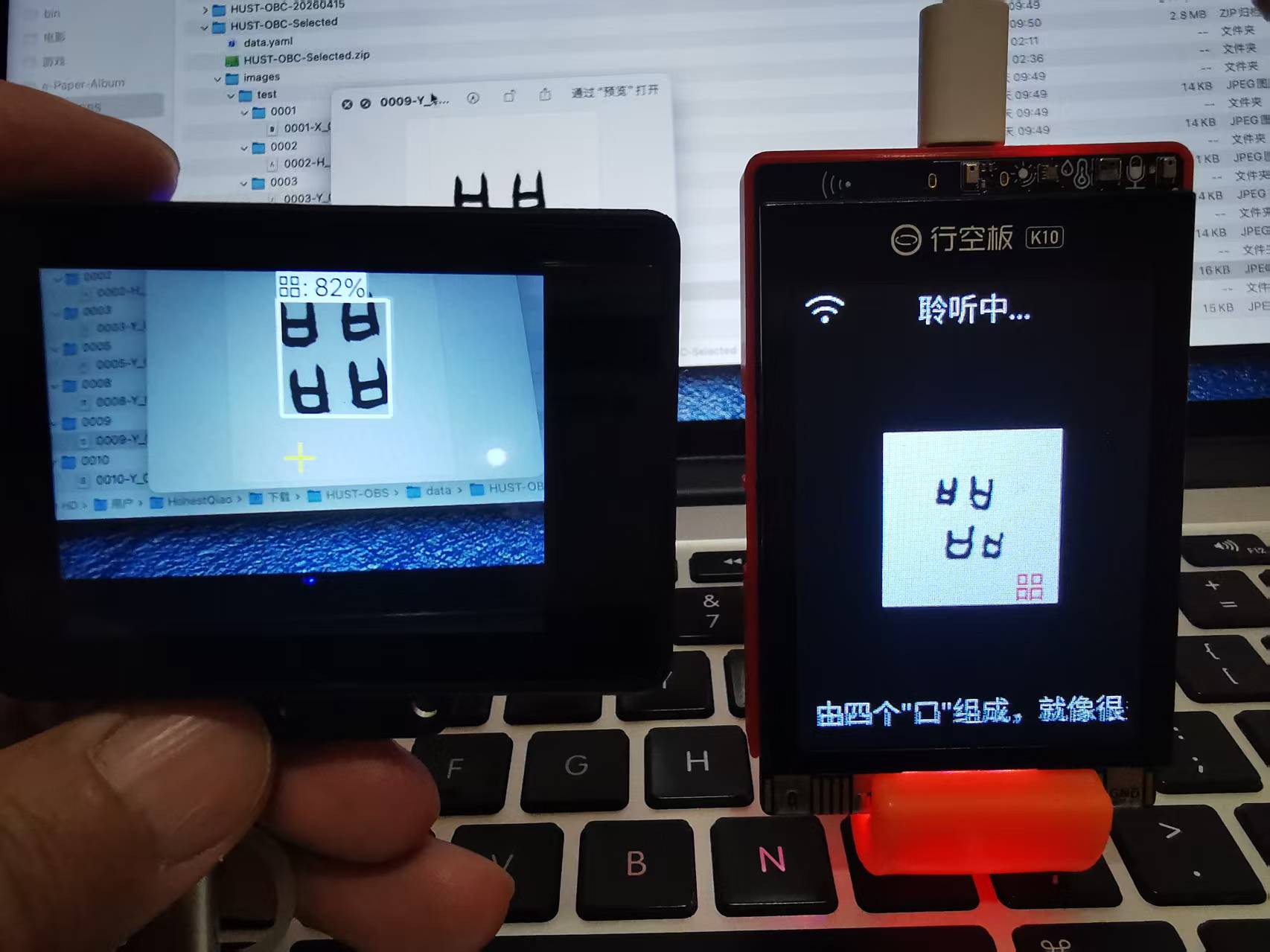
- 当识别到新甲骨文时,小智 AI 会用语音播报:"哇,我识别到了一个非常特别的甲骨文【㗊】字!这个字在古代很少见,是四个口聚在一起,那种热闹喧哗的感觉特别生动。"
- 支持语音追问:"这个字是什么意思?""还有什么类似的字?"
7.3 完整使用流程
- 唤醒:对着 DF-K10 说"你好小智"
- 切换模式:"切换到甲骨文识别模式"
- 识别:将甲骨文实物或图片对准二哈识图二的摄像头(距离 10~30cm 最佳)
- 结果返回:二哈识图二识别 → 通过 MCP 传给小智 → 小智屏幕显示字形图片 + 现代汉字 + 语音播报
- 互动追问:可以语音询问更多信息
整个流程无需联网,全部在本地设备上完成。就算拿到博物馆里,没有 WiFi 也能用(前提是 xiaozhi-mcphub 和 AI 服务已经配置好)。
步骤8 八、程序代码与项目文件
8.1 核心程序框架
数据集处理(Python)
↓
YOLO 格式数据集(images + labels + data.yaml)
↓
Mind+ V2 训练(YOLOv11n)
↓
ONNX 模型 + yaml 配置
↓
二哈识图二部署
↓
MCP 服务(二哈识图二 WiFi 模块)
↓
xiaozhi-mcphub 网关
↓
小智 AI(DF-K10)
↓
LCD 显示 + 语音播报
8.2 技术要点说明
1. 精确 YOLO 标注策略
1_select_images.py 的核心创新在于标注方式。传统全图标注(0.5 0.5 1.0 1.0)会让模型学到大量背景噪声。我采用了"原图保持 + 画布放大 + 精确框"的策略:
- 原图保持原样,居中粘贴到 2 倍大小的白色画布上
- 标注框精确计算原图在画布中的占比(宽度和高度均为 0.5)
- 最终标签为 class_idx 0.5 0.5 0.5 0.5
这样模型学会的是识别画布中心的甲骨文字形,而非背景区域。
2. 字形图片服务
serve_image.py 为 DF-K10 的 LCD 屏幕提供甲骨文字形图片。它读取 map.yaml 中的汉字到图片路径的映射,将原图等比缩放为 128×128 的固定尺寸(居中补白),并在右下角用红色字体标注汉字名,最后以 JPEG 格式返回。小智 AI 收到识别结果后,通过 HTTP 请求获取对应字形图片并显示在屏幕上。
3. K10 定制代码
DF-K10 端的定制代码主要完成三件事:监听 MCP 推送的识别结果、解析出汉字名并向 serve_image.py 请求字形图片、控制 LCD 分上下两个区域显示(上半部分字形图 + 下半部分汉字释读),同时触发语音播报。
8.3 项目文件清单
| 文件 | 说明 |
|---|---|
| oracle_recognition.mpmodel | Mind+ V2 模型训练项目文件 |
| dfrobot_oracle_recognition.8b0a.zip | 模型导出 |
| 1_select_images.py | 数据集处理脚本(Python):筛选图片、画布补白、生成 YOLO 标签、data.yaml 和 map.yaml |
| HUST-OBC-Selected.zip | YOLO 数据集(快速测试) |
| map.yaml | 汉字名到图片路径的映射,供 serve_image.py 使用 |
| serve_image.py | 本地 HTTP 图片服务,为 DF-K10 LCD 提供甲骨文字形图片 |
| K10 定制代码 | https://github.com/HonestQiao/xiaozhi-esp32/tree/df-k10-oracle/main/boards/df-k10 |
步骤9 九、创新点总结
9.1 技术创新
1. 精确 YOLO 标注策略
传统的全图标注(0.5 0.5 1.0 1.0)会让模型学到大量背景噪声。我采用了"原图保持 + 画布放大 + 精确框"的策略(0.5 0.5 0.5 0.5),让模型真正学会识别字形特征,而非图片背景。
2. MCP 协议在嵌入式视觉中的创新应用
MCP 原本多用于大模型调用搜索引擎、数据库等软件工具。我把它用在了硬件设备联动上——让大模型(小智 AI)能够"调用"二哈识图二的摄像头和视觉识别能力。这是一种跨设备、跨协议的 AI 协同。
9.2 应用创新
1. 从学术论文到可触摸的工具
ACL 2024 最佳论文证明了 AI 可以辅助甲骨文破译,但那是在实验室里、在服务器集群上跑出来的。我的项目把这套能力压缩进了两台手掌大的设备里,普通人随时随地可以用。
2. AI 重构传统文化
3000 年前的文字 + 2026 年的 AI 技术,这种跨越时空的结合本身就是一件很酷的事。它不只是技术展示,更是让传统文化以新的形式"活"起来。
9.3 教育价值
这个项目可以直接用于课堂教学场景:
- 学生拿着设备对准甲骨文实物,立刻就能看到现代汉字的释读
- 降低了甲骨文学习的门槛,让小朋友也能产生兴趣
- 可以作为"AI + 传统文化"跨学科课程的案例
步骤10 十、完整演示视频
步骤11 十一、复现指南
11.1 硬件清单
| 器材 | 数量 | 购买链接 | 备注 |
|---|---|---|---|
| 二哈识图二 HUSKYLENS 2 | 1 | DFRobot 商城 | 核心视觉识别 |
| 二哈识图二 WiFi 模块 | 1 | DFRobot 商城 | MCP 服务需要 |
| DF-K10 开发板 | 1 | DFRobot 商城 | 运行小智 AI |
11.2 软件清单
| 软件 | 版本 | 下载地址 |
|---|---|---|
| Mind+ V2 | 2.0 及以上 | https://mindplus.dfrobot.com.cn/ |
| Python | 3.12+ | https://www.python.org/ |
| Pillow | 最新 | pip install Pillow |
| xiaozhi-mcphub | 最新 | https://github.com/huangjunsen0406/xiaozhi-mcphub |
| Node.js | 18+ | https://nodejs.org/ |
| PostgreSQL | 14+ | https://www.postgresql.org/ |
11.3 一步一步复现
Step 1:准备数据集
# 下载 HUST-OBS 数据集 # 从 https://hyper.ai/cn/datasets/33506 下载 torrent 或 zip # 解压后运行处理脚本 python3 1_select_images.py # 输出:HUST-OBC-Selected/ 目录
Step 2:训练模型(Mind+ V2)
- 打开 Mind+ V2 → 模型训练 → 目标检测(M2)→ 专业模式
- 导入 YOLO 格式数据集
- 创建训练任务,模型选 YOLOv11n
- 设置训练轮次 50,关闭随机上下翻转
- 开始训练
- 导出 ONNX 模型
Step 3:部署到二哈识图二
- Mind+ 模型部署 → 部署至二哈识图二
- 填写信息,开始转换
- 下载安装包
- USB 连接二哈识图二,拷贝安装包
- 本地安装
Step 4:搭建 MCP 网关
git clone https://github.com/huangjunsen0406/xiaozhi-mcphub.git cd xiaozhi-mcphub # 编辑 .env 配置数据库 pnpm install pnpm dev # 访问 http://localhost:5173
Step 5:添加 MCP 端点
- 小智后台获取 MCP 接入点 → 添加到 xiaozhi-mcphub
- 二哈识图二连接 WiFi → 打开 MCP 应用获取地址 → 添加到 xiaozhi-mcphub
Step 6:烧录小智固件
- 编译 df-k10 固件
- 烧录 df-k10 固件
- 配置 WiFi 并激活
Step 7:测试使用
- 唤醒小智:"你好小智"
- "切换到甲骨文识别模式"
- 对准甲骨文,观察识别结果
11.4 常见问题 FAQ
Q1:模型训练时上传数据集报错?
A:检查 zip 包结构是否符合 YOLO 格式,images/ 和 labels/ 目录结构必须严格对应。文件名不要有特殊字符。
Q2:二哈识图二安装模型后找不到应用?
A:确认安装包已拷贝到 HUSKYLENS 设备的应用目录,然后重启设备。如果还不行,尝试重新安装一次。
Q3:MCP 连接不稳定?
A:确保二哈识图二和小智设备在同一个 WiFi 网络下。检查 xiaozhi-mcphub 的日志输出,看是否有连接错误。
Q4:识别效果不理想?
A:检查光照条件,白光均匀环境下效果最好。另外可以尝试调整二哈识图二与目标之间的距离(10~30cm 最佳)。
步骤12 十二、结语
做这个项目的初衷其实很简单:我想用AI能做一点更有意义的事。甲骨文是中国文化的根,如果 AI 能帮助更多人认识和理解这些 3000 年前的文字,哪怕只是一点点,那也是值得的。
从找数据集、写处理脚本、调训练参数,到部署模型、搭 MCP 网关、改小智代码,整个过程花了不少时间,也踩了不少坑。但当 DF-K10 的屏幕上第一次正确显示出甲骨文字形,并且用语音解释的时候,我觉得一切都值了。
未来,我希望把这个项目扩展到更多未破译的甲骨文类别,甚至结合扩散模型做字形还原。也希望它能走进课堂,让更多孩子通过 AI 的窗口,看到中华文明的源头。
材料清单
- DF-K10 X1 链接
材料清单
- 二哈识图二 X1 链接


 他的勋章
他的勋章
评论