 返回首页
返回首页
 回到顶部
回到顶部

1.项目介绍
1.1 项目简介
本项目是基于YOLOv8实例分割的优质苹果自动分拣项目,采用YOLOv8的实例分割能力,结合行空板M10和摄像头,识别并分类外观不同的苹果。系统能够实时检测摄像头画面中的苹果图像,识别出形状完美、外观优质的苹果(标签为:pleasing shape apple)和外形不规则、存在瑕疵的普通苹果(标签为“irregular apple”),实现基于形状检测的苹果自动分拣功能。本项目可用于水果礼盒定制、优质果品筛选、农业自动化等场景。
1.2 项目效果视频
2.项目制作分析
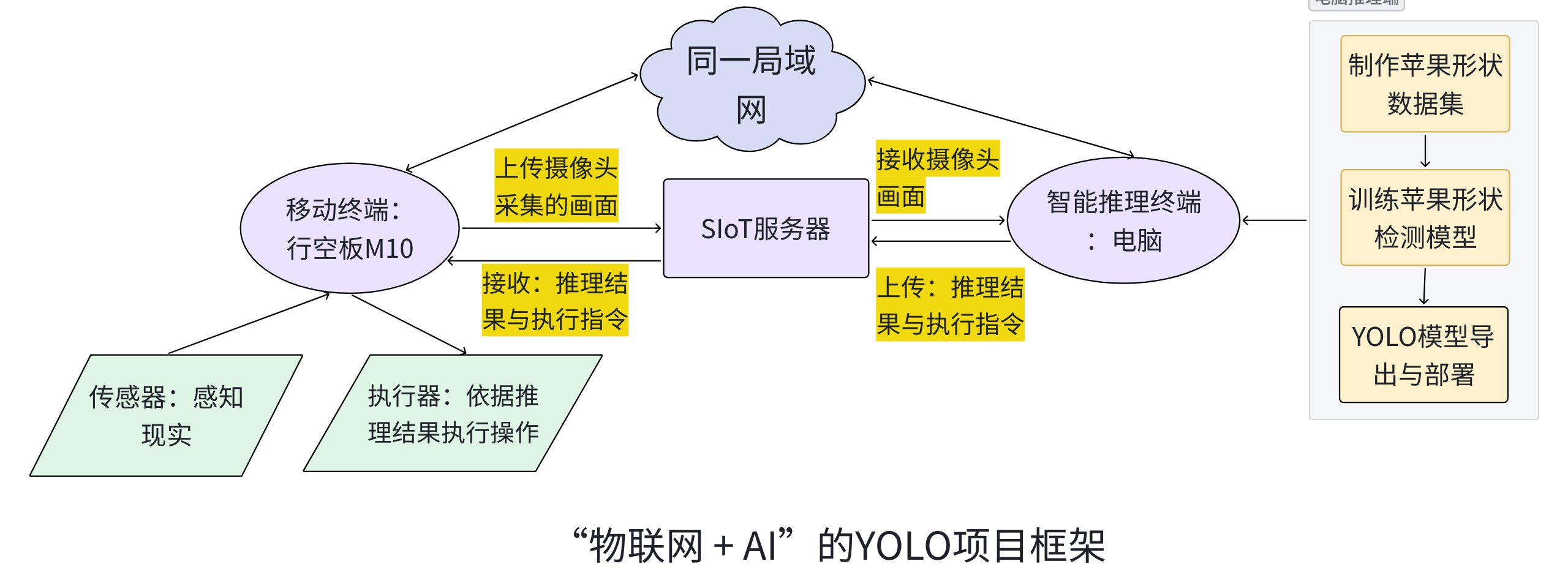
2.1 项目框架图
本苹果形状检测项目是基于YOLO实例分割技术,采集两类苹果数据集并使用数据标注软件标注苹果形状,使用YOLOv8框架训练出苹果形状检测模型(segment model),将模型部署到电脑,借助行空板M10与外界摄像头实时采集视频画面,通过物联网与SIoT技术,将行空板M10采集的画面传输到i电脑进行可视化推理并展示结果,完成自动分拣。
在本项目中,行空板M10与电脑通过局域网及 SIoT 服务连接,构成了“采集 + 推理 + 执行”的典型智能系统。行空板M10作为移动终端,能够外接传感器与执行器完成数据感知与执行控制。电脑作为外接算力,完成模型训练、部署与推理反馈。通过物联网实现电脑与行空板M10的实时通信,通过“AI + IoT”打造终端感知+一端推理的协同架构能整合具边缘感知、智能推理与实时执行等多个优势。
2.2 YOLO实例分割模型介绍
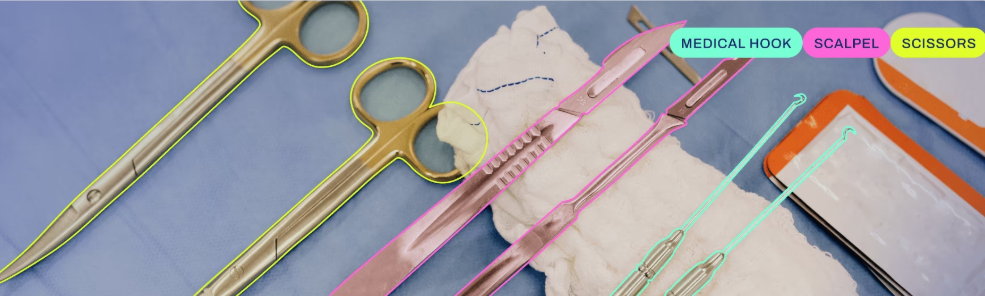
YOLO除了常为人熟知的目标检测功能外,还有一类叫做实例分割的模型,(YOLO segment model).实例分割模型的输出是一组勾勒出图像中每个物体的遮罩或轮廓,以及每个物体的类标签和置信度分数。实例分割比物体检测更进一步,它涉及识别图像中的单个物体,并将它们与图像的其他部分分割开来。当你不仅需要知道物体在图像中的位置,还需要知道它们的具体形状时,实例分割模型就非常有用了。相比 YOLO 目标检测,segment 支持更精细的轮廓分割,适用于检测对象形状、边缘缺陷、外观质量的任务,常用于果蔬筛选、手势识别、抠图抠像、表面质量检测等场景。
3.软硬件环境准备
3.1 软硬件器材清单

3.2 软件环境准备
由于我们使用电脑训练部署苹果形状检测模型,因此需要在电脑端安装相应的库(请事先在电脑上配置好Python相关环境变量)。
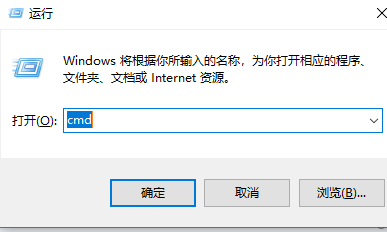
首先按下win+R,输入cmd进入窗口。
在命令行窗口中依次输入以下指令,安装ultralytics库与onnx相关库。
pip install ultralytics
pip install onnx==1.17.0
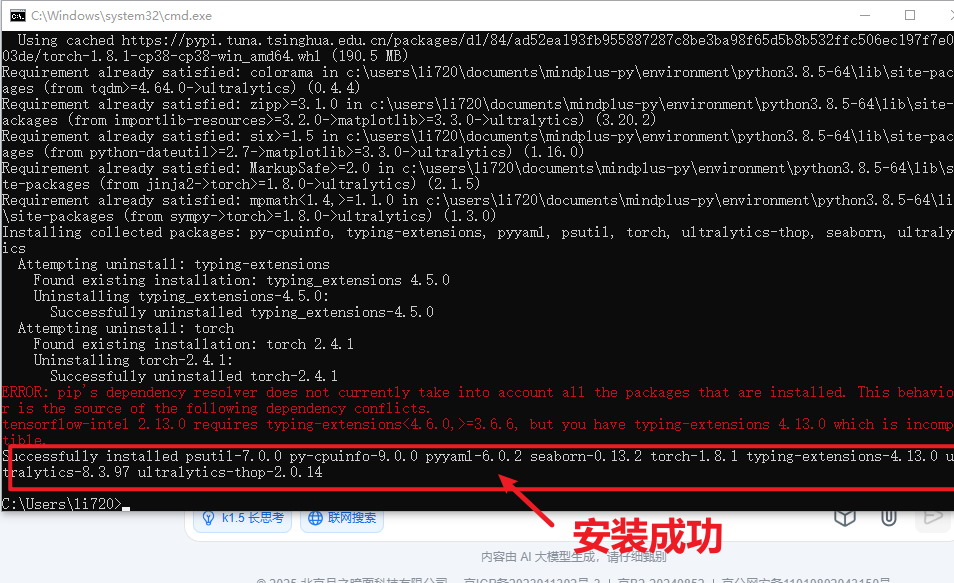
pip install onnxruntime==1.19.2当命令运行完成,出现以下截图表示安装成功。
3.3 硬件环境准备
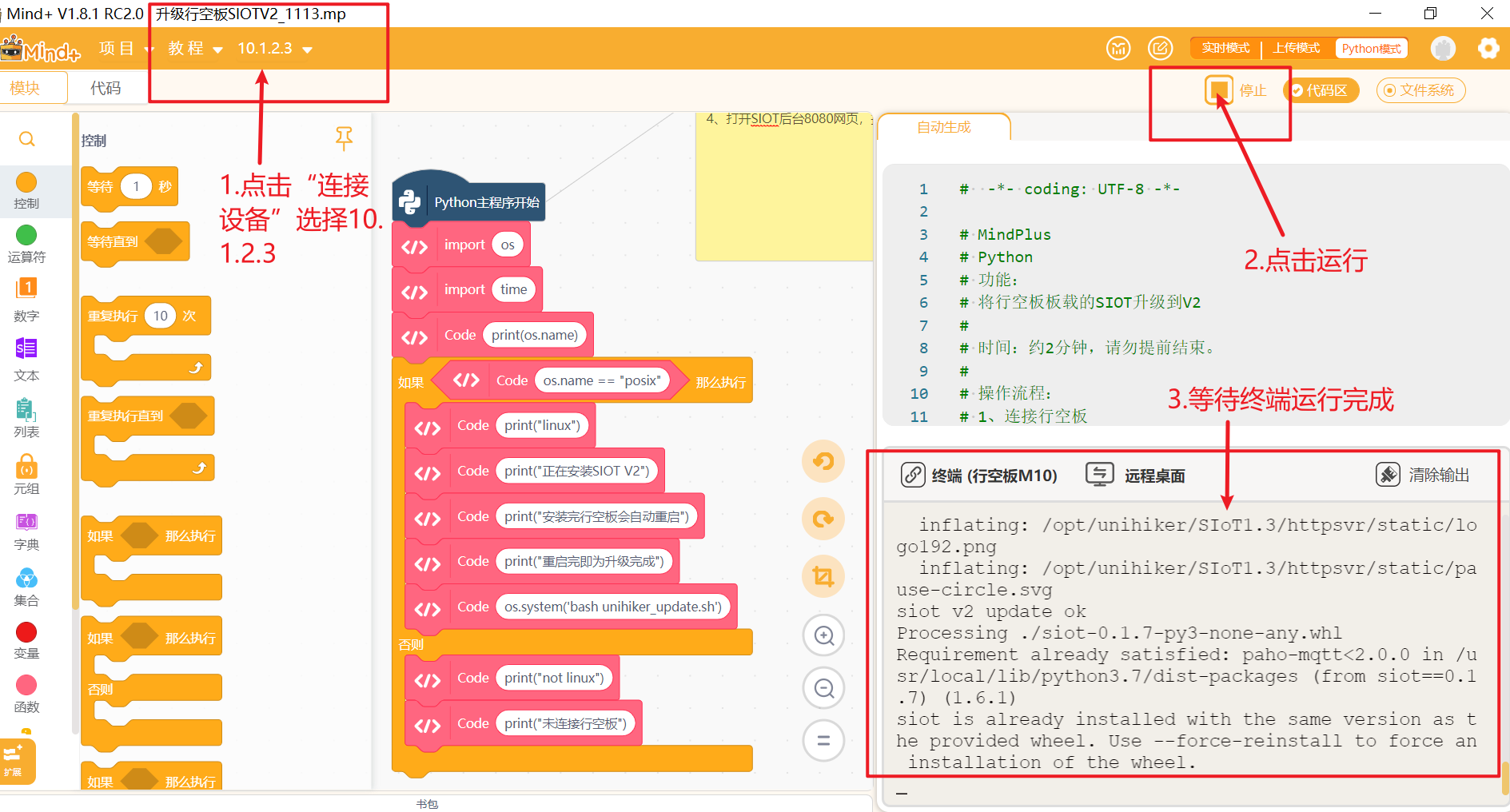
在本项目中我们要通过SIoT服务实现行空板M10与电脑的通讯,因此需要将行空板M10自带的siot升级至siot2.0版本。详情参考本链接。
使用USB数据线连接电脑与行空板,打开Mind+,选择Python模式。,等待行空板屏幕亮起表示行空板开机成功。运行“升级行空板SIOTV2_1113”程序(程序见最后附件)
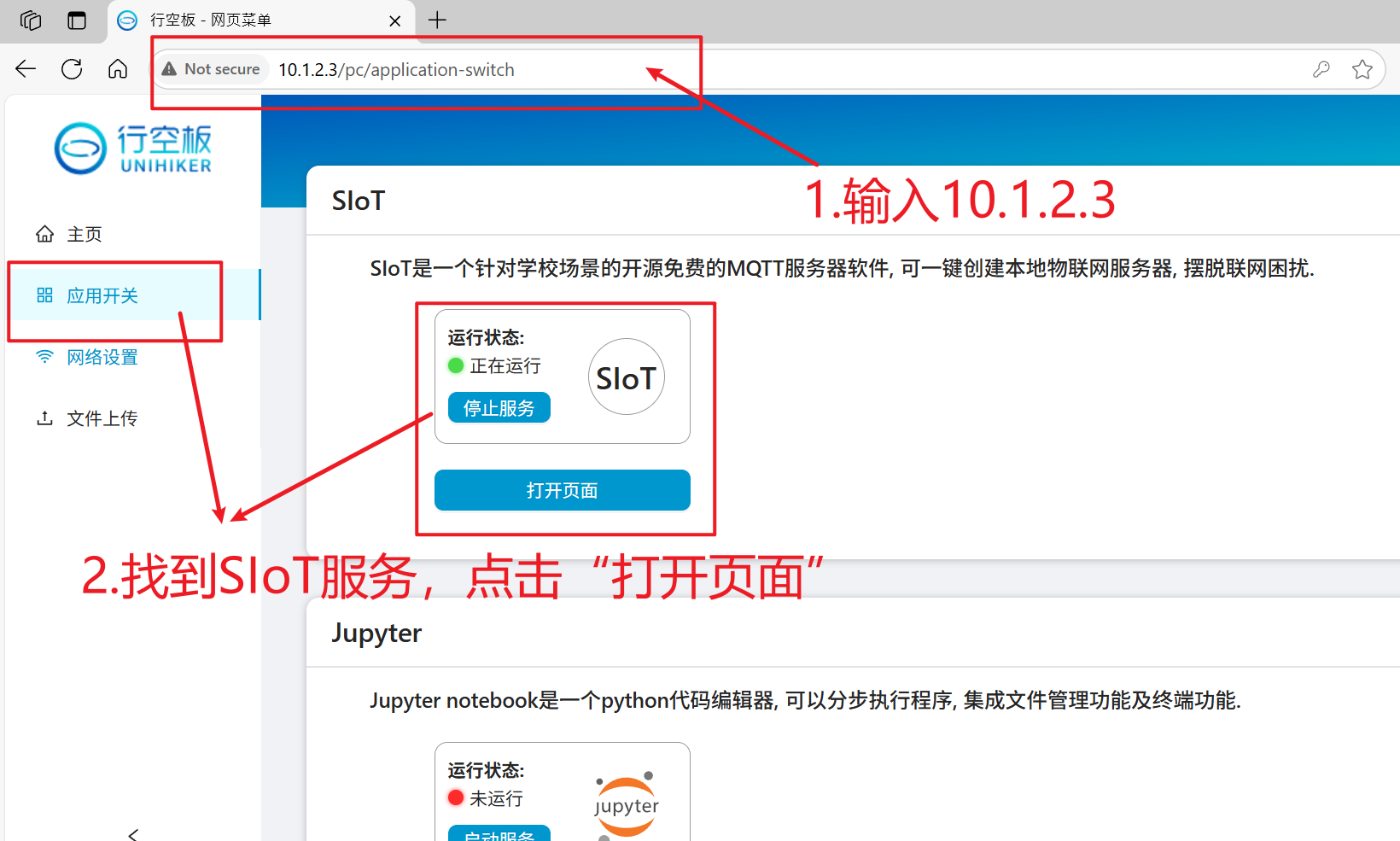
保持Mind+中行空板的连接,打开浏览器,输入“10.1.2.3”,进入行空板官方页面。
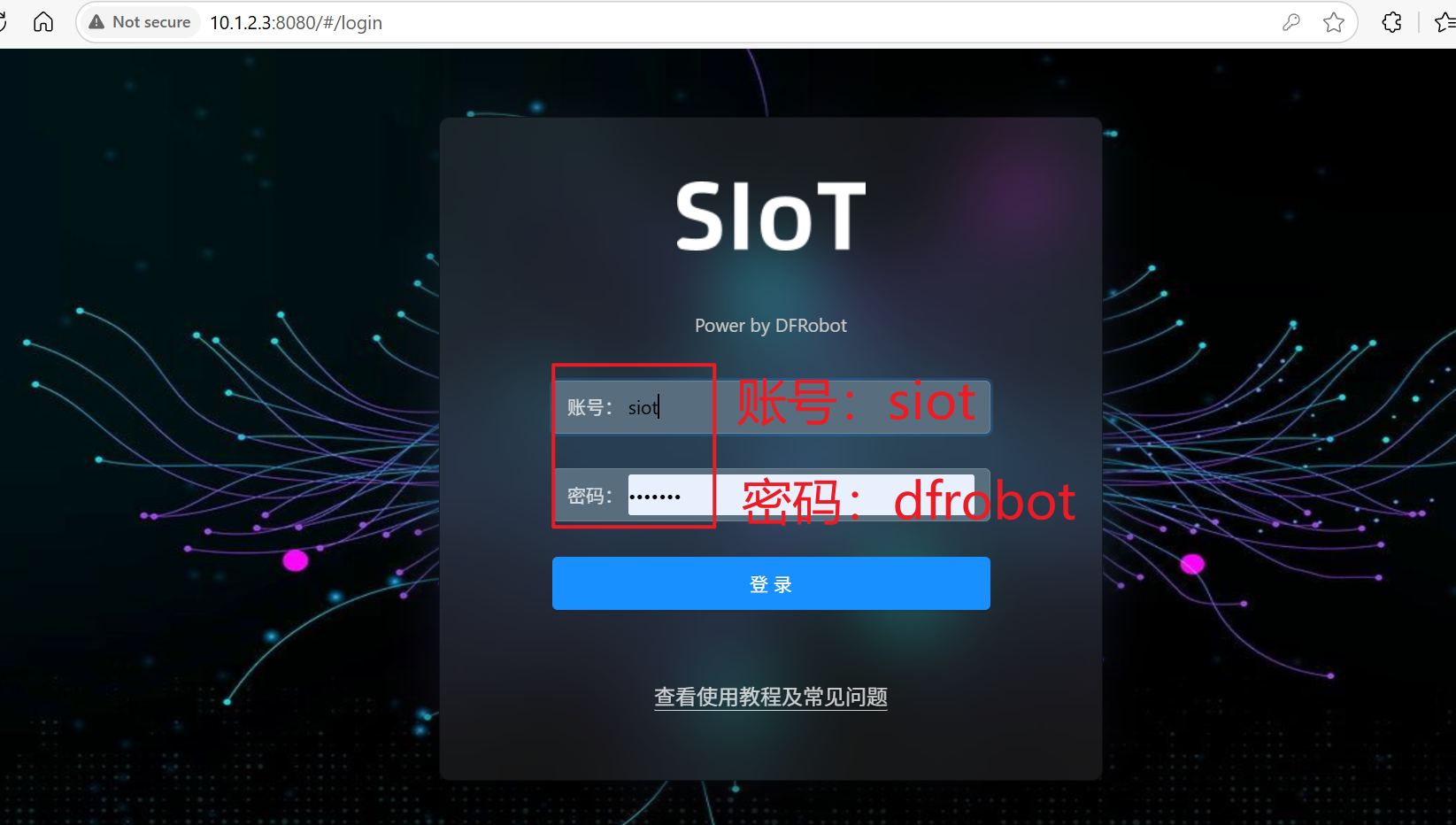
在siot页面输入账号和密码,点击登录。
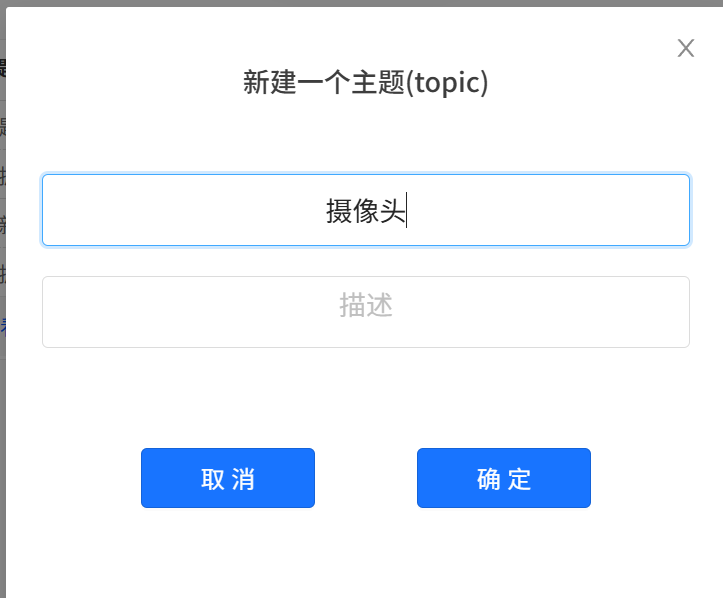
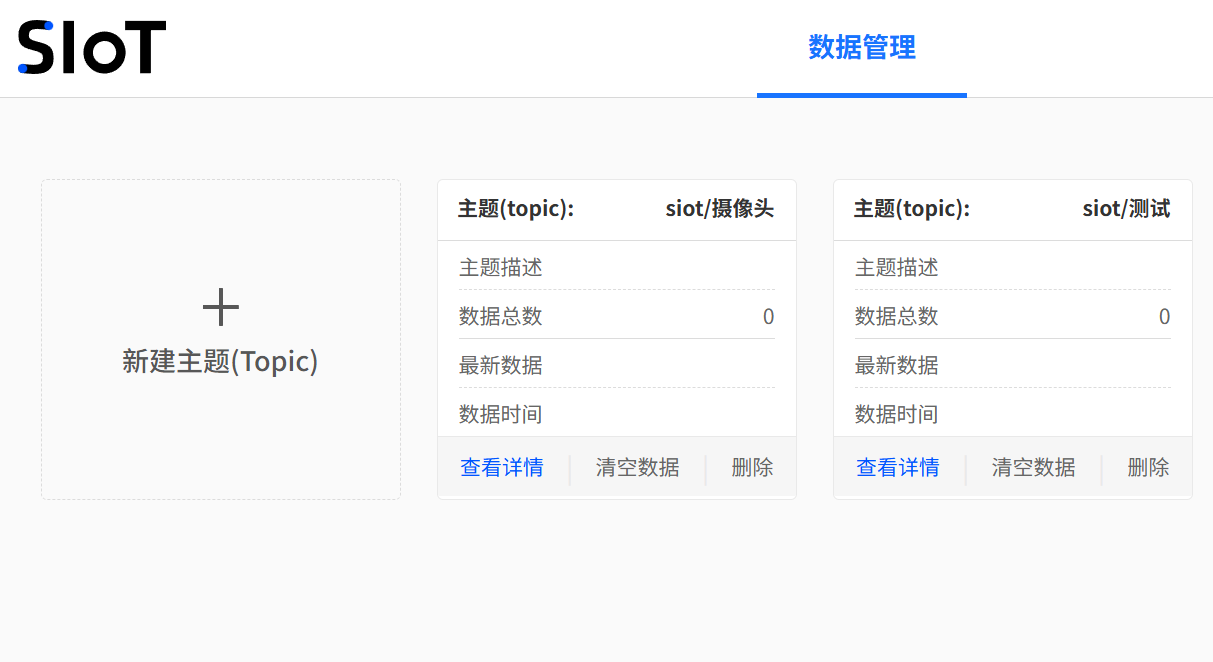
点击“新建主题”,创建一个名为”siot/摄像头“的主题,用于接收行空板M10摄像头采集的视频画面。
4. 制作步骤
4.1 数据集准备
为了训练苹果形状检测模型,我们需要准备符合YOLO segment数据集格式的苹果形状数据集。一个标准的YOLO 数据集包括训练集和验证集,每个子集都包含图像和标注文件(txt文件)。标注文件能提供目标的位置,形状和类别信息。
以苹果形状数据集数据集为例,标准的用于YOLO segment数据集的格式如下。
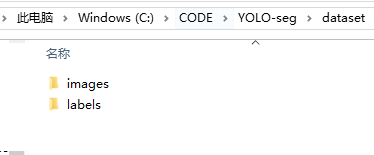
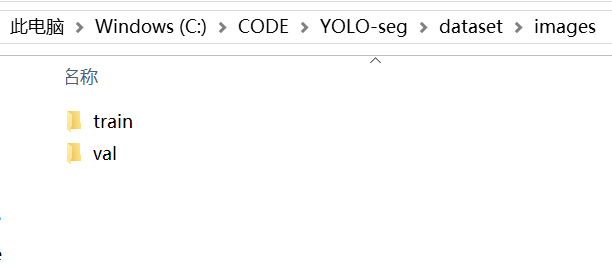
本项目使用的数据集总共包含两类的苹果的图片等信息(一类是外形规整无瑕疵品质较好的苹果;另一类是外形不太规整,有瑕疵,品质稍差的苹果),其中训练集和验证集图片数量共计约500张左右(数据集在文档最后的附件)。


dataset/ // 数据集根目录,用于存放训练和验证图像及标签
├── images/ // 图像文件夹,存放原始图片
│ ├── train/ // 训练集图像(用于模型学习)
│ └── val/ // 验证集图像(用于评估模型效果)
│
├── labels/ // 标签文件夹,存放与图像对应的分割掩码标注信息(.txt 或 .json)
│ ├── train/ // 训练集图像的分割标签(polygon 或 YOLO格式)
│ └── val/ // 验证集图像的分割标签
│
└── dataset.yaml // 数据集配置文件,包含以下信息:
// - path:数据集根目录路径(可为绝对或相对路径)
// - train:训练图像路径(如 images/train)
// - val:验证图像路径(如 images/val)
// - nc:分类数量(例如2类苹果)
// - names:类别名称列表(如 ['irregular apple', 'pleasing shape apple'])如下图,是苹果形状检测模型训练的YAML文件。

准备好数据集后,接下来我们就可以进入模型的训练环节了。
4.2 模型训练
在数据集的同一目录下创建一个名为”train.py“的文件,将以下训练代码复制到文件中,训练代码如下。我们使用ultralytics官方提供的预训练实例分割模型yolov8n-seg.pt,在此基础上使用苹果形状数据集,训练20轮次。
# train_yolov8_segment.py
from ultralytics import YOLO
# === 第一步:加载模型 ===
# 使用YOLOv8官方提供的预训练模型作为基础,可以选用以下之一:
# yolov8n-seg.pt(Nano,小且快)、yolov8s-seg.pt(Small)、yolov8m-seg.pt(Medium)
model = YOLO("yolov8n-seg.pt")
# === 第二步:开始训练 ===
model.train(
data="dataset.yaml", # 指向你的 dataset.yaml 配置文件
task="segment", # 明确任务类型为 "segment"
imgsz=640, # 图像输入尺寸(推荐为640或更大)
epochs=20, # 训练轮次
batch=16, # 每批次处理图像数,受限于显存
name="apple_seg_model", # 训练结果输出文件夹名:runs/segment/apple_seg_model
save=True, # 是否保存模型权重
save_period=10, # 每隔多少epoch保存一次
val=True, # 每个epoch结束后进行验证
workers=2 # 数据加载线程数量,适当调小防止卡顿
)
# === 第三步:可选 - 评估最优模型 ===
# 训练完成后自动生成 best.pt,可使用以下方式验证其效果:
# model.val() 会评估 metrics,如 mAP、IoU 等
metrics = model.val()
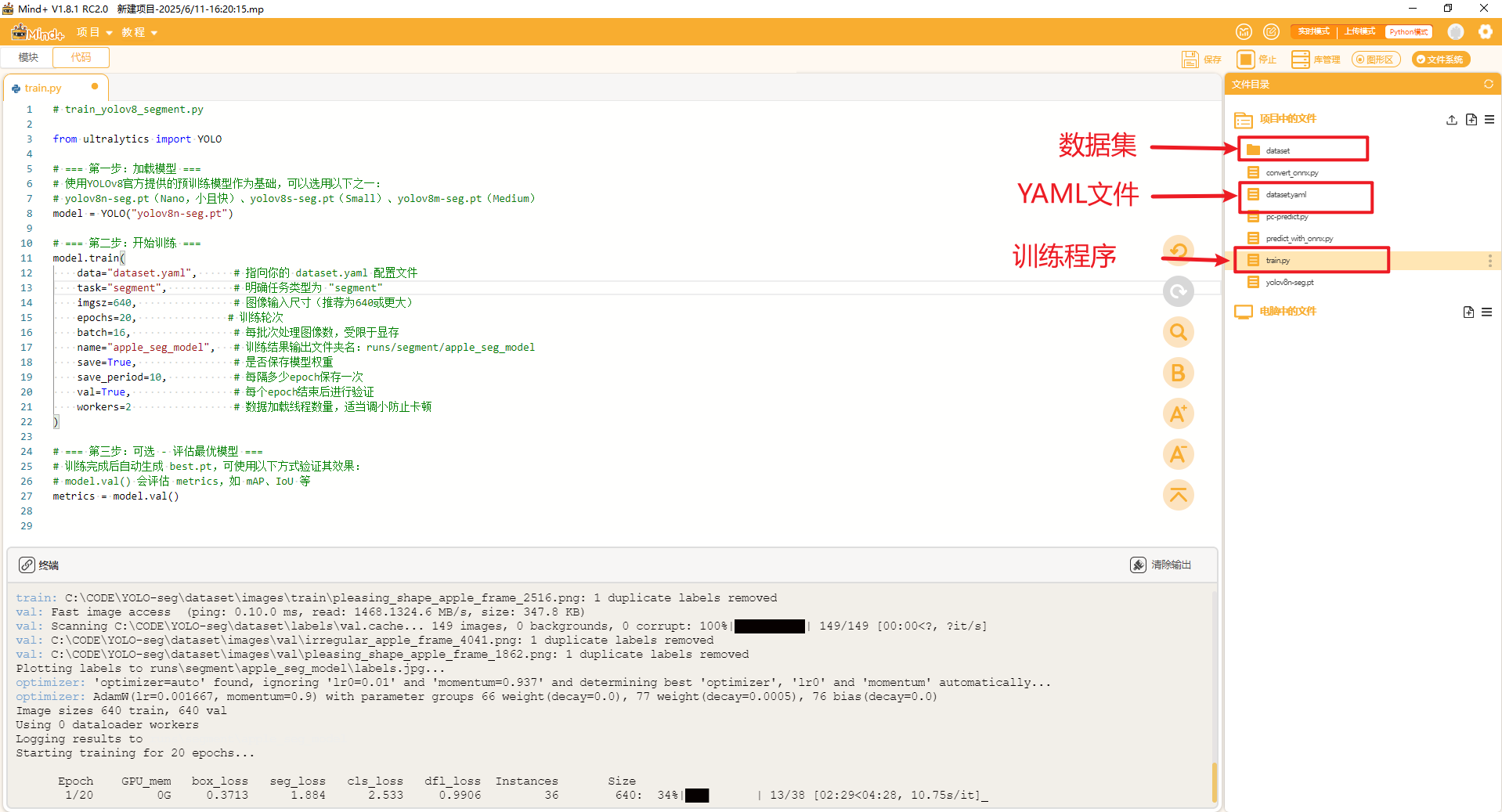
如下图,可以在终端看到详情的训练信息与训练结果。
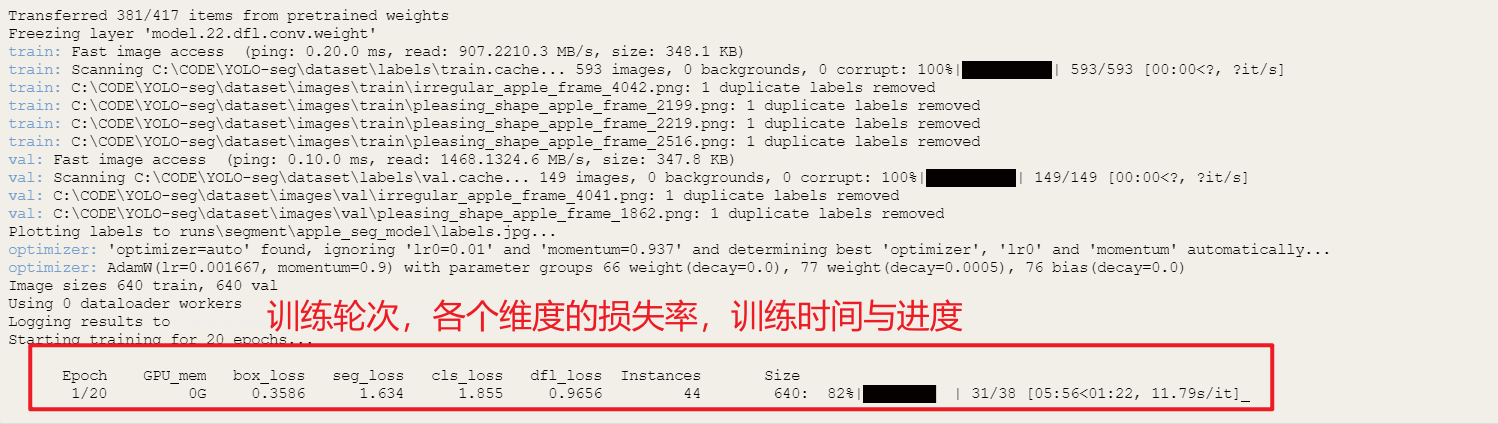
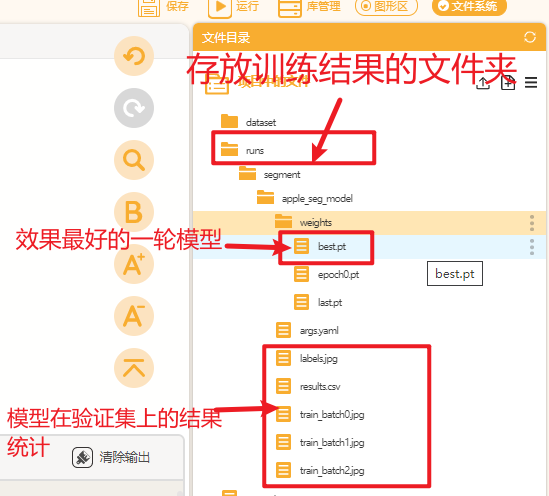
训练完成后在Mind+页面点击刷新按钮,可以观察到在文件目录中生成一个名为”runs"的文件夹,里面存放了训练得到的模型文件以及模型在验证集上的预测结果等信息。
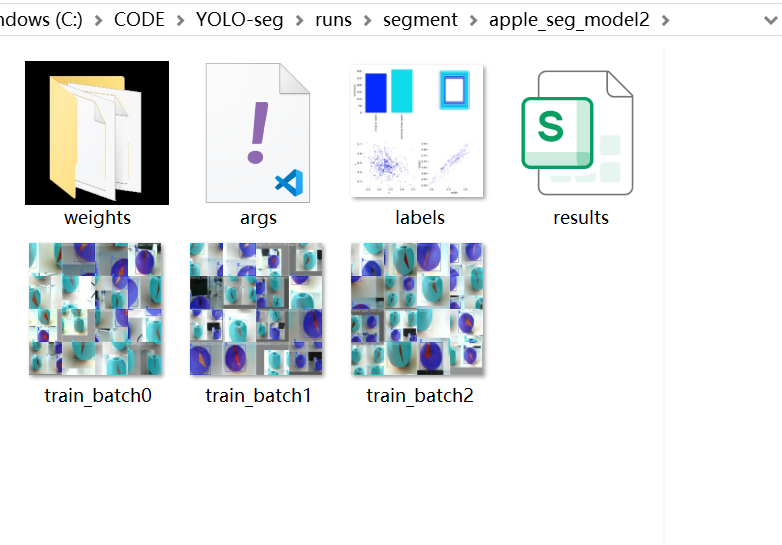
4.3 模型转换
我们训练得到的"best.pt"可以直接用于推理,我们也可以将"best.pt"转成onnx格式的模型文件。ONNX 格式,也是一种模型文件的格式,更加通用,可以与各种推理引擎兼容,提供更高效的推理速度。
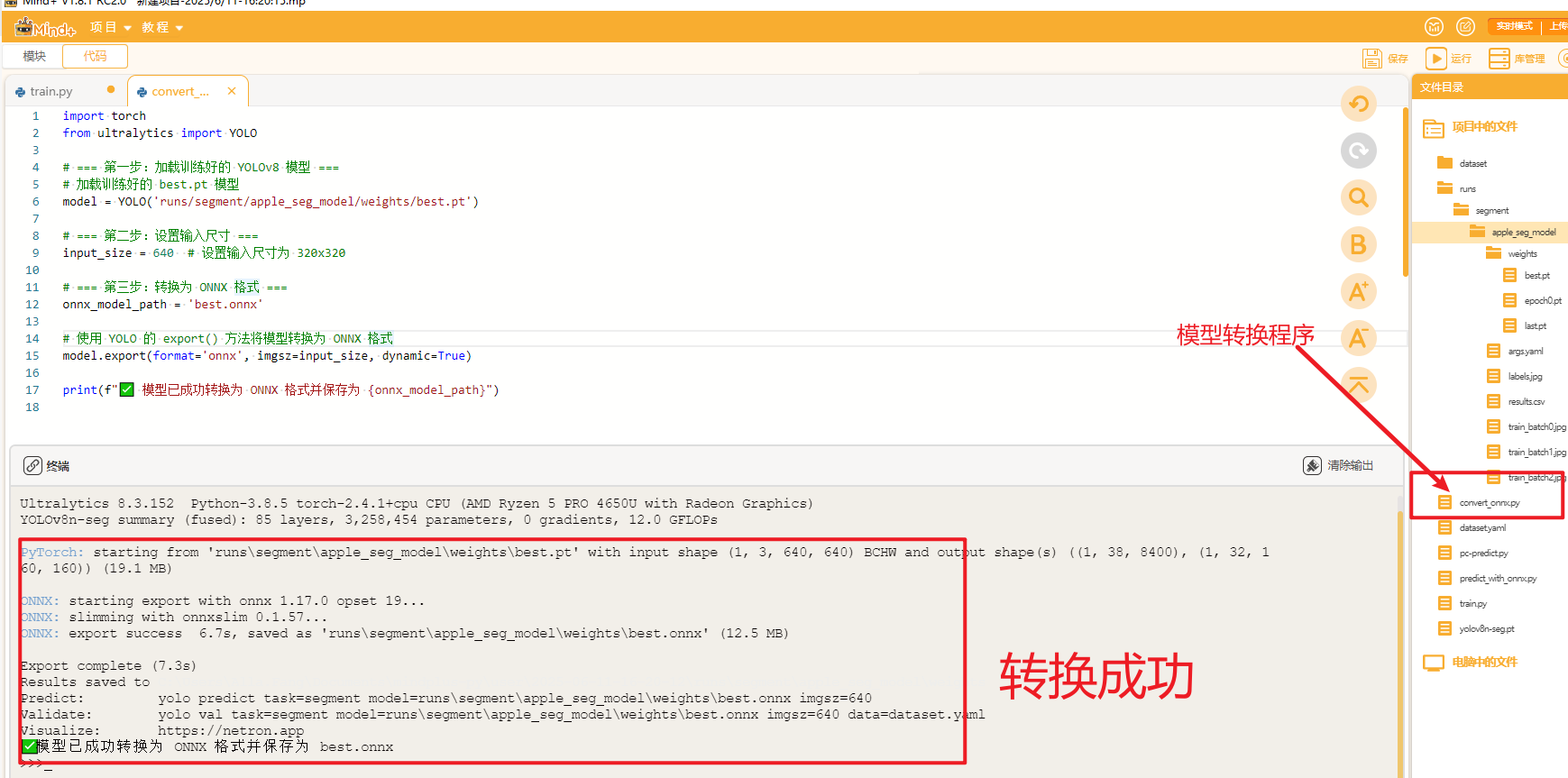
在同一目录下建立一个名为“convert_onnx.py”的文件,复制以下代码,将pt格式的模型转换成onnx。
import torch
from ultralytics import YOLO
# === 第一步:加载训练好的 YOLOv8 模型 ===
# 加载训练好的 best.pt 模型
model = YOLO('runs/segment/apple_seg_model/weights/best.pt')
# === 第二步:设置输入尺寸 ===
input_size = 640 # 设置输入尺寸为 640
# === 第三步:转换为 ONNX 格式 ===
onnx_model_path = 'best.onnx'
# 使用 YOLO 的 export() 方法将模型转换为 ONNX 格式
model.export(format='onnx', imgsz=input_size, dynamic=True)
print(f"✅ 模型已成功转换为 ONNX 格式并保存为 {onnx_model_path}")运行转换程序可以观察到以下结果,在best.pt文件同一目录下生成一个名为“best.onnx”的模型文件.
4.4 模型测评与导出
我们先在电脑端测试一下模型的性能,将两张测试图片拖入“项目中的文件“目录下。
新建一个名为”predict_with_onnx.py“的文件,填入以下推理测试代码,依次将图片名称修改为test1.png和test2.png
import cv2
import numpy as np
from ultralytics import YOLO
# 加载训练好的YOLOv8 Segment模型
model = YOLO("runs/segment/apple_seg_model/weights/best.onnx")
# 读取待推理的图片
image_path = "test1.png"
img = cv2.imread(image_path)
# 推理:使用YOLO模型进行推理
results = model(img)
# 获取第一个推理结果
result = results[0]
# 获取边界框、掩码、类别名映射
boxes = result.boxes
masks = result.masks
names = result.names # 类别索引映射
# 创建原图副本用于绘图
overlay = img.copy()
# 1. 绘制边界框和标签
for i, box in enumerate(boxes):
x1, y1, x2, y2 = box.xyxy[0].numpy().astype(int)
class_id = int(box.cls[0].item())
class_name = names[class_id]
# 绘制边框
cv2.rectangle(overlay, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 类别标签
label = f'{class_name}'
cv2.putText(overlay, label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 2. 绘制分割掩码
if masks is not None:
# 获取掩码张量数据,并转为 NumPy
mask_data = masks.data.cpu().numpy() # [N, H, W]
for i in range(mask_data.shape[0]):
mask_np = mask_data[i]
# 缩放掩码到原图尺寸
mask_resized = cv2.resize(mask_np, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_NEAREST)
# 转换为布尔掩码
mask_bool = mask_resized > 0.5
# 设置颜色和透明度
color = np.array([0, 255, 0], dtype=np.uint8)
alpha = 0.5
# 叠加透明掩码颜色
overlay[mask_bool] = (overlay[mask_bool] * (1 - alpha) + color * alpha).astype(np.uint8)
# 显示结果图像
cv2.imshow('Detected Image with Masks', overlay)
cv2.waitKey(0)
cv2.destroyAllWindows()
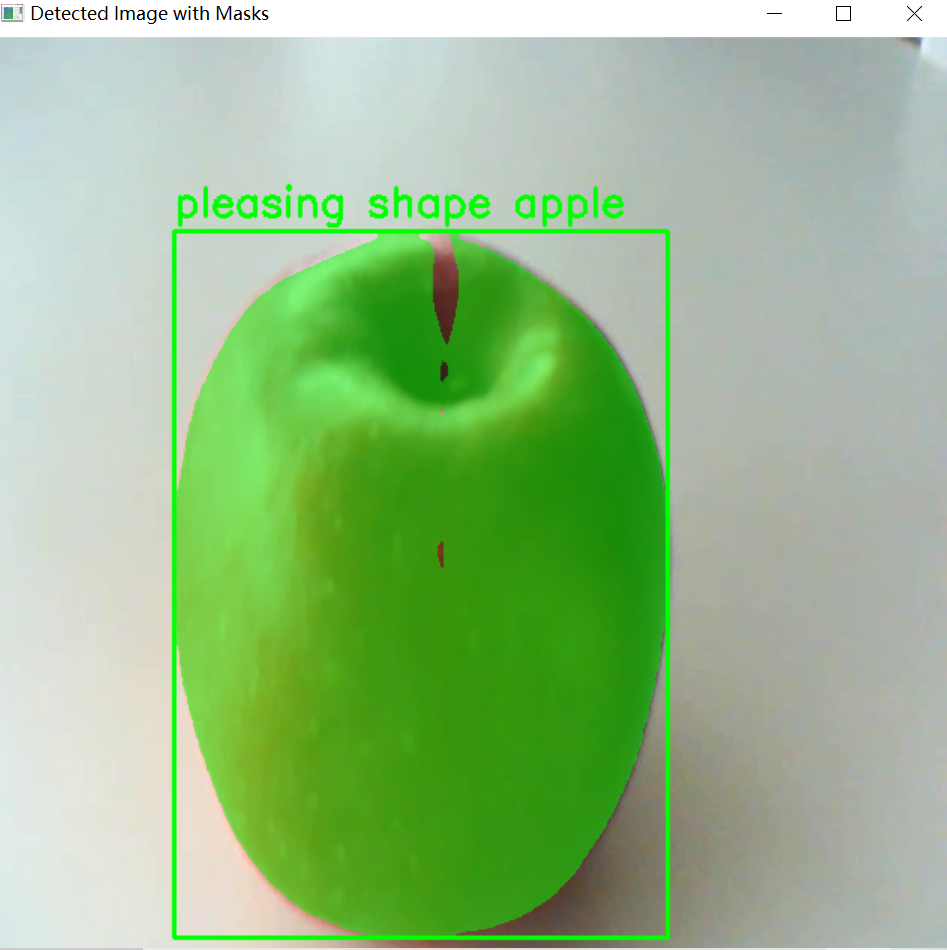
运行程序可以观察到模型在两类苹果的推理图片上的结果如下图。可以看到模型能准确的识别两类不同的苹果并将它们的轮廓给标记出来。



4.5 行空板M10传输视频到SIoT
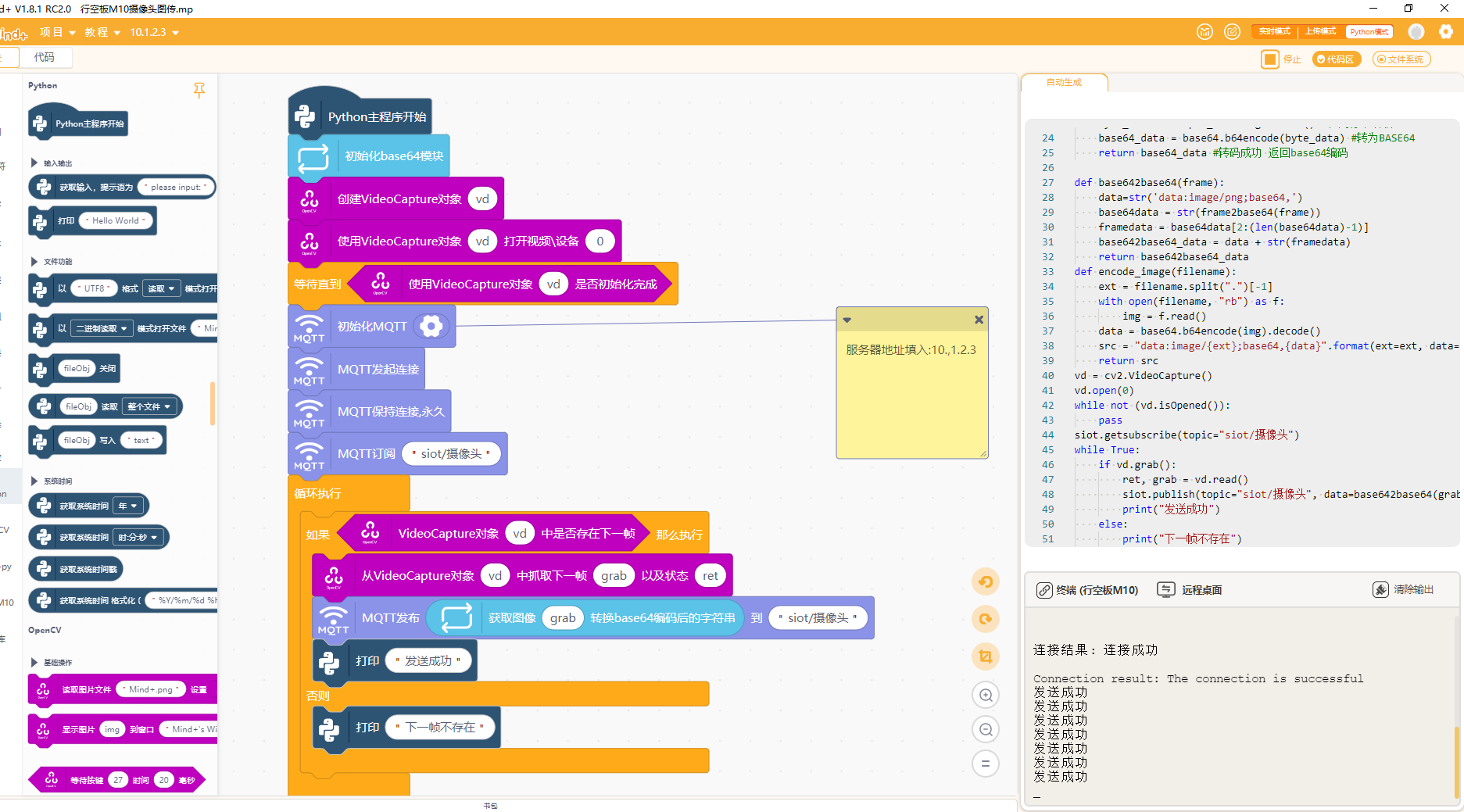
另开一个新的Mind+窗口,用于连接行空板M10,连接行空板M10与摄像头。


运行以下图形化程序向SIoT平台发送摄像头画面信息。该程序于在行空板M10上,通过摄像头采集图像帧,将其转为base64格式后,通过SIoT服务以MQTT方式发布。
4.6电脑推理并返回结果
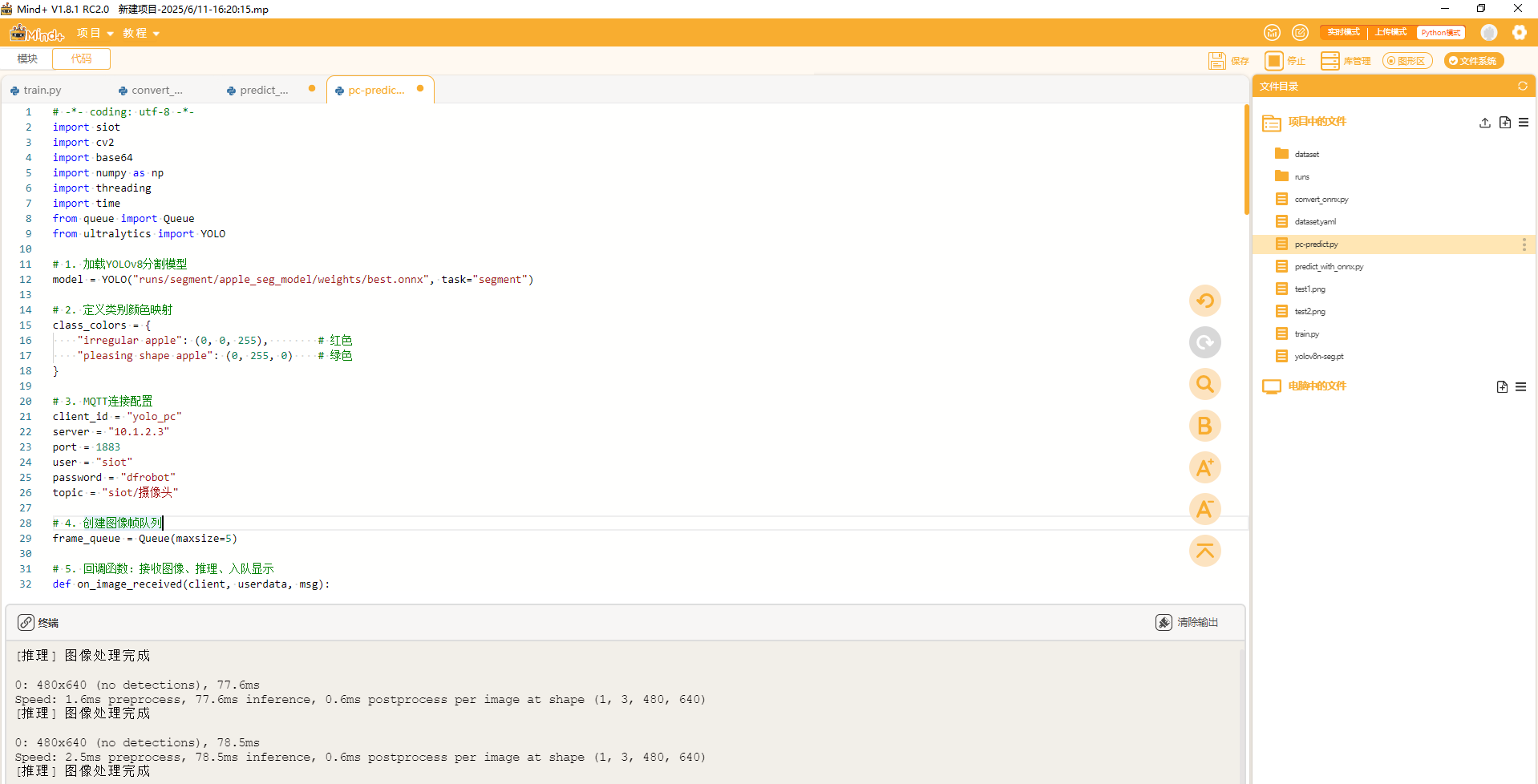
返回电脑端的程序,在项目中的文件目录下新建一个名为"pc-predict.py"文件,复制以下代码进去。
# -*- coding: utf-8 -*-
import siot
import cv2
import base64
import numpy as np
import threading
import time
from queue import Queue
from ultralytics import YOLO
# 1. 加载YOLOv8分割模型
model = YOLO("runs/segment/apple_seg_model/weights/best.onnx", task="segment")
# 2. 定义类别颜色映射
class_colors = {
"irregular apple": (0, 0, 255), # 红色
"pleasing shape apple": (0, 255, 0) # 绿色
}
# 3. MQTT连接配置
client_id = "yolo_pc"
server = "10.1.2.3"
port = 1883
user = "siot"
password = "dfrobot"
topic = "siot/摄像头"
# 4. 创建图像帧队列
frame_queue = Queue(maxsize=5)
# 5. 回调函数:接收图像、推理、入队显示
def on_image_received(client, userdata, msg):
try:
data = msg.payload.decode()
if "base64," not in data:
return
b64 = data.split("base64,")[-1]
img_bytes = base64.b64decode(b64)
img_array = np.frombuffer(img_bytes, np.uint8)
frame = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
if frame is None:
return
# ✅ YOLO 推理
results = model(frame)
result = results[0]
boxes = result.boxes
masks = result.masks
names = result.names
overlay = frame.copy()
# 绘制边界框和标签
for i, box in enumerate(boxes):
x1, y1, x2, y2 = box.xyxy[0].numpy().astype(int)
class_id = int(box.cls[0].item())
class_name = names[class_id]
color = class_colors.get(class_name, (255, 255, 255))
cv2.rectangle(overlay, (x1, y1), (x2, y2), color, 2)
cv2.putText(overlay, class_name, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
# 绘制分割掩码
if masks is not None:
mask_data = masks.data.cpu().numpy()
for i in range(mask_data.shape[0]):
mask_np = mask_data[i]
mask_resized = cv2.resize(mask_np, (frame.shape[1], frame.shape[0]), interpolation=cv2.INTER_NEAREST)
mask_bool = mask_resized > 0.5
class_id = int(boxes[i].cls[0].item())
class_name = names[class_id]
color = np.array(class_colors.get(class_name, (255, 255, 255)), dtype=np.uint8)
alpha = 0.4
overlay[mask_bool] = (overlay[mask_bool] * (1 - alpha) + color * alpha).astype(np.uint8)
# 将推理后的图像放入队列
if not frame_queue.full():
frame_queue.put(overlay)
else:
frame_queue.get_nowait()
frame_queue.put(overlay)
print("[推理] 图像处理完成")
except Exception as e:
print(f"[错误] 图像处理失败: {e}")
# 6. 初始化 MQTT
siot.init(client_id=client_id, server=server, port=port, user=user, password=password)
siot.set_callback(on_image_received)
siot.connect()
# 7. 启动 MQTT 后台监听线程
threading.Thread(target=siot.loop, daemon=True).start()
siot.getsubscribe(topic=topic)
# 8. 显示图像主循环
print("[系统] 启动成功,等待图像帧... 按 q 退出")
while True:
if not frame_queue.empty():
result_frame = frame_queue.get()
cv2.imshow("YOLO Segmentation from M10", result_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 9. 清理资源
cv2.destroyAllWindows()
两个Mind+窗口各自运行行空板M10的程序与电脑端推理的程序,可以观察到如下效果。
电脑端出现一个窗口实时显示行空板M10摄像头的视频画面,推理终端实时的显示推理结果(详情见效果视频)。


4.7 核心代码解析
我们一起来看一下本项目的核心代码。观察”pc_predict.py"文件,本文件运行在电脑端,带闹闹作为推理终端,接收行空板M10通过 SIoT 发布的图像帧,使用 YOLOv8 实例分割模型进行实时推理,最终在窗口中动态展示结果。
【输入】:摄像头采集图像(由M10上传)
【推理】:YOLO segment 模型识别每个苹果的类别与轮廓掩码
【可视化】:显示边框、标签和分割结果(带颜色叠加)
【输出】:显示窗口中的图像 + 控制台推理结果提示电脑端推理程序的逻辑是接收图像 → 解码 → YOLO推理 → 获取boxes和masks → 绘制边框与分割 → 显示窗口

在 YOLOv8 Segment 模型中,masks是模型输出中的关键组成部分,用于实现实例分割(Instance Segmentation)功能。它相较于传统的目标检测(仅输出矩形框)有了更高的“像素级”识别精度。masks对象表示:每一个检测到的目标所对应的“分割掩码”,本质上是一个二维或三维布尔/浮点型数组,用于标记图像中哪些像素属于该目标。在本项目中我们就是依据模型推理结果中的masks的值才判断出两类苹果在画面中的具体形状的。

本项目以YOLOv8实例分割模型为核心,通过行空板M10与电脑协同工作,实现了优质苹果的实时识别与分类。另外可在此基础上丰富项目功能,比如外接舵机,根据推理结果驱动硬件执行动作,如推杆分拣、导流道控制,实现流水线式自动化分拣。
5.项目相关资料附录
数据集与程序文件:
链接: https://pan.baidu.com/s/1VpjFYW8XGwJWDy2xP320Mg?pwd=wpnu



 他的勋章
他的勋章

sky0072025.06.25
沙发是我的