 返回首页
返回首页
 回到顶部
回到顶部
1.项目介绍
1.1项目简介
本项目基于YOLOv8的目标检测功能,实时检测视频画面中的商品的种类、数量,以及实时计价。通过训练YOLOv8模型,将模型部署到行空板M10上,利用YOLOv8模型推理输出的类别标签和目标框,通过摄像头,从实时视频中检测出视频画面中商品种类、数量、总价,并框出,为商品检测计数、计价等应用场景提供高效的技术支持。
1.2项目效果视频
【行空板M10实现商品检测及计价】
2.项目制作框架
本水果识别项目是通过YOLO目标检测算法,使用商品数据集,训练商品目标检测模型,实现画面中商品的检测,显示商品类别标签、数量和框出其位置、计算价格。
目标检测简单来说就是在图片或视频中找到特定的物体,并确定它们的位置和类别。
下图是我们的项目制作框架图,我们在电脑端完成模型的训练与测试,将模型部署到智能硬件——行空板M10中完成商品目标检测模型的应用,制作出智能商品检测装置。
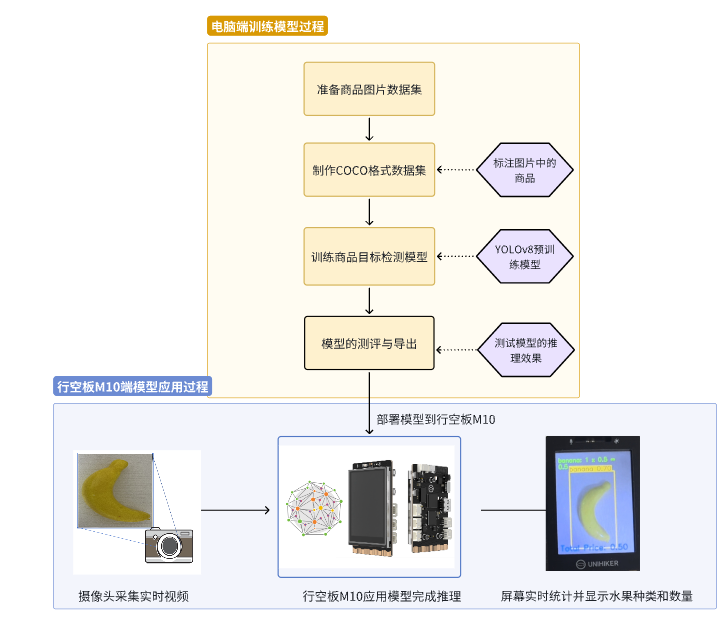
YOLO商品检测项目框架图
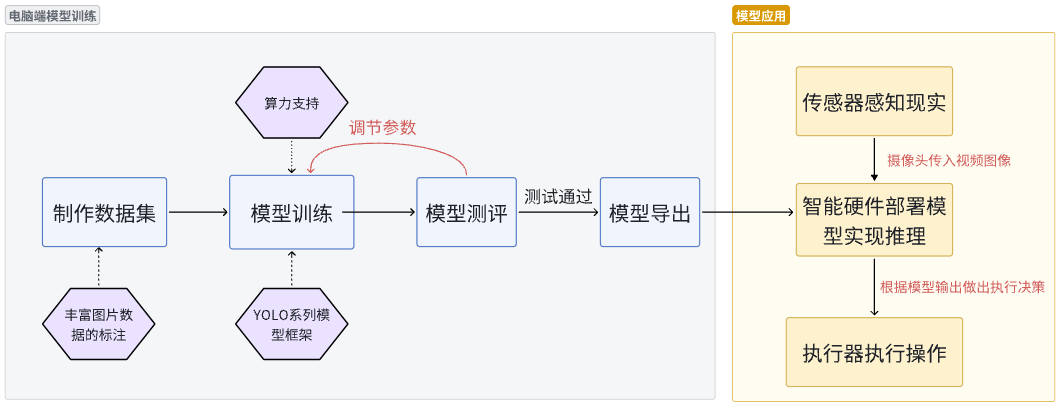
YOLO项目框架图,供参考
3.软硬件环境准备
3.1软硬件器材清单

注意行空板M10固件在0.3.5——0.4.0的版本均可以用于制作本项目,但都需要为行空板装conda环境,详情见3.3硬件环境准备。
3.2软件环境准备
由于我们使用电脑训练商品检测模型,因此需要在电脑端安装相应的库。
首先按下win+R,输入cmd进入窗口。
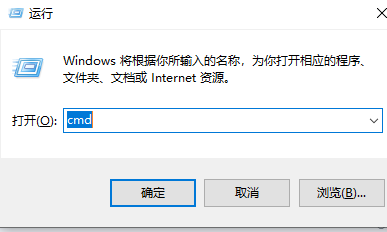
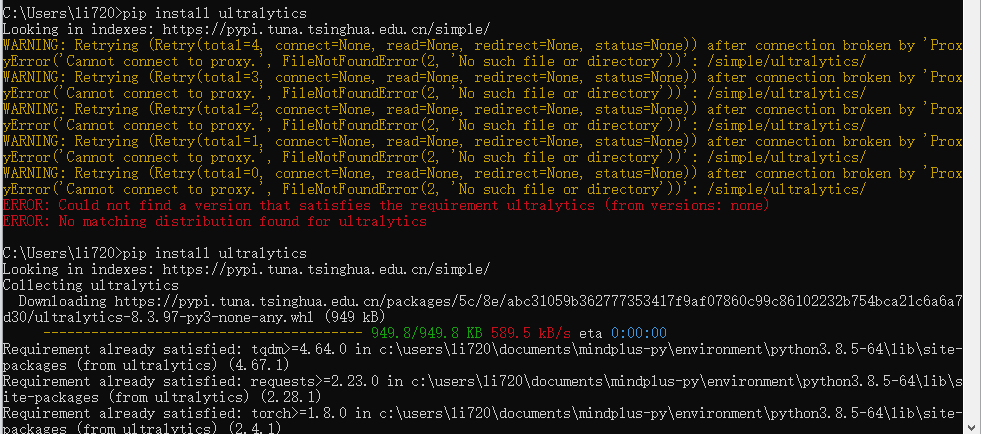
 在命令行窗口中依次输入以下指令,安装ultralytics库
在命令行窗口中依次输入以下指令,安装ultralytics库
pip install ultralytics
pip install onnx==1.16.1
pip install onnxruntime==1.17.1输入之后会出现以下页面。
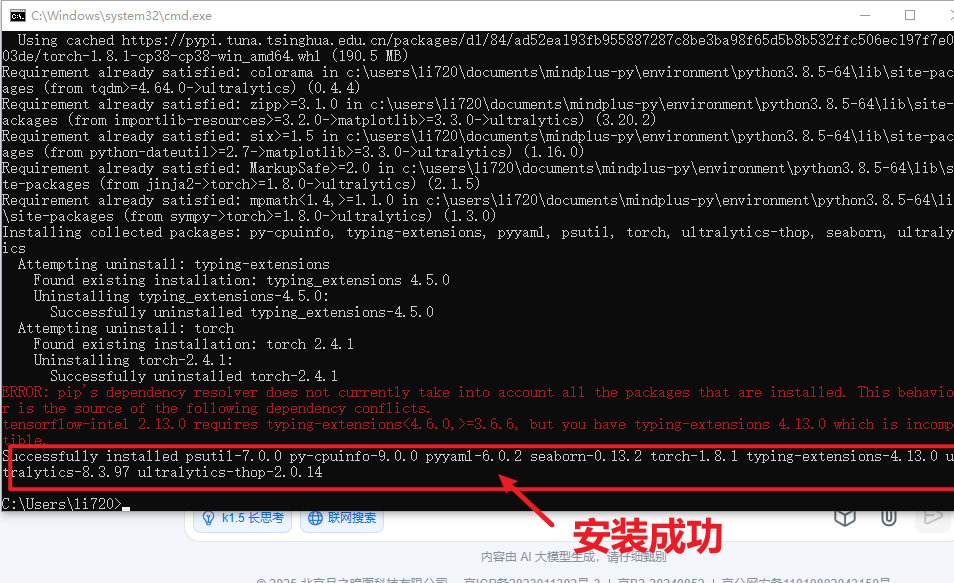
当命令运行完成,出现以下截图表示安装成功。
3.3硬件环境准备
在本项目中我们将要将训练好的YOLOv8框架的模型部署到行空板中,进行推理和执行操作。为了在行空板上成功运行YOLOv8,我们将使用Ultralytics官方提供的库进行部署 。
使用USB数据线连接行空板与电脑,等待行空板屏幕亮起表示行空板开机成功。

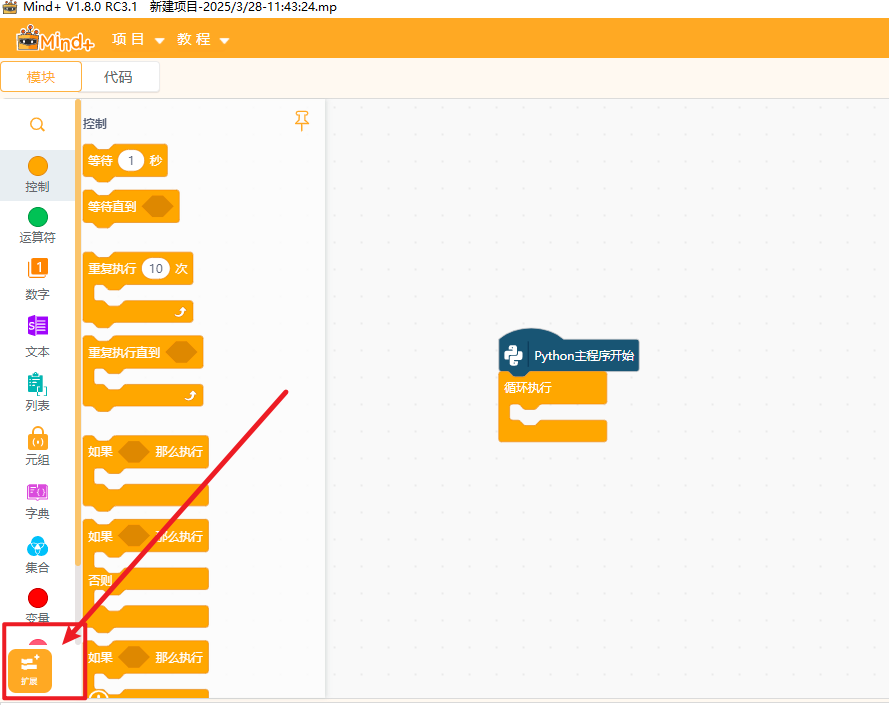
打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载
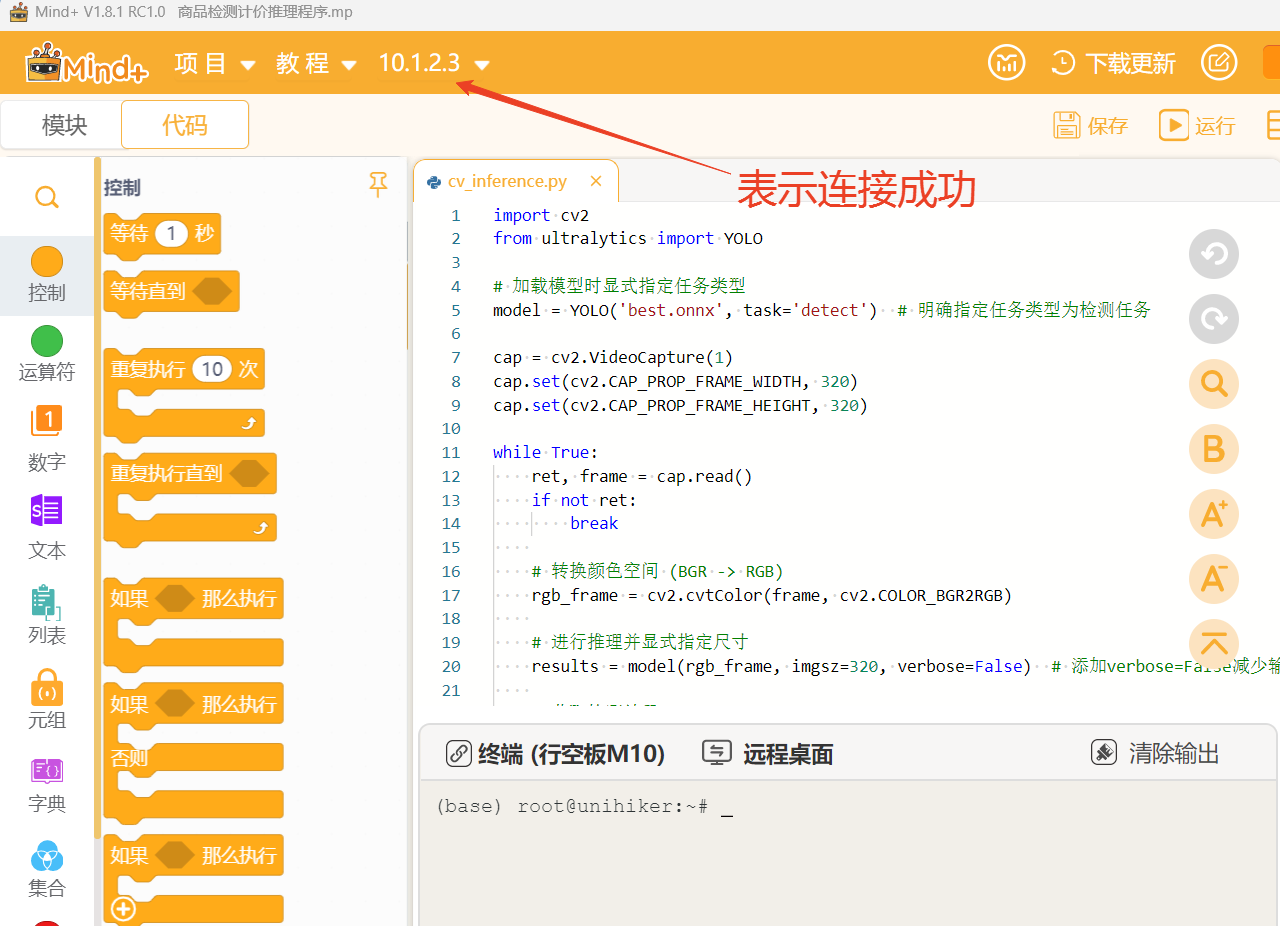
点击返回,点击连接设备,找到10.1.2.3.点击连接,等待连接成功.
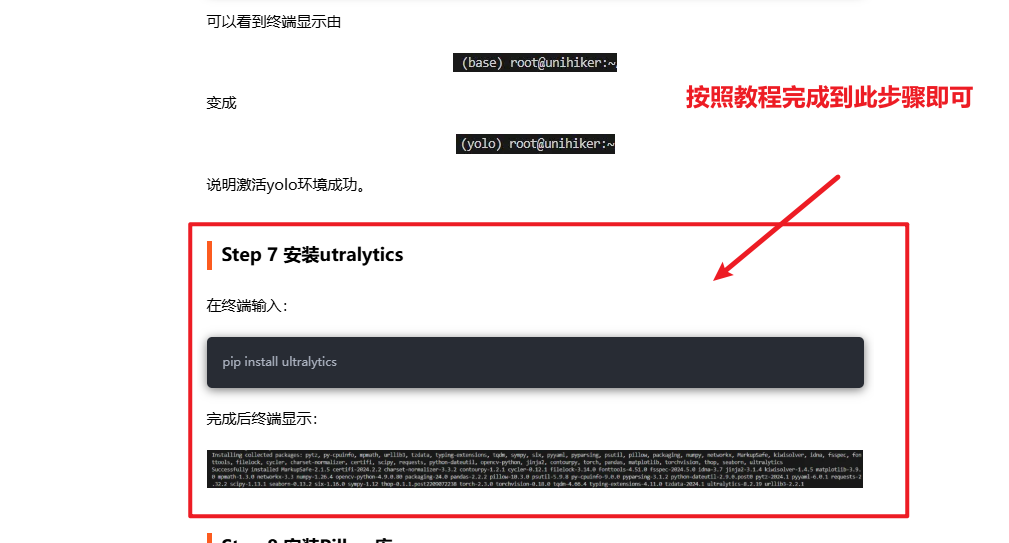
请参考此篇帖子的环境配置教程:如何在行空板上运行 YOLOv10n? 请按照这篇帖子的教程完成到Step 7 安装utralytics,如下图。
除了utralytics库本项目还需要使用onnx、onnxruntime、opencv -python 和pinpong库 依次在Mind+终端输入以下命令
(注意行空板需要联网,点此查看行空板联网操作教程)
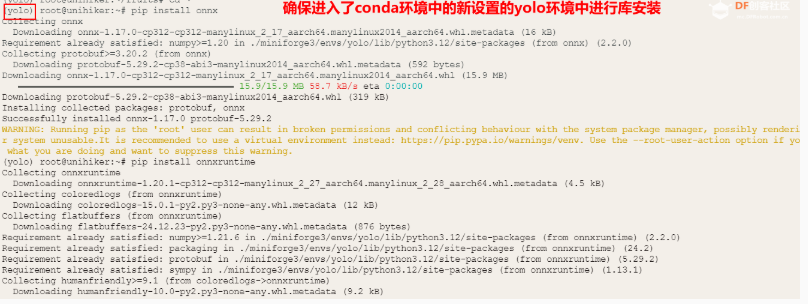
pip install onnx==1.16.1
pip install onnxruntime==1.17.1
pip install opencv-python
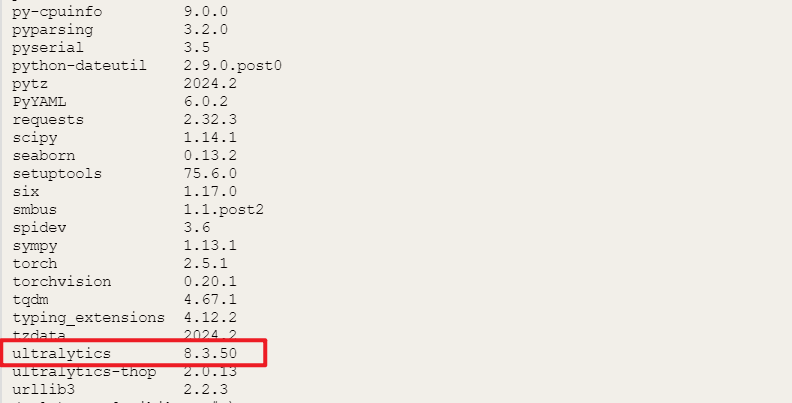
pip install pinpong在Mind+终端输入以下指令,可以检查相应库是否安装成功
pip list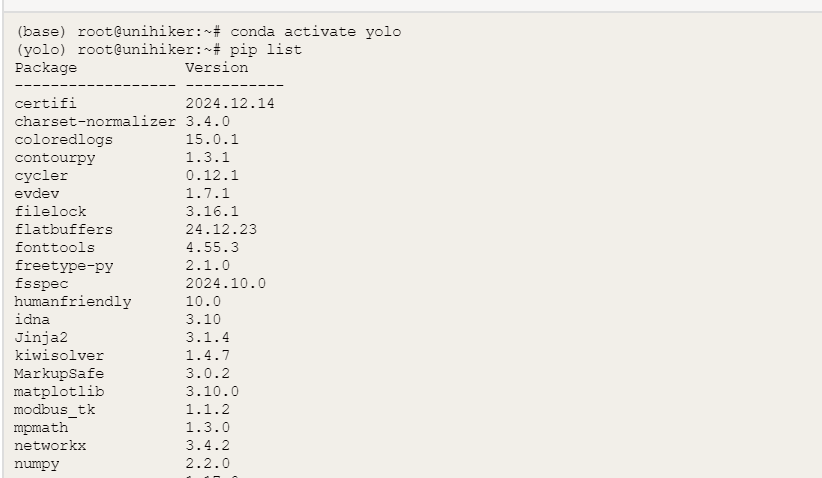
4. 制作步骤
4.1数据集准备
为了训练商品目标检测模型,我们需要准备COCO格式的商品数据集。一个标准的目标检测数据集包括训练集和验证集,每个集都包含图像和标注文件(txt文件)。标注文件能提供目标的位置和类别信息。
以商品检测的数据集为例为例,标准的用于目标检测的数据集的格式如下。

我们使用的商品数据集总共包含4种不同类别的商品如苹果、香蕉、挖耳勺、指甲剪等,其中训练集共有41个图片文件,验证集共有41个图片文件(数据集在文档最后的附件)。

其中YAML文件一个对于目标检测模型训练很重要的文件。YAML 文件通常包含数据集的路径信息,这些路径告诉模型训练脚本在哪里找到训练集和验证集的图像和标注文件。除此之外,YAML 文件定义了类别索引与类别名称之间的映射关系。这对于模型在训练和推理过程中正确识别和分类目标至关重要。如下图,是水果目标检测模型的YAML文件。

准备好数据集后,接下来我们就可以进入模型的训练环节了。
4.2模型训练
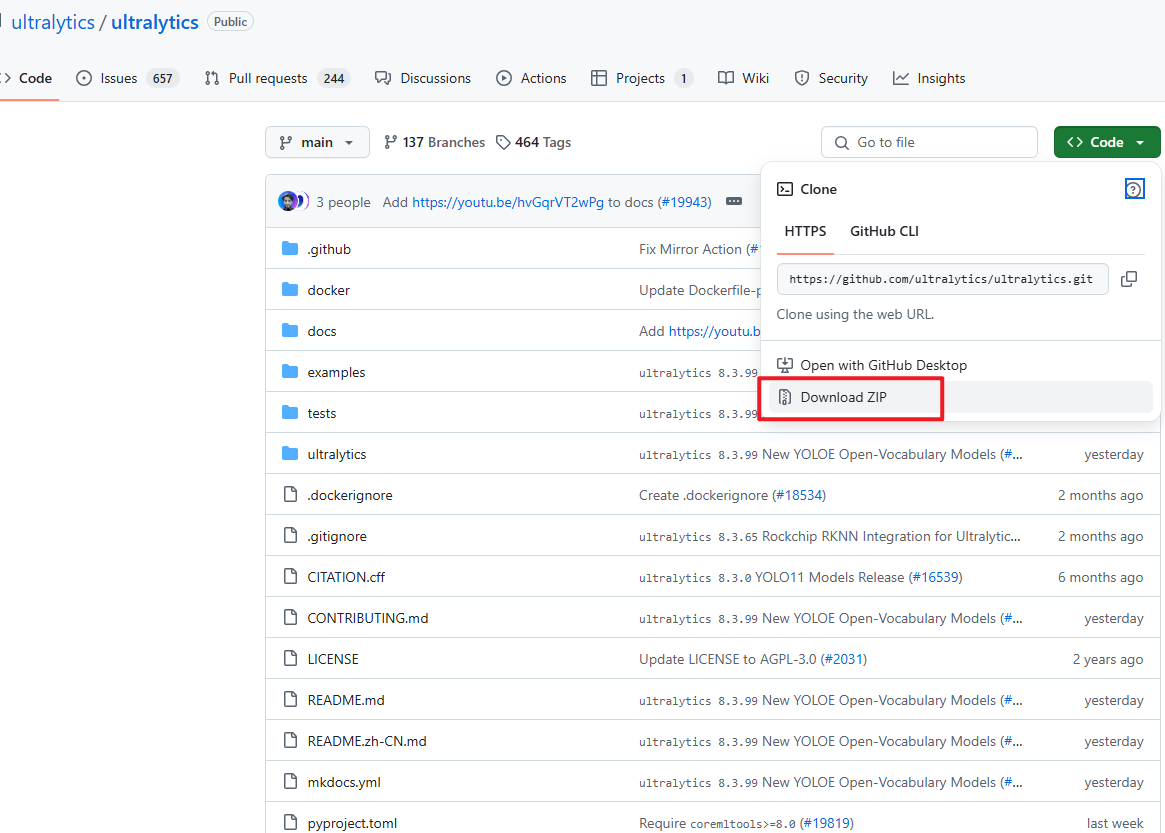
我们首先要去ultralytics的官方仓库下载YOLO项目文件。链接:https://github.com/ultralytics/ultralytics。如下图,将官方文件夹下载下来,并解压(文件夹已附在在本篇文档的最后)。
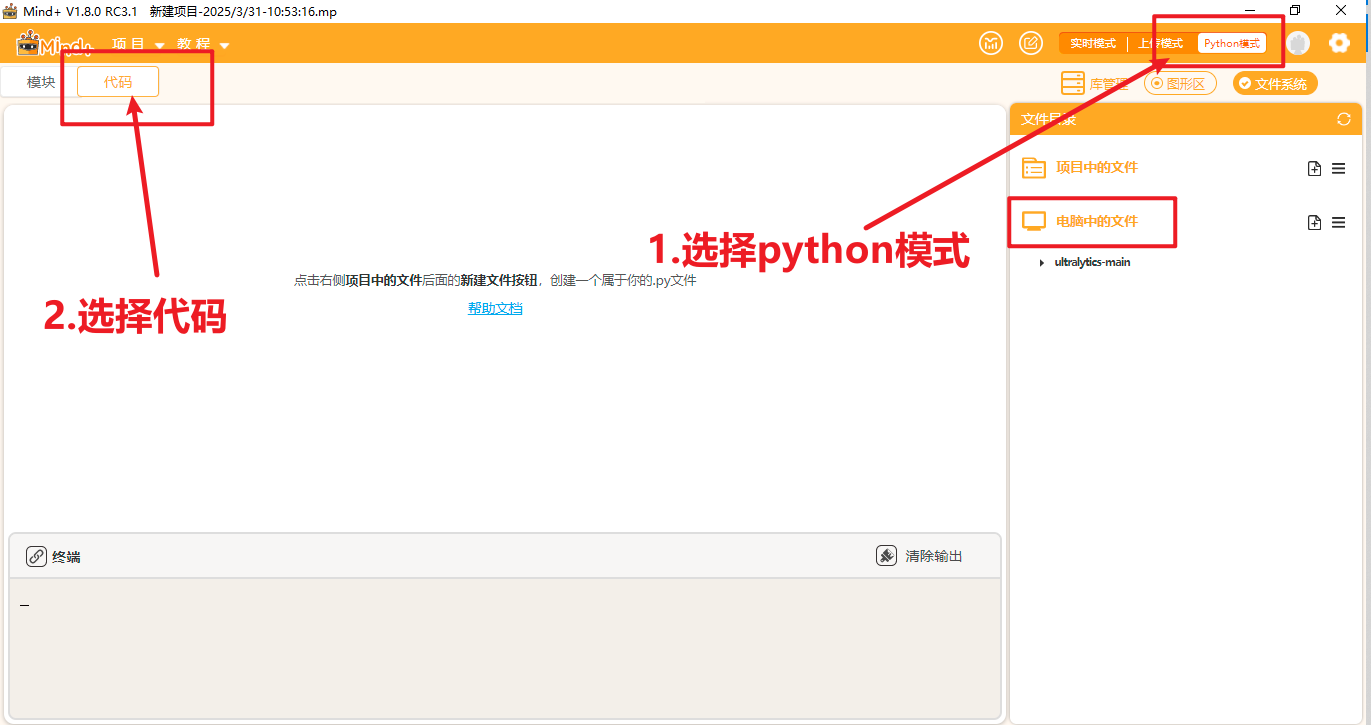
将文件放到一个能找到的路径,打开Mind+,选择Python模式下的代码模式,如下图。
在右侧“文件系统”中找到"电脑中的文件",找到此文件夹进行添加。
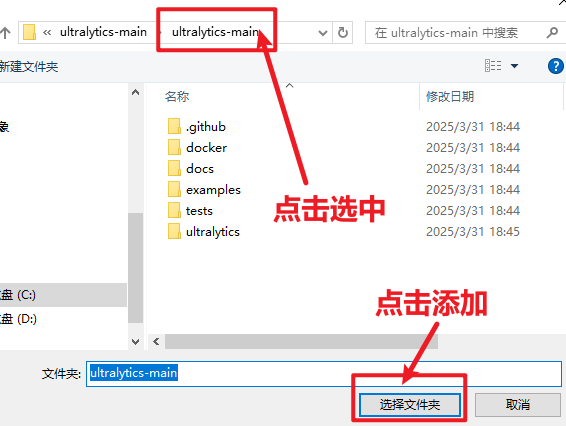
添加好后可以观察到如此下图。
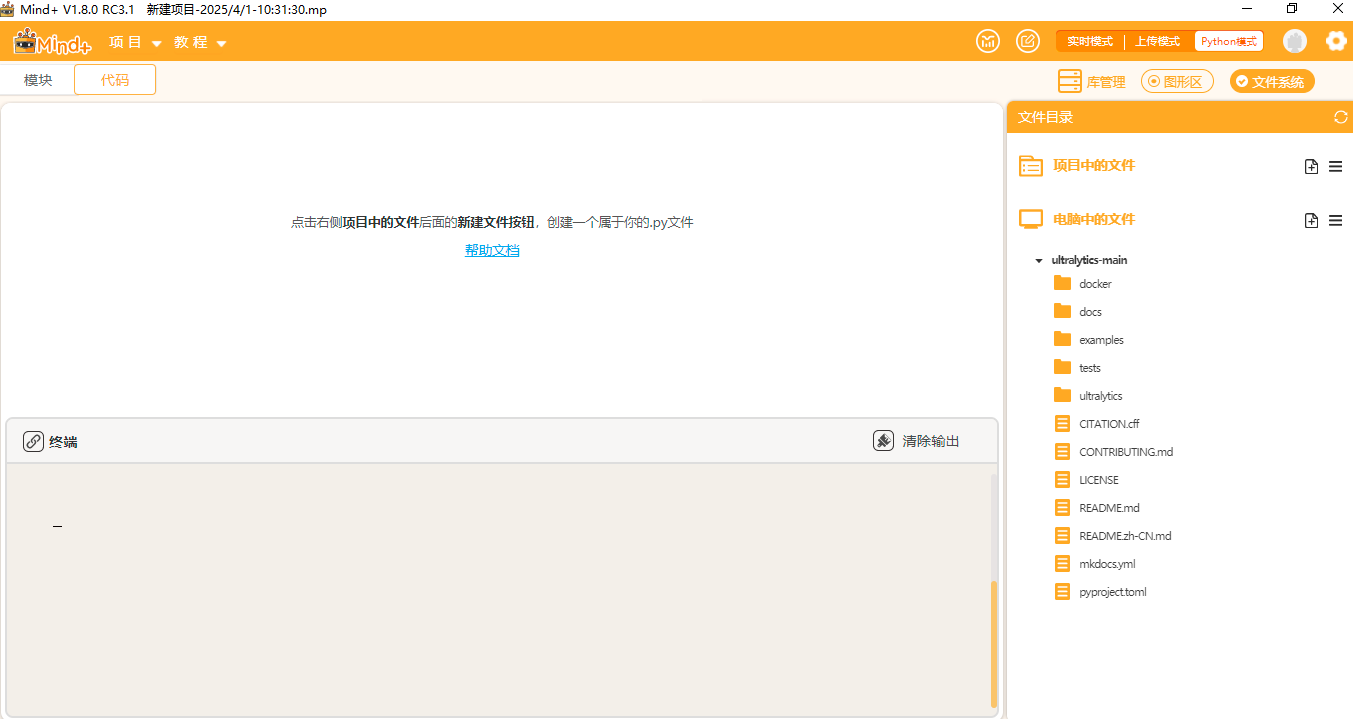
点击"新建文件夹",在ultralytics文件夹中分别新建三个文件夹,依次命名为"datasets"(用于存放数据集),"yamls"(用于存放数据集对应的yaml文件)"runs"(用于存放训练模型的py文件)。
建好后如下图。
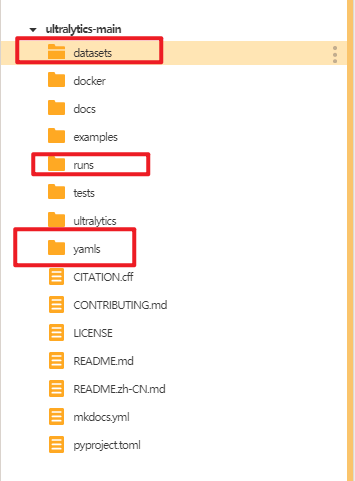
将商品数据集的训练集和验证集文件夹放入"datasets"文件夹,将水果数据集的yaml文件放入"yamls"文件夹。
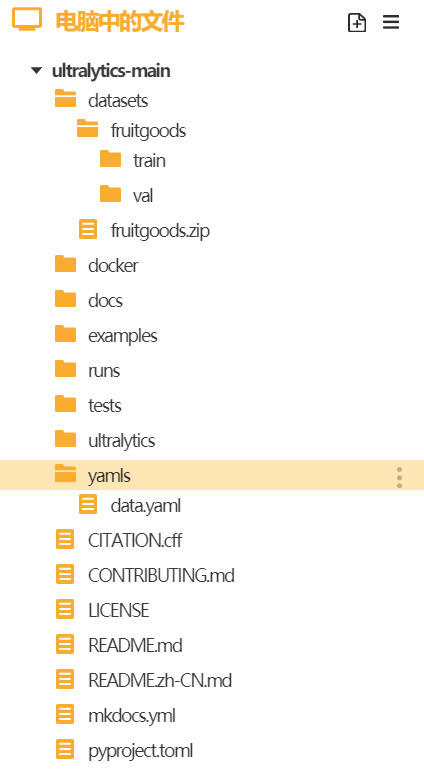
接着我们在"runs"文件夹中建立一个叫做"train.py"的文件,在此文件中编写训练YOLO模型的代码。
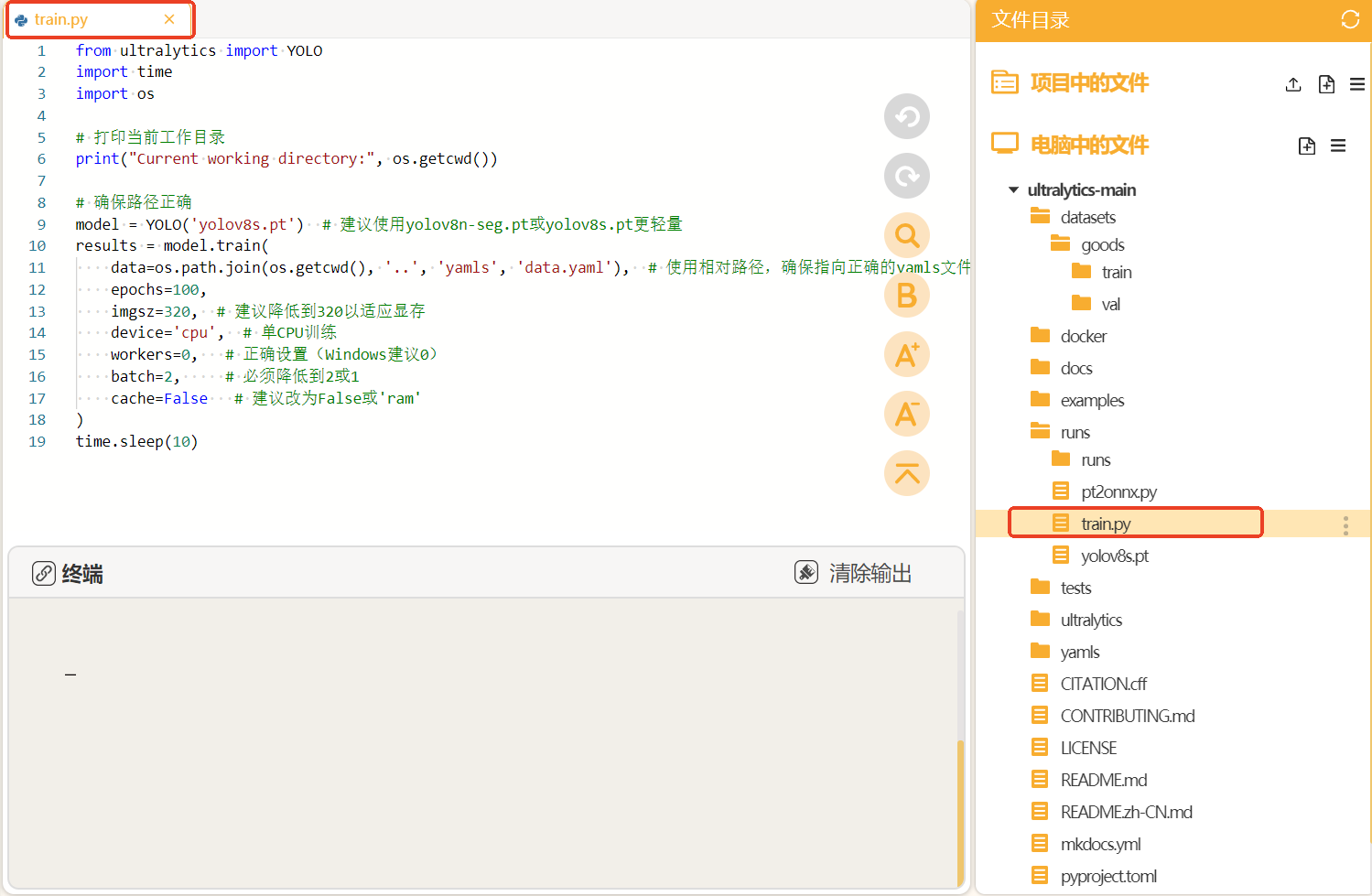
将训练代码粘贴到train.py中点击运行。我们在预训练模型"yolov8s"基础上进行商品目标检测模型的训练,设置训练轮次是100轮。图片的尺寸是320。
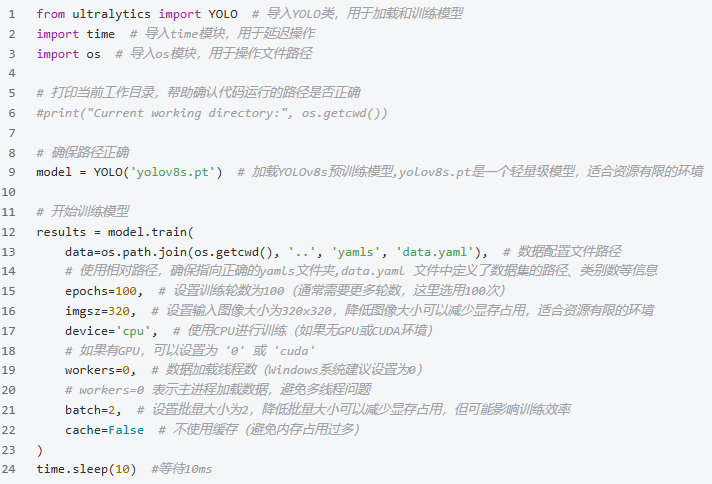
运行时可观察终端,自动下载预训练模型"yolov8s.pt",进行模型的训练。
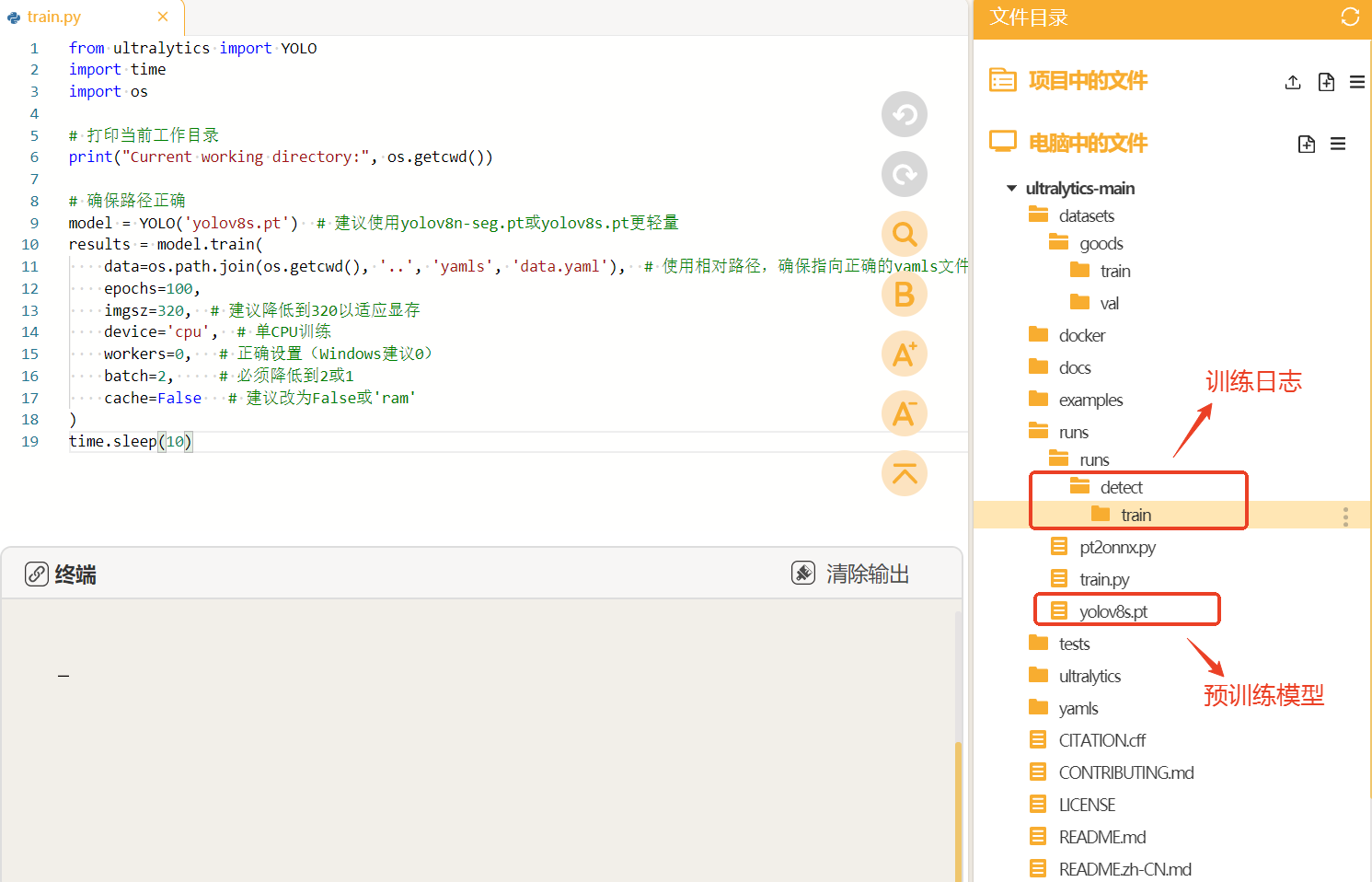
YOLO模型的训练对电脑的配置要求比较高,使用电脑CPU一般训练时间较长,可以考虑使用GPU或者云端算力进行训练,这里我们使用的时本地电脑的CPU训练方法,操作比较简单,耗时略长。
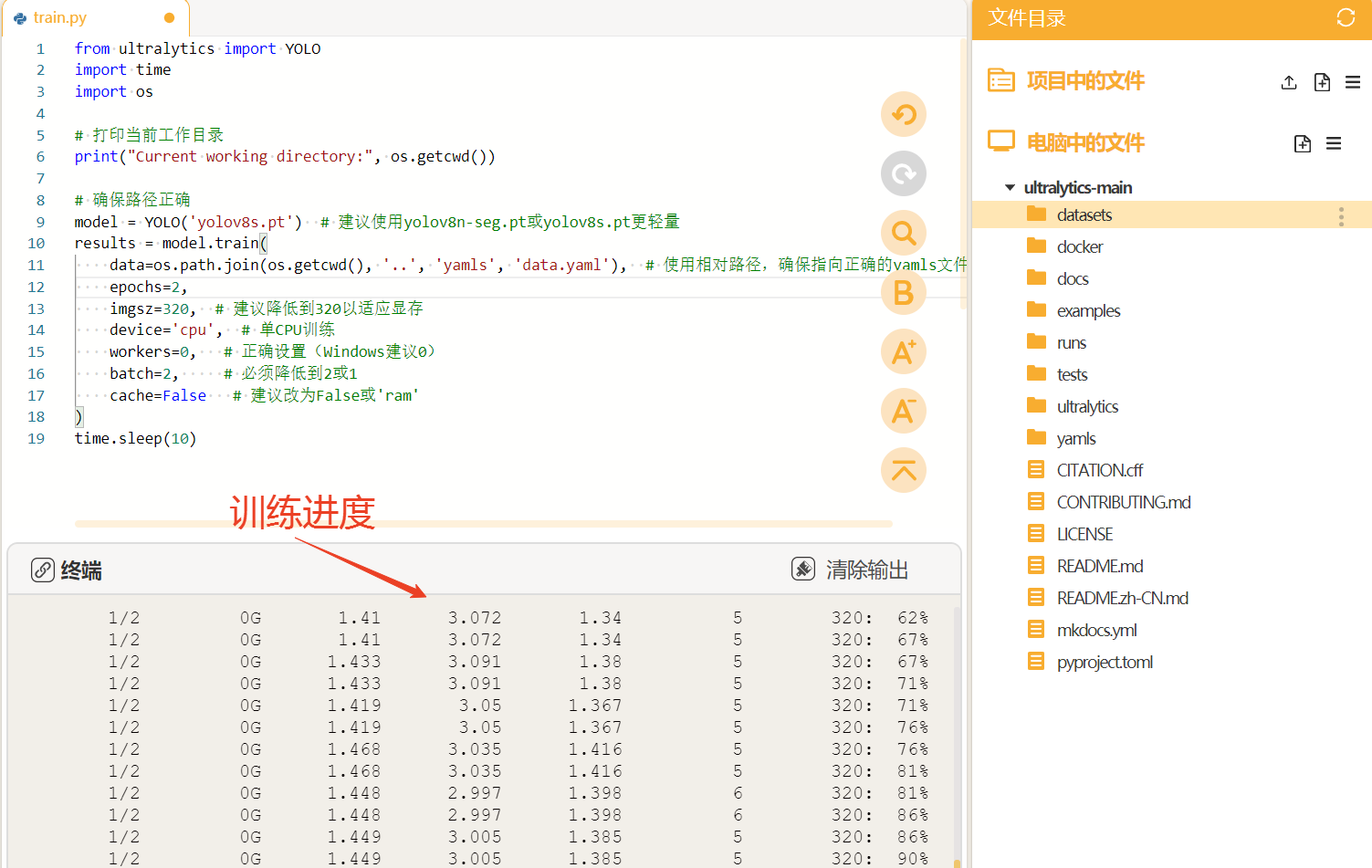
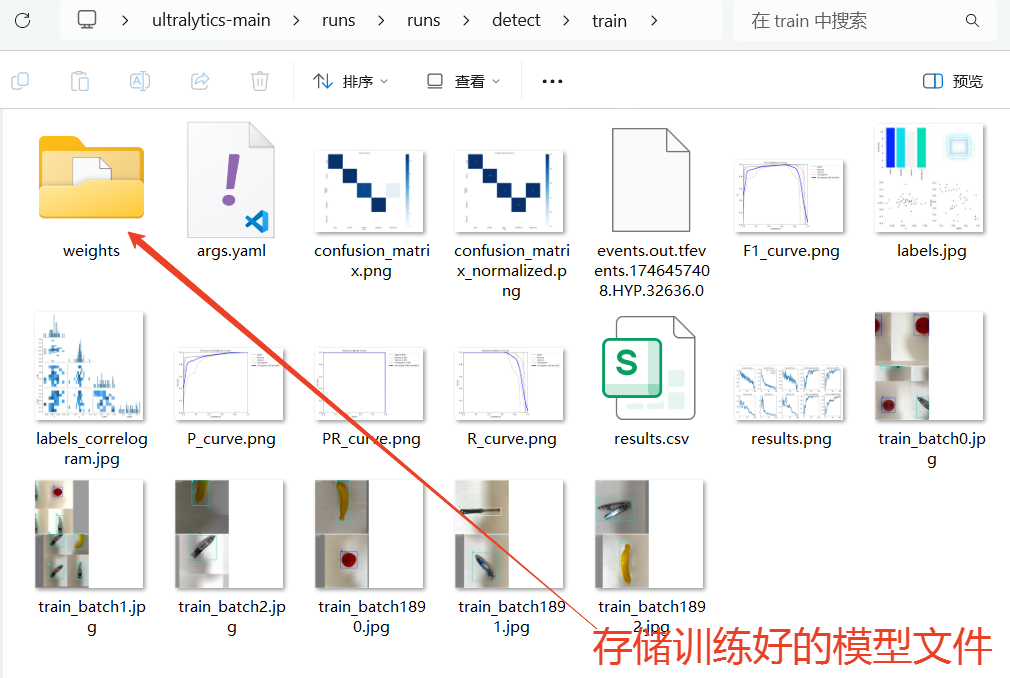
当训练完成后,我们可以观察"runs"文件夹中自动生成了"detect"文件夹(代表了目标检测任务),里面存放了训练模型的数据和训练好的模型文件。
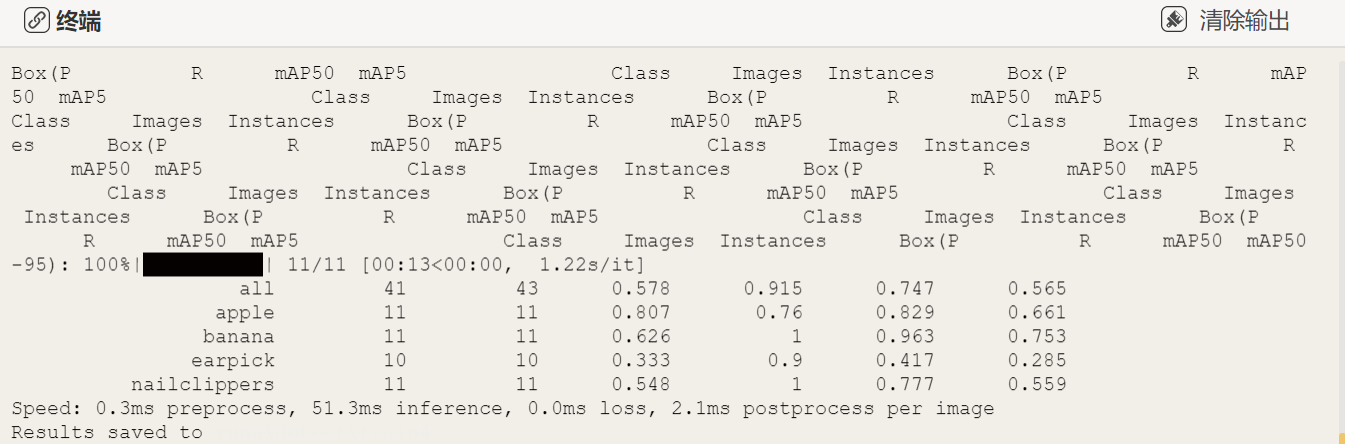
模型训练完成可以观察终端出现以下数据,是标记的所有商品类别标签和它的准确率、召回率、F1等数据。
4.3模型转换
我们训练得到的"best.pt"可以直接用于推理,我们也可以将"best.pt"转成onnx格式的模型文件。ONNX格式也是一种模型文件的格式,更加通用,可以与各种推理引擎兼容,提供更高效的推理速度。
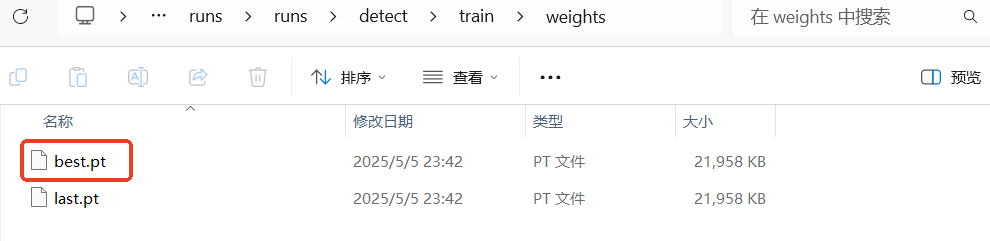
使用以下代码将pt格式的模型文件转成onnx格式的模型文件。
from ultralytics import YOLO
# 模型路径,这里填你的pt文件的实际路径
model_path = r'C:\Users\HYPAB\Desktop\ultralytics-main\runs\runs\detect\train\weights\best.pt' # 训练完成后保存的模型路径
# 加载模型
model = YOLO(model_path)
# 导出为onnx格式
model.export(format='onnx')
print("模型已成功导出为onnx格式")转换好后,可以在同一目录下找到转换好的onnx模型。
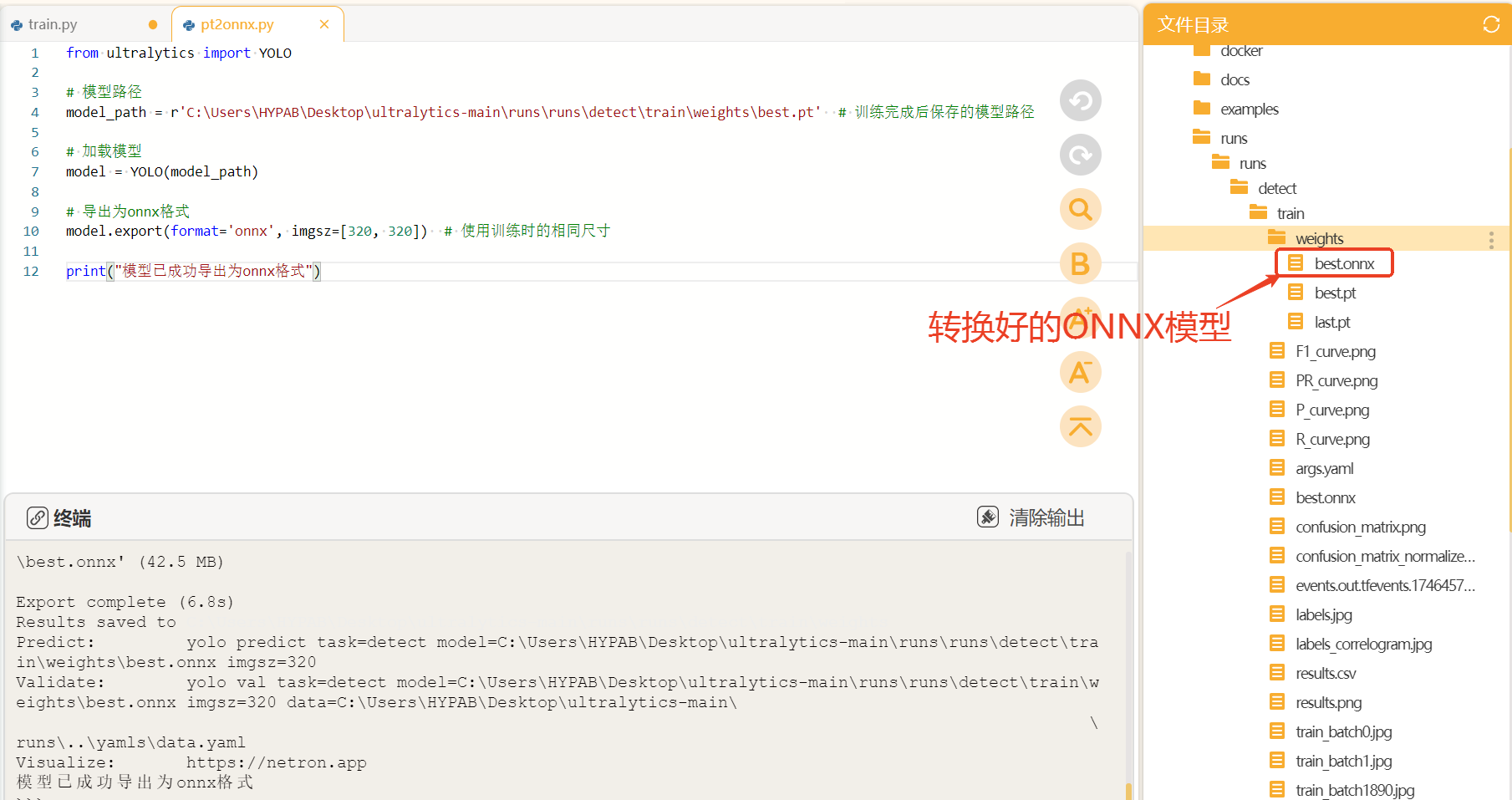
4.4模型测评与导出
我们先在电脑端测试一下模型的性能,将训练好的模型拖入Mind+项目中的文件下
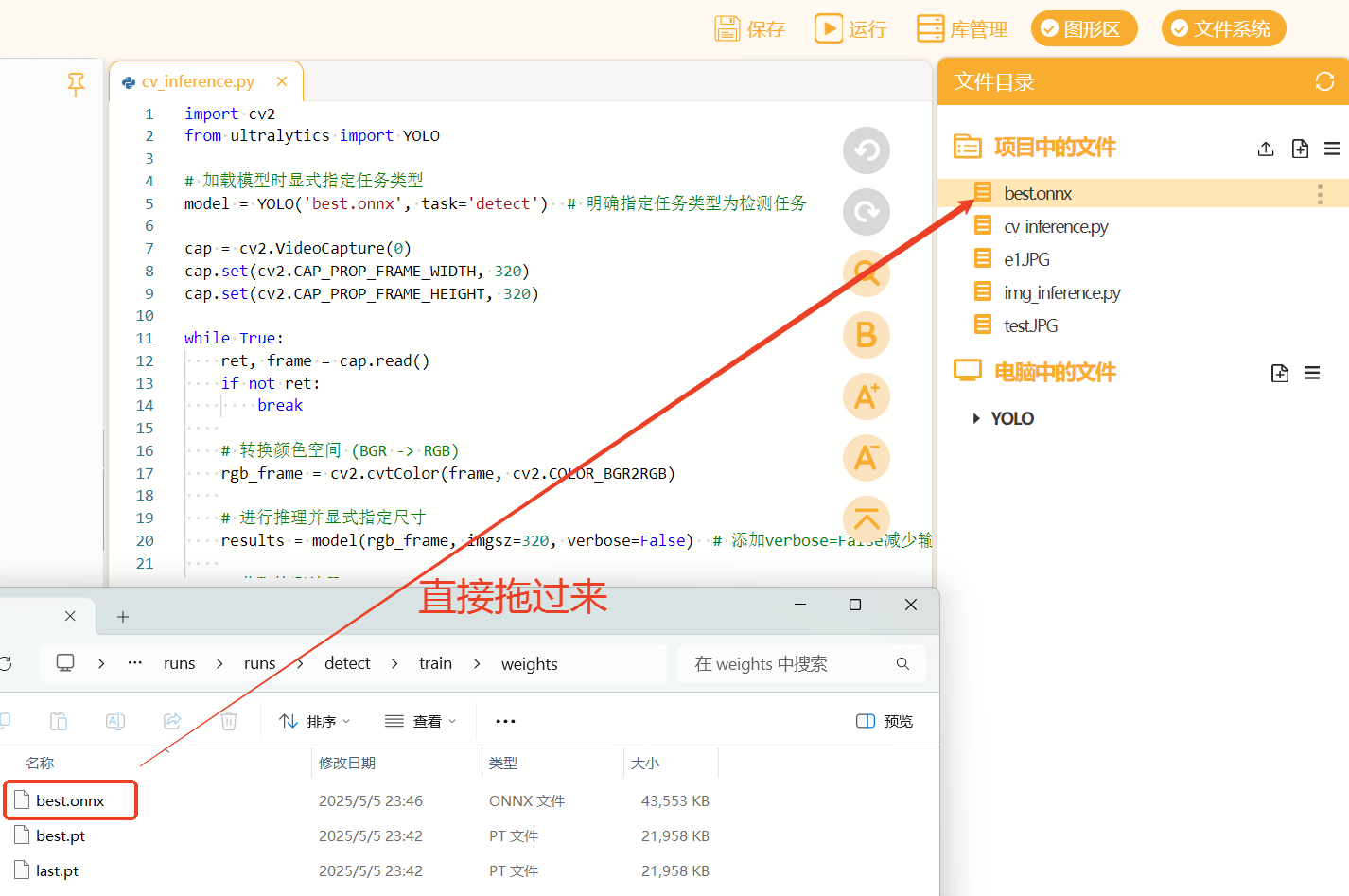
再在项目中的文件中新建一个叫做"img_inference.py"(用来测试图片推理效果),同时将测试图片"test.JPG"也拖入项目中的文件夹下。
测试图片如下图所示,由于我们训练模型时规定的输入尺寸为320*320,所以推理时图片尺寸不得大于这个尺寸。

将以下代码复制到"img_inference.py"文件中进行图片推理测试。
from ultralytics import YOLO
import cv2
# 1. 加载预训练模型
model = YOLO('best.onnx', task='detect') # 显式指定任务为检测
# 2. 进行图像推理(带类别统计)
def predict_image(image_path, conf=0.5):
# 读取图像并调整尺寸
img = cv2.imread(image_path)
img = cv2.resize(img, (320, 320))
# 执行推理
results = model.predict(
source=img,
conf=conf,
save=False,
imgsz=320
)
# 初始化类别计数器
class_counts = {}
# 遍历检测结果
for result in results:
# 获取检测到的所有类别
detected_classes = result.boxes.cls.tolist()
# 统计每个类别的出现次数
for class_id in detected_classes:
class_name = result.names[int(class_id)]
class_counts[class_name] = class_counts.get(class_name, 0) + 1
# 可视化结果
annotated_img = results[0].plot()
# 显示结果
cv2.imshow('Detection', annotated_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
return results, class_counts # 返回结果和统计信息
if __name__ == '__main__':
try:
# 执行检测并获取统计结果
image_results, counts = predict_image('test.JPG', conf=0.6)
# 打印检测统计
print("\n检测结果统计:")
for class_name, count in counts.items():
print(f"{class_name}: {count}个")
# 原始检测信息(可选)
print("\n详细检测信息:")
for result in image_results:
for box in result.boxes:
print(f"类别: {result.names[int(box.cls)]}, 置信度: {box.conf.item():.2f}")
except Exception as e:
print(f"发生错误: {str(e)}")点击Mind+右上角的”运行",运行代码观察效果。
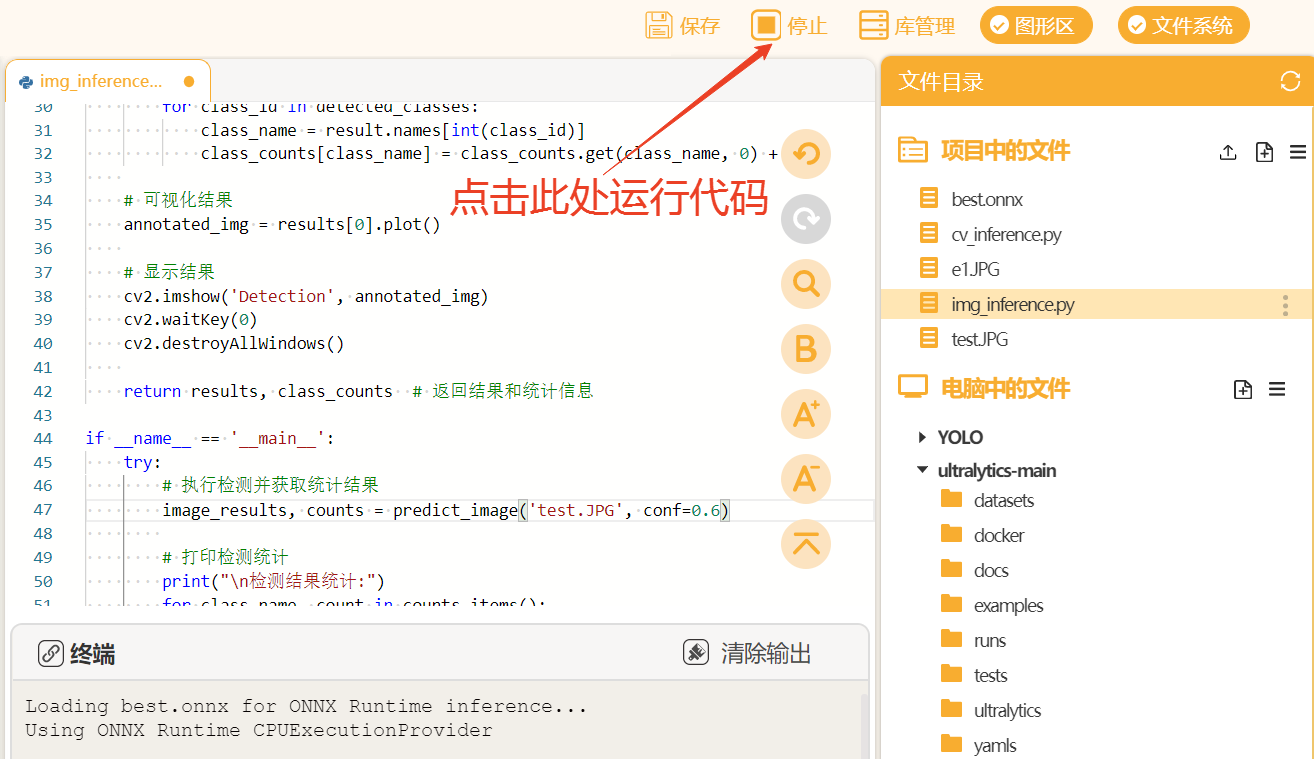
当程序运行时,可以观察到弹出以下窗口,显示在测试图片上的推理结果。观察图片,发现模型成功的检测到了图片中的四个苹果,且置信度都比较高,效果比较好。

观察终端的输出,可以看到终端出现了检测的商品类别的统计信息。
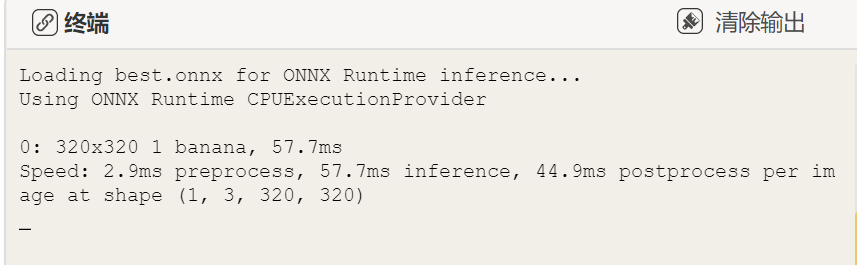
接着我们可以继续创建一个叫做"cv_inference.py"的文件(测试实时视频流下的推理效果,可以观看注释了解代码功能),将以下推理代码粘贴到"cv.inference.py"文件中。
import cv2
from ultralytics import YOLO
# 加载模型时显式指定任务类型
model = YOLO('best.onnx', task='detect') # 明确指定任务类型为检测任务
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320)
while True:
ret, frame = cap.read()
if not ret:
break
# 转换颜色空间 (BGR -> RGB)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 进行推理并显式指定尺寸
results = model(rgb_frame, imgsz=320, verbose=False) # 添加verbose=False减少输出
# 获取检测结果
detections = results[0].boxes.data.tolist()
# 统计水果数量
fruit_counts = {}
for detection in detections:
class_id = int(detection[5]) # 类别ID在第6个位置
class_name = model.names[class_id] # 获取类别名称
if class_name in fruit_counts:
fruit_counts[class_name] += 1
else:
fruit_counts[class_name] = 1
# 绘制结果
annotated_frame = results[0].plot()
# 在图像上添加统计信息
y_offset = 30
for fruit, count in fruit_counts.items():
cv2.putText(annotated_frame, f"{fruit}: {count}", (10, y_offset),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
y_offset += 30
# 打印推理时间
inference_time = results[0].speed['inference']
print(f"推理时间: {inference_time}ms")
# 打印检测结果统计
print("检测结果统计:")
for fruit, count in fruit_counts.items():
print(f"{fruit}: {count}个")
# 打印详细检测信息
print("详细检测信息:")
for detection in detections:
class_id = int(detection[5])
class_name = model.names[class_id]
confidence = detection[4]
print(f"类别: {class_name}, 置信度: {confidence:.2f}")
cv2.imshow('Detection', cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR))
if cv2.waitKey(1) == ord('a'):
break
cap.release()
cv2.destroyAllWindows()运行程序,可以看到出现一个窗口实时的显示电脑摄像头放入画面,并将画面中的商品检测结果实时的显示出来.这里视频流的尺寸仍是320*320。相比图片推理效果来看,受视频画质的限制,视频推理的置信度结果有所降低,不过准确度还是可以的。
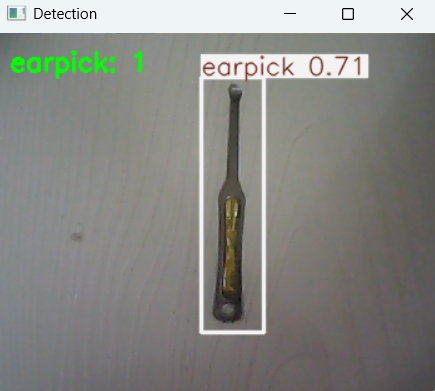
4.5部署模型到行空板完成执行操作
接着我们可以部署模型到行空板中制作商品自动计数及计价装置。使用USB数据线连接电脑与行空板。

连接行空板与摄像头。

打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载
点击返回,点击连接设备,找到10.1.2.3.点击连接,等待连接成功.
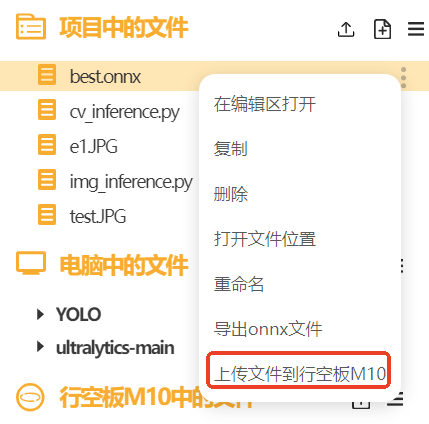
我们选中模型文件点击上传到行空板中。上传成功能在行空板的根目录下找到模型文件。

同样的,我们将"cv_inference.py"文件也上传到行空板中。因为需要屏幕显示商品的数量及价格等结果,所以新建了"goods_count.py"文件。
保持行空板的连接,在终端输入以下指令来激活行空板的yolo环境(请确保完成3.2硬件环境部署准备)。
conda activate yolo
接着在终端输入以下指令,因为需要屏幕显示计价等结果,所以把cv_inference.py程序稍作修改并保存为goods_count.py文件,在行空板中运行"goods_count.py"文件,第一次加载模型比较慢,请耐心等待。
python goods_count.py
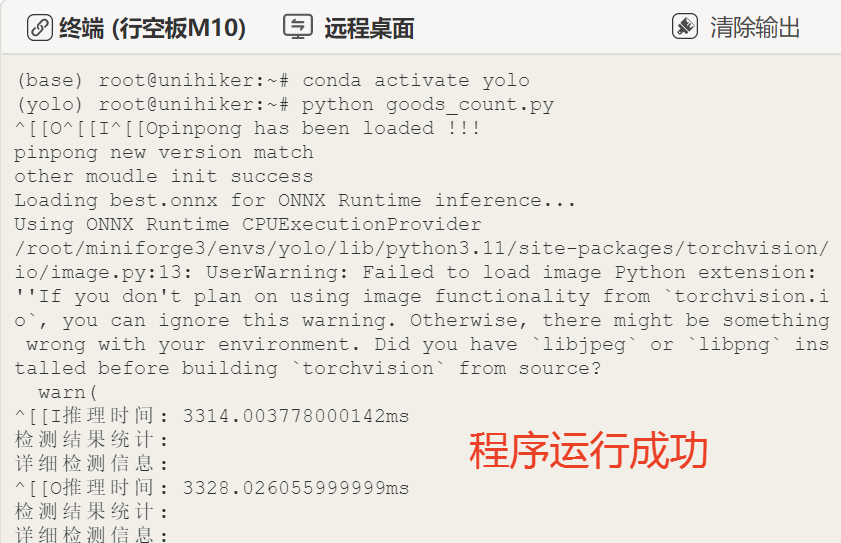
运行成功后,我们可以调整摄像头的角度,观察行空板屏幕能自动圈出画面中的水果,将数量显示在行空板屏幕画面左上角。这样,我们就成功用行空板M10与摄像头实现了实时检测商品并自动计数和计价的功能。

4.6核心代码解析
我们一起来看一下在行空板上运行的'goods_count.py'代码的核心功能代码。
如下图,此程序主要分成以下几个部分:
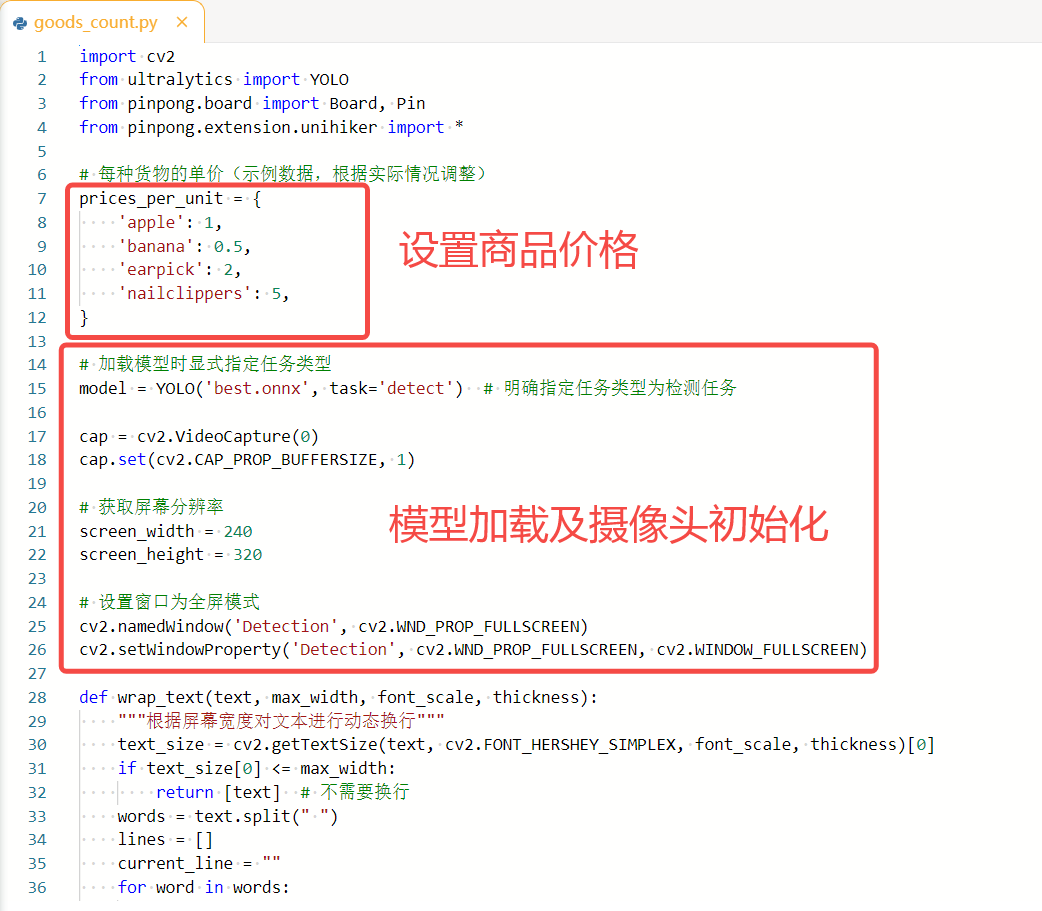
1.设置商品的价格。
prices_per_unit = {
'apple': 1,
'banana': 0.5,
'earpick': 2,
'nailclippers': 5,
}2.YOLO模型加载以及摄像头初始化。
import cv2
from ultralytics import YOLO
from pinpong.board import Board, Pin
from pinpong.extension.unihiker import *
# 加载模型时显式指定任务类型
model = YOLO('best.onnx', task='detect') # 明确指定任务类型为检测任务
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 获取屏幕分辨率
screen_width = 240
screen_height = 320
# 设置窗口为全屏模式
cv2.namedWindow('Detection', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
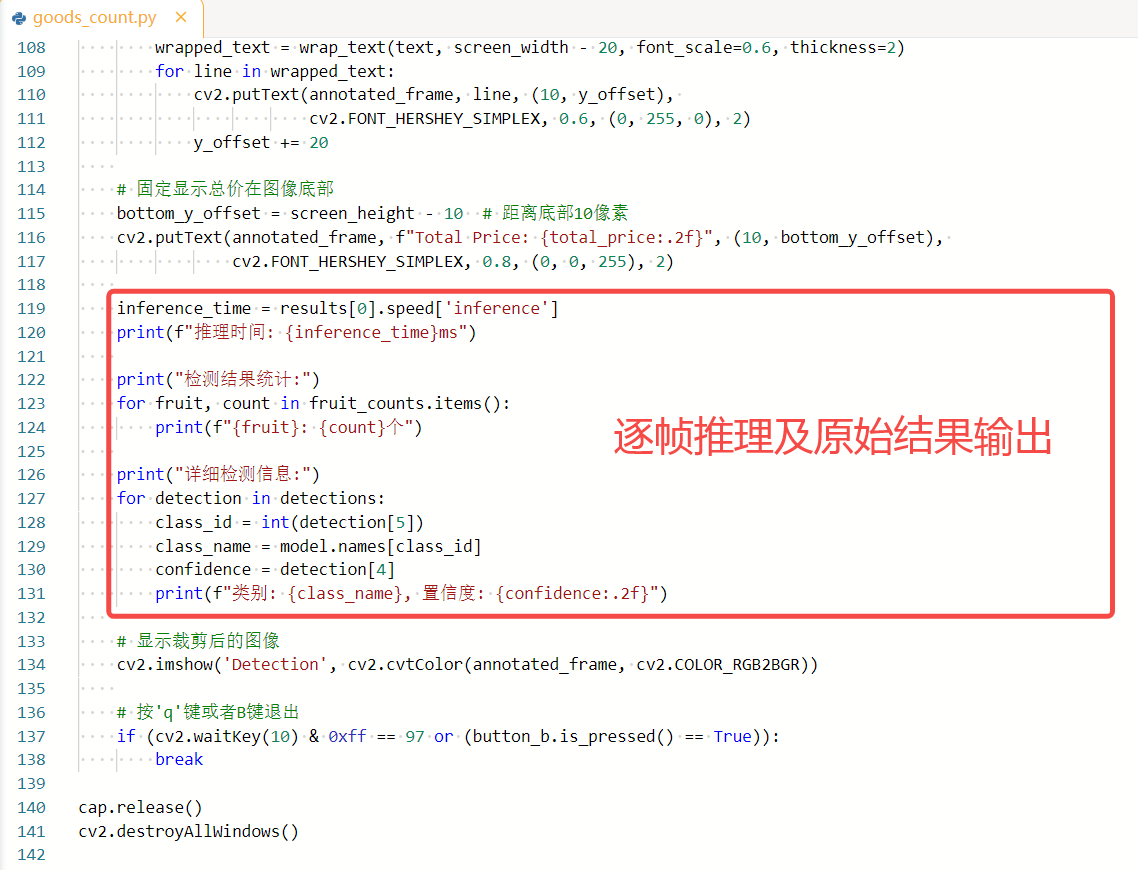
3.逐帧推理及原始结果输出(逐帧读取摄像头数据,调用模型进行推理,并输出原始检测结果)。
while True:
ret, frame = cap.read()
if not ret:
break
# 获取摄像头图像的宽高
h, w, _ = frame.shape
# 转换颜色空间 (BGR -> RGB)
rgb_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 进行推理并显式指定尺寸
results = model(rgb_frame, imgsz=320, verbose=False)
# 获取检测结果
detections = results[0].boxes.data.tolist()
inference_time = results[0].speed['inference']
print(f"推理时间: {inference_time}ms")
print("检测结果统计:")
for fruit, count in fruit_counts.items():
print(f"{fruit}: {count}个")
print("详细检测信息:")
for detection in detections:
class_id = int(detection[5])
class_name = model.names[class_id]
confidence = detection[4]
print(f"类别: {class_name}, 置信度: {confidence:.2f}")4.推理结果处理及屏幕显示(比如统计商品数量、计算价格、绘制检测框和标签、显示结果等)。
def wrap_text(text, max_width, font_scale, thickness):
"""根据屏幕宽度对文本进行动态换行"""
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, font_scale, thickness)[0]
if text_size[0] <= max_width:
return [text] # 不需要换行
words = text.split(" ")
lines = []
current_line = ""
for word in words:
test_line = (current_line + " " + word).strip()
test_size = cv2.getTextSize(test_line, cv2.FONT_HERSHEY_SIMPLEX, font_scale, thickness)[0]
if test_size[0] > max_width:
lines.append(current_line.strip())
current_line = word
else:
current_line = test_line
if current_line:
lines.append(current_line.strip())
return lines
while True:
ret, frame = cap.read()
if not ret:
break
# 获取摄像头图像的宽高
h, w, _ = frame.shape
# 根据屏幕宽高比例裁剪图像
aspect_ratio_screen = screen_width / screen_height
aspect_ratio_frame = w / h
if aspect_ratio_frame > aspect_ratio_screen:
# 图像宽度过大,需要裁剪宽度
new_width = int(h * aspect_ratio_screen)
x_offset = (w - new_width) // 2
cropped_frame = frame[:, x_offset:x_offset + new_width]
else:
# 图像高度过大,需要裁剪高度
new_height = int(w / aspect_ratio_screen)
y_offset = (h - new_height) // 2
cropped_frame = frame[y_offset:y_offset + new_height, :]
# 将裁剪后的图像调整为目标分辨率
resized_frame = cv2.resize(cropped_frame, (screen_width, screen_height))
# 转换颜色空间 (BGR -> RGB)
rgb_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 进行推理并显式指定尺寸
results = model(rgb_frame, imgsz=320, verbose=False)
# 获取检测结果
detections = results[0].boxes.data.tolist()
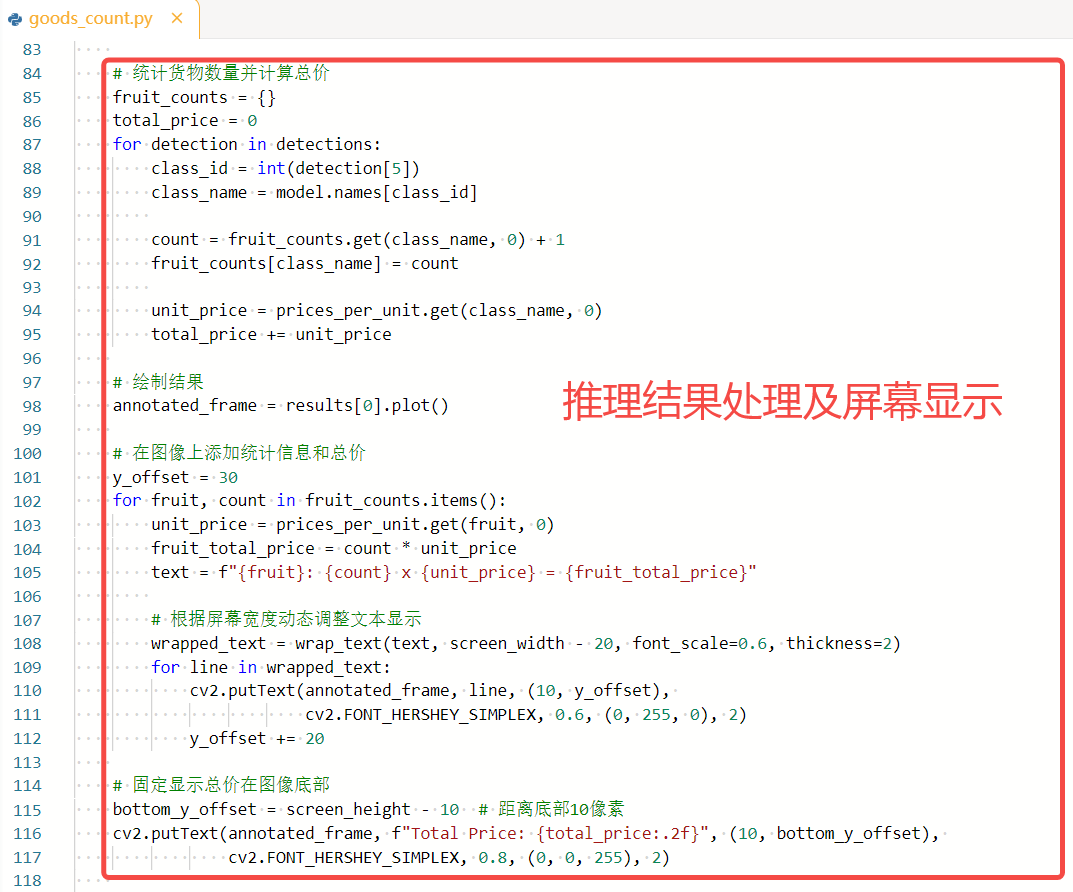
# 统计货物数量并计算总价
fruit_counts = {}
total_price = 0
for detection in detections:
class_id = int(detection[5])
class_name = model.names[class_id]
count = fruit_counts.get(class_name, 0) + 1
fruit_counts[class_name] = count
unit_price = prices_per_unit.get(class_name, 0)
total_price += unit_price
# 绘制结果
annotated_frame = results[0].plot()
# 在图像上添加统计信息和总价
y_offset = 30
for fruit, count in fruit_counts.items():
unit_price = prices_per_unit.get(fruit, 0)
fruit_total_price = count * unit_price
text = f"{fruit}: {count} x {unit_price} = {fruit_total_price}"
# 根据屏幕宽度动态调整文本显示
wrapped_text = wrap_text(text, screen_width - 20, font_scale=0.6, thickness=2)
for line in wrapped_text:
cv2.putText(annotated_frame, line, (10, y_offset),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
y_offset += 20
# 固定显示总价在图像底部
bottom_y_offset = screen_height - 10 # 距离底部10像素
cv2.putText(annotated_frame, f"Total Price: {total_price:.2f}", (10, bottom_y_offset),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
# 显示裁剪后的图像
cv2.imshow('Detection', cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR))
# 按'q'键或者B键退出
if (cv2.waitKey(10) & 0xff == 97 or (button_b.is_pressed() == True)):
break
cap.release()
cv2.destroyAllWindows()
其中第2和3的部分是通用代码,设置商品价格、推理结果处理及屏幕显示可以自定义为想要显示的效果。
怎么二次处理原始推理结果呢?,我们先来看看原始推理输出的结果有什么吧!
在程序中,我们使用的是以下语句来获取模型推理和打印推理结果。model()是YOLO模型的推理函数,conf=0.5设置置信度阈值为0.5,只有置信度大于或等于这个阈值的检测结果才会被保留,这个值可以根据实际需要进行修改。results存储了模型推理的输出结果。可以使用print语句将results打印出来。
# 使用YOLO模型进行目标检测
results = model(rgb_frame, imgsz=320, verbose=False, conf=0.5) # 对RGB图像进行推理,指定输入图像尺寸为320x320,并设置置信度阈值0.5才输出
print('模型的原始输出:',results)如下图,是我打印的模型推理的原始结果。
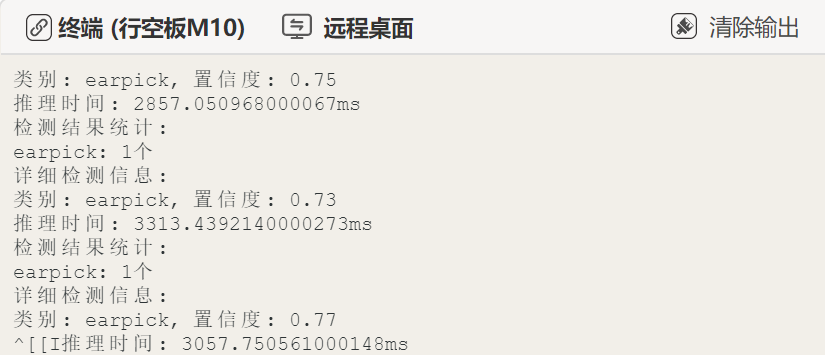
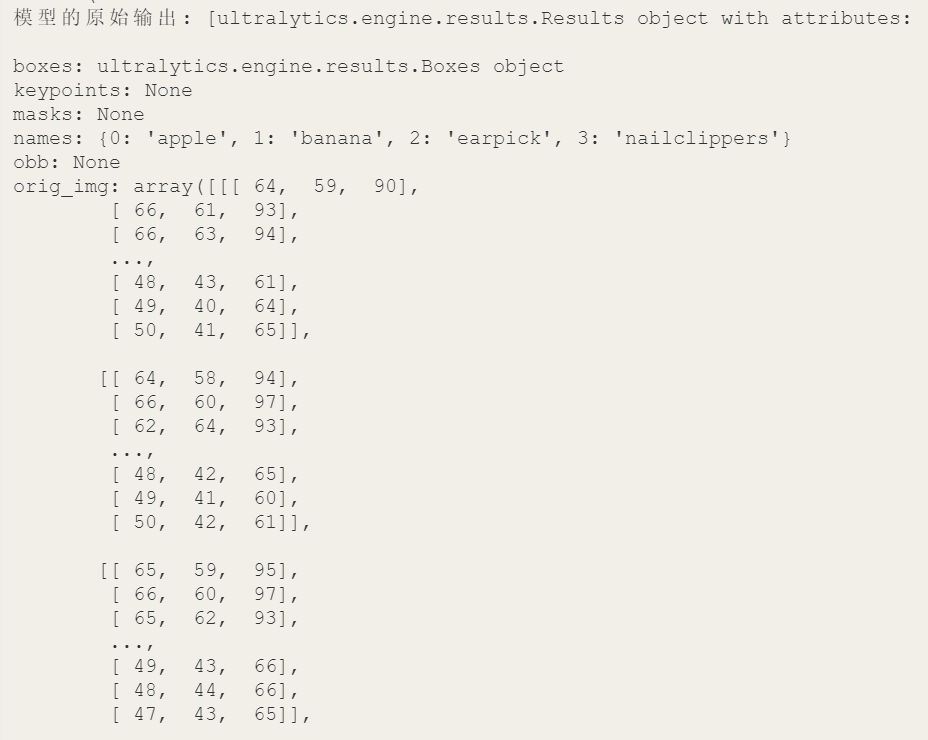

这里,以表格的形式整理了模型原始输出的全部内容,如下。我们可以观察到原始的推理输出有比较多的内容,在项目的人制作中不是每一个输出数据都要用到,其中最常被用的数据是"boxes"和"names"。boxes: 包含检测框的详细信息,包括边界框坐标、置信度和类别ID。这是最常被使用的数据。names: 提供类别ID到类别名称的映射,用于将检测结果转换为人类可读的类别名称。
为了能够从每一次推理的原始输出中挑出商品的类别与数量,可以在代码中加入遍历boxes数据,从中提取出检测出的每个类别与其置信度,同时统计数量,各个商品每出现一次就加1,然后计算价格。最后将所有的结果绘制并显示在屏幕上,从而实现了实时检测商品并自动计数和计价的功能。
(完整代码如下:)
import cv2
from ultralytics import YOLO
from pinpong.board import Board, Pin
from pinpong.extension.unihiker import *
# 每种货物的单价(示例数据,根据实际情况调整)
prices_per_unit = {
'apple': 1,
'banana': 0.5,
'earpick': 2,
'nailclippers': 5,
}
# 加载模型时显式指定任务类型
model = YOLO('best.onnx', task='detect') # 明确指定任务类型为检测任务
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 获取屏幕分辨率
screen_width = 240
screen_height = 320
# 设置窗口为全屏模式
cv2.namedWindow('Detection', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
def wrap_text(text, max_width, font_scale, thickness):
"""根据屏幕宽度对文本进行动态换行"""
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, font_scale, thickness)[0]
if text_size[0] <= max_width:
return [text] # 不需要换行
words = text.split(" ")
lines = []
current_line = ""
for word in words:
test_line = (current_line + " " + word).strip()
test_size = cv2.getTextSize(test_line, cv2.FONT_HERSHEY_SIMPLEX, font_scale, thickness)[0]
if test_size[0] > max_width:
lines.append(current_line.strip())
current_line = word
else:
current_line = test_line
if current_line:
lines.append(current_line.strip())
return lines
while True:
ret, frame = cap.read()
if not ret:
break
# 获取摄像头图像的宽高
h, w, _ = frame.shape
# 根据屏幕宽高比例裁剪图像
aspect_ratio_screen = screen_width / screen_height
aspect_ratio_frame = w / h
if aspect_ratio_frame > aspect_ratio_screen:
# 图像宽度过大,需要裁剪宽度
new_width = int(h * aspect_ratio_screen)
x_offset = (w - new_width) // 2
cropped_frame = frame[:, x_offset:x_offset + new_width]
else:
# 图像高度过大,需要裁剪高度
new_height = int(w / aspect_ratio_screen)
y_offset = (h - new_height) // 2
cropped_frame = frame[y_offset:y_offset + new_height, :]
# 将裁剪后的图像调整为目标分辨率
resized_frame = cv2.resize(cropped_frame, (screen_width, screen_height))
# 转换颜色空间 (BGR -> RGB)
rgb_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 进行推理并显式指定尺寸
results = model(rgb_frame, imgsz=320, verbose=False)
# 获取检测结果
detections = results[0].boxes.data.tolist()
# 统计货物数量并计算总价
fruit_counts = {}
total_price = 0
for detection in detections:
class_id = int(detection[5])
class_name = model.names[class_id]
count = fruit_counts.get(class_name, 0) + 1
fruit_counts[class_name] = count
unit_price = prices_per_unit.get(class_name, 0)
total_price += unit_price
# 绘制结果
annotated_frame = results[0].plot()
# 在图像上添加统计信息和总价
y_offset = 30
for fruit, count in fruit_counts.items():
unit_price = prices_per_unit.get(fruit, 0)
fruit_total_price = count * unit_price
text = f"{fruit}: {count} x {unit_price} = {fruit_total_price}"
# 根据屏幕宽度动态调整文本显示
wrapped_text = wrap_text(text, screen_width - 20, font_scale=0.6, thickness=2)
for line in wrapped_text:
cv2.putText(annotated_frame, line, (10, y_offset),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
y_offset += 20
# 固定显示总价在图像底部
bottom_y_offset = screen_height - 10 # 距离底部10像素
cv2.putText(annotated_frame, f"Total Price: {total_price:.2f}", (10, bottom_y_offset),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
inference_time = results[0].speed['inference']
print(f"推理时间: {inference_time}ms")
print("检测结果统计:")
for fruit, count in fruit_counts.items():
print(f"{fruit}: {count}个")
print("详细检测信息:")
for detection in detections:
class_id = int(detection[5])
class_name = model.names[class_id]
confidence = detection[4]
print(f"类别: {class_name}, 置信度: {confidence:.2f}")
# 显示裁剪后的图像
cv2.imshow('Detection', cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR))
# 按'q'键或者B键退出
if (cv2.waitKey(10) & 0xff == 97 or (button_b.is_pressed() == True)):
break
cap.release()
cv2.destroyAllWindows()
项目扩展思考:除了屏幕显示商品数量、价格,还可以结合其它硬件进行扩展,例如添加语音合成模块,将结果播报出来等等。
5.项目相关资料附录
项目文件: https://pan.baidu.com/s/1gPZMLvAXh2wHyd2w6i-Mrw?pwd=f2p3



 他的勋章
他的勋章


罗罗罗2025.11.17
666