 返回首页
返回首页
 回到顶部
回到顶部

一、实践目标
本项目在行空板上外接USB摄像头,通过摄像头来识别物体,找到画面中的人体并显示其姿态。
二、知识目标
1、学习使用MediaPipe中的pose模块和holistic模块进行人体姿态检测的方法。
三、实践准备
硬件清单:

软件使用:Mind+编程软件x1
四、实践过程
1、硬件搭建
1、将摄像头接入行空板的USB接口。
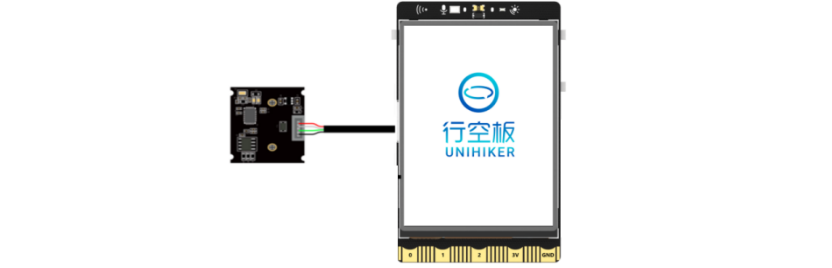
2、通过USB连接线将行空板连接到计算机。

2、软件编写
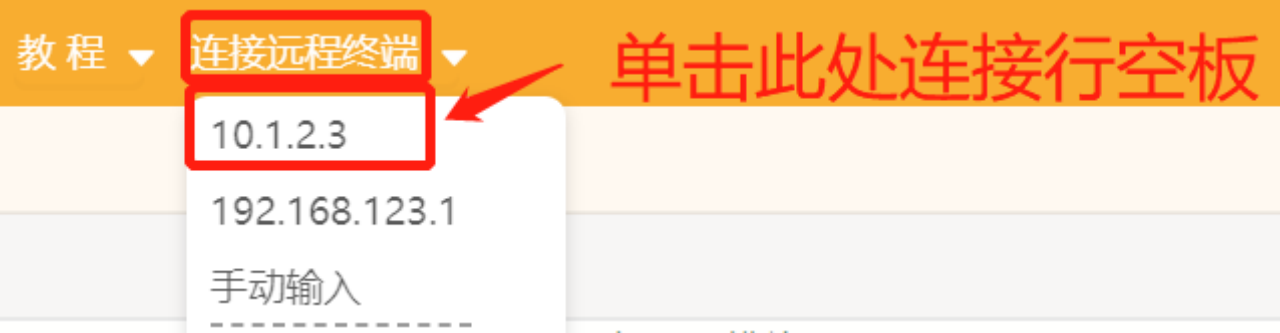
第一步:打开Mind+,远程连接行空板
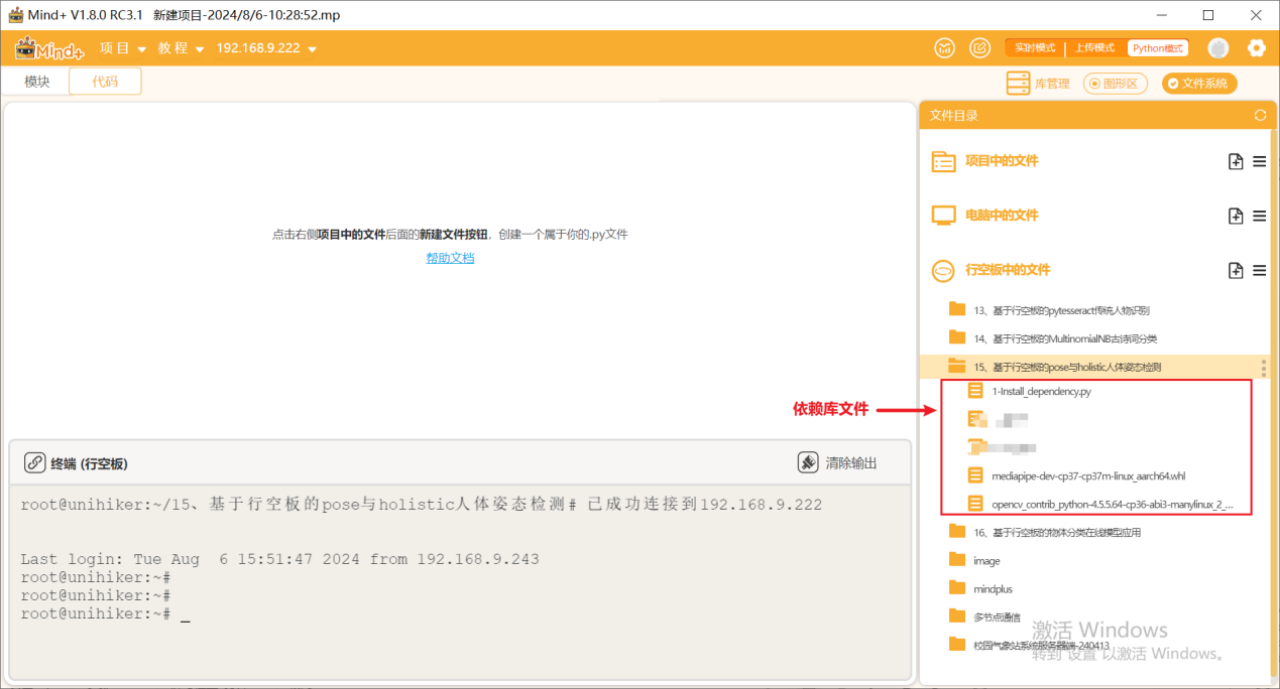
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的mediapipe pose与holistic人体姿态检测”的文件夹,导入本节课的依赖文件。
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main1.py”。
示例程序:
import cv2
import mediapipe as mp
# 初始化 MediaPipe 绘图和姿势识别模块
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_pose = mp.solutions.pose
# 打开默认摄像头(设备编号为 0)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) # 设置摄像头宽度
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240) # 设置摄像头高度
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置摄像头缓冲区大小
# 创建一个名为 'MediaPipe Pose' 的全屏窗口
cv2.namedWindow('MediaPipe Pose', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('MediaPipe Pose', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
# 使用 MediaPipe Pose 模块进行姿势识别,设置检测和跟踪的置信度
with mp_pose.Pose(
min_detection_confidence=0.5, # 设置最小检测置信度
model_complexity=0, # 设置模型复杂度,0 表示较低复杂度
min_tracking_confidence=0.5 # 设置最小跟踪置信度
) as pose:
while cap.isOpened(): # 检查摄像头是否已打开
success, image = cap.read() # 读取一帧图像
if not success: # 如果读取失败
print("Ignoring empty camera frame.")
continue # 忽略空帧并继续循环
# 为了提高性能,可以将图像标记为不可写,以便通过引用传递
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 将图像从 BGR 转换为 RGB
results = pose.process(image) # 使用 Pose 模块处理图像
# 在图像上绘制姿势注释
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 将图像从 RGB 转换回 BGR
mp_drawing.draw_landmarks(
image,
results.pose_landmarks, # 获取姿势地标
mp_pose.POSE_CONNECTIONS, # 获取姿势连接
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style() # 使用默认绘图样式
)
# 将图像顺时针旋转 90 度
image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# 将图像水平翻转,以获得自拍视图显示
cv2.imshow('MediaPipe Pose', cv2.flip(image, 1))
# 如果按下 Esc 键(ASCII 码为 27),则退出循环
if cv2.waitKey(5) & 0xFF == 27:
break
# 释放摄像头并关闭所有 OpenCV 窗口
cap.release()
cv2.destroyAllWindows()第四步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main2.py”。
示例程序:
import cv2
import mediapipe as mp
# 初始化 MediaPipe 绘图和整体模型模块
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_holistic = mp.solutions.holistic
# 打开默认摄像头(设备编号为 0)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) # 设置摄像头宽度
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240) # 设置摄像头高度
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置摄像头缓冲区大小
# 创建一个名为 'MediaPipe Holistic' 的全屏窗口
cv2.namedWindow('MediaPipe Holistic', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('MediaPipe Holistic', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
# 使用 MediaPipe Holistic 模块进行整体识别,设置检测和跟踪的置信度
with mp_holistic.Holistic(
min_detection_confidence=0.5, # 设置最小检测置信度
model_complexity=0, # 设置模型复杂度,0 表示较低复杂度
min_tracking_confidence=0.5 # 设置最小跟踪置信度
) as holistic:
while cap.isOpened(): # 检查摄像头是否已打开
success, image = cap.read() # 读取一帧图像
if not success: # 如果读取失败
print("Ignoring empty camera frame.")
continue # 忽略空帧并继续循环
# 为了提高性能,可以将图像标记为不可写,以便通过引用传递
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 将图像从 BGR 转换为 RGB
results = holistic.process(image) # 使用 Holistic 模块处理图像
# 在图像上绘制地标注释
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 将图像从 RGB 转换回 BGR
# 绘制面部地标
mp_drawing.draw_landmarks(
image,
results.face_landmarks, # 获取面部地标
mp_holistic.FACEMESH_CONTOURS, # 获取面部网格轮廓
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_contours_style() # 使用默认面部网格轮廓样式
)
# 绘制姿势地标
mp_drawing.draw_landmarks(
image,
results.pose_landmarks, # 获取姿势地标
mp_holistic.POSE_CONNECTIONS, # 获取姿势连接
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style() # 使用默认姿势地标样式
)
# 将图像顺时针旋转 90 度
image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# 将图像水平翻转,以获得自拍视图显示
cv2.imshow('MediaPipe Holistic', cv2.flip(image, 1))
# 如果按下 Esc 键(ASCII 码为 27),则退出循环
if cv2.waitKey(5) & 0xFF == 27:
break
# 释放摄像头并关闭所有 OpenCV 窗口
cap.release()
cv2.destroyAllWindows()3、运行调试
第一步:安装依赖库
运行1-Install_dependency.py程序文件,安装各个依赖库。
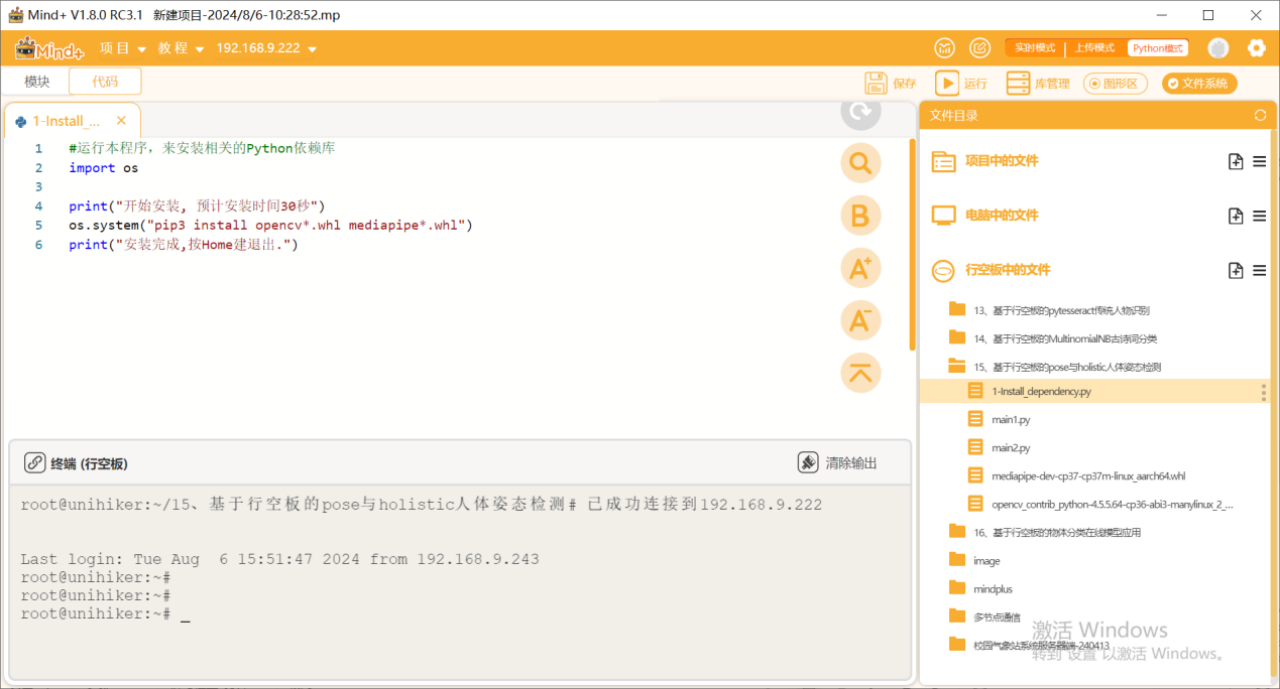
第二步:运行主程序1
运行“main1.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准人物,可以看到该人体的姿态被检测了出来。

第三步:运行主程序2
运行“main2.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准一个人物,可以看到该人体的面部、手部、姿态都被检测了出来。

4、程序解析
主程序1解析:
在上述的“main1.py”文件中,我们主要通过opencv库来调用摄像头,实时地从摄像头中读取图像,然后使用mediapipe库的pose模块进行姿势识别和绘制。识别到的姿势信息会在图像上进行标注,并在窗口中显示。整体流程如下,
① 初始化:导入所需的库并初始化 MediaPipe 绘图和姿势识别模块。打开摄像头并设置其参数,创建全屏显示窗口。
② 定义函数:定义一个用于在图像上绘制中文文字的函数(在本程序中未使用,但保留了函数定义)。
③ 主循环:程序进入一个无限循环,在每次循环中,程序会执行以下操作:
· 从摄像头读取一帧图像,如果读取失败则跳过当前帧。
· 将图像标记为不可写,以提高性能,然后将图像颜色空间从 BGR 转换为 RGB。
· 使用 MediaPipe Pose 模块处理图像以获取姿势信息。
· 将图像标记为可写,并将图像颜色空间转换回 BGR。
· 在图像上绘制姿势注释信息。
· 将图像顺时针旋转 90 度,并水平翻转以获得自拍视图显示。
· 在窗口中显示处理后的图像。如果按下 Esc 键,则退出循环。
④ 结束:当主循环结束时,释放摄像头设备并关闭所有 OpenCV 窗口。
主程序2解析:
在上述的“main2.py”文件中,我们主要通过opencv库来调用摄像头,实时地从摄像头中读取图像,然后使用mediapipe库的holistic模块进行面部和姿势识别和绘制。识别到的面部和姿势信息会在图像上进行标注,并在窗口中显示。整体流程如下,
① 初始化:导入所需的库并初始化 MediaPipe 绘图和整体模型模块。打开摄像头并设置其参数,创建全屏显示窗口。
② 主循环:程序进入一个无限循环,在每次循环中,程序会执行以下操作:
· 从摄像头读取一帧图像,如果读取失败则跳过当前帧。
· 将图像标记为不可写,以提高性能,然后将图像颜色空间从 BGR 转换为 RGB。
· 使用 MediaPipe Holistic 模块处理图像以获取面部和姿势信息。
· 将图像标记为可写,并将图像颜色空间转换回 BGR。
· 在图像上绘制面部和姿势的地标注释信息。
· 将图像顺时针旋转 90 度,并水平翻转以获得自拍视图显示。
· 在窗口中显示处理后的图像。如果按下 Esc 键,则退出循环。
③ 结束:当主循环结束时,释放摄像头设备并关闭所有 OpenCV 窗口。
相同点:
① 导入库:
· 两个程序都导入了 OpenCV 和 MediaPipe 库,用于图像处理和姿势检测。
② 摄像头设置:
· 两个程序都使用 OpenCV 打开摄像头,并设置摄像头的分辨率和缓冲区大小。
③ 全屏显示:
· 两个程序都创建了一个全屏窗口用于显示处理后的图像。
④ 主循环:
· 两个程序都包含一个主循环,从摄像头读取帧,处理图像,并显示在窗口中。
· 在读取失败时,两个程序都忽略当前帧并继续循环。
· 都检测按键事件,如果按下 Esc 键退出循环。
⑤ 图像处理:
· 两个程序都将图像从 BGR 转换为 RGB,再转换回 BGR,以便与 MediaPipe 的处理兼容。
· 两个程序都使用 MediaPipe 模块处理图像,并绘制相应的地标注释。
⑥ 翻转图像:
· 两个程序都在显示图像前,将图像进行顺时针旋转 90 度,并进行水平翻转以获得自拍视图。
不同点:
① 使用的 MediaPipe 模块:
· 第一个程序使用 mp.solutions.pose 模块进行姿势识别。
· 第二个程序使用 mp.solutions.holistic 模块进行整体识别,包括面部、姿势和手部。
② 绘制地标:
· 第一个程序只绘制了姿势地标。
· 第二个程序绘制了面部和姿势地标,增加了面部网格轮廓的绘制。
③ 变量和模块名称:
· 第一个程序的 MediaPipe 模块变量名为 pose,第二个程序为 holistic。
④ 模型复杂度:
· 两个程序都设置了模型复杂度为 0,但由于使用的 MediaPipe 模块不同,具体的复杂度设置会有所不同。
五、知识园地
1. 了解mediapipe库的pose 和holistic 模块
MediaPipe 库简介
MediaPipe 是由 Google 开发的一个跨平台、多模态的机器学习框架,主要用于实时处理和分析视频流。它提供了一系列高性能的机器学习模型和工具,广泛应用于计算机视觉任务中,如手势识别、人脸检测、姿态估计等。
MediaPipe Pose 模块
概述
MediaPipe Pose 是一个高性能的人体姿态估计解决方案,能够实时检测和追踪人体的骨骼关键点。它使用卷积神经网络(CNN)和深度学习技术来识别人类的姿态,并绘制出人体的骨骼结构。
功能
· 关键点检测:能够检测人体的 33 个关键点,包括头部、肩膀、肘部、手腕、髋部、膝盖和脚踝等。
· 实时性:高效的算法使得它能够在实时视频流中进行姿态估计。
· 平台支持:支持多种平台,包括桌面和移动设备。
MediaPipe Holistic 模块
概述
MediaPipe Holistic 是一个综合性的解决方案,能够同时检测和追踪面部、手部和人体的姿态。它结合了 MediaPipe 的 Face Mesh、Hands 和 Pose 模块,提供一个全面的多模态识别系统。
功能
· 面部网格:检测和追踪面部的 468 个关键点,用于细致的面部特征分析。
· 手部关键点:检测每只手的 21 个关键点,用于手势识别和跟踪。
· 人体姿态:检测人体的 33 个关键点,用于姿态估计。
· 多模态结合:同时处理和结合面部、手部和姿态的数据,提供更丰富的信息。
素材链接: https://pan.baidu.com/s/13llgZq2RvV1pKnxupewLfw?pwd=s4a9
提取码: s4a9



 他的勋章
他的勋章

地下铁2024.10.06
运行main1.py的时候,遇到下面一个错误: TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower). More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates 有可能是什么原因呢?谢谢。