 返回首页
返回首页
 回到顶部
回到顶部

1.项目介绍
1.1项目介绍
本项目旨在开发一款基于视觉目标检测与跟踪的智能小车系统,实现了控制小车实时跟踪对应颜色和特定目标的小球。目标跟踪是一种计算机视觉技术,核心任务是在连续的视频帧中识别并跟随指定的目标物体,该技术广泛应用于自动驾驶、安防监控与智能机器人等领域。系统利用电脑与行空板M10协同工作,将车载摄像头实时采集的视频帧图像通过MQTT协议上传至电脑端进行YOLOv8目标检测,将检测后的结果和对小车的控制指令再次通过MQTT协议传回行空板M10,从而实现对特定颜色目标(例如红球)的实时检测、跟踪同时控制小车进行运动。
1.2项目效果视频
【基于YOLO的行空板跟随小车】(见文末视频)
小车会持续追踪画面中出现的第一个红色小球,并标记一个ID编号,该ID编号会一直跟随该红色小球,当小球从画面中消失再出现的时候,该小球ID编号不变,小车会持续追踪该小球。追踪小球固定ID的过程如文末视频所示。
当红色小球第一次出现在画面中时,ID编号为1,当移除该小球后虽然第二个红色小球ID编号为1,但是当第一个红色小球再次回到画面中时,ID重新赋值为1。
2.项目制作框架
本项目系统采用感知执行层与训练推理层两部分。行空板M10作为感知执行层,负责实时采集车载摄像头画面,并通过MQTT协议将图像数据上传;电脑作为训练推理层,部署YOLOv8模型,对图像进行目标检测与跟踪推理,并将控制指令通过MQTT发送回行空板,实现对小车的精准控制与跟踪。整体架构如图所示。

感知执行层(行空板M10小车)
行空板M10小车由四个核心模块组成:图像采集模块通过摄像头获取视频帧并编码为Base64上传;运动控制模块利用PinPong库驱动电机实现移动功能;GUI模块通过Unihiker界面实时显示检测画面和状态;MQTT通信模块负责车与服务器间的指令、图像和警报数据传输,形成完整的远程监控与控制系统。
训练推理层(电脑)
电脑采用YOLOv8模型实现端到端目标检测与跟踪:服务器接收小车上传的Base64图像后,通过深度学习实时检测红球目标并生成运动指令(前进/转向/停止),同时将标注框叠加的可视化结果和运动指令通过MQTT回传,形成"图像采集-云端推理-指令反馈"的闭环控制流程。
3.软硬件环境准备
3.1 软硬件器材清单

注意行空板M10固件在0.3.5——0.4.0的版本均可以用于制作本项目。
3.2 软件环境准备
由于我们使用电脑训练小球检测模型,因此需要在电脑端安装相应的库。
首先按下win+R,输入cmd进入窗口。
在命令行窗口中依次输入以下指令,安装ultralytics库
pip install ultralytics
pip install onnx==1.16.1
pip install onnxruntime==1.17.1
输入之后会出现以下页面。
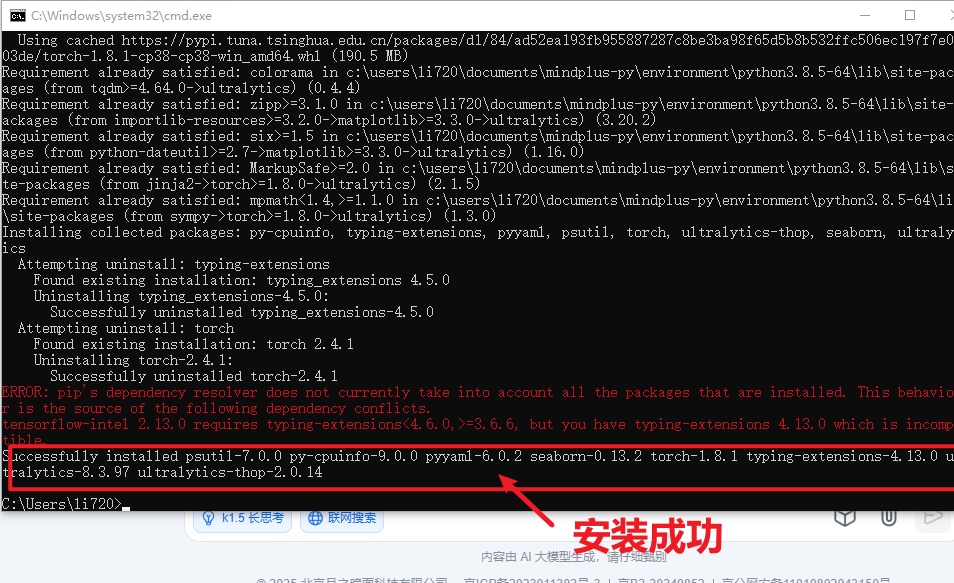
当命令运行完成,出现以下截图表示安装成功。
3.3 硬件环境准备
行空板无人驾驶小车安装教程.pdf(见附件)
按照安装教程将行空板无人驾驶小车组装好之后,先使用USB数据线连接行空板与电脑,等待行空板屏幕亮起表示行空板开机成功

将电脑接入无线网络(需使用 2.4G Wi-Fi)后,在浏览器输入"10.1.2.3"后打开进入网页
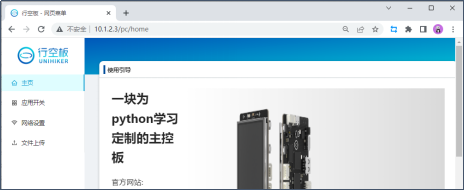
接下来,点击“网络设置”,寻找“连接 WiFi”,点击“扫描”寻找电脑连接的无线网,点选 WiFi 名称并输入密码,点击“连接”,等待连接成功。连接成功后,网页菜单会显示行空板的IP地址。
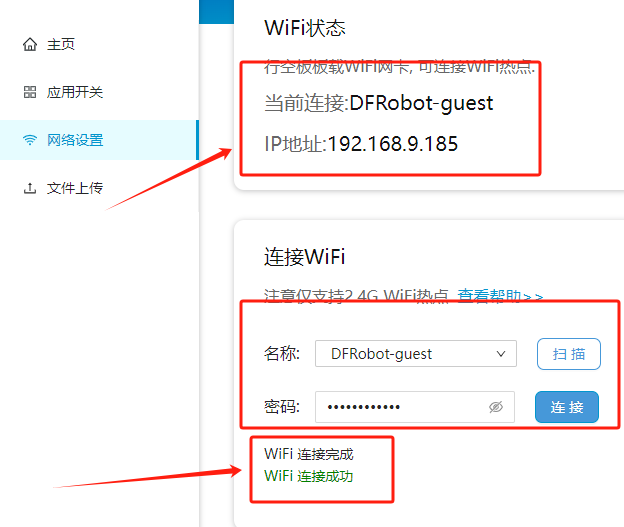
将数据线从行空板上拔下后将无人驾驶小车主控板的连接线接到行空板的type-c接口上,同时开启扩展板的电源键。

在行空板开机后等待一会,长按行空板Home键进入菜单,选择“查看网络信息”选项。
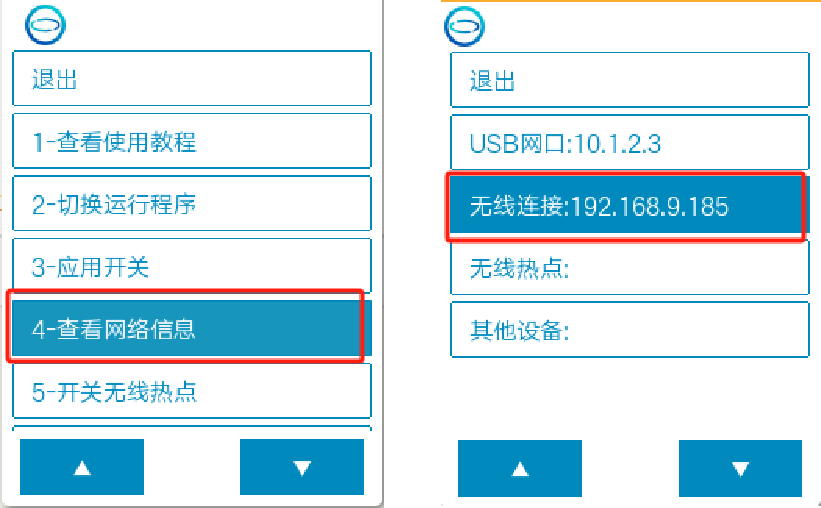
电脑打开浏览器输入查看到的IP地址(192.168.9.185)后打开进入网页,点击"应用开关",选择"SIoT v2"后打开页面。
分别创建创建3个Topic
car/raw_video:用于接收行空板摄像头上传的实时视频帧数据
car/control:用于接收对小车发布的控制指令(forward、left、right、stop)
car/processed_video:用于接收经过电脑端YOLOv8推理后的结果帧
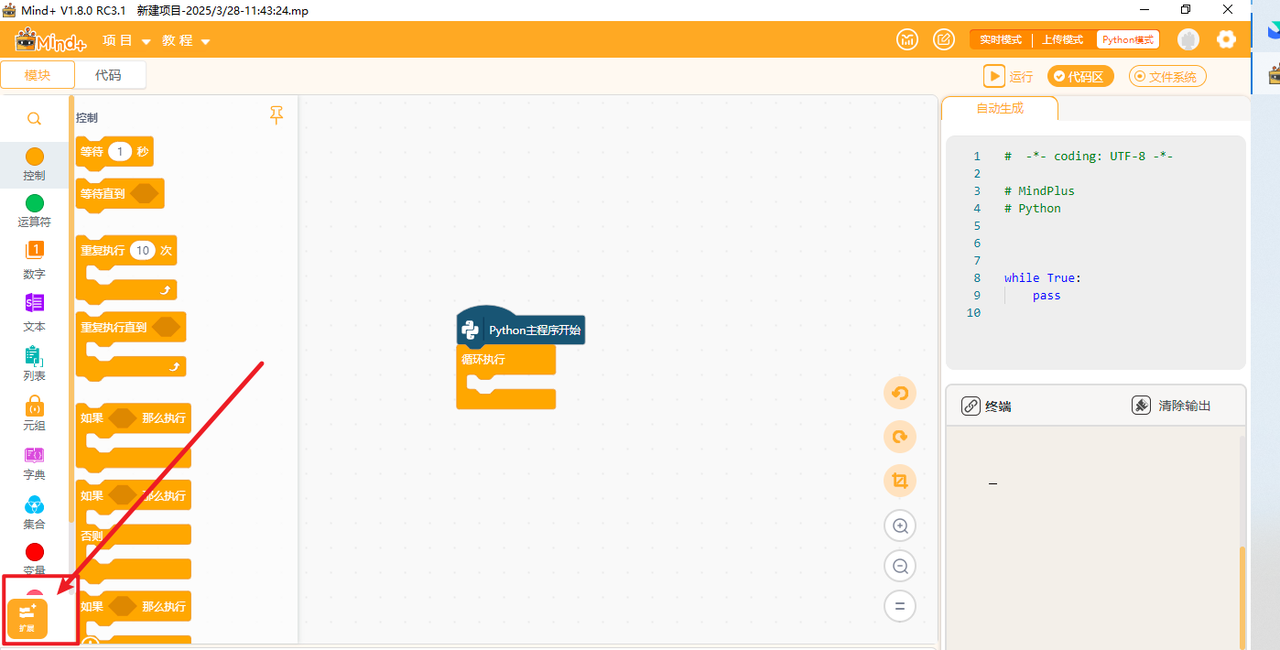
打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载
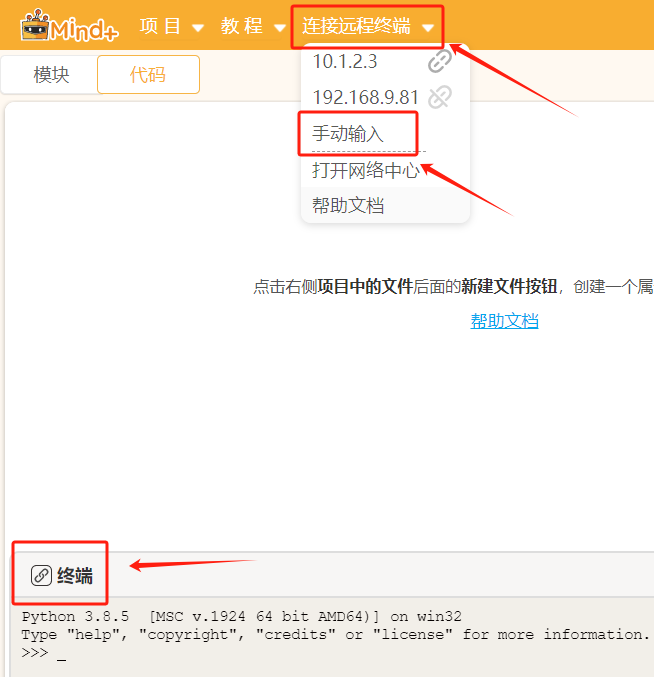
点击返回,点击终端,点击连接远程终端,选择手动输入,输入刚才查看的行空板IP地址192.168.9.185,点击连接,等待连接成功。
4.制作步骤
4.1数据集准备
为了训练目标检测模型,我们需要准备YOLO格式的数据集。一个标准的目标检测数据集包括训练集和验证集,每个都包含图像和标注文件(txt文件)。标注文件能提供目标的位置和类别信息。
以小球检测的数据集为例为例,标准的用于目标检测的数据集的格式如下。
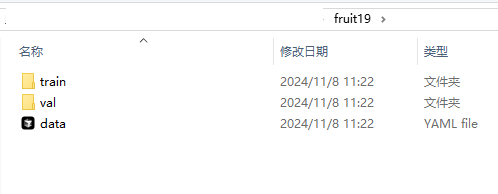
我们使用的数据集是自己拍和标注的包含五个种类(red、powder、purple、blue、white)的小球数据集,共有65张图片,其中训练集62张,验证集3张(数据集在文章末尾处)。考虑时间等各种成本因素,数据集图片数量较少,读者可以自己拍摄图片然后进行标注训练。
dataset/ //数据集
│
├── train/ // 训练集,使用训练集的数据进行模型训练
│ ├── images/ // 训练集的图片文件夹
│ └── labels/ // 训练集中图片的标注信息文件夹,作用是提供图像中目标的位置和类别信息。
│
├── val/ // 验证集,验证集用于评估模型在未见过的数据上的表现
│ ├── images/ // 验证集的图片文件夹
│ └── labels/ // 验证集图片的标注信息文件夹
│
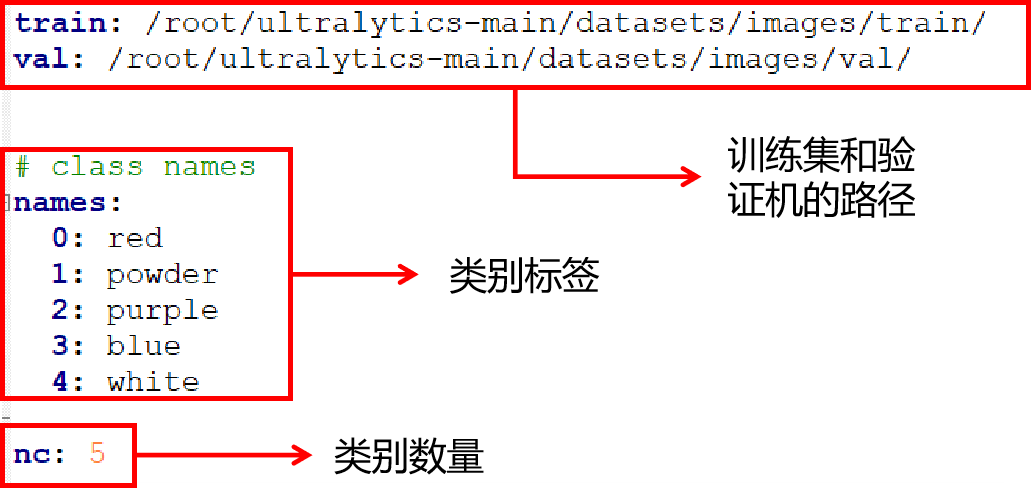
└── data.yaml // 数据集配置文件,用于定义数据集的参数,通常是一个 YAML 文件。其中YAML文件一个对于目标检测模型训练很重要的文件。YAML 文件通常包含数据集的路径信息,这些路径告诉模型训练脚本在哪里找到训练集和验证集的图像和标注文件。除此之外,YAML 文件定义了类别索引与类别名称之间的映射关系。这对于模型在训练和推理过程中正确识别和分类目标至关重要。如下图所示。
准备好数据集后,接下来我们就可以进入模型的训练环节了。
4.2模型训练
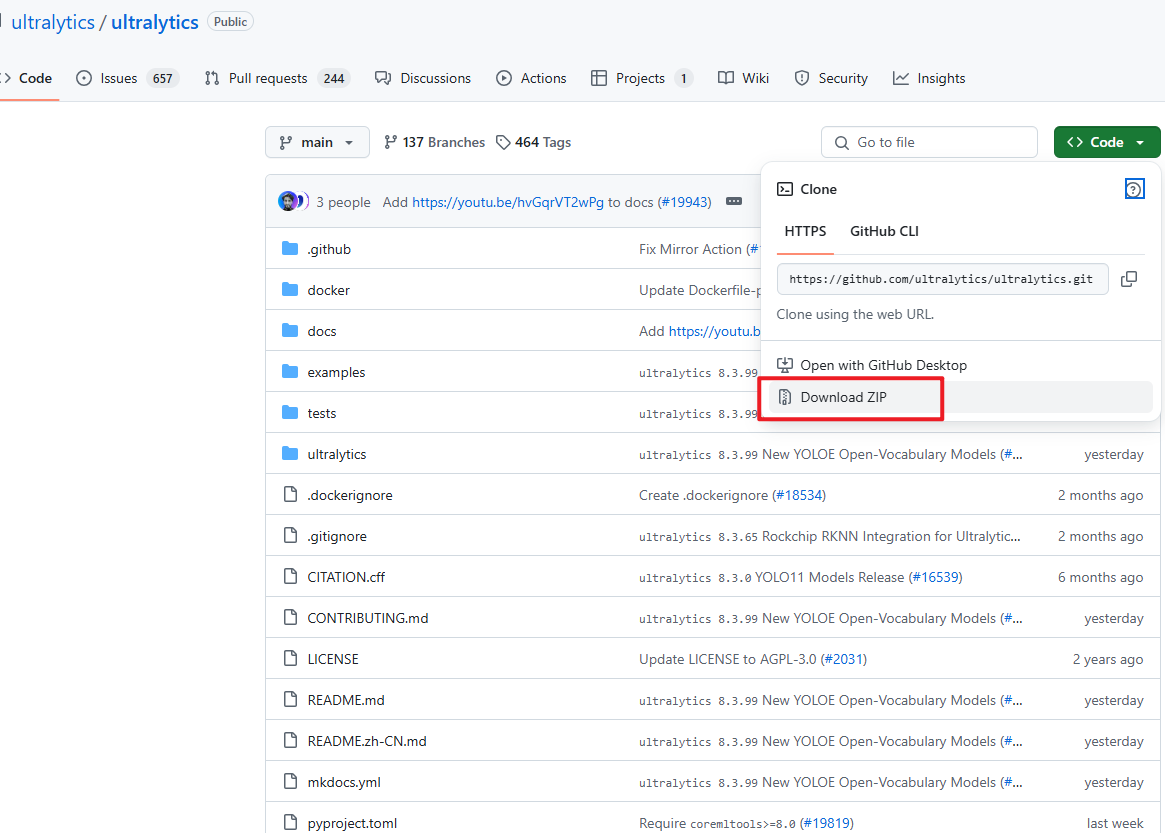
我们首先要去ultralytics的官方仓库下载YOLO项目文件。链接:https://github.com/ultralytics/ultralytics。如下图,将官方文件夹下载下来,并解压(文件夹已附在在本篇文档的最后)。
将文件放到一个能找到的路径,打开Mind+,选择Python模式下的代码模式,如下图。
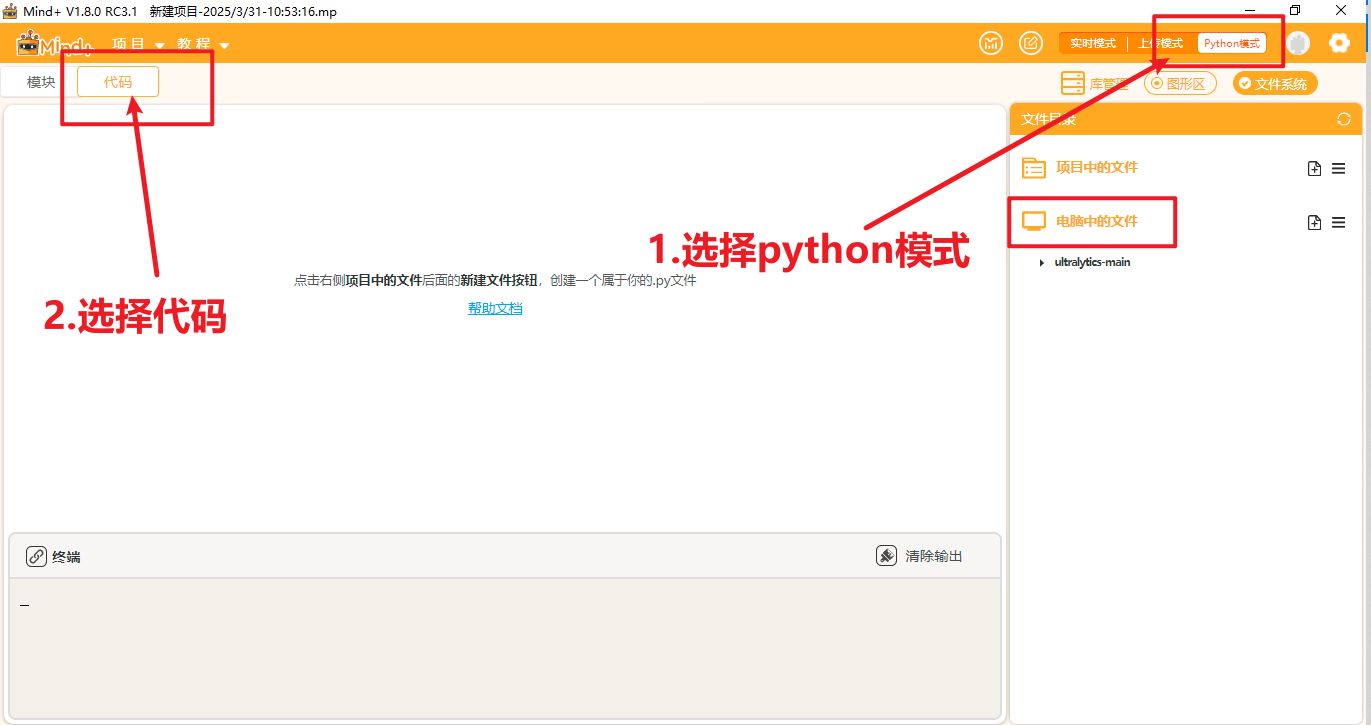
在右侧“文件系统”中找到"电脑中的文件",找到此文件夹进行添加。
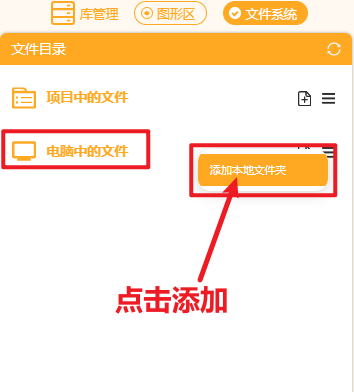
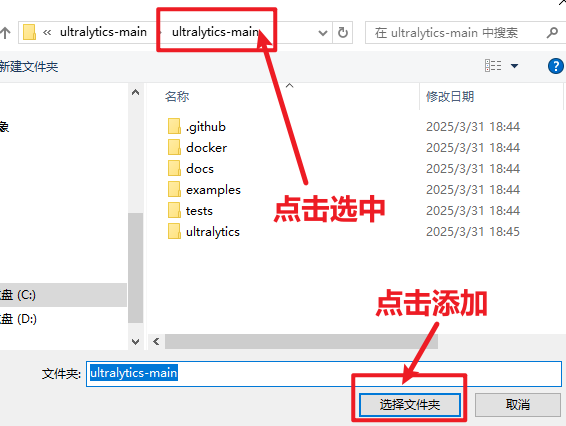
添加好后可以观察到如此下图。
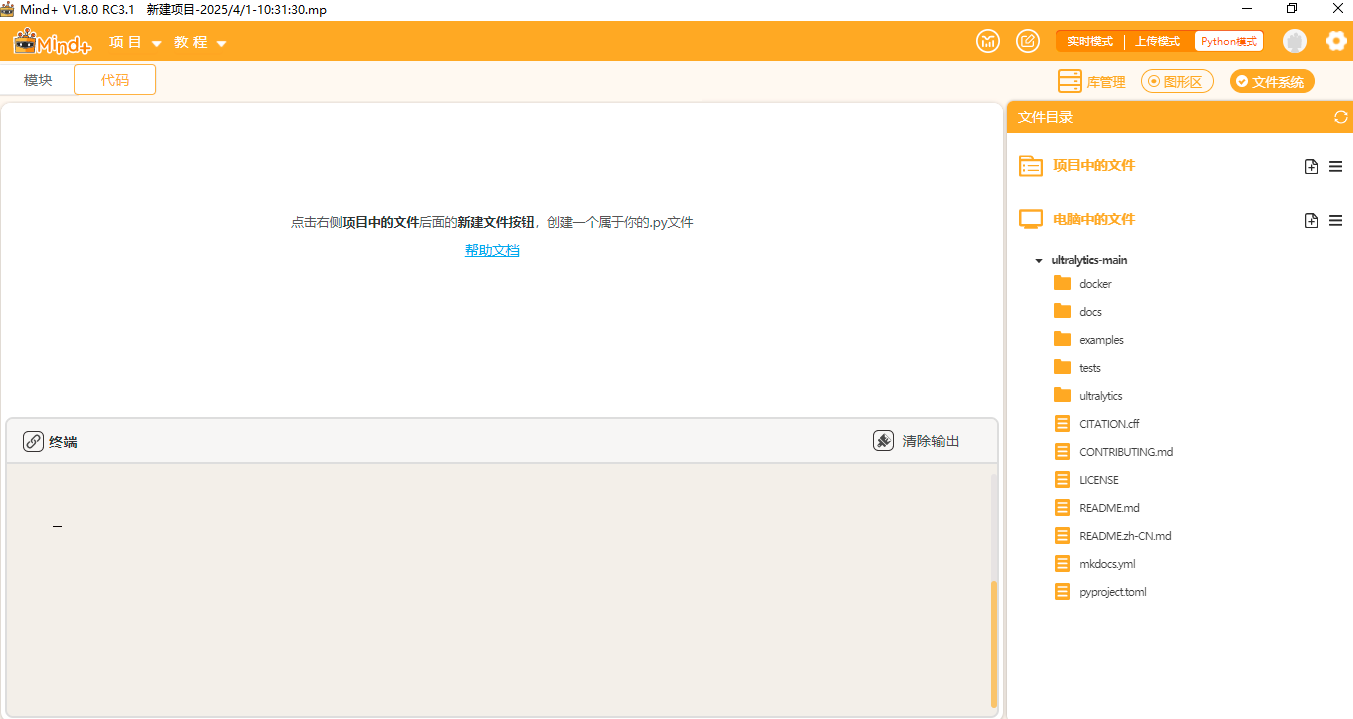
点击"新建文件夹",在ultralytics文件夹中分别新建三个文件夹,依次命名为"datasets"(用于存放数据集),"yamls"(用于存放数据集对应的yaml文件)"runs"(用于存放训练模型的py文件)。
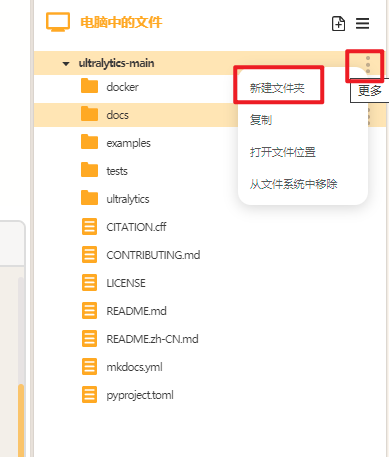
建好后如下图。
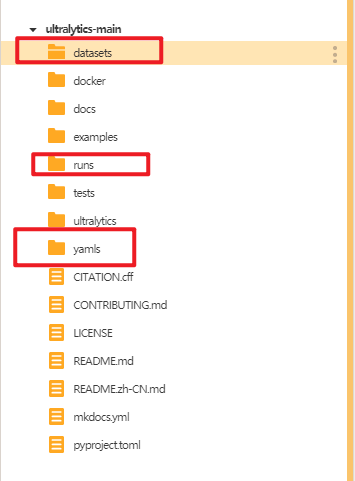
将水果数据集的训练集和验证集文件夹放入"dataset"文件夹,将水果数据集的yaml文件放入"yamls"文件夹。
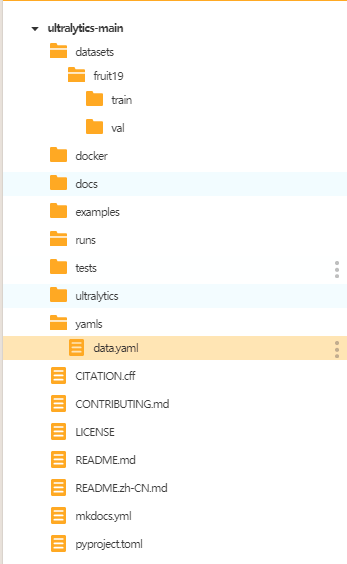
接着我们在"runs"文件夹中建立一个叫做"train.py"的文件,在此文件中编写训练YOLO模型的代码。
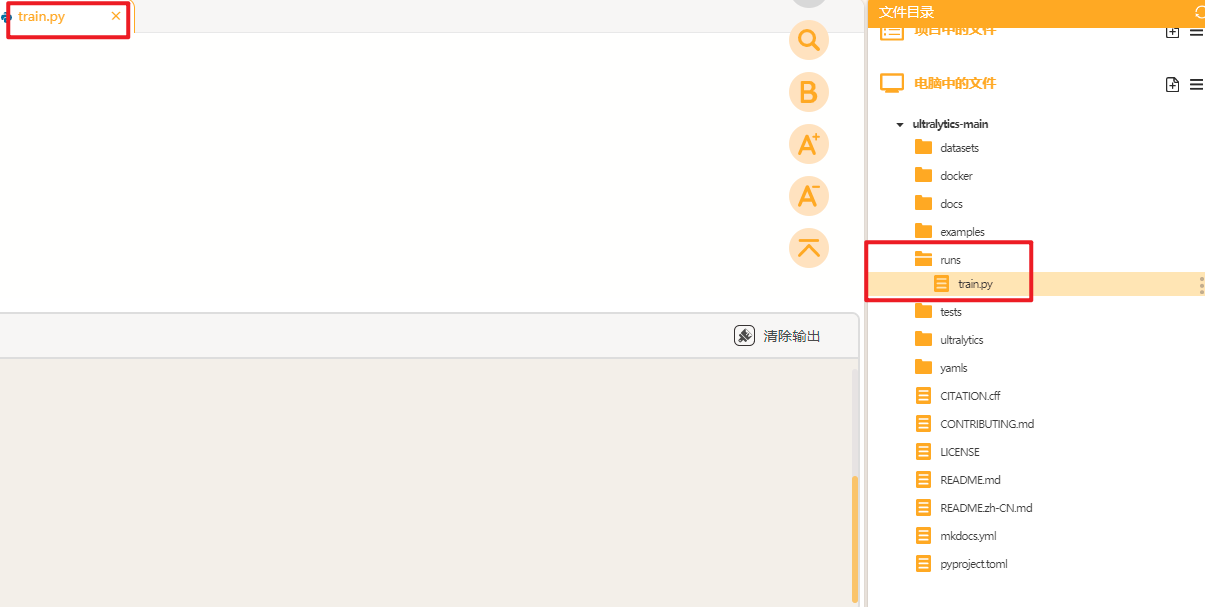
将训练代码粘贴到train.py中点击运行。我们在预训练模型"yolov8s"基础上进行水果目标检测模型的训练,设置训练轮次是2轮,如果电脑有GPU,可以相应的设置多一些轮次以获得更好的检测效果。图片的尺寸是640(640×640)或320(320×320),这里使用的是320。
from ultralytics import YOLO # 导入YOLO类,用于加载和训练模型
import time # 导入time模块,用于延迟操作
import os # 导入os模块,用于操作文件路径
# 打印当前工作目录,帮助确认代码运行的路径是否正确
#print("Current working directory:", os.getcwd())
# 确保路径正确
model = YOLO('yolov8n.pt') # 加载YOLOv8s预训练模型,yolov8s.pt是一个轻量级模型,适合资源有限的环境
# 开始训练模型
results = model.train(
data=os.path.join(os.getcwd(), '..', 'yamls', 'data.yaml'), # 数据配置文件路径
# 使用相对路径,确保指向正确的yamls文件夹,data.yaml 文件中定义了数据集的路径、类别数等信息
epochs=2, # 设置训练轮数为2
imgsz=320, # 设置输入图像大小为320x320,降低图像大小可以减少显存占用,适合资源有限的环境
device='cpu', # 使用CPU进行训练(如果无GPU或CUDA环境)
# 如果有GPU,可以设置为 '0' 或 'cuda'
workers=0, # 数据加载线程数(Windows系统建议设置为0)
# workers=0 表示主进程加载数据,避免多线程问题
batch=2, # 设置批量大小为2,降低批量大小可以减少显存占用,但可能影响训练效率
cache=False # 不使用缓存(避免内存占用过多)
)运行时可观察终端,自动下载预训练模型"yolov8n.pt",进行模型的训练。
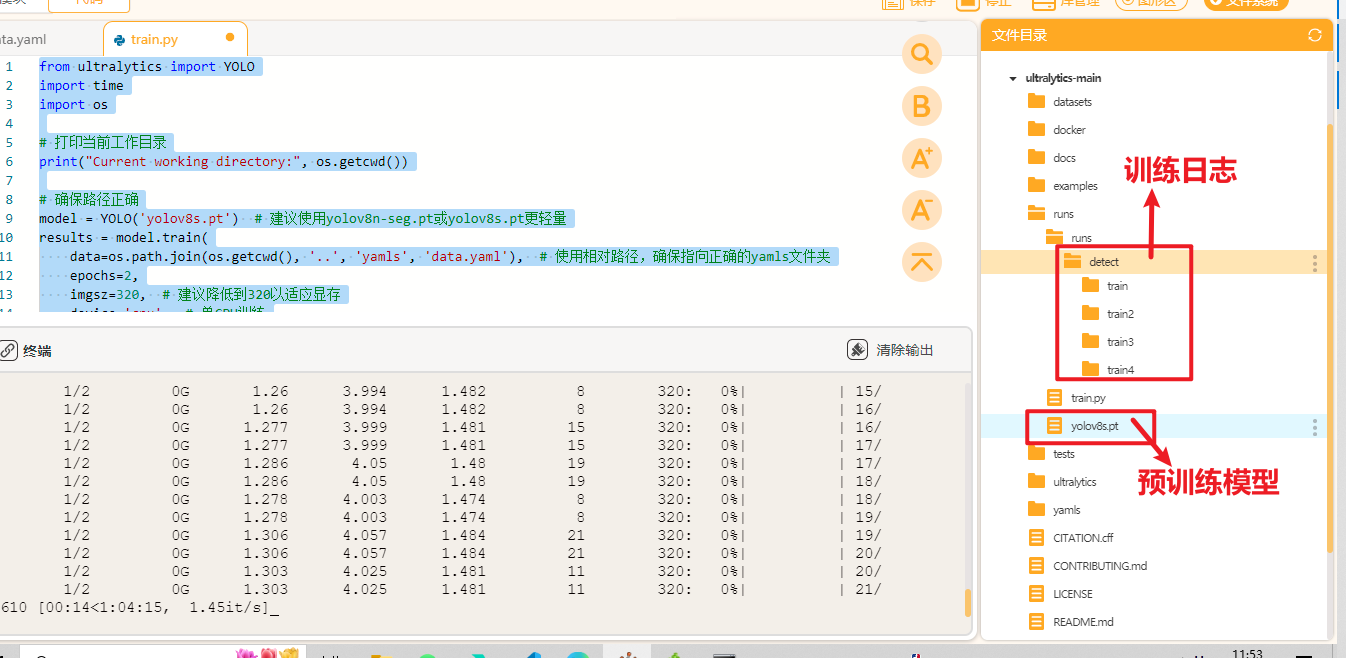
YOLO模型的训练对电脑的配置要求比较高,使用电脑CPU一般训练时间较长,可以考虑使用GPU或者云端算力进行训练,这里我们使用的时本地电脑的CPU训练方法,操作比较简单,耗时略长。
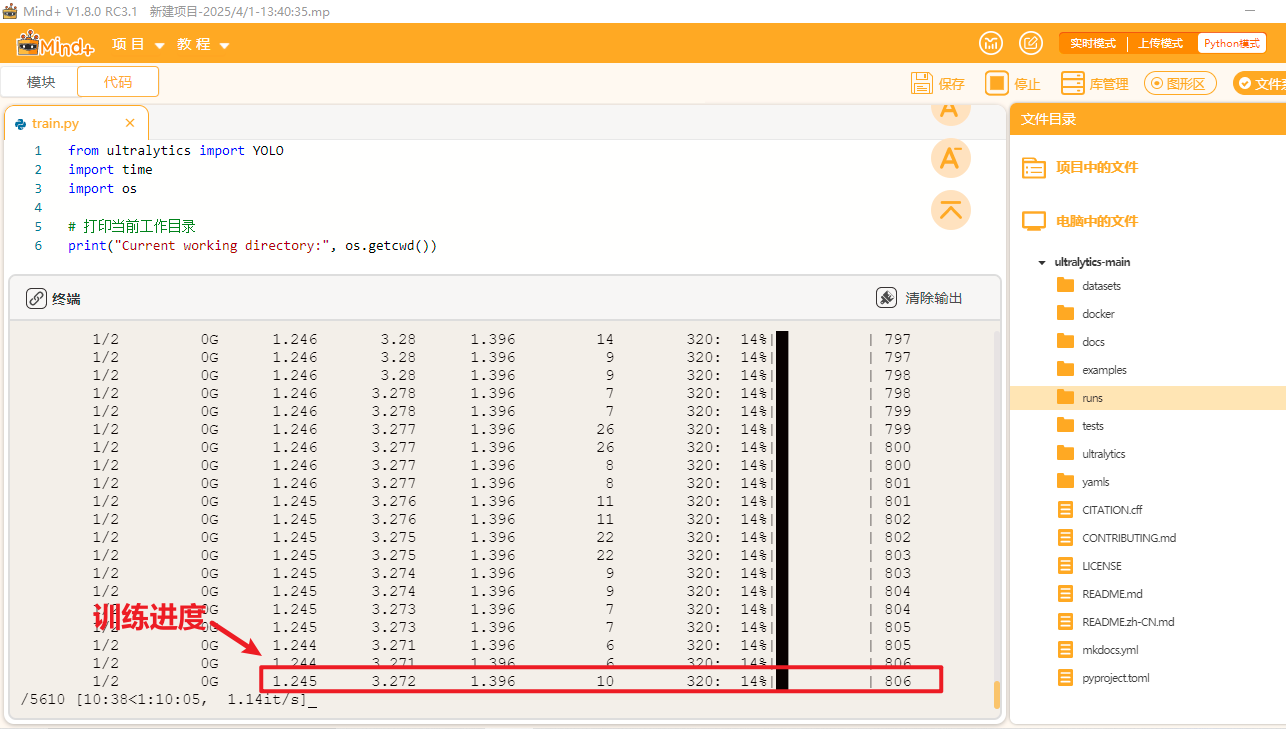
当训练完成后,我们可以观察"runs"文件夹中自动生成了"detect"文件夹(代表了目标检测任务),里面存放了训练模型的数据和训练好的模型文件。
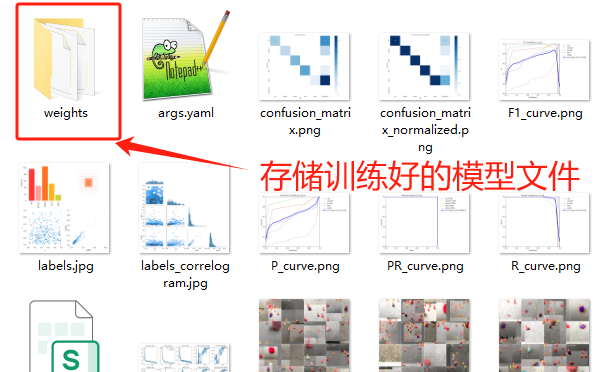
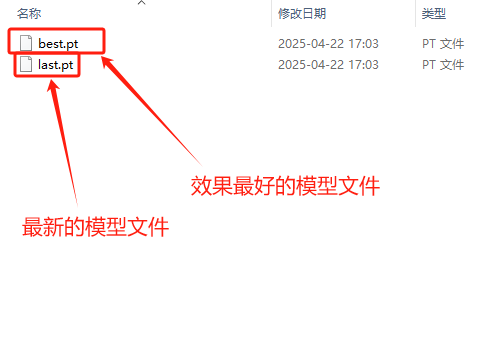
4.3 模型转换
我们训练得到的"best.pt"可以直接用于推理,我们也可以将"best.pt"转成onnx格式的模型文件。ONNX 格式,也是一种模型文件的格式,更加通用,可以与各种推理引擎兼容,提供更高效的推理速度
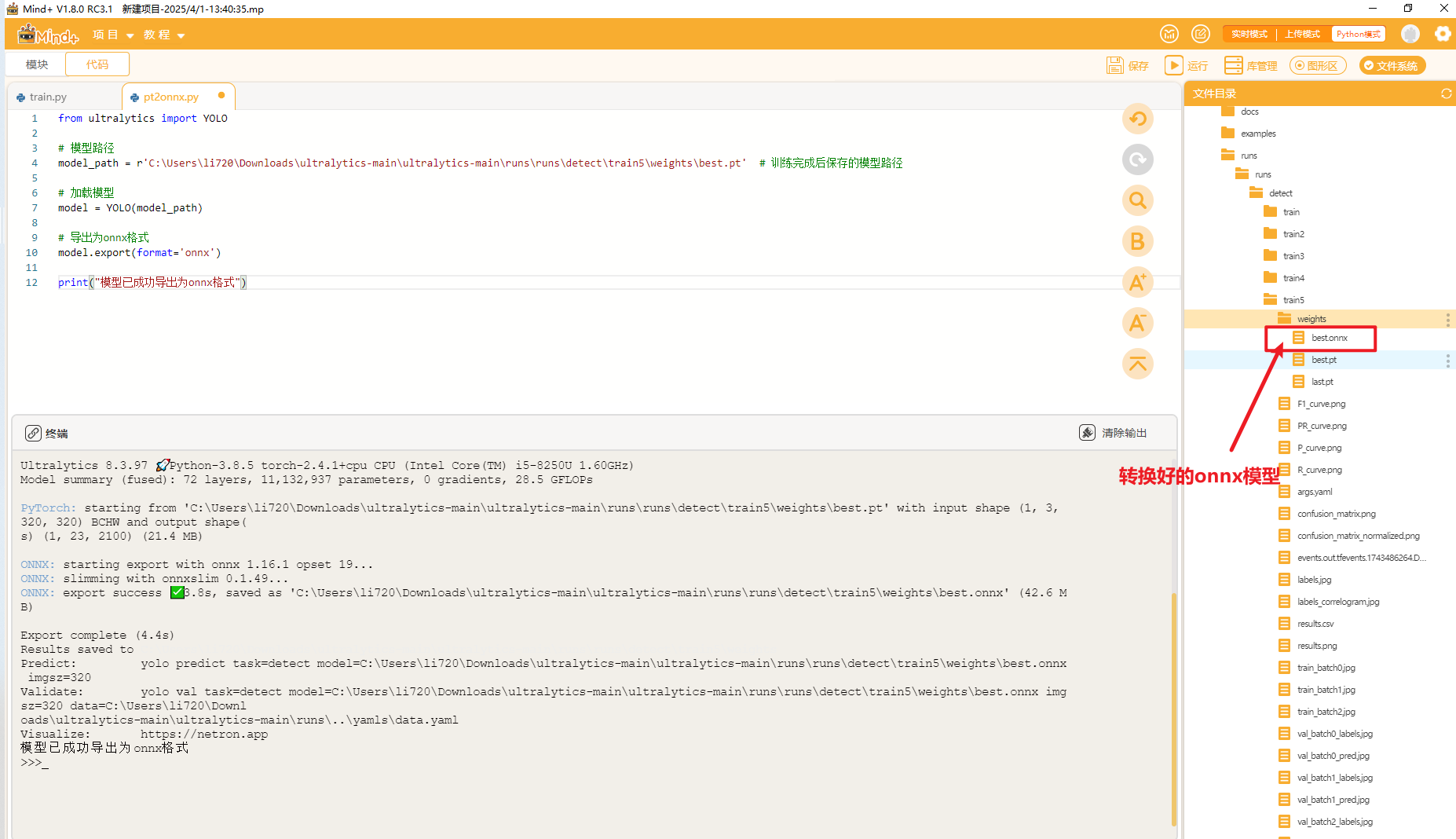
使用以下代码将pt格式的模型文件转成onnx格式的模型文件。
from ultralytics import YOLO
# 模型路径,这里填你的pt文件的实际路径
model_path = r'C:\Users\li720\Downloads\ultralytics-main\ultralytics-main\runs\runs\detect\train5\weights\best.pt' # 训练完成后保存的模型路径
# 加载模型
model = YOLO(model_path)
# 导出为onnx格式
model.export(format='onnx', imgsz=160, opset=12, dynamic=False)
print("模型已成功导出为onnx格式")通过修改"model.export(format='onnx', imgsz=160, opset=12, dynamic=False)"中imgsz参数可以修改转换模型所检测图像的大小,图片越小,速度越快,准确性越底;图片越大,速度越慢,准确性越高,具体测试结果如下表格总结所示:
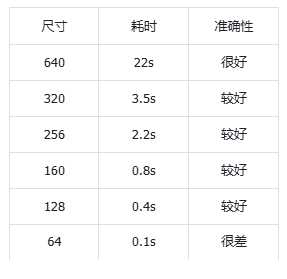
经过测试,使用160×160尺寸的图片效果最好,速度够快,也不会存在漏检、误检的情况。
注:性能为本数据集和模型的测试结果,如果您训练自己的数据集可以需要更多的测试。
转换好后,可以在同一目录下找到转换好的onnx模型。
4.4模型测评与导出
我们先在电脑端测试一下模型的性能,将训练好的模型拖入Mind+项目中的文件下
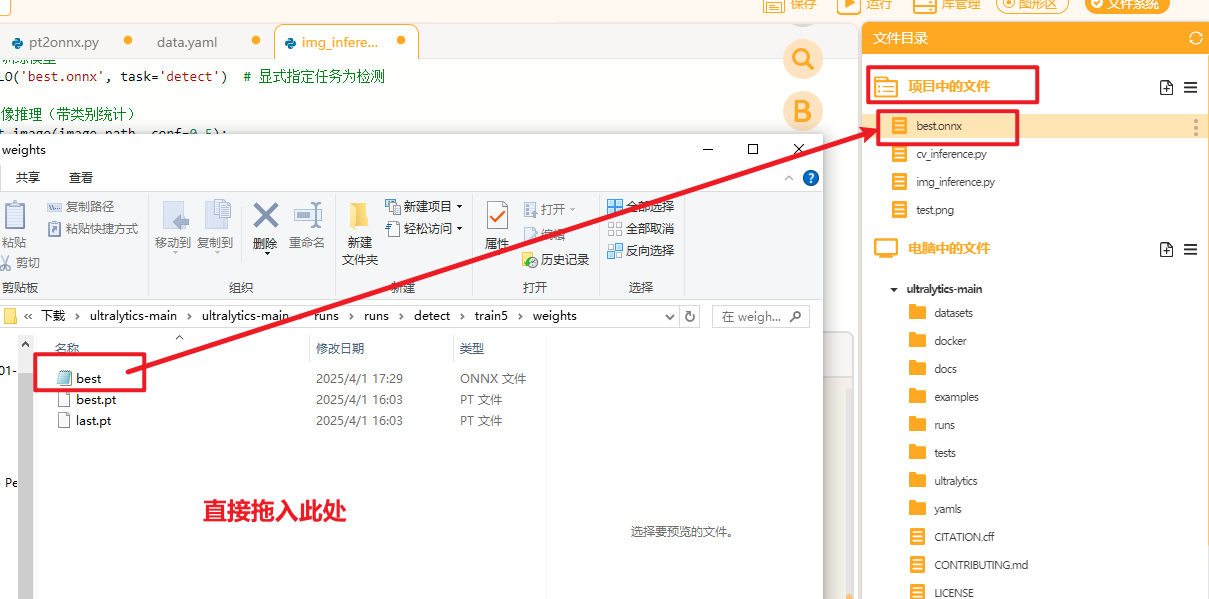
再在项目中的文件中新建一个叫做"img_inference.py"(用来测试图片推理效果),同时将测试图片"test.png"也拖入项目中的文件夹下。测试图片如下图所示

将以下代码复制到"img_inference.py"文件中进行图片推理测试。
from ultralytics import YOLO # 导入Ultralytics库中的YOLO类,用于目标检测与跟踪
import cv2 # 导入OpenCV库,用于图像读取与显示
# 1. 加载预训练模型
model = YOLO('best_ball_160.onnx') # 加载训练好的ONNX格式的YOLO模型,用于检测红球等目标
# 2. 定义图像推理与跟踪函数
def track_image(image_path, conf=0.5):
# 读取图像并调整尺寸
img = cv2.imread(image_path) # 使用OpenCV读取图像
img = cv2.resize(img, (320, 320)) # 将图像缩放到320x320大小,提升推理速度
# 执行推理(带跟踪功能)
results = model.track(
source=img, # 输入图像
conf=conf, # 设置置信度阈值
save=False, # 不保存可视化结果图像
imgsz=160 # 设置模型输入图像大小为160x160(与onnx转换时的imgsz参数一致)
)
# 初始化类别计数器,用于统计各类目标数量
class_counts = {}
# 遍历每个推理结果(results 是列表形式)
for result in results:
# 获取检测框中每个目标的类别ID列表
detected_classes = result.boxes.cls.tolist()
# 遍历每个目标类别,统计数量
for class_id in detected_classes:
class_name = result.names[int(class_id)] # 获取类别名称
class_counts[class_name] = class_counts.get(class_name, 0) + 1 # 统计数量
# 将检测结果(含ID、框、标签)绘制在原图上
annotated_img = results[0].plot()
# 显示可视化后的图像窗口
cv2.imshow('Track', annotated_img) # 显示检测结果
cv2.waitKey(0) # 等待按键关闭窗口
cv2.destroyAllWindows() # 关闭所有窗口
return results, class_counts # 返回检测结果和统计数据
# 主程序入口
if __name__ == '__main__':
try:
# 指定测试图像路径
image = r"D:\dfrobot\调研项目\行空板小车跟踪\1.jpg"
# 调用推理函数,获取检测结果与统计数据
image_results, counts = track_image(image, conf=0.4)
# 打印目标数量统计信息
print("\n检测结果统计:")
for class_name, count in counts.items():
print(f"{class_name}: {count}个") # 输出每类目标数量
# 打印详细检测信息(包括类别、置信度和唯一ID)
print("\n详细检测信息:")
for result in image_results:
for box in result.boxes:
print(f"类别: {result.names[int(box.cls)]}, " # 类别名称
f"置信度: {box.conf.item():.2f}, " # 检测置信度
f"ID:{int(box.id)}") # 跟踪ID,唯一标识每个目标
except Exception as e:
print(f"发生错误: {str(e)}") # 异常处理,输出错误信息
点击Mind+右上角的”运行",运行代码观察效果。
当程序运行时,可以观察到弹出以下窗口,显示在测试图片上的推理结果。

观察图片可以看到,模型成功识别并跟踪了图中的四个小球。每个小球都被分配了一个唯一的ID编号,便于在连续帧中进行目标跟踪。这种唯一ID的分配机制,使得模型能够在视频的连续帧中持续追踪每一个小球的位置变化,即使多个小球同时出现在画面中也不会混淆,配合显示的置信度信息,可以直观地反映出模型识别的准确性与稳定性,整体效果较为理想。
关闭弹出窗口后观察终端的输出,可以看到终端出现了检测到的小球类别的统计信息。
检测结果统计:
purple: 1个
red: 1个
blue: 1个
powder: 1个
详细检测信息:
类别: purple, 置信度: 0.94, ID:1
类别: red, 置信度: 0.92, ID:2
类别: blue, 置信度: 0.83, ID:3
类别: powder, 置信度: 0.81, ID:44.5 行空板与电脑端的视频传输
摄像头采集到的视频通过抽帧转换为连续图像,再使用 Base64 编码以文本形式发布到 MQTT 主题上,电脑端接收后解码并进行 YOLOv8 目标跟踪,标出检测框、ID 和置信度,再将带有标注的图像通过 Base64 编码发布,最终小车端解码并在显示屏上展示连续帧,实现模拟视频的效果。
Base64 是一种将二进制数据编码为 ASCII 文本格式的方式,它通过将输入数据每 3 字节(24 位)划分成 4 组 6 位数字,再映射到 64 个可打印字符(包括 A–Z、a–z、0–9、“+”、“/”)上,从而保证编码后内容仅包含文本字符,便于在文本协议(如 HTTP、MQTT、电子邮件等)中传输数据。
1.当输入数据长度不足 3 的倍数时,使用“=”进行填充。
2.编码后数据体积会增加约 33%,但提高了传输兼容性与安全性。
Base64编码核心代码:
︎
_, buf = cv2.imencode('.jpg', frame)
b64 = base64.b64encode(buf).decode()
siot.publish_save(topic=RAW_TOPIC, data=f"data:image/jpeg;base64,{b64}")该流程首先使用 cv2.imencode() 将 OpenCV 图像对象压缩为 JPEG 格式的字节流,再通过 base64.b64encode() 将其转换为 Base64 字符串并解码为 UTF-8 格式;随后添加 data:image/jpeg;base64, 的 MIME 协议头以标识数据类型,最终通过 MQTT 的 siot.publish_save() 将封装后的图像数据发布至指定主题,实现图像的高效编码、标准化封装及网络传输,便于订阅端直接解析和处理。
Base64解码核心代码:
def on_raw_callback(client, userdata, msg):
data = msg.payload.decode()
if "base64," not in data:
return
b64 = data.split("base64,")[-1]
arr = np.frombuffer(base64.b64decode(b64), np.uint8)
frame = cv2.imdecode(arr, cv2.IMREAD_COLOR)
print("[接收] 收到原始帧")该流程首先将接收到的图像字节流通过decode() 转换为字符串,并通过检查 "base64,"标记验证格式有效性后,提取其后部分作为 Base64 编码数据;随后使用 base64.b64decode() 解码为二进制数据,通过 NumPy 的 frombuffer() 转为 uint8 类型数组,最终由 OpenCV 的 imdecode() 重构为 BGR 格式的彩色图像,并在成功后输出 "[接收] 收到原始帧" 作为状态反馈,完成从数据传输到图像重建的全流程处理。
4.6 电脑端和行空板协同操作
将数据集训练的小球放在行空板小车前50厘米的距离,将行空板小车摄像头对准小球。在电脑上打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载
点击返回,点击终端,点击连接远程终端,选择手动输入,输入刚才查看的行空板小车的IP地址192.168.9.185,点击连接,等待连接成功。
出现下面标识标识连接成功。
选择"car_vc.py"(见附件见网盘)后点击运行,该程序是运行在行空板小车端,实现行空板小车的视频采集、图像传输、实时显示及运动控制的整体运行。
接着打开一个新的Mind+程序,该程序不进行任何终端连接操作,直接运行"yolo.py",观察小车的运行情况。
4.7 核心代码解析
感知执行层:
下面我们一起来看一下在行空板上运行的'car_cv.py'核心功能代码。此程序主要分为三部分:
(1)硬件与通信初始化:初始化电机、LED、蜂鸣器、GUI组件,配置MQTT连接等。

(2)基础控制逻辑与消息处理:定义电机控制逻辑、接收MQTT指令与图像数据、摄像头采集与上传。
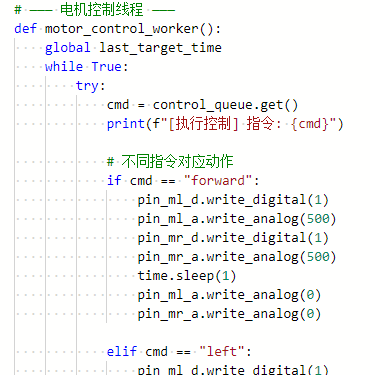
通过不断从队列中获取从MQTT接收到的控制指令来驱动小车进行运动,它支持五种指令:"forward"让两个电机同向转动使机器人前进;"left"和"right"通过控制左右电机不同转向和速度实现转向,先低速反向旋转2秒再中速调整0.2秒;"stop"直接停止所有电机,通过全局变量维护小车的运动状态。

定义MQTT消息回调函数on_message_callback,用于处理接收到的消息:当收到控制主题的指令后将指令放入控制队列(队列满时先清空);当收到图像处理主题(PROC_TOPIC=car/processed_video)的Base64编码图像数据时,会解码并调整图像尺寸为240×320,然后放入GUI帧队列供界面显示。两种消息处理都包含队列满时的安全处理机制,确保新消息能够及时处理而不阻塞。
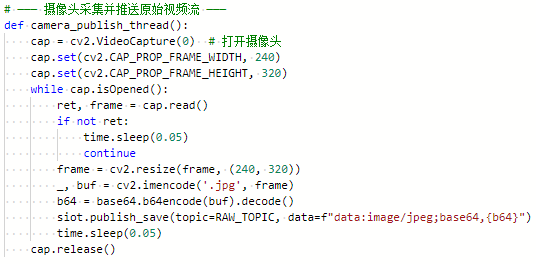
首先初始化摄像头并设置分辨率为240×320,然后在一个循环中持续捕获视频帧,将每帧图像调整为指定大小后转换为JPEG格式并进行Base64编码,最后通过MQTT协议发布到对应(RAW_TOPIC=car/raw_video)主题,发布间隔为0.05秒以确保流畅的视频传输,当摄像头关闭时自动释放资源。
(3)GUI图像显示优化。
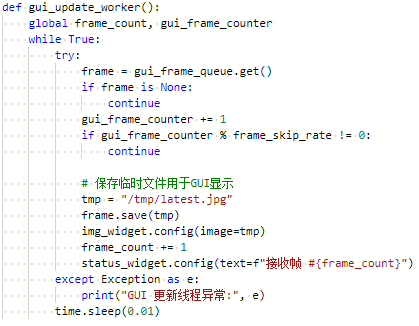
这段代码通过控制跳帧节奏实现流畅的画面更新。它会从动态接收的图像队列中按设定频率(如每3帧显示1帧)筛选关键画面,将选中的图像转为临时快照文件,主画面显示最新图像,状态栏同步更新已显示的帧数统计,从而在保证系统流畅运行的前提下实现视觉信息的有效传递。
训练推理层:
下面我们在一起来看一下在电脑上运行的'yolo.py'核心功能代码。此程序的三部分分别为:
(1)初始化模型、参数与摄像头/MQTT连接:加载YOLOv8模型,设置图像尺寸、控制参数,并初始化MQTT服务器连接,准备接收摄像头推流数据;
results = model.track(
frame,
imgsz=160, # 推理输入缩放到160x160,加速
conf=0.4, # 检测置信度阈值
iou=0.5, # IOU阈值
tracker="bytetrack.yaml", # 指定追踪器配置文件
stream=False
)
boxes = results[0].boxes # 检测到的所有目标框
annotated = results[0].plot() # 绘制检测结果到图像上在使用YOLOv8时,目标检测(model.predict())和目标跟踪(model.track())的关键区别在于:跟踪会为每一个检测到的目标分配并维持唯一的ID,可通过boxes.id进行获取。
要实现跟踪功能,需要指定追踪器配置文件,这里YOLO给了我们一个默认的配置文件bytetrack.yaml (见附件),该文件的所在位置为
ultralytics\ultralytics\cfg\trackers\bytetrack.yaml,它通过 高低置信度阈值 筛选检测框(减少漏检)、设置 匹配阈值 关联轨迹、限制最小检测框尺寸(抗噪声),并用缓冲区处理短暂遮挡,确保目标即使短暂消失也能恢复原有 ID,从而提升跟踪的连续性和准确性。

我们可以使用一个测试程序来打印推理后的结果。model()是YOLO模型的推理函数,conf=0.5设置置信度阈值为0.5,只有置信度大于或等于这个阈值的检测结果才会被保留,这个值可以根据实际需要进行修改。results存储了模型推理的输出结果。可以使用print语句将results打印出来。
# 使用YOLO模型进行目标检测
results = model(rgb_frame, imgsz=320, verbose=False, conf=0.5) # 对RGB图像进行推理,指定输入图像尺寸为320x320,并设置置信度阈值0.2才输出
print('模型的原始输出:',results)如下图,是该程序打印的模型推理的原始结果。

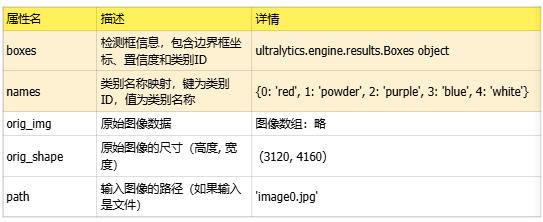
这里,以表格的形式整理了模型原始输出的全部内容,如下。我们可以观察到原始的推理输出有比较多的内容,在项目的人制作中不是每一个输出数据都要用到,其中最常被用的数据是"boxes"和"names"。boxes: 包含检测框的详细信息,包括边界框坐标、置信度和类别ID。这是最常被使用的数据。names: 提供类别ID到类别名称的映射,用于将检测结果转换为人类可读的类别名称。
(2)电脑端利用YOLO持续检测小球位置并通过MQTT发送“forward/left/right/stop”指令,行空板端在后台线程解读接收到的MQTT指令,并驱动左右电机实时调整方向和速度,同时刷新GUI画面;

上述代码是实现红球检测和目标跟踪的核心逻辑:
1.数据过滤阶段:通过筛选检测结果中的类别信息(cls=0表示红球),生成有效目标索引列表valid_indices。若无类别信息则默认全部有效,确保系统兼容性。
2.目标锁定阶段:当无锁定目标时,优先使用检测框ID(boxes.id)锁定第一个红球,若无ID则改用索引位置锁定,确保在各种情况下都能建立目标跟踪关系。整个过程通过详细的日志输出实时反映系统状态变化。

上述代码主要功能是根据检测框位置判断机器人运动方向:当目标ID存在时,计算目标框的中心位置和宽度比例,若目标过近(超过STOP_RATIO阈值)则停止,否则根据中心点相对左右阈值(left_thresh/right_thresh)决定左转、右转或前进;若目标丢失则停止。
(3)结果后处理与扩展功能:抑制指令冗余、发布处理后图像,检测日志记录等扩展功能,可以根据项目需求灵活修改。

这段代码有三个核心功能:
1) 判断发布的控制指令是否重复,如果发布控制指令与上次相同,则跳过该操作,避免小车重复接收到相同的控制指令;
2) 将标注后的图像(annotated)编码为JPEG格式并转换为Base64字符串,通过MQTT发布到PROC_TOPIC主题;
3) 记录每帧的推理日志(包含时间戳、控制指令、目标ID和检测框数量)到result.json文件。
5.项目相关资料汇总(见网盘链接)
本项目资源链接:https://pan.baidu.com/s/1VuAyOONdz-NYtYvcszH6Bg?pwd=wtqt



 他的勋章
他的勋章

罗罗罗2025.11.17
666
hnyzcj2025.06.10
赞