 返回首页
返回首页
 回到顶部
回到顶部
早上百度搜“神经网络KPU”,查到与非网的一篇文章《一文读懂APU/BPU/CPU/DPU/EPU/FPU/GPU等处理器》,介绍各种处理器非常详细,关于“KPU”的内容如下:
KPU
Knowledge Processing Unit。 嘉楠耘智(canaan)号称 2017 年将发布自己的 AI 芯片 KPU。嘉楠耘智要在 KPU 单一芯片中集成人工神经网络和高性能处理器,主要提供异构、实时、离线的人工智能应用服务。这又是一家向 AI 领域扩张的不差钱的矿机公司。作为一家做矿机芯片(自称是区块链专用芯片)和矿机的公司,嘉楠耘智累计获得近 3 亿元融资,估值近 33 亿人民币。据说嘉楠耘智近期将启动股改并推进 IPO。
另:Knowledge Processing Unit 这个词并不是嘉楠耘智第一个提出来的,早在 10 年前就已经有论文和书籍讲到这个词汇了。只是,现在嘉楠耘智将 KPU 申请了注册商标。
(原文链接:https://www.eefocus.com/mcu-dsp/391017/r0)
百度翻译:Knowledge Processing Unit,大致意思是“知识处理单元”。
搜索“嘉楠科技”,查到介绍嘉楠的文章《嘉楠CEO张楠赓:不做替代品,只做开拓者》,继续了解相关情况:
张楠赓并不像是一个典型的80后,一张年轻的面孔和头顶间杂的白发反映了创业者常有的疲惫。谈及自己的创业初衷,他坦言,“我喜欢折腾新鲜事。相比追随别人做已经很成熟的事情,我个人更愿意做出一些新的探索。”张楠赓十分笃定。
北航计算机本科毕业后,张楠赓有过一段在事业单位做“螺丝钉”的时光,每每回想起这段经历,张楠赓会觉得唏嘘不已。彼时,他还是航天科工集团的一名技术人员,这段服务期培养了他对技术一丝不苟,对工作认真负责的航天人精神。三年后,他没有走大多数同事选择的路,而是回校继续深造,理由依然是“我希望每天都能有新的东西出现,做更有挑战性的事情”。
求新并不代表浮躁,好奇心的确能够创造世界,但前提是能够将“求新”的态度,在产品定位、研发和推向市场的路径中,做到扎实,落到实处。不得不说,这与张楠赓在事业单位内积累的工作经验息息相关。
北航深造期间的张楠赓并不“安分”,在经历了很多新鲜尝试后,他最终将方向确立在区块链ASIC芯片。受限于学校教研室环境的困囿,张楠赓决定于2012年退学创业。几个月后,嘉楠科技横空出世,并于同年发布了全球首款基于ASIC芯片的区块链计算设备。嘉楠科技成为该领域历史最悠久的公司,没有之一。
选择AI芯片也与张楠赓个人的探索欲有关,“我有一个习惯,一个行业如果已经有做的不错的公司或者产品了,比如说做CPU,那我就觉得别去弄了。而AI芯片这边直至现在这么多年过去了,还是没有发展的特别好,这种行业才适合创业者去折腾。”
嘉楠科技作为中国AI芯片产业中的一员,自然也要经受同样的考验。张楠赓说,“我始终相信的是,只要产品足够好,我们就不畏惧任何挑战”。在2016年,嘉楠科技成功实现28nm 制程工艺芯片的量产,迈出了 AI 芯片量产的第一步。之后又在2018年实现量产全球首款基于RISC-V自研商用边缘智能计算芯片勘智K210。
在AI领域,张楠赓坦言嘉楠科技没有历史包袱,“我们不做追随者”。无论是RISC-V架构的采用,还是勘智K210中AI神经网络加速器KPU的自主研发,都是嘉楠科技硬实力的明证。
(原文链接:https://baijiahao.baidu.com/s?id=1639849500096450487&wfr=spider&for=pc)

oppo 算法工程师 稚晖在《嵌入式AI从入门到放肆【K210篇】– 硬件与环境》中描述为:
K210是个啥
K210是由一家叫做嘉楠的曾经做挖矿芯片的公司在去年推出的一款MCU,其特色在于芯片架构中包含了一个自研的神经网络硬件加速器KPU,可以高性能地进行卷积神经网络运算。
可不要以为MCU的性能就一定比不上高端SoC,至少在AI计算方面,K210的算力其实是相当可观的。根据嘉楠官方的描述,K210的KPU算力有0.8TOPS ,作为对比,拥有128个CUDA单元GPU的英伟达Jetson Nano的算力是0.47TFLOPS ;而最新的树莓派4只有不到0.1TFLOPS 。
(原文链接:https://zhuanlan.zhihu.com/p/81969854)
电路城《低成本的机器学习硬件平台:使用MicroPython快速构建基于AI的视觉和听觉设备》
有关的阐述:
本文介绍了 Seeed Technology 推出的一种简单且高性价比的替代方案,能使开发人员使用熟悉的 MicroPython 编程语言部署基于 AI 的高性能解决方案。
在机器视觉应用中,KPU 使用较小图像帧类型,以 30 fps 以上速度进行推断,用于智能产品的面部或对象检测。对于非实时应用,开发人员可以使用外部闪存来处理模型大小,从而只受限于闪存的容量。
**使用 MicroPython 快速开发**
创建 MicroPython 旨在为资源受限的微控制器提供 Python 编程语言的优化子集。MicroPython 为硬件访问提供直接支持,为嵌入式系统软件开发引入相对简单的基于 Python 的开发。
开发人员使用熟悉的 Python 导入机制,而非 C 语言库,来加载所需的库。例如,开发人员只需导入 MicroPython 机器模块即可访问微控制器的 I2C 接口、定时器等。对于使用图像传感器的设计,开发人员可以通过导入传感器模块,然后调用 sensor.snapshot(),从图像传感器返回一个帧,进而捕获图像。
Seeed 的 MaixPy 项目扩展了 MicroPython 的功能,支持作为 MAIX-I 模块核心的双核 K210 处理器和相关开发板。MaixPy MicroPython 解释器在 MAIX-I 模块的 K210 处理器上运行,可使用 MicroPython 功能和囊括了 K210 处理器 KPU 功能的MaixPy 专用模块,例如 MaixPy KPU 模块。
开发人员可以使用 MaixPy 和 KPU 模块轻松部署 CNN 推断。实际上,Seeed MaixHub 模型库提供了许多预训练的 CNN 模型,以便帮助开发人员着手使用 MAIX-I 模块。如需下载这些模型,开发人员就需提供机器 ID。该 ID 可通过在 MAIX 板上运行 ID 生成器实用程序获得。
例如,借助带 LCD 的 Seeed Sipeed MAIX Go 套件,开发人员可以加载面部检测的预训练模型。使用该模型执行推断只需要几行 Python 代码。
(原文链接:https://www.cirmall.com/articles/29038)
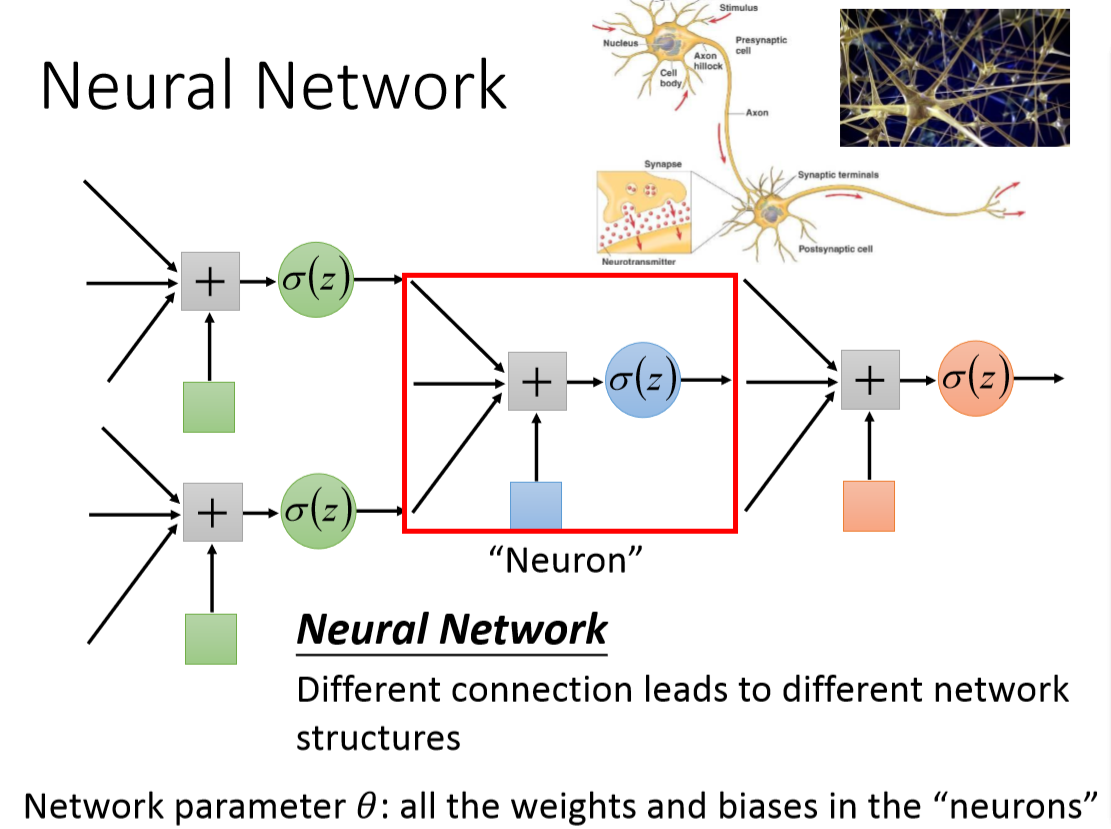
神经网络
是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。神经网络是 ML 系统(通常是深度学习子模块)的一个组成部分,它具有大量参数(称为权重),这些参数在训练过程中逐步调整,试图有效地表示它们处理的数据,因此你可以很好地泛化将要呈现给你的新案例。它之所以被这样称呼是因为它模仿生物大脑的结构,其中神经元通过突触交换电化学冲动,从而产生外部世界在我们脑海中刺激的表征和思想。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。
人脑神经元
对于神经元的研究由来已久,1904年生物学家就已经知晓了神经元的组成结构。一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。人脑中的神经元形状可以用下图做简单的说明:
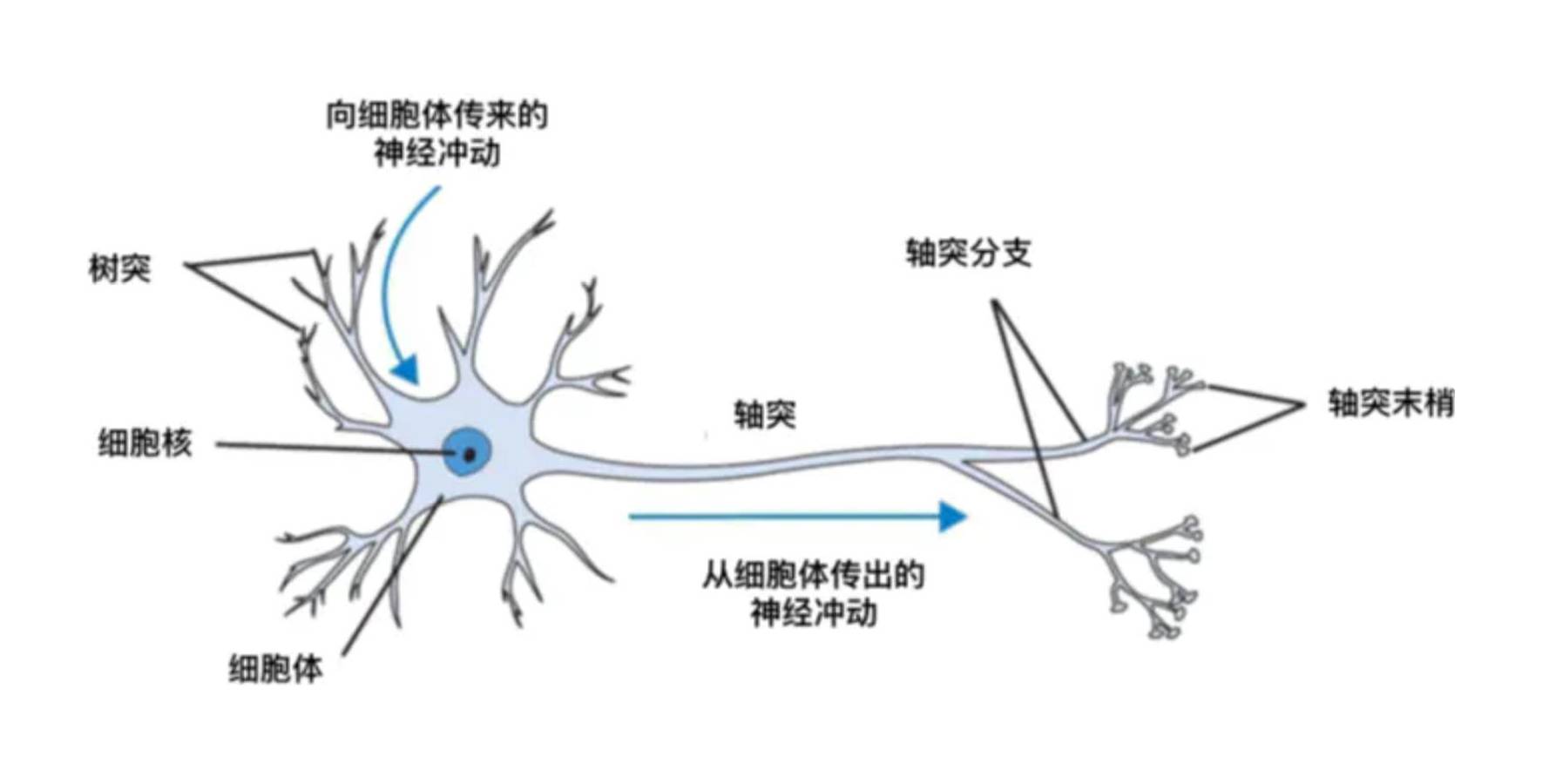
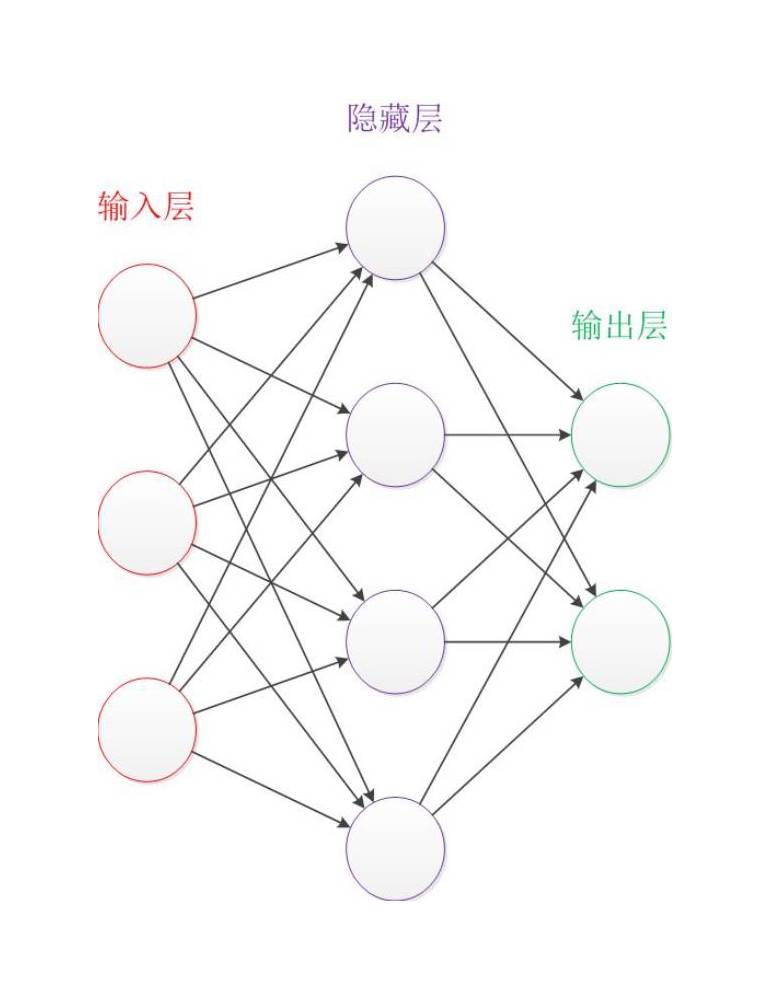
经典的神经网络图
这是一个包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。
1、设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
2、神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
3、结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
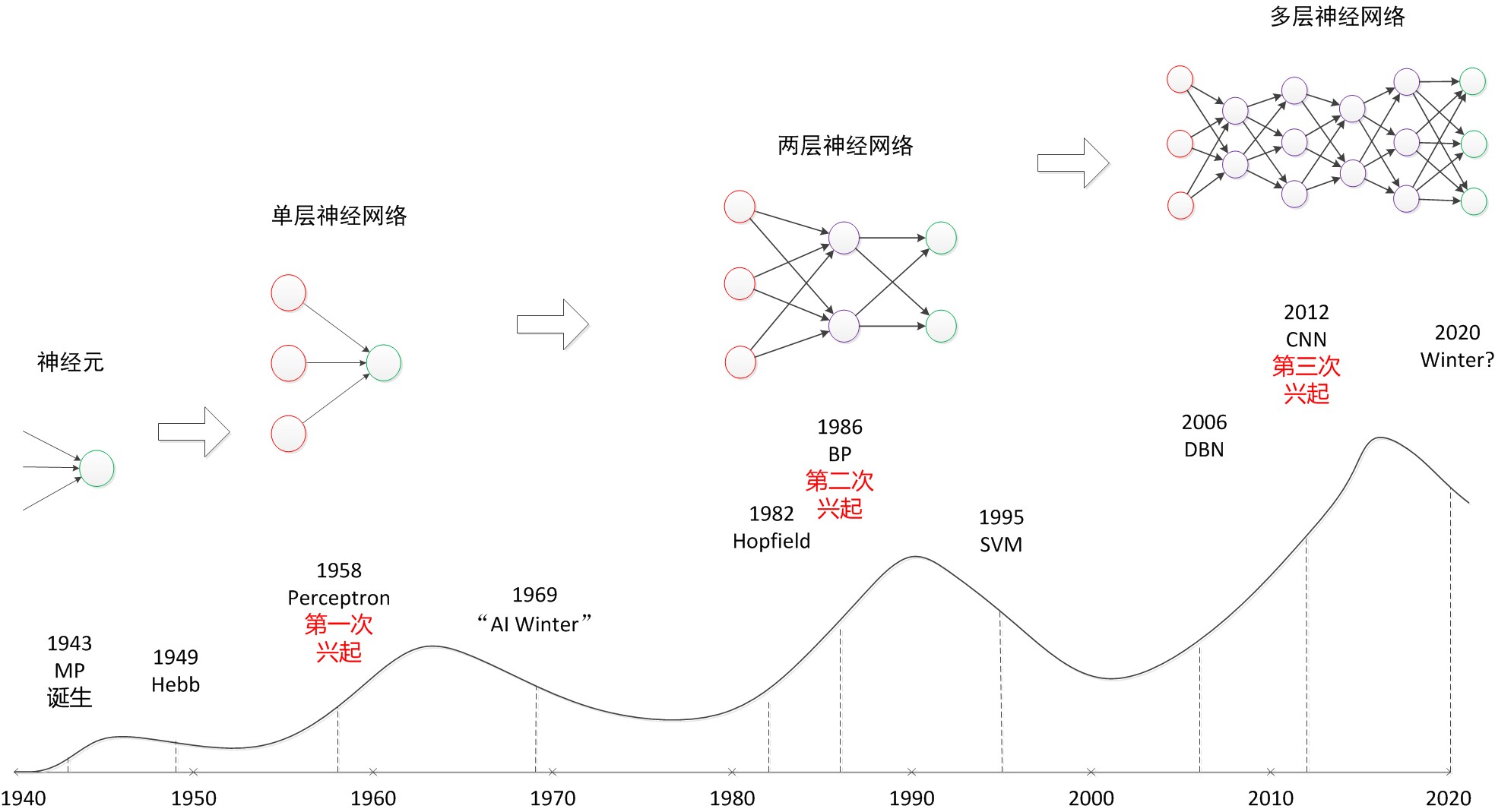
历史上神经网络的三起三落
既有被人捧上天的时刻,也有摔落在街头无人问津的时段,中间经历了数次大起大落。从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。
图中的顶点与谷底可以看作神经网络发展的高峰与低谷。图中的横轴是时间,以年为单位。纵轴是一个神经网络影响力的示意表示。如果把1949年Hebb模型提出到1958年的感知机诞生这个10年视为落下(没有兴起)的话,那么神经网络算是经历了“三起三落”这样一个过程,跟“小平”同志类似。俗话说,天将降大任于斯人也,必先苦其心志,劳其筋骨。经历过如此多波折的神经网络能够在现阶段取得成功也可以被看做是磨砺的积累吧。
历史最大的好处是可以给现在做参考。科学的研究呈现螺旋形上升的过程,不可能一帆风顺。同时,这也给现在过分热衷深度学习与人工智能的人敲响警钟,因为这不是第一次人们因为神经网络而疯狂了。1958年到1969年,以及1985年到1995,这两个十年间人们对于神经网络以及人工智能的期待并不现在低,可结果如何大家也能看的很清楚。因此,冷静才是对待目前深度学习热潮的最好办法。如果因为深度学习火热,或者可以有“钱景”就一窝蜂的涌入,那么最终的受害人只能是自己。神经网络界已经两次有被人们捧上天了的境况,相信也对于捧得越高,摔得越惨这句话深有体会。因此,神经网络界的学者也必须给这股热潮浇上一盆水,不要让媒体以及投资家们过分的高看这门技术。很有可能,三十年河东,三十年河西,在几年后,神经网络就再次陷入谷底。根据上图的历史曲线图,这是很有可能的。
详见《神经网络——最易懂最清晰的一篇文章》
https://blog.csdn.net/illikang/article/details/82019945
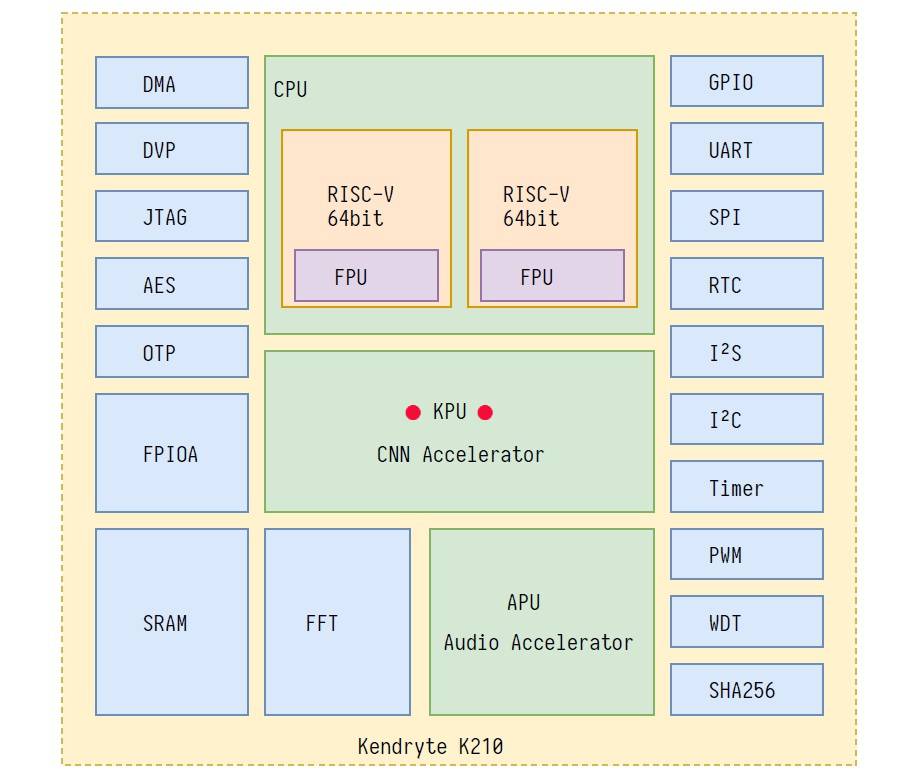
什么是KPU?
KPU是通用的神经网络处理器,它可以在低功耗的情况下实现卷积神经网络计算,时时获取被检测目标的大小、坐标和种类,对人脸或者物体进行检测和分类。
为什么需要KPU?
KPU,Neural Network Processor,或称为 Knowledge Processing Unit,是MAIX的AI处理部分的核心。
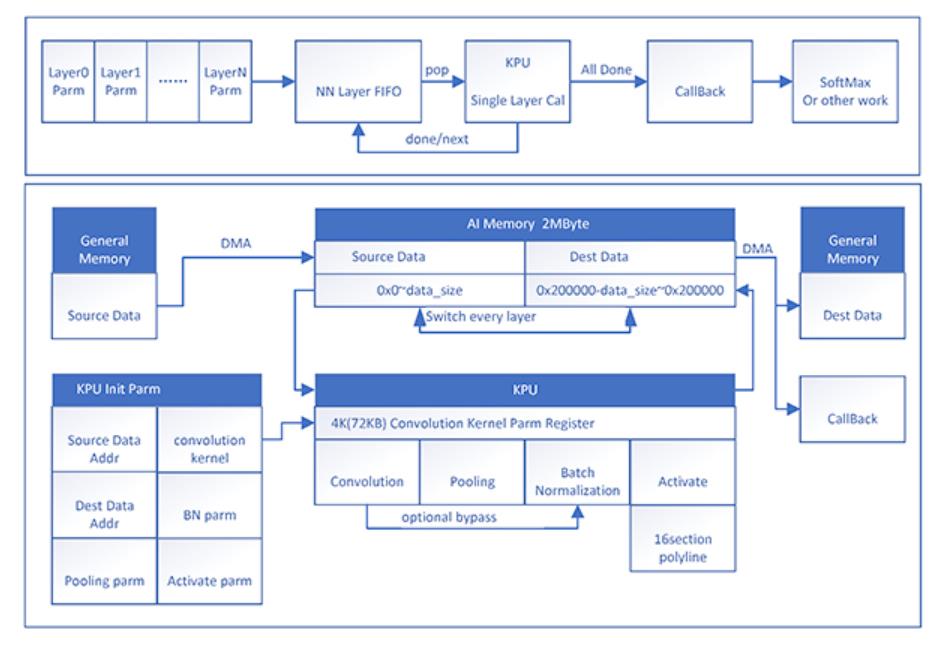
那么KPU是如何处理AI算法的呢?
首先,目前(2019Q1)所谓的AI算法, 主要是基于** 神经网络** 算法衍生的各种结构的神经网络模型,如VGG,ResNet,Inception, Xception, SeqeezeNet,MobileNet, etc.
那为什么不使用普通CPU/MCU进行神经网络算法的计算呢?
因为对多数应用场景来说,神经网络的运算量太大:
例如640x480像素的RGB图片分析,假设第一层网络每颜色通道有16个3x3卷积核,那么仅第一层就要进行640x480x3x16=15M次卷积运算,
而一次3x3矩阵的计算时间,就是9次乘加的时间,加载两个操作数到寄存器,各需要3周期,乘法一个周期,加法一个周期,比较是否到9一个周期,跳转一个周期,那么大致需要9x(3+3+1+1+1+1)=90周期
所以计算一层网络就用时15M*90=1.35G个周期!
我们去掉零头,1G个周期,那么100MHz主频运行的STM32就要10s计算一层,1GHz主频运行的Cortex-A7需要1s计算一层!
而通常情况下,一个实用的神经网络模型需要10层以上的计算!那对于没有优化的CPU就需要秒级甚至分钟级的时间去运算!
所以,一般来说,CPU/MCU来计算神经网络是非常耗时,不具有实用性的。
而神经网络运算的应用场景,又分为训练侧 与 推断侧。
对于训练模型所需要的高运算力,我们已经有了NVIDIA的各种高性能显卡来加速运算。
对于模型推断,通常是在消费电子/工业电子终端上,也即AIoT,对于体积,能耗会有要求,所以,我们必须引入专用的加速模块来加速模型推断运算,这时候,KPU就应运而生了!
KPU 具备以下几个特点:
支持主流训练框架按照特定限制规则训练出来的定点化模型
对网络层数无直接限制,支持每层卷积神经网络参数单独配置,包括输入输出通道数目、输入输 出行宽列高
支持两种卷积内核 1x1 和 3x3
支持任意形式的激活函数
实时工作时最大支持神经网络参数大小为 5.5MiB 到 5.9MiB
非实时工作时最大支持网络参数大小为(Flash 容量-软件体积)


 他的勋章
他的勋章

9mm2023.07.28
666