 返回首页
返回首页
 回到顶部
回到顶部
1. 闯关任务
端侧小模型论文分类微调练习打榜赛 赛中提交结果超过基线,并提交复现文档。
2. XTuner介绍
一句话介绍XTuner:
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。
核心特点:
高效:支持在有限资源下微调大模型,如在8GB显存上微调7B参数模型,也支持多节点微调70B+模型;自动分发高性能算子加速训练;兼容DeepSpeed优化策略。
灵活:支持多种大语言模型(如InternLM、Llama、ChatGLM等)和多模态模型;支持多种数据格式;支持QLoRA、LoRA、全量参数微调等多种微调算法。
全能:支持增量预训练、指令微调与Agent微调;预定义多种对话模板;训练所得模型可无缝接入部署工具LMDeploy和评测工具OpenCompass。
3. 环境安装
在创建开发机界面选择镜像为 Cuda12.2-conda,并选择 GPU 为50% A100(越大越好)。
Conda 管理环境
conda activate /root/share/pre_envs/pytorch2.3.1cu12.1
pip install 'xtuner[deepspeed]' timm==1.0.9
pip install transformers==4.48.0
pip install modelscope
输入xtuner list-cfg检验环境安装
4. 数据获取
关于数据详情参考InternLM论文分类微调实践(swift 版)数据部分
原本的数据是swift版本,因此需要代码转化。这里直接贴现成的数据sftdata.jsonl给大家:
convert_to_alpaca.py(数据转化仅供参考)
5. 训练
链接模型位置命令
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat ./
微调脚本
internlm2_5_chat_7b_qlora_alpaca_e3_copy.py
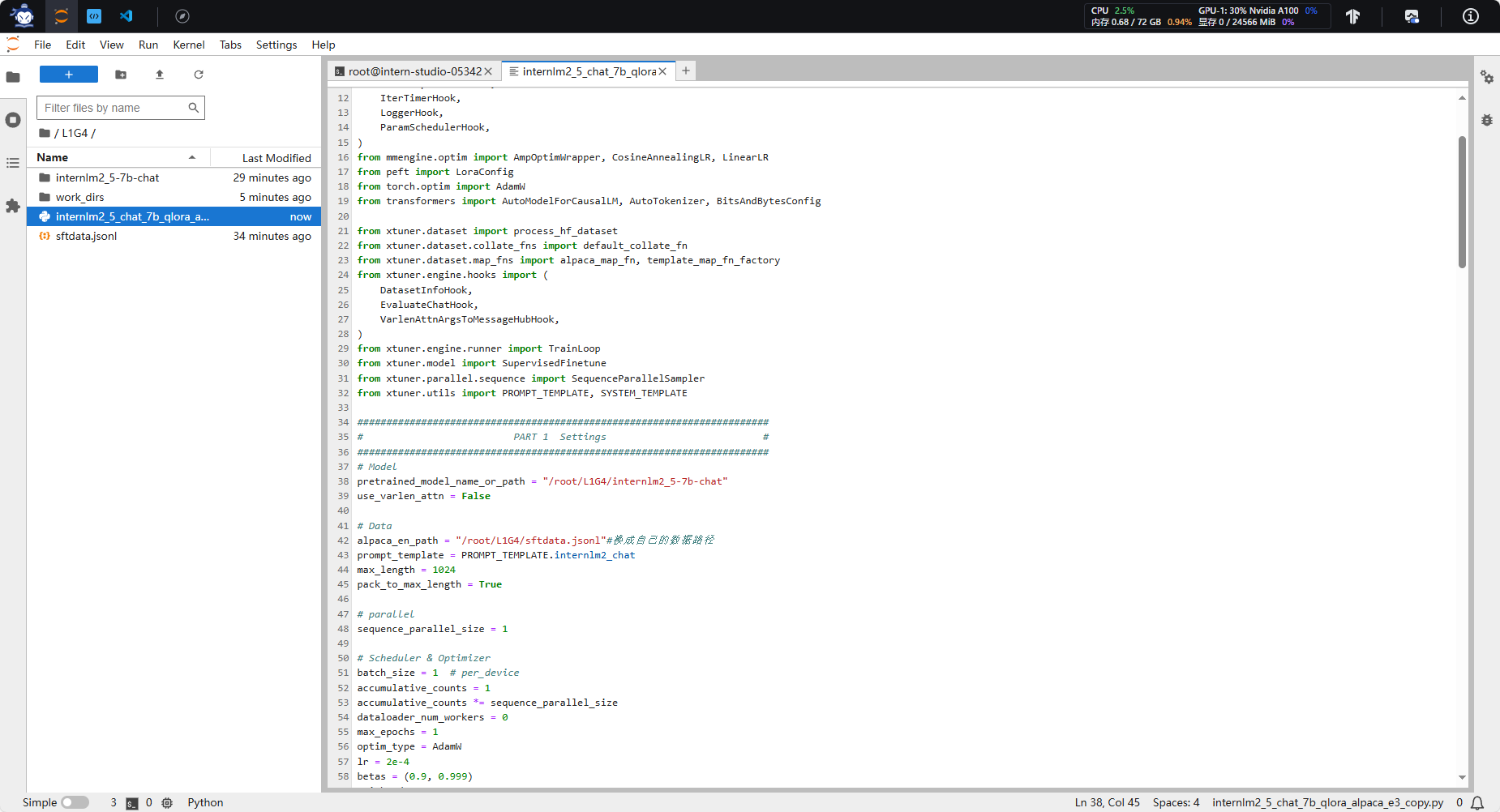
pretrained_model_name_or_path alpaca_en_path 只需要注意34和38行模型、数据位置就好了。
# Copyright (c) OpenMMLab. All rights reserved.
# —— 动态补丁:兼容 transformers>=4.48 ——
from transformers.cache_utils import DynamicCache # 1. 引入类
if not hasattr(DynamicCache, "get_max_length"): # 2. 判断是否缺失
DynamicCache.get_max_length = DynamicCache.get_max_cache_shape # 3. 补一个别名
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (
CheckpointHook,
DistSamplerSeedHook,
IterTimerHook,
LoggerHook,
ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (
DatasetInfoHook,
EvaluateChatHook,
VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "./internlm2_5-7b-chat"
use_varlen_attn = False
# Data
alpaca_en_path = "/root/L1G4/sftdata.jsonl"#换成自己的数据路径
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 1024
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 2 # per_device
accumulative_counts = 1
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 1
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 50
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 50
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["请给我介绍五个上海的景点", "Please tell me five scenic spots in Shanghai"]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side="right",
)
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
),
),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=16,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
),
)
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, path='json', data_files=alpaca_en_path),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=alpaca_map_fn,
template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn,
)
sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale="dynamic",
dtype="float16",
)
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True,
),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True,
),
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template,
),
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit,
),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend="nccl"),
)
# set visualizer
visualizer = None
# set log level
log_level = "INFO"
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
启动
启动脚本
cd #你的项目根目录
xtuner train internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero1
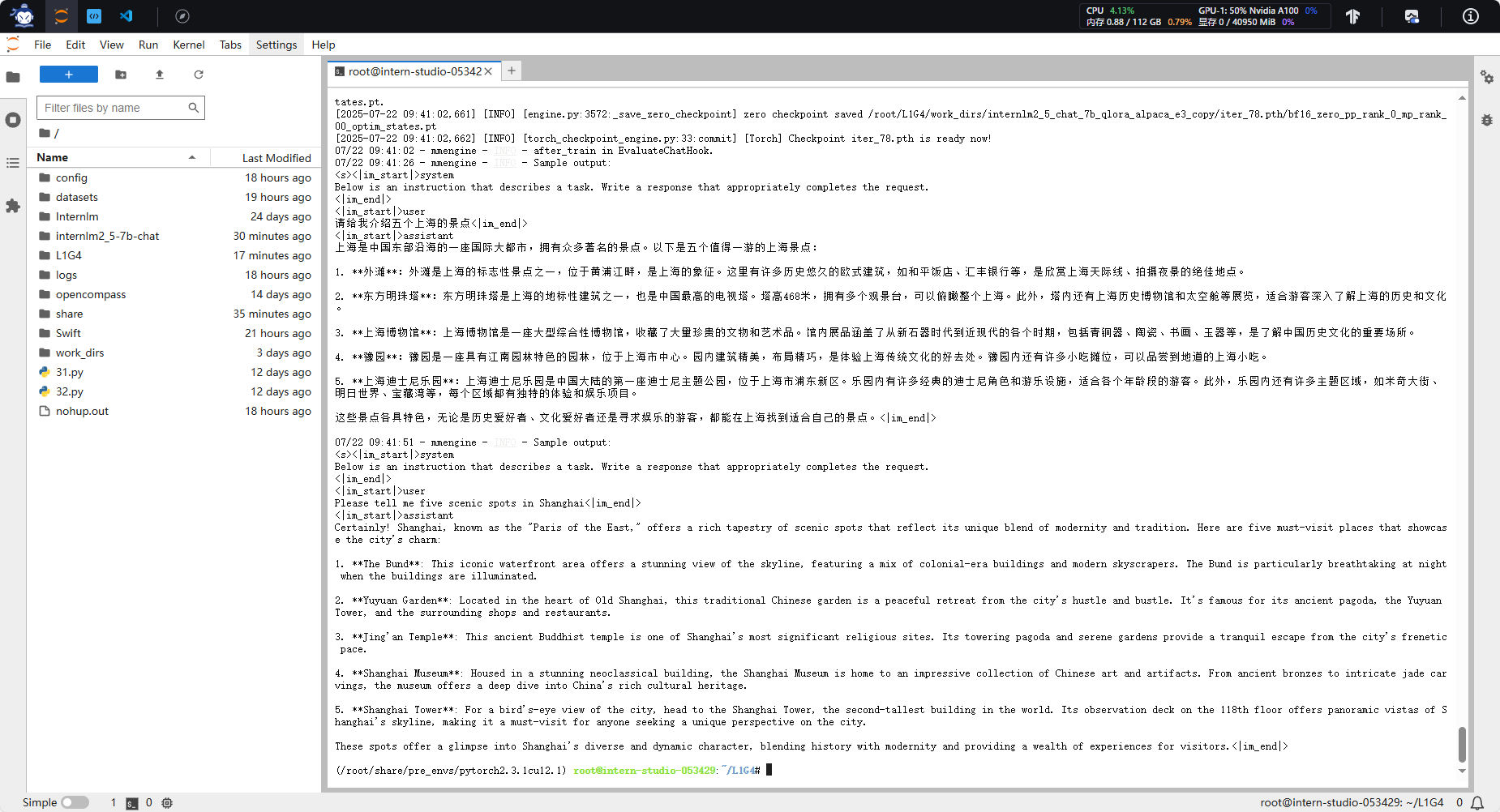
合并
在完成XTuner的微调后,需要进行两个步骤:首先将PTH格式的模型转换为HuggingFace格式,然后将adapter与基础模型合并。
按照以下步骤操作:
1. 将PTH格式转换为HuggingFace格式
cd #你的项目根目录
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ./work_dirs/internlm2_5_chat_7b_qlora_alpaca_e3_copy/iter_xx.pth ./work_dirs/hf
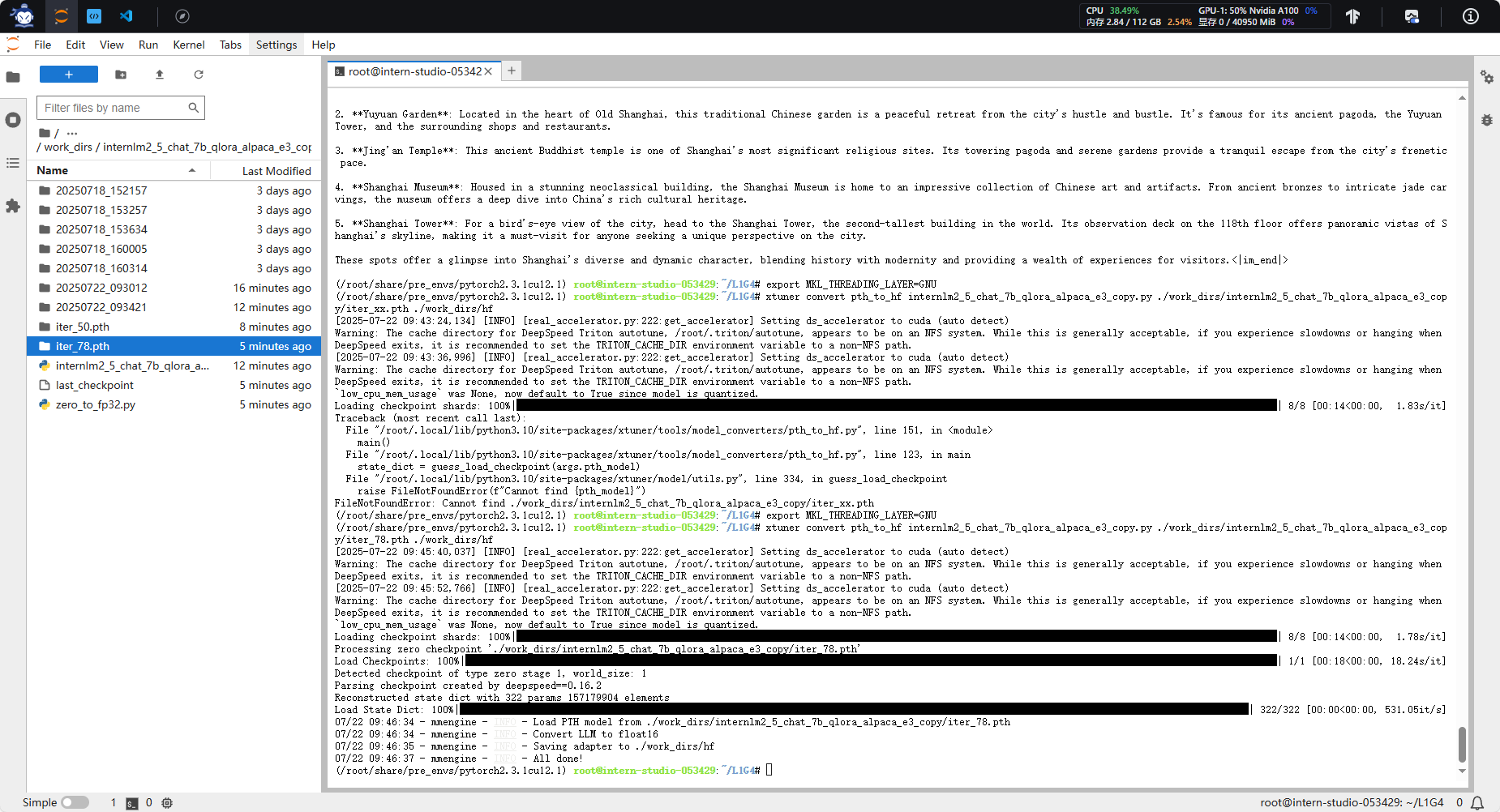
2. 合并adapter和基础模型
cd #你的项目根目录
export MKL_THREADING_LAYER=GNU
xtuner convert merge ./internlm2_5-7b-chat ./work_dirs/hf ./work_dirs/merged --max-shard-size 2GB
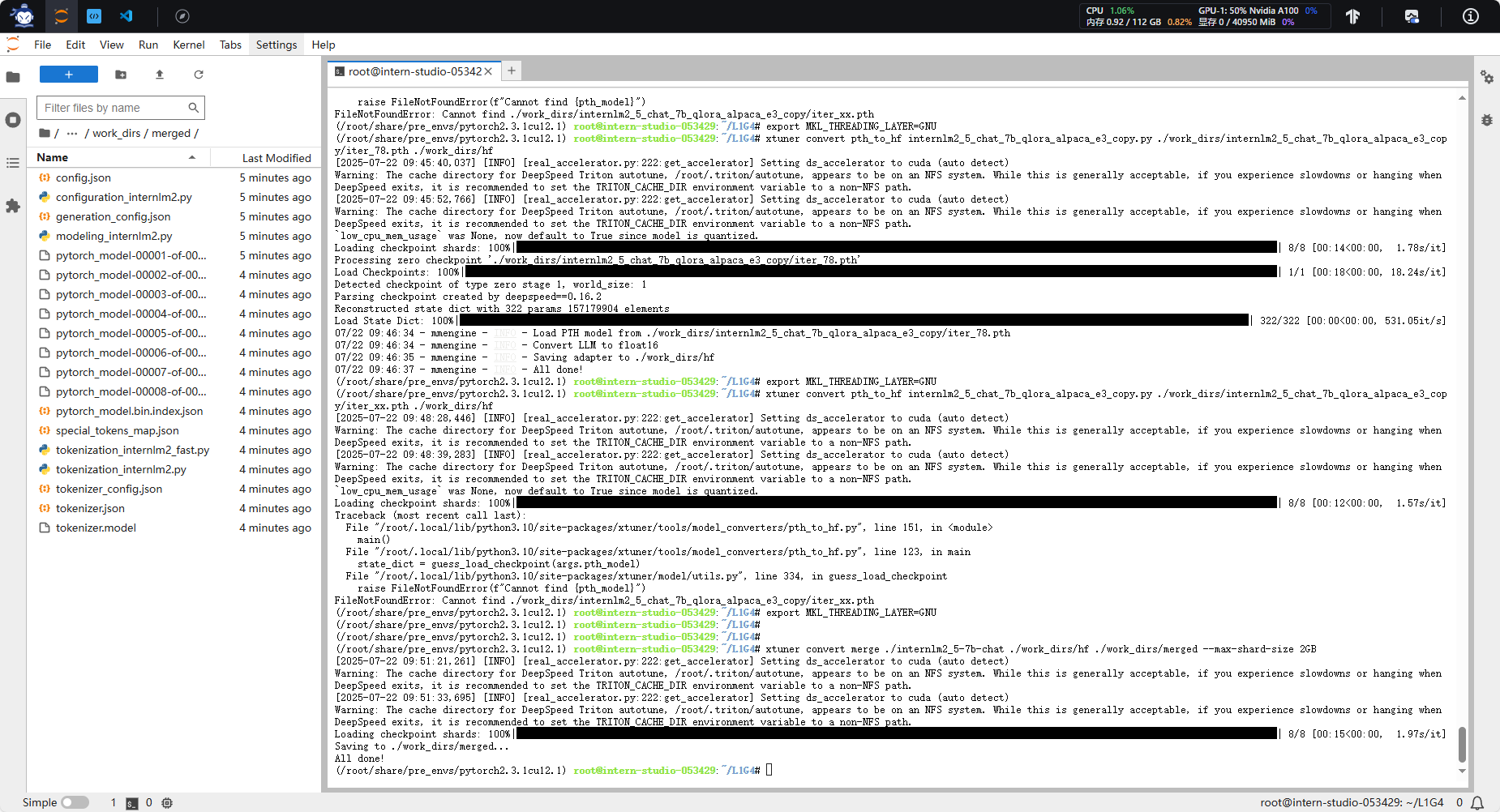
完成这两个步骤后,合并好的模型将保存在./work_dirs/merged目录下,你可以直接使用这个模型进行推理了。
7. 提交模型完成评测
将微调好的模型上传模型至 ModelScope 模型库 ,有 ① swift 指令 ② ModeScope 官方 Python SDK 两种方法,二选一即可。
成功上传至ModelScope 模型库后,把hub_model_id(下面会告诉大家如何获得)填写至信息提交单中,后台会自动拉取并跑评测,因此稍等一段时间就可以在榜单上看到自己的成绩。
7.2 ModeScope 官方 Python SDK
pip install modelscope
【上传脚本】
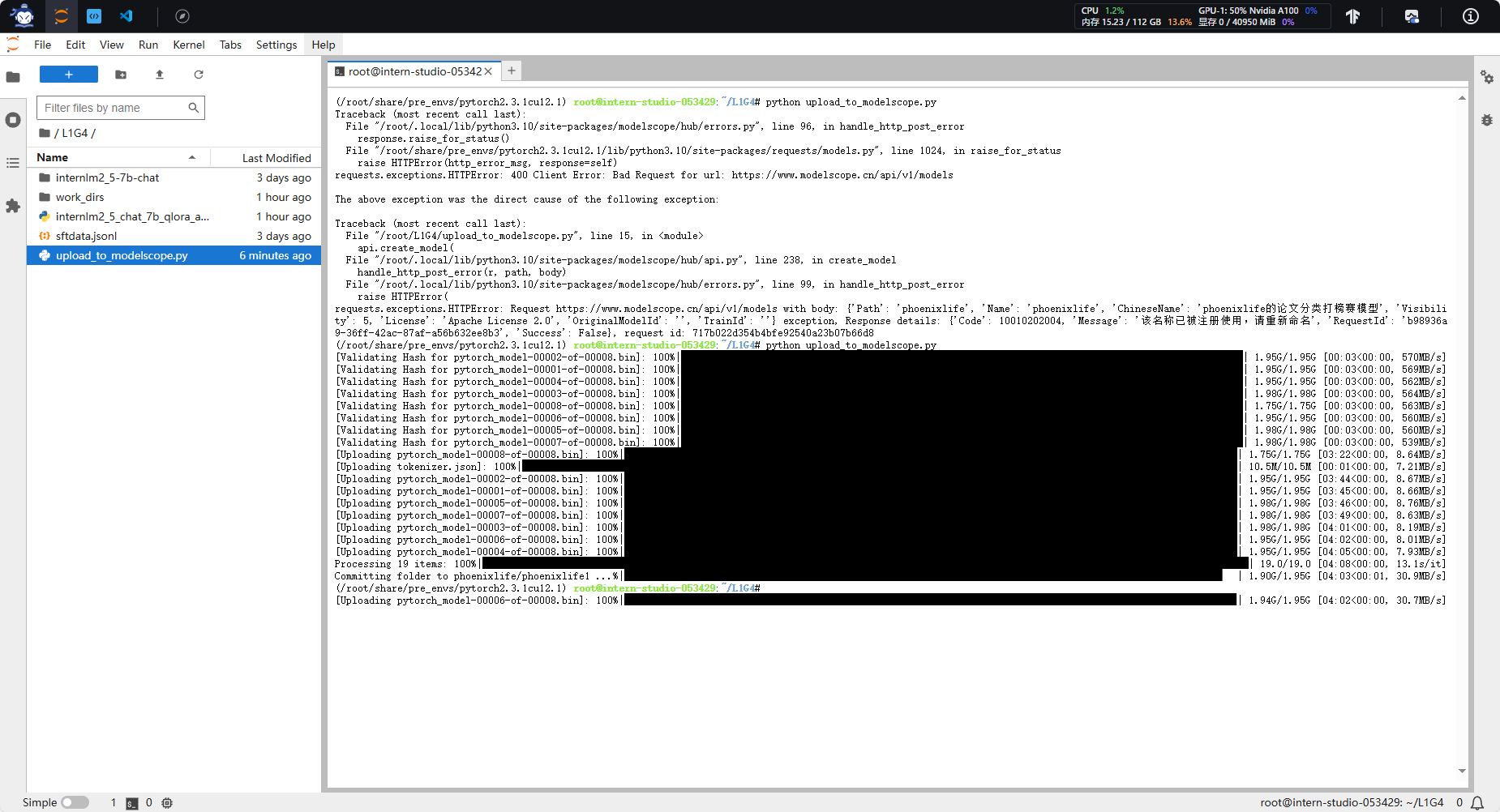
from modelscope.hub.api import HubApi
from modelscope.hub.constants import Licenses, ModelVisibility
# 配置基本信息
YOUR_ACCESS_TOKEN = 'xxx(从modelscope获取,即上节的hub_token)'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
# 取名字
owner_name = 'xxx' # ModelScope 的用户名,需根据自己情况修改
model_name = 'xxx' # 为模型库取个响亮优雅又好听的名字,需根据自己情况修改
model_id = f"{owner_name}/{model_name}"
# 创建模型库,若已通过6.1节的ModelScope网页端创建,此段代码可忽略
api.create_model(
model_id,
visibility=ModelVisibility.PUBLIC,
license=Licenses.APACHE_V2,
chinese_name=f"{owner_name}的论文分类打榜赛模型"
)
# 上传模型
api.upload_folder(
repo_id=f"{owner_name}/{model_name}",
folder_path='/root/path/to/your/model', # 微调后模型的文件夹名称
commit_message='upload model folder to repo', # 写点开心的上传信息
)【参考】
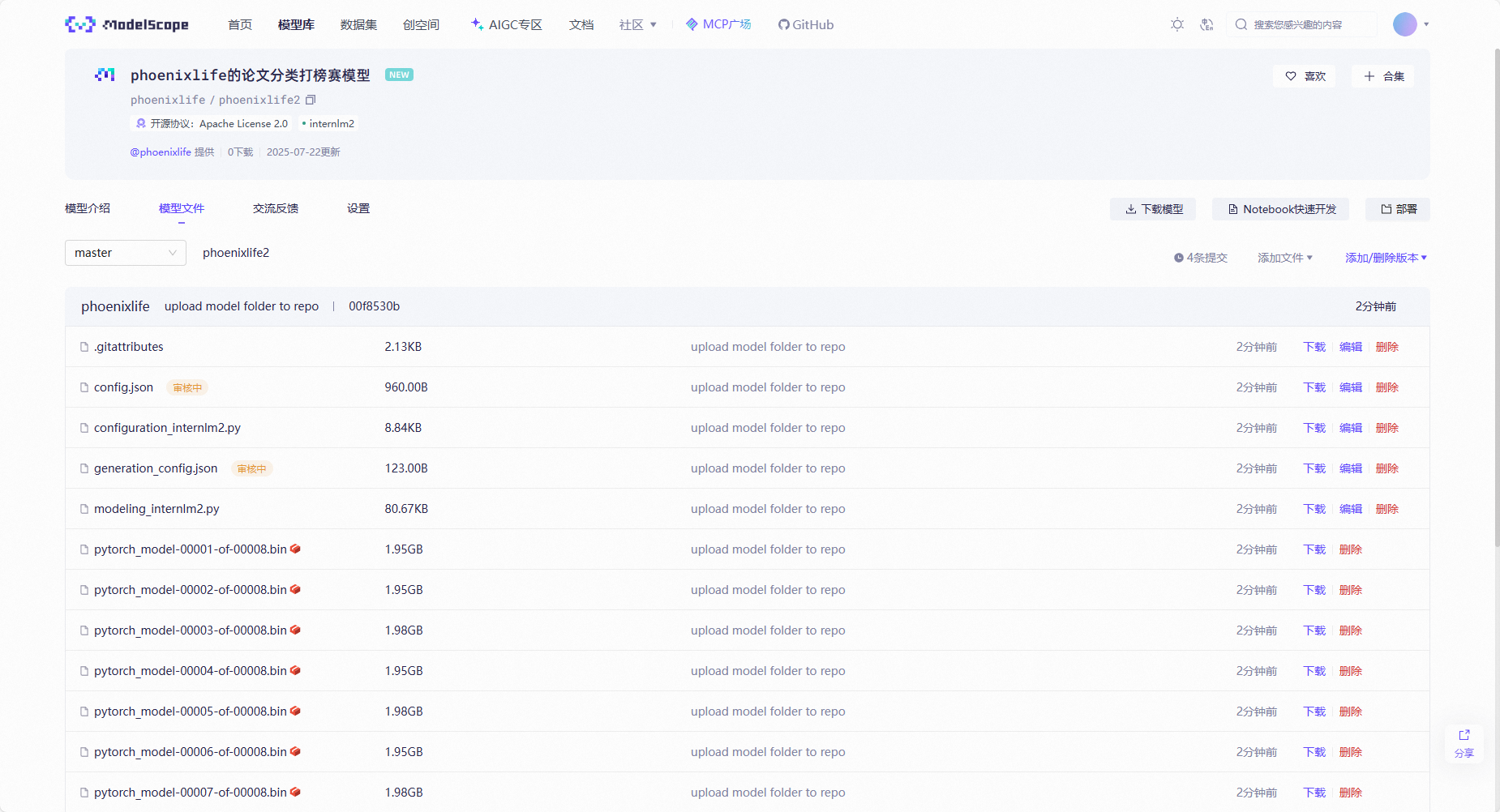
https://www.modelscope.cn/docs/models/upload
上传成功后如下图:
7.3 填链接提交模型
记住你的“Modelscope账号名称/模型库名称“,如“Shanghai_AI_Laboratory/internlm3-8b-instruct”,然后填写信息提交单等待成绩榜单更新吧!!!如果完成了测评,会在成绩榜单最下面的提交记录中,查找自己的uid进行查询。
信息提交单:https://aicarrier.feishu.cn/share/base/form/shrcn0JkjbZKMeMPw04uHCWc5Pg
成绩榜单(动态更新中):
各个模型的基线成绩如下图,看看你的分数如何吧!!
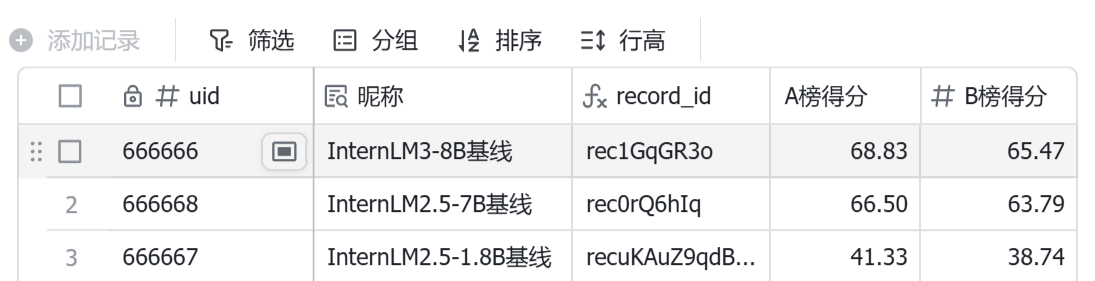
8. 刷榜
还等什么, 快来刷榜吧!!!挑战米神!
如何更高效的拿分呢?
1. 从数据入手
2. 从算法入手
3. 从参数入手
从算法入手 比如很火的GRPO 很酷是吧,但貌似有些难度。
从数据入手 比如加大训练数据,有些累。
从参数入手 这个ez哈哈

提交
swift export \
--model /root/paper/config/swift_output/InternLM3-8B-Lora-SFT/v4-20250511-153230/checkpoint-45-merged \
--push_to_hub true \
--hub_model_id 'zhangfc12345678/camp5-2' \
--hub_token '03xx' \
--use_hf false
重新提交表单发现 work了, 都超基线了!
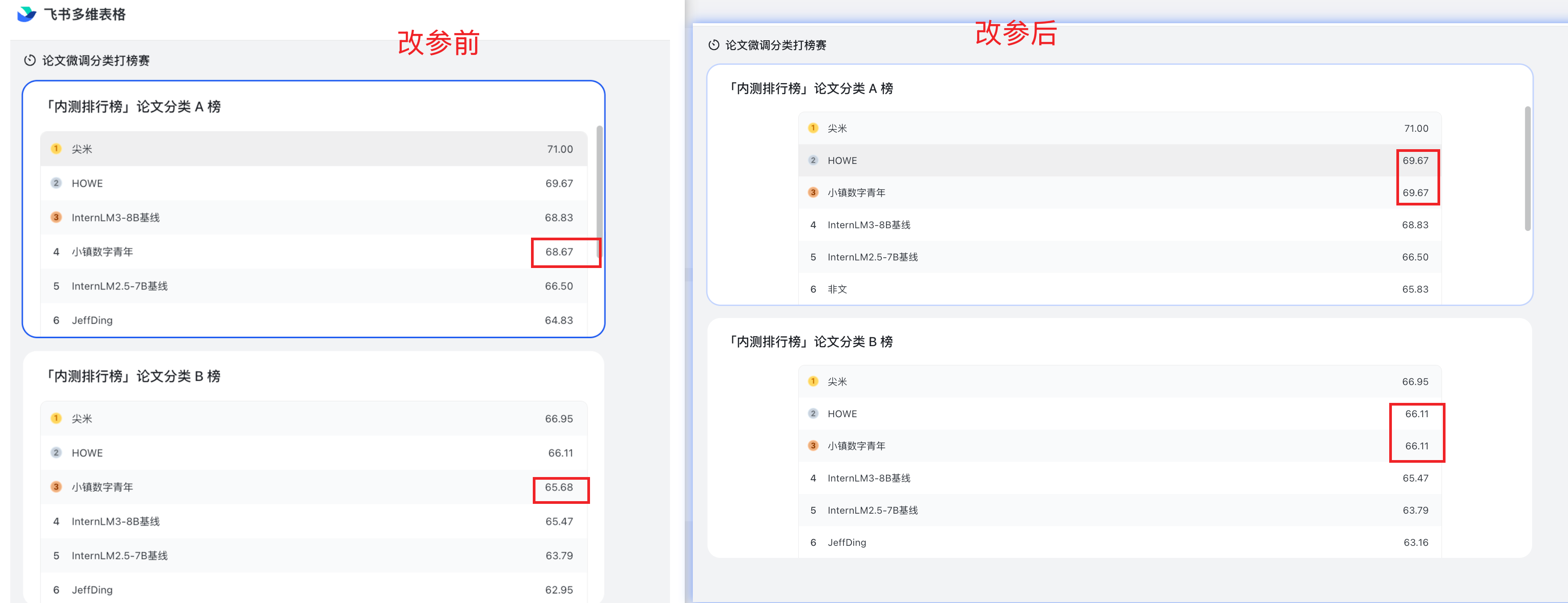
之前的 conda 管理(过于冗余已更新):
conda create -n xtuner_513 python=3.10 -y
conda activate xtuner_513
pip install torch==2.4.0+cu121 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install xtuner timm flash_attn datasets==2.21.0 deepspeed==0.16.1
conda install mpi4py -y
conda create -n xtuner_513 python=3.10 -y
conda activate xtuner_513
pip install torch==2.4.0+cu121 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install xtuner timm flash_attn datasets==2.21.0 deepspeed==0.16.1
conda install mpi4py -y
#为了兼容模型,降级transformers版本
pip uninstall transformers -y
pip install transformers==4.48.0 --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple



 他的勋章
他的勋章









木子哦2025.07.22
干货!