 返回首页
返回首页
 回到顶部
回到顶部
1.项目介绍
1.1项目简介
在当今数字化时代,语音识别技术在诸多领域发挥着重要作用,从智能语音助手到智能家居控制。语音识别技术能够将人类的语音信号转换为文字或命令,为我们带来便捷的交互体验。
本项目使用 Mind+ 的 AI 工具库 - 音频分类工具库,通过图形化代码,直观地看到语音信号处理和特征提取的过程。并且,在实践中使用自定义的语音数据集,通过神经网络训练出语音分类模型,最终在电脑端应用语音模型完成对特定语音命令的识别,实现控制设备开关灯的功能。
1.2项目效果视频
【mind+实现AI项目:基于音频嵌入与全连接神经网络的语音识别控制系统】
2.AI知识介绍
2.1 音频嵌入
定义:通过数学方法将音频信号(如波形)转换为固定长度的低维向量(例如128维数组),该向量能表征音频的关键特征。
技术方法:
•传统特征提取:如MFCC(梅尔频率倒谱系数),通过时频变换提取音色、节奏等特征。
•深度学习模型:使用预训练网络(如VGGish、Wav2Vec)对音频进行编码,生成高维语义向量。
核心应用:
•语音识别与指令理解
如智能助手(Siri、Alexa)将语音转换为文本,依赖音频嵌入捕捉音素、语调等信息。
•说话人识别与验证
通过嵌入向量区分不同人的声音特征,用于身份验证或客服场景。
•音乐信息检索与推荐
嵌入可表示歌曲的风格、节奏,助力相似歌曲推荐或播放列表生成(如Spotify)。
•情感分析与内容理解
检测语音中的情绪(愤怒、喜悦),应用于客服质检或心理健康监测。
•异常检测
识别工业设备异常噪音(如机械故障)或环境危险声音(如玻璃碎裂)。
• 生成式任务
嵌入作为语音合成(TTS)或音乐生成的中间表示,提升生成内容的质量。
优势:降维保留关键信息,提升计算效率,并支持跨任务迁移学习。
2.2 全连接神经网络
语音识别模型通常基于深度学习中的神经网络构建。常见的语音识别模型有全连接神经网络、循环神经网络(RNN)及其变体长短时记忆网络(LSTM)和门控循环单元(GRU),以及卷积神经网络(CNN)。这些模型能够学习音频特征与对应文本或命令之间的映射关系,从而实现语音识别的功能。
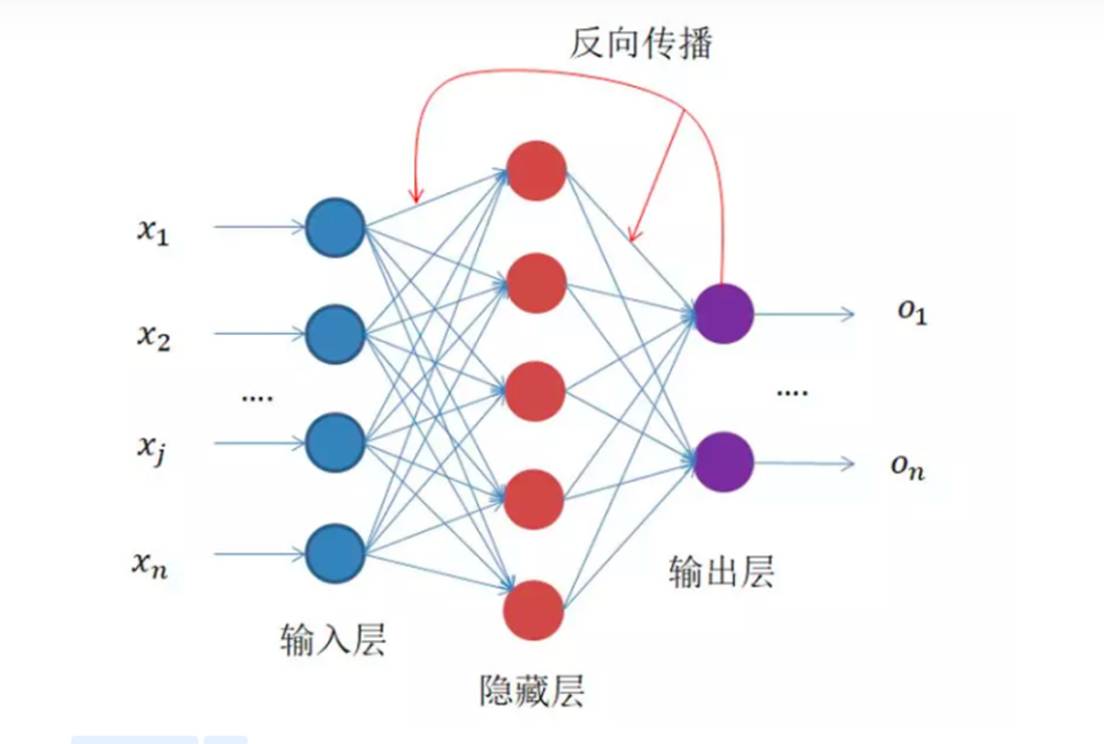
全连接神经网络(Fully Connected Neural Network, FCNN)
定义
全连接神经网络是一种基础的人工神经网络模型,其核心特点是相邻层的所有神经元之间两两连接。它通过多层非线性变换,学习从输入数据到输出目标的映射关系,适用于解决分类、回归等任务。
核心结构组成
1.输入层
○ 作用:接收原始数据或预处理后的特征(例如音频嵌入向量、图像像素值等)。
○ 神经元数量:由输入数据的维度决定(如128维音频嵌入对应128个输入神经元)。
2.隐藏层
○ 作用:提取数据的深层特征。
○ 关键特性:
▪每层神经元接收前一层所有神经元的输出信号,并产生新的输出信号。
▪使用激活函数(如ReLU)引入非线性,使模型能够学习复杂模式。
○ 典型设计:通常包含1~3层,神经元数量逐层递减(如128 → 64 → 32)。
3. 输出层
○ 作用:根据任务类型生成最终结果。
○ 常见配置:
▪分类任务:使用Softmax激活函数输出类别概率分布(如“80%是猫叫,20%是狗叫”)。
▪回归任务:直接输出数值(如预测音频的响度值)。
2.3 基于音频向量分类的实现
通过音频嵌入+全连接网络进行分类的典型流程:
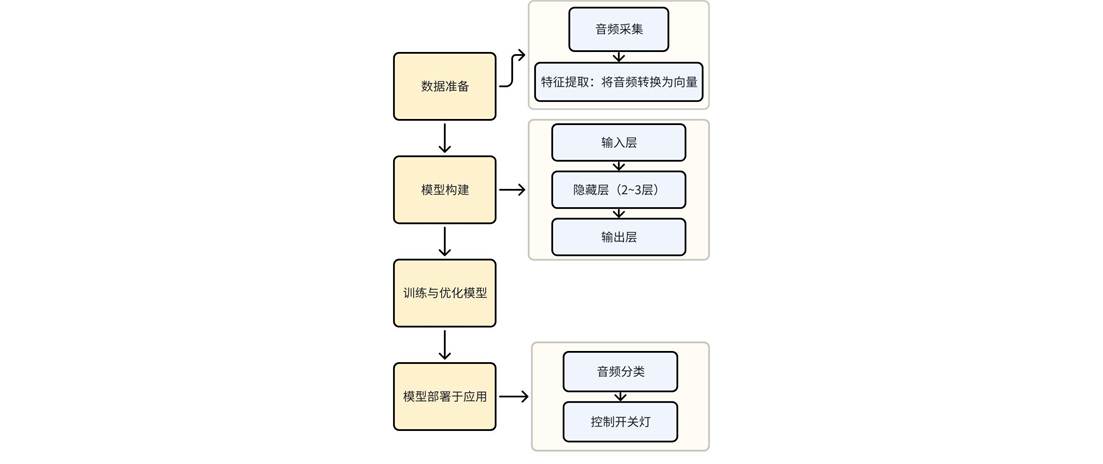
步骤1:数据准备
• 特征提取:将音频转换为向量,常用方法包括:
○ MFCC(梅尔频率倒谱系数):捕捉语音的音色特征。
○ 预训练模型:生成高维语义嵌入。
• 预处理:归一化、降噪、数据增强。
步骤2:模型构建
• 输入层:维度与音频向量一致(如128维)。
• 隐藏层:2~3层,每层神经元数递减(如256→128→64),使用ReLU激活。
• 输出层:神经元数等于类别数,Softmax激活输出概率。
步骤3:训练与优化
• 损失函数:交叉熵损失(CrossEntropyLoss)。
• 优化器:Adam(自适应学习率调整)。
• 正则化:Dropout、L2正则化防止过拟合。
• 评估指标:准确率、F1分数、混淆矩阵。
步骤4:部署与应用
• 模型轻量化以适应设备。
• 实时分类场景(如语音指令识别)可优化推理速度。
2.4 AI 工具库介绍
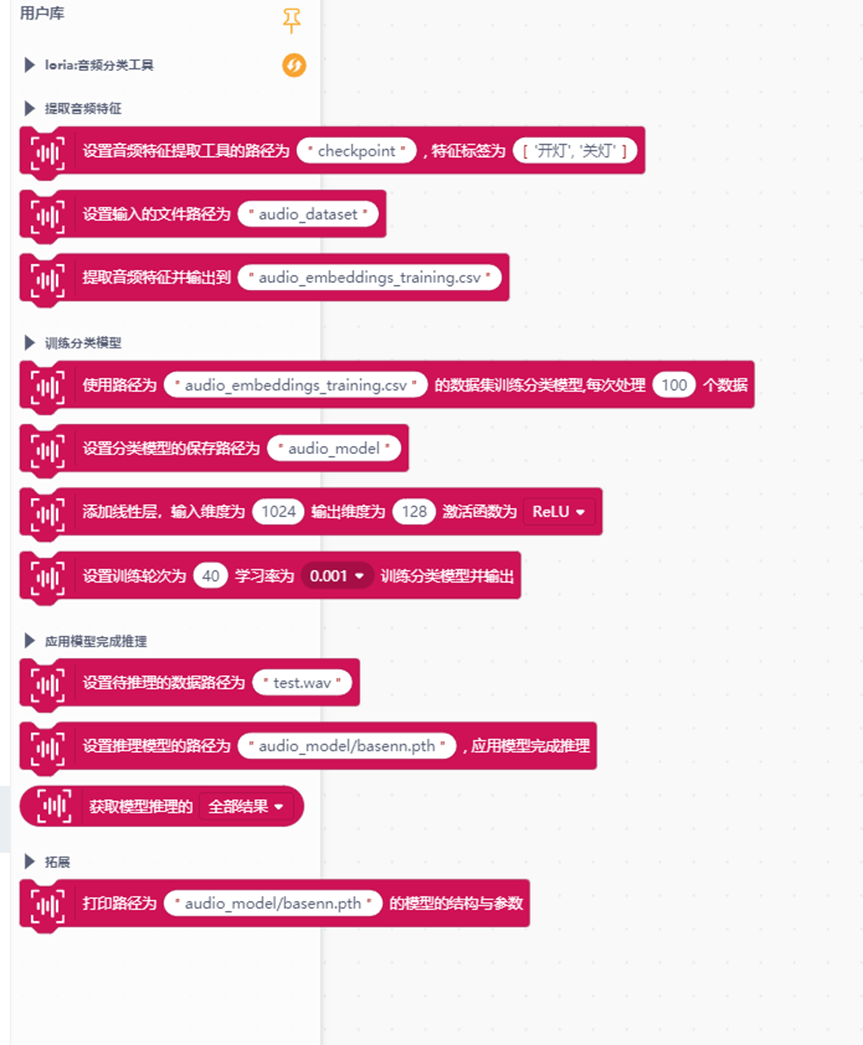
在 Mind+ 软件中有一个名为“音频分类工具”的 AI 工具库,它支持语音信号的采集、特征提取以及语音分类模型的训练与应用,如下图。

这个库包含了三大功能:第一部分是提取音频特征并输出文件;第二部分是通过数据集训练模型;第三部分是应用模型完成推理。通过此库,我们可以在教学中降低语音识别技术的学习门槛,借助直观的图形化编程和可视化界面,帮助学生理解语音信号处理和特征提取的过程,同时能够快速构建和训练语音识别模型,完成特定的语音识别任务。
3.软硬件环境准备
3.1软硬件器材清单

3.2软件环境准备
本项目需要在电脑端和行空板端分别安装库。
3.2.1 64位电脑系统离线安装库
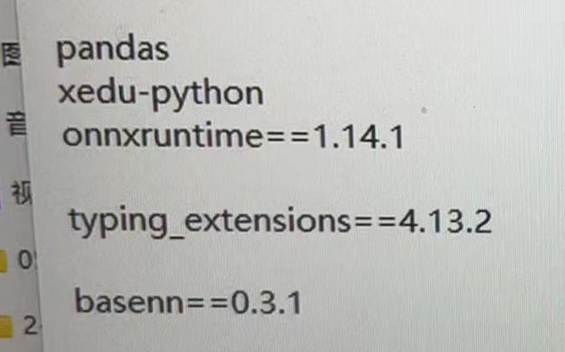
本项目需要在电脑端安装xedu-python==0.2.3 BaseNN==0.3.1
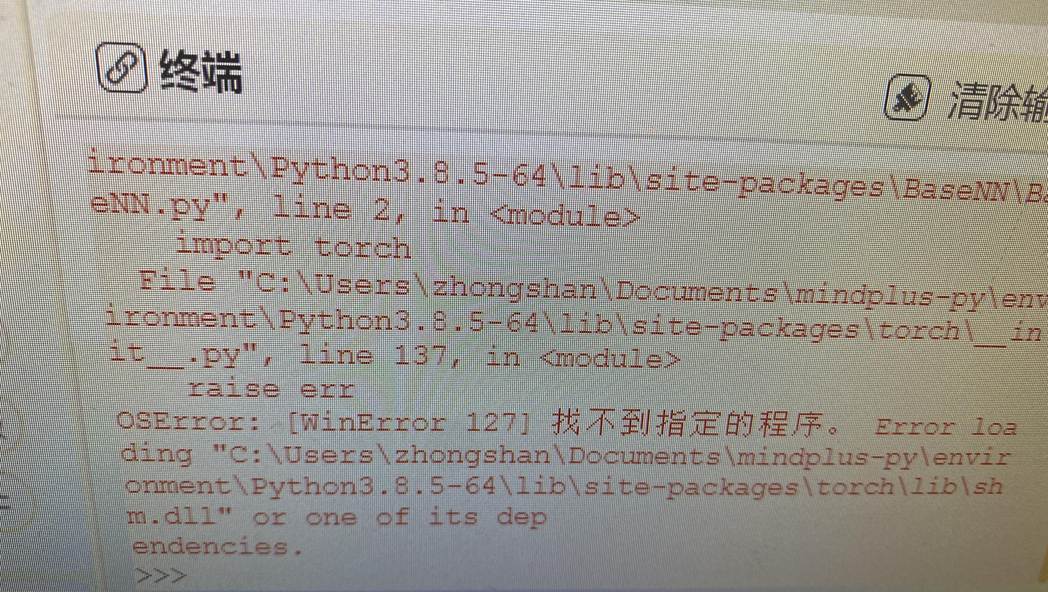
关于环境安装,如果程序运行出现这样类似的报错,大概率是电脑端环境没有安装成功。
一键安装包中有些python库版本可能不适用win7的python环境,可以自我检查并手动在电脑端安装以下版本的依赖库。
3.2.2 行空板上装库
连接行空板,在行空板端需要安装:xedu-python==0.2.3 BaseNN==0.3.1
(具体操作见上面视频)
3.2.3 在软件中添加图形化用户库
在Mind+软件中点击左下角'扩展库',在用户库中搜索一下链接:https://gitee.com/limengya10204507415/ext-audio_classification,搜索并点击加载'音频分类工具'库。

4.行空板语音控制开关灯项目制作
项目制作主要分为四个步骤:数据采集、特征提取、模型训练、部署模型并应用到行空板。
1.数据采集(行空板):创建音频数据集文件夹,使用行空板采集音频数据
2.特征提取(电脑端):断开行空板,在电脑端使用音频特征提取工具(audio_embedding model)提取音频特征写入csv文件
3.模型训练(电脑端):在电脑端使用音频特征csv文件搭建全连接神经网络训练音频特征分类模型
4.模型部署和应用(行空板):部署音频特征模型到行空板M10实验盒,应用模型实现语音控制行空板亮灯和熄灭灯
4.1行空板端采集音频
相关文件和操作视频
操作步骤:
使用USB数据线连接电脑与行空板,在编写录音程序前先在右侧项目中的文件创建音频数据集文件夹.按照以下格式创建文件夹
└─audio_dataset //音频数据集文件夹
│
└─class_1 // 存放类别1音频的文件夹,这里的类别名就是语音内容
└─class_2 // 存放类别2音频的文件夹
如下图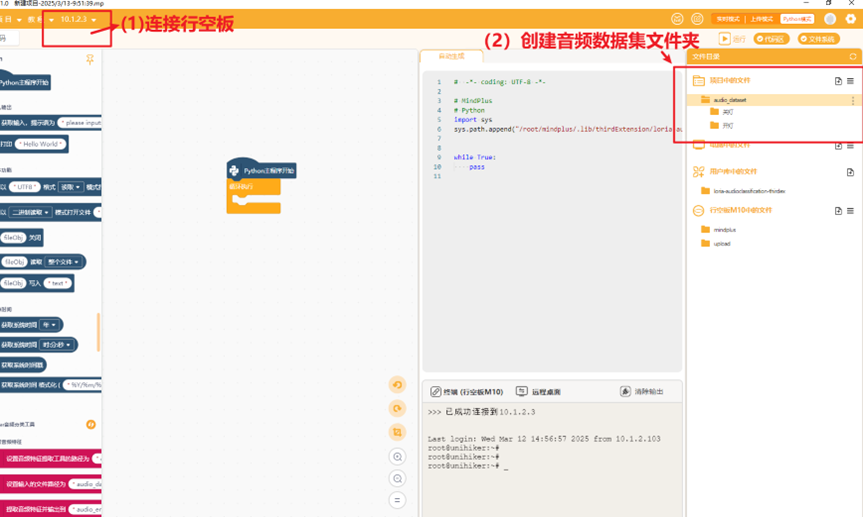
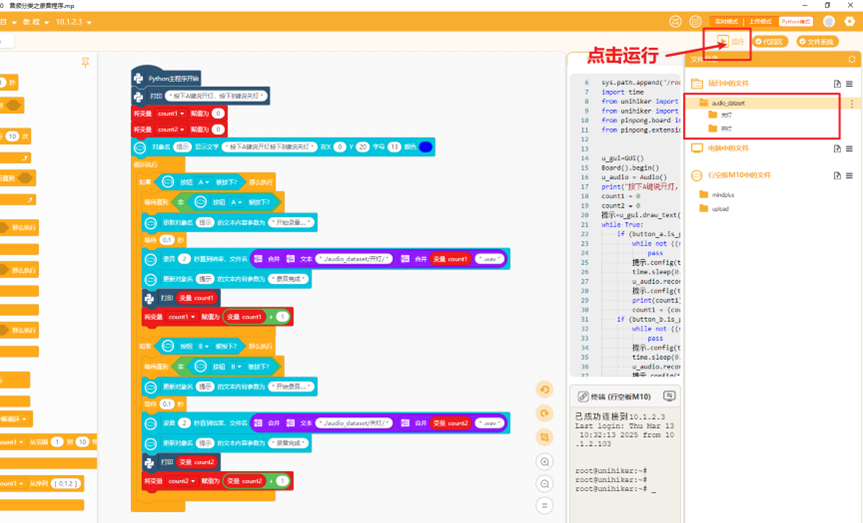
接着编写录音程序,使用行空板麦克风录音,自动将音频文件存放到对应类别文件夹,如下图
运行程序,按下A键,观察行空板屏幕出现“开始录音”,对准麦克风说“开灯”,录制最少30-40条左右,效果比较好;按下B键,观察行空板屏幕出现“开始录音”,对准麦克风说“关灯”,两类音频的录制条数最好保持一致
录制完找到音频文件,点击下载到电脑,方便后续在电脑端提取音频特征和训练模型,如下图
运行程序,按下A键,观察行空板屏幕出现“开始录音”,对准麦克风说“开灯”,录制最少30-40条左右,效果比较好;按下B键,观察行空板屏幕出现“开始录音”,对准麦克风说“关灯”,两类音频的录制条数最好保持一致
录制完找到音频文件,点击下载到电脑,方便后续在电脑端提取音频特征和训练模型,如下图
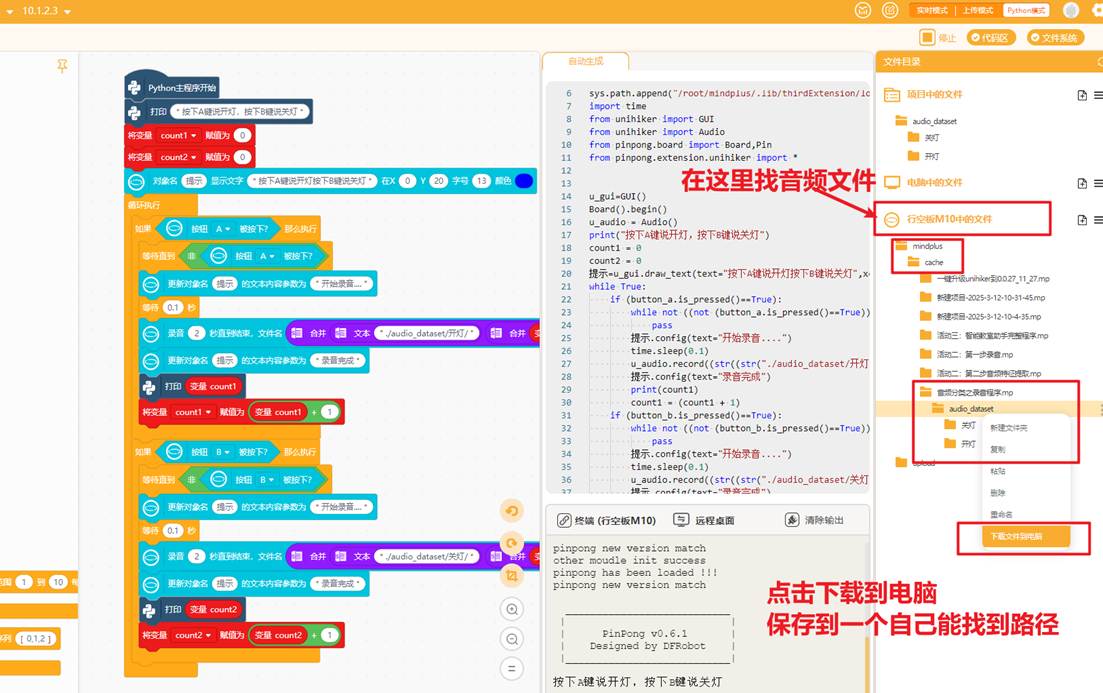
4.2电脑端提取音频特征
相关文件和操作视频
操作步骤:
断开行空板的连接,将音频数据集文件和音频特征提取工具(checkpoint文件夹)拖入项目中的文件目录下,编写特征提取程序,运行即可
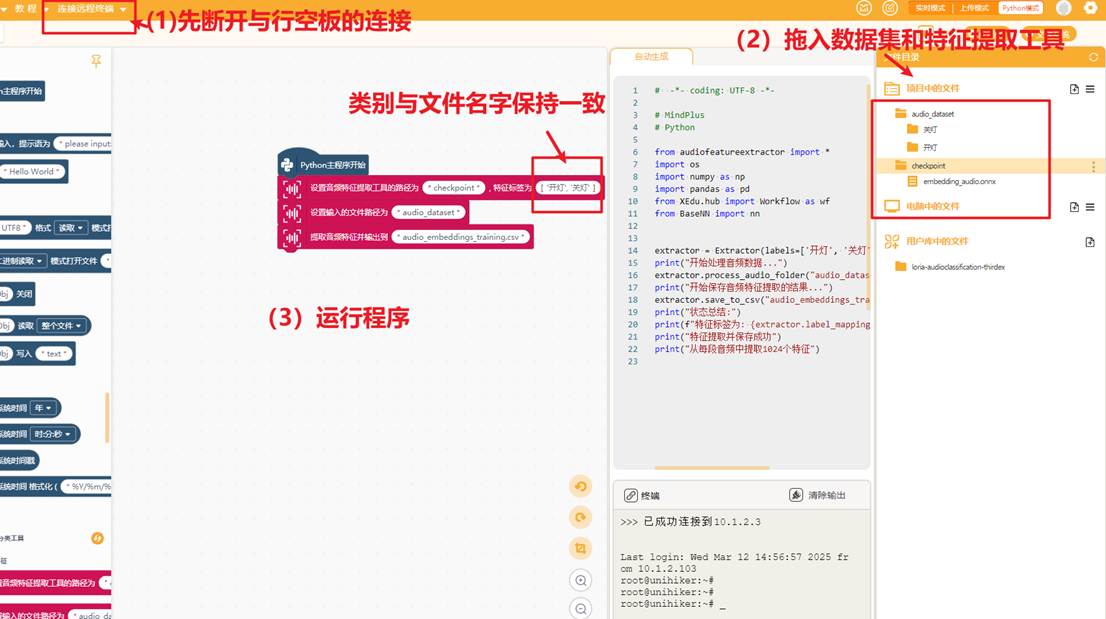
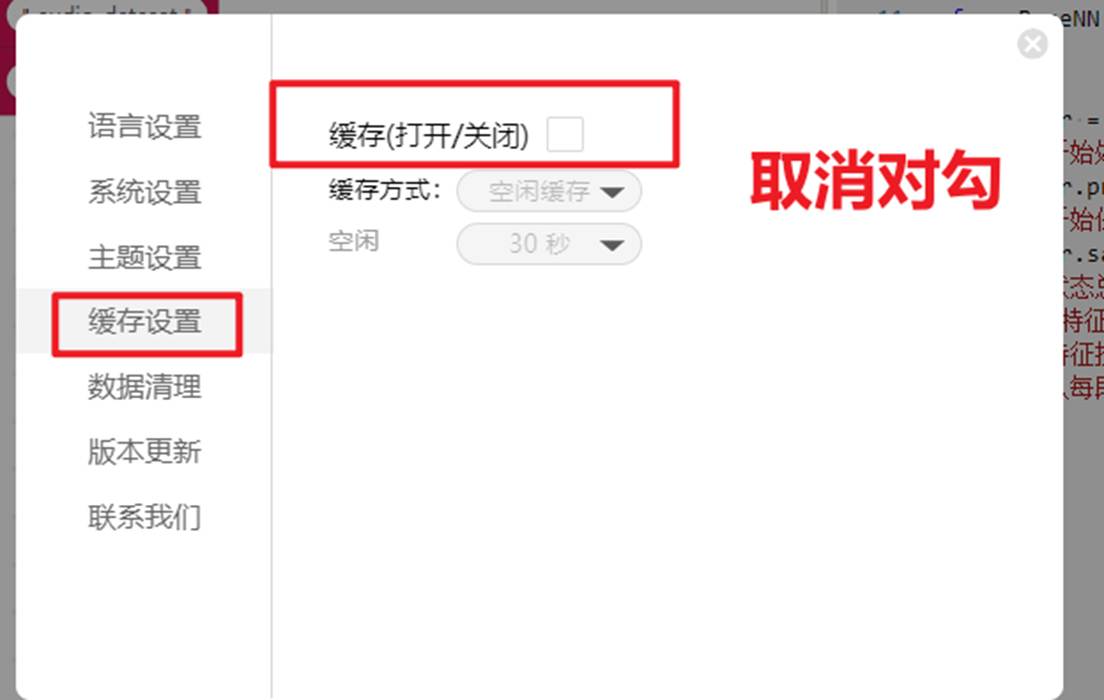
注意请先关闭mind+自动缓存,避免卡顿
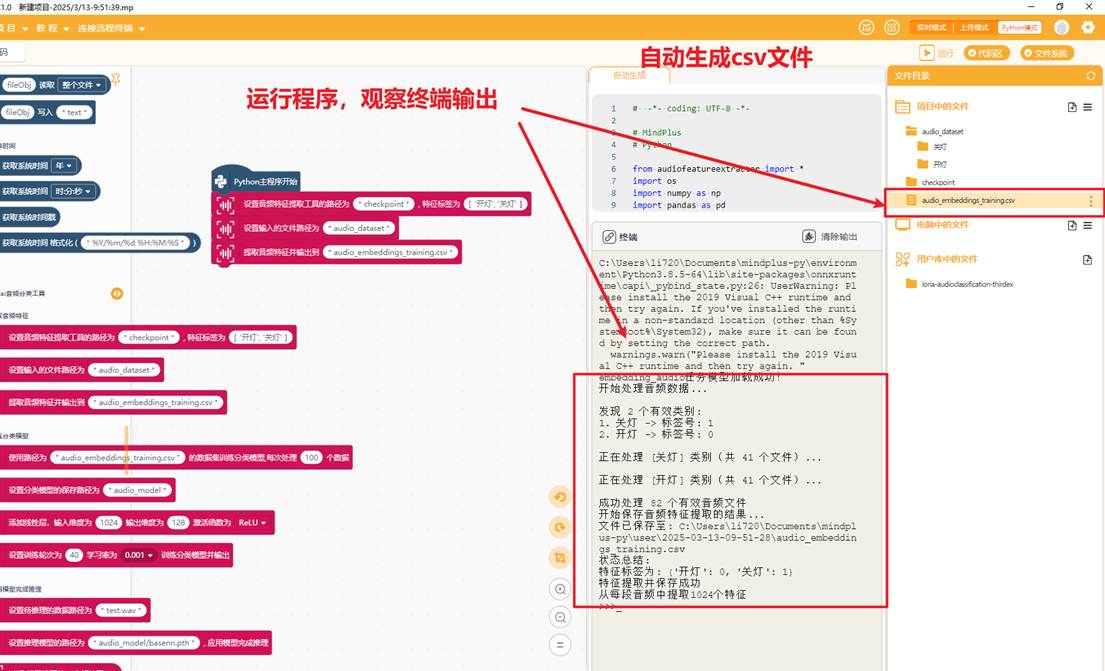
程序运行后会自动出现保存音频特征的csv文件
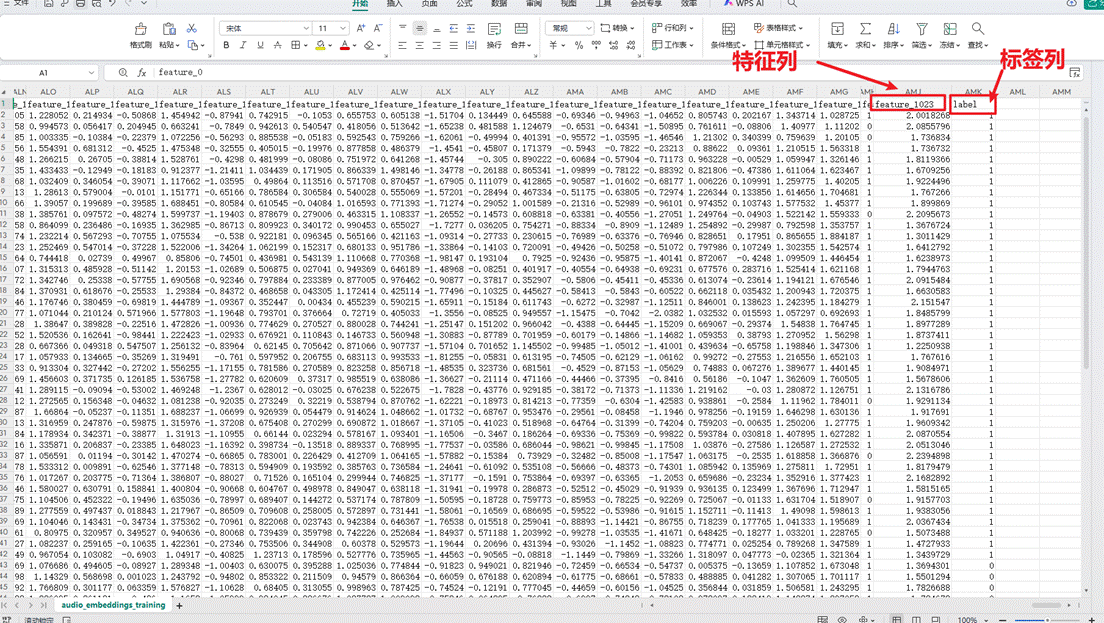
可以自行打开csv文件观察,发现这个csv列表一共有1025列,其中1024列是音频特征列,1列是标签列,audio_embedding 模型从每一个音频中提取了1024个音频特征并以数字化的形式显示,我们可以用这些特征来训练分类模型,csv文件如下图。
4.3电脑端训练音频特征分类模型
相关文件和操作视频
操作步骤:
提取完特征后,使用音频特征训练音频分类模型,这里使用的是全连接神经网络,(第一层的输入层的维度是特征数量,这里是1024。每一层的输出层的维度与下一层输入层的维度数量相等)最后一层的输出维度是特征标签数量。训练模型的程序如下。
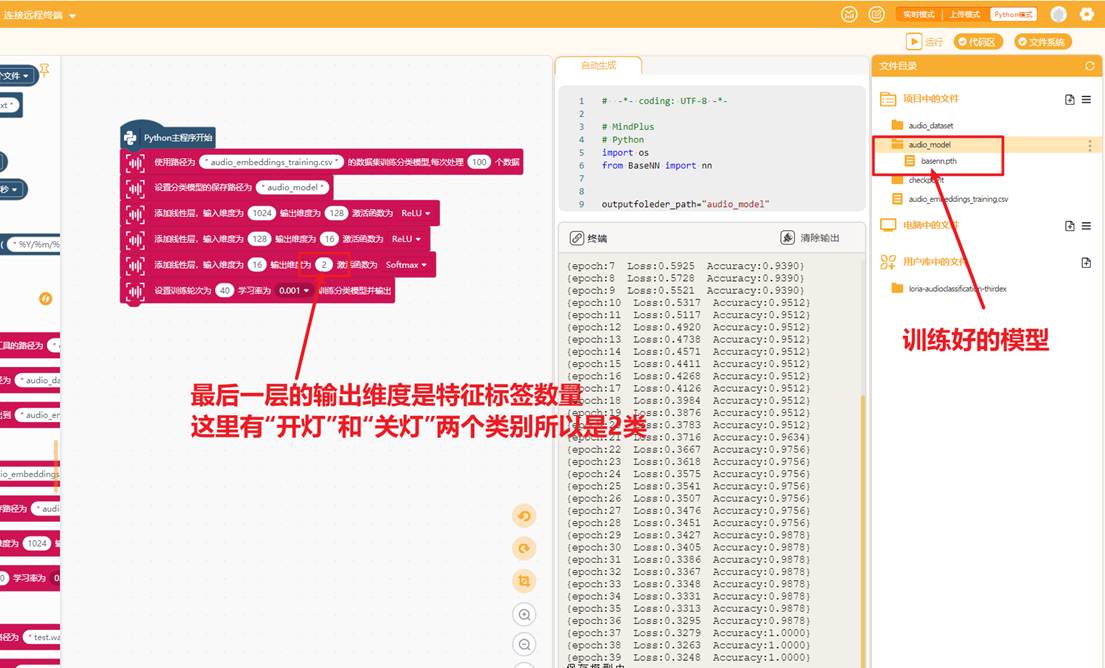
可以使用模型在电脑端进行推理,秉承着"用什么训练,用什么推理"的原则,这里是使用checkpoint中的audio_embedding模型将test.wav文件转成1024维度的向量,将向量输入到我们自训练的模型推理,获取结果
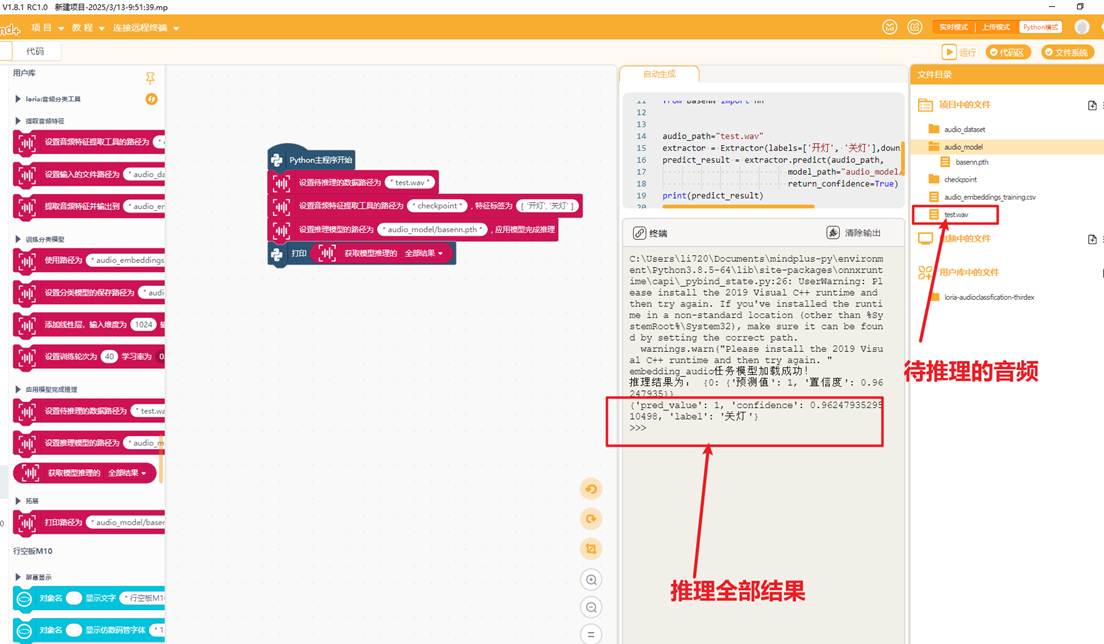
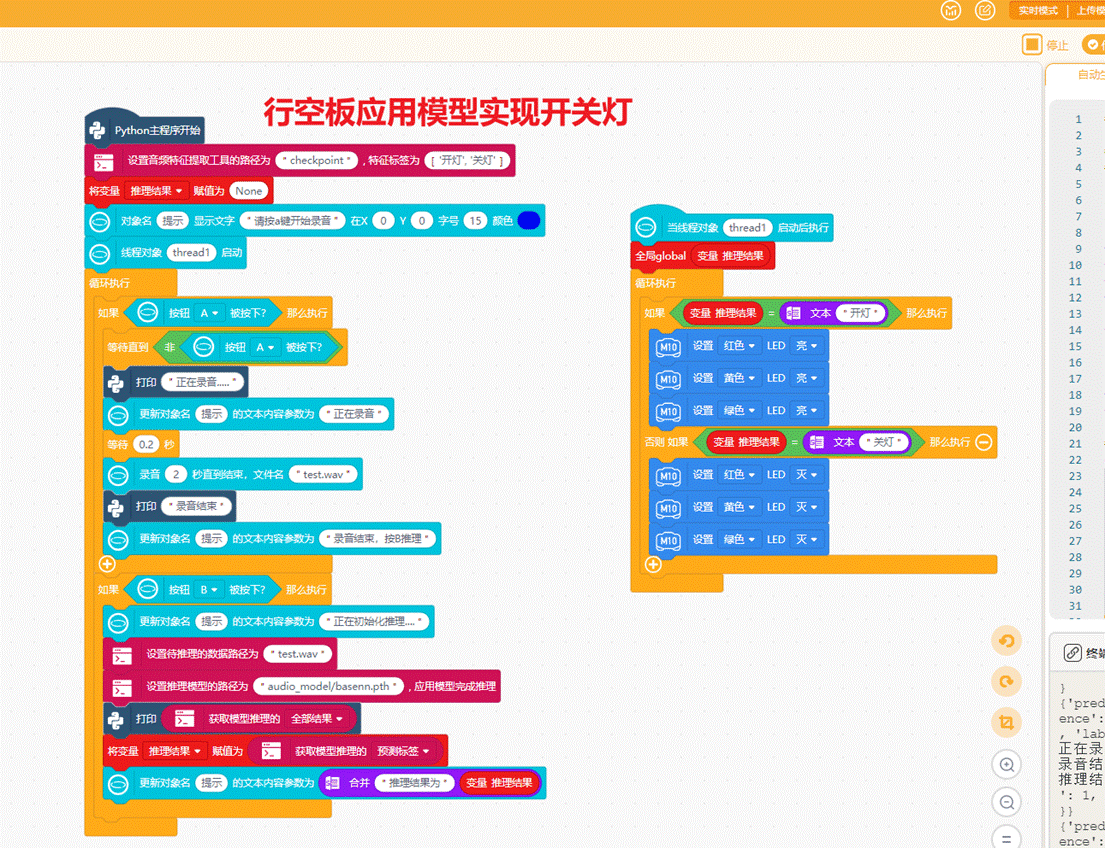
4.4部署模型到行空板实现开关灯
相关文件和操作视频
行空板实验盒的用户库链接:https://gitee.com/zhaoruiz/ext-unihiker-box
操作步骤:
连接行空板,确保右侧项目中的文件有"checkpoint"文件夹和"audio_model"文件夹,可以使用以下程序实现语音控制行空板实验盒开灯和熄灭灯
5.常见问题
5.1如果遇到找不到指定程序的错误怎么办?
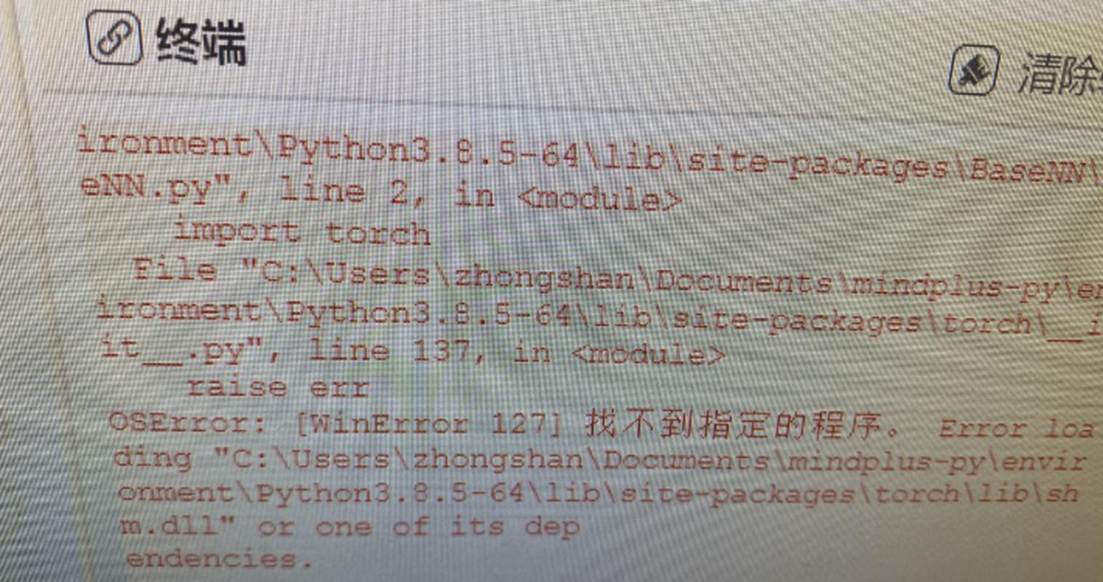
出现这样的报错,大概率时因为运行此库的python依赖库没有安装成功,或者库版本不对。这里列出了win7系统下使用此用户库所需要的python依赖版本,请自我检查。

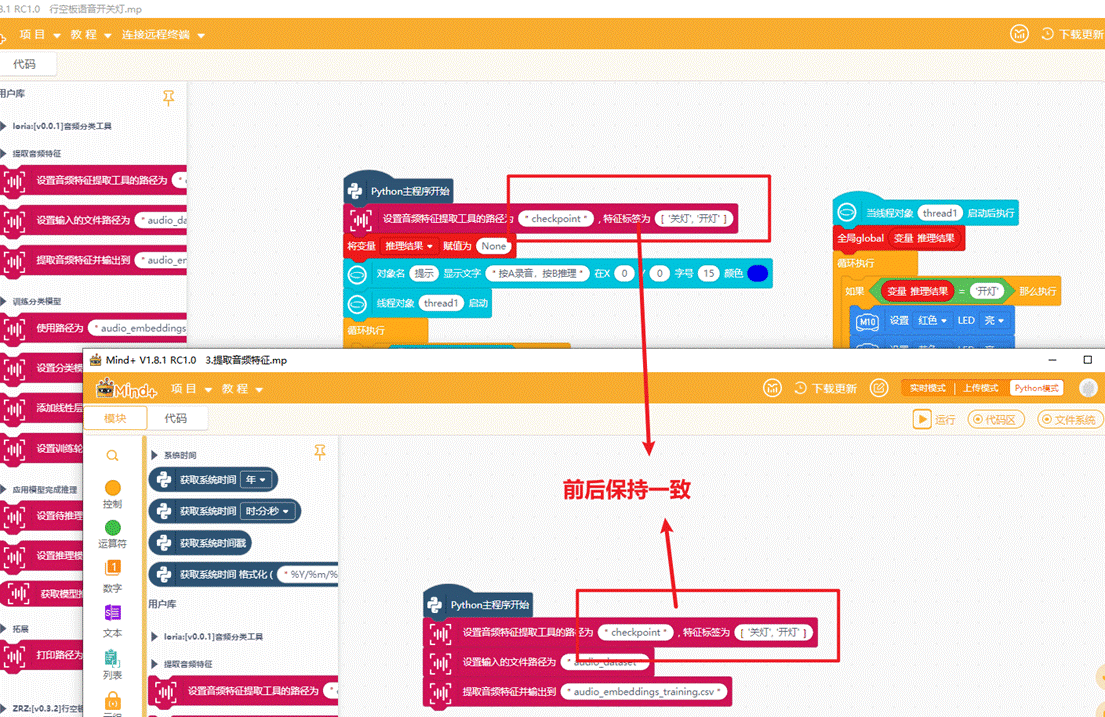
5.2提示:前后特征标签的顺序必须保持一致
在提取音频特征时和应用模型完成开关灯项目时,前后特征标签的顺序必须保持一致,如下图。否则模型影响推理的结果。
5.3其他出错怎么办?
1.Python中,如果出错,则会在“终端”中打印信息,因此,排查错误主要依耐“终端”输出的信息
2.可以将出错信息复制关键词 ,在行空板官方文档中搜索查找是否有对应解决方案:行空板官方文档
3.可以将“自动生成”的代码和“终端”输出的信息,发给各种大语言模型分析问题,例如chatGPT、文心一言、讯飞星火等
4.加入行空板官方群查找解决办法
6.附件
项目相关文件链接: https://pan.baidu.com/s/16kdemcWTkhWPaPRBLfO_wA?pwd=hawc



 他的勋章
他的勋章


罗罗罗2025.11.19
666