 返回首页
返回首页
 回到顶部
回到顶部
一、项目的构想
1.讯飞语音合成
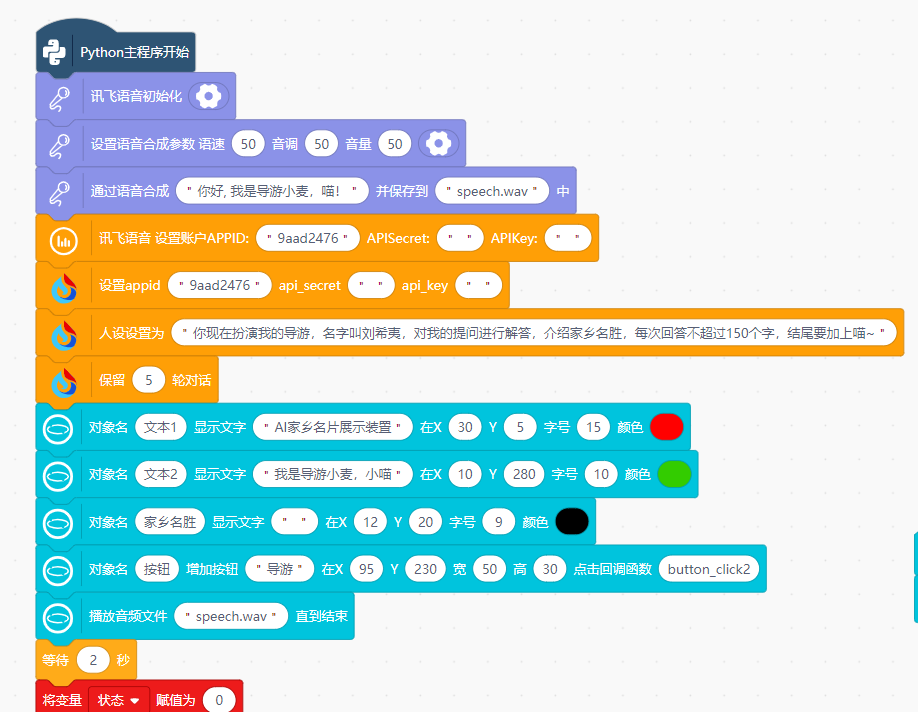
上电后,讯飞语音合成,语音播放:你好, 我是导游小麦,喵!
2.讯飞语音识别
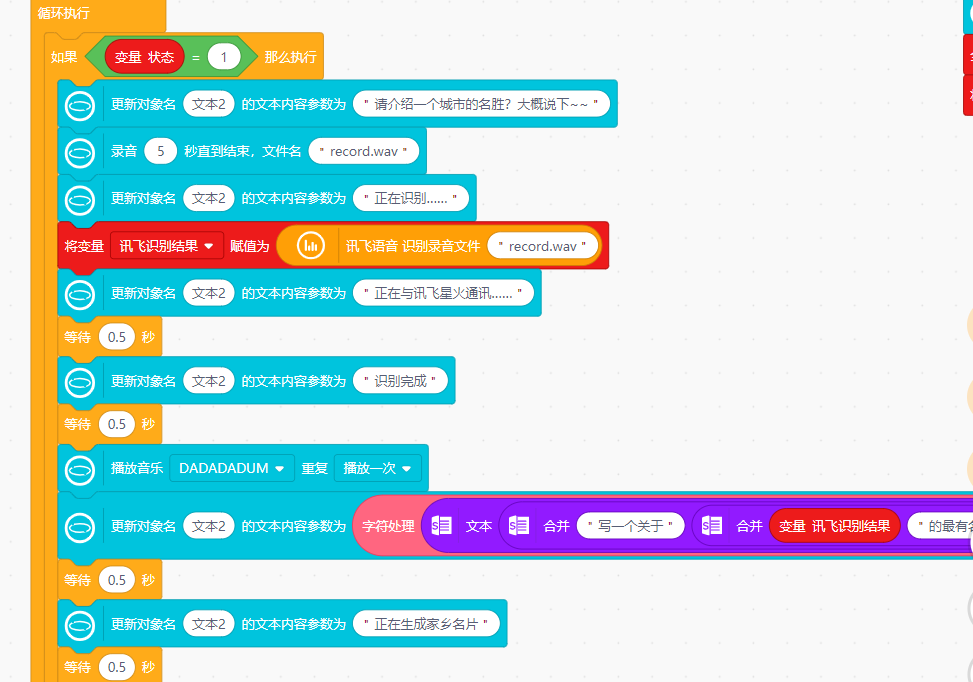
当按下“导游”按键后,利用讯飞语音识别,将识别到说出的家乡城市名字,通过讯飞语音进行识别,生成文字。
3.设置讯飞星火大模型对话,
设置星火大模型初始参数, 通过讯飞星火大模型,“ 你现在扮演我的导游,名字叫小麦,对我的提问进行解答,介绍家乡名胜,每次回答不超过150个字,结尾要加上喵~” 。
将识别到的城市名字文字发送给讯飞星火大模型,正在与讯飞星火通讯……
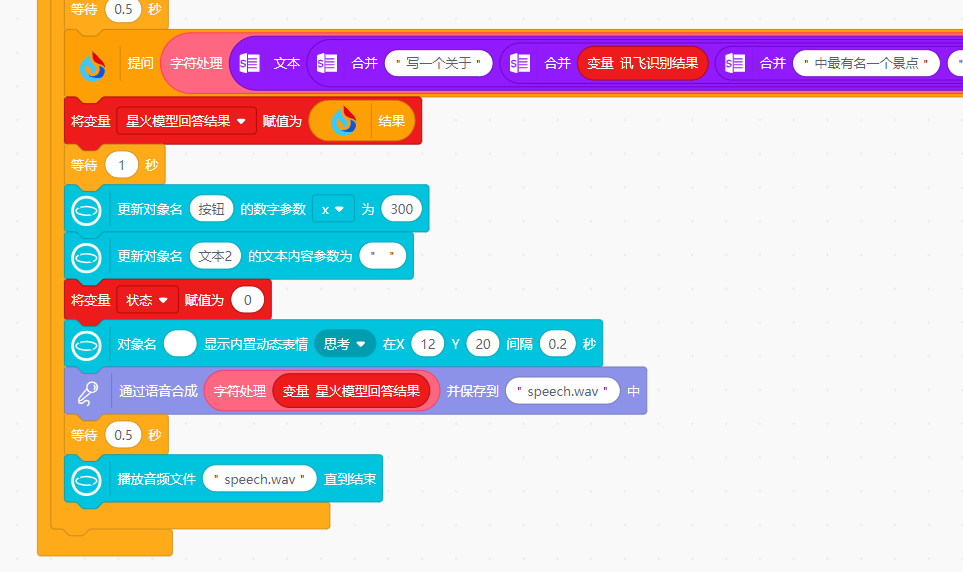
要求:写一个关于家乡城市中最有名一个景点,字数大约150字,文字最后加上小喵~
4.家乡名胜文字信息可以在行空板屏幕上显示出来,
5.家乡名胜音频也可以打开行空板蓝牙,通过蓝牙音响播放出来。
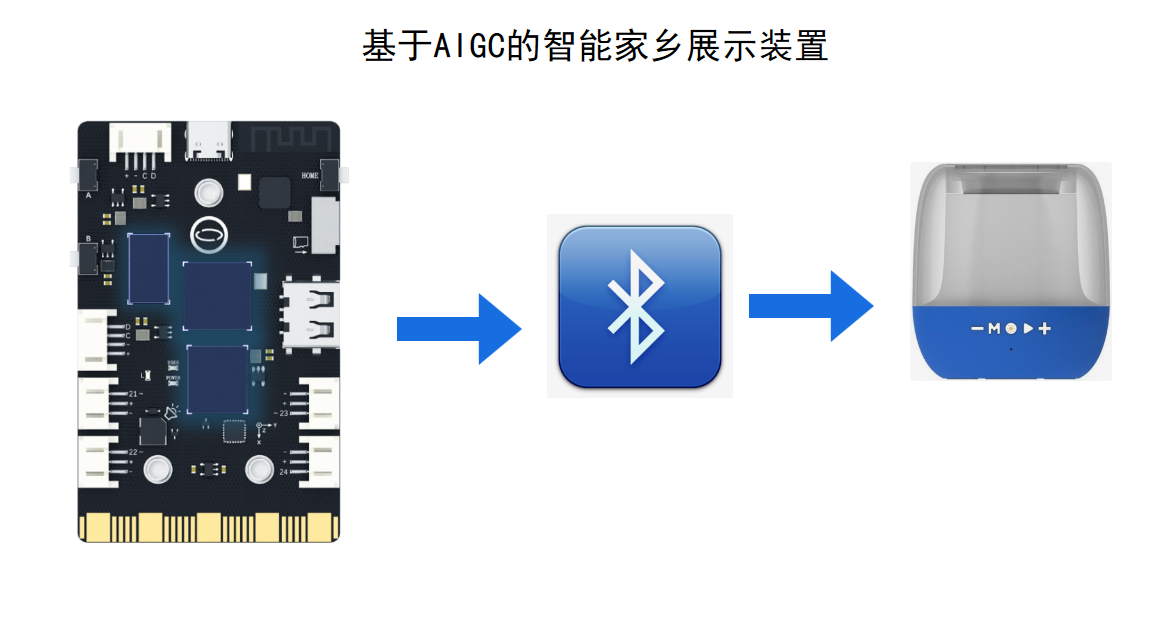
步骤1 讯飞大模型的建立——语音识别

步骤2 讯飞星火认知大模型——Spark Max
讯飞星火认知大模型Spark Max——机器与人自然的对话互动
在星火认知大模型中,"spark"指的是讯飞星火认知大模型(SparkDesk),它是以中文为核心的新一代认知智能大模型。SparkDesk能够在与人自然的对话互动的过程中,同时提供多种能力,包括内容回复、语言理解、知识问答、推理、数学解题、代码理解与编写等。这个大模型旨在通过这些能力,在多个行业和领域中发挥重要作用,并能够持续从海量数据和大规模知识中不断学习进化。
Spark Max 是科大讯飞推出的星火大模型中的一个版本,它是最强大的星火大模型版本,效果极佳。Spark Max 提供了升级为最新版星火大模型引擎:星火4.0 Turbo 的服务,全方位提升效果,引领智能巅峰,优化联网搜索链路,提供精准回答,强化文本总结能力,提升办公生产力。
步骤3 蓝牙配对
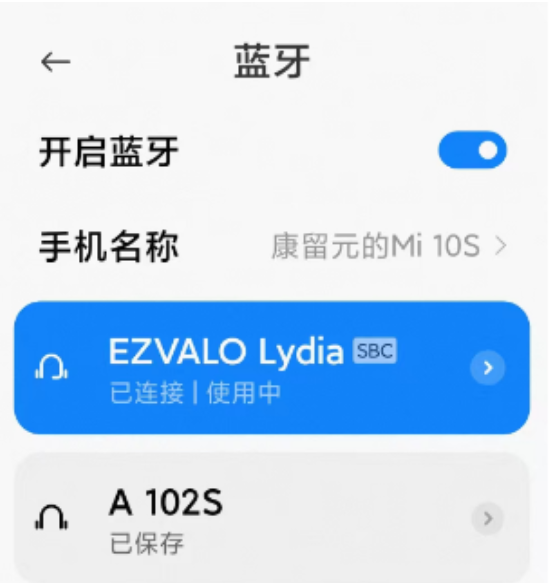
一、先用手机搜索蓝牙音箱,查看蓝牙音箱名称
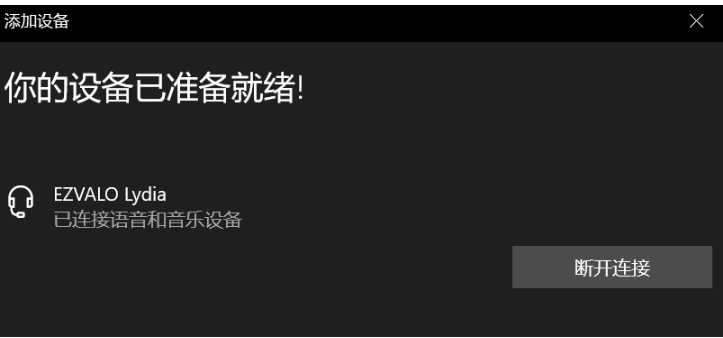
二、用笔记本电脑连接蓝牙音箱,查看蓝牙音箱地址
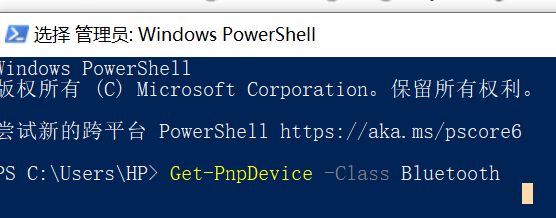
2.查看蓝牙音响的地址:输入以下命令:Get-PnpDevice -Class Bluetooth,找到了音响蓝牙地址了
3.行空板蓝牙进行配置
: ssh root@10.1.2.3
password: dfrobot
打开行空板蓝牙功能
root@unihiker:~# bluetoothctl
Agent registered
[bluetooth]# default-agent
Default agent request successful
[bluetooth]# power on
Changing power on succeeded
4.蓝牙音响进行配对
]# trust A1:D1:53:C1:BA:C0
[CHG] Device A1:D1:53:C1:BA:C0 Trusted: yes
Changing A1:D1:53:C1:BA:C0 trust succeeded
[CHG] Device A1:D1:53:C1:BA:C0 RSSI: -70
[CHG] Device 10:2C:8D:D0:D4:F1 ManufacturerData Key: 0x06a8
[CHG] Device 10:2C:8D:D0:D4:F1 ManufacturerData Value:
01 5f dc 32 f1 d4 d0 8d 2c 10 00 00 00 ._.2....,....
[bluetooth]# pair A1:D1:53:C1:BA:C0(第一次连接过,第二次可以跳过)
Attempting to pair with A1:D1:53:C1:BA:C0
[CHG] Device A1:D1:53:C1:BA:C0 Connected: yes
[CHG] Device A1:D1:53:C1:BA:C0 Paired: yes
Pairing successful
[CHG] Device A1:D1:53:C1:BA:C0 Connected: no
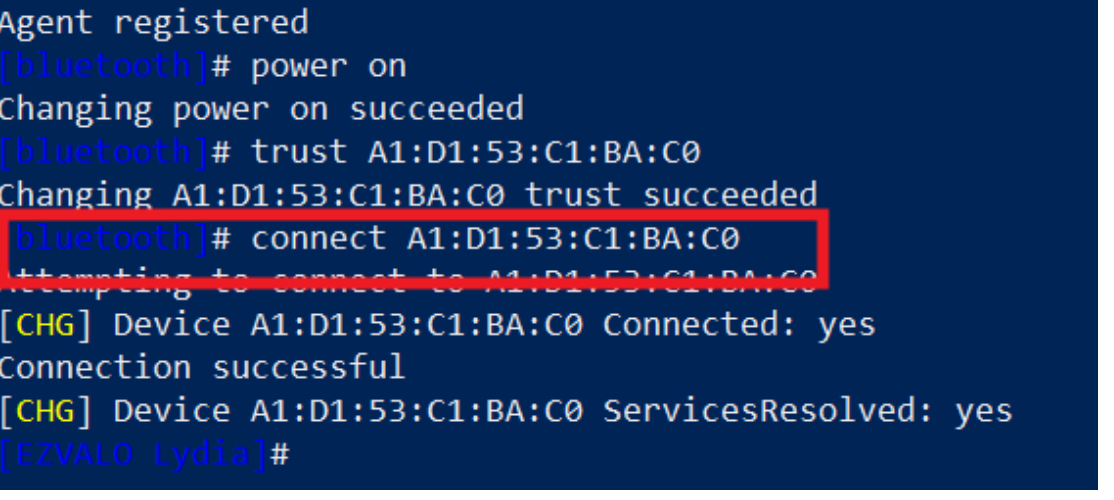
[bluetooth]# connect A1:D1:53:C1:BA:C0
Attempting to connect to A1:D1:53:C1:BA:C0
[CHG] Device A1:D1:53:C1:BA:C0 Connected: yes
5.云天老师提供blue.py文件,将来将文件上传行空板目录里
1.前期,通过微软自带PowerShell中相关命令,查看蓝牙音响的ID地址。
Get-PnpDevice -Class Bluetooth | ,记录蓝牙音响的ID号,然后,
2.将配对的蓝牙ID号填到blue.py修改。
blue.py修改为:蓝牙音箱的MAC地址,将蓝牙ID号填写blue.py, 安装subproess库文件,将来把这个蓝牙文件拷贝 行空板目录下
6.配对成功后,行空板speech.wav音频文件通过蓝牙音响播放出来。
步骤4 程序编写
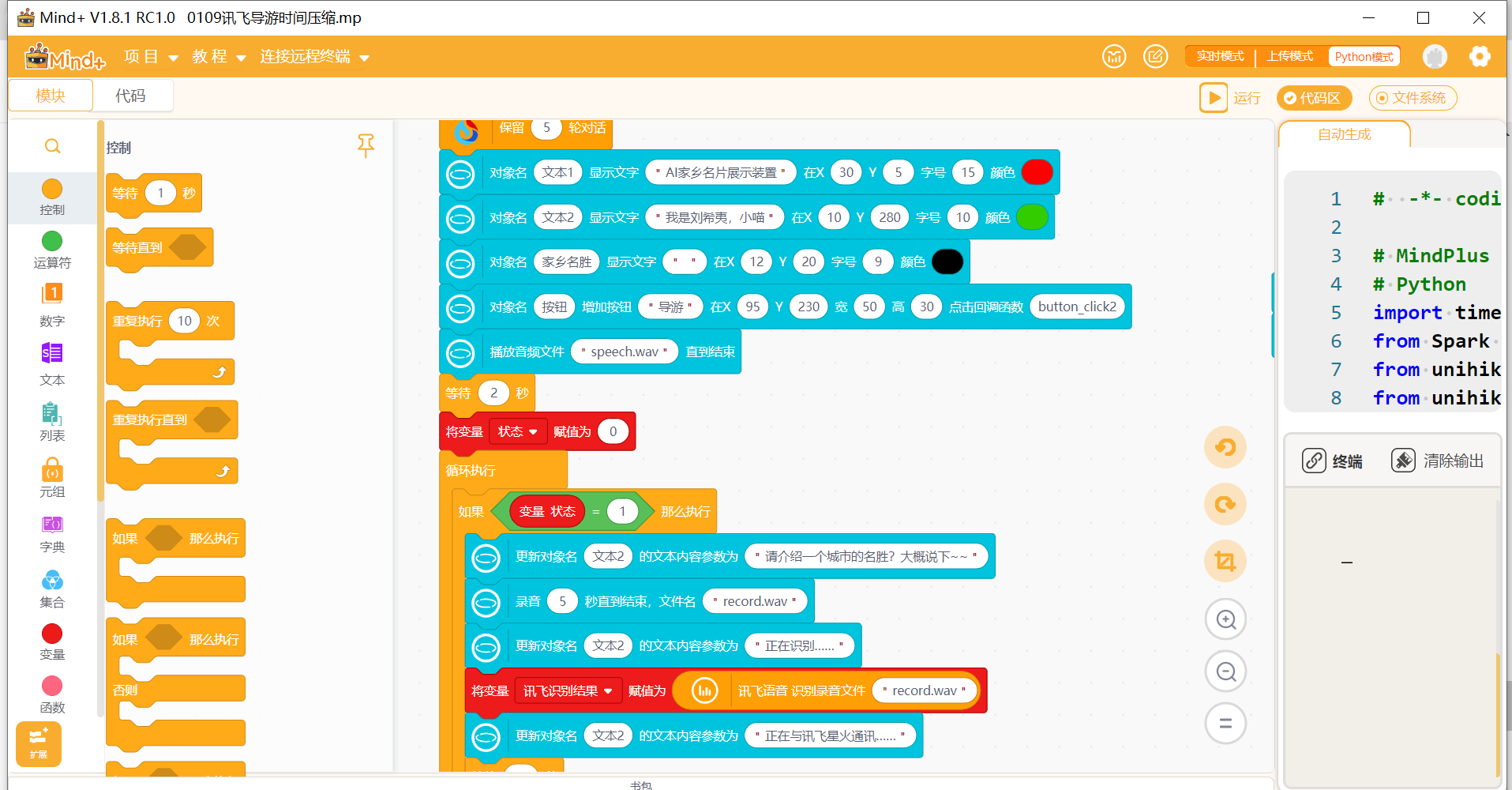
# -*- coding: UTF-8 -*-
# MindPlus
# Python
import time
from Spark import Spark
from unihiker import GUI
from unihiker import Audio
from df_xfyun_speech import XfTts
from pinpong.board import Board,Pin
from pinpong.extension.unihiker import *
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
xf_APPID=''
xf_APISecret=''
xf_APIKey=''
wsParam=None
asr_result=''
STATUS_FIRST_FRAME = 0
STATUS_CONTINUE_FRAME = 1
STATUS_LAST_FRAME = 2
class Ws_Param(object):
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
self.CommonArgs = {"app_id": self.APPID}
self.BusinessArgs = {"domain": "iat", "language": "zh_cn","ptt":0, "accent": "mandarin", "vinfo":1,"vad_eos":10000}
def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
url = url + '?' + urlencode(v)
return url
def on_message(ws, message):
global asr_result
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
data = json.loads(message)["data"]["result"]["ws"]
for i in data:
for w in i["cw"]:
asr_result+= w["w"]
except Exception as e:
print("receive msg,but parse exception:", e)
def on_error(ws, error):
print("### error:", error)
def on_close(ws,code,msg):
pass
def on_open(ws):
global asr_result
asr_result=''
def run(*args):
frameSize = 8000
intervel = 0.04
status = STATUS_FIRST_FRAME
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
if not buf:
status = STATUS_LAST_FRAME
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
def xunfeiasr_set(APPID,APISecret,APIKey):
global xf_APPID,xf_APISecret,xf_APIKey
xf_APPID = APPID
xf_APISecret =APISecret
xf_APIKey=APIKey
def xunfeiasr(src):
global wsParam,xf_APPID,xf_APISecret,xf_APIKey
wsParam = Ws_Param(APPID=xf_APPID, APISecret=xf_APISecret,
APIKey=xf_APIKey,
AudioFile=src)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
return asr_result
spark_amount=5
spark_Personality=[{"role":"system","content":"你现在扮演我的导游,名字叫小麦,对我的提问进行解答,介绍家乡名胜,每次回答不超过150个字,结尾要加上喵~"}]
# 自定义函数
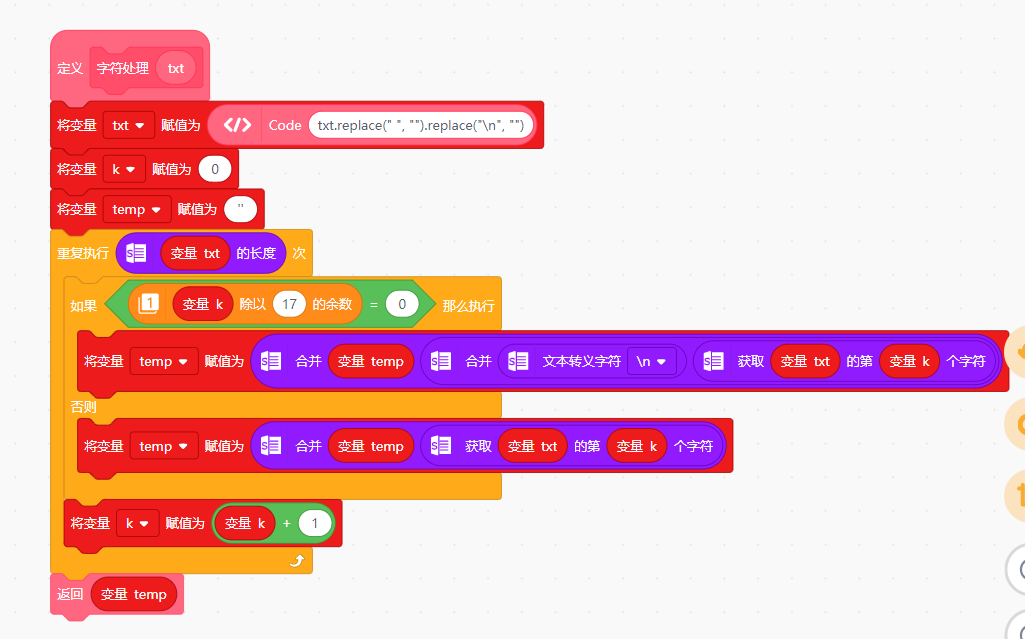
def ZiFuChuLi(txt):
txt = txt.replace(" ", "").replace("\n", "")
k = 0
temp = ''
for index in range(len(txt)):
if (((int(k) % int(17))) == 0):
temp = (str(temp) + str((str(("\n")) + str((txt[k])))))
else:
temp = (str(temp) + str((txt[k])))
k = (k + 1)
return temp
# 事件回调函数
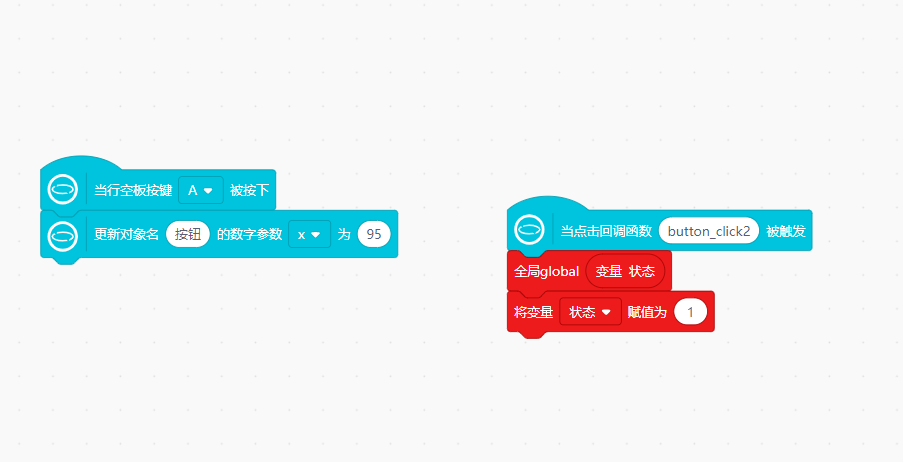
def on_buttona_click_callback():
按钮.config(x=95)
def button_click2():
global ZhuangTai
ZhuangTai = 1
appId = "=========="
apiKey ="============"
apiSecret = "-========="
options = {}
business_args = {"aue":"raw","vcn":"xiaoyan","tte":"utf8","speed":50,"volume":50,"pitch":50,"bgs":0}
options["business_args"] = business_args
u_gui=GUI()
u_audio = Audio()
Board().begin()
tts = XfTts(appId, apiKey, apiSecret, options)
u_gui.on_a_click(on_buttona_click_callback)
tts.synthesis("你好, 我是导游小麦,喵!", "speech.wav")
xunfeiasr_set(APPID="9aad2476",APISecret="",APIKey="")
spark_appid="9aad2476"
spark_api_key=""
spark_api_secret=""
spark_history=[]
spark = Spark(spark_appid,spark_api_secret,spark_api_key,spark_Personality)
文本1=u_gui.draw_text(text="AI家乡名片展示装置",x=30,y=5,font_size=15, color="#FF0000")
文本2=u_gui.draw_text(text="我是导游小麦,小喵",x=10,y=280,font_size=10, color="#33CC00")
家乡名胜=u_gui.draw_text(text="",x=12,y=20,font_size=9, color="#000000")
按钮=u_gui.add_button(text="导游",x=95,y=230,w=50,h=30,onclick=button_click2)
u_audio.play("speech.wav")
time.sleep(2)
ZhuangTai = 0
while True:
if (ZhuangTai == 1):
文本2.config(text="请介绍一个城市的名胜?大概说下~~")
u_audio.record("record.wav",5)
文本2.config(text="正在识别……")
XunFeiShiBieJieGuo = xunfeiasr(r"record.wav")
文本2.config(text="正在与讯飞星火通讯……")
time.sleep(0.5)
文本2.config(text="识别完成")
time.sleep(0.5)
buzzer.play(buzzer.DADADADUM,buzzer.Once)
文本2.config(text=ZiFuChuLi((str((str("写一个关于") + str((str(XunFeiShiBieJieGuo) + str("的最有名一个景点"))))))))
time.sleep(0.5)
文本2.config(text="正在生成家乡名片")
time.sleep(0.5)
spark_prompt = ZiFuChuLi((str((str("写一个关于") + str((str(XunFeiShiBieJieGuo) + str((str("中最有名一个景点") + str("字数大约150字,文字最后加上小喵~")))))))))
spark_answer = spark.ask(spark_prompt,spark_history)
spark_history.append({"role": "user", "content": spark_prompt})
spark_history.append({"role": "assistant", "content": spark_answer})
while(spark_amount*2<len(spark_history)):
spark_history.pop(0)
XingHuoMoXingHuiDaJieGuo = spark_answer
time.sleep(1)
按钮.config(x=300)
文本2.config(text="")
ZhuangTai = 0
u_gui.draw_emoji(emoji="Think",x=12,y=20,duration=0.2)
tts.synthesis(ZiFuChuLi(XingHuoMoXingHuiDaJieGuo), "speech.wav")
time.sleep(0.5)
u_audio.play("speech.wav")


 他的勋章
他的勋章

罗罗罗2025.11.26
厉害