 返回首页
返回首页
 回到顶部
回到顶部

1.项目介绍
1.1项目简介
本项目是一个创新性的宠物状态监测系统,核心采用了先进的YOLOv11姿态识别技术,结合行空板M10强大的边缘计算与物联网能力。系统通过行空板实时采集宠物狗的活动图像或视频流,利用本地优化的YOLOv11模型精准检测狗狗的身体姿态和关键点(如耳朵、尾巴、身体等)。基于识别到的姿态特征,运用特定算法分析并判断宠物的实时姿势与当前的状态(四种姿势的识别:standing站立,lying趴下休息,sitting坐立,running邀请玩耍等)。分析结果通过SIoT物联网服务传输至云端进行记录和展示。用户可随时获取宠物的状态变化情况。
本项目深度展示了深度学习模型(YOLOv11)在嵌入式边缘设备(行空板M10)上的高效部署与实时推理能力,以及如何通过物联网技术实现宠物状态的无感监测与远程关怀,适用于智能宠物监护、宠物行为研究、宠物健康管理、提升宠物福利等场景。
1.2项目效果视频
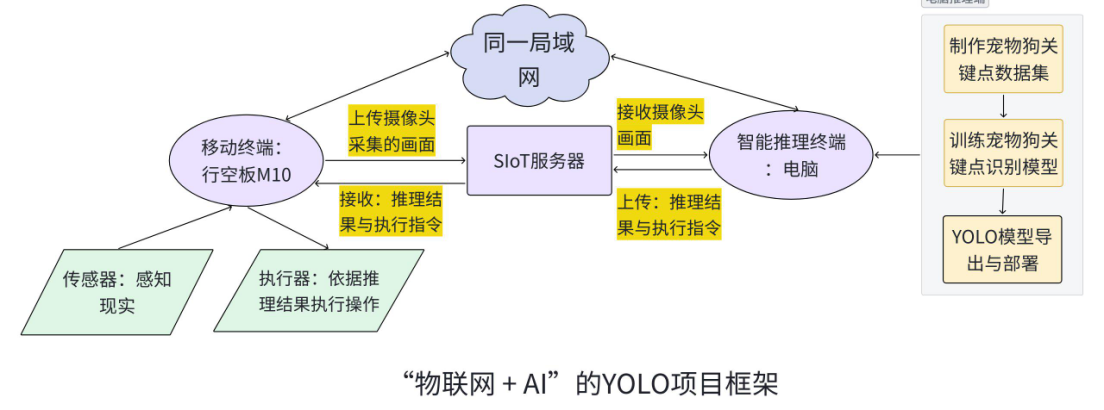
2.项目制作框架
本项目是基于YOLO姿态识别技术,借助行空板M10与摄像头实时采集视频画面,通过物联网与SIOT技术,将行空板M10采集的画面传输到电脑,进行宠物姿态可视化推理,判断宠物情绪,并将结果发送云端。
在本项目中,行空板M10与电脑通过局域网及 SIoT 服务连接,构成了“采集 + 推理 + 执行”的典型智能系统。行空板M10作为移动终端,能够外接传感器与执行器完成数据感知与执行控制。电脑作为外接算力,完成模型训练、部署与推理反馈。通过物联网实现电脑与行空板M10的实时通信,通过“AI + IoT”打造终端感知+一端推理的协同架构能整合边缘感知、智能推理与实时执行等多个优势。
什么是YOLO姿态识别与估计
姿态估计是一项涉及识别图像中特定点(通常称为关键点)位置的任务。关键点可以代表物体的各个部分,如关节、地标或其他显著特征。关键点的位置通常用一组二维 [x, y] 或 3D [x, y, visible] 坐标
姿态估计模型的输出是一组代表图像中物体关键点的点,通常还包括每个点的置信度分数。当您需要识别场景中物体的特定部分及其相互之间的位置关系时,姿态估计是一个不错的选择。常见的姿态识别与估计有官方的YOLO系列的pose模型,可以直接识别人体的关键点。除此之外,我们还可以使用自己标注的关键点数据集,在预训练模型yolo-pose模型基础上进行训练实现个性化的关键点识别与姿势估计,例如使用狗狗关键点数据集实现狗狗姿势识别与估计。


3.软硬件环境准备
3.1软硬件器材清单

3.2软件环境准备
由于我们使用电脑训练水果检测模型,因此需要在电脑端安装相应的库。
首先按下win+R,输入cmd进入窗口。
在命令行窗口中依次输入以下指令,安装ultralytics库
pip install ultralytics
pip install onnx==1.16.1
pip install onnxruntime==1.17.1输入之后会出现以下页面。

当命令运行完成,出现以下截图表示安装成功。

3.3硬件环境准备
在本项目中我们要通过SIoT服务实现行空板M10与电脑的通讯,因此需要将行空板M10自带的siot升级至siot2.0版本。详情参考本链接:https://mindplus.dfrobot.com.cn/dashboard#
使用USB数据线连接电脑与行空板,打开Mind+,选择Python模式。,等待行空板屏幕亮起表示行空板开机成功。运行“升级行空板SIOTV2_1113”程序(程序见最后附件)
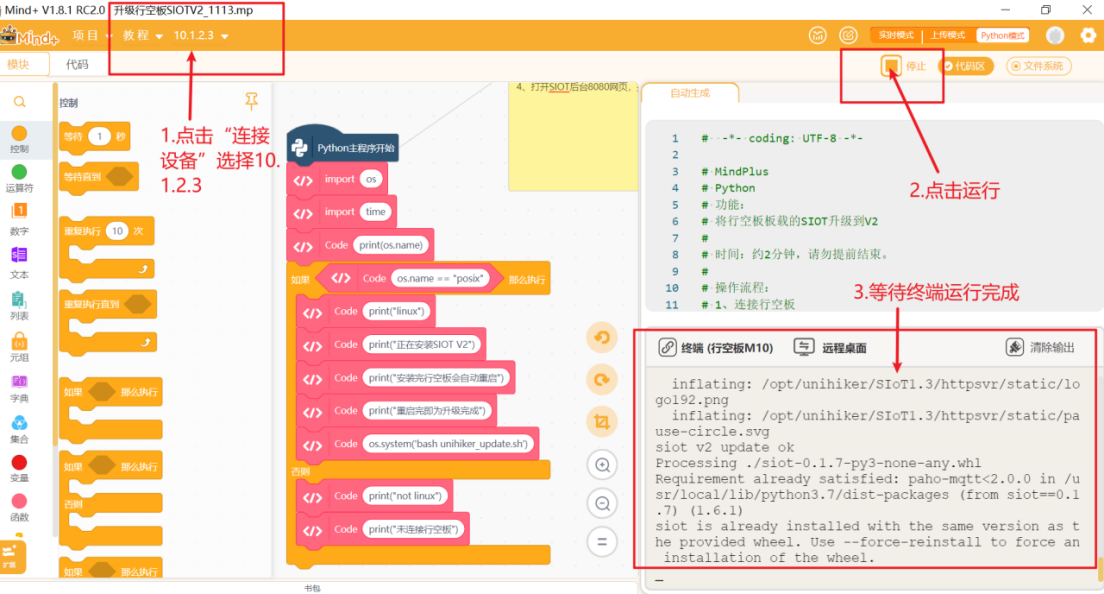
保持Mind+中行空板的连接,打开浏览器,输入“10.1.2.3”,进入行空板官方页面。
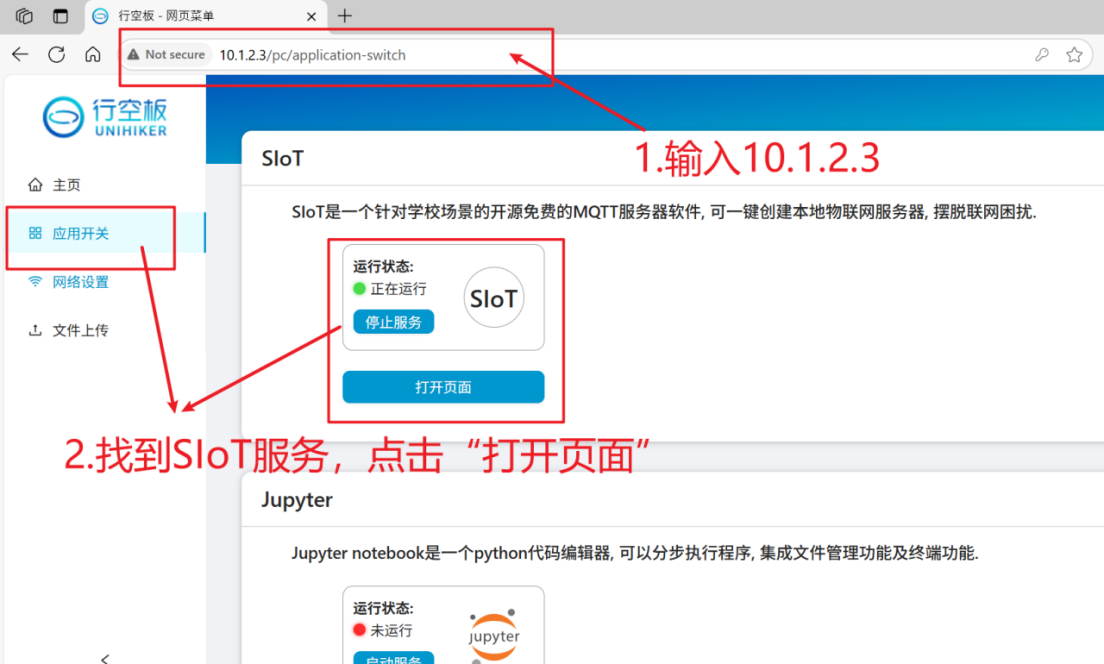
在siot页面输入账号和密码,点击登录
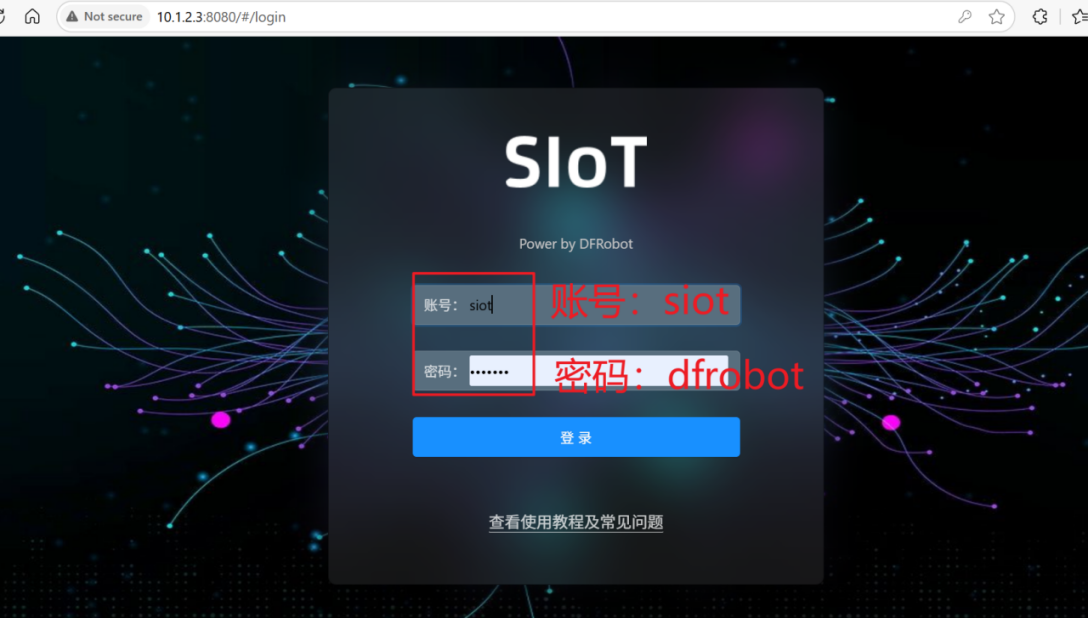
点击“新建主题”,创建一个名为”siot/摄像头“的主题,用于接收行空板M10摄像头采集的视频画面。
依次创建如下的多个主题,用于行空板和电脑端的数据通信。
4. 制作步骤
4.1数据集准备
为了训练狗狗姿态检测识别模型,我们需要准备符合训练格式的数据集。一个标准的目标检测数据集包括训练集和验证集,每个集都包含图像和标注文件(txt文件)。标注文件能提供目标的位置和类别信息。
标准的用于姿态识别的数据集的格式如下。

我们使用的数据集总共包含不同姿态,品种的狗狗图片和标注信息(目标位置和关键点信息)。
dataset/ //数据集
│
├── train/ // 训练集,使用训练集的数据进行模型训练
│ ├── images/ // 训练集的图片文件夹
│ └── labels/ // 训练集中图片的标注信息文件夹,作用是提供图像中目标的位置和类别信息。
│
├── val/ // 验证集,验证集用于评估模型在未见过的数据上的表现
│ ├── images/ // 验证集的图片文件夹
│ └── labels/ // 验证集图片的标注信息文件夹
│
└── data.yaml // 数据集配置文件,用于定义数据集的参数,通常是一个 YAML 文件。其中YAML文件一个对于目标检测模型训练很重要的文件。YAML 文件通常包含数据集的路径信息,这些路径告诉模型训练脚本在哪里找到训练集和验证集的图像和标注文件。除此之外,YAML 文件定义了关键点数据,类别索引与类别名称之间的映射关系。这对于模型在训练和推理过程中正确识别和分类目标至关重要。如下图,是狗狗姿势识别模型的YAML文件。
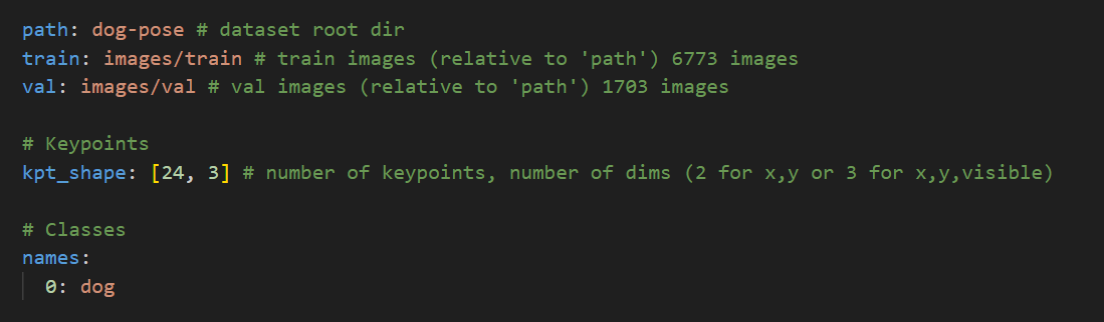
本项目中,我们使用到了yolo官方给出的狗狗关键点数据集,包含了狗狗身上的24个关键点信息,在此基础上做了数据集的轻量化处理。


https://docs.ultralytics.com/zh/datasets/pose/dog-pose/
准备好数据集后,接下来我们就可以进入模型的训练环节了。
4.2模型训练
我们首先要去ultralytics的官方仓库下载YOLO项目文件。链接:https://github.com/ultralytics/ultralytics。如下图,将官方文件夹下载下来,并解压(文件夹已附在在本篇文档的最后)。
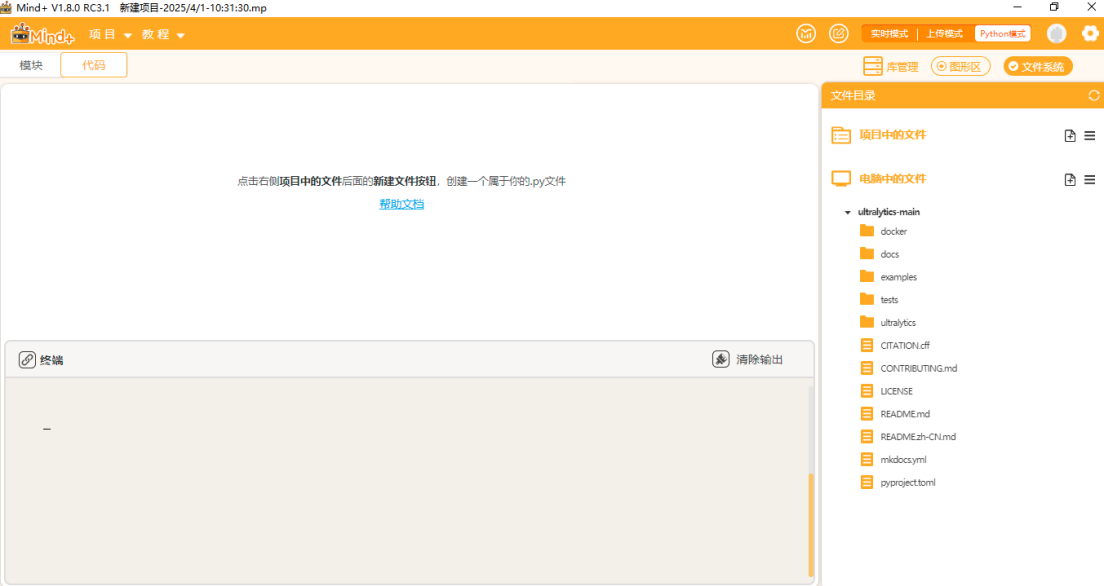
将文件放到一个能找到的路径,打开Mind+,选择Python模式下的代码模式,如下图。
在右侧“文件系统”中找到"电脑中的文件",找到此文件夹进行添加。
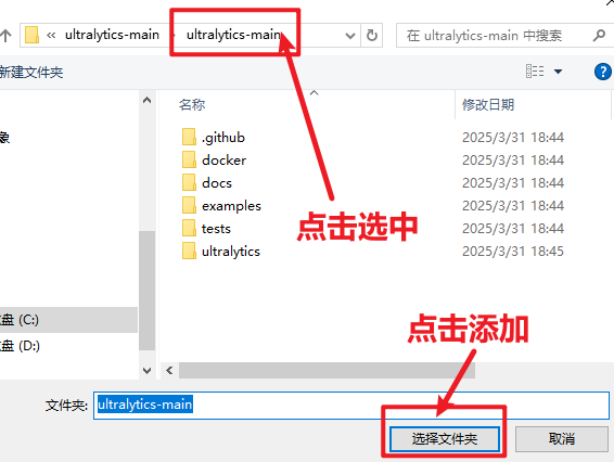
添加好后可以观察到如此下图。
点击"新建文件夹",在ultralytics文件夹中分别新建三个文件夹,依次命名为"datasets"(用于存放数据集),"yamls"(用于存放数据集对应的yaml文件)"runs"(用于存放训练模型的py文件)。
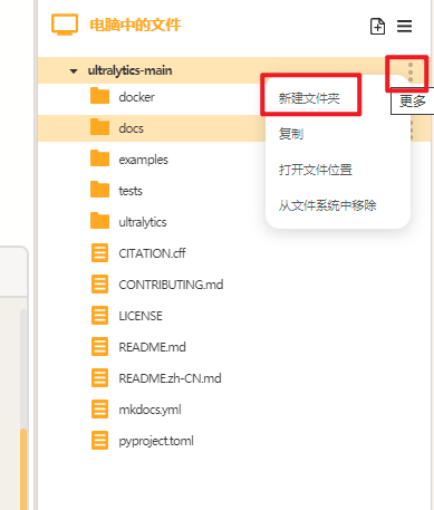
建好后如下图。
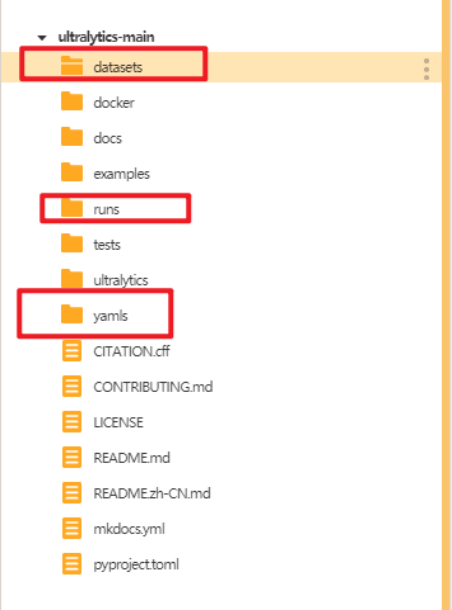
将数据集的训练集和验证集文件夹放入"dataset"文件夹,将水果数据集的yaml文件放入"yamls"文件夹。
接着我们在"runs"文件夹中建立一个叫做"train.py"的文件,在此文件中编写训练YOLO模型的代码。
将训练代码粘贴到train.py中点击运行。我们在预训练模型"yolo11n-pose.pt"基础上进行狗狗姿势检测模型的训练,设置训练轮次是30轮。图片的尺寸是320。
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
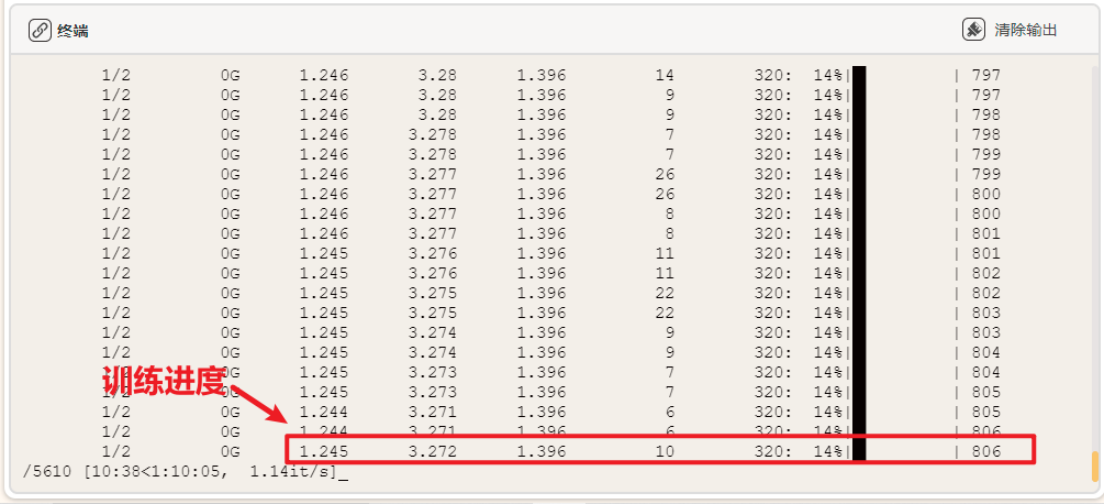
results = model.train(data="dog-pose.yaml", epochs=30, imgsz=320, batch=2, cache=False)运行时可观察终端,自动下载预训练模型"yolov11n-pose.pt",进行模型的训练。
YOLO模型的训练对电脑的配置要求比较高,使用电脑CPU一般训练时间较长,可以考虑使用GPU或者云端算力进行训练,这里我们使用的时本地电脑的CPU训练方法,操作比较简单,耗时略长。
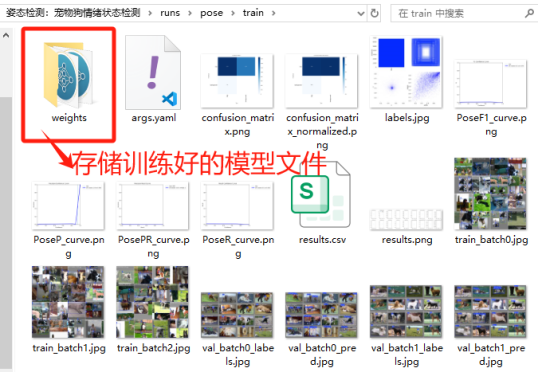
当训练完成后,我们可以观察"runs"文件夹中自动生成了"pose"文件夹(代表“姿态识别”任务),里面存放了训练模型的数据和训练好的模型文件。
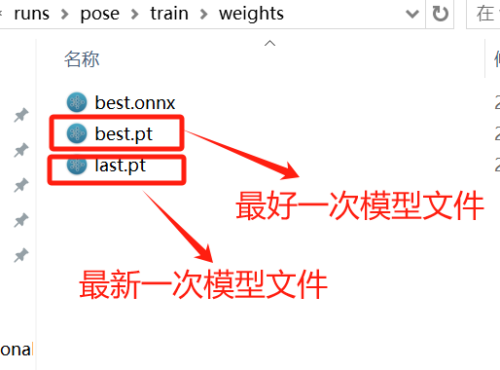
我们训练得到的"best.pt"可以直接用于推理,我们也可以将"best.pt"转成onnx格式的模型文件。ONNX 格式,也是一种模型文件的格式,更加通用,可以与各种推理引擎兼容,提供更高效的推理速度。
4.3模型测评
我们先在电脑端测试一下模型的性能,将训练好的模型拖入Mind+项目中的文件下
再在项目中的文件中新建一个叫做"img_inference.py"(用来测试图片推理效果),同时将测试图片也拖入项目中的文件夹下。



测试图片如下图所示:
将以下代码复制到"img_inference.py"文件中进行图片推理测试。
from ultralytics import YOLO
import cv2
import numpy as np
from scipy.spatial import ConvexHull
# 定义宠物关键点索引
KEYPOINTS = {
0: "front left paw", 1: "front left knee", 2: "front left elbow",
3: "rear left paw", 4: "rear left knee", 5: "rear left elbow",
6: "front right paw", 7: "front right knee", 8: "front right elbow",
9: "rear right paw", 10: "rear right knee", 11: "rear right elbow",
12: "tail start", 13: "tail end", 14: "left ear base",
15: "right ear base", 16: "nose",
17: "chin", 18: "left ear tip", 19: "right ear tip",
20: "left eye", 21: "right eye", 22: "withers", 23: "throat"
}
# 宠物骨架连接定义
PET_SKELETON = [
# 前腿
(0, 1), (1, 2), (2, 22), # 左前腿
(6, 7), (7, 8), (8, 22), # 右前腿
# 后腿
(3, 4), (4, 5), (5, 12), # 左后腿
(9, 10), (10, 11), (11, 12), # 右后腿
# 尾巴
(12, 13),
# 耳朵
(14, 18), (15, 19),
# 头部
(16, 17), (16, 20), (16, 21), (20, 21),
(16, 22), (22, 23),
# 身体中线
(22, 12)
]
def determine_posture(kpts,x1, y1, x2, y2):
"""
根据宠物关键点判断基本姿势:站立、躺倒、奔跑
:param kpts: 宠物24个关键点坐标 (x, y),无效点为None
:return: 姿势类型 ('standing', 'lying', 'running','sitting','playing')
"""
print(len(np.array(kpts)))
for i in range(24):
print(kpts[i])
# 1. 收集所有有效关键点
valid_points = [np.array(kpts[i]) for i in range(24) if kpts[i] != (0,0)]
print("有效点个数:",len(valid_points))
# 如果没有足够的关键点,返回未知
# if len(valid_points) < 4:
# return "unknown"
# 2. 计算关键点的分布范围(宽高比)
width = x2 - x1
height = y2 - y1
# 避免除零错误
if height == 0:
aspect_ratio = 0
else:
aspect_ratio = width / height
# 3. 计算身体主方向角度
def calculate_angle(vec1, vec2):
"""计算两个向量之间的角度(度数)"""
dot = vec1[0]*vec2[0] + vec1[1]*vec2[1]
det = vec1[0]*vec2[1] - vec1[1]*vec2[0]
angle = np.degrees(np.arctan2(det, dot))
return angle if angle >= 0 else angle + 360
body_angle = None
reference_points = []
# 身体方向参考点优先级
if kpts[22] != (0,0) and kpts[12] != (0,0): # 肩隆和尾巴根部
reference_points = [(22, 12)]
elif kpts[16] != (0,0) and kpts[12] != (0,0): # 鼻子和尾巴根部
reference_points = [(16, 12)]
elif kpts[16] != (0,0) and kpts[5] != (0,0): # 鼻子和左后肘
reference_points = [(16, 5)]
elif kpts[16] != (0,0) and kpts[11] != (0,0): # 鼻子和右后肘
reference_points = [(16, 11)]
elif kpts[17] != (0,0) and kpts[5] != (0,0): # 左眼和左后肘
reference_points = [(20, 5)]
elif kpts[17] != (0,0) and kpts[5] != (0,0): # 右眼和左后肘
reference_points = [(21, 5)]
print(reference_points)
# 计算身体角度
if reference_points:
start_idx, end_idx = reference_points[0]
start_pt = np.array(kpts[start_idx])
end_pt = np.array(kpts[end_idx])
body_vec = end_pt - start_pt
body_angle = np.degrees(np.arctan2(body_vec[1], body_vec[0]))
if body_angle < 0:
body_angle += 360
print("身体角度",body_angle)
#计算伸展腿和水平线的角度
def extended_leg_angle(s_idx,e_idx):
start_pt=np.array(kpts[s_idx])
end_pt = np.array(kpts[e_idx])
eleg_vec = end_pt - start_pt
eleg_angle = np.degrees(np.arctan2(eleg_vec[1], eleg_vec[0]))
if eleg_angle < 0:
eleg_angle += 360
print("伸展腿角度",s_idx,e_idx,eleg_angle)
return eleg_angle
# 4. 使用关节角度判断腿部伸展情况
def leg_angle(paw_idx, knee_idx, elbow_idx):
"""计算腿部关节角度(以膝盖为顶点)"""
if kpts[paw_idx] is None or kpts[knee_idx] is None or kpts[elbow_idx] is None:
return None
paw = np.array(kpts[paw_idx])
knee = np.array(kpts[knee_idx])
elbow = np.array(kpts[elbow_idx])
# 计算从膝盖到爪子和膝盖到肘部的向量
vec1 = paw - knee
vec2 = elbow - knee
# 计算两个向量之间的角度
angle = calculate_angle(vec1, vec2)
return angle
# 计算每条腿的角度
front_leg_angles = [
leg_angle(0, 1, 2), # 左前腿
leg_angle(6, 7, 8) # 右前腿
]
rear_leg_angles = [
leg_angle(3, 4, 5), # 左后腿
leg_angle(9, 10, 11) # 右后腿
]
# 5. 确定腿部伸展状态和是否竖直
# 前腿伸展角度阈值(160度以上为伸展)
front_extended = False
front_vertical = False
max_front_angle = 0
t=0
for angle in front_leg_angles:
t=t+1
if angle is not None:
max_front_angle = max(max_front_angle, angle)
if 200 > angle > 160: # 角度大于160度视为伸展
front_extended = True
if t==1:
fan=extended_leg_angle(1,2)
if t==2:
fan=extended_leg_angle(7,8)
if 250 < fan< 290:
front_vertical=True
print("最大前腿伸展角度",max_front_angle,front_vertical)
# 后腿伸展角度阈值(155度以上为伸展)
rear_extended = False
rear_vertical = False
max_rear_angle = 0
t=0
for angle in rear_leg_angles:
t=t+1
if angle is not None:
max_rear_angle = max(max_rear_angle, angle)
if 220 > angle > 140: # 后腿伸展阈值稍低
rear_extended = True
if t==1:
ran=extended_leg_angle(4,5)
if t==2:
ran=extended_leg_angle(10,11)
if 250 < ran< 290:
rear_vertical=True
print("最大后腿伸展角度",max_rear_angle,rear_vertical)
# 6. 姿势判断逻辑
# 奔跑:前后腿都有至少一条腿伸展
if front_extended and not rear_extended:
if body_angle is None:
return "sitting"
if front_extended and rear_extended:
print("伸展")
if body_angle is None:
return "unkown"
# 排除垂直方向(站起/坐立)的角度范围
if not (80 < body_angle < 100 or 260 < body_angle < 280):
if not (front_vertical or rear_vertical):
if (kpts[14] != (0,0) or kpts[18] !=(0,0)) and (kpts[15] !=(0,0) and kpts[19]!=(0.0)):
return "lying"
return "running"
if front_vertical and front_vertical:
return "standing"
if front_vertical or rear_vertical:
if body_angle >185:
return "playing"
if (145 < body_angle < 215) or (325 < body_angle) or (body_angle < 35):
if front_vertical or rear_vertical:
print("竖直")
return "standing"
# 躺倒:身体宽高比大(宽>高),或者身体角度接近水平
if aspect_ratio > 1.5:
print("比例")
return "lying"
# 站立/坐立:默认情况
return "lying"
# 加载预训练模型
model = YOLO('best.pt') # 使用YOLOv11的宠物关键点检测模型
# 加载测试图像
image_path = 'test.png'
image = cv2.imread(image_path)
if image is None:
print(f"错误: 无法加载图像 {image_path}")
exit()
image_height, image_width = image.shape[:2]
# 进行预测
results = model(image, conf=0.3) # 降低置信度阈值以检测更多关键点
# 颜色定义
kpt_color = (0, 255, 0) # 关键点颜色 (BGR格式)
line_color = (0, 0, 255) # 骨架线颜色 (BGR格式)
# 姿势颜色映射
posture_colors = {
"standing": (0, 255, 0), # 绿色 - 站立
"lying": (0, 255, 255), # 黄色 - 躺倒
"running": (255, 0, 0), # 蓝色 - 奔跑
"sitting": (255,255,0), # 荧光 - 坐立
"playing":(0,0,0), # 黑色 - 邀请玩耍姿势
"unknown": (128, 128, 128) # 灰色 - 未知
}
# 姿势描述
POSTURE_DESCRIPTIONS = {
"standing": "站立姿势",
"lying": "趴下休息姿势",
"running": "奔跑姿势",
"sitting" : "坐立姿势",
"playing" : "邀请玩耍",
"unknown": "姿势未知"
}
# 在图像上绘制结果
for result in results:
# 只处理第一个检测到的狗实例
if len(result.boxes) > 0:
box = result.boxes[0] # 只取第一个边界框
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
conf = box.conf.item()
# 获取第一个实例的关键点
if result.keypoints is not None and len(result.keypoints) > 0:
keypoints = result.keypoints[0] # 只取第一个关键点实例
kpt_data = [None] * 24
for idx, kpt in enumerate(keypoints.xy[0]):
if idx < 24 and not kpt[0].isnan():
kpt_data[idx] = (kpt[0].item(), kpt[1].item())
# 判断姿势
posture = determine_posture(kpt_data,x1, y1, x2, y2)
# 根据姿势设置边框颜色
color = posture_colors.get(posture, (128, 128, 128))
cv2.rectangle(image, (x1, y1), (x2, y2), color, 3)
# 绘制姿势标签
label = f'{posture.upper()} ({conf:.2f})'
cv2.putText(image, label, (x1, y1 + 30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, color, 2)
# 绘制关键点和骨架(只绘制第一个实例)
valid_points = []
for i, kpt in enumerate(keypoints.xy[0]):
if i < 24 and not kpt[0].isnan():
x, y = int(kpt[0].item()), int(kpt[1].item())
if (10 <= x < image_width - 10 and
10 <= y < image_height - 10):
valid_points.append(i)
cv2.circle(image, (x, y), 5, kpt_color, -1)
cv2.putText(image, str(i), (x+5, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 0), 1)
# 绘制骨架连接线
for start, end in PET_SKELETON:
if (start < len(keypoints.xy[0]) and end < len(keypoints.xy[0]) and
not keypoints.xy[0][start][0].isnan() and
not keypoints.xy[0][end][0].isnan()):
x1_pt = int(keypoints.xy[0][start][0].item())
y1_pt = int(keypoints.xy[0][start][1].item())
x2_pt = int(keypoints.xy[0][end][0].item())
y2_pt = int(keypoints.xy[0][end][1].item())
if (0 < x1_pt and 0 < y1_pt and 0 < x2_pt and 0 < y2_pt ):
cv2.line(image, (x1_pt, y1_pt), (x2_pt, y2_pt), line_color, 2)
break # 处理完第一个实例后跳出循环
# 显示并保存结果
output_path = 'dog_posture_result.jpg'
cv2.imwrite(output_path, image)
print(f"结果已保存至: {output_path}")
# 显示结果
cv2.imshow('Dog Posture Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()点击Mind+右上角的”运行",运行代码观察效果。

当程序运行时,弹出弹窗显示图片识别结果如下:
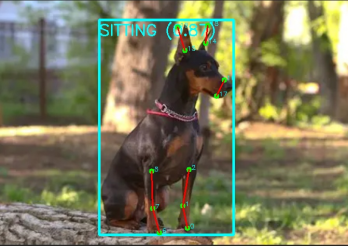
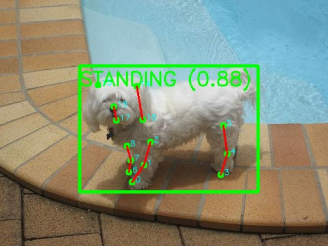
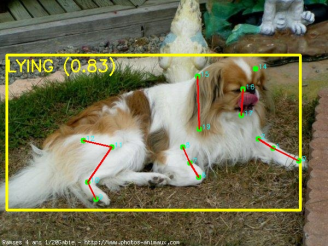
可以看到模型识别出了狗狗的整体位置框,以及每个关键点的位置,并对姿势做出了相应的判断。
4.4行空板M10传输视频到SIoT
另开一个新的Mind+窗口,用于连接行空板M10,连接行空板M10与摄像头。


运行以下图形化程序向SIoT平台发送摄像头画面信息。该程序于在行空板M10上,点击屏幕上的按钮开始游戏,通过摄像头采集图像帧,将其转为base64格式后,通过SIoT服务以MQTT方式发布。设计一个简单的行空板界面,当收到电脑端的游戏结果后,将结果显示在屏幕上。
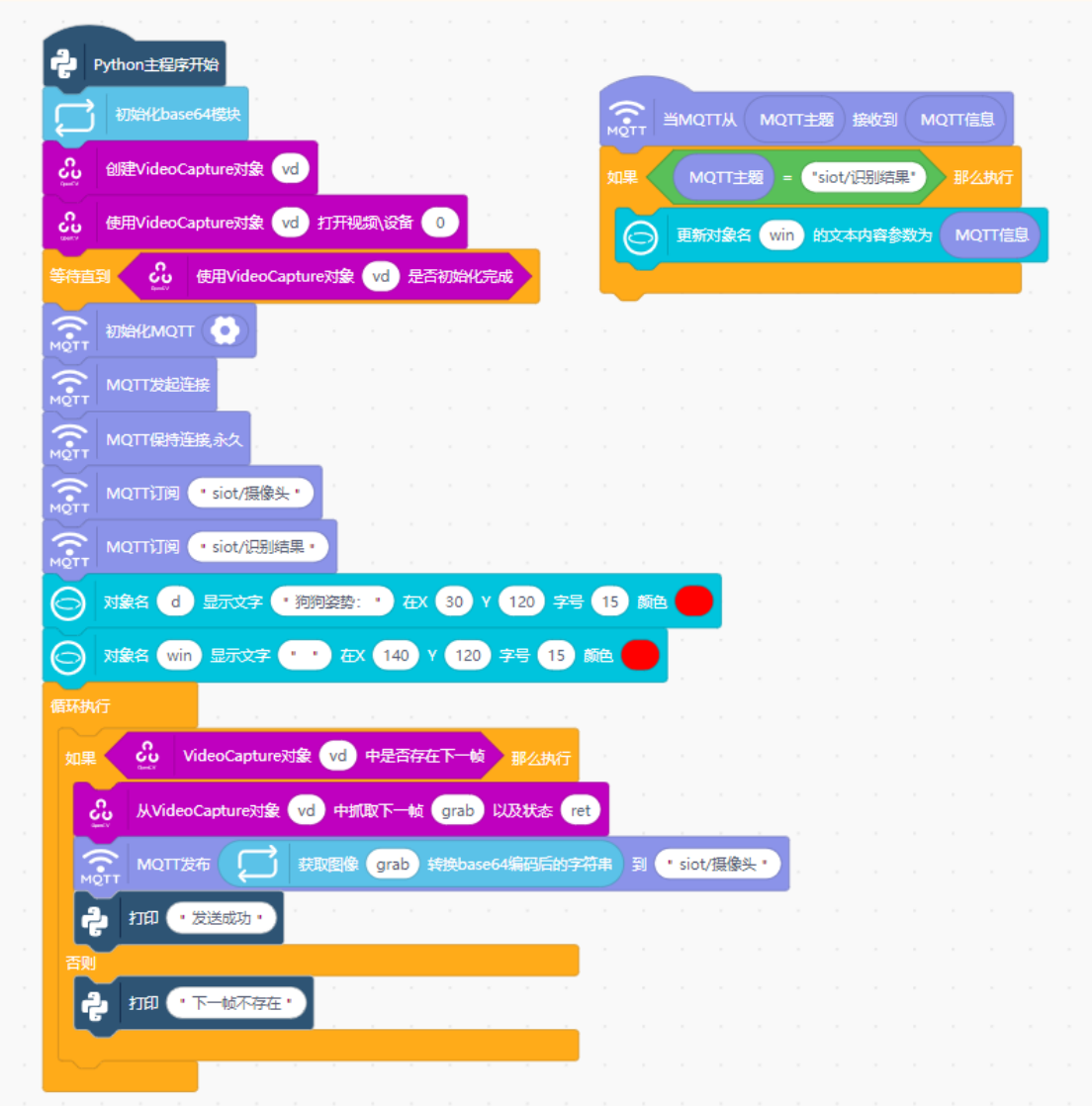
4.5电脑推理并返回结果
返回电脑端项目,在项目中的文件目录下新建一个名为 "pc-predict.py" 文件,复制以下代码进去。
# -*- coding: utf-8 -*-
import siot
import cv2
import base64
import numpy as np
import threading
import time
from queue import Queue
from ultralytics import YOLO
from collections import deque
# 定义宠物关键点索引
KEYPOINTS = {
0: "front left paw", 1: "front left knee", 2: "front left elbow",
3: "rear left paw", 4: "rear left knee", 5: "rear left elbow",
6: "front right paw", 7: "front right knee", 8: "front right elbow",
9: "rear right paw", 10: "rear right knee", 11: "rear right elbow",
12: "tail start", 13: "tail end", 14: "left ear base",
15: "right ear base", 16: "nose",
17: "chin", 18: "left ear tip", 19: "right ear tip",
20: "left eye", 21: "right eye", 22: "withers", 23: "throat"
}
# 宠物骨架连接定义
PET_SKELETON = [
# 前腿
(0, 1), (1, 2), (2, 22), # 左前腿
(6, 7), (7, 8), (8, 22), # 右前腿
# 后腿
(3, 4), (4, 5), (5, 12), # 左后腿
(9, 10), (10, 11), (11, 12), # 右后腿
# 尾巴
(12, 13),
# 耳朵
(14, 18), (15, 19),
# 头部
(16, 17), (16, 20), (16, 21), (20, 21),
(16, 22), (22, 23),
# 身体中线
(22, 12)
]
def determine_posture(kpts,x1, y1, x2, y2):
"""
根据宠物关键点判断基本姿势:站立,趴卧,坐立,跑,邀请玩耍
:param kpts: 宠物24个关键点坐标 (x, y),无效点为(0,0)
:return: 姿势类型 ('standing', 'lying', 'running','sitting','playing')
"""
# 1. 收集所有有效关键点
valid_points = [np.array(kpts[i]) for i in range(24) if kpts[i] != (0,0)]
# 如果没有足够的关键点,返回未知
if len(valid_points) < 4:
return "unknown"
# 2. 计算关键点的分布范围(宽高比)
width = x2 - x1
height = y2 - y1
# 避免除零错误
if height == 0:
aspect_ratio = 0
else:
aspect_ratio = width / height
# 3. 计算身体主方向角度
def calculate_angle(vec1, vec2):
"""计算两个向量之间的角度(度数)"""
dot = vec1[0]*vec2[0] + vec1[1]*vec2[1]
det = vec1[0]*vec2[1] - vec1[1]*vec2[0]
angle = np.degrees(np.arctan2(det, dot))
return angle if angle >= 0 else angle + 360
body_angle = None
reference_points = []
# 身体方向参考点优先级
if kpts[22] != (0,0) and kpts[12] != (0,0): # 肩隆和尾巴根部
reference_points = [(22, 12)]
elif kpts[16] != (0,0) and kpts[12] != (0,0): # 鼻子和尾巴根部
reference_points = [(16, 12)]
elif kpts[16] != (0,0) and kpts[5] != (0,0): # 鼻子和左后肘
reference_points = [(16, 5)]
elif kpts[16] != (0,0) and kpts[11] != (0,0): # 鼻子和右后肘
reference_points = [(16, 11)]
elif kpts[17] != (0,0) and kpts[5] != (0,0): # 左眼和左后肘
reference_points = [(20, 5)]
elif kpts[17] != (0,0) and kpts[5] != (0,0): # 右眼和左后肘
reference_points = [(21, 5)]
# 计算身体角度
if reference_points:
start_idx, end_idx = reference_points[0]
start_pt = np.array(kpts[start_idx])
end_pt = np.array(kpts[end_idx])
body_vec = end_pt - start_pt
body_angle = np.degrees(np.arctan2(body_vec[1], body_vec[0]))
if body_angle < 0:
body_angle += 360
#计算伸展腿和水平线的角度
def extended_leg_angle(s_idx,e_idx):
start_pt=np.array(kpts[s_idx])
end_pt = np.array(kpts[e_idx])
eleg_vec = end_pt - start_pt
eleg_angle = np.degrees(np.arctan2(eleg_vec[1], eleg_vec[0]))
if eleg_angle < 0:
eleg_angle += 360
return eleg_angle
# 4. 使用关节角度判断腿部伸展情况
def leg_angle(paw_idx, knee_idx, elbow_idx):
"""计算腿部关节角度(以膝盖为顶点)"""
if kpts[paw_idx] == (0,0) or kpts[knee_idx] == (0,0) or kpts[elbow_idx] == (0,0):
return None
paw = np.array(kpts[paw_idx])
knee = np.array(kpts[knee_idx])
elbow = np.array(kpts[elbow_idx])
# 计算从膝盖到爪子和膝盖到肘部的向量
vec1 = paw - knee
vec2 = elbow - knee
# 计算两个向量之间的角度
angle = calculate_angle(vec1, vec2)
return angle
# 计算每条腿的角度
front_leg_angles = [
leg_angle(0, 1, 2), # 左前腿
leg_angle(6, 7, 8) # 右前腿
]
rear_leg_angles = [
leg_angle(3, 4, 5), # 左后腿
leg_angle(9, 10, 11) # 右后腿
]
# 5. 确定腿部伸展状态和是否竖直
# 前腿伸展角度阈值(160度以上为伸展)
front_extended = False
front_vertical = False
max_front_angle = 0
t=0
for angle in front_leg_angles:
t=t+1
if angle is not None:
max_front_angle = max(max_front_angle, angle)
if 200 > angle > 160: # 角度大于160度视为伸展
front_extended = True
if t==1:
fan=extended_leg_angle(1,2)
if t==2:
fan=extended_leg_angle(7,8)
if 255 < fan < 285:
front_vertical=True
# 后腿伸展角度阈值(155度以上为伸展)
rear_extended = False
rear_vertical = False
max_rear_angle = 0
t=0
for angle in rear_leg_angles:
t=t+1
if angle is not None:
max_rear_angle = max(max_rear_angle, angle)
if 220 > angle > 140: # 后腿伸展阈值稍低
rear_extended = True
if t==1:
ran=extended_leg_angle(4,5)
if t==2:
ran=extended_leg_angle(10,11)
if 255 < ran < 285:
rear_vertical=True
# 6. 姿势判断逻辑
# 奔跑:前后腿都有至少一条腿伸展
if front_extended and not rear_extended:
if body_angle is None:
return "sitting"
if front_extended and rear_extended:
# 排除垂直方向(站起/坐立)的角度范围
if not (80 < body_angle < 100 or 260 < body_angle < 280):
if not (front_vertical or rear_vertical):
if (kpts[14] != (0,0) or kpts[18] !=(0,0)) and (kpts[15] !=(0,0) and kpts[19]!=(0.0)):
return "lying"
return "running"
if front_vertical and front_vertical:
return "standing"
if front_vertical or rear_vertical:
if body_angle >185:
return "playing"
if (145 < body_angle < 215) or (325 < body_angle) or (body_angle < 35):
if front_vertical or rear_vertical:
return "standing"
# 躺倒:身体宽高比大(宽>高),或者身体角度接近水平
if aspect_ratio > 1.5:
return "lying"
# 站立/坐立:默认情况
return "standing"
# 加载预训练模型
model = YOLO('best.pt') # 使用YOLOv8的宠物关键点检测模型
# 定义颜色映射
posture_colors = {
"standing": (0, 255, 0), # 绿色 - 站立
"lying": (0, 255, 255), # 黄色 - 躺倒
"running": (255, 0, 0), # 蓝色 - 奔跑
"sitting": (255,255,0), # 荧光 - 坐立
"playing": (128, 0, 128), # 紫色 - 邀请玩耍姿势
"unknown": (128, 128, 128) # 灰色 - 未知
}
# 姿势描述
posture_chinese= {
"standing": "站立",
"lying": "趴下休息",
"running": "奔跑",
"sitting" : "坐立",
"playing" : "邀请玩耍",
"unknown": "姿势未知"
}
# MQTT连接配置
client_id = "dog_gesture_pc"
server = "10.1.2.3"
port = 1883
user = "siot"
password = "dfrobot"
camera_topic = "siot/摄像头" # 接收摄像头数据的topic
result_topic = "siot/识别结果" # 发送结果的topic
TARGET_WIDTH = 480 # 目标宽度 - 比纯文本显示稍大但仍小于原始尺寸
TARGET_HEIGHT = 360 # 目标高度
SKIP_FRAMES = 3 # 每4帧处理1帧 (0,1,2,3 → 只处理0)
BUFFER_SIZE = 8 # 缓冲区大小
# 创建队列(优化大小)
input_queue = Queue(maxsize=3) # 输入队列(原始帧)
output_queue = Queue(maxsize=3) # 输出队列(结果帧)
# 存储最近帧的关键点和边界框
keypoints_buffer = deque(maxlen=BUFFER_SIZE)
bbox_buffer = deque(maxlen=BUFFER_SIZE)
# 全局变量
current_posture = "unknown"
last_valid_result = None
last_posture = "unknown"
last_avg_kpts = None
last_avg_bbox = None
def resize_image(frame):
"""降低图像分辨率以加速处理"""
return cv2.resize(frame, (TARGET_WIDTH, TARGET_HEIGHT))
def draw_keypoints_and_skeleton(frame, kpts, bbox, posture):
"""
在图像上绘制关键点、骨架和姿势结果(优化版)
"""
# 创建半透明覆盖层用于绘制骨架
overlay = frame.copy()
output = frame.copy()
# 绘制边界框
color = posture_colors.get(posture, (255, 255, 255))
if bbox is not None:
x1, y1, x2, y2 = bbox
cv2.rectangle(overlay, (x1, y1), (x2, y2), color, 2)
# 绘制关键点 (非(0,0)的点)
if kpts is not None:
for i, kpt in enumerate(kpts):
if kpt != (0, 0):
x, y = int(kpt[0]), int(kpt[1])
cv2.circle(overlay, (x, y), 4, (0, 0, 255), -1) # 红色点
# 绘制骨架
if kpts is not None:
for connection in PET_SKELETON:
start_idx, end_idx = connection
start_kpt = kpts[start_idx]
end_kpt = kpts[end_idx]
if start_kpt != (0, 0) and end_kpt != (0, 0):
start_pt = (int(start_kpt[0]), int(start_kpt[1]))
end_pt = (int(end_kpt[0]), int(end_kpt[1]))
cv2.line(overlay, start_pt, end_pt, (255, 255, 255), 1) # 白色骨架
# 添加半透明覆盖层
alpha = 0.6 # 透明度
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
# 显示姿势结果
posture_text = f"posture: {posture}"
cv2.putText(output, posture_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
return output
def calculate_average_keypoints():
"""
计算缓冲区关键点的平均值
"""
if len(keypoints_buffer) == 0:
return None, None
# 初始化平均关键点数组
avg_kpts = [(0, 0)] * 24
valid_counts = [0] * 24
# 累积关键点值
for kpts in keypoints_buffer:
for i in range(24):
if kpts[i] != (0, 0):
x, y = kpts[i]
avg_kpts[i] = (avg_kpts[i][0] + x, avg_kpts[i][1] + y)
valid_counts[i] += 1
# 计算平均值
for i in range(24):
if valid_counts[i] > 0:
avg_x = avg_kpts[i][0] / valid_counts[i]
avg_y = avg_kpts[i][1] / valid_counts[i]
avg_kpts[i] = (avg_x, avg_y)
else:
avg_kpts[i] = (0, 0)
# 计算平均边界框
avg_bbox = np.mean(bbox_buffer, axis=0).astype(int)
return avg_kpts, avg_bbox
def inference_thread():
"""专用推理线程"""
global current_posture, last_valid_result, last_avg_kpts, last_avg_bbox, last_posture
while True:
# 从输入队列获取帧
if not input_queue.empty():
frame = input_queue.get()
# 执行推理
results = model(frame, verbose=False) # 禁用详细输出
# 检测结果处理
detected = False
current_kpts = None
current_bbox = None
if len(results[0].boxes) > 0:
result = results[0]
box = result.boxes[0]
kpts = result.keypoints[0] if result.keypoints is not None else None
# 处理关键点
processed_kpts = [(0, 0)] * 24
if kpts is not None and kpts.data.shape[1] >= 2:
kpts_data = kpts.data[0].cpu().numpy()
for i in range(min(24, len(kpts_data))):
x, y = kpts_data[i][0], kpts_data[i][1]
processed_kpts[i] = (x, y)
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)
# 存储到缓冲区
keypoints_buffer.append(processed_kpts)
bbox_buffer.append([x1, y1, x2, y2])
detected = True
current_kpts = processed_kpts
current_bbox = [x1, y1, x2, y2]
# 每BUFFER_SIZE帧计算平均关键点
if len(keypoints_buffer) == BUFFER_SIZE:
avg_kpts, avg_bbox = calculate_average_keypoints()
if avg_kpts is not None:
# 姿势判断
current_posture = determine_posture(avg_kpts, *avg_bbox)
siot.publish_save(result_topic, posture_chinese[current_posture])
# 保存平均结果用于后续绘制
last_avg_kpts = avg_kpts
last_avg_bbox = avg_bbox
last_posture = current_posture
# 清空缓冲区(只保留最近帧)
keypoints_buffer.clear()
bbox_buffer.clear()
# 绘制结果
if detected:
# 使用当前检测结果绘制
result_frame = draw_keypoints_and_skeleton(
frame,
current_kpts,
current_bbox,
last_posture
)
elif last_avg_kpts is not None:
# 使用上次平均结果绘制
result_frame = draw_keypoints_and_skeleton(
frame,
last_avg_kpts,
last_avg_bbox,
last_posture
)
else:
# 没有检测结果时显示基本帧
result_frame = draw_keypoints_and_skeleton(
frame,
None,
None,
"unknown"
)
# 保存有效结果
last_valid_result = result_frame.copy()
# 放入输出队列
if not output_queue.full():
output_queue.put(result_frame)
else:
# 如果队列满,替换最旧帧
_ = output_queue.get_nowait()
output_queue.put(result_frame)
# 短暂休眠防止CPU占用过高
time.sleep(0.01)
def on_image_received(client, userdata, msg):
"""MQTT回调函数(优化版)"""
try:
# 1. 解析图像
data = msg.payload.decode()
if "base64," not in data:
return
b64 = data.split("base64,")[-1]
img_bytes = base64.b64decode(b64)
img_array = np.frombuffer(img_bytes, np.uint8)
frame = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
if frame is None:
return
# 2. 降低分辨率
frame = resize_image(frame)
# 3. 跳帧处理 - 使用全局计数器
if not hasattr(on_image_received, "frame_counter"):
on_image_received.frame_counter = 0
on_image_received.frame_counter += 1
if on_image_received.frame_counter % (SKIP_FRAMES + 1) != 0:
return
# 4. 放入输入队列(如果队列满则跳过)
if not input_queue.full():
input_queue.put(frame)
except Exception as e:
print(f"[Error] Image processing failed: {e}")
# 初始化 MQTT
siot.init(client_id=client_id, server=server, port=port, user=user, password=password)
siot.set_callback(on_image_received)
siot.connect()
# 启动MQTT监听线程
mqtt_thread = threading.Thread(target=siot.loop, daemon=True)
mqtt_thread.start()
siot.getsubscribe(camera_topic)
# 启动推理线程
inference_thread = threading.Thread(target=inference_thread, daemon=True)
inference_thread.start()
# 显示主循环
print("[优化版] 已启动,按'q'退出")
cv2.namedWindow("Dog Pose Detection", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Dog Pose Detection", TARGET_WIDTH, TARGET_HEIGHT)
while True:
display_frame = None
# 优先使用输出队列中的帧
if not output_queue.empty():
display_frame = output_queue.get()
# 次之使用上次有效结果
elif last_valid_result is not None:
display_frame = last_valid_result
# 显示帧
if display_frame is not None:
cv2.imshow("Dog Pose Detection", display_frame)
# 退出检查
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('r'): # 重置缓冲区
keypoints_buffer.clear()
bbox_buffer.clear()
last_avg_kpts = None
last_avg_bbox = None
last_posture = "unknown"
print("缓冲区已重置")
# 清理资源
cv2.destroyAllWindows()
同时运行行空板端程序和电脑端程序,等同时连上siot后,可以在电脑端看到实时的摄像头窗口和手势推理结果:
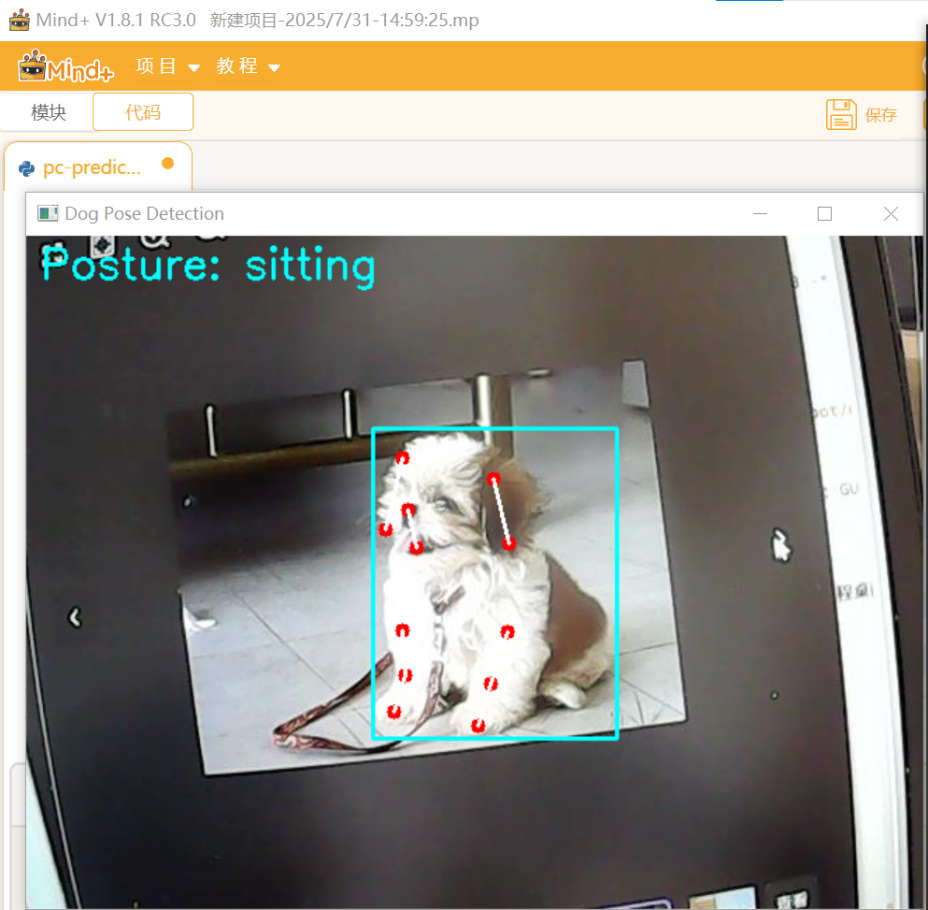
4.5核心代码解析
我们一起来看一下在电脑上运行的 "pc-predict.py" 代码的核心功能代码。
1.姿势识别算法
def determine_posture(kpts,x1, y1, x2, y2):
"""
根据宠物关键点判断基本姿势:站立,趴卧,坐立,跑,邀请玩耍
:param kpts: 宠物24个关键点坐标 (x, y),无效点为(0,0);宠物边界框的起止点坐标(x1,y1),(x2,y2)
:return: 姿势类型 ('standing', 'lying', 'running','sitting','playing')
"""
# 1. 收集所有有效关键点
......
# 2. 计算分布范围(宽高比)
......
# 3. 计算身体主方向角度
def calculate_angle(vec1, vec2):
......
# 计算身体角度
......
#计算伸展腿和水平线的角度
def extended_leg_angle(s_idx,e_idx):
......
# 4. 使用关节角度判断腿部伸展情况
def leg_angle(paw_idx, knee_idx, elbow_idx):
"""计算腿部关节角度(以膝盖为顶点)"""
......
# 计算每条腿的角度
# 5. 确定腿部伸展状态和是否竖直地面
......
# 6. 姿势判断逻辑
# 奔跑:前后腿都有至少一条腿伸展
# 躺倒:身体宽高比大(宽>高),或者身体角度接近水平
# 站立/坐立:默认情况
......算法架构:
1. 整体特征:
○ 边界框宽高比 → 身体整体趋势
○ 关键点向量 → 身体角度和腿部角度
2. 关节分析:
○ 通过腿部三点角度计算(爪-膝-肘)-----判断腿部伸展状态
3. 决策逻辑:
○ 基于规则的多条件判断
○ 设置多个优先级进行数据的处理
2.MQTT物联网通信
# MQTT通信核心代码
def on_image_received(client, userdata, msg):
"""MQTT消息回调函数"""
# 1. 提取Base64图像数据
b64 = msg.payload.decode().split("base64,")[-1]
# 2. 解码为OpenCV图像
img_bytes = base64.b64decode(b64)
img_array = np.frombuffer(img_bytes, np.uint8)
frame = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
# 3. 图像处理流水线
process_frame(frame)
# MQTT初始化
siot.init(client_id=client_id, server=server, port=port, user=user, password=password)
siot.set_callback(on_image_received)
siot.connect()
# 启动独立线程处理网络通信
threading.Thread(target=siot.loop, daemon=True).start()1.异步通信模型:使用回调函数处理到达的消息,避免阻塞主线程
数据流处理:
2.Base64解码 → 字节流转换 → OpenCV图像重建
实现网络数据到可处理图像的转换流水线
3.线程分离:网络监听在独立线程运行,确保图像处理不受网络延迟影响
4.主题订阅:通过siot.subscribe(camera_topic)接收指定视频流
3.多帧平均处理
# 全局缓冲区
SKIP_FRAMES = 3 # 每4帧处理1帧 (0,1,2,3 → 只处理0)
BUFFER_SIZE = 8 # 缓冲区大小
# 创建队列(优化大小)
input_queue = Queue(maxsize=3) # 输入队列(原始帧)
output_queue = Queue(maxsize=3) # 输出队列(结果帧)
# 存储最近帧的关键点和边界框
keypoints_buffer = deque(maxlen=BUFFER_SIZE) # 关键点滑动窗口
bbox_buffer = deque(maxlen=BUFFER_SIZE) # 边界框滑动窗口
def calculate_average_keypoints():
"""关键点平均计算"""采用多帧平均处理,设置一个固定长度的滑动窗口deque,通过FIFO方式实现时间窗口,对窗口内的数据进行多帧平均后再判断最终姿势,可以有效消除关键点识别的抖动,增强视频流识别准确率和稳定性。
5.项目相关资料附录

项目程序文件链接: https://pan.baidu.com/s/1NYISULj3gmr3VoL4J6Yxbw?pwd=cgmg


 他的勋章
他的勋章



罗罗罗2025.11.19
666