 返回首页
返回首页
 回到顶部
回到顶部

【项目背景】
人工智能技术飞速发展的今天,AI智能体的应用已经渗透到我们生活的方方面面。从简单的自动化任务到复杂的决策支持,AI智能体正逐渐成为我们生活中不可或缺的一部分。最近,我了解到一个AI项目“斯坦福小镇”,它是一个创新的人工智能项目,旨在模拟一个由25个AI智能体组成的虚拟社区,每个智能体都被赋予了独特的身份和职责,如医生、教师、学生等,它们在这个虚拟环境中生活和工作,模拟现实世界的人类社会。这些智能体利用先进的自然语言处理和机器学习技术,能够进行复杂的决策、学习和社交互动,从而展示AI在模拟人类行为和社会结构方面的潜力。小镇不仅是一个技术实验平台,用于测试AI在不同情境下的行为和适应能力,也是一个教育工具,帮助人们了解AI的工作原理及其在解决现实世界问题中的应用。同时,它还引发了关于AI技术对社会、伦理和文化影响的深入探讨。尽管“斯坦福小镇”是一个虚构的概念,但它体现了人工智能领域中一些真实的研究和发展方向,为我们提供了一个探索AI未来可能性的窗口。
从“斯坦福小镇”得到灵感,我们提出了一个创新的项目——“云天之家”,这是一个虚拟的家庭,由2个AI智能体组成,每个智能体都有自己独特的身份和职责。这些智能体不仅有独立的日常工作,还能进行的“约会”交流互动,拥有“记忆”,模拟人类社会的日常生活。
【项目设计】
在这个项目中,我们特别为两个核心智能体设计了身份:外科男医生李明和高中数学老师王芳。他们不仅是“云天之家”的成员,还是一对恋人。这两个角色将接入讯飞星火大模型,这是一款先进的AI语言模型,能够提供自然语言理解和生成的能力,使得李明和王芳能够以更加真实和自然的方式进行交流。
项目的核心目标是探索AI智能体在模拟人类社交互动中的潜力。通过为李明和王芳设计一天的工作和社交活动,我们希望能够模拟出他们的日常生活和工作流程。每天,AI“管家”会为这两个角色安排8个不同的事件,这些事件可能包括工作、学习、休闲等各个方面。通过分析这些事件,我们可以更好地理解AI智能体在处理复杂社交情境时的能力。
在一天的工作结束后,李明和王芳会进行“约会”,这是他们社交互动的高潮。在约会中,他们会根据当天的事件选择一个话题进行交流。为了增加交流的自然性和随机性,我们设计了一个机制,通过产生一个10以内的随机数来决定谁先开口。如果随机数小于5,李明先发言;如果大于等于5,王芳先发言。
交流过程中,我们会监控对话内容,一旦检测到“再见”、“晚安”等结束语,对话将自动停止。此外,为了防止对话内容重复,我们规定在交流超过8轮后,将开始“新的一天”。在新的一天中,李明和王芳会继续他们的工作和社交活动,同时,他们的记忆库中会保存前一天的交流主题,作为第二天交流的参考内容。
【项目硬件】
本项目主板使用两个行空板,使用python的调用讯飞星火认知大模型spark库,接入大模型。并利用讯飞语音合成功能,将智能体生成的文本合成音频,再通过连接的蓝牙音箱输出语音。


【智能体设定】
1.角色设定
text=[{"role":"system","content":"你现在扮演高中数学教师王芳,你工作在河北省一个县城高中,教学能力强,为人和蔼,善解人意,深受学生的喜爱;接下来请用王芳的口吻和男友外科医李明对话。字数控制在50以内。"}]
text=[{"role":"system","content":"你现在扮演外科医生李明,你工作在河北省一个县医院,医术高明,为人谦和,善解人意;接下来请用李明的口吻和女友高中数学老师王芳对话。字数控制在50以内。"}]
因星火认知大模型中”Spark Max“API调用时可使用”system“,system用于设置对话背景(仅Max、Ultra版本支持)。
2.角色形象
通过讯飞”绘画大师“,为两个智能体设计形象照片。

3.AI”管家“——日常工作规划师
tishici="[\"与同事讨论今天一个心脏手术方案\",\"在休息时间和同事聊天,分享了小时候去河边玩的趣事\",\"在手术过程中遇到困难,同事王杰及时提供支持和指导\"]"
query = f"你是一位日常工作规划师,请给一名外科医生安排一天的工作,包括1.日常外科医生在医院的常规工作;2.与同事在工作时发生的事情及交流内容;3.与来就诊的患者之间的交流及发生的事情;4.也可记录在工作休息期间发生的有趣的事情;5.也可记录由你帮助生成一些有可能发生在外科医生身上的事情;以上内容总共帮安排8件事,输出形式如:{tishici},其中不要出现我举的例子"
query_text =[
{"role": "system", "content":query} , # 设置对话背景或者模型角色
{"role": "user", "content": "请按排今天的工作"} # 用户的问题
]
4.AI”管家“——话题选择师
query ="你是一位话题选择师,现在外科医生李明想和一位高中数学教师王芳聊天,两人是情侣关系,你认为外科医生李明会选择以下哪个话题,只选其中一个,把你选出的这个话题,按照李明口吻把这个话题转换成一句话。"
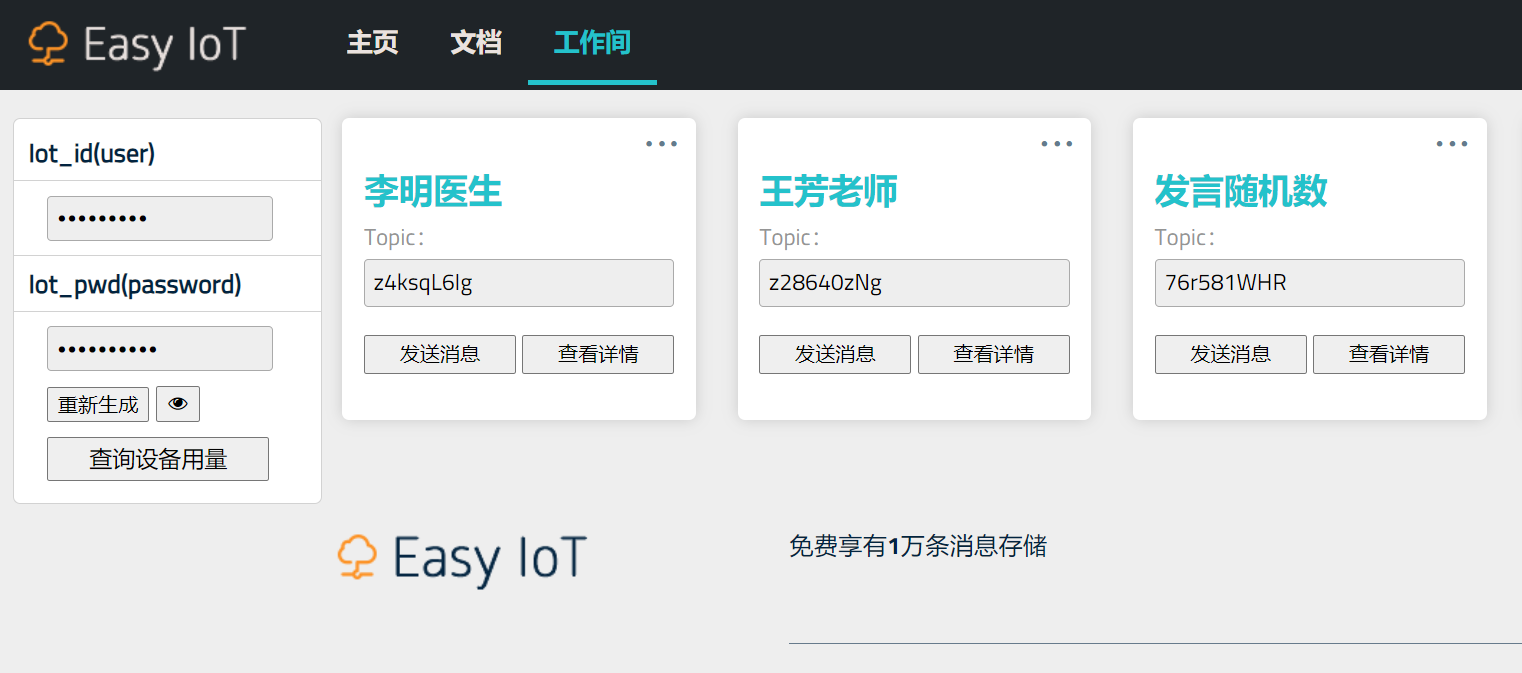
【物联网平台】
两个智能体交流的话语,通过物联网平台Easy IOT进行传递。互相订阅主题。
siot.init(client_id="513882381813616",server="iot.dfrobot.com.cn",port=1883,user="****",password="******")
siot.connect()
siot.loop()
siot.set_callback(on_message_callback)
siot.getsubscribe(topic="z28640zNg")
【智能体外科医生程序】
import sys
sys.path.append("/root/mindplus/.lib/thirdExtension/ac000108-spark-thirdex")
import sparkApi as sA
import time
from unihiker import Audio
from df_xfyun_speech import XfTts
import siot
import random
from unihiker import GUI
u_gui=GUI()
logo=u_gui.draw_image(image="logo_doctor.png",x=0,y=0)
# 事件回调函数
def on_message_callback(client, userdata, msg):
global teacher_query,bs
teacher_query=msg.payload.decode()
bs=1
siot.init(client_id="513882381813616",server="iot.dfrobot.com.cn",port=1883,user="******",password="********")
siot.connect()
siot.loop()
siot.set_callback(on_message_callback)
siot.getsubscribe(topic="z28640zNg")
# 角色定义
class Character:
def __init__(self, name, occupation, gender):
self.name = name
self.occupation = occupation
self.gender = gender
self.memories = []
def remember(self, event):
self.memories.append(event)
def get_memories(self):
return self.memories
# 初始化角色
doctor = Character("李明", "外科医生", "男")
# 初始化星火认知大模型参数
appid = "*******************"
api_secret = "***********************"
api_key = "**********************"
domain = "generalv3.5" # Max版本
#domain = "generalv3" # Pro版本
#domain = "general" # Lite版本
#domain = "max-32k"
#Spark_url ="wss://spark-api.xf-yun.com/chat/max-32k"
Spark_url = "wss://spark-api.xf-yun.com/v3.5/chat" # Max服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v3.1/chat" # Pro服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v1.1/chat" # Lite服务地址
options = {}
business_args = {"aue":"raw","vcn":"x4_pengfei","tte":"utf8","speed":50,"volume":50,"pitch":50,"bgs":0}
options["business_args"] = business_args
u_audio = Audio()
tts = XfTts(appid, api_key, api_secret, options)
teacher_query=""
bs=0
text=[{"role":"system","content":"你现在扮演外科医生李明,你工作在河北省一个县医院,医术高明,为人谦和,善解人意;接下来请用李明的口吻和女友高中数学老师王芳对话。字数控制在50以内。"}]
def getText(role,content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text
while True:
sA.state=False
sA.answer=""
tishici="[\"与同事讨论今天一个心脏手术方案\",\"在休息时间和同事聊天,分享了小时候去河边玩的趣事\",\"在手术过程中遇到困难,同事王杰及时提供支持和指导\"]"
query = f"你是一位日常工作规划师,请给一名外科医生安排一天的工作,包括1.日常外科医生在医院的常规工作;2.与同事在工作时发生的事情及交流内容;3.与来就诊的患者之间的交流及发生的事情;4.也可记录在工作休息期间发生的有趣的事情;5.也可记录由你帮助生成一些有可能发生在外科医生身上的事情;以上内容总共帮安排8件事,输出形式如:{tishici},其中不要出现我举的例子"
query_text =[
{"role": "system", "content":query} , # 设置对话背景或者模型角色
{"role": "user", "content": "请按排今天的工作"} # 用户的问题
]
sA.main(appid, api_key,api_secret, Spark_url, domain, query_text,"maker")#"按排日程工作"
print()
print(sA.answer)
print("******************")
if sA.answer.find("[")!=-1 and sA.answer.find("]")!=-1:
temp=sA.answer[sA.answer.find("["):sA.answer.find("]")]
elif sA.answer.find(":")!=-1:
temp=sA.answer[sA.answer.find(":"):]
else:
temp=sA.answer
query ="你是一位话题选择师,现在外科医生李明想和一位高中数学教师王芳聊天,两人是情侣关系,你认为外科医生李明会选择以下哪个话题,只选其中一个,把你选出的这个话题,按照李明口吻把这个话题转换成一句话。"
temp=temp+","+str(doctor.memories)
query_text =[
{"role": "system", "content":query} , # 设置对话背景或者模型角色
{"role": "user", "content": "所有话题为:"+temp} # 用户的问题
]
print(query_text)
sA.state=False
sA.answer=""
sA.main(appid,api_key,api_secret, Spark_url, domain, query_text,"Maker")#"安排聊天开启内容"
while not sA.state:
print(sA.state)
print("-----------------")
print(sA.answer)
temp=""
query=""
if sA.answer.find("转换")!=-1:
temp=sA.answer[sA.answer.find("转换"):]
if temp.find(":")!=-1:
query=temp[temp.find(":")+1:]
else:
query=temp
elif sA.answer.find(":")!=-1:
query=sA.answer[sA.answer.find(":")+1:]
elif sA.answer.find(":")!=-1:
query=sA.answer[sA.answer.find(":")+1:]
else:
query=sA.answer
print("++++++++++++++++++")
print(query)
print("###################")
r=random.randint(1, 10)
siot.publish(topic="76r581WHR", data=str(r))
if r<=5:
tts.synthesis(query, "speech_li.wav")
u_audio.play("speech_li.wav")
siot.publish(topic="z4ksqL6Ig", data=query)
doctor.remember(query)
if len(doctor.memories)>8:
doctor.memories.pop(0)
k=0
while k<7:
if bs==1:
if k==0:
doctor.remember(teacher_query)
if len(doctor.memories)>8:
doctor.memories.pop(0)
k=k+1
bs=0
sA.state=False
sA.answer=""
if teacher_query.find("晚安")!=-1:
tts.synthesis("好的,晚安", "speech_li.wav")
u_audio.play("speech_li.wav")
break
elif teacher_query.find("再见")!=-1:
tts.synthesis("好的,再见", "speech_li.wav")
u_audio.play("speech_li.wav")
break
question = checklen(getText("user",teacher_query))
sA.main(appid, api_key,api_secret, Spark_url, domain,question,"doctor")#答
if sA.state:
doctor_speak = sA.answer
print(f"{doctor_speak}")
if doctor_speak.find(":")!=-1:
tts.synthesis(doctor_speak[doctor_speak.find(":"):], "speech_li.wav")
u_audio.play("speech_li.wav")
else:
tts.synthesis(doctor_speak, "speech_li.wav")
u_audio.play("speech_li.wav")
getText("assistant",sA.answer)
#print(text)
siot.publish(topic="z4ksqL6Ig", data=doctor_speak)
【智能体——高中数学老师程序】
import sys
sys.path.append("/root/mindplus/.lib/thirdExtension/ac000108-spark-thirdex")
import sparkWangfang as sA
import time
from unihiker import Audio
from df_xfyun_speech import XfTts
import siot
from unihiker import GUI
u_gui=GUI()
logo=u_gui.draw_image(image="logo_teacher.png",x=0,y=0)
# 事件回调函数
def on_message_callback(client, userdata, msg):
global doctor_query,bs,fayan
if msg.topic=="76r581WHR":
fayan=int(msg.payload.decode())
else:
doctor_query=msg.payload.decode()
bs=1
siot.init(client_id="513882381813617",server="iot.dfrobot.com.cn",port=1883,user="********",password="********")
siot.connect()
siot.loop()
siot.set_callback(on_message_callback)
siot.getsubscribe(topic="z4ksqL6Ig")
siot.getsubscribe(topic="76r581WHR")
# 角色定义
class Character:
def __init__(self, name, occupation, gender):
self.name = name
self.occupation = occupation
self.gender = gender
self.memories = []
def remember(self, event):
self.memories.append(event)
def get_memories(self):
return self.memories
# 初始化角色
teacher = Character("王芳", "高中数学教师", "女")
# 初始化星火认知大模型参数
appid = "********"
api_secret = "***********************************"
api_key = "*****************************************"
domain = "generalv3.5" # Max版本
#domain = "generalv3" # Pro版本
#domain = "general" # Lite版本
Spark_url = "wss://spark-api.xf-yun.com/v3.5/chat" # Max服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v3.1/chat" # Pro服务地址
#Spark_url = "wss://spark-api.xf-yun.com/v1.1/chat" # Lite服务地址
options = {}
business_args = {"aue":"raw","vcn":"xiaoyan","tte":"utf8","speed":50,"volume":50,"pitch":50,"bgs":0}
options["business_args"] = business_args
u_audio = Audio()
tts = XfTts(appid, api_key, api_secret, options)
doctor_query=""
bs=0
fayan=-1
text=[{"role":"system","content":"你现在扮演高中数学教师王芳,你工作在河北省一个县城高中,教学能力强,为人和蔼,善解人意,深受学生的喜爱;接下来请用王芳的口吻和男友外科医李明对话。字数控制在50以内。"}]
def getText(role,content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text
while True:
sA.state=False
sA.answer=""
tishici="[\"参加学校的教研活动,与其他数学老师一起探讨新的教学方法和课程改革\",\"设计一个数学游戏,让学生在玩乐中学习\",\"阅读最新的教育研究文章,以提升自己的教学技能和知识水平\"]"
query = f"你是一位日常工作规划师,请给一名高中数学老师安排一天的工作,包括1.日常高中数学老师在学校的常规工作;2.与同事在工作时发生的事情及交流内容;3.与所教学生之间的交流及发生的事情;4.也可记录在工作休息期间发生的有趣的事情;5.也可记录由你帮助生成一些有可能发生在高中数学老师身上的事情;以上内容总共帮安排8件事,输出形式如:{tishici},其中不要出现我举的例子"
query_text =[
{"role": "system", "content":query} , # 设置对话背景或者模型角色
{"role": "user", "content": "请按排今天的工作"} # 用户的问题
]
sA.main(appid, api_key,api_secret, Spark_url, domain, query_text,"Maker")#"按排日程工作"
print()
print(sA.answer)
print("******************")
if sA.answer.find("[")!=-1 and sA.answer.find("]")!=-1:
temp=sA.answer[sA.answer.find("["):sA.answer.find("]")]
elif sA.answer.find(":")!=-1:
temp=sA.answer[sA.answer.find(":"):]
else:
temp=sA.answer
query ="你是一位话题选择师,现在高中数学教师王芳想和一位外科医生李明聊天,两人是情侣关系,你认为王芳会选择以下哪个话题,只选其中一个,把你选出的这个话题,按照王芳口吻把这个话题转换成一句话。"
temp=temp+","+str(teacher.memories)
query_text =[
{"role": "system", "content":query} , # 设置对话背景或者模型角色
{"role": "user", "content": "所有话题为:"+temp} # 用户的问题
]
print(query_text)
sA.state=False
sA.answer=""
sA.main(appid,api_key,api_secret, Spark_url, domain, query_text,"Maker")#"安排聊天开启内容"
while not sA.state:
print(sA.state)
print("-----------------")
print(sA.answer)
temp=""
query=""
if sA.answer.find("转换")!=-1:
temp=sA.answer[sA.answer.find("转换"):]
if temp.find(":")!=-1:
query=temp[temp.find(":")+1:]
else:
query=temp
elif sA.answer.find(":")!=-1:
query=sA.answer[sA.answer.find(":")+1:]
elif sA.answer.find(":")!=-1:
query=sA.answer[sA.answer.find(":")+1:]
else:
query=sA.answer
print("++++++++++++++++++")
print(query)
print("###################")
while fayan==-1:
pass
if fayan>5:
fayan=-1
tts.synthesis(query, "speech.wav")
u_audio.play("speech.wav")
siot.publish(topic="z28640zNg", data=query)
teacher.remember(query)
if len(teacher.memories)>8:
teacher.memories.pop(0)
k=0
while k<7:
if bs==1:
if k==0:
teacher.remember(doctor_query)
if len(teacher.memories)>8:
teacher.memories.pop(0)
k=k+1
bs=0
sA.state=False
sA.answer=""
if doctor_query.find("晚安")!=-1 :
tts.synthesis("好的,晚安", "speech.wav")
u_audio.play("speech.wav")
break
elif doctor_query.find("再见")!=-1 :
tts.synthesis("好的,再见", "speech.wav")
u_audio.play("speech.wav")
break
question = checklen(getText("user",doctor_query))
sA.main(appid, api_key,api_secret, Spark_url, domain,question,"teacher")#答
if sA.state:
teacher_speak = sA.answer
print(f"{teacher_speak}")
if teacher_speak.find(":")!=-1:
tts.synthesis(teacher_speak[teacher_speak.find(":"):], "speech.wav")
u_audio.play("speech.wav")
else:
tts.synthesis(teacher_speak, "speech.wav")
u_audio.play("speech.wav")
getText("assistant",sA.answer)
#print(text)
siot.publish(topic="z28640zNg", data=teacher_speak)
【演示视频】
通过这个项目,我们希望能够探索AI智能体在模拟人类情感和社交互动方面的潜力,同时也为AI技术在社交领域的应用提供新的视角和思路。这个项目不仅是技术上的挑战,也是对AI智能体社会角色和行为模式的一次深入研究。
【备注补充】
Mind+ Python模式,扩展中的”讯飞语音合成“,有一处错误,希望更正。在”df_xfyun_speech“中的”__init__.py“文件中,有一处设置语音角色的语句:self.business_args = options.get('business_args ', default_business_args ),”business_args“后多了一个空格,使得无法设置语音合成的角色。


 他的勋章
他的勋章

评论