 返回首页
返回首页
 回到顶部
回到顶部

一、实践目标
本项目在行空板上外接USB摄像头,通过摄像头并结合YOLO模型来识别车牌号码。
二、知识目标
1、学习使用opencv库读取视频帧、保存图片的方法。
2、简单了解车牌识别的原理。
3、简单YOLO模型。
三、实践准备
硬件清单

软件使用
Mind+编程软件x1
四、实践过程
1、硬件搭建
将摄像头接入行空板的USB接口。
2、软件编写
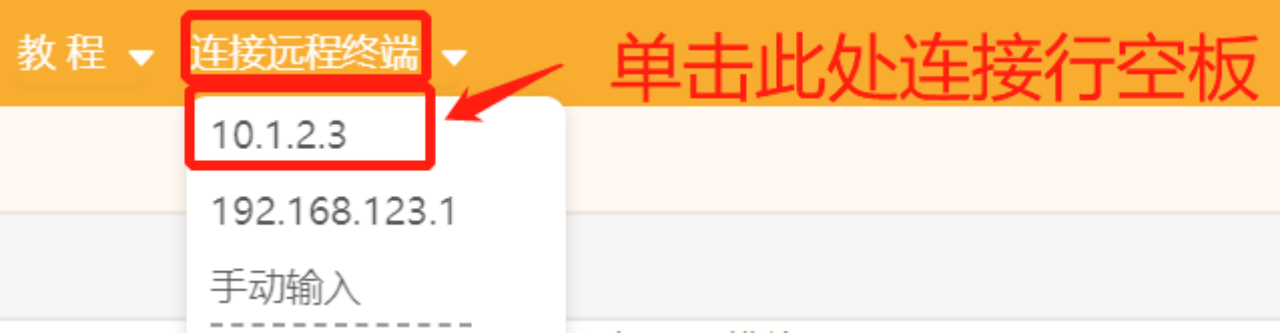
第一步:创建与保存项目文件打开Mind+,远程连接行空板
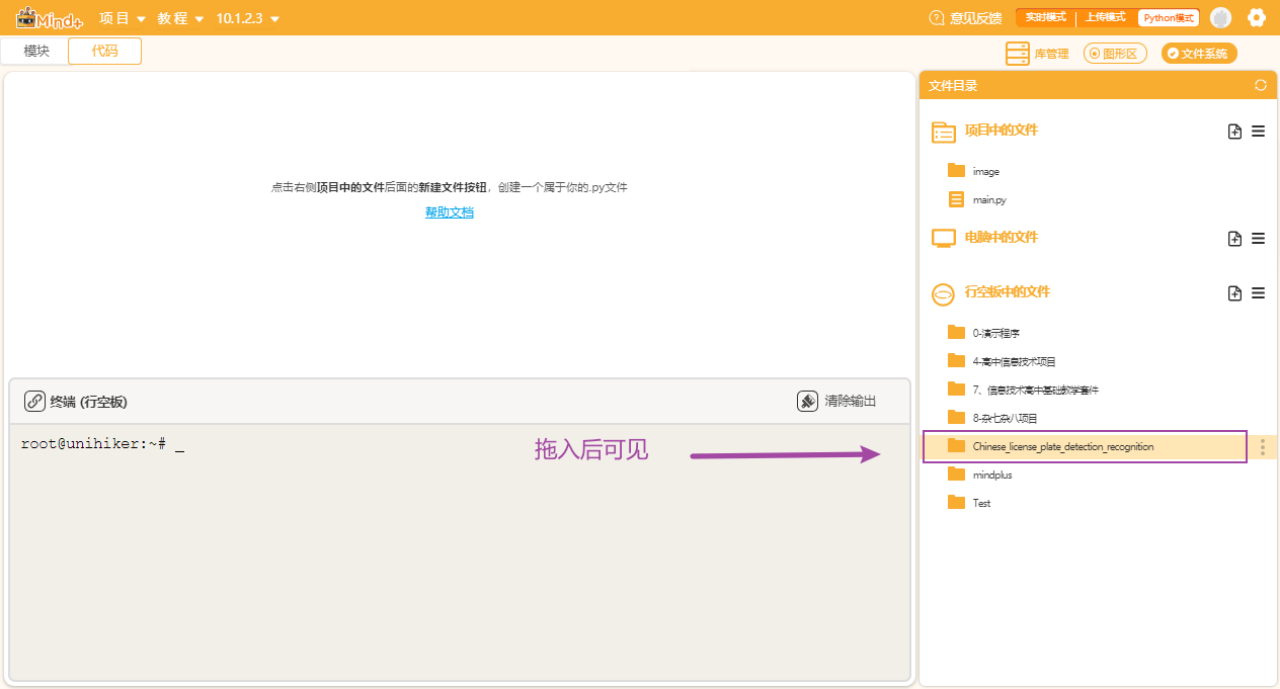
第二步:导入车牌识别文件夹
将Chinese_license_plate_detection_recognition文件夹拖入到“行空板中的文件”中,素材文件夹链接见附录1。
Tip1:不要修改该文件夹路径,就放在这里(root下)。
Tip2:该文件夹存储的是车牌识别模型等文件,其中“0-Install_dependency.py”程序文件用于安装车牌识别所需的依赖库,“Recognition_plate.py”是编写好的用于车牌识别的程序模块。
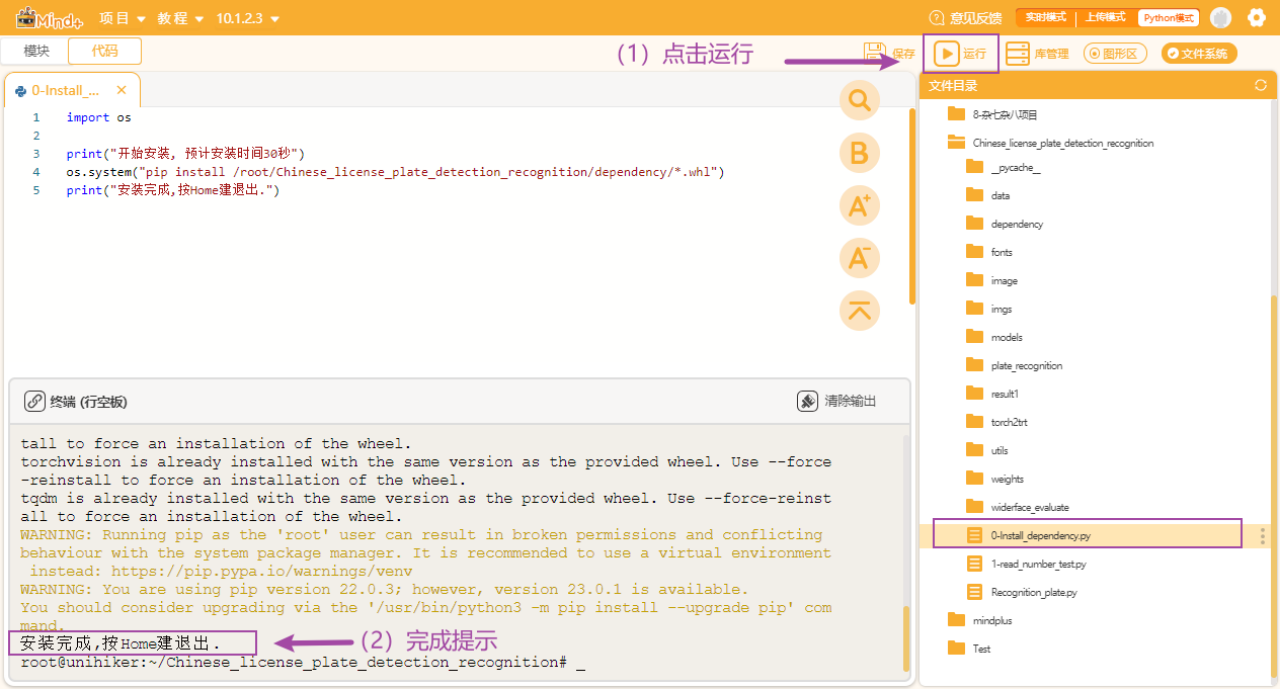
第三步:安装依赖
双击打开“Chinese_license_plate_detection_recognition”中的“0-Install_dependency.py”程序文件,点击右上方的运行按钮,等待自动安装完成。
第四步:编写程序
在上述“0-Install_dependency.py”同级目录下新建一个项目文件,并命名为“1-read_number_test.py”。
示例程序:
import sys
sys.path.append("/root/Chinese_license_plate_detection_recognition")
import Recognition_plate # 导入车牌识别模块
import cv2
import numpy as np
cap = cv2.VideoCapture(0) # 打开摄像头
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 240) # 设置摄像头的宽度
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320) # 设置摄像头的高度
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置摄像头的缓冲区大小
cv2.namedWindow('cvwindow', cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty('cvwindow', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置窗口为全屏
while not cap.isOpened(): # 如果摄像头没有打开,就一直等待
continue
while True: # 主循环
cv2.waitKey(5) # 等待5毫秒
cvimg_success, img_src = cap.read() # 读取摄像头的画面
cvimg_h, cvimg_w, cvimg_c = img_src.shape # 获取画面的宽高和通道数
cvimg_w1 = cvimg_h * 240 // 320
cvimg_x1 = (cvimg_w - cvimg_w1) // 2
img_src = img_src[:, cvimg_x1:cvimg_x1 + cvimg_w1] # 调整画面的大小
img_src = cv2.resize(img_src, (240, 320)) # 将画面缩放到240x320
cvimg_src = img_src.copy() # 复制画面
cv2.imshow('cvwindow', cvimg_src) # 显示画面
if cv2.waitKey(1) & 0xFF == ord('a'):
cv2.imwrite("/root/Chinese_license_plate_detection_recognition/imgs/3.png", cvimg_src) # 保存当前的画面
number = Recognition_plate.recognize() ###识别车牌号码###recognize
print(number) # 进行车牌识别并打印结果五、知识园地
1、车牌识别原理
车牌号识别原理是通过摄像头对车辆进行拍照,然后通过车辆图像进行车牌号识别,识别过程中涉及的步骤有:车辆检测—图像采集—图片预处理—车牌定位—字符分割—字符识别—结果输出。
(1)车辆检测
在拍照之前,要检测车辆是否进入了摄像头的最佳焦距位置。所以,车辆检测就是车牌识别的第一步。摄像头是被动采集数据的,所以它不知道什么时候拍照。其实,有很多种方法来触发摄像头拍照,比如生活中最常用的是红外法,当车辆进入拍摄区域,红外射线会被车辆遮挡,这个时候摄像头和系统联动,就会拍下车辆的照片。
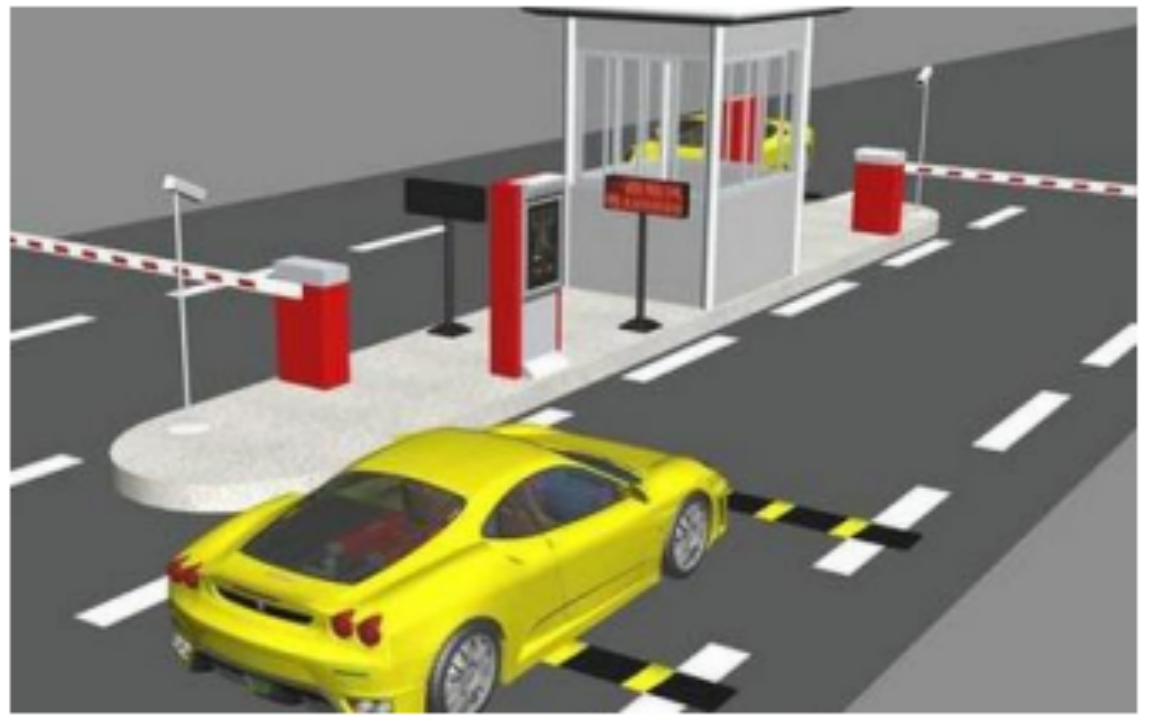
(2)图像采集
对进入有效焦距范围的车辆拍摄照片,这一步很容易理解。车牌识别系统的软件端会根据车辆进入的视频来截取图片,或者直接拍摄图片。获取照片后,提供给识别系统备用。

(3)图片预处理
我们都知道车有很多种颜色,颜色一多,计算机就容易眼花缭乱。因此,需要将图片处理为只有黑色和白色,这种图片处理方式就是图片二值化,也称为“熊猫化”!处理过程中,会对图片的每一个像素点进行 RGB 值判断,根据设定的值(例如 160),将大于 160 的像素点处理成白色,将小于 160 的像素点处理成黑色。

(4)车牌定位
图片处理完成后,怎样才能对车牌进行定位呢?车牌是规则的长方形,那就需要找到图片中的长方形,然后计算机扫描处理后的图片,由左到右,由上到下,把颜色从黑到白或者由白到黑的像素全部记录下来。然后根据这些像素来计算哪个区域是长方形,并且找到符合车牌的比例的位置进行定位。如何判断是不是车牌号呢?很简单,对该区域再来一波扫描。因为是处理后的图片,如果有车牌号,那就一定会有黑白变化,尤其是纵向方向。这样就缩小了范围,能够很快找到车牌。

(5)字符分割
成功找到车牌后,根据扫描到的车牌对每一个字符宽度做纵向分割。因为车牌图像已经处理成了黑白两种颜色,所以车牌字符要么是白色字黑底,要么黑色字白底,很容易得到字符的高度和宽度。分割就是以此为依据,把车牌的所有字符都分割成单个字符。

(6)字符识别
将分割好的字符,依次从车牌库模板中进行比对,然后从车牌模板库中找出相似度最高的图片。目的就是获得车牌省别等的汉字,26 个英文大写字母,和 0-9 的 10 个数字。

(7)结果输出
比对过程中,会将相似度最高的图片模板依次存放到一个数组中,最后通过遍历的方法,获得识别成功的车牌号。
2、YOLO简介
YOLO(You Only Look Once)是一种流行的对象检测算法。与传统的对象检测方法(例如R-CNN和它的变体)不同,YOLO在单个网络中将边界框预测和类别概率预测统一起来,从而实现了端到端的对象检测,这使得它在保持较高准确率的同时具有很高的运行速度。
YOLO的工作原理是将输入图像划分为 SxS 的网格,每个网格负责预测一个对象。每个网格会预测 B 个边界框以及这些边界框的置信度,以及 C 个类别的概率。边界框的置信度是指预测的边界框内含有对象的置信度和这个边界框准确预测对象位置的置信度的乘积。如果网格中没有对象,那么该网格预测的边界框的置信度应该为零。否则,置信度应该等于预测的边界框和实际边界框的交并比(IoU)。
YOLO的主要优点是速度快和准确率高。因为它在单个网络中完成了所有的预测,所以它可以实时地进行对象检测。同时,由于它在全局上下文中直接预测边界框,因此它能够很好地处理各种尺度和形状的对象。然而,YOLO也有一些限制,例如它在处理小对象和预测大量重叠对象时可能会表现得不太好。
目前,YOLO已经有多个版本,包括YOLOv1、YOLOv2(YOLO9000)、YOLOv3、YOLOv4和最新的YOLOv5,每个新版本都在速度和精度上做出了改进。
3、运行调试
第一步:运行主程序
打开并运行“1-read_number_test.py”,能看到屏幕显示摄像头的实时画面,此时,将车牌放在画面中,按下板载按键a拍摄待识别的车牌照片,几秒后在终端可看到显示了识别到的车牌结果。
同时,也可以在同级路径的“imgs”文件夹下看到拍摄的车牌图片“3.png”。
4、程序解析
在上述的“1-read_number_test.py”文件中,我们主要通过OpenCV库来读取摄像头的图像画面,然后将图像尺寸大小处理成240x320的分辨率后在行空板屏幕上显示,之后设置识别条件,按下按键a,调用Recognition_plate模块的recognize()函数来识别。
打开“Recognition_plate.py”文件,我们可以看到这段代码主要实现了通过Yolo模型来进行车牌的检测和识别,具体的关键步骤如下:
1.加载模型:使用load_model函数加载预训练的车牌检测和识别模型。这里的Yolo模型保存在models文件夹中。
2.图像预处理:在detect_Recognition_plate函数中,首先对输入的图像进行预处理,包括缩放、裁剪等操作,然后将预处理后的图像转换为模型可以接受的格式。
3.车牌检测:将预处理后的图像输入到车牌检测模型中,得到车牌的位置和关键点坐标。
4.获取车牌图像:利用车牌的关键点坐标,使用four_point_transform函数进行透视变换,得到车牌的图像。
5.车牌识别:将车牌图像输入到车牌识别模型中,得到车牌号码。如果设置了颜色识别选项,还可以得到车牌的颜色。
6.结果处理:将检测和识别的结果进行整理,包括车牌的位置、车牌号码、车牌颜色等信息。
7.结果展示:使用draw_result函数将检测和识别的结果绘制到原始图像上,包括绘制车牌的位置和车牌号码。



 他的勋章
他的勋章

评论