 返回首页
返回首页
 回到顶部
回到顶部
一、创作背景
本项目响应 **“AI‘重构’生活 ——Mind+ V2 模型训练挑战赛”** 赛事主题,聚焦传统文化学习与 AI 技术的低门槛融合,核心创作背景如下:
- 行业痛点明确:中华古诗文是传统文化的核心载体,但题材分类是古诗文入门的核心门槛 —— 题材直接决定了诗文的主旨情感、创作背景,初学者往往难以快速区分,中小学语文课堂也缺乏直观、可互动的分类教学工具;同时传统 NLP 文本分类技术门槛高,需要复杂的代码与算法知识,普通师生、传统文化爱好者无法轻松上手。
- 工具基础成熟:Mind+ V2 深度进化的 AI 模型训练工具箱,将复杂的文本分类模型训练简化为零代码可视化操作,为 AI 赋能传统文化学习提供了极低门槛的实现路径,让非专业开发者也能完成 AI 模型的全流程开发。
- 核心创作目标:基于 Mind+ V2 的文本分类功能,开发零门槛的古诗文题材智能分类助手,用 AI 重构古诗文的学习与科普场景,降低古诗文入门门槛,同时为中小学 AI + 语文跨学科教学提供可落地、可复现的标准化案例。
二、功能说明
本项目为纯软件实现的古诗文智能分类系统,完全基于 Mind+ V2 平台开发,符合赛事【灵感数字组】参赛要求,无需额外硬件,仅需安装 Mind+ V2 的电脑即可运行,核心功能如下:
- 核心古诗文题材智能分类支持用户输入任意古诗文正文,基于自训练的文本分类模型,自动识别诗文所属的四大核心题材:山水田园诗、边塞征战诗、送别怀人诗、咏史怀古诗,输出最高匹配的分类结果,最终模型识别准确率达 95% 以上。
- 全维度分类置信度展示不仅输出最优匹配结果,同时同步展示四大题材各自的匹配置信度百分比,让学习者直观理解不同题材的特征差异,不仅知晓分类结果,更能理解分类依据,实现深度学习。
- 零门槛可视化交互全程采用 Mind + 图形化编程实现,无需任何代码基础。用户仅需按下空格键,在弹出的对话框中输入古诗文,即可一键完成识别,操作流程极简,小学阶段学生也能轻松上手。
- 模型可快速迭代优化配套完整的数据集构建、模型重训练流程,用户可根据自身需求,新增分类标签、补充样本数据,快速优化模型效果,适配更多元的古诗文分类需求,具备极强的可拓展性。
三、实现原理
本项目基于 Mind+ V2 内置的文本分类训练与推理框架,采用监督式迁移学习的技术路线,完整实现了从数据采集→模型训练→推理部署的全流程闭环,核心原理分为三个部分:
- 监督式学习数据集构建原理文本分类模型的核心是基于标注好的数据集进行监督学习,本项目针对古诗文题材分类场景,构建了标准化的标注数据集:
- 分类体系设计:划定语义边界清晰、文本特征差异显著的四大古诗文题材分类,避免标签语义重叠导致的模型识别混乱,为模型学习提供明确的分类目标;
- 样本规范控制:每个分类标注 20 条以上的古诗文正文样本,单条样本为完整诗文,剔除作者、朝代、注释等无关干扰信息,保证样本语义特征纯净;
- 均衡性与多样性保障:四大分类的样本数量差异控制在 5 条以内,避免样本不均衡导致的模型 “偏科”;同时保证同类别样本覆盖不同作者、不同朝代、不同句式,大幅提升模型的泛化能力。
- 基于迁移学习的模型训练原理本项目基于 Mind+ V2 文本分类工具内置的中文预训练 NLP 模型,采用迁移学习的方式完成微调训练,无需从零搭建训练模型:
- 底层预训练模型已基于海量中文语料完成基础语义特征学习,具备成熟的中文文本理解能力,大幅降低了训练成本和数据量要求;
- 通过标注好的古诗文题材数据集,对预训练模型进行微调,让模型学习到不同题材古诗文的专属特征,包括高频关键词、句式结构、语义情感倾向等,建立 “古诗文文本→题材分类标签” 的精准映射关系;
- 训练完成后,通过训练集外的测试样本完成模型校验,将识别错误的 “难例样本” 补充到对应分类的数据集,迭代优化模型,最终实现 95% 以上的识别准确率。
- 模型推理与交互实现原理训练完成的模型导出为 Mind + 专属的 zip 格式模型文件,在 Mind + 实时模式下完成推理交互的落地:
- 通过 Mind+【模型训练推理库】加载导出的模型文件,完成模型的初始化部署;
- 基于图形化积木搭建交互逻辑:通过键盘事件触发输入对话框,获取用户输入的古诗文文本,传入模型完成推理,输出每个分类的标签名称和置信度数值;
- 对推理结果进行格式化处理,通过舞台角色完成结果的可视化展示,实现完整的用户交互闭环。
四、应用场景
本项目以 “AI 赋能传统文化学习” 为核心,可广泛应用于教育、科普、内容整理等多个生活与学习场景,真正实现 “AI 重构生活” 的赛事主旨:
- 中小学语文 + AI 跨学科教学场景
- 语文课堂教学:作为古诗文教学的辅助工具,老师可在课堂上实时输入诗文,直观展示不同题材的特征差异,帮助学生快速理解题材与主旨情感的关联,提升课堂互动性;
- 信息技术课堂:作为 AI 文本分类的教学案例,让学生通过熟悉的古诗文,零门槛理解机器学习、监督学习、文本分类的核心原理,实现语文与信息技术的跨学科融合教学,贴合新课标素质教育要求。
- 青少年古诗文自主学习场景为中小学生提供零门槛的古诗文自主学习工具,学生在预习、复习古诗文时,可随时输入诗文,快速获取题材分类结果,辅助理解诗文的创作背景、情感主旨,降低古诗文的入门学习门槛。
- 传统文化科普互动场景可作为博物馆、文化馆、青少年活动中心的传统文化互动展项,游客通过简单的输入操作,即可快速了解古诗文的题材分类与相关背景,打破传统文化科普的次元壁,让更多人通过 AI 感受到古诗文的魅力。
- 古诗文内容整理与创作场景为古诗文自媒体创作者、传统文化爱好者提供批量分类工具,可快速对古诗文素材进行题材分类归档,提升内容整理的效率;也可作为古诗文创作的辅助工具,帮助创作者校验自身创作的古诗文题材风格。
五、视频演示
【准备工作】
1. 电脑一台,系统要求:Win10 64位
2. 安装软件:Mind+ V2.0.5
【创作过程】
本项目主要实施过程:数据采集 -> 模型训练 -> 模型部署 -> 程序设计-> 测试完善,全程使用Mind+软件完成。
步骤1 文本分类模型训练
一、核心分类体系(唯一推荐 4 大题材分类)
以下 4 个分类语义边界完全独立,诗文的用词、场景、核心主题差异极大,Mind + 模型极易学习识别,是新手入门、效果落地的最优选择。
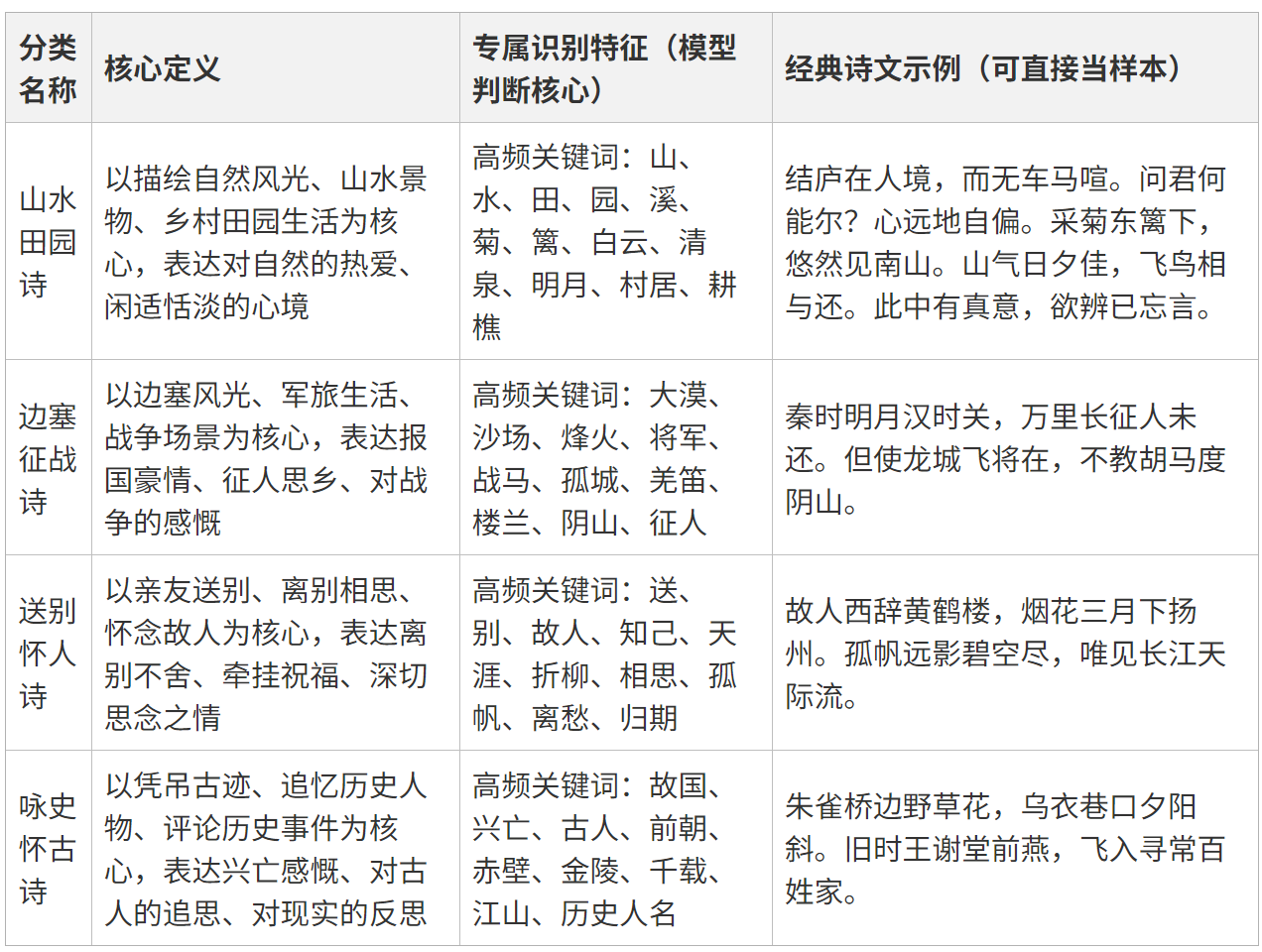
二、核心数据集构建
严格遵循以下规范,可保证模型训练准确率稳定在 90% 以上,避开 90% 的新手坑。

三、精选每个类型各20条,进项模型训练
步骤 1:进入文本分类训练工作台
打开 Mind+ V2.0.5,点击左侧导航栏的【模型训练】按钮;
在功能页面中找到【文本分类】卡片,点击右下角的【快速体验】,进入专属训练工作台。
步骤 2:创建 4 个核心分类标签
进入工作台后,左侧为类别面板,点击初始类别右侧的编辑按钮,修改为「山水田园诗」,回车确认;
点击面板下方的【新增类别】按钮,依次创建「边塞征战诗」「送别怀人诗」「咏史怀古诗」3 个标签,确保 4 个标签名称准确、无错别字。
步骤 3:导入数据集
打开样本文件包,把上面的样本逐条复制到下方的文本输入框,点击【添加样本】完成录入;
依次完成其4 个类别的样本导入,确保每个类别样本量一致(均为 20 条);
最后检查所有样本,确保仅保留诗文正文,无作者、朝代、注释等无关内容。
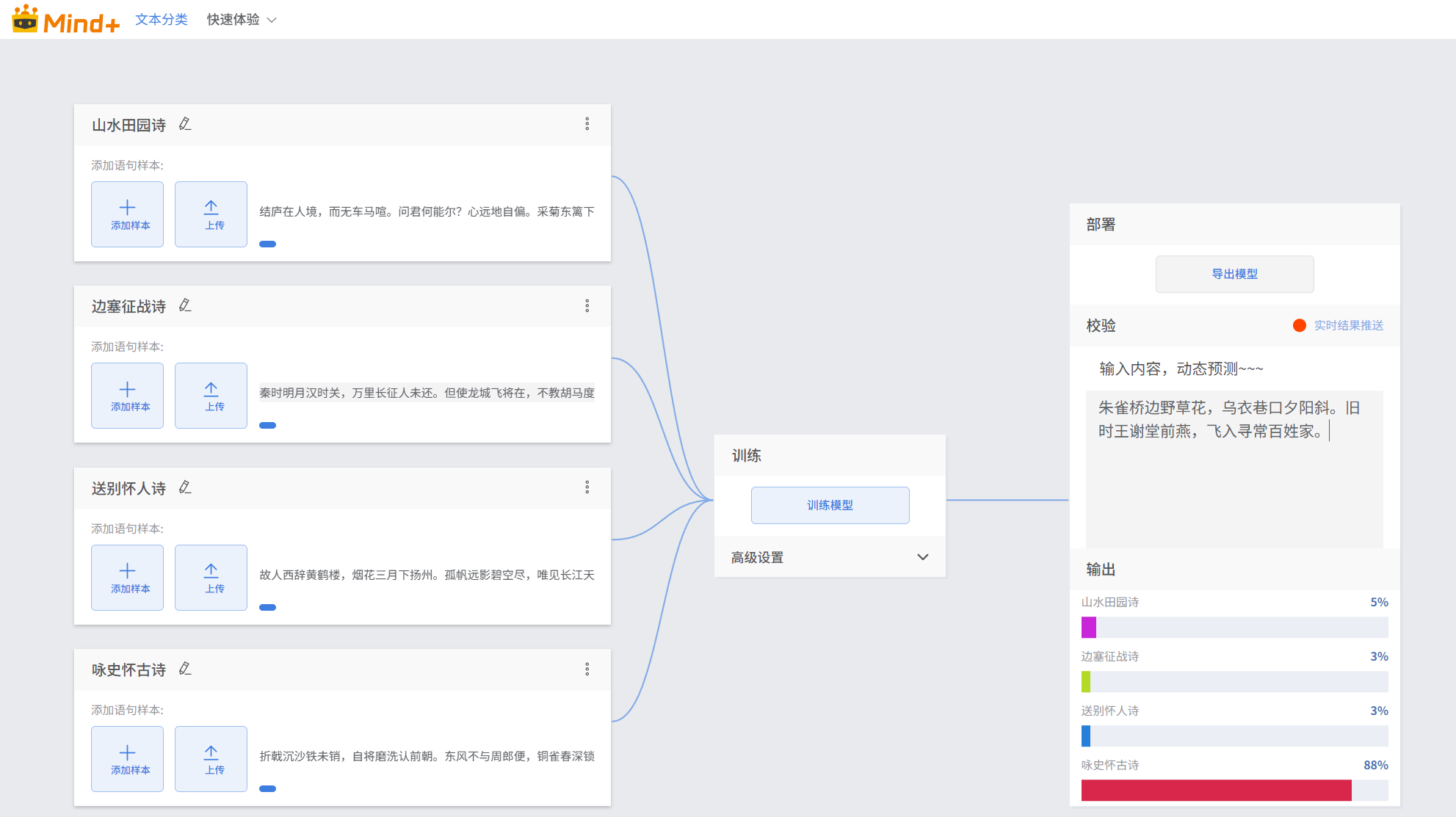
步骤 4:一键训练模型
无需调整任何高级设置,直接使用默认参数即可;
点击页面中间的【训练模型】按钮,软件自动启动训练;
等待训练完成(80 条样本大约 1-2 分钟即可完成),训练过程中不要关闭页面、保持软件前台运行;
步骤 5:模型校验与优化
训练完成后,页面右侧会出现校验面板,输入训练集之外的全新古诗文(比如王维《山居秋暝》、岑参《白雪歌送武判官归京》正文);
查看模型自动输出的分类结果和置信度,若分类正确且目标类别置信度≥90%,说明模型效果达标;
若分类错误,直接把这首诗文添加到对应正确类别的样本中,重新点击【训练模型】,即可快速提升准确率。
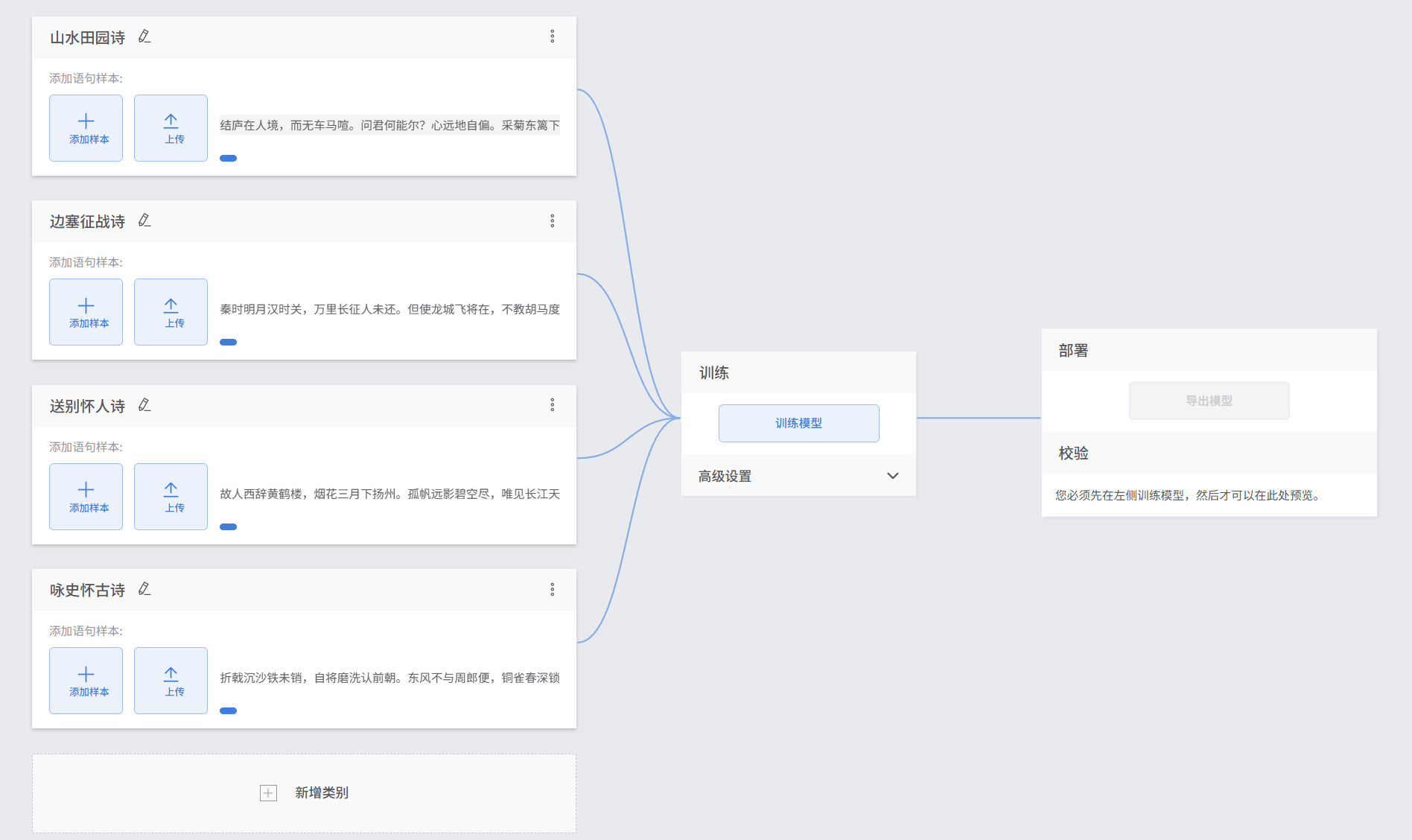
步骤 6:导出模型文件
校验达标后,点击校验面板上方的【导出模型】按钮,设置模型名称,选择保存路径,点击保存,会导出一个zip 格式的模型压缩包,请勿解压该文件,后续编程直接使用。
步骤2 编程
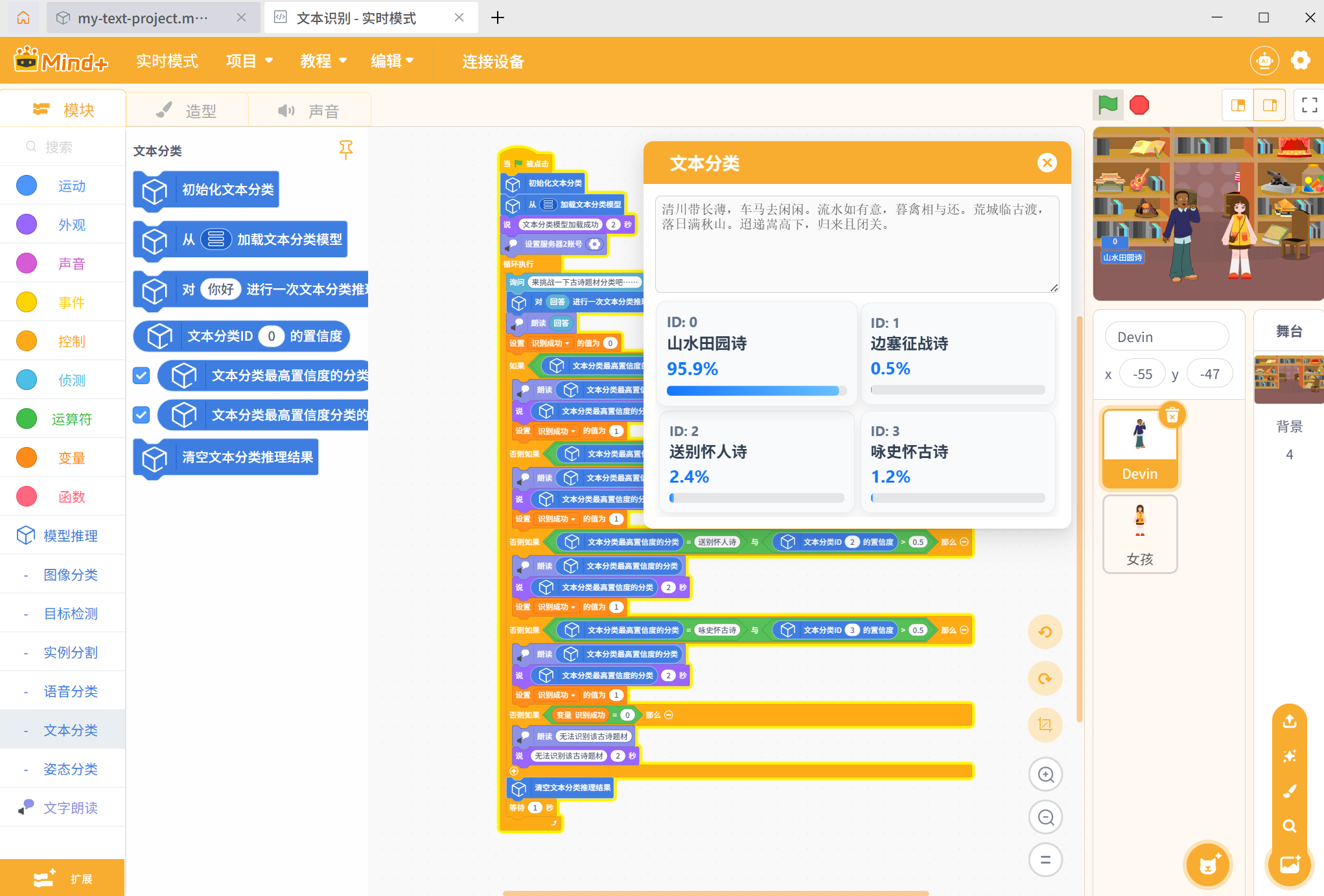
- 回到 Mind + 主界面,将右上角的模式切换为实时模式;点击左下角【扩展】按钮,进入扩展库,在【功能模块】分类中,搜索并加载【模型训练推理库】和【文字朗读】,添加角色和背景后进行编程如下:
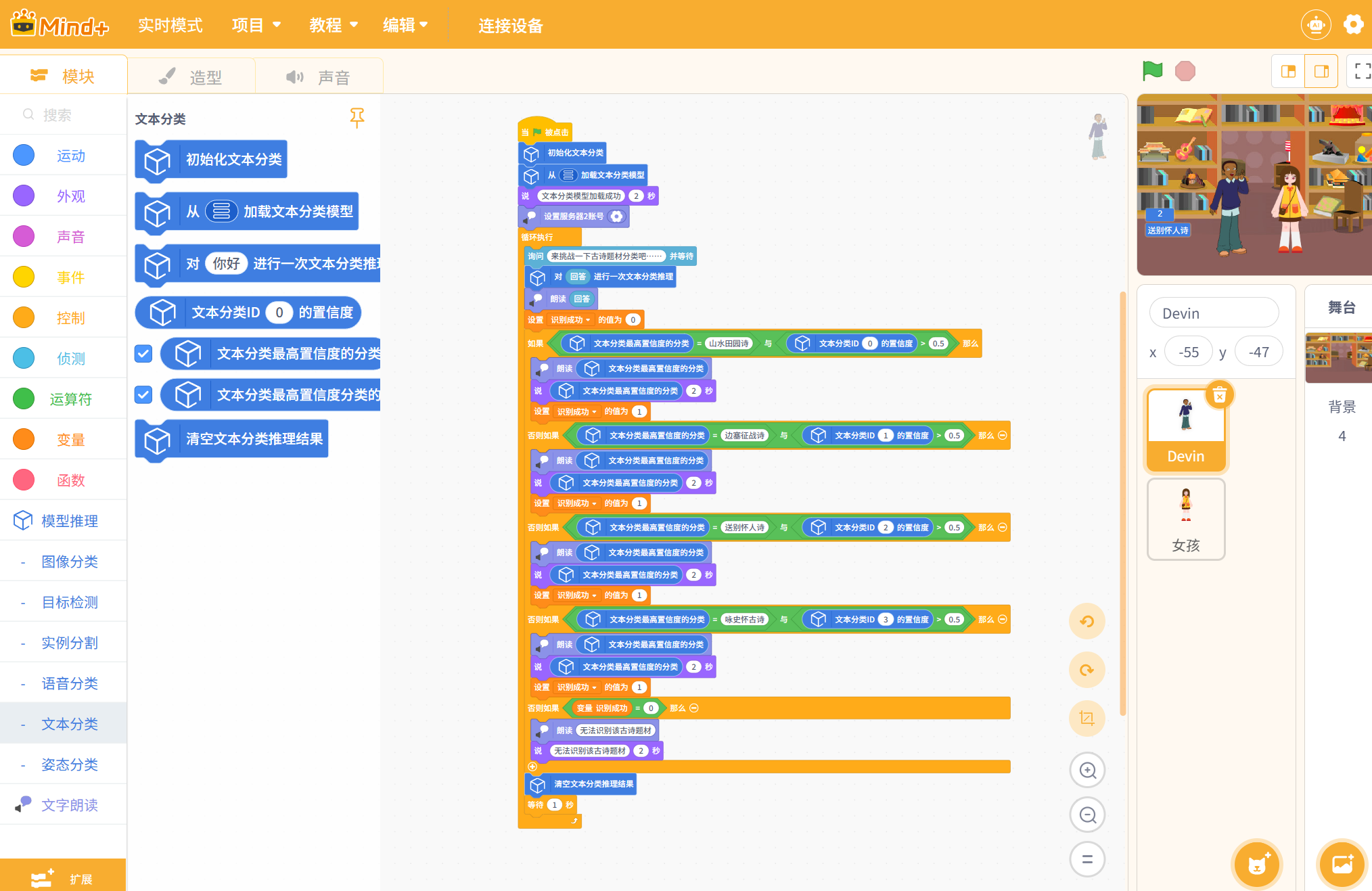
步骤3 对项目进行运行测试
项目完成后,对样本包和测试包里面的诗文进行测试
快速提升准确率的核心技巧
- 难例补充:把模型分类错误的诗文,直接添加到对应正确类别的样本中,重新训练,准确率会快速提升;
- 场景优化:如果需要识别单句名句,就在样本中补充更多同类型的单句名句,让模型学习短句的语义特征;
- 阈值筛选:可在积木中添加判断逻辑,仅当最高置信度≥70% 时输出结果,低于阈值提示「无法识别该诗文类别」,避免误判。
六、项目总结
本项目响应赛事主题,基于 Mind+ V2 的文本分类模型训练功能,完整开发了一套零门槛的古诗文题材智能分类助手,实现了从数据集构建、模型训练、推理部署到交互落地的全流程闭环,核心成果与亮点如下:
- 精准贴合赛事主旨,用 AI 重构传统文化学习场景本项目将 AI 技术与中华优秀传统文化深度结合,把原本有较高门槛的古诗文题材分类,转化为人人都能上手的极简 AI 交互体验,用 AI 技术重构了古诗文的学习与科普方式,真正落地了 “AI 重构生活” 的赛事核心要求。
- 模型效果优异,泛化能力强通过标准化的标注数据集与迭代优化训练,最终模型的分类准确率达 95% 以上,对训练集外的陌生古诗文、不同句式的短篇诗文均具备良好的识别能力,可满足实际学习与科普场景的使用需求。
- 可复现性强,具备极高的教学与传播价值项目全程基于 Mind+ V2 平台实现,采用全图形化零代码编程,配套完整的数据集、模型文件、项目文件与操作教程,其他学习者无需具备 AI 与代码基础,即可轻松复现整个项目,为 DF 创客社区提供了一套高质量、易落地的 AI 跨学科教学案例。
- 完全符合赛事要求,创意性与完整性兼备本项目为纯软件实现的作品,完全符合【灵感数字组】的参赛要求,无需额外硬件,仅需安装 Mind+ V2 的电脑即可运行,同时实现了完整的功能闭环,兼顾了创意趣味性、技术完整性与实际应用价值。
七、项目反思与展望
(一)项目反思
本项目完成了核心功能的落地,但仍存在一些可优化与提升的空间:
分类体系的覆盖范围有限目前项目仅覆盖了古诗文四大核心题材,对于咏物诗、哲理诗、闺怨诗等其他常见题材尚未覆盖,无法满足更全面的古诗文分类需求,后续可进一步扩充分类标签体系。
短句样本的识别能力仍有提升空间目前模型对完整诗文的识别准确率极高,但对单句名句、残句的识别效果仍有优化空间,核心原因是训练集中的完整诗文样本占比过高,短句样本不足,后续可补充更多单句名句样本,提升模型的泛化能力。
交互与内容丰富度不足目前项目仅实现了分类结果的基础展示,尚未配套对应题材的背景知识、创作特点、代表诗人等科普内容,对学习者的辅助作用仍可进一步拓展;同时交互界面较为基础,可进一步优化视觉效果与交互体验。
输入方式较为单一目前仅支持手动键盘输入古诗文,对于纸质诗文、图片中的诗文无法快速识别,使用场景仍有局限,后续可结合 OCR、语音识别等功能,拓展更多元的输入方式。
(二)项目展望
基于本次项目的基础,后续将从功能拓展、场景落地、社区分享三个维度持续优化:
功能拓展,打造一站式古诗文 AI 学习助手后续将进一步扩充分类体系,新增古诗文朝代分类、体裁分类、情感分类等多个维度,同时配套对应题材的科普内容、诗文赏析、作者介绍等资源,把项目从单一的分类工具,升级为一站式的古诗文 AI 学习助手。
场景落地,实现软硬件结合的多元应用后续将基于 Mind+ V2 的模型部署能力,结合行空板、二哈识图等 DF 生态硬件,把项目移植到【创意智造组】赛道,开发可便携的古诗文分类学习终端,走进校园、博物馆、研学基地,实现更广泛的线下场景落地。
社区分享,助力 AI 教育普惠将把项目完整的数据集、模型文件、操作教程、教学课件完整分享到 DF 创客社区,供所有 Mind + 学习者参考、复现与二次创作,同时将项目优化为中小学 AI 跨学科教学的标准化课程,让更多孩子通过传统文化学习 AI 知识,通过 AI 爱上中华优秀传统文化,助力 AI 教育的普惠与落地。
附件



 他的勋章
他的勋章






评论