 返回首页
返回首页
 回到顶部
回到顶部

1.项目介绍
1.1项目简介
本项目基于 YOLOv8 的目标检测功能,结合 OBB(Oriented Bounding Boxes)模型,OBB模型是通过引入旋转边界框来更准确地定位和检测图像中的物体,实时检测视频画面中货物的位置偏差,并自动进行校正。通过训练 YOLOv8 模型,将模型部署到行空板M10 上,USB摄像头实时捕捉货物位置画面,利用 YOLOv8 模型推理输出货物位置和偏差信息,并自动控制机械装置进行校正,为货物位置管理等应用场景提供高效的技术支持。核心功能如下:
1.实时货物检测:利用 YOLOv8 算法对摄像头捕获的视频流进行实时分析,快速准确地识别和定位各种货物。
2.位置偏差识别:通过 OBB 模型对比货物的理想位置与实际位置,精确计算货物的偏移量。
3.自动校正控制:根据位置偏差,自动控制机械装置(如机械臂)对货物进行微调,使其恢复到正确位置。
1.2项目效果视频
【行空板M10实现基于YOLO的货物位置自动校正装置】
2.项目制作框架
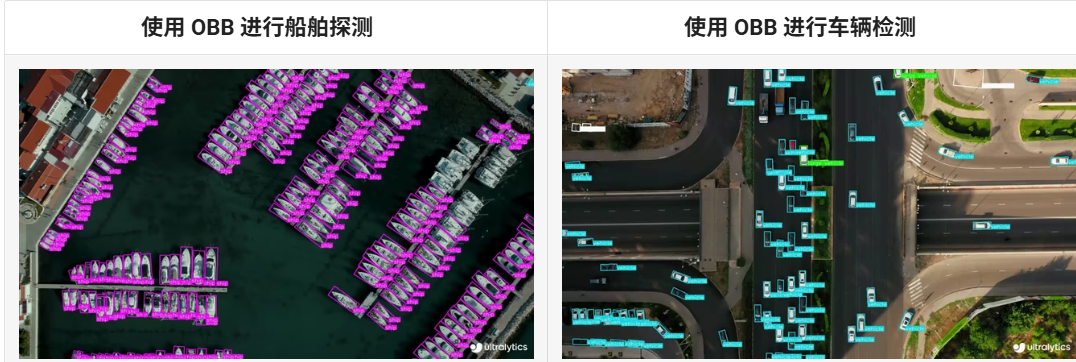
本项目是通过YOLO目标检测算法,使用货物数据集,训练YOLOv8-OBB模型,检测画面中货物信息及位置等信息,显示货物的物体类型、置信度、旋转角度等信息。
OBB(Oriented Bounding Boxes)Object Detection,中文为定向边界框物体检测,它比标准物体检测更进一步,因为它引入了一个额外的角度来更准确地定位图像中的物体,也就是能根据物体的角度,用旋转的边界框来更准确地定位物体。定向边界框物体检测的输出是一组精确包围图像中物体的旋转边界框,以及每个边界框的类别标签和置信度分数等信息。当物体以不同角度出现时,定向边界框尤其有用。例如在航空图像中,物体可能以各种角度出现,因为传统的轴对齐边界框可能会包含很多背景,所以效果不佳。而 OBB 模型输出的是旋转边界框,能更紧密地贴合物体的实际形状,还带有类别标签和置信度分数等信息,效果很好。
下图是我们的项目制作框架图,我们在电脑端完成模型的训练与测试,将模型部署到智能硬件——行空板M10中完成货物位置检测模型的应用,并制作出自动校正装置。
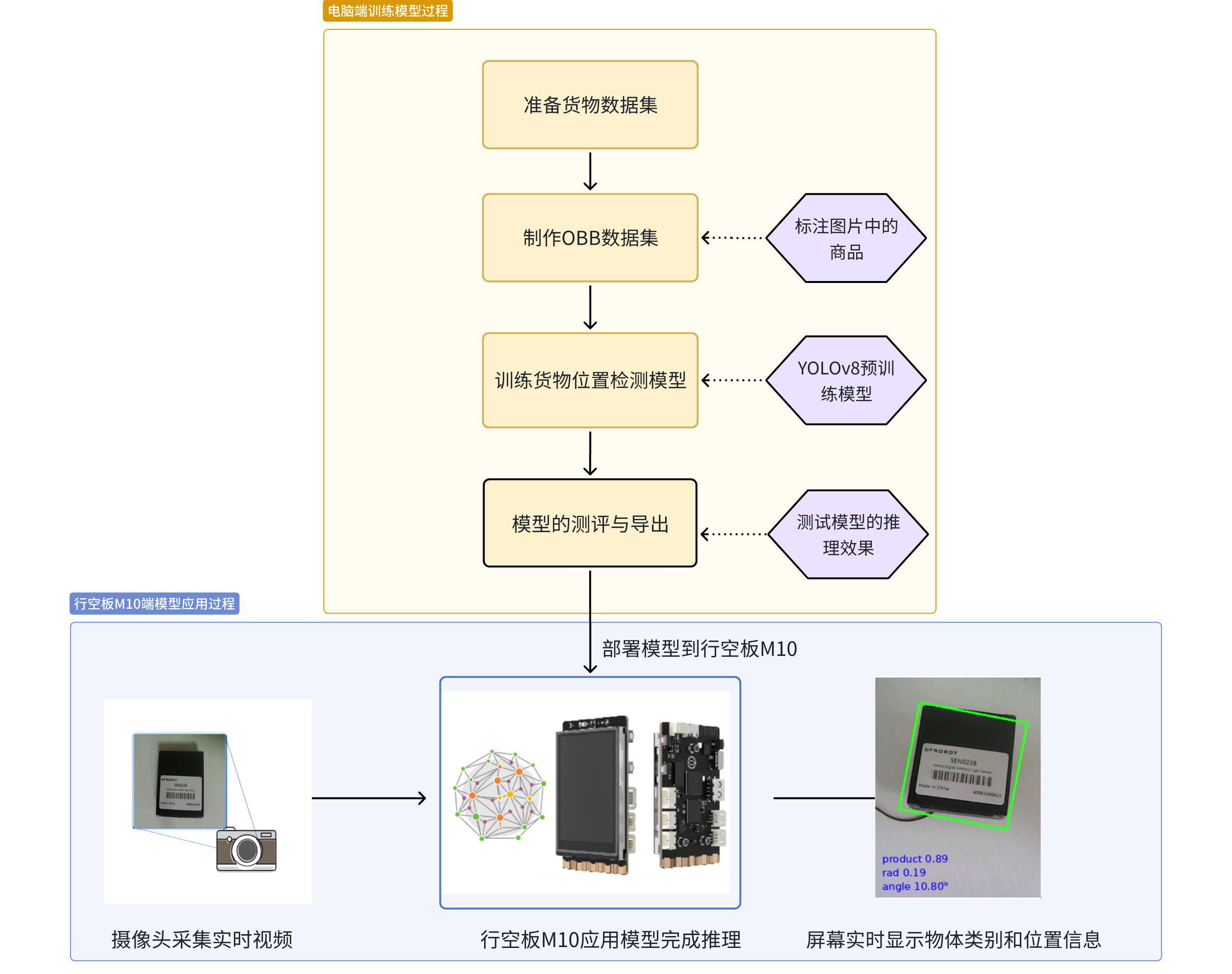
YOLO货物位置检测及自动校正装置项目框架图
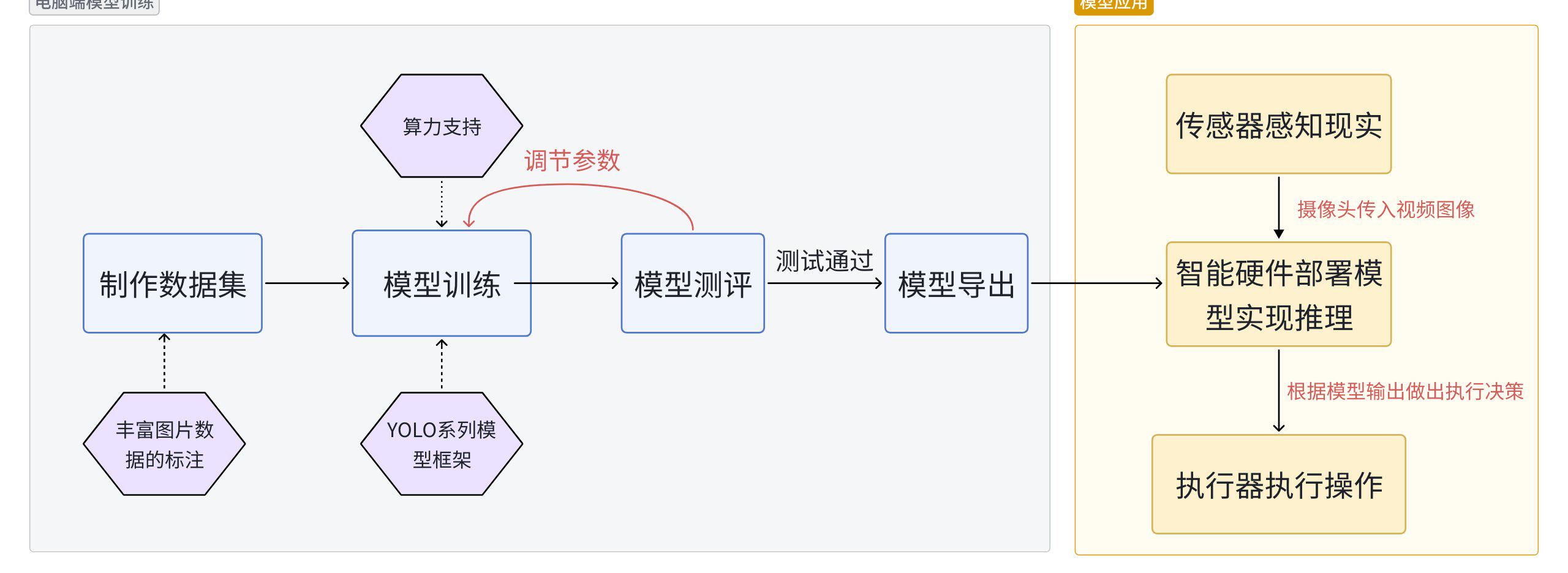
YOLO项目框架图,供参考
3.软硬件环境准备
3.1软硬件器材清单

注意行空板M10固件在0.3.5——0.4.0的版本均可以用于制作本项目,但都需要为行空板装conda环境,详情见3.3硬件环境准备。
3.2软件环境准备
由于我们使用电脑进行训练货物位置检测模型,因此需要在电脑端安装相应的库。
首先按下win+R,输入cmd进入窗口。
在命令行窗口中依次输入以下指令,安装ultralytics库
pip install ultralytics
pip install onnx==1.16.1
pip install onnxruntime==1.17.1输入之后会出现以下页面。
当命令运行完成,出现以下截图表示安装成功。
3.3硬件环境准备
在本项目中我们将要将训练好的YOLOv8框架的模型部署到行空板中,进行推理和执行操作。为了在行空板上成功运行YOLOv8,我们将使用Ultralytics官方提供的库进行部署 。
使用USB数据线连接行空板与电脑,等待行空板屏幕亮起表示行空板开机成功。

打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载。
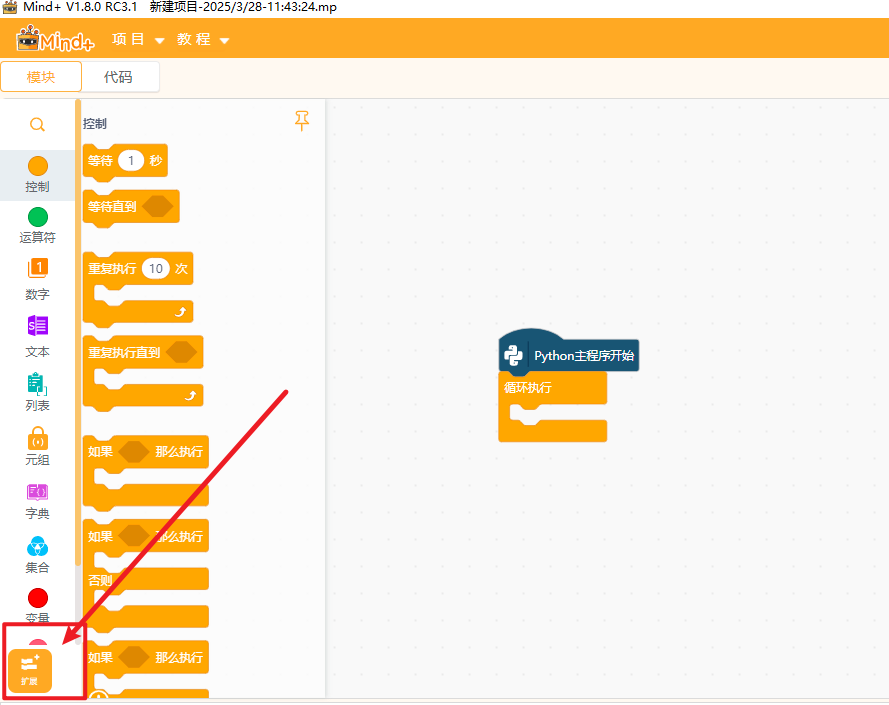
点击返回,点击连接设备,找到10.1.2.3.点击连接,等待连接成功.
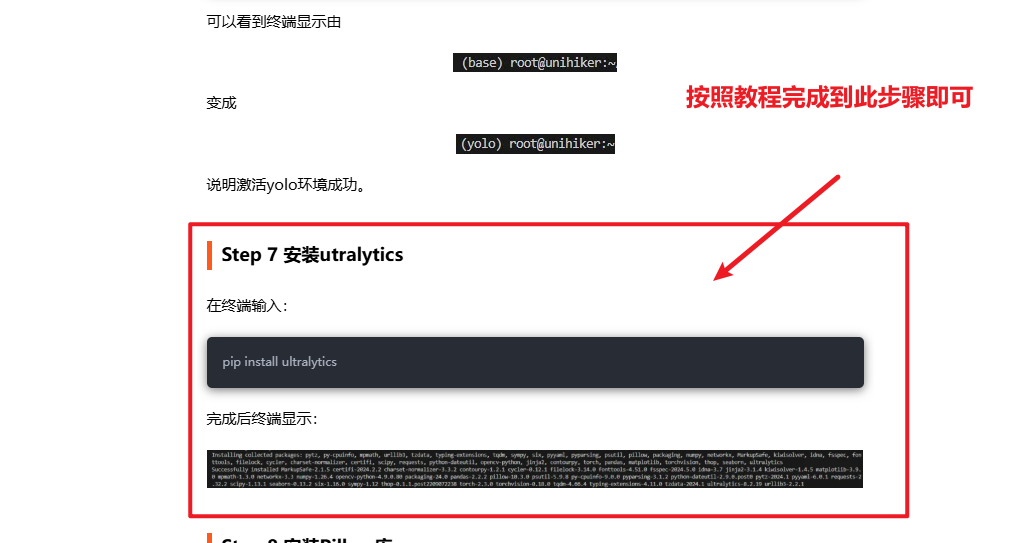
请参考此篇帖子的环境配置教程:如何在行空板上运行 YOLOv10n? 请按照这篇帖子的教程完成到Step 7 安装utralytics,如下图。
除了utralytics库本项目还需要使用onnx、onnxruntime、opencv -python 和pinpong库 依次在Mind+终端输入以下命令
(注意行空板需要联网,点此查看:行空板联网操作教程)
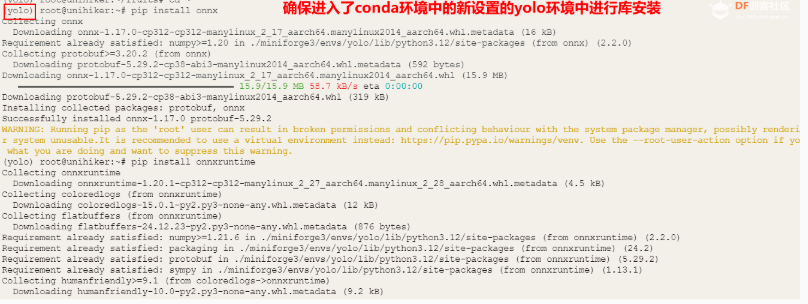
pip install onnx==1.16.1
pip install onnxruntime==1.17.1
pip install opencv-python
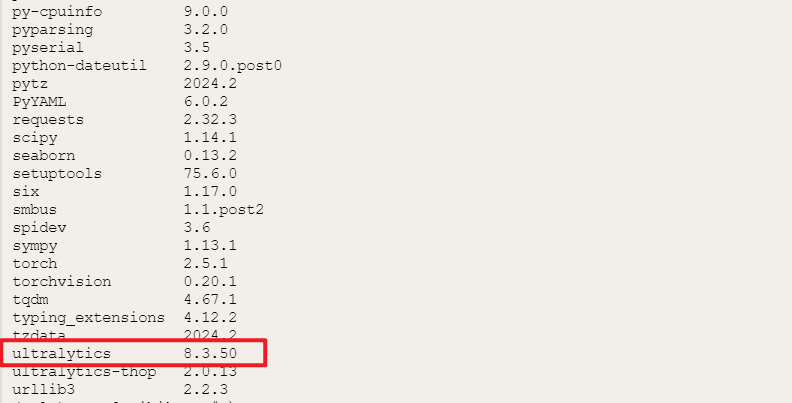
pip install pinpong在Mind+终端输入以下指令,可以检查相应库是否安装成功
pip list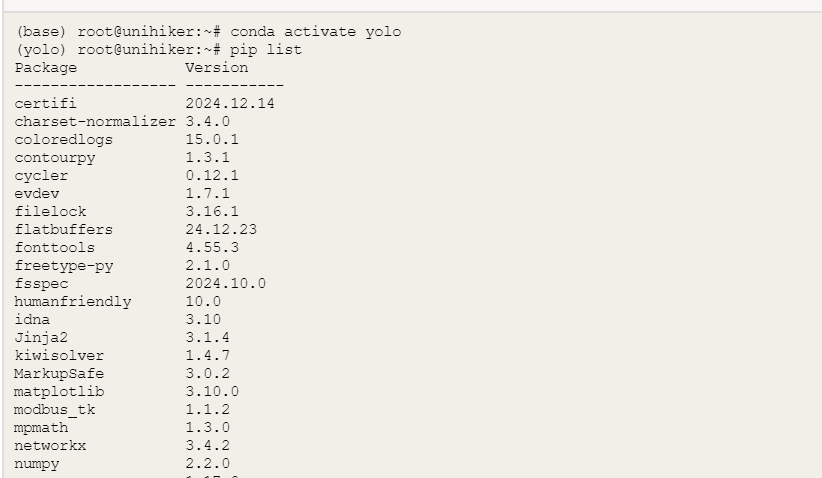
4. 制作步骤
4.1数据集准备(概括为以下几个步骤):
4.1.1采集图片
目标:制作只有一个类别的数据集。
功能:使用摄像头拍摄视频,从视频中抽取指定数量的帧的图片并保存。
要求:录制视频的时候,从多个角度去录制视频,录制时间至少25秒。
代码:以下是代码,这里将视频的尺寸裁剪为了320*320的尺寸,因为该尺寸图片实践下来效果较好,代码里面可以修改分辨率和图片尺寸。
import cv2
# 初始化摄像头
cap = cv2.VideoCapture(1)
if not cap.isOpened():
print("无法打开摄像头")
exit()
# 设置视频编码器、帧率、分辨率
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = None
recording = False
print("按空格键开始录制,按ESC键结束录制并保存文件")
print("按ESC键结束程序")
while True:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头画面")
break
# 显示摄像头画面
cv2.imshow('Recorder', frame)
# 检测按键是否按下
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
if not recording:
print("开始录制...")
recording = True
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (320, 320))
elif key == 27: # ESC键的ASCII值是27
if recording:
print("结束录制并保存文件")
recording = False
if out is not None:
out.release()
out = None
break
if recording:
# 调整大小为320x320
frame = cv2.resize(frame, (320, 320))
# 写入视频文件
if out is not None:
out.write(frame)
# 释放资源
cap.release()
if out is not None:
out.release()
cv2.destroyAllWindows()接下来从视频里面抽取500张图片(根据上面录制视频的帧数,至少录制视频25秒才能达到500帧),这里将图片的尺寸修改为了320*320。
import cv2
import os
import random
# 主程序
def extract_random_frames(video_path, num_frames, output_dir):
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("无法打开视频文件")
return
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
if total_frames == 0:
print("视频文件无效或无帧")
return
if num_frames > total_frames:
print(f"请求的帧数({num_frames})超过视频总帧数({total_frames}), 将提取所有可用帧")
num_frames = total_frames
# 随机选择帧
frame_indices = random.sample(range(total_frames), num_frames)
print(f"开始从视频中提取{num_frames}帧...")
extracted_frames = 0
current_frame = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if current_frame in frame_indices:
# 调整大小为320x320
frame = cv2.resize(frame, (320, 320))
# 保存图片
frame_path = os.path.join(output_dir, f"frame_{current_frame}.png")
cv2.imwrite(frame_path, frame)
extracted_frames += 1
print(f"已提取第{extracted_frames}帧,总共有{num_frames}帧")
if extracted_frames >= num_frames:
break
current_frame += 1
cap.release()
print(f"成功提取{extracted_frames}帧图片,保存在 '{output_dir}'")
# 指定视频路径和输出目录
video_path = "output.avi" # 替换为你的视频文件路径
output_dir = "block"
# 提取500帧
extract_random_frames(video_path, 500, output_dir)注意在采集图片时多采集不同角度(如45度,90度)下的物体的图片。这样模型能学习不同角度的物品的数据能够更好的识别出不同角度下的物体。


4.1.2下载rolabelImg并打开
到官方仓库下载robelImg的源文件并解压(详情见附录)。
解压后,打开文件夹。将图片数据集放入"roLabelImg-master\data"文件夹内。
输入cmd进入命令行页面。
在命令行页面输出以下指令。
python roLabelImg.py
按下回车,出现操作页面。
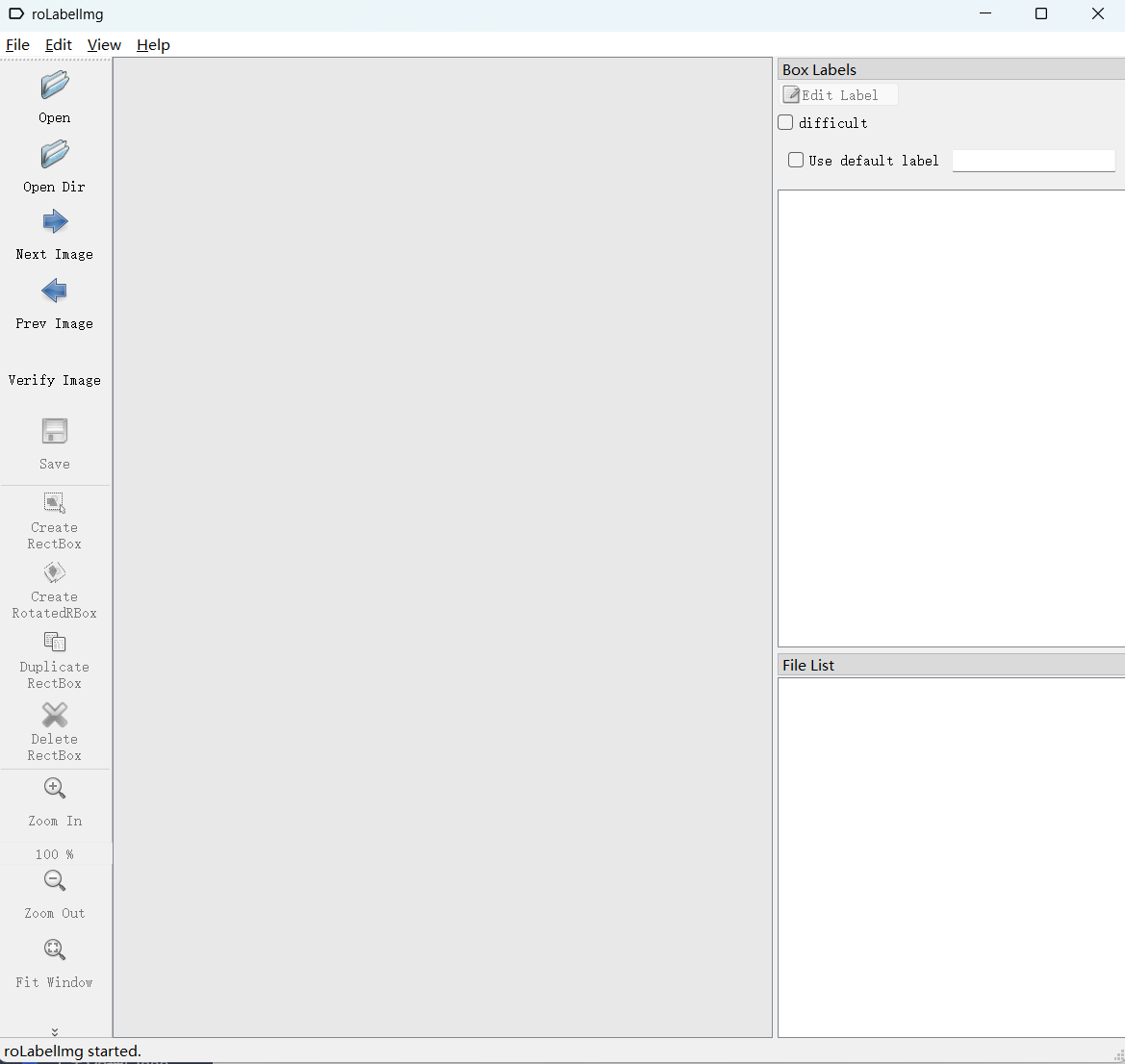
4.1.3数据标注
点击Open Dir,找到自己导入的文件夹,然后选中。
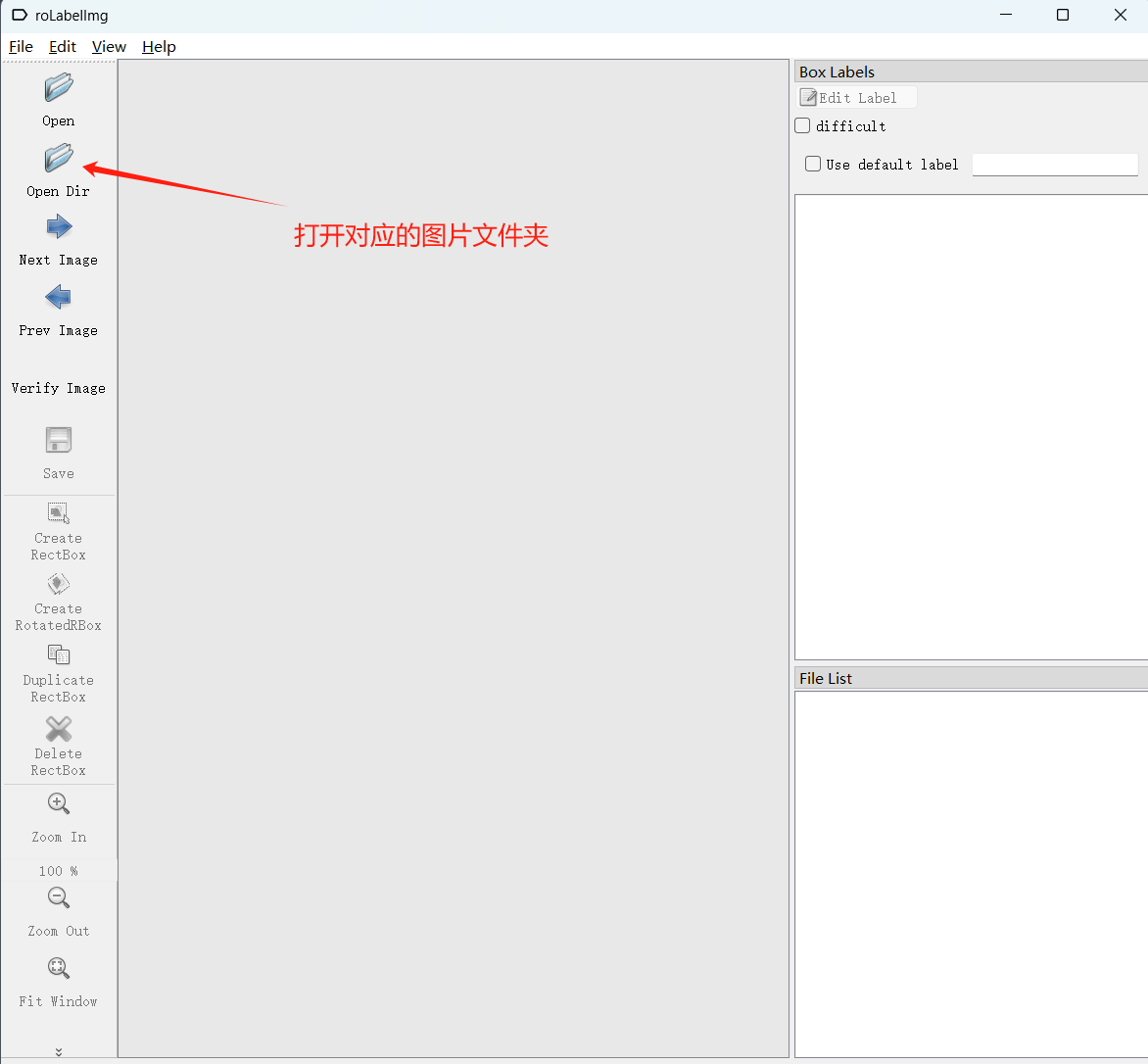
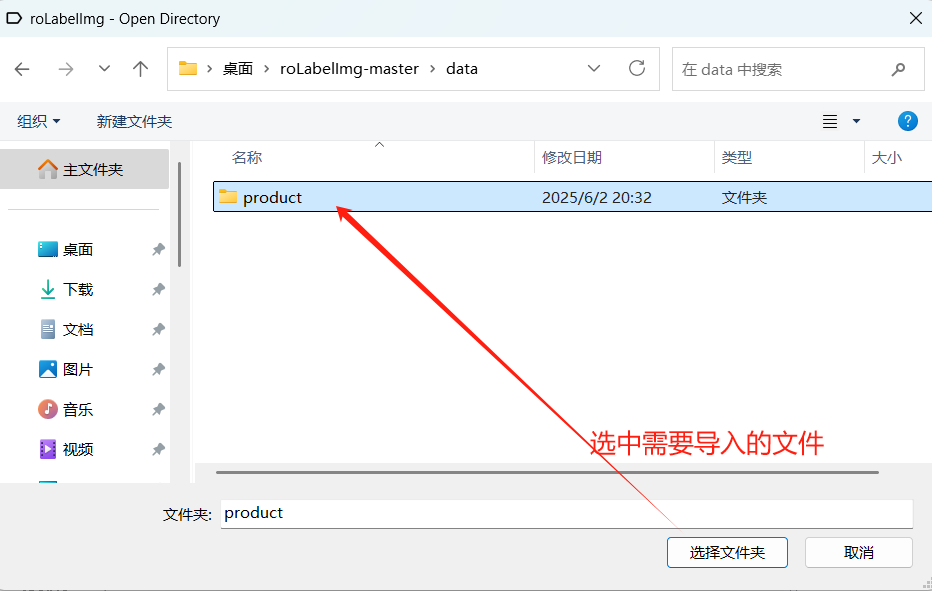
打开后如下图所示:

在标注时一定时选择'create rotatedRBox'(制作旋转矩形框),对应快捷键是E。
按下E,鼠标变成十字型,按下鼠标的左键开始标注旋转矩形。
(注意:如果标注过程中闪退,报错为IndentationError: unexpected indent,可点此参照该解决方案)

在标注时,如果物体是斜的可以按键盘上的"ZXCV"四个键中的任意一个,是矩形旋转以标注倾斜的物体。(注意:物体在图片中是斜的的时候一定要旋转矩形标注,这样在训练时模型才能学习到倾斜的物体)

标好后,手动输入类别名,这里以"product"为例。
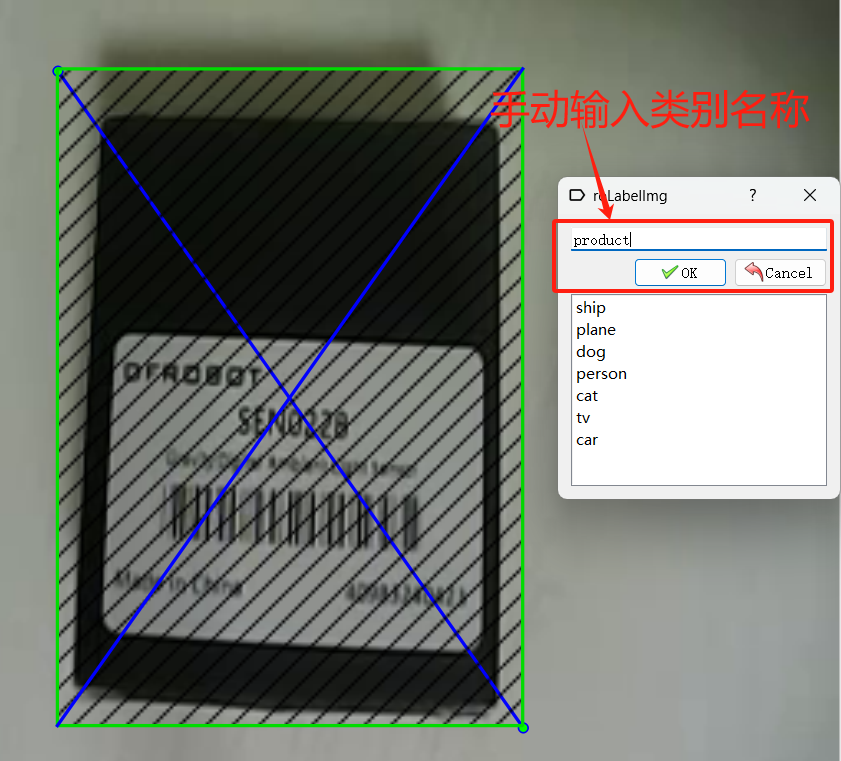
输完类别后,按下"ctrl+s"选择保存标注信息。(一定要按下保存)
标注完一张后按下键盘的D键,进入下一张图片的标注。标注完成后,打开image文件夹如下图。每一张图片后对应有一个同名的xml文件,xml文件中存储了标注信息。
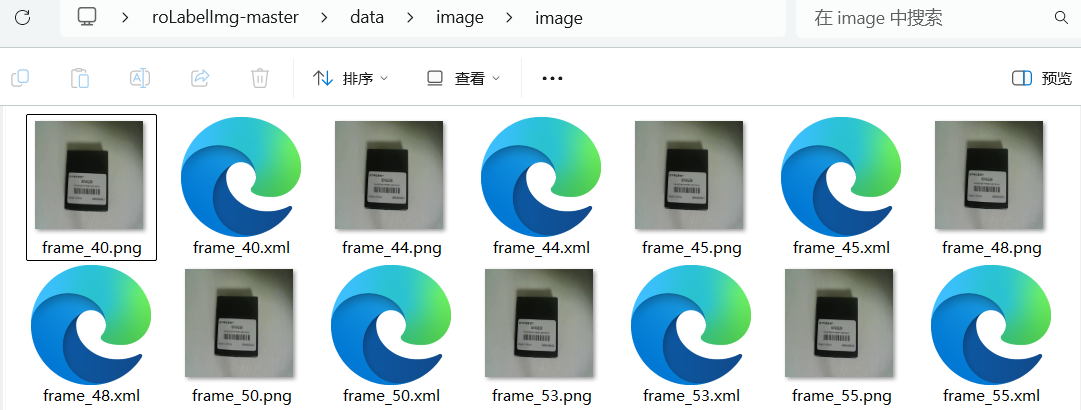
可以打开标注文件看一下里面的内容。

可以看一下ultralytics官方对用obb模型标注文件的要求:
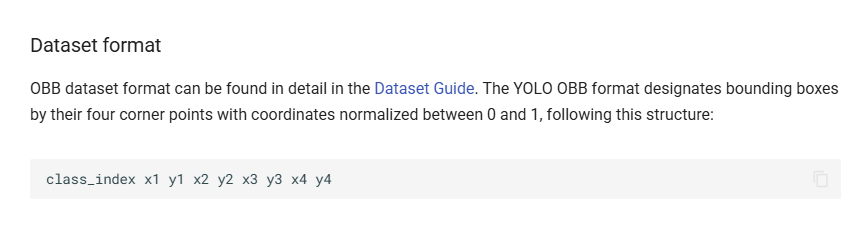
可以看到使用rolabelimg标注得到的标注信息是不符合yolo官方obb模型的训练的,因此我们要对标注信息注处理。
4.1.4数据转换
使用rolabelImg用旋转矩形标注图片生成的标注文件是xml格式,需要转换成训练yolo模型需要的txt格式,使用以下代码完成数据转换。
首先我们对image文件夹做处理,将图片数据与标注数据xml文件分离。使用以下程序进行分离。
import os
import shutil
# 原始混合文件夹
source_folder = r"C:\Users\HYPAB\Desktop\roLabelImg-master\data\image"#修改成自己电脑数据集的路径
# 创建目标子文件夹
image_folder = os.path.join(source_folder, "image_only")
label_folder = os.path.join(source_folder, "label_only")
os.makedirs(image_folder, exist_ok=True)
os.makedirs(label_folder, exist_ok=True)
# 遍历并分类移动
for file in os.listdir(source_folder):
full_path = os.path.join(source_folder, file)
if os.path.isfile(full_path):
if file.lower().endswith('.png'):
shutil.move(full_path, os.path.join(image_folder, file))
elif file.lower().endswith('.xml'):
shutil.move(full_path, os.path.join(label_folder, file))
print("✅ 图片和XML标注文件已分开完成")
运行后,image文件夹变成了这样,分成两个子文件夹各自存放图片文件和xml文件。
# 文件名称 :converttodota.py
# 功能描述 :将 roLabelImg 标注格式的 XML 文件转换为 DOTA 格式的 TXT 文件
import os
import xml.etree.ElementTree as ET
import math
cls_list = ['product'] # 修改为自己的类别标签
def edit_xml(xml_file, dotaxml_file):
tree = ET.parse(xml_file)
objs = tree.findall('object')
for ix, obj in enumerate(objs):
x0 = ET.Element("x0")
y0 = ET.Element("y0")
x1 = ET.Element("x1")
y1 = ET.Element("y1")
x2 = ET.Element("x2")
y2 = ET.Element("y2")
x3 = ET.Element("x3")
y3 = ET.Element("y3")
if obj.find('robndbox') is None:
obj_bnd = obj.find('bndbox')
if obj_bnd is None:
continue
obj_xmin = obj_bnd.find('xmin')
obj_ymin = obj_bnd.find('ymin')
obj_xmax = obj_bnd.find('xmax')
obj_ymax = obj_bnd.find('ymax')
xmin = max(float(obj_xmin.text), 0)
ymin = max(float(obj_ymin.text), 0)
xmax = max(float(obj_xmax.text), 0)
ymax = max(float(obj_ymax.text), 0)
obj_bnd.remove(obj_xmin)
obj_bnd.remove(obj_ymin)
obj_bnd.remove(obj_xmax)
obj_bnd.remove(obj_ymax)
x0.text = str(xmin)
y0.text = str(ymax)
x1.text = str(xmax)
y1.text = str(ymax)
x2.text = str(xmax)
y2.text = str(ymin)
x3.text = str(xmin)
y3.text = str(ymin)
else:
obj_bnd = obj.find('robndbox')
obj_bnd.tag = 'bndbox'
cx = float(obj_bnd.find('cx').text)
cy = float(obj_bnd.find('cy').text)
w = float(obj_bnd.find('w').text)
h = float(obj_bnd.find('h').text)
angle = float(obj_bnd.find('angle').text)
obj_bnd.clear() # 删除所有子节点
x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)
x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)
x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)
x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)
obj_bnd.append(x0)
obj_bnd.append(y0)
obj_bnd.append(x1)
obj_bnd.append(y1)
obj_bnd.append(x2)
obj_bnd.append(y2)
obj_bnd.append(x3)
obj_bnd.append(y3)
tree.write(dotaxml_file, method='xml', encoding='utf-8')
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc
yoff = yp - yc
cosTheta = math.cos(theta)
sinTheta = math.sin(theta)
pResx = cosTheta * xoff + sinTheta * yoff
pResy = - sinTheta * xoff + cosTheta * yoff
return str(int(xc + pResx)), str(int(yc + pResy))
def totxt(xml_path, out_path):
files = os.listdir(xml_path)
for i, file in enumerate(files):
try:
tree = ET.parse(os.path.join(xml_path, file))
root = tree.getroot()
name = file.split('.')[0]
output = os.path.join(out_path, name + '.txt')
with open(output, 'w') as f:
objs = root.findall('object')
for obj in objs:
cls = obj.find('name').text
box = obj.find('bndbox')
if box is None: continue
x0 = int(float(box.find('x0').text))
y0 = int(float(box.find('y0').text))
x1 = int(float(box.find('x1').text))
y1 = int(float(box.find('y1').text))
x2 = int(float(box.find('x2').text))
y2 = int(float(box.find('y2').text))
x3 = int(float(box.find('x3').text))
y3 = int(float(box.find('y3').text))
x0 = max(x0, 0)
x1 = max(x1, 0)
x2 = max(x2, 0)
x3 = max(x3, 0)
y0 = max(y0, 0)
y1 = max(y1, 0)
y2 = max(y2, 0)
y3 = max(y3, 0)
for cls_index, cls_name in enumerate(cls_list):
if cls == cls_name:
f.write(f"{x0} {y0} {x1} {y1} {x2} {y2} {x3} {y3} {cls} {cls_index}\n")
print(f"[{i+1}/{len(files)}] 已处理 {file}")
except Exception as e:
print(f"❌ 错误处理文件 {file}: {e}")
if __name__ == '__main__':
roxml_path = r'C:\Users\HYPAB\Desktop\roLabelImg-master\data\image\label_only'#修改成自己电脑数据集的路径
dotaxml_path = r'C:\Users\HYPAB\Desktop\roLabelImg-master\data\image\dotaxml'
out_path = r'C:\Users\HYPAB\Desktop\roLabelImg-master\data\image\dotaTxt'
os.makedirs(dotaxml_path, exist_ok=True)
os.makedirs(out_path, exist_ok=True)
filelist = os.listdir(roxml_path)
for file in filelist:
edit_xml(os.path.join(roxml_path, file), os.path.join(dotaxml_path, file))
totxt(dotaxml_path, out_path)
运行后,可以看到生成了两个文件夹分别是'dotaTxt'和'dotaxml'。
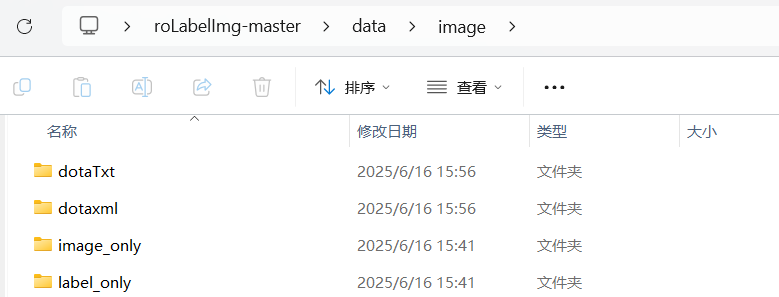
此时我们需要对这份文件进行整理,删除dotaxml、label_only两个文件夹,将image文件夹名字修改为'product'(以类别命名),将'dotaTxt'文件夹修改成'label',将image_only修改成image。
4.1.5划分训练集和验证集
运行以下程序划分成训练集和验证集:
import os
import shutil
import random
from sklearn.model_selection import train_test_split
# 设置随机种子以保证结果可复现
random.seed(42)
# 数据集根目录
dataset_root = r'C:\Users\HYPAB\Desktop\roLabelImg-master\data\product'
# 图片和标注文件夹
image_folder = os.path.join(dataset_root, 'image')
label_folder = os.path.join(dataset_root, 'label')
# 检查图片和标注文件的对应关系
image_files = os.listdir(image_folder)
label_files = os.listdir(label_folder)
# 创建字典来存储图片和对应的标注文件
image_label_dict = {}
# 检查每张图片是否有对应的标注文件
for image_file in image_files:
image_name = os.path.splitext(image_file)[0]
label_file = f"{image_name}.txt"
if label_file in label_files:
image_label_dict[image_file] = label_file
else:
print(f"Warning: No label file found for image {image_file}")
# 检查每个标注文件是否有对应的图片
for label_file in label_files:
label_name = os.path.splitext(label_file)[0]
image_file = f"{label_name}.png" # 假设图片格式为PNG,可以根据实际情况修改
if image_file not in image_files:
print(f"Warning: No image file found for label {label_file}")
# 将数据集划分为训练集和验证集
image_files = list(image_label_dict.keys())
train_images, val_images = train_test_split(image_files, test_size=0.2, random_state=42)
# 创建训练集和验证集的目录结构
train_image_dir = os.path.join(dataset_root, 'train/images')
train_label_dir = os.path.join(dataset_root, 'train/labels')
val_image_dir = os.path.join(dataset_root, 'val/images')
val_label_dir = os.path.join(dataset_root, 'val/labels')
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_image_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
# 复制文件到相应的目录
for image_file in train_images:
shutil.copy(os.path.join(image_folder, image_file), train_image_dir)
shutil.copy(os.path.join(label_folder, image_label_dict[image_file]), train_label_dir)
for image_file in val_images:
shutil.copy(os.path.join(image_folder, image_file), val_image_dir)
shutil.copy(os.path.join(label_folder, image_label_dict[image_file]), val_label_dir)
# 生成data.yaml文件
data_yaml = f"""train: {os.path.join(dataset_root, 'train')}
val: {os.path.join(dataset_root, 'val')}
nc: 1 # 类别数量,根据实际情况修改
names: ['product'] # 类别名称,根据实际情况修改
"""
with open(os.path.join(dataset_root, 'data.yaml'), 'w') as f:
f.write(data_yaml)
print("Dataset preparation completed successfully!")完成后找到从ultralytics官方仓库下载的ultralytics文件夹,如何下载看下面4.2模型训练章节。
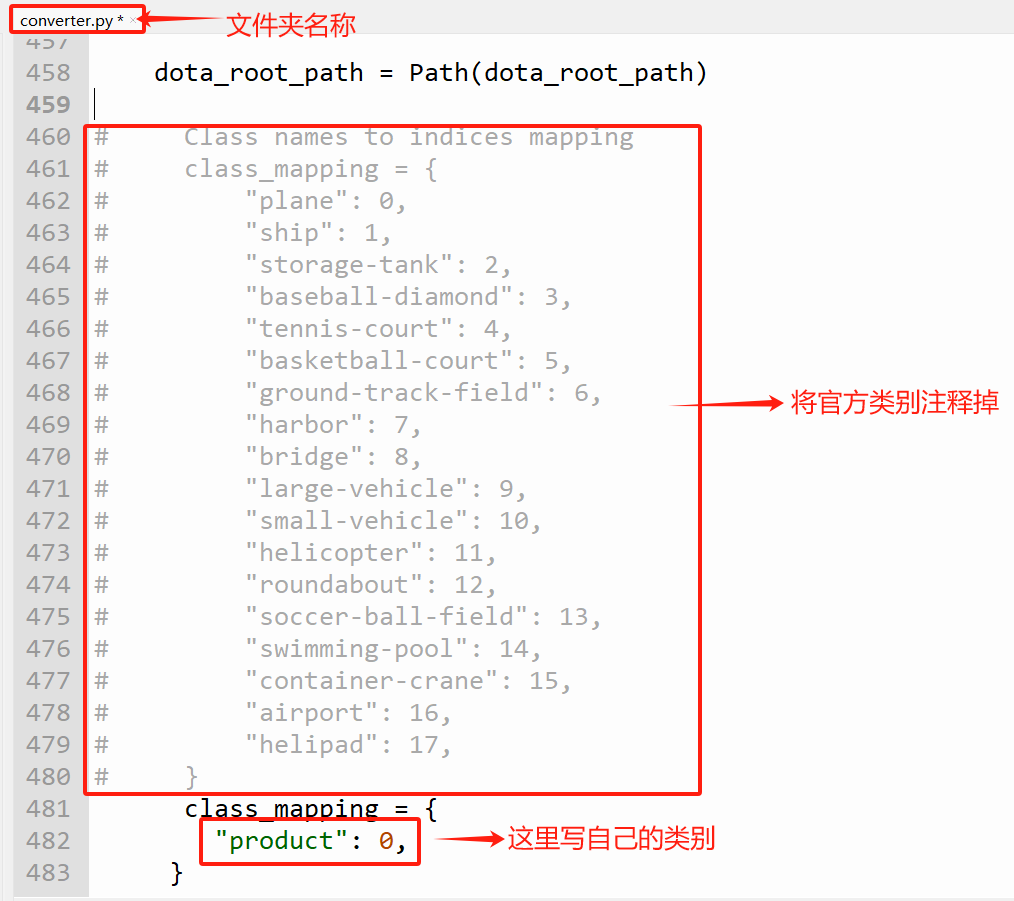
在ultralytics-main\ultralytics\data中找到一个名为converter.py的文件,找到约460行的代码,进行如下图的操作:
然后在data文件夹下新建一个名为'convertTOobb.py'的文件:
填入以下代码并运行:
import converter
converter.convert_dota_to_yolo_obb(r'C:/Users/HYPAB/Desktop/roLabelImg-master/data/product') #改为自己电脑数据集的路径至此,用于模型训练的数据集制作好了。
(注意:如果电脑除了mind+,还有其它python环境,运行convertTOobb.py可能会报错,按照上一步去对应python环境下修改converter.py并保存即可。)
4.2模型训练
我们首先要去ultralytics的官方仓库下载YOLO项目文件。链接:https://github.com/ultralytics/ultralytics。如下图,将官方文件夹下载下来,并解压(文件夹已附在在本篇文档的最后)。
将文件放到一个能找到的路径,打开Mind+,选择Python模式下的代码模式,如下图。
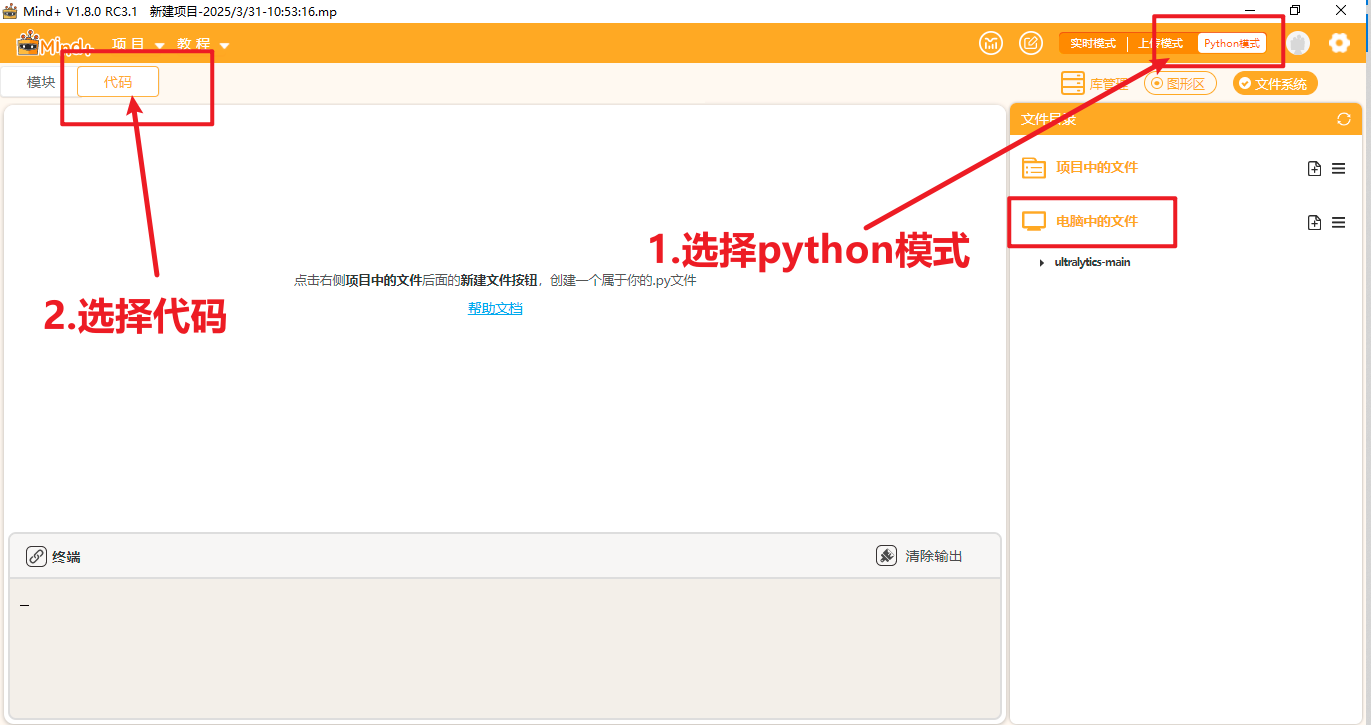
在右侧“文件系统”中找到"电脑中的文件",找到此文件夹进行添加。
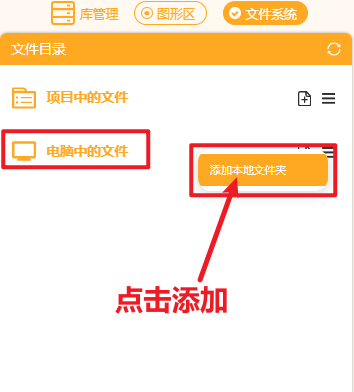
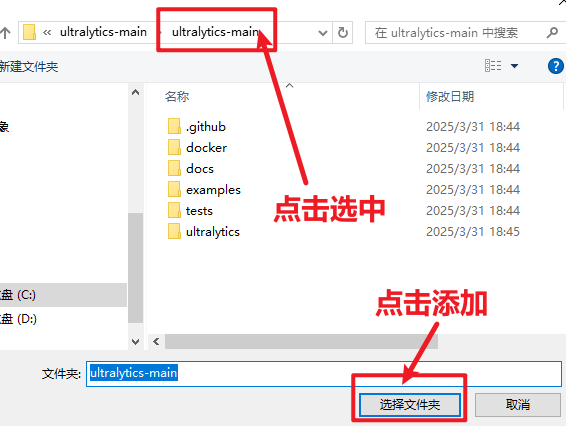
添加好后可以观察到如此下图。
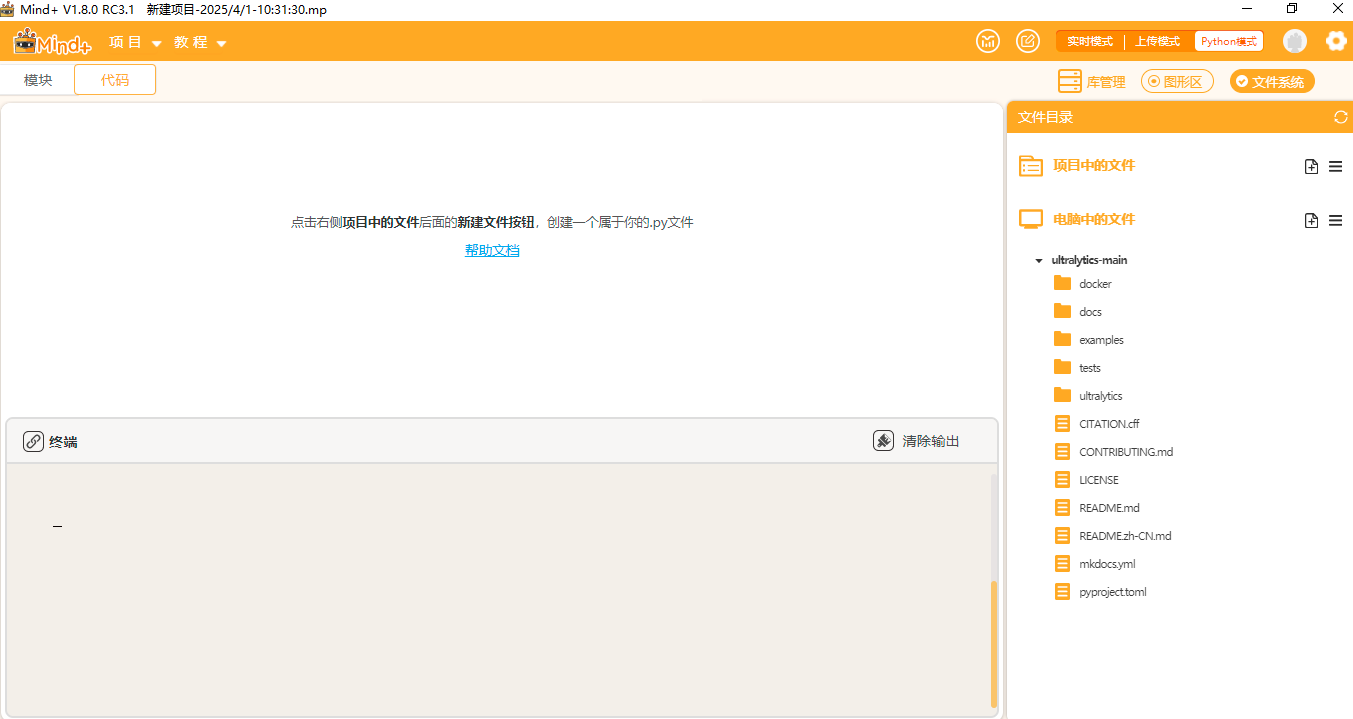
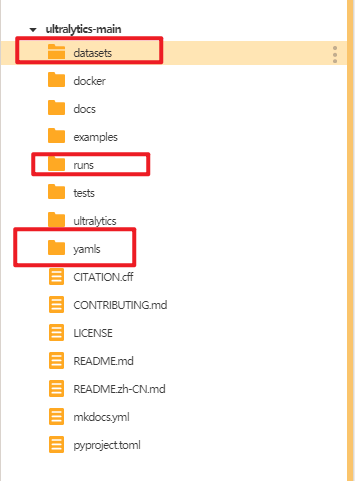
点击"新建文件夹",在ultralytics文件夹中分别新建三个文件夹,依次命名为"datasets"(用于存放数据集),"yamls"(用于存放数据集对应的yaml文件)"runs"(用于存放训练模型的py文件)。
建好后如下图。
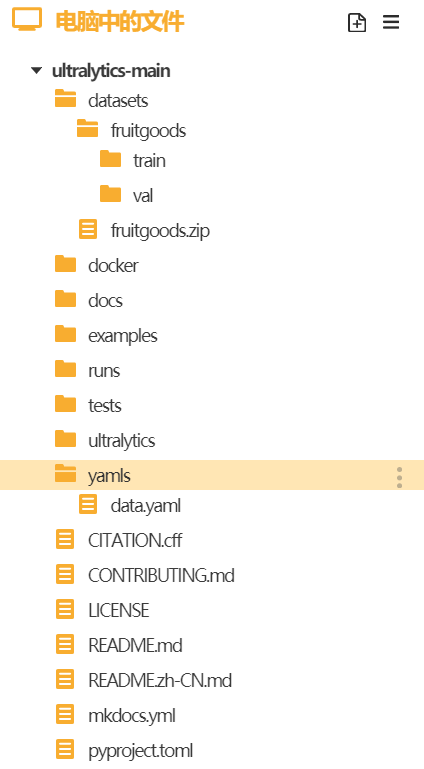
将货物位置检测数据集的训练集和验证集文件夹放入"datasets"文件夹,将货物位置检测数据集的yaml文件放入"yamls"文件夹。
接着我们在"runs"文件夹中建立一个叫做"train1.py"的文件,在此文件中编写训练YOLO模型的代码。
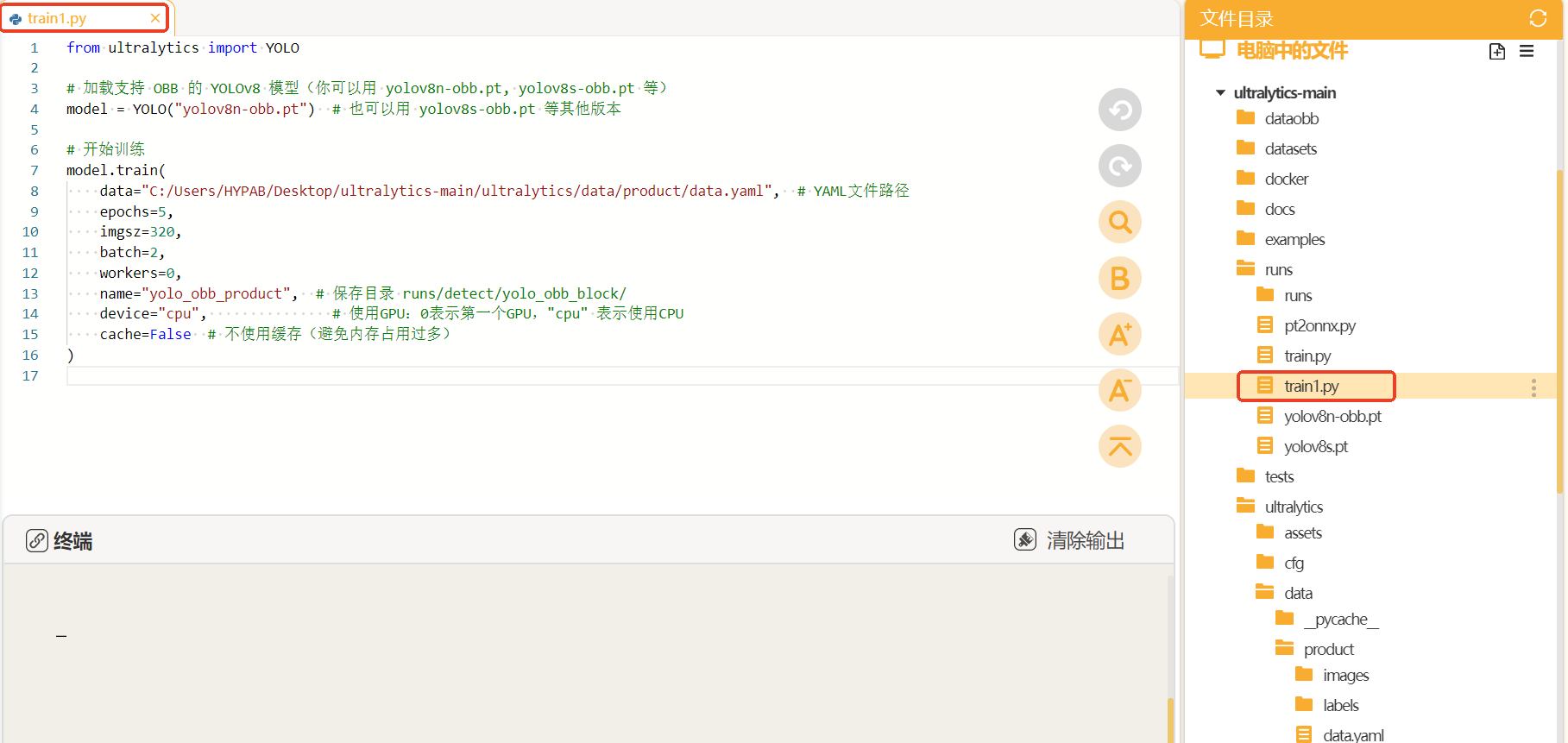
将训练代码粘贴到train.py中点击运行。我们在预训练模型"yolov8n-obb.pt"基础上进行货物位置检测模型的训练,设置训练轮次是5轮。图片的尺寸是320。
from ultralytics import YOLO # 导入YOLO类,用于加载和训练模型
# 加载支持 OBB 的 YOLOv8 模型(你可以用 yolov8n-obb.pt, yolov8s-obb.pt 等)
model = YOLO("yolov8n-obb.pt") # 也可以用 yolov8s-obb.pt 等其他版本
# 开始训练
model.train(
data="C:/Users/HYPAB/Desktop/ultralytics-main/ultralytics/data/product/data.yaml", # YAML文件路径,注意改为自己的文件路径
epochs=5, # 设置训练轮数为5(通常需要更多轮数,这里选用5次,可以修改)
imgsz=320, # 设置输入图像大小为320x320,降低图像大小可以减少显存占用,适合资源有限的环境
batch=2, # 设置批量大小为2,降低批量大小可以减少显存占用,但可能影响训练效率
workers=0, # 数据加载线程数(Windows系统建议设置为0)
# workers=0 表示主进程加载数据,避免多线程问题
name="yolo_obb_product", # 保存目录 runs/detect/yolo_obb_block/
device="cpu", # 使用GPU:0表示第一个GPU,"cpu" 表示使用CPU
cache=False # 不使用缓存(避免内存占用过多)
)运行时可观察终端,自动下载预训练模型"yolov8s.pt",进行模型的训练。
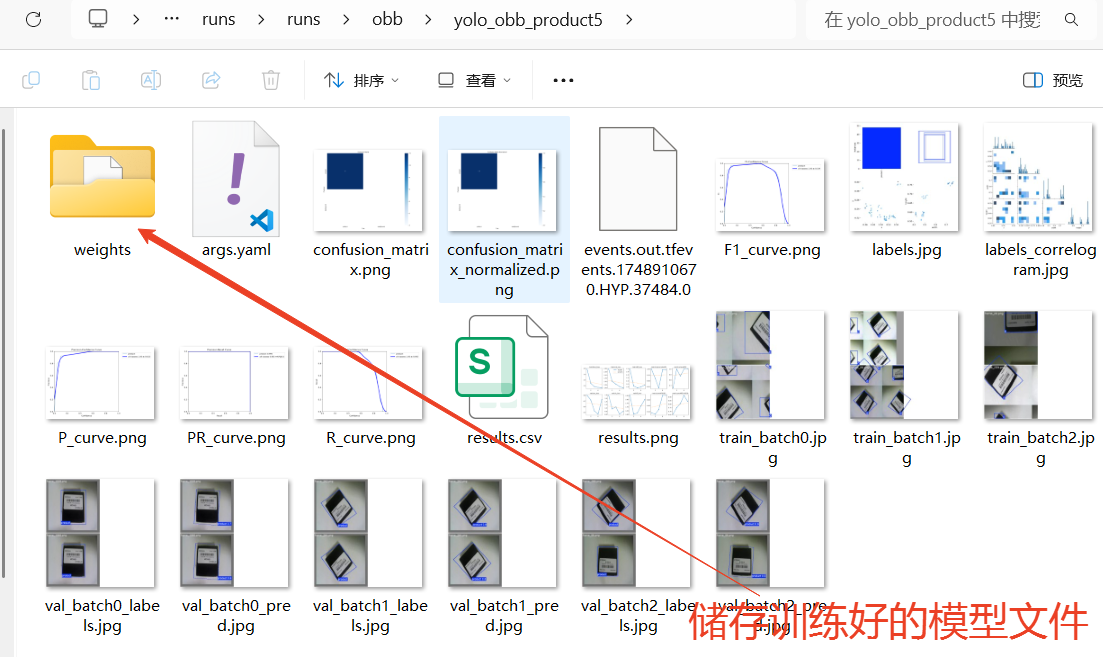
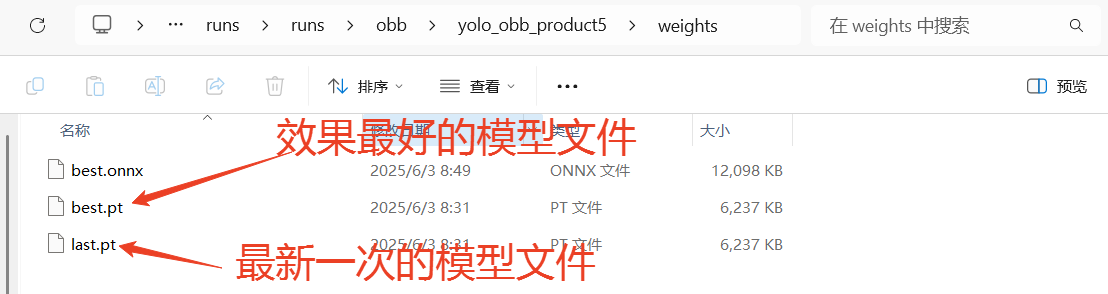
YOLO模型的训练对电脑的配置要求比较高,使用电脑CPU一般训练时间较长,可以考虑使用GPU或者云端算力进行训练,这里我们使用的时本地电脑的CPU训练方法,操作比较简单,耗时略长。当训练完成后,我们可以观察"runs"文件夹中自动生成了"obb"文件夹,里面存放了训练模型的数据和训练好的模型文件。
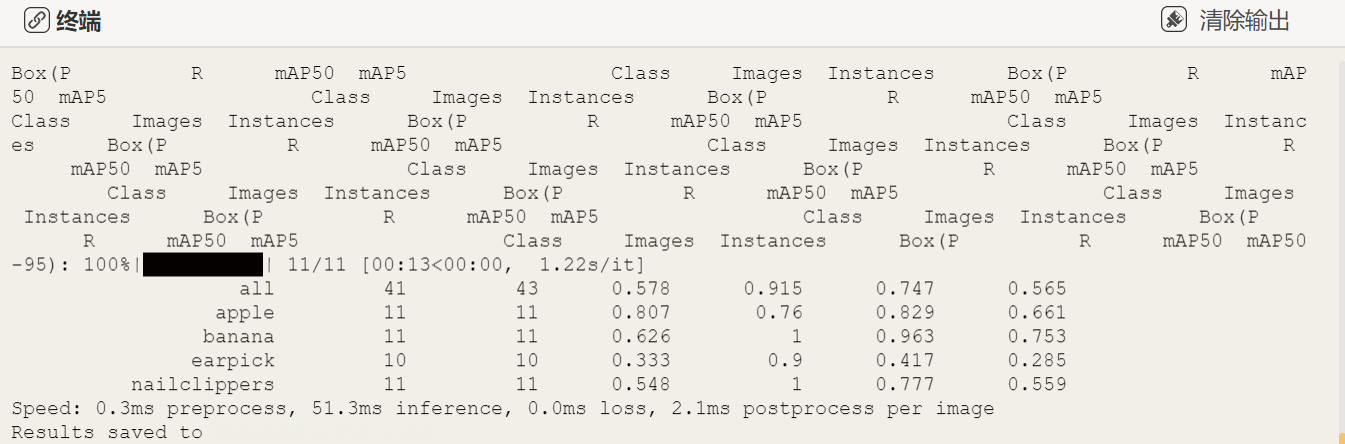
模型训练完成可以观察终端出现以下数据,是标记的所有商品类别标签和它的准确率、召回率、F1等数据。
4.3模型转换
我们训练得到的"best.pt"可以直接用于推理,我们也可以将"best.pt"转成onnx格式的模型文件。ONNX格式也是一种模型文件的格式,更加通用,可以与各种推理引擎兼容,提供更高效的推理速度。
使用以下代码将pt格式的模型文件转成onnx格式的模型文件。
from ultralytics import YOLO
# 模型路径,这里填你的pt文件的实际路径
model_path = r'C:/Users/HYPAB/Desktop/ultralytics-main/runs/runs/obb/yolo_obb_product5/weights/best.pt' # 训练完成后保存的模型路径
# 加载模型
model = YOLO(model_path)
# 导出为onnx格式
model.export(format='onnx')
print("模型已成功导出为onnx格式")转换好后,可以在同一目录下找到转换好的onnx模型。
4.4模型测评与导出
我们先在电脑端测试一下模型的性能,将训练好的模型拖入Mind+项目中的文件下,这里使用pt模型,也可以使用onnx模型。
再在项目中的文件中新建一个叫做"img_inference.py"(用来测试图片推理效果),同时将测试图片"frame_262.png"也拖入项目中的文件夹下。
测试图片如下图所示,由于我们训练模型时规定的输入尺寸为320*320,所以推理时图片尺寸不得大于这个尺寸。

将以下代码复制到"img_inference.py"文件中进行图片推理测试。
from ultralytics import YOLO
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# 加载模型
model = YOLO("best.pt")
# 加载并调整图像尺寸
image = cv2.imread("frame_262.png")
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image_rgb, (320, 320)) # 匹配模型输入尺寸
# 推理
results = model(resized_image, conf=0.1)
# 解析结果并输出角度
for result in results:
if result.obb:
xywhr = result.obb.xywhr.cpu().numpy()
names = [result.names[cls.item()] for cls in result.obb.cls.int()]
confs = result.obb.conf.cpu().numpy()
for i in range(len(xywhr)):
xc, yc, w, h, angle_rad = xywhr[i] # angle_rad 是以弧度表示的角度
angle_deg = np.degrees(angle_rad) # 转换为度数
# 输出到终端
print(f"检测到物体: {names[i]}")
print(f"置信度: {confs[i]:.2f}")
print(f"中心坐标 (x,y): ({xc:.1f}, {yc:.1f})")
print(f"宽度和高度 (w,h): ({w:.1f}, {h:.1f})")
print(f"旋转角度 (弧度): {angle_rad:.2f}")
print(f"旋转角度 (度数): {angle_deg:.2f}°")
print("-" * 50) # 分隔线
# 绘制旋转框
rect = ((xc, yc), (w, h), angle_deg)
polygon = cv2.boxPoints(rect).astype(int)
scale_x = image.shape[1] / 320
scale_y = image.shape[0] / 320
polygon[:, 0] = (polygon[:, 0] * scale_x).astype(int)
polygon[:, 1] = (polygon[:, 1] * scale_y).astype(int)
cv2.polylines(image, [polygon], True, (0, 255, 0), 2)
# 使用Pillow绘制文本
# 将OpenCV图像转换为Pillow图像
pillow_img = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pillow_img)
# 指定字体文件路径和字体大小
try:
font = ImageFont.truetype("arial.ttf", 20) # Windows
#font = ImageFont.truetype("/System/Library/Fonts/PingFang.ttc", 20) # macOS
# font = ImageFont.truetype("usr/share/fonts/truetype/freefont/FreeSans.ttf", 20) # Linux
except IOError:
font = ImageFont.load_default()
# 绘制三行文本
text1 = f"{names[i]} {confs[i]:.2f}"
text2 = f"rad {angle_rad:.2f}"
text3 = f"angel {angle_deg:.2f}°"
# 在左下角绘制三行文本
x = 10
y = image.shape[0] - 65 # 调整起始位置,确保三行文本都在图像内
draw.text((x, y), text1, fill=(0, 0, 255), font=font)
draw.text((x, y + 20), text2, fill=(0, 0, 255), font=font)
draw.text((x, y + 40), text3, fill=(0, 0, 255), font=font)
# 将Pillow图像转换回OpenCV图像
image = cv2.cvtColor(np.array(pillow_img), cv2.COLOR_RGB2BGR)
else:
print("No OBB detected.")
cv2.imshow("Result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()点击Mind+右上角的”运行",运行代码观察效果。
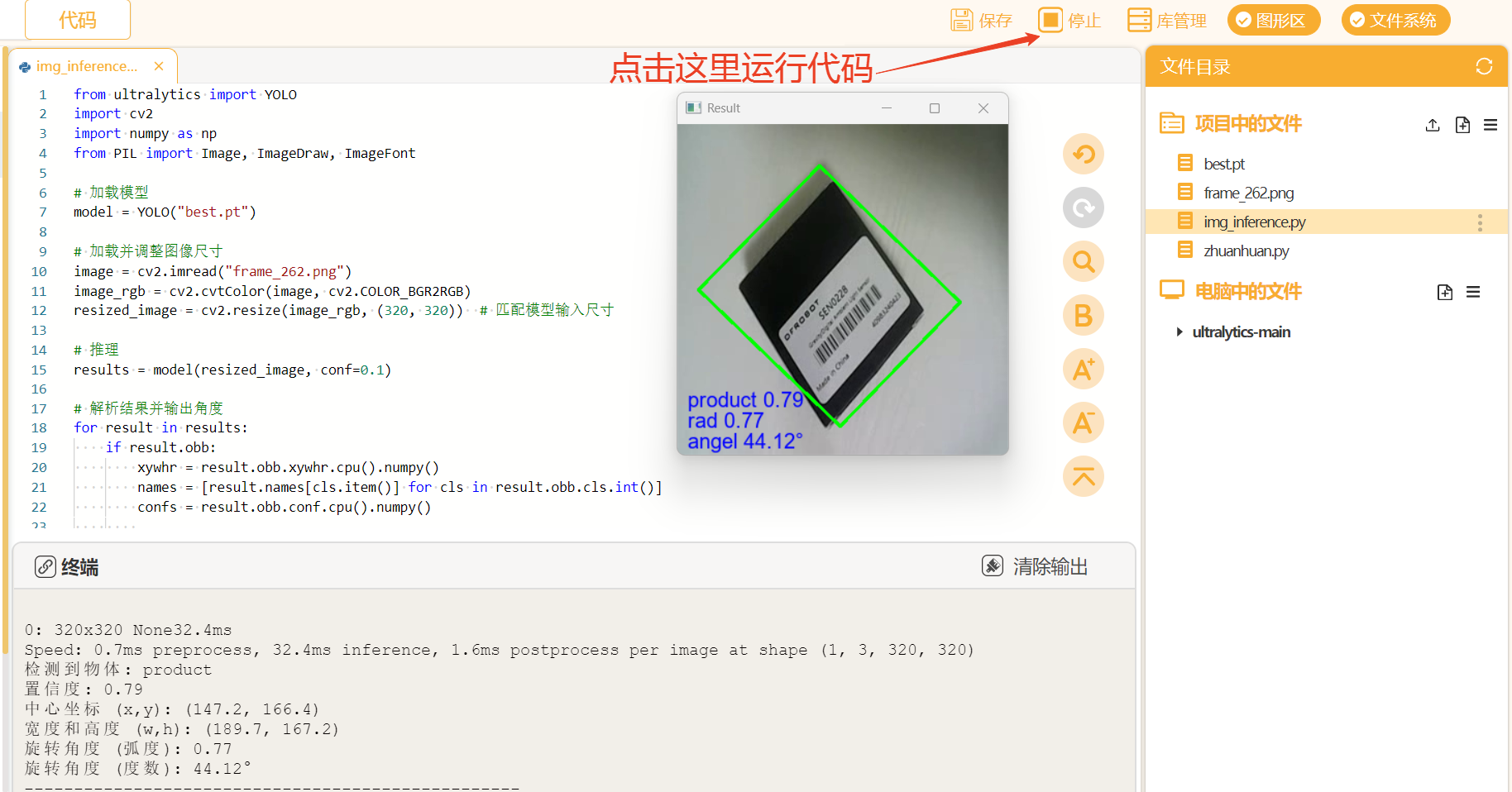
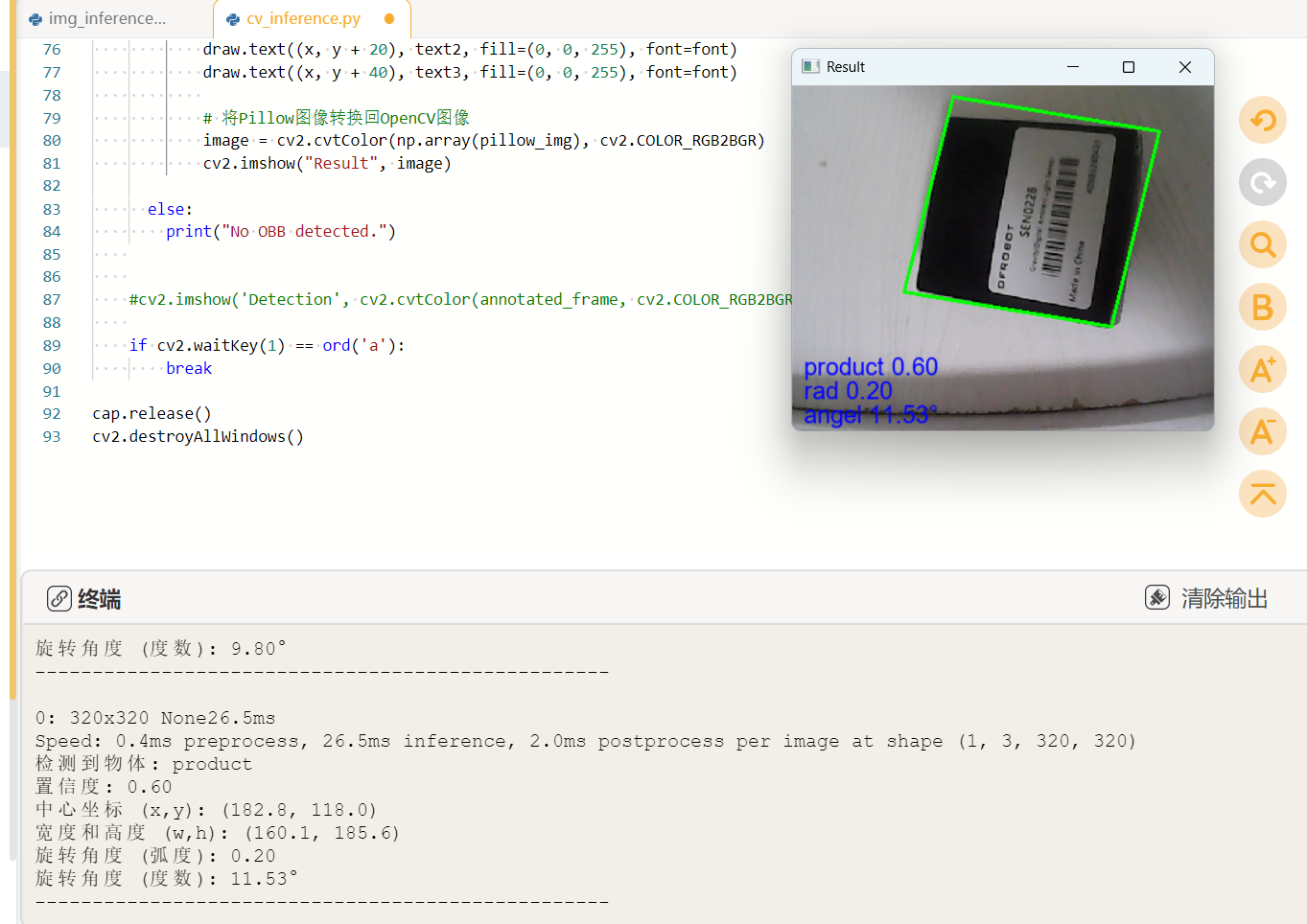
当程序运行时,可以观察到弹出以下窗口,显示在测试图片上的推理结果。观察图片,图片上显示货物名称、置信度、弧度、角度等信息,效果比较好。

观察终端的输出,可以看到终端出现了货物名称及位置等信息。

from ultralytics import YOLO
import time
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# 加载模型
model = YOLO("best.pt")
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320)
while True:
ret, frame = cap.read()
if not ret:
break
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image_rgb, (320, 320)) # 匹配模型输入尺寸
# 推理
results = model(resized_image, conf=0.1)
# 解析结果并输出角度
for result in results:
if result.obb:
xywhr = result.obb.xywhr.cpu().numpy()
names = [result.names[cls.item()] for cls in result.obb.cls.int()]
confs = result.obb.conf.cpu().numpy()
for i in range(len(xywhr)):
xc, yc, w, h, angle_rad = xywhr[i] # angle_rad 是以弧度表示的角度
angle_deg = np.degrees(angle_rad) # 转换为度数
# 输出到终端
print(f"检测到物体: {names[i]}")
print(f"置信度: {confs[i]:.2f}")
print(f"中心坐标 (x,y): ({xc:.1f}, {yc:.1f})")
print(f"宽度和高度 (w,h): ({w:.1f}, {h:.1f})")
print(f"旋转角度 (弧度): {angle_rad:.2f}")
print(f"旋转角度 (度数): {angle_deg:.2f}°")
print("-" * 50) # 分隔线
# 绘制旋转框
rect = ((xc, yc), (w, h), angle_deg)
polygon = cv2.boxPoints(rect).astype(int)
scale_x = frame.shape[1] / 320
scale_y = frame.shape[0] / 320
polygon[:, 0] = (polygon[:, 0] * scale_x).astype(int)
polygon[:, 1] = (polygon[:, 1] * scale_y).astype(int)
cv2.polylines(frame, [polygon], True, (0, 255, 0), 2)
# 使用Pillow绘制文本
# 将OpenCV图像转换为Pillow图像
pillow_img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pillow_img)
# 指定字体文件路径和字体大小
try:
font = ImageFont.truetype("arial.ttf", 20) # Windows
#font = ImageFont.truetype("/System/Library/Fonts/PingFang.ttc", 20) # macOS
# font = ImageFont.truetype("usr/share/fonts/truetype/freefont/FreeSans.ttf", 20) # Linux
except IOError:
font = ImageFont.load_default()
# 绘制三行文本
text1 = f"{names[i]} {confs[i]:.2f}"
text2 = f"rad {angle_rad:.2f}"
text3 = f"angel {angle_deg:.2f}°"
# 在左下角绘制三行文本
x = 10
y = frame.shape[0] - 65 # 调整起始位置,确保三行文本都在图像内
draw.text((x, y), text1, fill=(0, 0, 255), font=font)
draw.text((x, y + 20), text2, fill=(0, 0, 255), font=font)
draw.text((x, y + 40), text3, fill=(0, 0, 255), font=font)
# 将Pillow图像转换回OpenCV图像
image = cv2.cvtColor(np.array(pillow_img), cv2.COLOR_RGB2BGR)
cv2.imshow("Result", image)
time.sleep(1) #加入延迟,为了避免检测过快,可以去掉
else:
print("No OBB detected.")
if cv2.waitKey(1) == ord('a'):
break
cap.release()
cv2.destroyAllWindows()运行程序,可以发现一个窗口实时显示摄像头捕捉画面,并实时显示画面中的货物位置等信息。这里视频流的尺寸仍是320*320。
4.5部署模型到行空板完成执行操作
接着我们可以部署模型到行空板中制作货物位置自动校正装置。使用USB数据线连接电脑与行空板。

连接行空板与摄像头。

打开编程软件Mind+,点击左下角的扩展,在官方库中找到行空板库点击加载
点击返回,点击连接设备,找到10.1.2.3点击连接,等待连接成功。
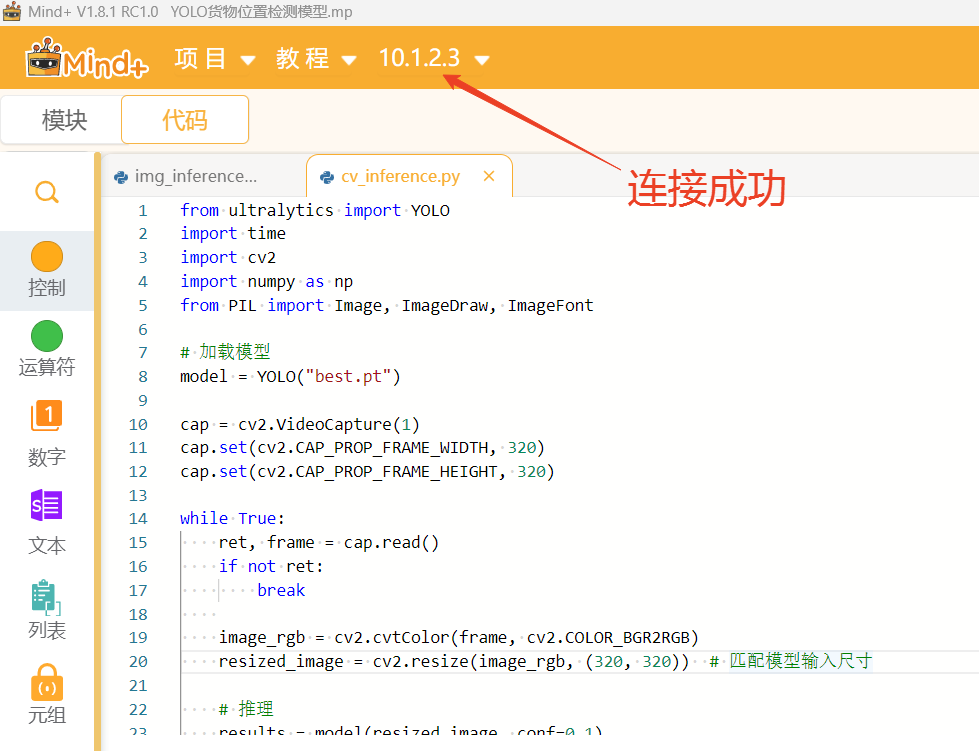
我们选中模型文件点击上传到行空板中。上传成功能在行空板的根目录下找到模型文件。
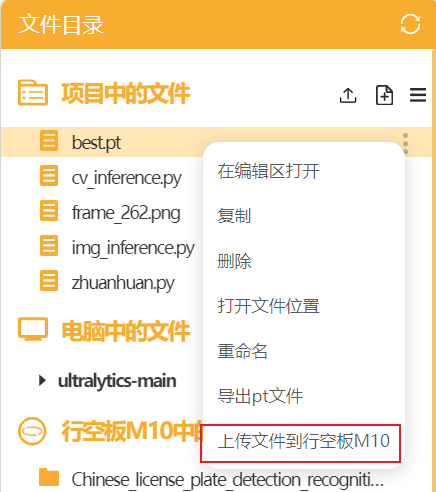

因为需要屏幕显示货物位置信息等结果,所以新建了"cv_auto_correct.py"文件(文章末尾的mp文件里面有该文件)。
保持行空板的连接,在终端输入以下指令来激活行空板的yolo环境(请确保完成3.2硬件环境部署准备)。
conda activate yolo
接着在终端输入以下指令,在行空板中运行"cv_auto_correct.py"文件,第一次加载模型比较慢,请耐心等待。
python cv_auto_correct.py
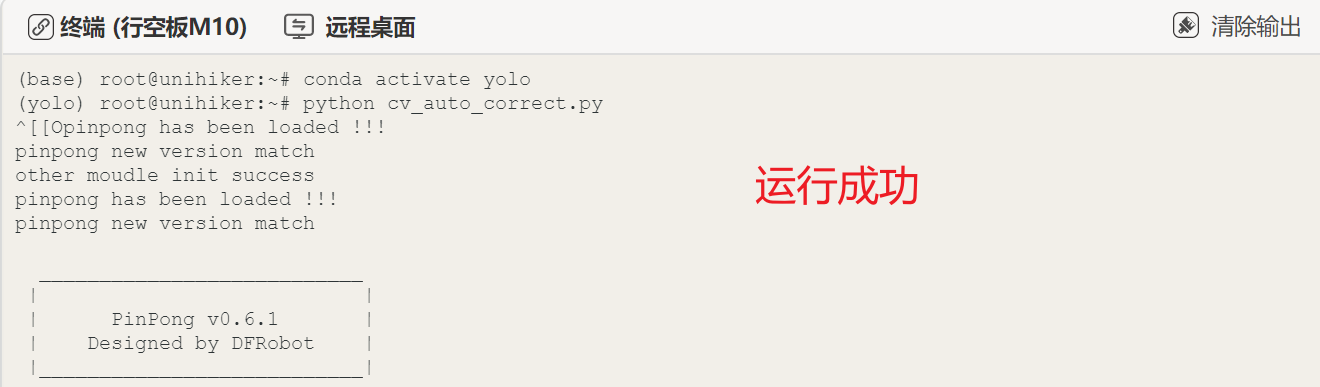
运行成功后,调整下摄像头然后正对准货物,按下按钮保存图片并开始推理,行空板屏幕显示货物位置信息在左下角,经过几秒之后舵机转动完成校正。这样,成功实现了货物位置自动校正装置的功能。

4.6核心代码解析
我们一起来看一下在行空板上运行的'cv_auto_correct.py'代码的核心功能代码。
如下图,此程序主要分成以下几个部分:
1.YOLO模型加载以及摄像头初始化、按钮舵机等硬件初始化。
from ultralytics import YOLO
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from pinpong.board import Servo
from pinpong.board import Board, Pin
from pinpong.extension.unihiker import *
Board().begin()
p_p21_in=Pin(Pin.P21, Pin.IN)
servo1 = Servo(Pin((Pin.P22)))
servo1.write_angle(45)
# 加载模型
model = YOLO("best.pt")
# 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 屏幕分辨率(假设屏幕分辨率为 320x240,根据实际情况调整)
screen_width = 240
screen_height = 320
# 创建 OpenCV 窗口,确保无边框且全屏显示
cv2.namedWindow('Detection', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
# 隐藏窗口边框和标题栏(如果当前环境支持的话)
cv2.namedWindow('Detection', cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
while True:
# 从摄像头读取帧
ret, frame = cap.read()
if not ret:
break
# 获取摄像头图像的宽高
h, w, _ = frame.shape
# 根据屏幕宽高比例裁剪图像
aspect_ratio_screen = screen_width / screen_height
aspect_ratio_frame = w / h
if aspect_ratio_frame > aspect_ratio_screen:
# 图像宽度过大,需要裁剪宽度
new_width = int(h * aspect_ratio_screen)
x_offset = (w - new_width) // 2
cropped_frame = frame[:, x_offset:x_offset + new_width]
else:
# 图像高度过大,需要裁剪高度
new_height = int(w / aspect_ratio_screen)
y_offset = (h - new_height) // 2
cropped_frame = frame[y_offset:y_offset + new_height, :]
# 将裁剪后的图像调整为目标分辨率(完全填充屏幕,无上下边界)
resized_frame = cv2.resize(cropped_frame, (screen_width, screen_height))2.按下按钮保存图片并推理,显示推理效果及原始结果输出。
if (p_p21_in.read_digital()==True):
cv2.imwrite("Mind+.png", resized_frame)
resized_frame = cv2.imread("Mind+.png", cv2.IMREAD_UNCHANGED)
# 转换颜色空间 (BGR -> RGB) 供 YOLO 使用
frame_rgb = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 推理
results = model(frame_rgb, conf=0.1)
print("推理完成,显示物体信息")
# 解析结果并绘制旋转框和文本
for result in results:
if result.obb:
xywhr = result.obb.xywhr.cpu().numpy()
names = [result.names[cls.item()] for cls in result.obb.cls.int()]
confs = result.obb.conf.cpu().numpy()
for i in range(len(xywhr)):
xc, yc, w, h, angle_rad = xywhr[i]
angle_deg = np.degrees(angle_rad)
# 输出到终端
print(f"检测到物体: {names[i]}")
print(f"置信度: {confs[i]:.2f}")
print(f"中心坐标 (x,y): ({xc:.1f}, {yc:.1f})")
print(f"宽度和高度 (w,h): ({w:.1f}, {h:.1f})")
print(f"旋转角度 (弧度): {angle_rad:.2f}")
print(f"旋转角度 (度数): {angle_deg:.2f}°")
print("-" * 50) # 分隔线3.屏幕显示推理结果以及舵机转动(显示物体名称、置信度、弧度、角度等信息)。
# 绘制旋转框
rect = ((xc, yc), (w, h), angle_deg)
polygon = cv2.boxPoints(rect).astype(int)
scale_x = resized_frame.shape[1] / screen_width
scale_y = resized_frame.shape[0] / screen_height
polygon[:, 0] = (polygon[:, 0] * scale_x).astype(int)
polygon[:, 1] = (polygon[:, 1] * scale_y).astype(int)
cv2.polylines(resized_frame, [polygon], True, (0, 255, 0), 2)
# 使用 Pillow 绘制文本
pillow_img = Image.fromarray(cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pillow_img)
try:
#font = ImageFont.truetype("/usr/share/fonts/truetype/freefont/FreeSans.ttf", 50) # Linux
font = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 15)
except IOError:
font = ImageFont.load_default()
text1 = f"{names[i]} {confs[i]:.2f}"
text2 = f"rad {angle_rad:.2f}"
text3 = f"angle {angle_deg:.2f}°"
x = 10
y = screen_height - 65
draw.text((x, y), text1, fill=(0, 0, 255), font=font)
draw.text((x, y + 20), text2, fill=(0, 0, 255), font=font)
draw.text((x, y + 40), text3, fill=(0, 0, 255), font=font)
resized_frame = cv2.cvtColor(np.array(pillow_img), cv2.COLOR_RGB2BGR)
processed_frame = resized_frame
cv2.imshow('Detection', processed_frame)
cv2.waitKey(5000) # 暂停 5 秒
servo1.write_angle(90)
cv2.waitKey(5000) # 暂停 5 秒
# 显示裁剪后的图像(完全适配屏幕分辨率,无上下留边,无图标)
cv2.imshow('Detection', resized_frame)
# 按下 'q' 键或者行空板 B 键退出循环
if (cv2.waitKey(10) & 0xff == ord('q') or (button_b.is_pressed() == True)):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()其中第1的部分是通用代码,屏幕显示推理结果信息、控制执行器等可以自定义。



怎么二次处理原始推理结果呢?,我们先来看看原始推理输出的结果有什么吧!
在程序中,我们使用的是以下语句来获取模型推理和打印推理结果。model()是YOLO模型的推理函数,conf=0.1设置置信度阈值为0.1,只有置信度大于或等于这个阈值的检测结果才会被保留,这个值可以根据实际需要进行修改。results存储了模型推理的输出结果。可以使用print语句将results打印出来。
# 使用YOLO模型进行目标检测
results = model(resized_image, conf=0.1) # 对RGB图像进行推理,指定输入图像尺寸为320x320,并设置置信度阈值0.1才输出
print('模型的原始输出:',results)打印模型推理的原始结果如下图所示:

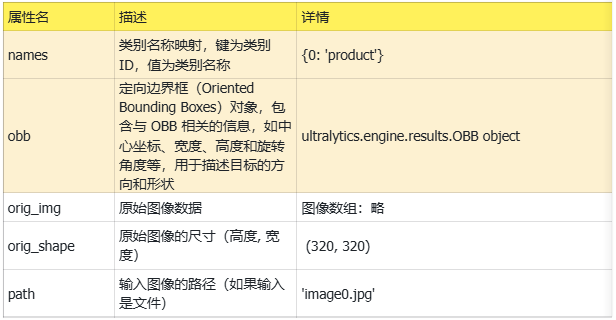
这里,以表格的形式整理了模型原始输出的全部内容,如下。我们可以观察到原始的推理输出有比较多的内容,在项目的人制作中不是每一个输出数据都要用到,其中本项目最常被用的数据是"names"和"obb"。names: 提供类别ID到类别名称的映射,用于将检测结果转换为人类可读的类别名称。obb:代表定向边界框(Oriented Bounding Boxes)对象,包含与 OBB 相关的信息,如中心坐标、宽度、高度和旋转角度等,用于描述目标的方向和形状。
完整代码如下所示:
from ultralytics import YOLO
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from pinpong.board import Servo
from pinpong.board import Board, Pin
from pinpong.extension.unihiker import *
Board().begin()
p_p21_in=Pin(Pin.P21, Pin.IN)
servo1 = Servo(Pin((Pin.P22)))
servo1.write_angle(45)
# 加载模型
model = YOLO("best.pt")
# 打开摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 屏幕分辨率(假设屏幕分辨率为 320x240,根据实际情况调整)
screen_width = 240
screen_height = 320
# 创建 OpenCV 窗口,确保无边框且全屏显示
cv2.namedWindow('Detection', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
# 隐藏窗口边框和标题栏(如果当前环境支持的话)
cv2.namedWindow('Detection', cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO)
cv2.setWindowProperty('Detection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
while True:
# 从摄像头读取帧
ret, frame = cap.read()
if not ret:
break
# 获取摄像头图像的宽高
h, w, _ = frame.shape
# 根据屏幕宽高比例裁剪图像
aspect_ratio_screen = screen_width / screen_height
aspect_ratio_frame = w / h
if aspect_ratio_frame > aspect_ratio_screen:
# 图像宽度过大,需要裁剪宽度
new_width = int(h * aspect_ratio_screen)
x_offset = (w - new_width) // 2
cropped_frame = frame[:, x_offset:x_offset + new_width]
else:
# 图像高度过大,需要裁剪高度
new_height = int(w / aspect_ratio_screen)
y_offset = (h - new_height) // 2
cropped_frame = frame[y_offset:y_offset + new_height, :]
# 将裁剪后的图像调整为目标分辨率(完全填充屏幕,无上下边界)
resized_frame = cv2.resize(cropped_frame, (screen_width, screen_height))
if (p_p21_in.read_digital()==True):
cv2.imwrite("Mind+.png", resized_frame)
resized_frame = cv2.imread("Mind+.png", cv2.IMREAD_UNCHANGED)
# 转换颜色空间 (BGR -> RGB) 供 YOLO 使用
frame_rgb = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 推理
results = model(frame_rgb, conf=0.1)
print("推理完成,显示物体信息")
# 解析结果并绘制旋转框和文本
for result in results:
if result.obb:
xywhr = result.obb.xywhr.cpu().numpy()
names = [result.names[cls.item()] for cls in result.obb.cls.int()]
confs = result.obb.conf.cpu().numpy()
for i in range(len(xywhr)):
xc, yc, w, h, angle_rad = xywhr[i]
angle_deg = np.degrees(angle_rad)
# 输出到终端
print(f"检测到物体: {names[i]}")
print(f"置信度: {confs[i]:.2f}")
print(f"中心坐标 (x,y): ({xc:.1f}, {yc:.1f})")
print(f"宽度和高度 (w,h): ({w:.1f}, {h:.1f})")
print(f"旋转角度 (弧度): {angle_rad:.2f}")
print(f"旋转角度 (度数): {angle_deg:.2f}°")
print("-" * 50) # 分隔线
# 绘制旋转框
rect = ((xc, yc), (w, h), angle_deg)
polygon = cv2.boxPoints(rect).astype(int)
scale_x = resized_frame.shape[1] / screen_width
scale_y = resized_frame.shape[0] / screen_height
polygon[:, 0] = (polygon[:, 0] * scale_x).astype(int)
polygon[:, 1] = (polygon[:, 1] * scale_y).astype(int)
cv2.polylines(resized_frame, [polygon], True, (0, 255, 0), 2)
# 使用 Pillow 绘制文本
pillow_img = Image.fromarray(cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pillow_img)
try:
#font = ImageFont.truetype("/usr/share/fonts/truetype/freefont/FreeSans.ttf", 50) # Linux
font = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 15)
except IOError:
font = ImageFont.load_default()
text1 = f"{names[i]} {confs[i]:.2f}"
text2 = f"rad {angle_rad:.2f}"
text3 = f"angle {angle_deg:.2f}°"
x = 10
y = screen_height - 65
draw.text((x, y), text1, fill=(0, 0, 255), font=font)
draw.text((x, y + 20), text2, fill=(0, 0, 255), font=font)
draw.text((x, y + 40), text3, fill=(0, 0, 255), font=font)
resized_frame = cv2.cvtColor(np.array(pillow_img), cv2.COLOR_RGB2BGR)
processed_frame = resized_frame
cv2.imshow('Detection', processed_frame)
cv2.waitKey(5000) # 暂停 5 秒
servo1.write_angle(90)
cv2.waitKey(5000) # 暂停 5 秒
# 显示裁剪后的图像(完全适配屏幕分辨率,无上下留边,无图标)
cv2.imshow('Detection', resized_frame)
# 按下 'q' 键或者行空板 B 键退出循环
if (cv2.waitKey(10) & 0xff == ord('q') or (button_b.is_pressed() == True)):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()项目扩展思考:后续可以通过记录货物位置偏差和校正操作的数据,为仓储管理提供分析支持,优化库存布局和操作流程。
5.项目相关资料附录
本项目相关文档:https://pan.baidu.com/s/1CFjDWOy8f_y_Bp34xZqm4A?pwd=8hm8



 他的勋章
他的勋章

罗罗罗2025.11.17
666
easy猿2025.08.27
牛