 返回首页
返回首页
 回到顶部
回到顶部

本系列课程资料文件: https://pan.baidu.com/s/1chr893ncV_X96S3I9IRMvA?pwd=2ew5
随着智能科技的飞速发展,车载语音助手成为现代汽车的重要组成部分。本项目将设计一款车载语音交互系统,利用语音识别技术将驾驶员的语音指令快速准确地转化为可执行操作。例如,语音控制指令,控制车灯的开启和关闭、音乐播放等。使驾驶员可以通过简单的语音指令完成各类任务,从而提升行车效率。

任务目标
通过语音指令“开灯/关灯”,控制小车上的LED灯打开和关闭;通过语音指令“笑话”,控制小车的音频模块讲笑话;通过语音指令“音乐”,控制音频模块播放音乐。

知识点
1.掌握采集语音指令数据集的方法
2.掌握训练语音模型的关键步骤
3.了解语音识别技术的实现过程
4.认识频谱图并了解其作用
材料清单
硬件准备:

软件使用:Mind+编程软件
下载地址:https://mindplus.cc/

课前准备
环境设置:在开始正式学习之前,我们需要对行空板进行一些基础准备,确保系统和环境设置都正确。具体步骤,请参考:行空板无人驾驶系列课程 第一课 课前准备 部分内容。
动手实践
任务一:采集语音指令数据集
通过按下A键,使用行空板上的麦克风分别录入“开灯”、“关灯”、“笑话”、“音乐”四条语音控制指令。
任务二:训练语音指令识别模型
将录好的语音指令数据集,训练成用于识别的语音模型。
任务三:语音控制系统
使用语音控制指令,控制小车上的LED灯和音频模块执行对应的操作。
任务一:采集语音指令数据集
1.软件准备
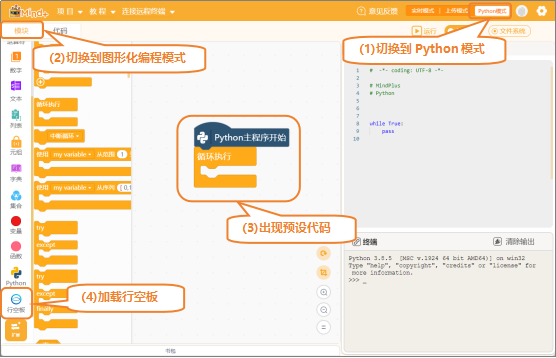
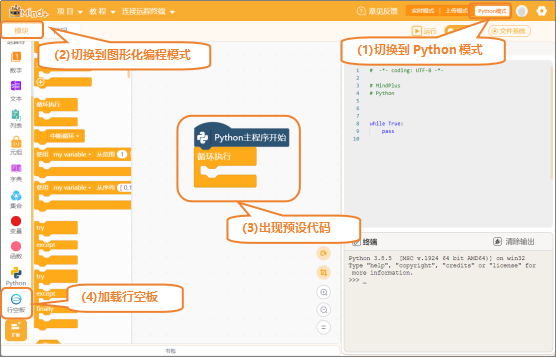
(1)打开Mind+:按照下面的图示完成软件准备工作。
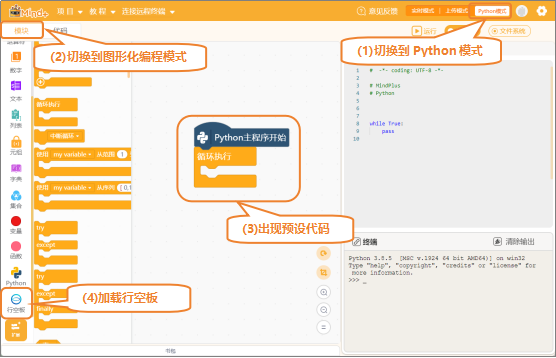
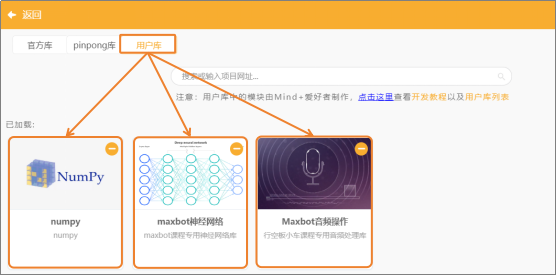
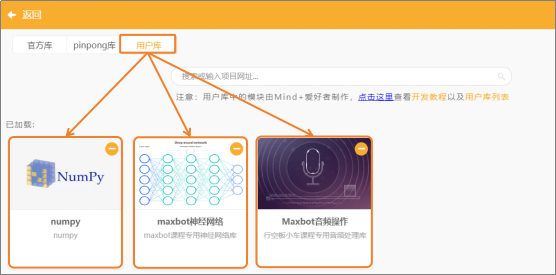
(2)添加用户库:点击“扩展”,在“用户库”中,选择“numpy”、“maxbot神经网络”、“maxbot音频操作”,并完成添加。
2.编写程序
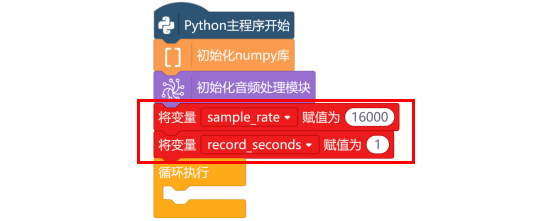
在“Python主程序开始”下,使用“初始化numpy库”指令,导入numpy库。numpy库的作用是将录制的音频数据进行归一化、缩放、转换。

使用“初始化音频处理模块”指令,导入处理音频的库。之后录制音频、保存音频都将使用这个库中的指令。

录制音频前需设置采样率和采样时长,因此新建“变量sample_rate”,并初始化为16000,设置音频采样率为16000;新建“变量record_seconds”,初始化为1,设置音频采样时长为1秒。
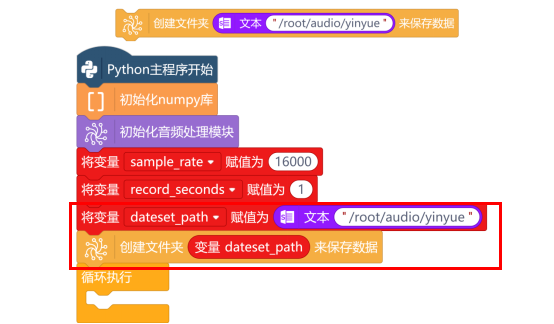
接下来,使用“创建文件夹 来保存数据”指令,来对采集好的音频进行保存。指令中填写路径“/root/audio/yinyue”,当然,也可以新一个建“变量dateset_path”,并初始化为“/root/audio/yinyue”,后面要使用这个路径时,直接使用变量名即可。
按下A按键,开始录制音频。在“循环执行”指令中,将“按钮A被按下?”指令作为判断条件,放入“如果……那么执行……”指令中,当条件被满足时,将“录制音频()采样数()采样率()”指令放到该指令中。其中,采样数为:采样频率*采样时长(sample_rate*record_seconds);采样频率为:sample_rate。
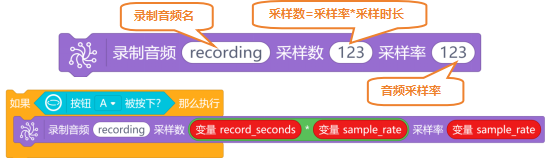
录制音频时,使用“等待录音完成”指令,等待录音完成。然后,使用“对象名 对音频 数据处理”指令,将录制好的音频统一后进行保存。
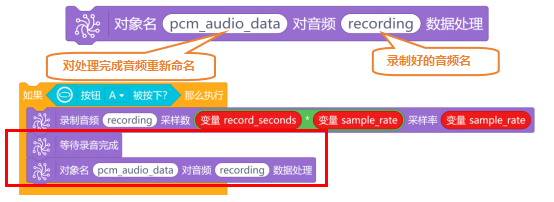
音频处理完成后,就需要对音频进行保存了。音频保存的格式为“xx.wav”,并保存到“/root/audio/yinyue”这个路径下。首先使用“将路径 和路径 连接起来”指令,将“/root/audio/yinyue”和“xx.wav”连接起来,确认好保存路径和音频文件名。

为满足训练需求,需采集至少10条语音指令音频。这10条以上的音频都需要保存到“yinyue”这个文件下。因此,音频文件名可以设置为0.wav、1.wav、2.wav……这样的形式进行保存。
新建变量count,在“Python主程序开始”下,初始化变量值为0.音频文件名使用“合并”指令,将变量count和音频后缀名.wav合并起来。最后新建变量file_name,用来存储合并后的音频文件名。
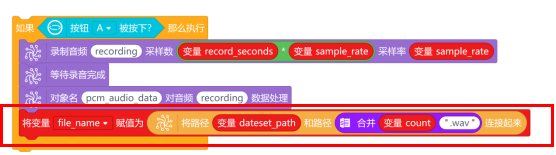
确认好保存路径和音频文件名后,就使用“保存音频为 采样率 音频数据源”指令,对录制好的音频数据源pcm_audio_data,进行保存。保存完成后,使用“将变量count赋值为 ”指令,将变量count+1。
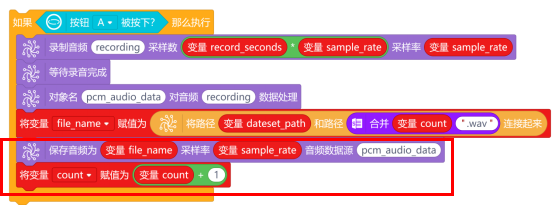
最后,使用“打印 ”与“对象名 显示文字 ”指令,在每个功能步骤下加上提示,完整程序如下:

3.程序运行
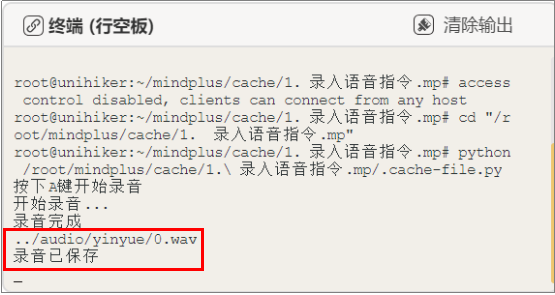
远程连接192.168.1.80,连接成功后,点击运行。程序运行成功后,行空板上显示提示操作“按下A键开始录音”。音频录取操作如下:按下A键,快速松开,对着行空板上的麦克风说“音乐”,音频录制完成后,行空板上显示“录音已保存”。要采集第2条“音乐”指令,重复上面操作即可。同时,Mind+终端打印区也会出现对应的提示。
注意:录音时需快速按下并松开A键,长按会录制无效音频。为了能让训练的模型识别更精准,最好能够采集30条左右的“音乐”指令音频。

4.试一试
这个项目中,需要使用到“音乐”、“开启”、“关闭”、“笑话”,这四个语音指令。录制前,需要修改程序中的“变量dateset_path”的路径后,再运行程序。例如,录制“开启”语音指令时,修改变量dateset_path的路径为“/root/audio/kaiqi”,然后运行程序,进行“开启”语音指令的录制。“关闭”、“笑话”的路径只需要使用同样的方式修改文件夹名。
注意:修改音频文件保存路径后,需要重新运行程序,然后才能开始该指令的音频录制。

任务二:训练语音指令识别模型
1.查看音频文件
开始程序编写之前,我们先要学会如何查看录制成功的音频文件,音频文件的查看方法如下。
方法一:
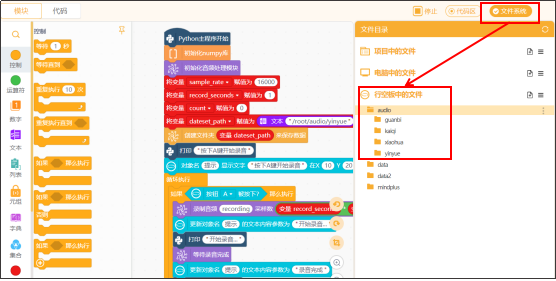
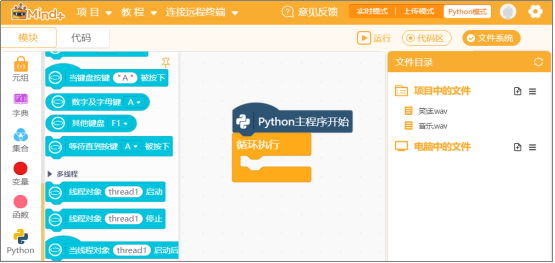
点击Mind+运行右侧的文件系统,在“行空板中的文件”目录下,找到“audio”文件夹,就可以看到“guanbi”、“kaiqi”、“xiaohua”、“yinyue”这四个文件夹,点击该文件夹,可以看到录制的音频文件。
方法二:
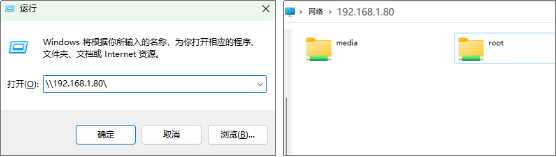
使用“win+R”快捷键,打开运行窗口,输入“\\192.168.1.80\”并回车,打开文件夹窗口。
双击“root”文件夹打开,出现输入网络验证窗口,输入访问账号以及密码。账号:root,密码:dfrobot,点击确定即可打开。
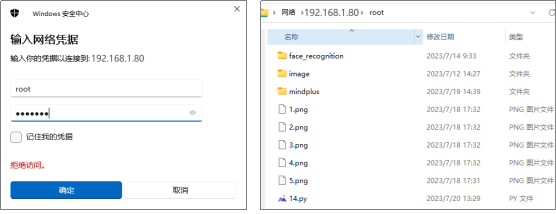
接下来,就可以按照路径“root/audio”,查看到音频文件夹,打开对应的文件夹,可以查看录制好的音频文件,双击音频文件,可以听录制好的音频。
2.软件准备
(1)打开Mind+:按照下面的图示完成软件准备工作。
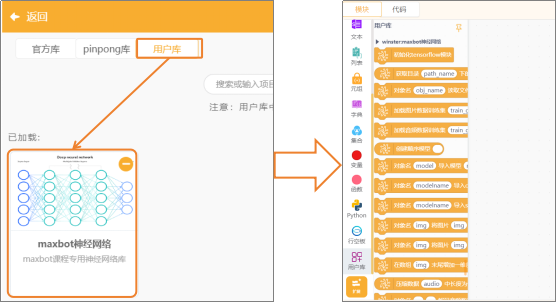
(2)添加用户库:点击“扩展”,在“用户库”中,选择“maxbot神经网络”,并完成添加
3.编写程序
训练语音模型的关键步骤主要分为以下几个部分:导入数据集、数据预处理、创建神经网络、训练模型、保存模型(评估并保存模型)。下面,就根据这几个步骤进行编写程序。
(1)导入数据集
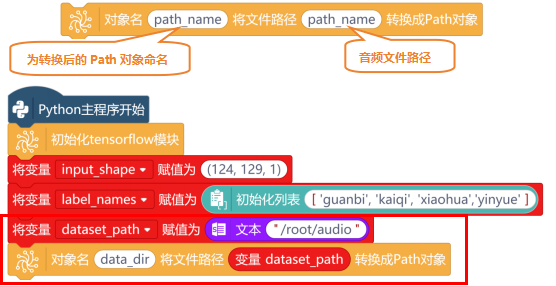
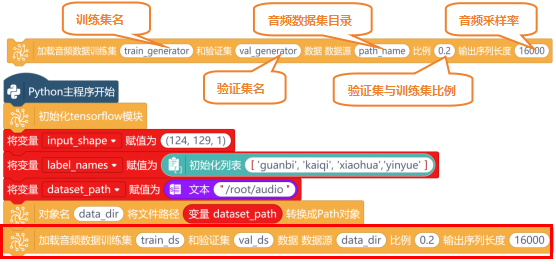
在“Python主程序开始”下,使用“初始化Tensorflow模块”指令,进行初始化。

新建“变量input_shape”,并初始化值为(124,129,1),用于定义音频的输入形状。再新建一个“列表label_names”,初始化列表的值为['guanbi', 'kaiqi', 'xiaohua','yinyue']。
注意:列表中的文件名字符顺序,必须为保存并排序后的音频文件夹名。

确认音频文件数据集目录,使用“对象名 将文件路径 转换成path对象”指令,将音频文件保存的路径(/root/audio)创建一个path路径,用于表示数据集目录。新建“变量dataset_path”,并初始化变量的值为“/root/audio”。
(2)数据预处理
使用“加载音频数据训练集 和验证集 数据 数据源 比例 输出序列长度”指令,从数据集目录中加载音频数据,创建训练集和验证集。其中,比例设置为0.2,表示数据集中20%用于验证集,80%用于训练集。输出序列长度设置为16000,与任务一中音频采样率保持一致。
接下来,就需要使用“将音频训练集 和验证集 转化成频谱图训练集 和验证集”指令,将一系列的数据进行预处理,主要是将音频数据转换成适合神经网络训练的频谱图。
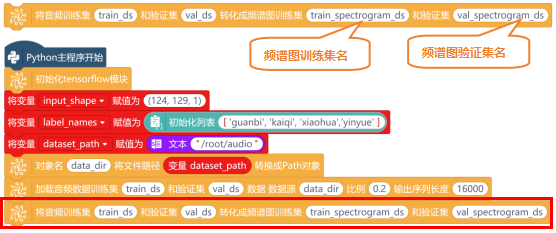
使用“创建顺序模型 ”指令,创建一个序列模型,并将其命名为“audio_model”。新建“变量model”,用来存储创建好的模型。
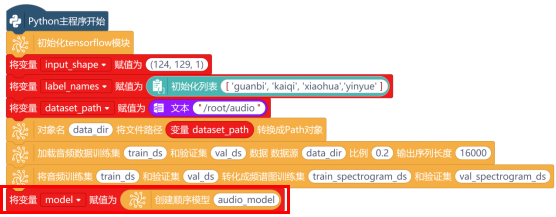
3.构建神经网络
下面,就要开始神经网络模型的构建了,通过添加层顺序进行堆叠,从而构建一个完整的神经网络。首先,使用“为模型 频谱图输出层”指令,为模型添加输入层。

使用“为模型 添加 层”指令和“卷积层,卷积核数量32,激活函数为relu,输入数据格式none”指令,对输入的数据进行卷积操作,以从局部区域中提取特征。其中,卷积核数量32,表示卷积层的滤波器数量,也就是卷积后得到的特征图数量。使用同样的方法,再添加一个卷积核数量64的卷积层。

使用“为模型 添加 层”指令、“池化层”指令以及“展平层”指令,分别为模型添加池化层和展平层。池化层的作用是降低数据的空间维度,减少参数数量,同时保留重要的特征。展平层的作用是将输入数据从多维数组展平成为一维数组,以便传递给全连接层进行处理。

最后,就是添加全连接层(Dense层),使用“Dense层,神经元个数为128 激活函数为relu层”指令,添加第一个全连接层。其中,神经元个数128,表示全连接层包含128个神经元,也就是该层的输出维度。

使用同样的方法,添加最后一个全连接层。修改神经元个数为列表变量label_names的长度,修改激活函数为softmax。这里的神经元个数为音频文件中,录制了几个不同类别的音频数目。激活函数softmax,用于将输出转化为各类别的概率分布,在多分类问题中,通常将最后一层的激活函数设为 softmax。

4.训练模型
神经网络模型构建成功后,就可以使用“打印”指令和“模型 的结构”指令,打印该模型结构。然后使用“设置模型 参数,优化器Adam,损失函数SparseCategoricalCrossentropy,评价函数accuracy”指令,进行模型编译。

模型编译成功后,使用“训练模型 训练数据集 训练次数 验证数据集”指令,进行模型训练。指令中设置训练数据集为train_spectrogram_ds,训练次数为3,验证数据集为val_spectrogram_ds。
5.保存模型
模型训练好后,使用“以saved_model格式保存模型 到”指令,将训练好的模型保存到路径为“/root/audio/saved_model”的文件夹中。

接下来,就使用“将数据集 的音频文件转化为频谱图并保存文件夹”指令,将音频频谱图保存到路径为“/root/audio/spectrogram_images”的文件中。需要注意的是,用于训练集的音频数据量只占总体的80%,因此保存的频谱图会少于总的音频数据。

最后,使用“对象名 显示文字 在X Y 字号 颜色”指令与“更新对象名 的文本内容参数为 ”指令,将训练过程的步骤信息显示在行空板的屏幕上,完整程序如下。

4.程序运行
远程连接192.168.1.80,连接成功后,点击运行。由于这个项目中涉及音频文件导入,数据预处理、神经网络模型构建、训练模型,保存模型,因此程序运行的时间会稍微长一点。模型保存成功后,行空板上和Mind+终端打印区出现“模型已保存”的字样,程序自动终止运行。
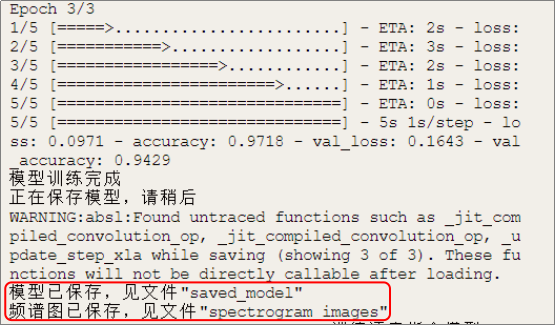
如果想要查看保存好的模型和频谱图,可以通过查看音频文件的方法,找到对应文件名,进行模型和频谱图的查看。频谱图的作用,见知识园地。
任务三:语音控制系统
1.硬件连接
使用type-c转A数据线,将USB音频模块与行空板连接,然后再使用type-c转A线将摄像头连接在音频模块上。

2.软件准备
(1)打开Mind+:按照下面的图示完成软件准备工作。
(2)添加用户库:点击“扩展”,在“用户库”中,选择“numpy”、“maxbot神经网络”、“maxbot音频操作”,并完成添加。
(3)导入音频文件:将音频文件素材文件夹中的“笑话.wav”、“音乐.wav”音频文件,导入项目文件中。
3.编写程序
首先,在“Python主程序开始”下,使用“初始化numpy库”、“初始化tensorflow模块”、“初始化音频处理模块”指令,进行初始化操作。

新建“列表classes”,初始化列表的值为保存并排序后的音频文件夹名['guanbi', 'kaiqi', 'xiaohua','yinyue']。
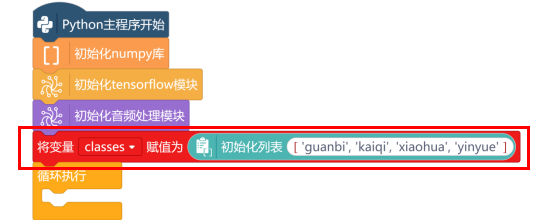
使用“对象名 导入saved_model模型 ”指令,导入训练完成的模型,模型路径为“/root/audio/saved_model”。
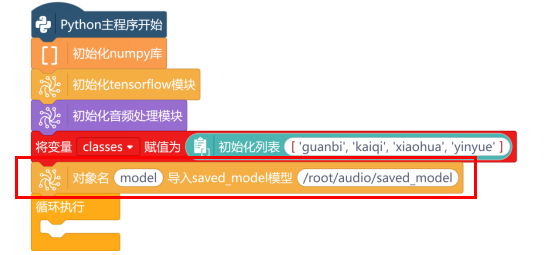
模型导入成功后,新建“变量sample_rate”、“变量record_seconds”,设置对应的音频采样率和音频采样时长。
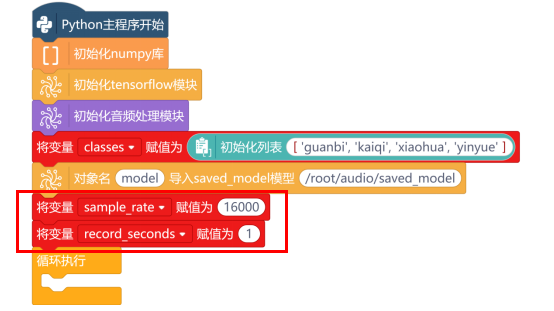
接下来,就可以通过按下行空板的A按键,开始录音了。录音的程序与任务一中采集语音指令一样,只需要修改音频文件的路径为“/root/audio”,音频文件名为“recording.wav”即可。
注意:路径是文本型,需放入“文本 ”指令中。
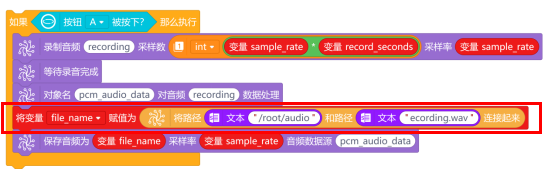
音频保存后,使用“对象名 读取文件 ”指令,读取指定路径“/root/audio/recording.wav”的音频文件内容,并存储在新对象x中。

使用“对象名 解码音频数据 样本数”指令,将对象x中的音频数据,按照样本数16000进行解码,返回解码后的音频数据对象x和新的采样率变量sample_rate_new。
注意:这条指令中第1个变量x,是解码后的音频数据。第2个变量x,是读取的音频文件内容。使用内容替换的方式,替换变量x中的内容,因此没有新建对象名。

音频数据解码成功后,使用“对象名 将单个音频数据 转化成频谱图”指令,对该音频数据进行处理,将它转换成频谱图以便于神经网络处理。

新建数组predictions,然后使用“将数据 传递给模型 ”指令,将音频频谱图数据,传递给模型model进行预测,将预测的结果赋值给数组predictions。这个预测结果是一个数组,包含该语音指令,在每个类别('guanbi', 'kaiqi', 'xiaohua', 'yinyue')中的得分。
例如,输入语音指令“开启”,将开启的音频频谱图在classes('guanbi', 'kaiqi', 'xiaohua', 'yinyue')这四个音频类别中使用训练好的模型model中进行预测,预测结果为predictions = [0.2, 0.7, 0.1, 0.2]。

通过“[ ] 的计算最大值位置”指令,返回数组predictions中最大值的位置。然后,新建“变量result”,使用“列表 索引 的值”指令,从列表classes中,索引出对应的类别名称,并赋值将类别名称赋值给变量result。
数组predictions的最大值为0.7,对应的位置是1(数组的位置从0开始计算)。从列表classes('guanbi', 'kaiqi', 'xiaohua', 'yinyue')中,索引出1的值为“kaiqi”。因此,变量result的值为“kaiqi”,也就是说音频识别结果为“kaiqi”。

最后,使用“如果 那么执行”指令,进行判断。当变量result等于“kaiqi”时,使用“设置数字引脚 输出”指令,控制连接到引脚P1,P4的LED灯,输出高电平;当变量result等于“guanbi”时,使用“设置数字引脚 输出”指令,控制连接到引脚P1,P4的LED灯,输出低电平;当变量result等于“yinyue”时,使用“播放音频文件 直到结束”指令,控制音频模块播放音乐;当变量result等于“xiaohua”时,使用“播放音频文件 直到结束”指令,控制音频模块播放笑话。
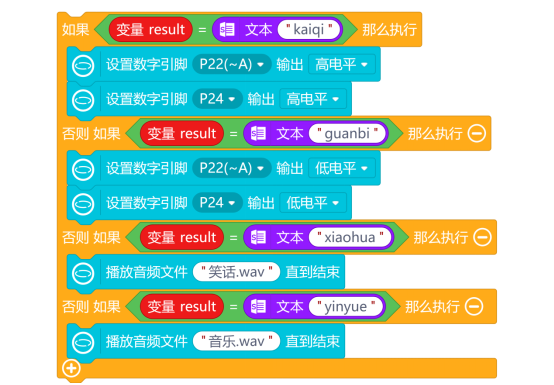
添加“打印”指令,“对象名 显示文字 在X Y 字号 颜色”指令,“更新对象名 的文本内容参数为 ”指令,提示语音识别过程中执行的步骤,完整程序如下。

4.程序运行
远程连接192.168.1.80,连接成功后,点击运行。当Mind+终端中打印“模型导入成功,按下A键以录音1秒”后,就可以开启语音指令的识别了。例如,按住A按键,对着麦克风说语音指令“开启”,语音识别成功后,小车上的LED灯亮起。

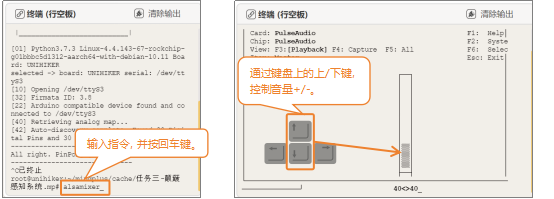
注意:若播放音乐过程中你听到的声音较小或没有声音,需要在行空板“终端区”调整音量。操作时,首先停止运行代码,并在“终端区”输入“alsamixer”并按回车键,然后按下键盘上的上下箭头键,控制音量增减,操作完成后只需要按下“Esc”键退出设置。需要将音量设置大于25,低于25时,声音很小,几乎听不清楚。
知识园地
1.语音识别技术,也被称为自动语音识别
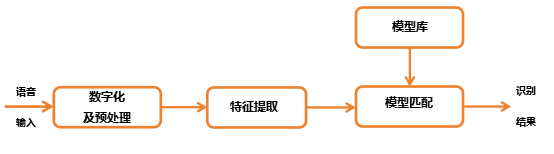
(Automatic Speech Recognition,简称ASR)是让机器通过识别把语音信号转变为相应的文本或命令的人工智能技术,也就是让机器听懂人类的语音的技术。它的基本工作流程是,将录入的声音进行数字化和预处理之后,通过特征提取获得能够表征语言特点的特征向量,然后通过加入模型库进行模式匹配,获得概率最高的文本,输出最终结果。
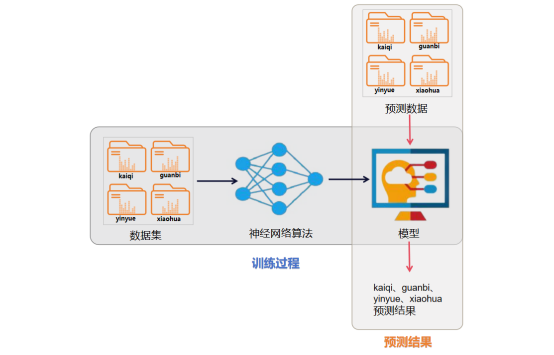
下面,通过一张图,来了解一下语音识别系统从数据集训练到实际应用预测的完整流程。
2. 认识频谱图并了解其作用
语音识别的核心任务是将语音信号转化为文本或执行指令。在这个过程中,语音模型扮演着至关重要的角色,它直接决定了语音识别系统的性能和准确性。训练语音模型的关键步骤主要分为5部分:导入数据集、数据预处理、创建神经网络、训练模型、保存模型。

细心的同学一定发现了,训练语音模型的步骤与之前学习过的训练物体识别模型的步骤是一样。但是,在保存语音识别模型时,还保存了频谱图。


频谱图是一种用于可视化音频信号的工具,它显示了音频信号在不同频率上的能量分布情况。频谱图通常是在时间和频率两个维度上绘制的,横轴表示时间,纵轴表示频率,而颜色或亮度表示每个时间点上的频率成分的能量强度或振幅。
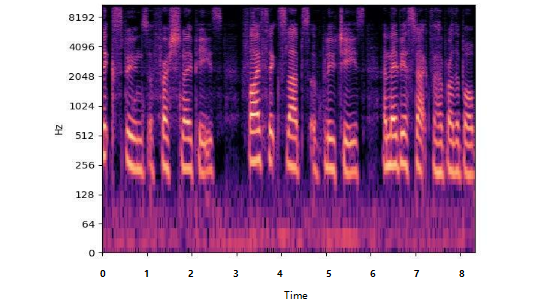
频谱图是声音的可视化工具,能够直观展示声音的频率和能量分布。它就像声音的照片,展示了声音在不同时间和不同频率上的变化。频谱图的主要作用就是帮助我们理解声音的细节、识别声音模式。
1.理解声音的细节:通过频谱图,你可以看到声音中有哪些高音和低音部分。比如,你可以看到音乐中高音的钢琴声和低音的鼓声在什么时候出现。
2.识别声音模式:频谱图可以帮助我们识别不同的声音特征。比如,在语音识别中,可以看到说话时每个字母和单词的频率变化,这有助于计算机识别我们在说什么。
3.指令学习
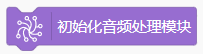 |
| 这条指令用于导入录音和音频处理相关的库。 |
 |
| 这条指令主要是用于根据设置好的采样数和采样率进行音频录制。 |
 |
| 这条指令是用于确保录制音频完成。 |
 |
| 这条指令主要作用对录制好的音频进行统一的数据处理。 |
 |
| 这条指令用于将录制好的音频按照设置的采样率和数据源进行保存。 |
 |
| 这条指令的作用是基于指定目录中的音频文件创建训练集和验证集的数据生成器。生成器将会根据设定的参数从目录中加载音频数据,并按照指定的批次大小和输出序列长度生成相应的数据流,用于模型的训练和验证。 |
 |
| 这条指令的作用是对音频数据进行预处理,将原始的音频波形转换为频谱图,并准备成可以用于训练的数据集。 |
 |
| 这条指令的作用是将原始的音频波形数据经过处理,转换为频谱图,并为神经网络模型的输入做好准备。 |
 |
| 这条指令主要是使用 TensorFlow对输入的音频数据 x 进行解码,将其转换为原始的音频波形数据。 |
 |
| 这条指令主要是将输入的音频数据传递给训练好的模型,对音频数据进行预测和推断。 |
挑战自我
既然可以使用语音指令,控制小车上的LED灯亮、灭。那大家想一想,是否可以通过前进、后退语音指令控制小车执行对应的操作呢?在采集语音指令数据时,采集好“前进”、“后退”的语音指令即可。接下来,大家自己试一试吧!



 他的勋章
他的勋章

罗罗罗2025.11.19
666