 返回首页
返回首页
 回到顶部
回到顶部

随着智能交通和自动驾驶技术的快速发展,智能小车在现代交通系统中扮演着越来越重要的角色。为了提高小车的自主驾驶能力和交通安全性,我们提出了一个基于摄像头的智能小车区域识别系统。通过整合摄像头、图像处理技术和深度学习算法,实现一个能够实时识别行驶区域并进行相应驾驶决策的智能小车系统。这个系统将为智能交通和自动驾驶领域提供一种高效、低成本的解决方案,并推动智能小车在各种应用场景中的广泛应用。

任务目标
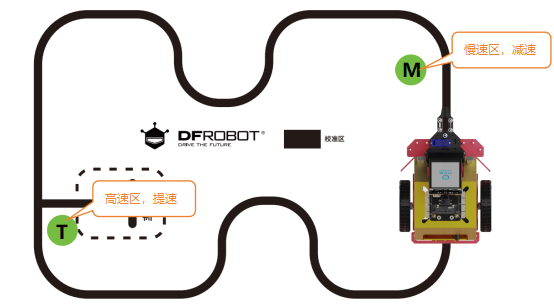
设计并实现一个基于摄像头的智能小车区域识别系统,能够通过摄像头捕捉到的实时图像数据,识别不同的行驶区域(如加速区、减速区等),并控制小车作出相应的驾驶行为调整(加速/减速行驶)。
知识点
1. 掌握获取背景颜色HSV值的方法
2. 掌握如何根据识别的区域标识控制小车加速、减速
材料清单
硬件清单:
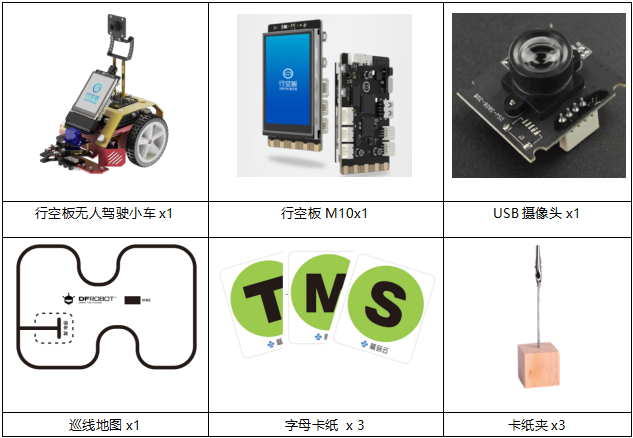
软件使用:Mind+编程软件
下载地址:https://mindplus.cc/

课 前 准 备 ——环境设置
在开始正式学习之前,我们需要对行空板进行一些基础准备,确保系统和环境设置都正确。
具体步骤,请参考:行空板无人驾驶系列课程 第一课 课前准备 部分内容。
动手实践
这个项目将重点放在区域标志识别系统设计部分,我们将收集大量区域卡纸M与区域卡纸T的图像,然后使用深度学习框架TensorFlow来训练识别模型。最后,将训练好的模型部署在小车上,配合USB摄像头来进行区域标志识别。因此,分为以下几个小任务来实现。
任务一:采集区域字母图像
通过摄像头,采集区域卡纸M和区域卡纸T的图像,并将采集好的图像,保存在行空板文件中。
任务二:训练区域识别模型
使用TensorFlow模型,对收集好的图像数据进行模型训练,并将训练好的模型进行保存。
任务三:区域标志识别
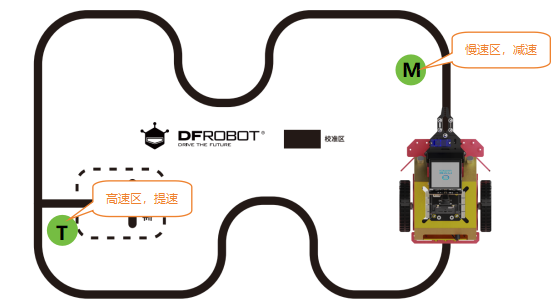
将训练好的识别模型部署在行空板小车上,小车在巡线过程中,识别到区域卡纸M时,减速;识别到区域卡纸T时,加速。
任务一:采集区域字母图像
1. 硬件连接
使用type-c转A数据线,将USB音频模块与行空板连接,然后再使用type-c转A线将摄像头连接在音频模块上。

2. 软件准备
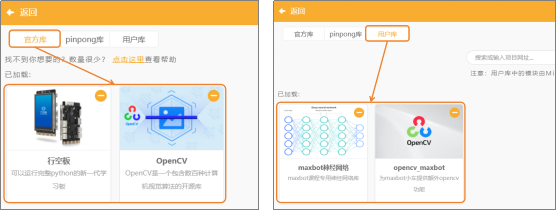
(1)添加官方库:点击“扩展”,在“官方库”中,选择“行空板”与“Opencv”。
(2)添加用户库:选择“maxbot神经网络”、“opencv_maxbot”。
3. 编写程序
本任务中图像采集方法与第4课货物识别系统的任务一相同,此处仅简要介绍步骤,详细内容可参考第4课。
(1)创建文件夹
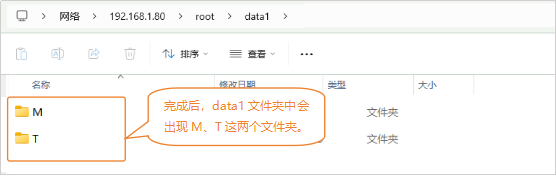
首先,新建“变量file_name”,并初始化变量的值为“/root/data1/M”。使用“创建文件夹 来保存数据”指令,在“/root/data1”中,创建一个名为“M”的文件夹,用来保存采集到卡纸M的图像。

(2)打开摄像头并显示图像
打开摄像头,并从摄像头中获取图像,然后将图像进行裁剪后,显示在行空板上。
(3)采集图像并保存
当按钮A被按下时,开始采集图像,最后将采集的图像保存在创建好的文件夹中。

区域图像采集的完整程序如下:

4. 程序运行
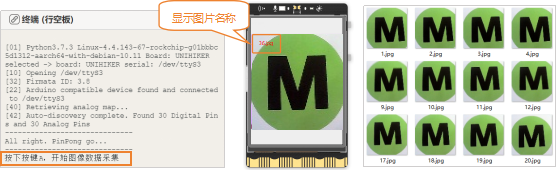
远程连接192.168.1.80,连接成功后,点击运行。程序运行成功后,Mind+终端打印区出现提示“按下A键开始图像数据采集”。图像采集操作如下:将USB摄像头,对着区域卡纸M,行空板上出现区域卡纸M的图像后,按下A键不松手,可快速采集图像数据。直到采集到大约500张图像数据后,松开按键。
注意:采集图像过程中,需要调整摄像头角度,多角度采集物体图像,可以提高识别率。
5. 试一试
这个项目中,还需要采集区域卡纸T的图像,大家尝试一下,修改程序中的file_name,采集区域卡纸T的图像。
提示:任务一的程序中修改file_name中的文件名,再次运行程序后,进行对应的图像采集即可。
任务二:训练区域识别模型
1. 软件准备
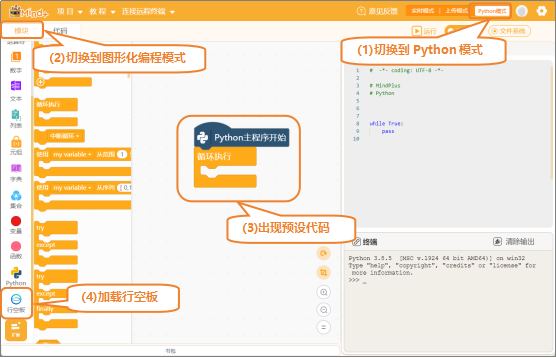
(1)打开Mind+:按照下面的图示完成软件准备工作。
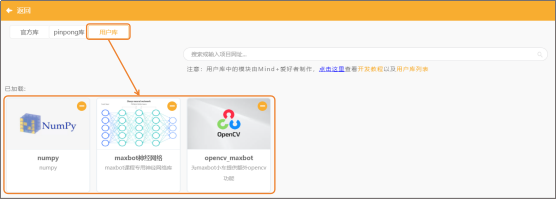
(2)添加用户库:选择“maxbot神经网络”、“opencv_maxbot”、“numpy”。
2. 编写程序
要完成物体识别模型的训练,需要用的卷积神经网络算法,程序主要通过以下5个步骤来完成:导入数据集、数据预处理、创建神经网络、训练模型、保存模型。
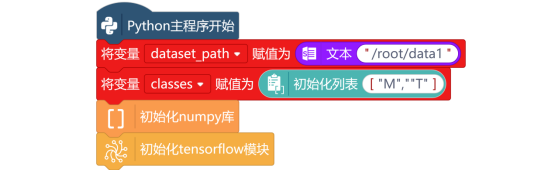
1. 导入数据集
训练模型需要用到采集到的图片,新建“变量dataset_path”,并初始化变量的值为图片保存的路径“/root/data1”,然后新建“列表classes”,并初始化列表的值为文件夹名。最后,使用“初始化numpy”与“初始化tensorflow模块”指令,将numpy库和tensorflow库,进行初始化。
2. 数据预处理
要处理数据,使用“加载图片数据训练集 和验证集 数据 数据源 比例 输入大小 ”指令,从数据集目录中加载图片数据,并创建训练集和验证集。数据集和验证集创建成功后,使用“创建顺序模型 ”指令,创建一个序列模型,并将其命名为“sign_model”,用来存储创建好的模型。

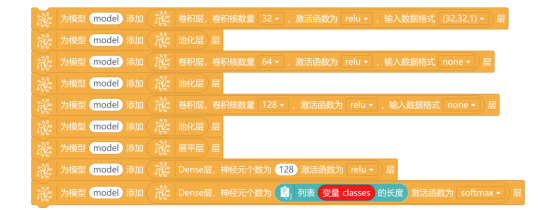
3. 创建神经网络
需要使用“为模型 添加 层”与“卷积层,卷积核数量 激活函数为 ,输入数据格式 层”指令,分别创建三个卷积层和池化层,需要修改卷积层的卷积核数量和输入数据格式。使用同样的方法再添加一层展平层和两层Dense层。通过3层卷积层、3层池化层、1层展平层、两层全连接层,构建完整的神经网络模型。
4. 训练模型
训练模型的过程没有对应的程序指令,但是我们可以通过“打印 ”和“模型的 结构 ”指令,对训练模型的过程和训练次数进行打印。在训练模型时,需要先使用“设置模型 参数,优化器,损失函数,评价函数”指令,对模型进行编译。

5. 保存模型
使用“训练模型 训练数据集 训练次数 验证数据集”指令,进行模型训练。最后使用“以saved_model格式保存模型 到 ”指令,将训练好的模型进行保存。保存完成后,使用“将saved_model模型 转化为ONNX模型 ”指令,将TensorFlow模型转换为ONNX格式。

训练区域识别模型的完整程序如下:

3. 程序运行
远程连接192.168.1.80,连接成功后,点击运行。直到行空板和Mind+终端显示“模型转化完成,程序终止”字符串后,模型训练完成,自动退出程序。
任务三:区域标志识别
1. 硬件连接
这个巡线传感器是由3个独立的巡线传感器组合在一起,因此,每个巡线传感器是独立工作的。下面,将这三个巡线传感器分别连接P10、P11、P13这三个引脚。左侧巡线传感器—P10、中间巡线传感器—P11、右侧巡线传感器—P13。

2. 软件准备
(1)添加官方库:点击“扩展”,在“官方库”中,选择“行空板”与“Opencv”。
(2)添加用户库:选择“numpy”、“opencv_maxbot”、“maxbot神经网络”、“Maxbot行空板小车电机驱动”。
3.编写程序
使用ONNX模型进行物体识别,需要通过模型加载和预处理、图像处理、图像预测与展示这三个步骤。这些步骤已在第4课任务三中学习过,具体说明可参考该部分内容,此处不再赘述。
注意:因仅训练了M和T区域的识别模型,Numpy数组应设置为1,2。
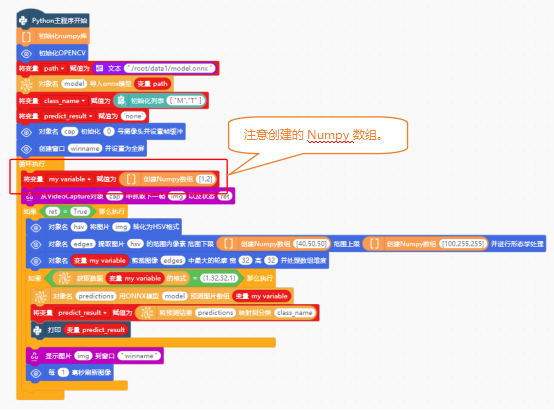
完成摄像头识别功能后,分别创建line_track_low和line_track_high函数,实现低速和高速巡线逻辑。当然,还需要在“Python主程序开始”指令下,使用“pin初始化 引脚号 模式”指令,对巡线传感器引脚进行初始化。
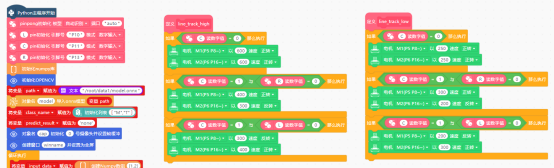
由于摄像头识别和巡线两个独立的功能,要同时执行。因此,巡线功能需要在线程中实现。使用“线程对象thread启动”指令与“当线程对象thread1启动后执行”指令,在“Python主程序开始”下,启动线程。在“当线程对象thread1启动后执行”指令下,并添加“循环执行”指令。
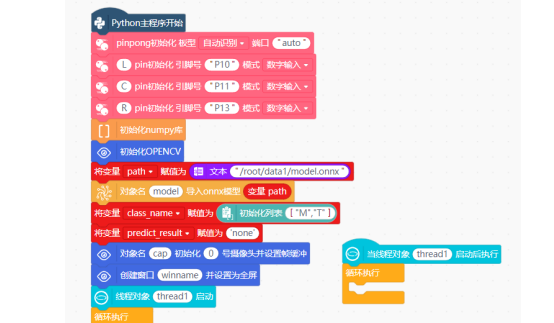
如何在线程中调用对应的巡线函数呢?我们假设M区域为低速区,T区域为高速区。可以通过识别结果“变量predict_result”的值来进行判断,当识别结果“变量predict_result”的值为“M”时,小车进入低速区,调用“函数line_track_low”。
注意:需要将变量predict_result声明为“全局变量”。
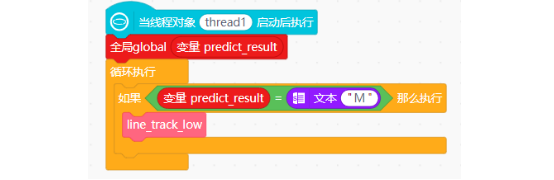
当识别结果“变量predict_result”的值为“T”时,小车进入高速区,调用“函数line_track_high”。
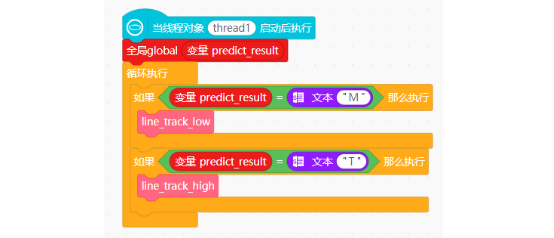
初始状态下,小车应以低速模式巡线。因此,在“当线程对象 thread1启动后执行”指令下,除了根据识别结果进行两种不同的巡线方式之外,还需要在启用线程时,就调用一次“函数 line_track_low”,完整程序如下:
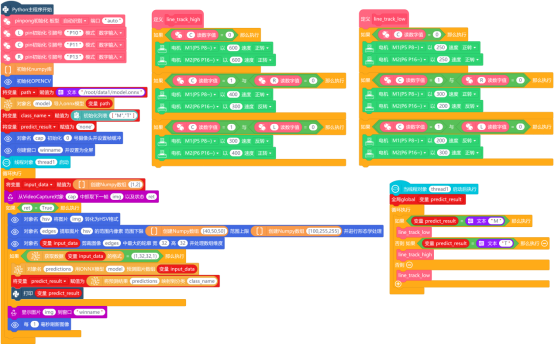
4. 程序运行
远程连接192.168.1.80,连接成功后,点击运行。程序运行成功后,摄像头打开,将摄像头检测到的画面实时显示在行空板屏幕上,小车进入低速巡线模式。当摄像头识别到区域卡纸T时,小车增加巡线速度,进入高速巡线模式;当摄像头识别到区域卡纸M时,小车降低巡线速度,进入低速巡线模式。
5. 试一试
调试时可能出现误识别问题,例如将卡纸M识别为T。这是由于小车巡线时摄像头抖动导致的。
因为小车在巡线过程中,车体运动会带着摄像头出现抖动,就会导致识别结果出现识别不准确的情况。既然我们已经发现了问题,大家想一想,该如何对程序进行优化呢?
思考:新建“变量count_M”,当识别结果为“M”时,变量count_M+1,当变量count_M的值大于5时,说明识别到标志“M”,调用“函数line_track_low”。大家试一下,通过这样的方式,是否可以优化我们的程序呢?如果可以,怎样来调整程序呢?
知识园地
1. 获取背景颜色的HSV值
在第9课、第10课中,都用到了HSV值,并且知道可以通过HSV值,进行颜色提取,从而实现图像去噪,这是识别的重要步骤。HSV值在识别中至关重要,以下是获取HSV值的方法:
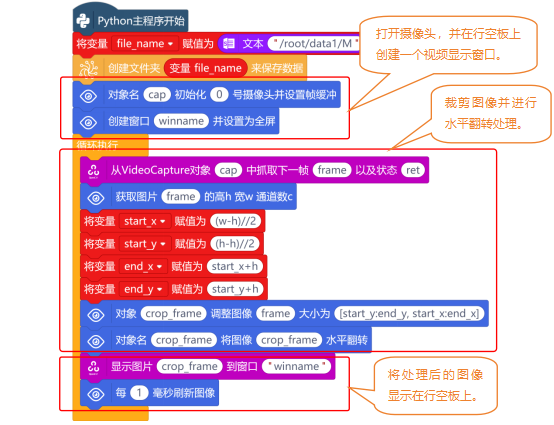
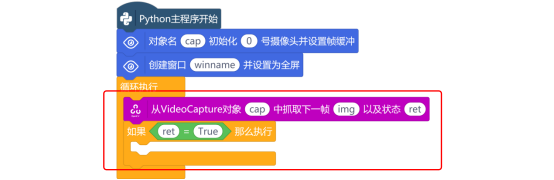
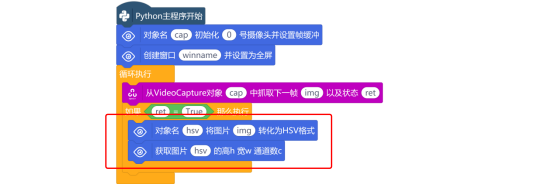
要获取HSV值,需要摄像头实时地捕获图像,因此,使用“对象名 初始化 号摄像头并设置帧缓冲”与“创建窗口 并设置为全屏”指令,对摄像头进行初始化,并在行空板屏幕上创建一个显示窗口。

打开摄像头后,使用“从VideoCapture对象 中抓取下一帧 以及状态 ”指令,从摄像头中捕获图像。
当图像捕获成功后,使用“对象名 将图片 转化为HSV格式”指令,对捕获的图像转化为HSV格式的图像。然后使用“获取图片 的高h 宽w 通道数c”指令,来获取图像的高、宽和通道数。
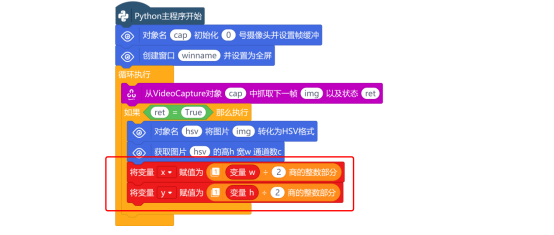
知道图片的高为h,宽为w,怎么才能算出图片的中心点坐标呢?使用“商的整数部分”指令,分别将h除以2,w除以2,并将值赋值给对应的“变量x”、“变量y”。
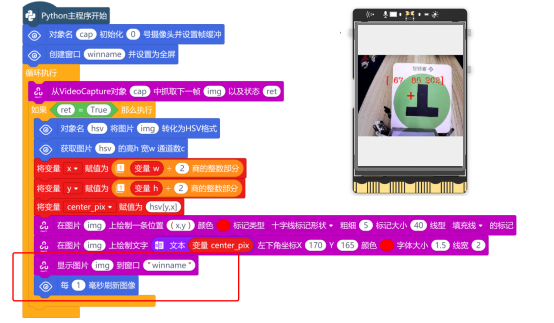
获取中点坐标后,新建“变量center_pix”,并通过“hsv[center_Y, center_X]”方式对坐标进行索引操作,将获取图片中心点的像素值,赋值给“变量center_pix”。

为确保HSV值准确,可通过“在图片上 绘制标记形状 ”指令添加十字标记。为了方便查看,使用“在图片上 绘制文字”指令,将HSV值显示在图片上。

最后,使用“显示图片 到窗口 ”与“每 毫秒刷新图像”指令,将绘制有十字标记形状的图像,显示在行空板上,完整程序如下:
挑战自我
现在我们已经学会了如何获取HSV值,那下面大家修改一下任务三中的程序。根据实际获取的HSV值,修改“对象名 提取图片 的范围内像素 范围下限 范围上限 并进行形态学处理”指令中的范围下限和范围上限值。




 他的勋章
他的勋章


罗罗罗2025.11.17
666