 返回首页
返回首页
 回到顶部
回到顶部

1. 1项目介绍
本项目致力于打造一个懂情绪、护安全的智能驾驶“伙伴”,帮助缓解长途驾驶中无聊、缺互动且疲劳的真实问题。比如:高速开车时想分享开心事却没人回应,或是深夜赶路时眼皮打架却没人及时提醒。我们通过图像分类技术识别表情,让行空板M10化身成贴身驾驶伙伴,它能通过摄像头实时捕捉你的面部表情,精准识别开心、生气、疲劳打盹等状态,并给予实时的互动,如一旦发现你眼皮耷拉、头部微垂的打盹迹象,立刻用文字+图片+音乐提醒“休息,休息一会”。
你可以把它用在日常通勤路上,比如在早高峰堵车时与它互动来缓解烦躁;也能拓展到长途自驾场景,让它实时监测疲劳状态;甚至还能适配网约车、货运司机的工作场景,为职业驾驶安全加一道“防护锁”。从数据收集、模型训练到推理与应用,完整呈现人工智能技术如何解决真实生活需求,让 “懂情绪、护安全” 的智能陪伴,走进每一段日常车程。
1.2演示视频
2. 项目实现原理
本项目基于图像分类技术实现表情识别与互动功能,整个实现过程涵盖从数据准备到模型推理与应用的全流程。具体而言,首先通过 Mind+ 模型训练平台进行图像分类模型的图像采集与模型训练;训练完成后,对模型进行校验与优化,并导出为适用于行空板M10的格式;最终将模型部署至行空板M10进行推理应用,利用其摄像头捕获实时画面,由模型进行推理识别,输出表情类别,并执行对应的操作。
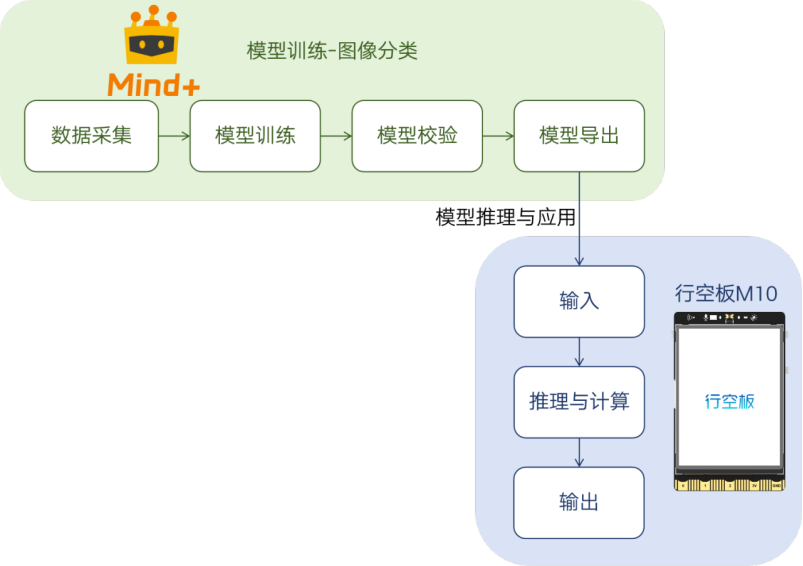
3.软硬件环境准备
3.1软硬件器材清单

注意:行空板系统版本在 v0.4.1 及以上均适用于本项目制作,行空板的 Python 环境版本为 3.12,Mind + 编程软件版本为 v2.0。
3.2硬件连接准备
本项目需在行空板上实现图像 “输入 - 推理与计算 - 输出” 流程:通过 USB 摄像头拍摄图像,在行空板部署图像分类模型完成推理与结果输出。
请参照连接图,完成电脑、行空板与 USB 摄像头的连接:

3.3软件平台准备
官网下载安装Mind+ 2.0及以上版本安装包,安装完成后,双击打开。

3.4环境和扩展准备
本项目需要行空板的Python环境的版本为3.12.7,请根据下面的步骤将其切换到指定版本。
打开编程软件Mind+,选择“程序设计”中的“Python模式”。


进入 “扩展” 页面并搜索 “行空板”,点击扩展包上的 “下载” 按钮。
下载完成后点击该扩展包完成加载,再点击 “返回” 按钮返回编程界面。
在终端连接选项中中选择“默认-10.1.2.3”以连接行空板M10。
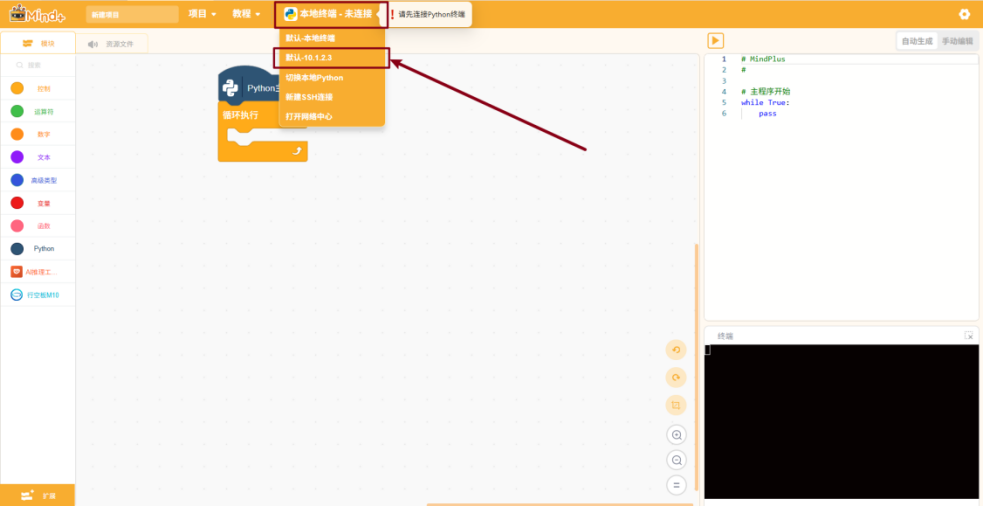
在终端中输入“python --version”后按下“回车”键以检查行空板M10的Python环境版本:
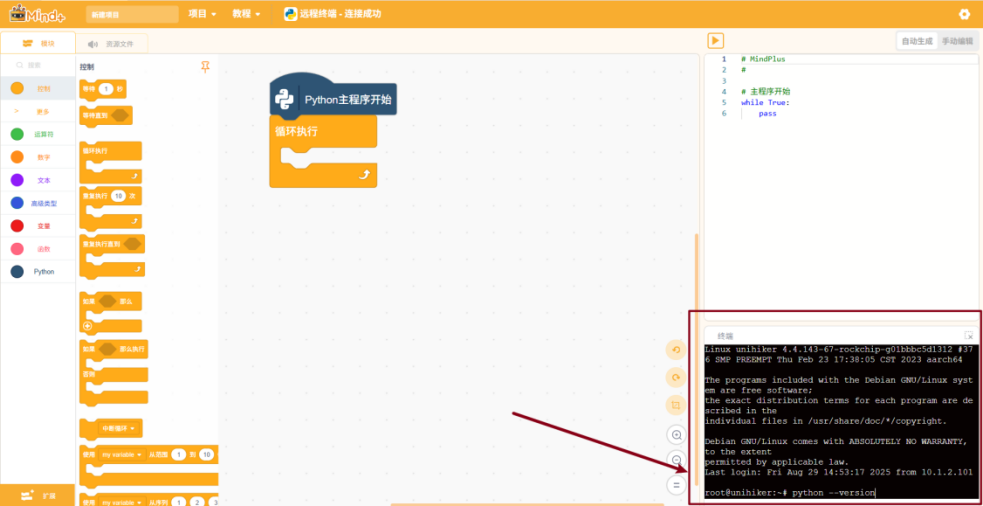
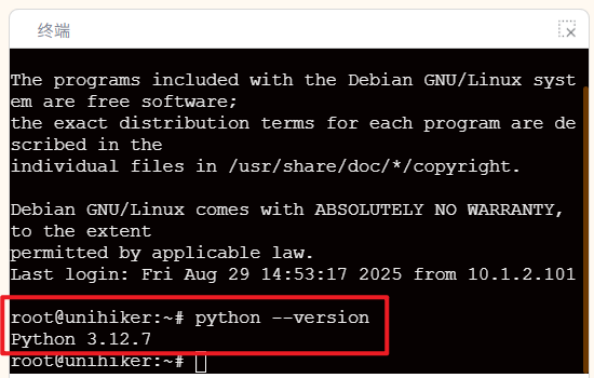
如上图行空板的Python环境已为指定版本3.12.7。
若版本不符合,请在终端中输入“pyenv global 3.12.7”以将其切换为该版本。
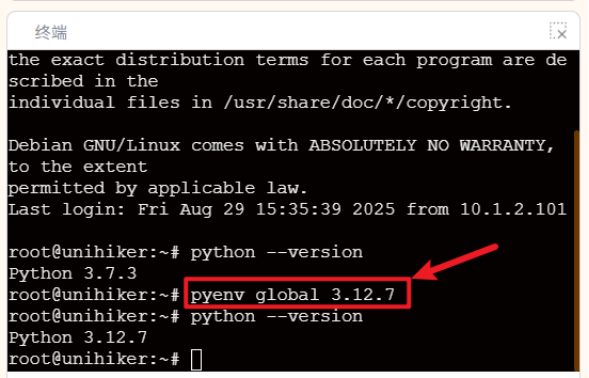
环境切换完毕后,需要加载扩展并按照提示下载依赖库。请按照下面的步骤操作。
由于依赖库是要下载到行空板中的,我们需要先给行空板联网。
在浏览器地址栏中输入“10.1.2.3”。

选择“网络设置”->点击“扫描”->选择无线网络名称并输入密码->点击“连接”。
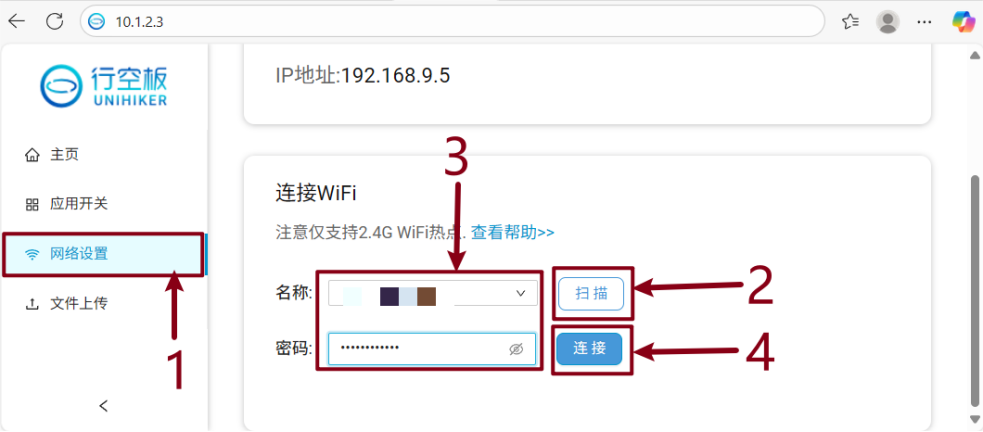
显示“wifi连接成功”,你的行空板已经连接好了网络。
行空板的环境和网络都设置成功了,接下来需要加载模型推理相关的扩展。
在扩展中搜索“模型训练”点击下载并添加该用户库。
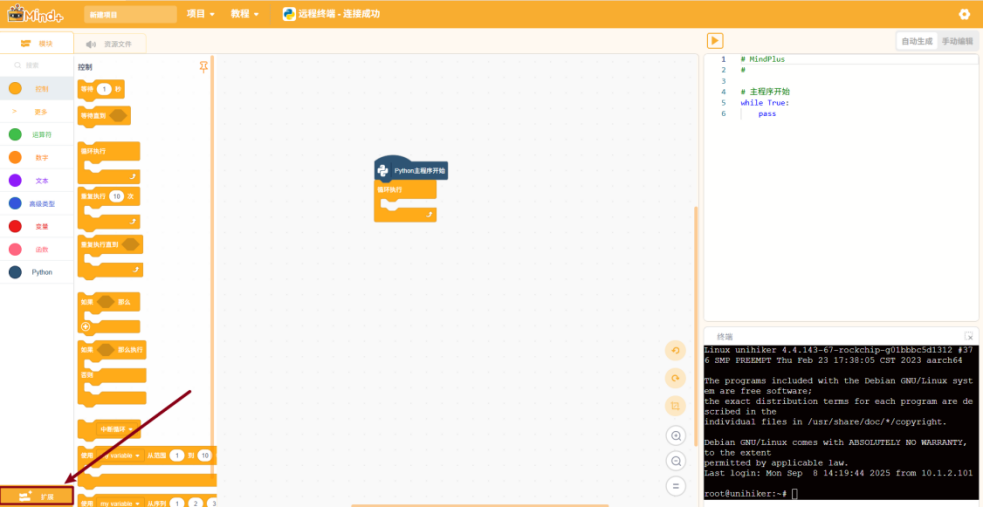
出现下载指定依赖库的提示后,按照提示点击 “确定” 进行下载。
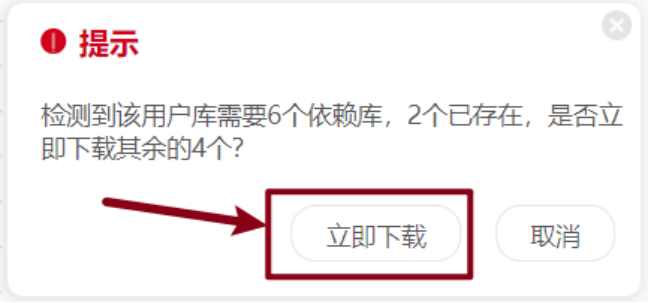
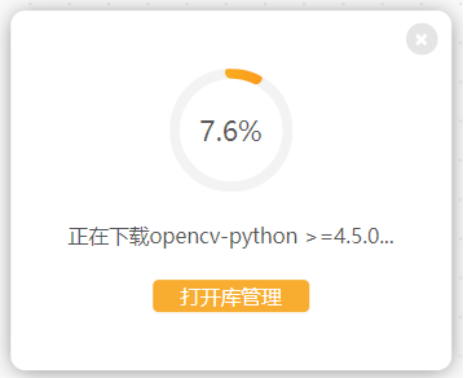
4.项目制作
我们使用Mind+中的模型训练来完成人脸表情的采集、模型训练和导出。
首先,打开Mind+软件,选择“模型训练”并打开“图像分类”(注意:只有Mind+2.0及以上版本才有模型训练功能)。
打开初始界面如下:
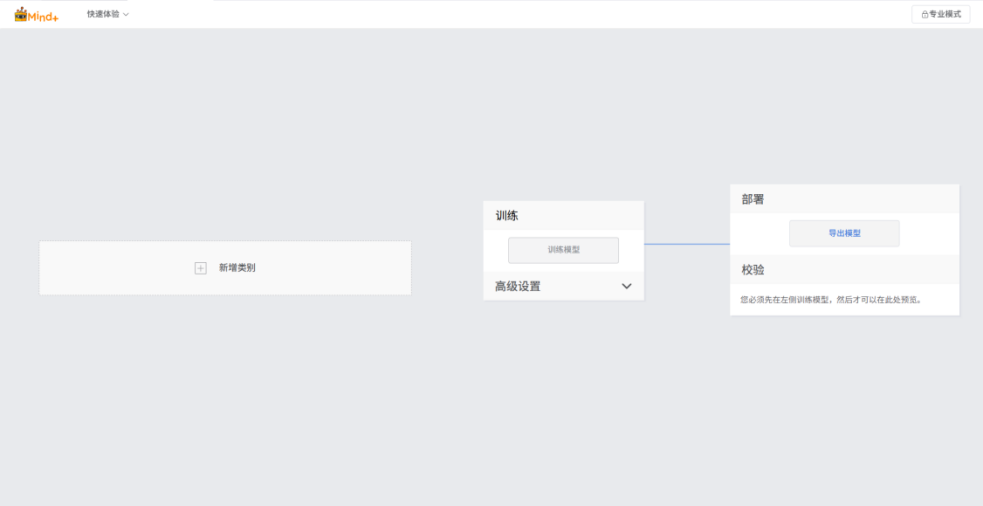
页面分为三部分,从左至右依次为:数据采集、模型训练、模型校验与导出(后面会详细说明各部分的使用方法)。
4.1数据采集
为了训练表情分类模型,我们需要准备含有不同类别的数据集。
点击“新增类别”进行类别的设置。
编辑类别的名称。
本项目中使用了面无表情、开心、疲劳和愤怒的三种表情,所以需要添加四个类别,设置好的类别如下:
类别设置完成后,接下来依次对每一个类别进行数据的采集,我们可以使用摄像头进行采集,步骤如下:
点击摄像头进行数据采集。
长按“按住即可录制”按钮开始数据采集。
默认为一秒采集一张照片,可根据需要在设置中进行调整。
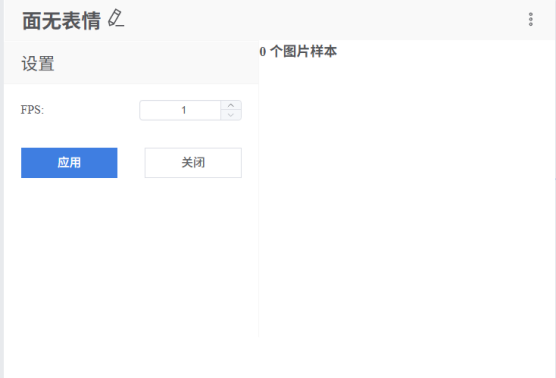
(FPS为每秒帧数,是指每秒钟采集的图像帧数量)
按照上述采集步骤依次对剩下三类表情进行采集。
所有表情采集结束后,关闭摄像头。
到这里,表情数据集就准备完毕了,本项目使用数据集大小为:每个类别50个样本,四个类别共计200个样本。
该数据集见附件,你也可以通过下面的步骤上传数据。
点击“上传数据”,并选择“选择文件上传”。
打开数据集对应类别的数据集文件夹。
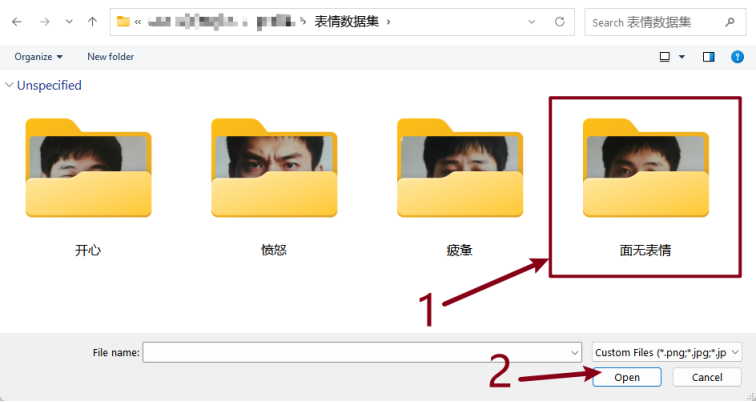
将文件全选后,点击“打开”。
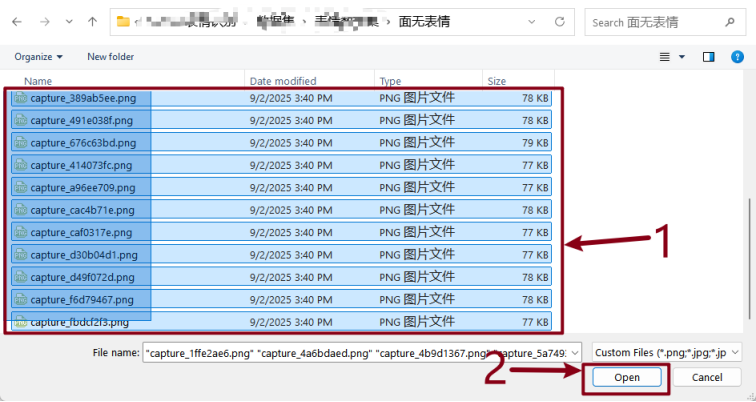
按照相同的方式上传剩余三类的数据。
上传完成后如下:
数据集准备完成后,我们即可进入模型训练环节。
4.2模型训练
在训练模型前,我们需要根据数据集特点修改训练参数。
展开“高级设置”以调整参数。
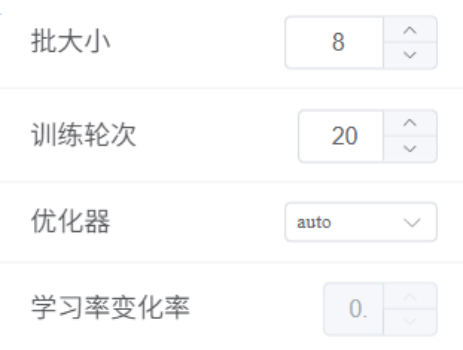
本项目使用的数据量约为 200 张,训练模型的参数如下:
参数设置完成后,只需点击 “训练模型” 按钮,即可开始模型训练(训练过程中请保持该页面开启,确保训练不中断)。
在训练过程中,点击“深入了解”,可对模型训练过程进行监测。
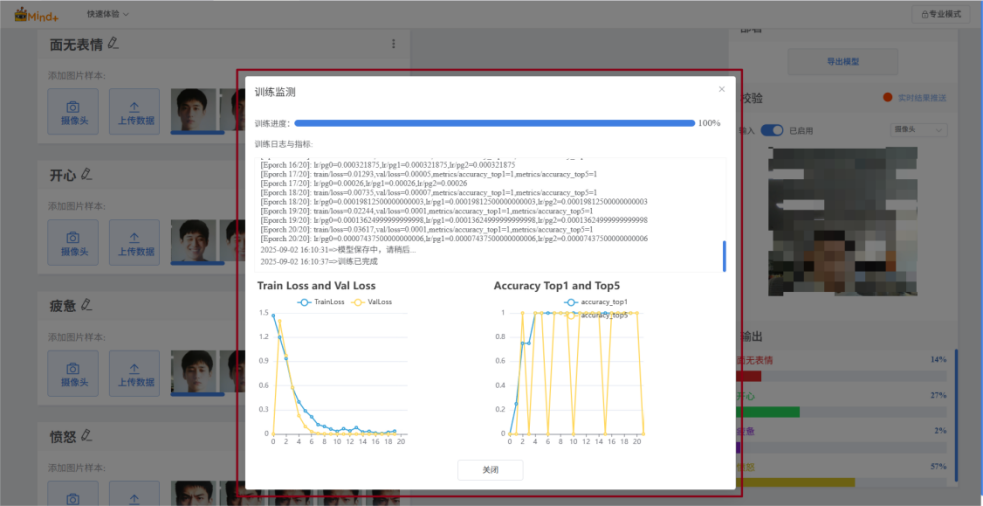
等待训练完成,点击“确定”。
4.3模型校验与导出
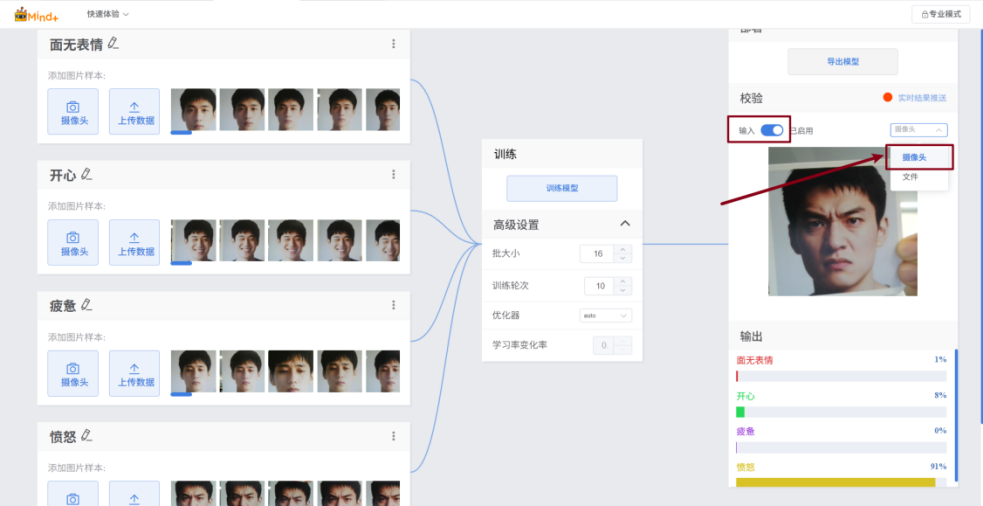
模型训练结束后,可以通过模型校验来验证模型效果。请按照下面的步骤使用摄像头拍摄进行校验。
开启“输入”开关->选择摄像头->将摄像头对准目标->观察输出
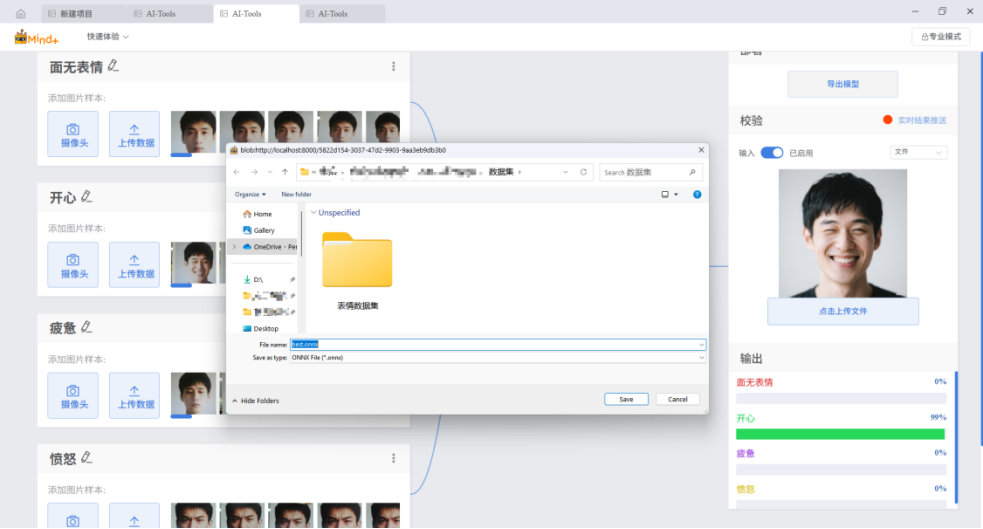
同时,该项目的附件中也提供了测试文件,可通过下面的步骤进行上传文件的校验。
开启“输入”开关->选择“文件”->点击“选择文件上传”->选择文件并点击确定->观察校验结果。
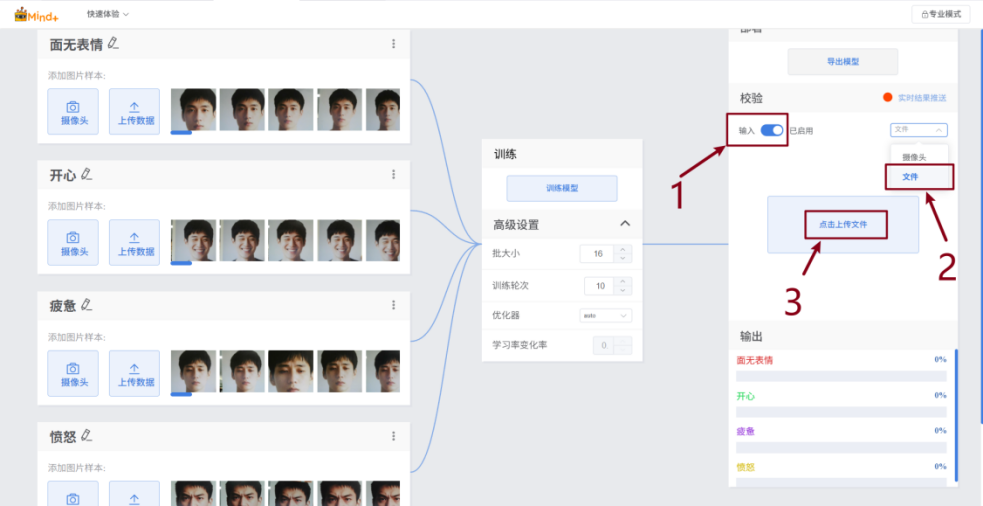
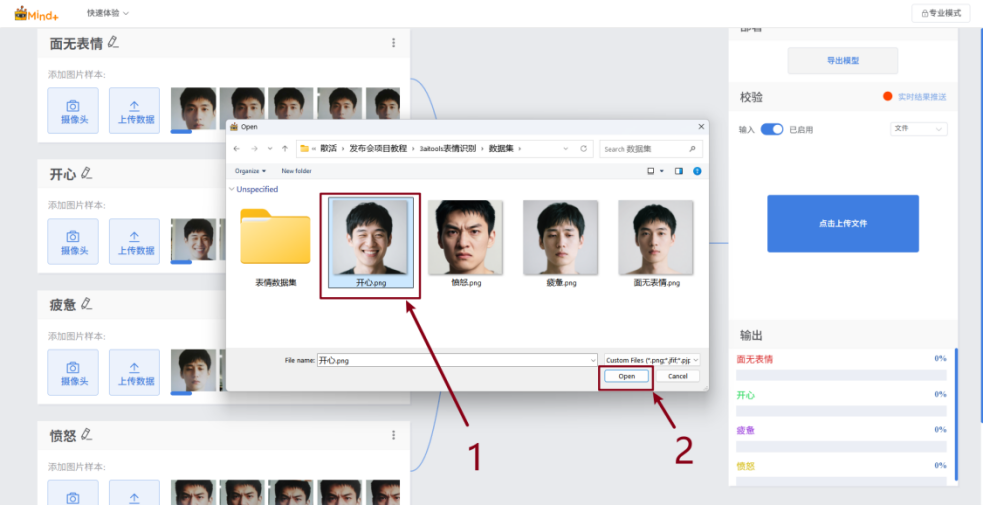
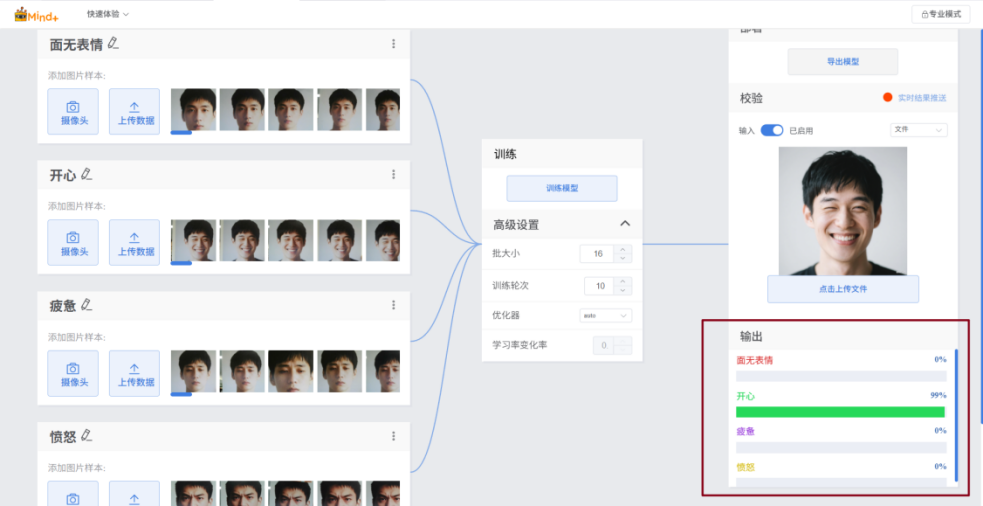
校验结果符合预期后,即可导出模型文件。
点击“导出模型”将模型导出为onnx格式的文件和yaml格式的配置文件(上述两个文件在模型推理与应用中会使用到)。
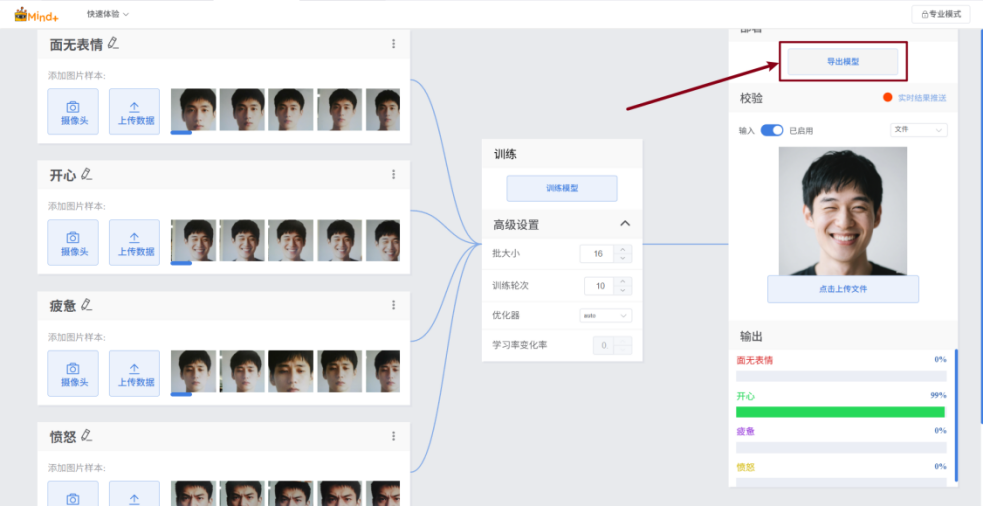
选择位置保存模型文件。
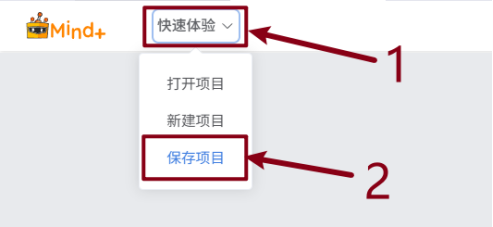
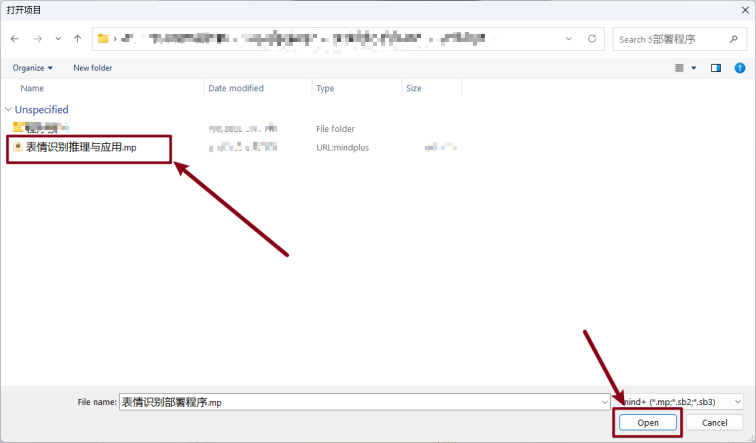
建议将该模型训练项目保存为项目文件,方便后期对模型进行优化和调整。步骤如下:
展开“快速体验”,选择保存项目。选择要保存的位置,点击“确认”完成保存操作。并通过“快速体验”中的“打开项目”打开保存的项目文件。
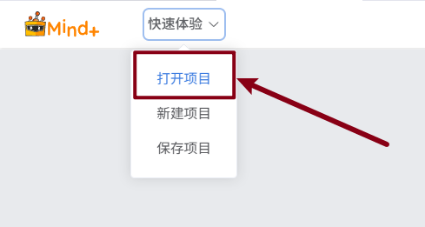
模型训练和导出到这一步就结束了,之后就是模型的推理与应用了。
4.4模型推理与应用
请按照下列步骤将模型训练导出的模型文件上传到行空板M10中,并编写程序完成表情的图像分类并执行对应结果。
请按照下面的步骤上传模型文件。
打开Mind+编程软件并进入python模式。
第一步:请按照下面的步骤上传模型文件。
点击“资源文件”->选择“上传文件”->选择模型(.onnx)及其配置文件(.yaml)->点击“打开”。
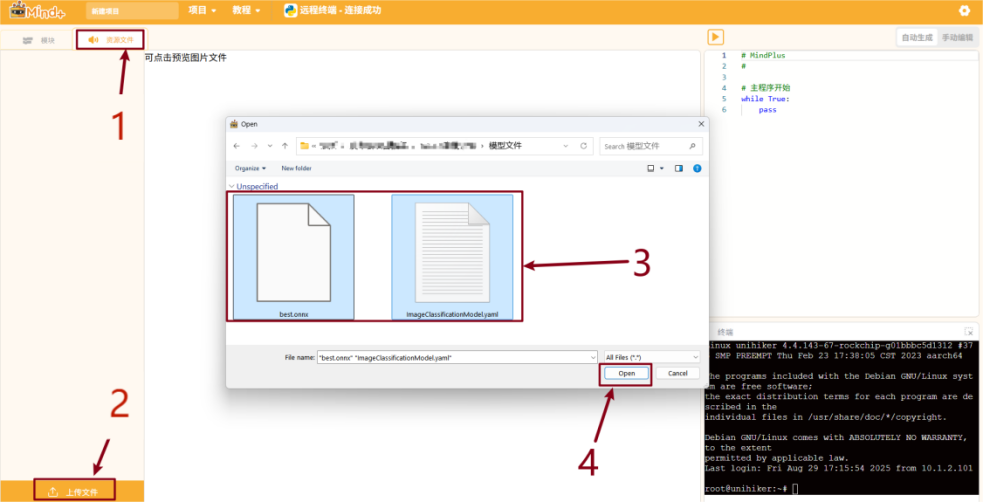
模型文件上传成功。
第二步,编写程序,程序如下:
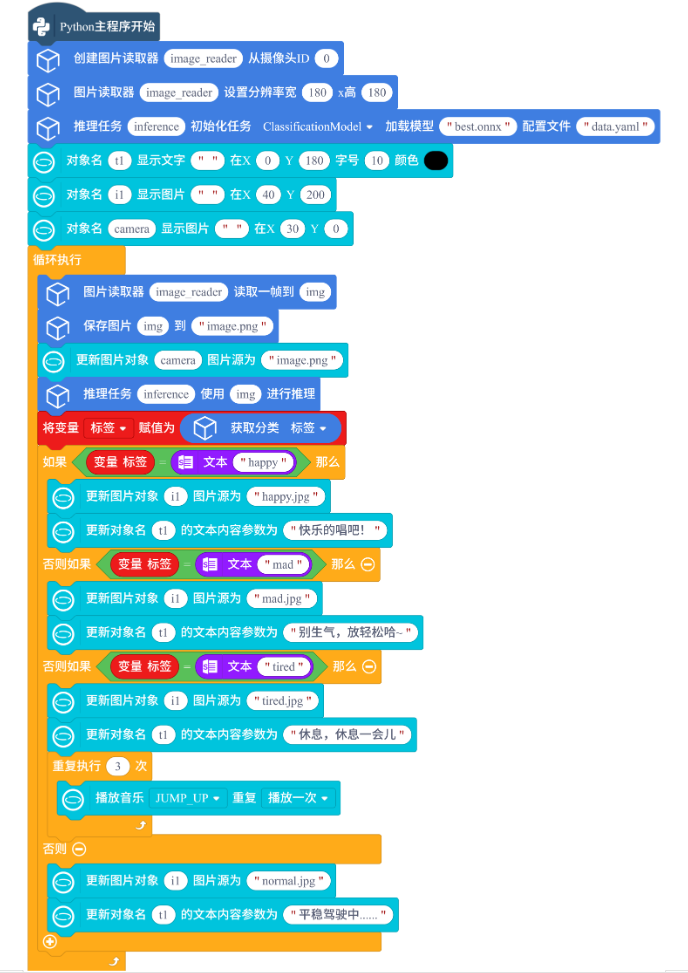
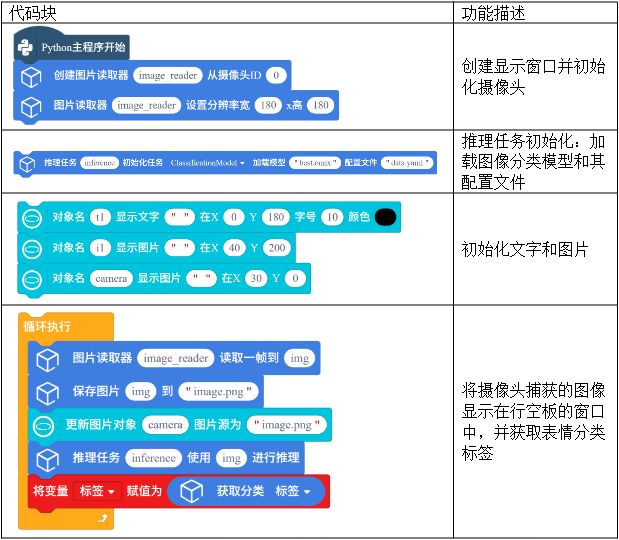
我们一起来看一下表情识别推理与应用程序的核心功能。
如下图,此程序主要分成以下几个部分:

第三步,运行并验证,点击“运行”图标运行程序。

将摄像头对准驾驶员的脸部,行空板对拍摄到的画面实时进行推理,显示表情分类并执行相应的操作与驾驶员进行互动。
实现效果图片如下:

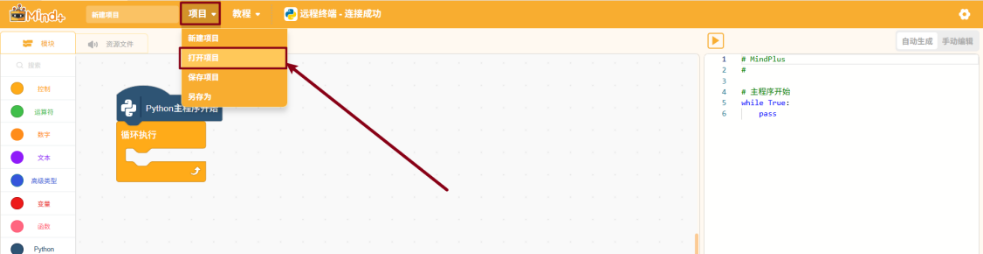
项目附件中附有完整程序文件,操作流程如下:
展开 “项目” 菜单并点击 “打开项目”,并点击“运行”即可实现程序效果。

5.附件清单
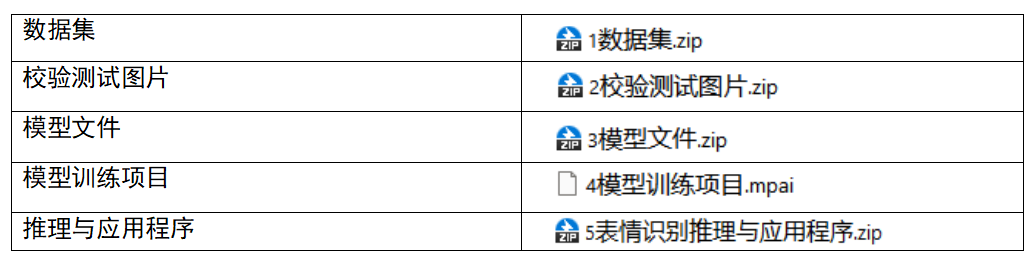
通过网盘分享的文件链接: https://pan.baidu.com/s/1oQPxaPFxGUoY_mppAv3ejw?pwd=eedp



 他的勋章
他的勋章

19192026.02.12
老师,用您的程序运行后出现下方错误,什么原因?怎么解决呢? root@unihiker:~# [INFO] Camera 0 opened successfully [model-mp-core] Model loaded successfully: best.onnx [Classification] Raw output shape: (1, 4) Traceback (most recent call last): File "/root/mindplus2/python-block/projects/表情识别推理与应用2/main.py", line 33, in <module> BiaoQian = result_output['result'][0]["class_name"] ~~~~~~~~~~~~~~~~~~~~~~~^^^ IndexError: list index out of range
19192026.02.04
请教老师,python --version Python 3.7.3 root@unihiker:~# pyenv global 3.12.7 -bash: pyenv:未找到命令 这个怎么解决呢?
李越橘2026.06.11
同问
19192026.01.23
请教一下,为什么我打开mind+2.0模型训练中的“图像分类”界面是英文的,如何切换到中文呢?
zoey不种土豆2026.01.26
软件界面语言不一致问题: https://mindplus.dfrobot.com.cn/mp2/FAQ/AITools/Model-shows-abnormalities/
罗罗罗2025.11.16
666
WT2025.09.23
你好,请问这个mind+ 2.0 版本从哪里能下载到 想跟着你的步骤一步步做
zoey不种土豆2025.09.23
目前还在内测阶段,可以关注3-5周后的正式公测哈
zoey不种土豆2026.03.16
Mind+ V2官网:https://mindplus.cc/ 技术文档:https://mindplus.dfrobot.com.cn/mp2/