 返回首页
返回首页
 回到顶部
回到顶部

科技的发展使得自动化和智能化成为现代物流、仓储和零售业的重要趋势。而无人驾驶小车和货物识别技术的应用也得到了更加广泛地关注。而货物识别技术就可以帮助小车识别和处理不同的货物,进一步提升自动化和智能化的水平。
本项目将使用行空板和USB摄像头,设计一个可以识别鞋子、纸箱以及瓶子的货物识别系统。
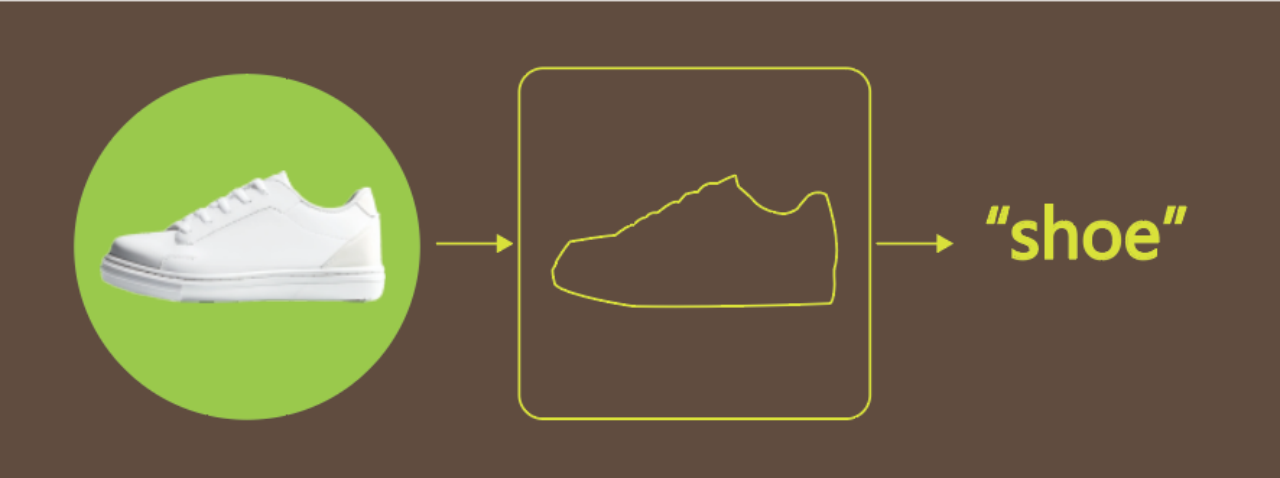
任务目标
当摄像头识别到鞋子、纸箱、瓶子这几个物体时,将对应的货物名称在Mind+终端打印出来。
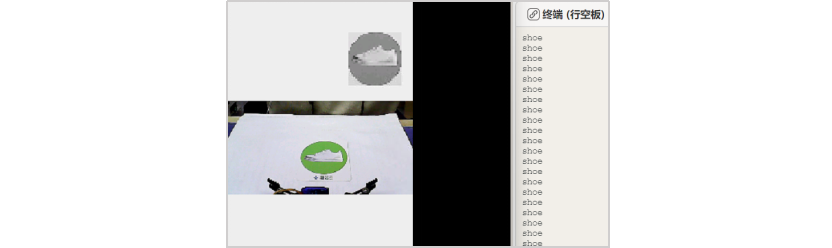
材料清单
硬件清单:

软件使用:Mind+编程软件 x1
下载地址:https://mindplus.cc/

接下来我们将通过采集、训练以及识别三个过程,逐步体验CNN的货物识别实现过程。
任务一:采集物体图像
1. 硬件连接
将USB摄像头连接到行空板上,如下图。硬件连接成功后,使用USB线将行空板连接到计算机。
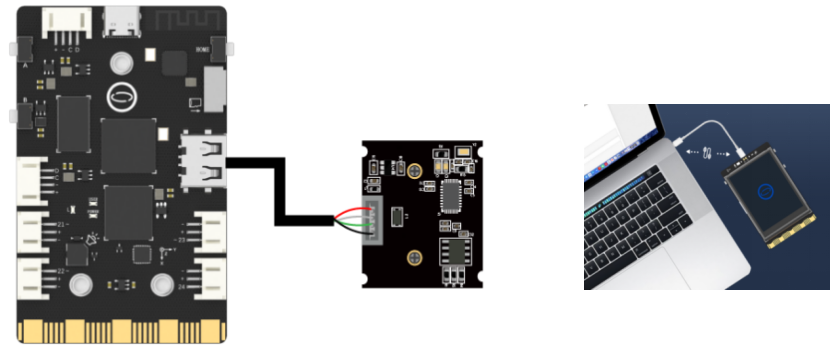
2. 软件准备
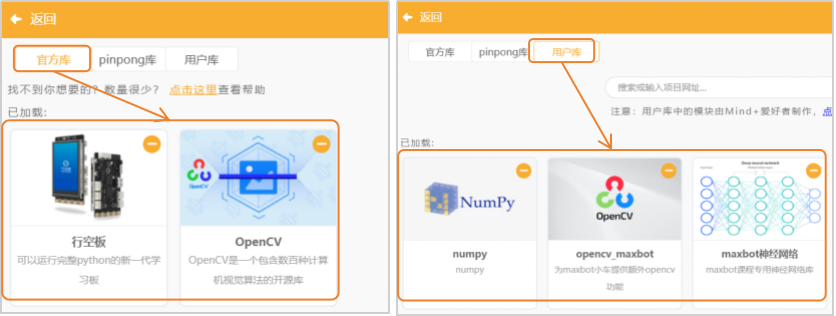
(1)添加官方库:点击“扩展”,在“官方库”中,选择“行空板”与“Opencv”。
(2)添加用户库:选择“numpy”、“opencv_maxbot”、“maxbot神经网络”。
注意:numpy”、“opencv_maxbot”和“maxbot神经网络”的查找,只需要在检索框中输入下列链接,然后点击完成加载。
numpy : https://gitee.com/kiki12345/maxbot_numpy
opencv_maxbot: https://gitee.com/kiki12345/maxbot_opencv
maxbot神经网络: https://gitee.com/kiki12345/maxbot_cnn
3. 编写程序
这个任务中,主要是使用USB摄像头,对货物卡纸进行图片拍照。拍好的图片,需要使用“创建文件夹 来保存数据”指令,来对拍好的图片进行保存。使用时填好要保存的路径,也可以用变量保存路径,然后再使用。
注意:文件路径是文本型,所以路径需要放到“文本 ”指令中。
然后,设置摄像画面。打开摄像头,并设置摄像头画面全部显示(全屏)。
接下来,使用“从VideoCapture对象vd中抓取下一帧grab以及状态ret”指令,从捕获的视频流中抓取一帧图像。
图像捕获成功后,使用“获取图片 的高h 宽w 通道数c”指令,获取帧的形状,以便计算裁剪区域。
如何才能计算出裁剪区域的起点坐标和终点坐标呢?上一步我们已经获取了图片的高(h)和宽(w),要从图片中心裁剪出一个正方形区域。因此,要裁剪的正方形边长已经等于图像的高度(h)。

图像起始坐标x,就为(w-h)//2。新建“变量start_x”,并将变量start_x的值赋值为(w-h)//2。

图像起始坐标y,就为(h-h)//2。新建“变量start_y”,并将变量start_y的值赋值为(h-h)//2。

而终点坐标变量end_x,变量end_y,只需要在起点坐标(start_x,start_y)的基础上加一个高h就可以了。

然后,使用“对象 调整图像 大小为 ”指令,将图像frame根据计算好的坐标进行裁剪。将裁剪后的图像重新命名为crop_frame,图像裁剪的大小为[start_y:end_y, start_x:end_x]。

使用“显示图像 到窗口”指令,将裁剪后的图像显示在行空板屏幕上。但是,我们希望在行空板上看到的图像是镜像的,所以在显示图像指令前,使用“对象名 将图像 水平翻转”指令,对图像进行水平翻转后再显示。要让摄像头的图像是实时的视频流,使用“每 毫秒刷新图像”指令,每隔1毫秒刷新一次图像。

按下A按键,开始保存图片。通过条件语句“如果……那么执行”指令,对“按钮A被按下?”指令进行判断,如果条件为真,将“对象名 用opencv将图像 剪裁为宽 高 ”指令放到该指令中。然后,将图像crop_frame裁剪为宽96,高96的图片,并将裁剪后的图片重新创建一个对象名resized_frame。
注意:“对象名 用opencv将图像 剪裁为宽 高 ”指令,是指对图像进行缩放。其中宽96和高96,是将图像缩放到96*96像素,96*96这个尺寸是经常被用于机器学习和深度学习模型的尺寸。

图像缩放后,就需要对图像文件进行保存了。图片保存的格式为“xx.jpg”,保存路径为“/root/data/shoe”,并将路径保存起来,用于给采集的图片命名。

最后,在Mind+终端增加一些文字提示并将采集图片名显示在行空板屏幕上,完整程序如下:
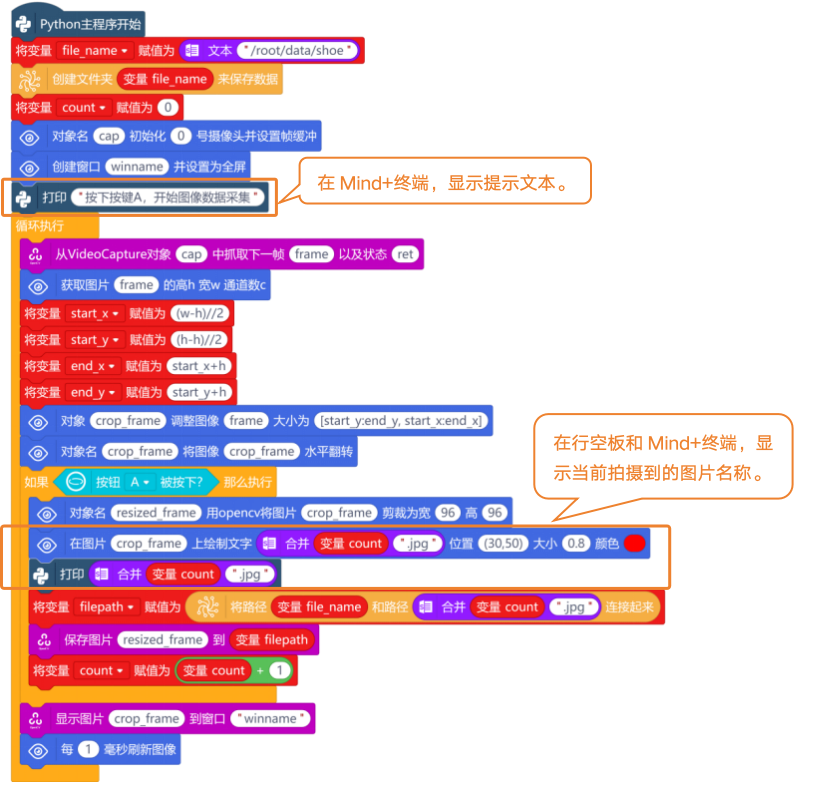
4. 程序运行
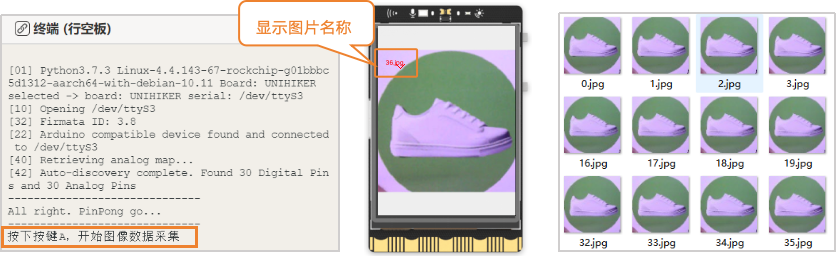
连接行空板成功后,点击运行。程序运行成功后,Mind+终端打印区出现提示“按下A键开始图像数据采集”。图像数据采集操作如下:将USB摄像头,对着货物卡纸鞋子,行空板上出现鞋子的图像后,按下A键不松手,可快速采集图像数据。直到采集到大约500张图像数据后,松开按键。
注意:采集图像过程中,需要调整摄像头角度,多角度采集物体图像,可以提高识别率。
5. 试一试
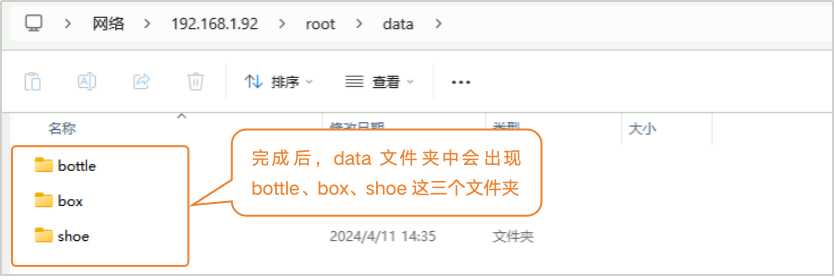
大家还可以尝试采集更多种类的货物图片,比如瓶子和纸箱的图片(bottle、box)。
提示:任务一的程序中修改file_name中的文件名,再次运行程序后,进行对应的图像采集即可。
任务二:训练物体识别模型
1. 编写程序
要完成物体识别模型的训练,需要用的卷积神经网络算法,程序主要通过以下6个步骤来完成:导入数据集、数据预处理、创建神经网络、训练模型、评估模型、保存模型。
(1) 导入数据集
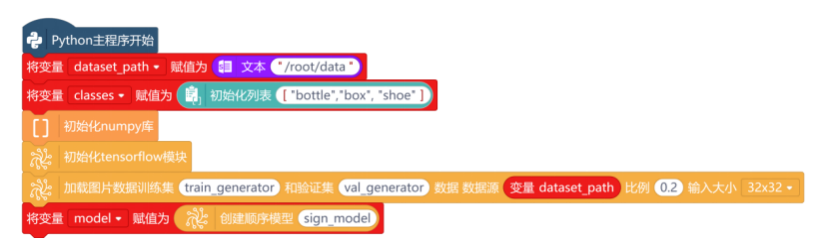
采集好的图片保存在路径“/root/data”这个文件夹中,新建“变量dataset_path”,并初始化变量的值为文本型的“/root/data”。然后,我们可以将要识别的货物,按照采集顺序(即为保存并排序后的图片文件夹顺序)写入列表变量,如下图中的列表["bottle","box", "shoe"]。

(2) 数据预处理
这个项目中,要用到numpy库和TensorFlow库,来完成数据集的划分。一般数据集分为用于训练的训练集和用于测试模型效果的验证集。实现过程是:首先进行模块初始化,然后划分数据集并创建模型,完整的程序如下图所示。
(3) 创建神经网络
下面,就可以开始构建卷积神经网络模型了,一个卷积神经网络模型,需要包含多个卷积层、最大池化层和全连接层。添加卷积层,使用“为模型 添加 层”指令。

然后,使用“卷积层,卷积核数量 激活函数为 ,输入数据格式 层”指令,对输入的图片数据进行卷积操作,以从局部区域中提取特征。其中,选择卷积核数量32,表示卷积层的滤波器数量,也就是卷积后得到的特征图数量。激活函数为relu,输入数据格式为(32x32x1)。

使用“为模型 添加 层”指令与“池化层”指令,对卷积层进行池化操作,减小特征图的空间维度,保留最重要的特征。

重复添加第二个卷积层和池化层,修改卷积层的卷积和数量为64,激活函数为relu,输入格式为none。

添加第三个卷积层和池化层,修改卷层的卷积核数量为128,激活函数为relu,输入格式为none。

接下来使用“为模型 添加 层”指令和“展平层”指令,添加展平层。展平层的作用是将卷积层提取的特征图展平成一个向量,为全连接层做准备。

然后,使用“为模型 添加 层”指令,和“Dense层,神经元个数为 激活函数 为 层”指令,添加一个全连接层。设置神经元个数为128,激活函数为relu。这一层的作用是连接上一层的所有神经元,实现对特征的组合和分类。

最后,使用“为模型 添加 层”指令,和“Dense层,神经元个数为 激活函数 为 层”指令,再添加一个全连接层。并修改神经元个数为“列表 变量classes 的长度”,修改激活函数为softmax。这一层的作用是将具有类别数目的classes列表,使用softmax函数进行多类别分类。

(4) 训练模型
卷积神经网络构建成功后,使用“模型 的结构”和“打印”指令,打印一下模型的结构。

(5) 评估模型
使用“设置模型 参数,优化器,损失函数,评价函数”指令,对模型进行编译,并设置优化器为“Adam”,损失函数为“CategoricalCrossentropy”,评价函数为“accuracy”。

模型编译完成后,使用“训练模型 训练数据集 训练次数 验证数据集”指令,结合刚才分好的数据集,进行模型训练。

(6) 保存模型
模型训练完成后,使用“以saved_model格式保存模型 到 ”指令,将训练好的模型保存为TensorFlow SavedModel 格式,可用于部署和后续使用。

使用“将saved_model模型 转化为ONNX模型 ”指令,将TensorFlow模型转换为ONNX格式。

最后,完整训练程序如下:

2. 程序运行
连接行空板,点击运行。直到Mind+终端打印“模型转化完成,程序终止”字符串后,模型训练完成,自动退出程序。
注意:由于要加载的图片数据比较多,整个模型训练所花的时间也比较久,需要3-5分钟左右。
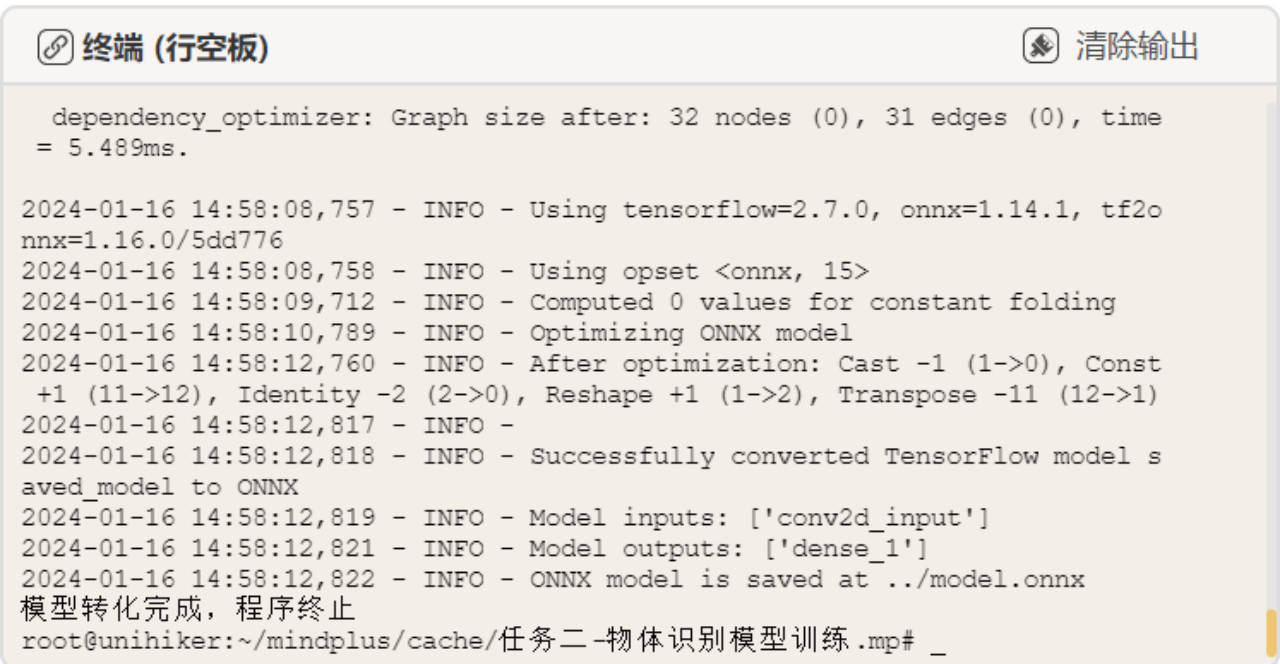
在模型训练过程中,出现了“no module name ‘tf2onnx’”的报错,我们可以在终端中输入指令“pip install tf2onnx”按回车键,进行安装,安装完成后,再次运行程序即可。
任务三:货物识别
1. 编写程序
使用ONNX模型进行物体识别,需要通过模型加载和预处理、图像处理、图像预测与展示这三个步骤。
(1) 模型加载和预处理
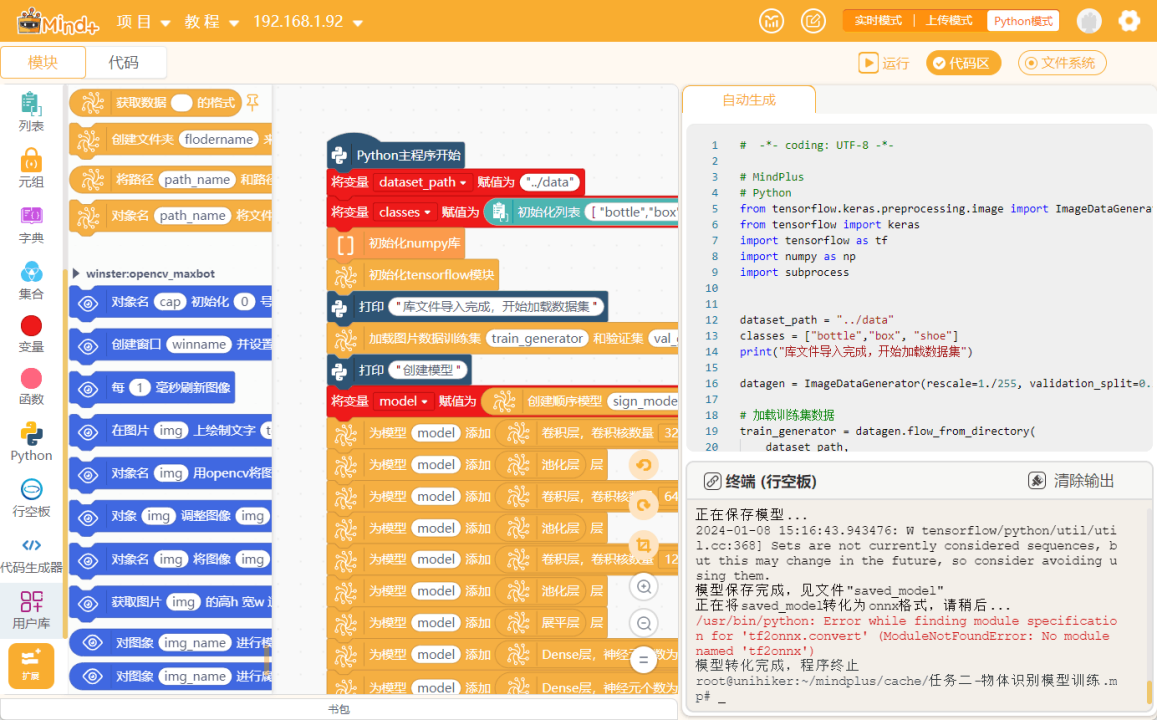
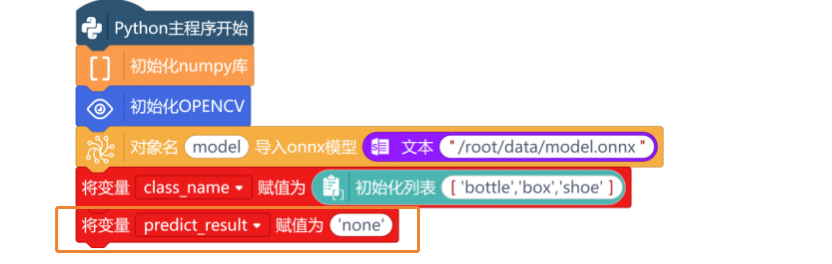
首先,使用“初始化numpy”指令与“初始化OPENCV”指令,进行初始化操作,再加载任务二保存好的model.onnx模型。

货物类别和预测结果初始化(赋值为“none”),依然可以通过变量完成。注意类别要和训练时建立的列表顺序保持一致,如“['bottle', 'box', 'shoe']”。
(2) 图像处理
要从摄像头中读取待识别的图像,使用“对象名 初始化 号摄像头并设置帧缓冲”指令,创建一个视频捕获对象“cap”,并初始化摄像头的编号为0。使用“创建窗口winname并设置为全屏”指令,在屏幕上创建一个名为winname的窗口,并将窗口设置为全屏模式,以便将摄像头中的视频流全屏显示在行空板屏幕上。
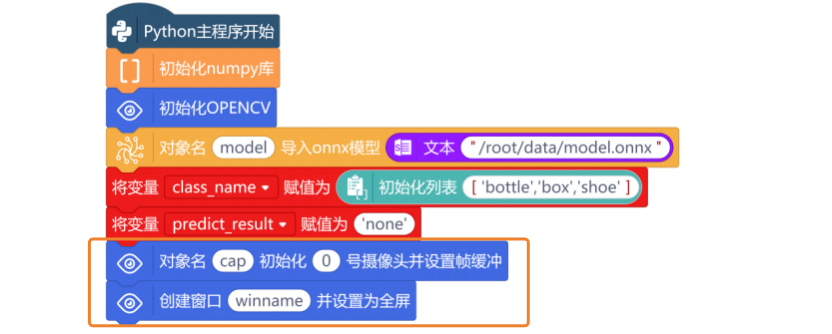
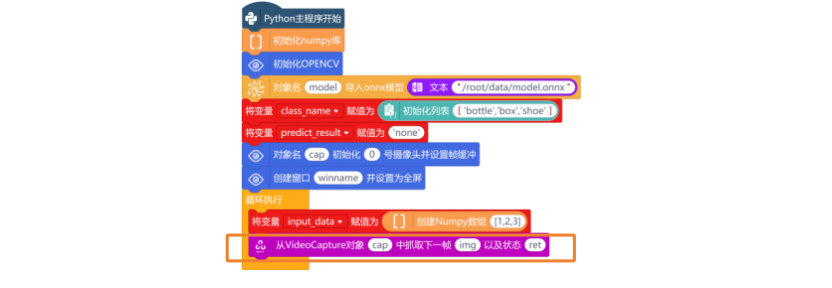
新建“变量input_data”,并将该变量复制为“创建Numpy数组[1,2,3]”指令,初始化Numpy数组的输入数据。
接下来,就需要使用“从VideoCapture对象vd中抓取下一帧grab以及状态ret”指令,从捕获的视频流中抓取一帧图像。
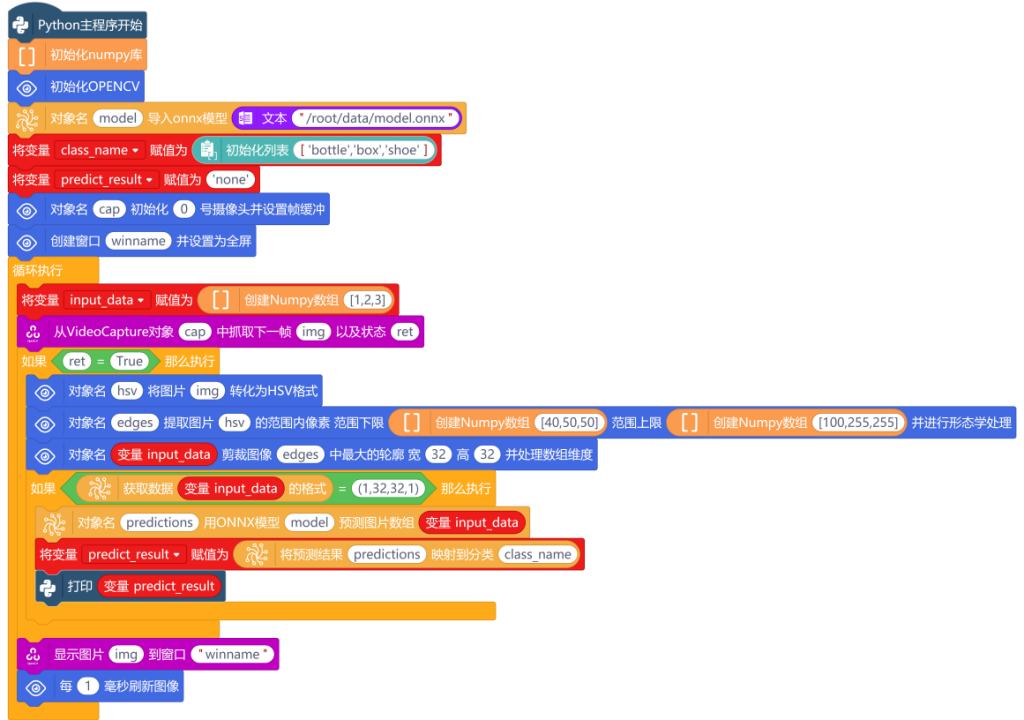
抓取图片后,需要使用“如果……那么执行”指令与“逻辑运算符 =”指令,判断状态ret的值是否True(判断读取帧是否成功)。

判断条件为真时,说明成功读取了帧,使用“对象名 将图片 转换为HSV格式”指令,将摄像头捕获的图像img从BGR颜色空间转换为HSV颜色空间。

接下来,使用“对象名 提取图片 的范围内像素 范围下限 范围上限 并进行形态学去噪”指令,通过设定范围上限和范围下限的阈值,进行颜色分割,得到我们感兴趣的物体区域。范围下限与范围上限,使用“创建Numpy数组 ”指令,设置下限为“[40,50,50]”,上限为“[100,255,255]”。

图片分割成功后,使用“对象名 剪裁图像 中最大的轮廓 宽 高 并处理数组维度”指令,设置宽为32,高为32,对分割出来的区域进行轮廓检测,来定位可能的物体。
注意:设置宽为32,高为32,是因为要与模型训练的图像尺寸一致。

最后,使用“显示图片img并设置图片名称“Mind+.png””指令,将抓取的图像显示在创建的行空板窗口中,并使用“每1毫秒刷新图像”指令,不断地刷新图像,将摄像头中的视频流显示在行空板上。

(3) 图像预测与展示
模型预测前,需要使用“获取数据 的格式”指令,检查提取的图像区域是否符合模型所期望的输入形状。使用条件判断指令“如果……那么执行”,判断“获取数据 变量input_data的格式”是否为(1,32,32,1)。
注意:在条件(1,32,32,1)中,第一个1是指:单个样本;两个32分别指:高度和宽度为32像素,最后一个1是指:通道参数。

当条件为真时,说明剪裁的图像符合图像预测模型。使用“对象名 用ONNX模型 预测图片数组 ”指令,将变量input_data作为预测图片数组,加载到ONNX模型中,进行预测。

然后,使用“将预测结果 映射到分类 ”指令,从模型输出的预测结果中获取最大概率所对应的类别标签,并返回预测概率最高的类别索引,将类别名称赋值给变量predict_result。

最后,使用“打印”指令,将预测结果打印出来,完整程序如下:
2. 程序运行
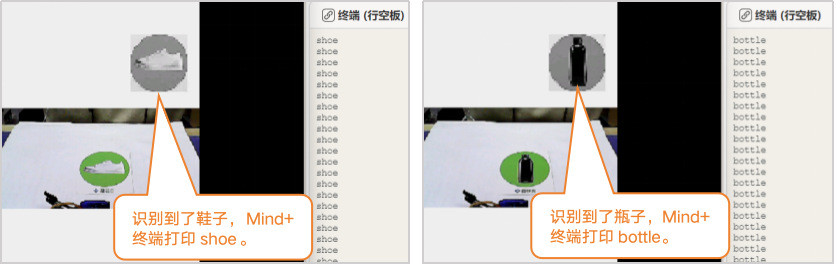
连接行空板,点击运行。程序运行成功后,行空板上显示摄像头检测到的画面,当识别鞋子、纸箱、瓶子卡纸中的物体时,Mind+终端打印出货物名称。
知识园地
1. 卷积神经网络算法的训练过程
使用卷积神经网络算法训练模型,主要是为了解决物体识别问题。而训练模型程序框架大致分为6步:导入数据集、数据预处理、创建神经网络、训练模型、评估模型、保存模型。
(1)导入数据集:首先需要将准备好的用于训练的图片数据集导入。

(2)数据预处理:在训练模型之前,需要对数据进行预处理以准备好输入模型。数据预处理包括对图像进行随访、裁剪、标准化等操作,提高模型的训练效果。

(3)创建神经网络:根据识别要求,设计并创建卷积神经网络。包括合适的网络结构、确定卷积层、池化层、全连接层的数量和大小,以及选择合适的激活函数和优化算法,这个项目就是利用TensorFlow来构建模型。其中,包括3层卷积层、3层池化层、1层展平层、两层dense层。
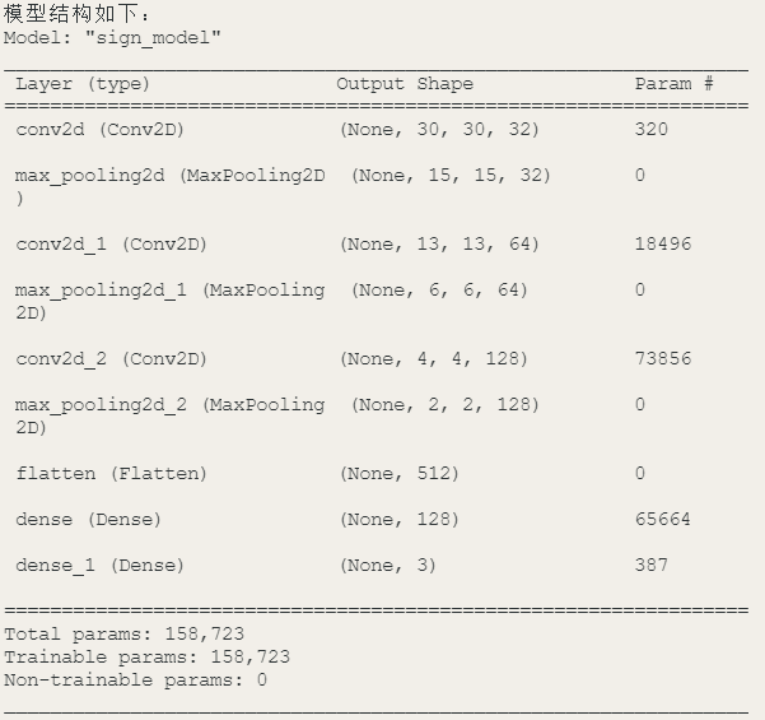
(4)训练模型:将准备好的数据输入到神经网络模型中进行训练。通过迭代的方式,将数据输入到模型中,计算损失函数并更新模型的参数。这个过程通过多次迭代和调整参数来优化模型,使其逐渐收敛到最佳状态。其中Epoch2/3,表示在三个训练周期中的第二个周期。
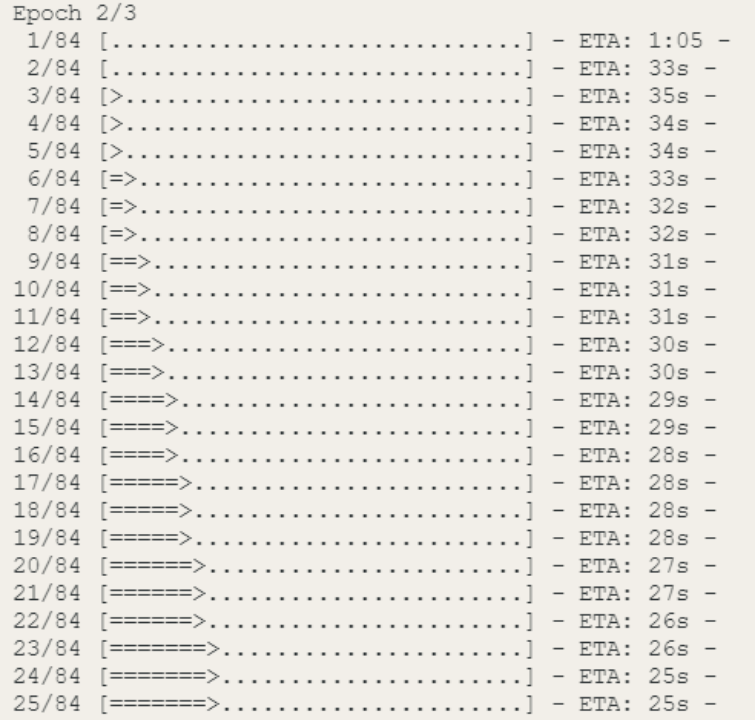
(5)评估模型:使用独立的验证集或测试集对训练得到的模型进行评估。通过计算模型在验证集或测试集上的准确率、精确率、召回率等指标,来评估模型的性能和泛化能力。根据评估结果,可以调整模型的超参数或进行进一步的优化。
(6)保存模型:最后,将训练好的模型保存下来,以便后续在应用中的使用。

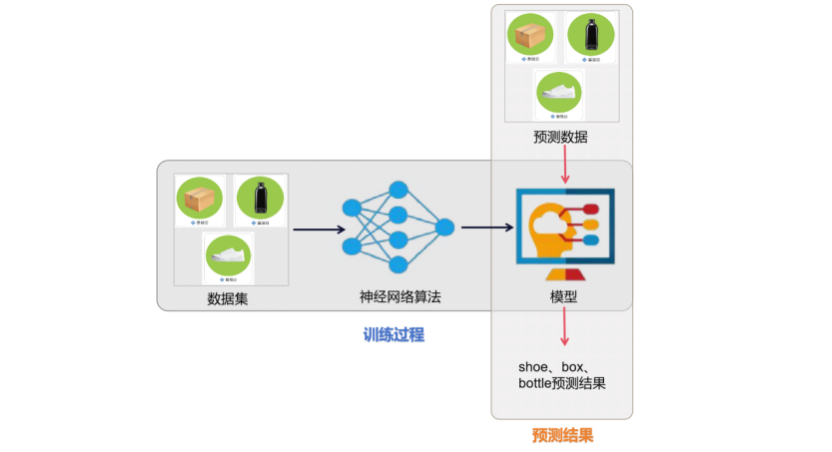
2. 卷积神经网络算法的实现过程
神经网络算法的实现过程如下,相比传统的机器学习算法,神经网络算法最大的优势是免去了繁琐的特征工程,由算法自动发现数据潜在特征。



 他的勋章
他的勋章

评论