 返回首页
返回首页
 回到顶部
回到顶部
一、创作背景
婴儿不会用语言表达需求,啼哭是他们与外界沟通的唯一方式,而新手父母、隔代照顾者往往无法快速精准地分辨婴儿不同啼哭背后的需求,常常陷入 “宝宝哭了却不知道怎么办” 的焦虑中,尤其是夜间育儿、单人带娃的场景下,这种信息差会大幅提升育儿的身心负担。
当下主流的婴儿监护产品多以硬件为主,门槛高、普适性差,普通家庭难以便捷地使用 AI 技术解决这一育儿痛点。本次借助 Mind+ V2 深度进化的 AI 工具箱,以低门槛的音频分类模型训练能力,打造了这款纯软件、轻量化的婴儿啼哭智能识别工具,让 AI 技术落地到日常育儿场景,用技术重构新手父母的育儿体验,真正实现 “AI 听懂宝宝的心声”,贴合本次大赛 “AI 重构生活” 的核心主题。
二、功能说明
本项目基于 Mind+ V2 的音频分类模型训练功能,实现了婴儿啼哭 6 类核心需求的智能识别,全程仅需一台安装 Mind+ V2 的电脑,借助麦克风即可完成全部操作,核心功能如下:
1.婴儿啼哭六分类精准识别:可精准识别婴儿啼哭对应的 6 类核心需求 —— 要抱抱、睡醒了、困乏了、饥饿了、不舒服、换尿布,覆盖婴儿日常绝大多数啼哭场景。
2. 可视化友好交互:内置 10 秒录音倒计时功能,用户可清晰掌握识别进度,识别完成后有明确的状态提示,操作流程简单直观,无任何使用门槛。
3.多轮投票抗误判机制:10 秒识别周期内以每秒 5 次的频率进行音频推理与结果投票,通过累计票数统计最终结果,大幅降低单次音频推理的误判概率,提升识别稳定性。
4.智能结果校验与兜底:设置最低有效识别票数阈值,过滤无效识别结果;针对模型加载失败、麦克风异常、无有效婴儿啼哭、识别数据异常等场景,均设计了对应的友好提示与异常处理逻辑,程序鲁棒性强。
5.轻量化一键操作:无需复杂的参数设置与模型调试,点击角色即可一键启动识别,新手父母、无编程基础的用户也能轻松上手。
三、项目实现原理
本项目分为AI 模型训练与程序逻辑开发两大核心环节,全程基于 Mind+ V2 平台完成开发与部署,核心实现原理如下:
(一)音频分类模型训练原理
1.数据集构建:采集不同场景、不同年龄段婴儿的啼哭音频数据,按照「要抱抱、睡醒了、困乏了、饥饿了、不舒服、换尿布」6 个标签进行分类标注,同时采集家庭环境背景噪音作为负样本,保证数据集的场景覆盖度与标注准确性。
2.音频特征提取:借助 Mind+ V2 音频分类工具箱,自动将音频数据转化为梅尔频谱特征图,完成音频信号的数字化处理,适配深度学习模型的训练要求。
3.模型训练与优化:基于 Mind + 内置的音频分类深度学习框架,对标注好的数据集进行模型训练,通过多轮迭代优化模型权重,提升 6 类啼哭的分类识别准确率,最终导出可直接调用的.mpmodel格式模型文件。
(二)程序核心逻辑实现
项目程序分为四大核心模块,形成完整的识别闭环,逻辑架构如下:
1.全局初始化模块程序启动(绿旗触发)时,自动完成语音分类环境初始化、训练好的啼哭识别模型加载、全量全局变量归零初始化,同时播放用户引导语,告知操作方式;模型加载完成后标记加载状态,为后续异常校验提供依据。
2.核心识别与投票模块用户点击婴儿头像角色启动识别后,先执行防重复点击逻辑,避免多流程叠加错乱;同步校验模型加载状态,模型未就绪时直接给出提示并终止流程。校验通过后,同步启动倒计时交互与麦克风实时推理,在 10 秒识别周期内,循环读取模型输出的最高置信度分类 ID,对对应类别的票数进行累计,完成多轮投票统计。
3.结果统计与校验模块10 秒识别周期结束后,自动停止麦克风推理,释放音频资源;统计 6 类啼哭需求的累计票数,筛选出票数最高的类别作为初步识别结果;通过最低有效票数阈值进行二次校验,最高票数低于阈值时,判定为「未检测到有效婴儿啼哭」,避免环境噪音、无效音频导致的误判。
4.结果展示模块最终结果确定后,通过广播触发结果展示逻辑,针对「识别异常」「无有效婴儿啼哭」「有效识别结果」三种场景,分别给出对应的友好提示,同时展示最终识别结果与匹配次数,让用户清晰直观地获取宝宝的啼哭需求。
四、应用场景
- 1.新手父母居家育儿辅助
- 作为新手父母的日常育儿工具,帮助其快速分辨婴儿啼哭的核心需求,减少育儿焦虑,尤其适配夜间单人带娃、新手爸妈无育儿经验的场景,大幅降低育儿门槛。
- 2.母婴护理专业场景辅助
- 可作为月子中心、母婴护理机构、育儿嫂的辅助工作工具,帮助护理人员快速响应婴儿需求,提升母婴护理的效率与专业性。
- 3.隔代育儿场景适配
- 帮助爷爷奶奶、外公外婆等隔代照顾者,快速理解婴儿的啼哭含义,解决隔代育儿中 “听不懂宝宝需求” 的痛点,提升隔代育儿的体验与效果。
- 4.育儿科普教育场景
- 可作为亲子育儿科普的互动工具,帮助准父母、育儿爱好者了解婴儿不同啼哭背后的需求差异,普及科学育儿知识,降低 AI 技术与育儿知识的学习门槛。
- 5.智能母婴产品原型拓展
- 本项目的核心识别模型与逻辑,可直接拓展对接行空板等开源硬件,实现离线部署,打造便携式婴儿啼哭监护终端、智能婴儿床、智能母婴监护器等产品,具备极强的硬件落地与商业化拓展潜力。
五、视频演示
【准备工作】
1. 下载并安装Mind+ V2最新正式版
2. 确保电脑配备可用的麦克风,并给Mind+开放麦克风权限
3. 无需任何其他软件、硬件、扩展支持
【创作过程】
本项目主要实施过程:数据采集 -> 模型训练 -> 模型部署 -> 程序设计-> 测试完善,全程使用Mind+软件完成。
【运行步骤】
1. 下载本项目所有文件,将“婴儿啼哭识别.mpcode”项目文件与“婴儿啼哭识别.mpmodel”模型文件放在同一文件夹内
2. 打开Mind+ V2,点击「文件→打开项目」,选择婴儿啼哭识别.mpcode
3. 点击舞台上方的绿旗,启动程序
4. 播放婴儿啼哭音频或对着麦克风发出声音,系统将自动识别并显示结果
步骤1 语音分类模型训练
数据采集与预处理
数据集构建
- 样本来源:公开婴儿啼哭数据集 (条件限制无法采集真实的婴儿啼哭声音)
- 样本数量:每类 60 条有效音频样本
- 样本规格:采样率 44.1kHz,单声道,16 位深度
预处理操作
- 使用 Audacity 软件去除音频中的背景噪音
- 统一所有样本的音量和时长
- 对每类样本进行标注,生成 Mind + 支持的数据集格式
Mind+ V2 音频分类模型训练步骤
- 打开 Mind+ V2,选择语音分类任务,点击新建项目
- 项目名称填写 “婴儿哭声识别”
- 进入数据标注界面:
- 点击添加类别,依次添加 "不舒服、饥饿了、换尿布、要抱抱、困乏了、睡醒了"6 个类别
- 点击每个类别右侧的导入按钮,导入对应类别的音频文件
- 确认所有样本标注正确后,点击模型训练
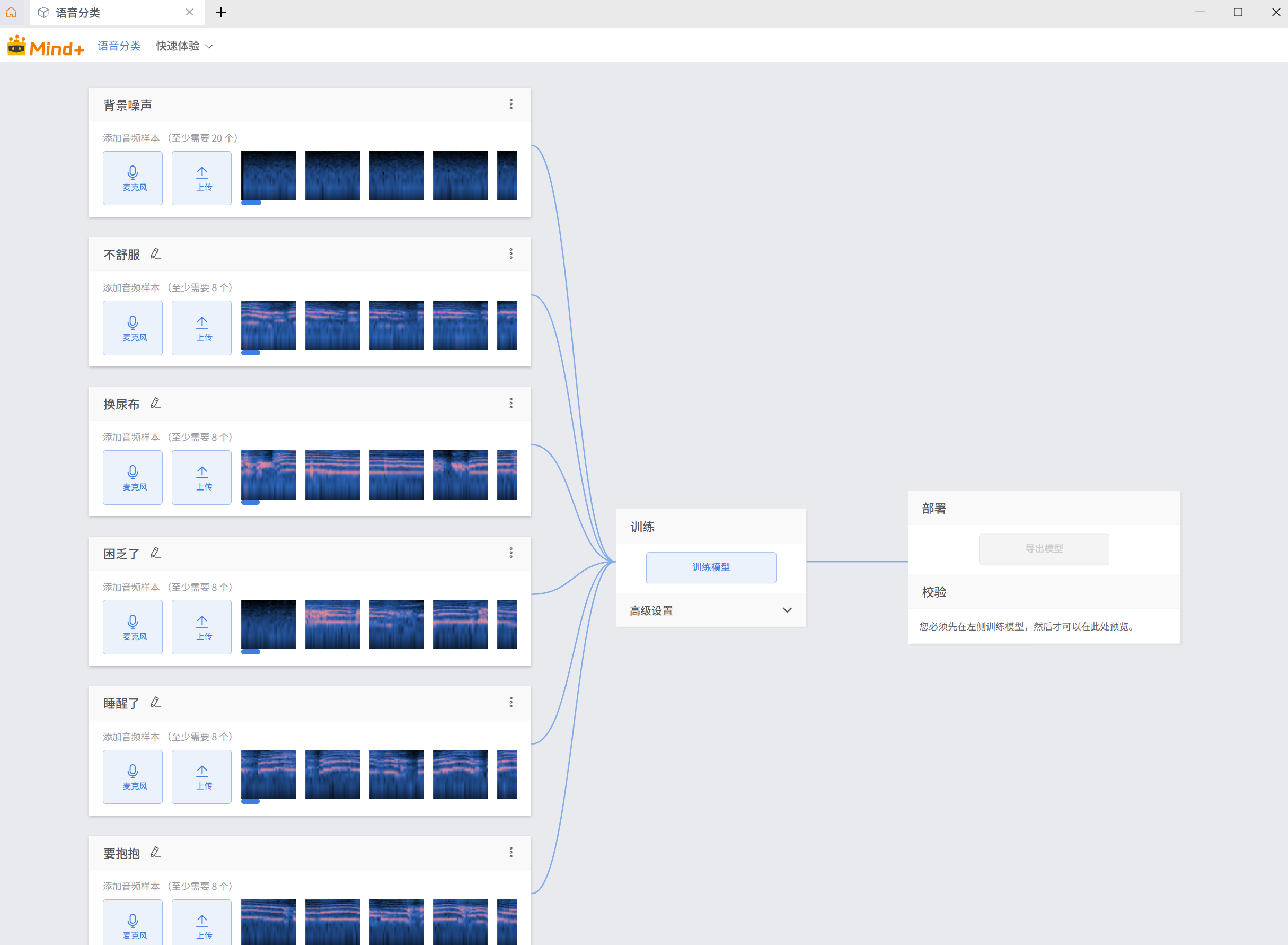
- 模型训练设置:
- 训练轮次:50 轮(默认值,经验证效果最佳)
- 点击开始训练,等待训练完成
- 训练完成后,播放音频进行测试,验证模型准确率
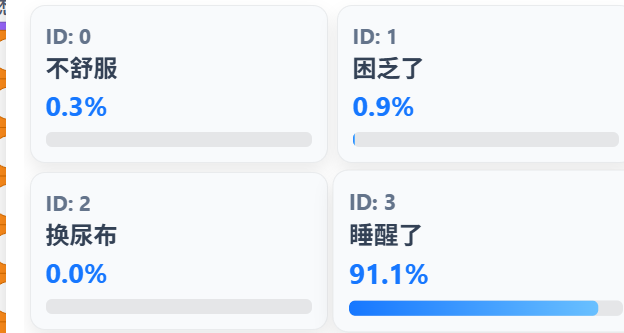
- 点击导出模型,保存为婴儿啼哭识别.mpmodel文件
步骤2 编程
宝宝角色(核心识别模块)

倒计时脚本:

编程如下:

医生角色:

结果接收

编程如下: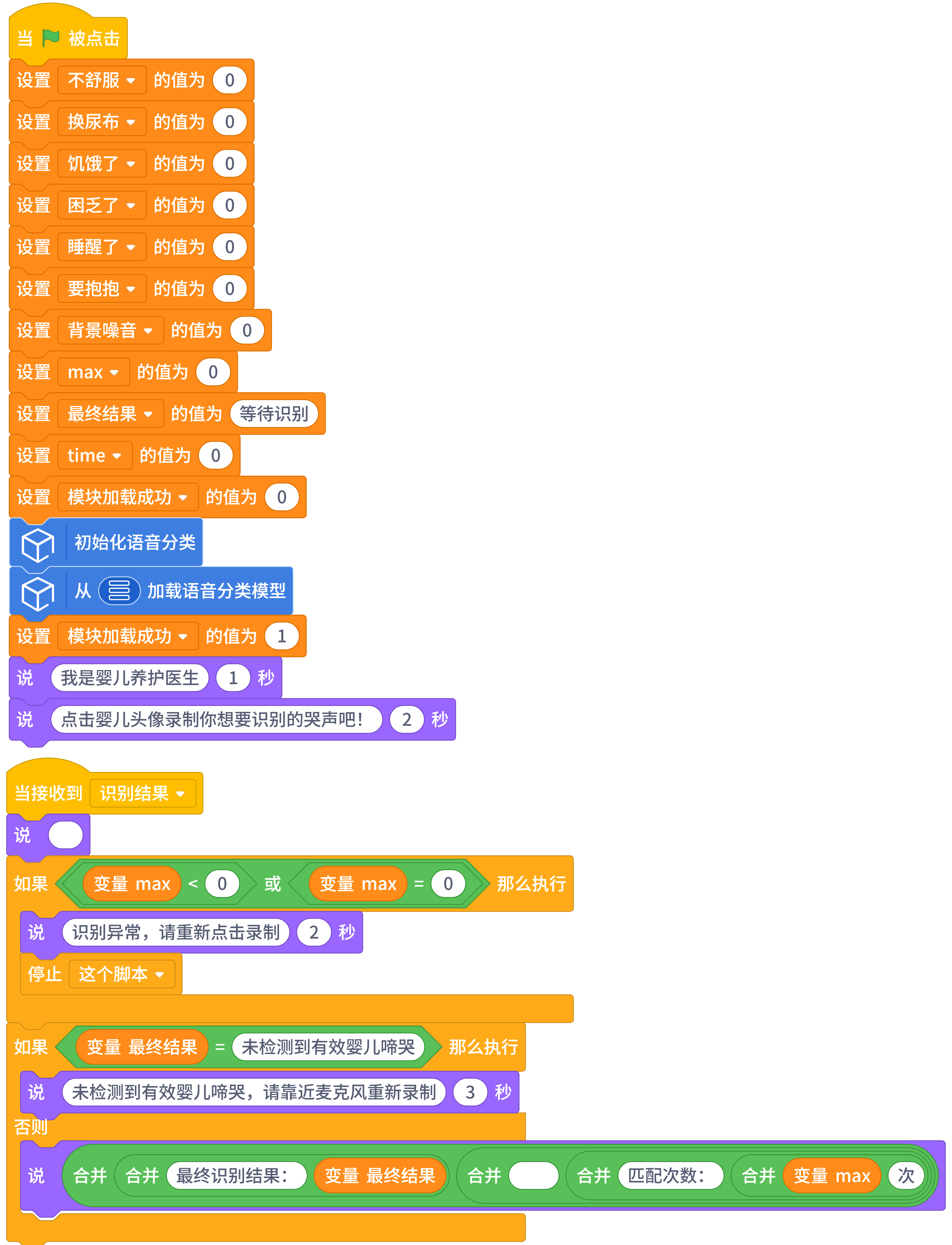
六、项目总结
本项目基于 Mind+ V2 的音频分类模型训练功能,完整实现了婴儿啼哭 6 类核心需求的智能识别,打造了一款纯软件、轻量化、低门槛的育儿辅助工具,核心成果如下:
- 1.完成了婴儿啼哭六分类音频模型的训练与优化,实现了日常家庭场景下婴儿啼哭需求的稳定识别,核心功能闭环完整,运行稳定。
- 2.设计了多轮投票的识别机制,大幅降低了单次音频推理的误判率,同时通过最低有效票数阈值过滤无效结果,显著提升了识别的准确率与抗干扰能力。
- 3.交互设计极致轻量化,无需复杂操作,一键即可启动识别,无编程基础、无育儿经验的用户也能轻松上手,真正实现了 AI 技术的普惠化。
- 4.完整覆盖了模型加载、权限获取、识别过程、结果输出全流程的异常处理,程序鲁棒性强,在各类异常场景下均能给出明确的用户提示,不会出现程序卡死、无响应的问题。
- 5.深度贴合本次大赛 “AI 重构生活” 的主题,以 AI 技术解决了新手父母育儿的真实痛点,让人工智能走出实验室,落地到日常家庭育儿的微小场景中,展现了 “低门槛、高创意” 的 AI 数字化表达。
- 6.总感觉识别率不太高,可能与在学校的环境和硬件麦克风有关
六、反思和展望
(一)项目反思
- 1.模型泛化能力仍有提升空间:目前项目的训练数据集主要覆盖 0-1 岁婴儿的啼哭音频,对于新生儿(0-3 个月)和 1 岁以上幼儿的啼哭识别准确率仍有优化空间,数据集的年龄段、场景覆盖度仍需扩充。
- 2.复杂环境抗干扰能力不足:在高噪音的家庭环境(如电视声、多人交谈声)中,背景噪音会对识别准确率产生一定影响,噪音过滤与抗干扰逻辑仍需进一步优化。
- 3.功能场景适配性有待拓展:目前项目仅实现了单轮手动触发的识别功能,尚未实现婴儿啼哭自动触发、连续监护、远程提醒等功能,对于夜间无人监护等场景的适配性不足。
- 4.育儿服务闭环尚未完善:目前项目仅实现了啼哭需求的识别,未针对不同需求匹配对应的科学安抚、护理方案,育儿辅助的完整闭环仍需补充。
- 5.该模型使用的样本是网上下载的,缺少实时录制的(条件限制),有待补充。
(二)未来展望
- 1.模型与数据集优化:持续扩充不同年龄段、不同家庭场景、不同口音环境下的婴儿啼哭数据集,优化模型训练参数,进一步提升模型的泛化能力与复杂环境下的识别准确率。
- 2.功能场景拓展:新增婴儿啼哭自动触发识别、24 小时连续监护模式,对接消息推送能力,实现婴儿啼哭实时提醒,适配夜间监护、临时无人看护等场景。
- 3.软硬件结合落地:基于现有核心模型与逻辑,对接行空板等开源硬件,实现脱离电脑的离线部署,打造便携式婴儿啼哭监护终端,拓展创意智造方向的落地能力。
- 4.完善育儿服务闭环:针对不同的啼哭需求,匹配对应的科学安抚方法、护理知识、育儿建议,新增育儿日志功能,自动记录婴儿啼哭的时间、类型、频次,生成个性化育儿分析报告,形成 “识别 - 分析 - 建议 - 记录” 的完整育儿辅助闭环。
- 5.多端适配与分享:拓展网页端、移动端的适配能力,让工具可以在更多设备上运行;新增识别结果分享功能,帮助父母远程同步宝宝的状态,让异地家人也能参与到宝宝的成长中。
附:素材链接
通过网盘分享的文件:DF大赛.rar
链接: https://pan.baidu.com/s/1Xtz41vKAGLu7zyIrsNd2yQ?pwd=d6i1 提取码: d6i1



 他的勋章
他的勋章






评论