 返回首页
返回首页
 回到顶部
回到顶部

1.项目介绍
1.1项目简介
在当今数字化时代,文本分类技术在诸多领域发挥着重要作用,从社交媒体情感分析到客户服务质量评估。预训练语言模型(如BERT)作为自然语言处理领域的核心技术,通过深度双向Transformer架构构建,凭借其强大的语义理解能力广泛应用于各类文本理解任务。
文本分类技术能自动分析大量反馈文本,精准识别学生对餐饮服务的态度倾向。本项目使用Mind+的AI工具库-文本分类库,通过图形化代码,结合BERT预训练模型,构建食堂服务品质感知系统。使用食堂服务评价数据集,通过BERT微调训练出情感分类模型,可直观理解文本分类原理,并训练出能自动识别"积极"、"消极"、"中性"三类评价的智能系统。
1.2项目效果视频
2.AI知识介绍
2.1 文本分类的概念与应用
概念: 文本分类是将文本自动分配到预定义类别的任务,核心是通过模型学习文本特征与标签的映射关系。
应用场景:
情感分析:判断评论的正/负面情绪(如“菜品好吃” vs. “排队太久”)。
主题分类:区分反馈类型(服务、卫生、价格等)。
需求挖掘:识别学生提出的改进建议。
2.2 BERT模型与其作用
BERT简介:
BERT 是由 Google 提出的 基于 Transformer 的预训练语言模型,其核心优势在于:
双向上下文理解:通过 Masked Language Model (MLM) 和 Next Sentence Prediction (NSP) 任务,学习词语在句子中的上下文关系。
强大的语义表征能力:在大规模语料(如 Wikipedia、BookCorpus)上预训练,能有效捕捉文本的深层语义特征。
通用性强:适用于多种 NLP 任务(文本分类、问答、命名实体识别等)。
在本项目中,我们使用 BERT-base-Chinese 版本,适用于中文文本处理。
作用: BERT能够捕捉深层语义信息,微调时仅需添加简单输出层即可高效解决文本分类问题,显著提升准确率。
2.3 BERT + Fine-tuning实现文本分类流程
Fine-tuning(微调)
Fine-tuning 是指在预训练模型的基础上,使用特定领域的数据进行进一步训练,使其适应具体任务(如文本分类)。
整体流程
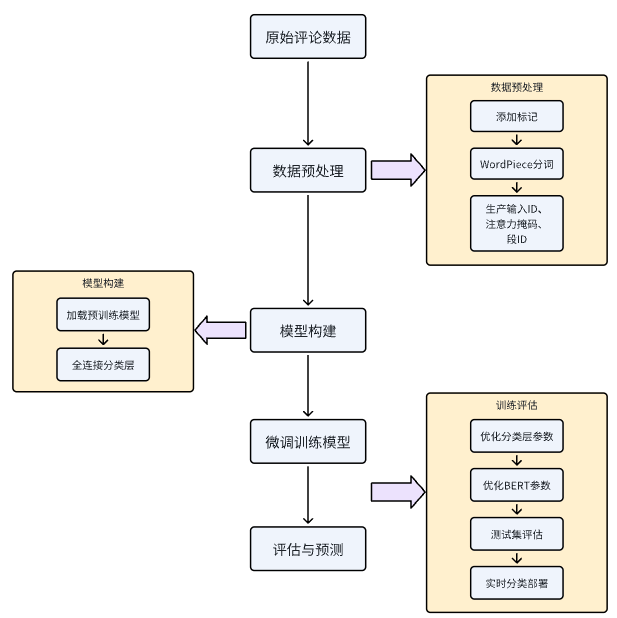
2.4 AI工具库介绍
在Mind+软件中有一个名为"文本分类"AI工具库,如下图。
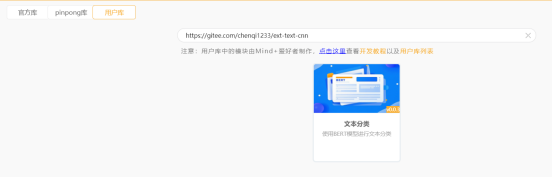
这个库包含了四个部分:加载数据、设置模型参数、模型训练和基本的模型操作。通过加载数据部分,可以初始化模块,设置文本类别标签,设置测试的数据,并加载训练数据集;在模型参数部分,设置模型参数和训练参数,可以很清晰直观的了解模型的设置过程;在模型训练部分,需要设置预训练模型的文件路径,并进行进一步的训练和验证;在模型操作部分,可进行模型的评估,模型导出与导入,以及获取推理结果等操作。
3.软硬件环境准备
3.1软硬件器材清单
3.2软件环境准备
在Mind+软件中点击左下角'扩展库',在用户库中搜索一下链接:https://gitee.com/chenqi1233/ext-text-cnn,搜索并点击加载'文本分类'库。
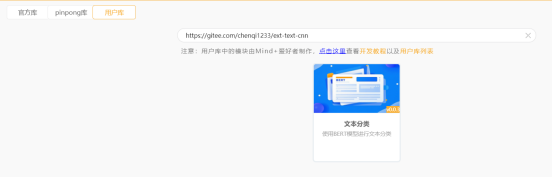
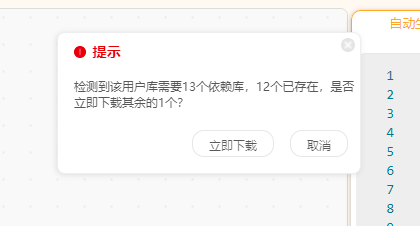
在加载本库时,会自动检查并下载运行库需要的python依赖包,点击'立即下载'即可。
4.训练并应用文本分类模型
使用自定义的数据集,通过加载预训练模型bert-base-chinese,训练一个文本分类模型,完成食堂评价分类任务。
4.1数据集准备
数据集内容为对食堂服务品质的评价,分为积极、消极和中性三类。每个类别都提供了30条以上的真实场景评价数据,涵盖了菜品质量、服务态度、环境卫生、价格等多个方面,确保模型训练的有效性和实用性。
以下是数据集的结构和内容示例:(数据集见最后附录)
data/
├── 积极.txt
├── 消极.txt
└── 中性.txt4.2加载数据
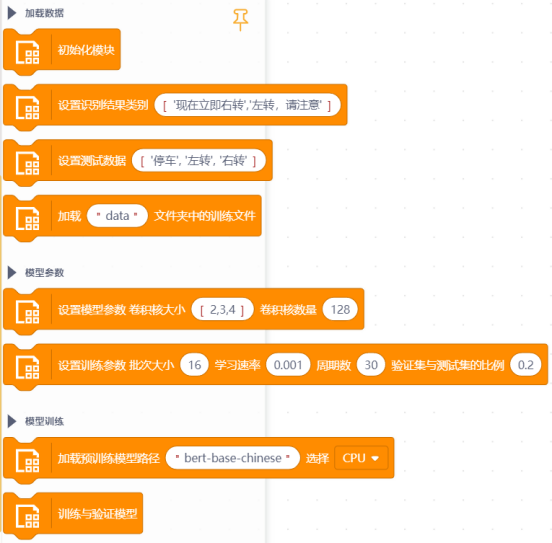
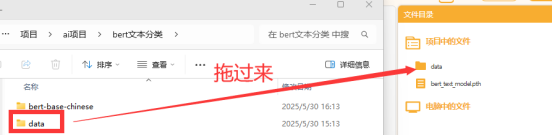
将数据集文件夹拖入项目中的文件目录下,如下图。
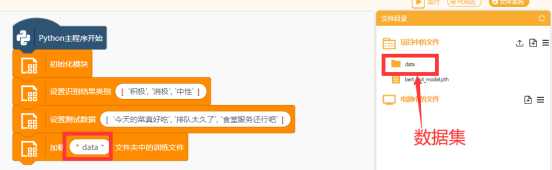
设置识别结果类别为(注意用英文标点格式):'积极', '消极', '中性'
设置测试数据(测试数据个数和内容任意):'今天的菜真好吃', '排队太久了', '食堂服务还行吧'
填入数据集的文件路径:data
4.3模型训练
下载预训练模型bert-base-chinese(预训练模型见最后附录)。
将预训练模型文件夹的实际路径填入下方方框内,注意格式,如下图。
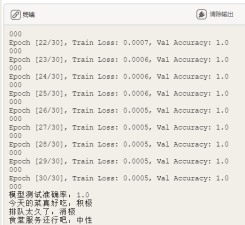
使用以下训练代码完成训练,将训练好的模型保存为'bert_test_model.pth'
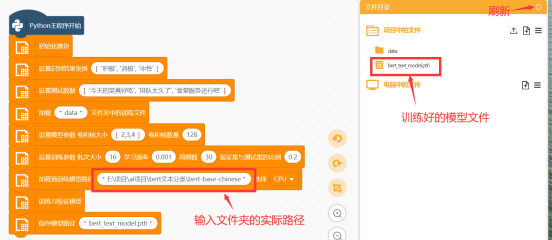
当程序运行结束后,我们刷新右侧'项目中的文件',看到自动生成了一个名为'bert_text_model.pth'的文件,这就是我们训练得到的食堂评价文本分类模型。
4.4应用模型完成推理
点击运行程序,可以观察模型对测试数据的推理结果。
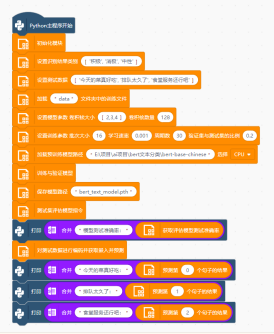
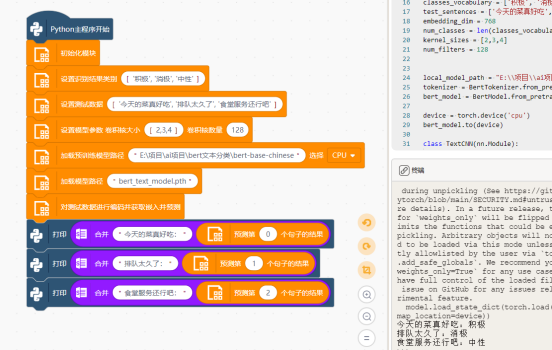
加载之前训练好保存的模型文件进行预测,运行如下程序并观察结果输出:
5.资料附录
资源链接: https://pan.baidu.com/s/1UqJe-jORz3i9w1SjqR2QSw?pwd=azhq



 他的勋章
他的勋章

罗罗罗2025.11.18
666