 返回首页
返回首页
 回到顶部
回到顶部
有幸参加人工智能创新型教师培育计划(第一期),本期活动主题为人工智能经典实验挑战。培训以“机器学习”“深度学习”与“模型部署”为主要内容,以经典实验操作核心学科技能。今天分享学习内容,是南通大学附属中学刘正云老师讲授的《人工智能实验之机器学习》。(文章内容整理于南通大学附属中学刘正云老师教学PPT)
1、什么是机器学习 1.1在已知的数据中学习规律从而建立模型,并且借助更多 的数据自动修正、优化模型, 最终利⽤模型解决问题的AI 研究⽅法叫做“机器学习”。 1.2机器学习实际上分为两个阶段:在已知数据中学习规 律,叫做“模型训练”,即 “学习”;将新的数据输⼊ 到模型中得出结果,叫做 “模型推理”,即“应⽤”。
2、机器学习的工作流程 机器学习的工作流程⼤致可以分为数据准备、模型搭建、模型训练、模型评估等环节。从⼯作流程看,训练AI模型的难度在数据准备和算法搭建,⽽训练的速度则决定于算力。 只要找到合适的工具,训练常见的AI模型并不困难。比如旋松⼀个螺帽,徒⼿很难,但能找到相应的⼯具(钢丝钳、扳手、套筒等)会容易。随着技术的发展,越来越多的 AI开发⼯具出现。
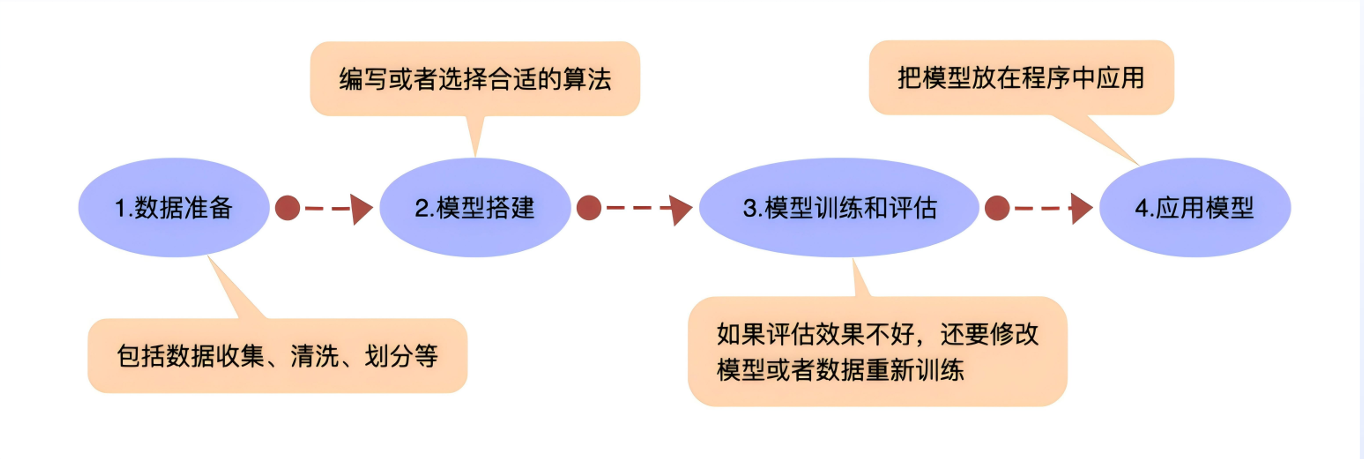
3、训练机器学习模型工具:XEdu XEdu是为AI教育设计的一套完整的学习与开发工具,遵照“极简”理念而开发,开箱即用。XEdu核心工具为深度学习工具库XEduHub、计算机视觉库MMEdu,加上神经网络库BaseNN和传统机器学习库BaseML等。
XEdu一键安装包下载地址:
p6bm2if73b.feishu.cn/file/boxcn7ejYk2XUDsHI3Miq9546Uf
下载最新版exe,同时建议准备win10电脑。
第一步:双击运行,将自解压为XEdu文件夹(安装到纯英文路径下)。
第二步:根据自己喜好,选择自己习惯的IDE。(XEdu自带Thonny、Jupyter)
(下图为解压后文件内容)
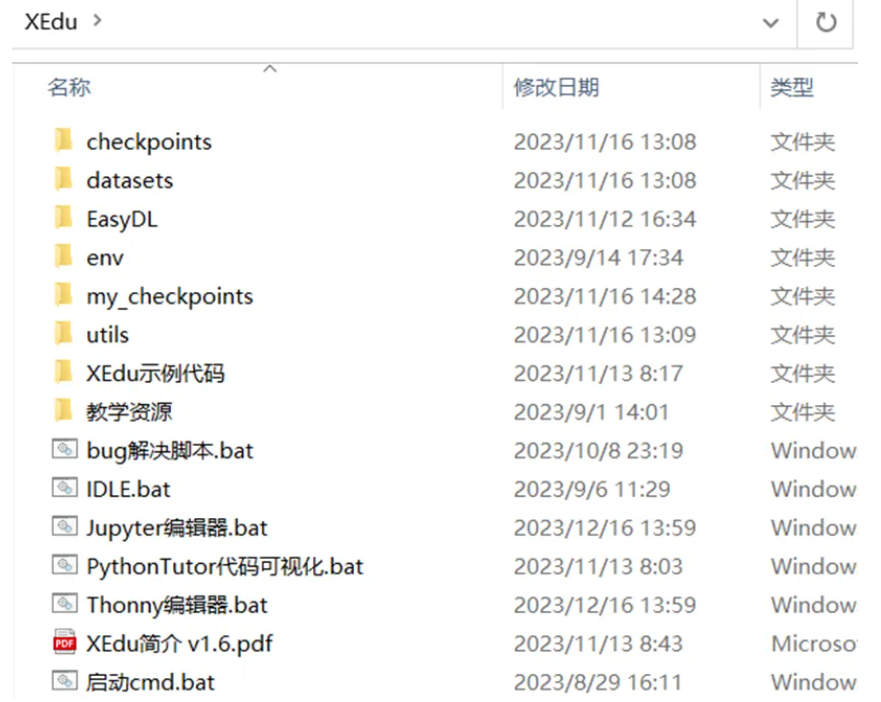
步骤1 XEdu下载及安装如下
4.机器学习的一般流程:
准备数据集——模型搭建与训练——模型验证——模型推理
5.训练温度传感器数据预测模型
5.1数据集准备(附件里有数据集,可供下载)
5.1.1数据采集
采集数据的方法有很多,本实验需要用到的数据,是通过行空板+温度传感器LM35进行测量的,以下是数据集展示:
LM35工作原理:温度传感器工作时,电路将测量到的温度信号转换成电压信号输出到信号放大电路,与温度值对应的电压信号经放大后输出至A/D转换电路,把电压信号转换成数字量送给主控板,此时获得的就是当前的温度值对应的模拟值,之后通过对模拟值进行处理,就可获得当前的温度值了。
5.1.2数据集划分
准备训练前,先要将数据集进行划分,将其拆分为训练集和验证集,训练集用于训练模型,验证集用于评估模型的性能。
此步骤可以手动完成,也可以用代码完成。
这里借助XEdu的数据处理库BaseDT,指定csv文件路径以及划分比例,将数据集划分为训练集(_train.csv)和验证集(_val.csv)。
# 更新库文件
!pip install --upgrade BaseDT
from BaseDT.dataset import split_tab_dataset
# 指定待拆分的csv数据集
path = "data/make_sensor.csv"
# 指定特征数据列、标签列、训练集比重
tx,ty,val_x,val_y =
split_tab_dataset(path,data_column=range(0,1),label_column=1,train_val_ratio=0.8)5.2模型搭建与训练 用BaseML训练机器学习模型
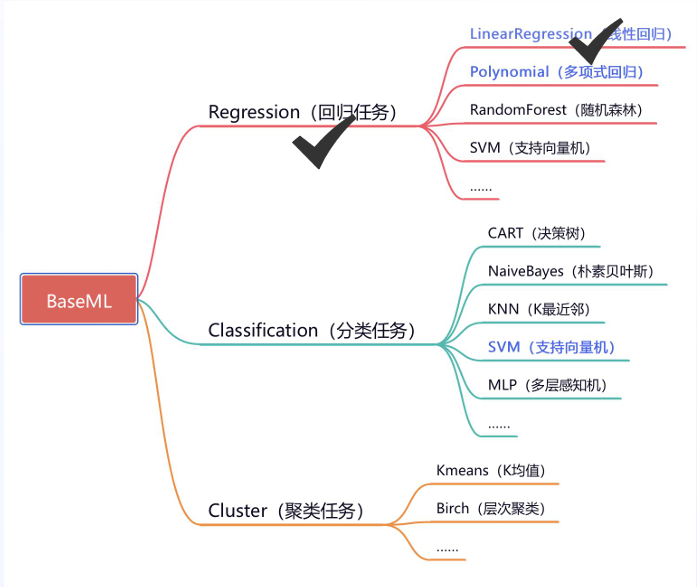
BaseML是"XEdu“中的一款子工具,用极简的代码引入各种的机器学习训练方法,如线性回归、KNN、SVM等等,从而快速训练或应用。
回归任务是预测连续值的任务。
例如:根据房屋面积、房屋年龄等特征预测房屋价格;
根据学生的平时成绩、学习时间等特征预测学生的期末分数;
根据上一年的产量、天气、农场员工数等属性预测下一年玉米农场的产量。
回归任务可以被分为线性回归和非线性回归两种。线性回归是假设输入特征和目标变量之间存在线性关系的回归任务;而非线性回归是假设输入特征和目标变量之间存在非线性关系的回归任务。
首先我们需要导入必要的库文件并构建线性回归模型。LinearRegression用于线性回归,它可以帮助我们建立和分析线性模型,从而预测变量之间的关系。
将数据集载入模型,进行模型训练,并将模型保存至指定路径。
#导入基础库/导入BaseML库中的Regression模块,并设置别名reg
from BaseML import Regression as reg
# 实例化模型/创建线性回归模型实例
model = reg(algorithm = 'LinearRegression')
# 指定数据集,data_train.csv是表格文件,包含用于训练的数据
model.load_tab_data('data/data_train.csv')
# 模型训练,利用算法从数据中寻找规律
model.train()
# 模型保存至指定路径
model.save('checkpoints/linear_regression.pkl')5.3模型验证 模型训练完成,但是该模型效果如何?R的平方值可以评价回归模型的准确度。因此,我们可以根据以下的代码进行模型验证。
#导入基础库
from BaseML import Regression as reg
# 实例化模型
model = reg(algorithm = 'LinearRegression')
# 载入已保存的模型
model.load('checkpoints/linear_regression.pkl')
# data_evaluation.csv是包含测试数据的文件,从中读出自变量X并
应用模型进行预测,然后用文件中的y计算误差
new_data = 'data/data_evaluation.csv'
# 模型评估/对回归任务来说,R平方值是评估指标之一,范围在0和1之间。预
测结果完全准确时R平方值为1,数值越接近1表示误差越小,当R平方值为0时,
意味着模型与实际数据之间没有相关性。
r2,result = model.valid(new_data, metrics='r2')5.4模型推理 模型验证后我们就可以应用模型啦。输入模拟引脚数值,测试输出的摄氏温度是否正确。
#导入基础库
from BaseML import Regression as reg
model = reg('LinearRegression') # 实例化模型
#载入训练好的模型
model.load('checkpoints/linear_regression.pkl')
# 输入新的待推理数据
new_data = [200]
#进行模型推理,得到预测值,并打印
result = model.inference(new_data)
print(result)
附件



 他的勋章
他的勋章








评论