 返回首页
返回首页
 回到顶部
回到顶部
一、研究背景
在数字经济与全球化供应链深度融合的今天,物流分拣线已从后台设备跃升为产业竞争的核心战场。面对全球日均超30亿件货物的分拨需求,传统作业模式正被智能化、柔性化的分拣线颠覆。从无人仓里的磁悬浮传送带到跨境枢纽中的AI视觉机器人,从云端算法调度到数字孪生预演,物流分拣线正以技术创新重构物流效率的边界。
物流分拣线历经半个世纪的技术迭代,形成四大代际跃迁:
1.机械化分拣(1970-1990),以传送带+人工分拣台为主,分拣速度低于1000件/小时,依赖人工目视识别。
2.自动化分拣(1990-2010),激光扫描+PLC控制实现自动分拣,处理量突破5000件/小时,准确率提升至95%。
3.智能化分拣(2010-2020),机器视觉+AI算法开启智能识别时代,分拣速度达2万件/小时,SKU处理种类扩展至百万级。
4.智慧化分拣(2020-至今),5G+数字孪生实现预测性维护,柔性机器人突破异形件限制,分拣线自主决策能力初现。
• 最新成果:2024年顺丰投产全球首条“零人工干预”分拣线,通过6D视觉+量子计算优化,异常处理效率提升90%。
据Logistics IQ数据,2028年全球智能分拣线市场规模将突破1200亿美元,其中中国占比预计达58%。在“双碳”目标与数字中国战略驱动下,物流分拣线正从效率工具进化为供应链的智能中枢。未来,当分拣线能自主感知市场需求、自组织生产资源、自适应环境变化,物流产业将真正实现从“人脑决策”到“系统涌现”的质变。这场始于传送带的革命,终将重塑全球商品流通的底层逻辑。
二、研究目的
智慧分拣是现代工厂信息化发展的新阶段。它利用先进的信息技术,如物联网(AIoT)、大数据、人工智能、云计算等,将工厂中的设备、人员、物料、工艺等各个要素进行全面的互联互通,实现智能化的生产、管理和决策。
例如,在传统工厂中,货物的分拣需要人工手动分类,而在智慧分拣工厂,通过在设备上安装传感器摄像头等设备,能够实时分析货物类型以及状态,并进行机械臂分拣和数据上传,大大提高了设备的生产效率。
所以我们研究的“基于AI模型训练中图像检测的智能工厂分拣项目”致力于精确的实现工厂各类物料的分拣筛选工作。通过摄像头进行物品的识别,然后利用AI模型,检测物品,确认货物的类别,然后分拣在传送带上的物品,最终完成货物的分类筛选。同时AI在识别出物品后,会在行空板上显示物品的名称和相应物品的图片,同时还会通过语音进行播报此物品的相应功能。
此项目从数据收集、模型训练到推理与应用,完整呈现人工智能技术如何解决生活与工作需求,实出工厂的智能化,并能大大提高生产效率。
三、主要创新点
1. 本项目是基于AI模型训练中图像检测功能来完成物品的识别功能。
2.本项目是利用物联网,进行模型的识别与功能的执行。
3.本项目是用行空板M10来完成相应功能的实现。
4.本项目的传送装置是用乐高进行搭建成功的。
四、Mind+ V2图像分类功能简介

图像分类是人工智能中的基础任务之一,它可以让计算机自动识别图片所属类别。通过分析图片的内容,计算机能够判断图中对象是猫、狗、交通标志,或者其他指定类别。
它不仅能对静态图片进行识别,还能实时分析摄像头采集的画面,快速判断当前场景中出现的物体类别,实现动态识别和监控。这让图像分类不仅适用于照片整理和教学演示,也能应用于安防、智能驾驶、宠物识别等多种场景。
应用场景
物体识别:识别动物、植物、交通标志等,实现计算机对图片内容的自动识别分类。
工业检测:检查产品外观或发现缺陷,提高生产效率和质量控制水平。
教育与科研:用于快速实验、教学演示或科研数据分析,帮助理解人工智能的应用原理。
五、作品实现过程
1.进行乐高搭建传送装置,实现自动运行与传送功能。

2.实现原理
本项目基于图像分类技术实现物品识别与互动功能,整个实现过程涵盖从数据准备到模型推理与应用的全流程。具体而言,首先通过 Mind+ 模型训练平台进行图像分类模型的图像采集与模型训练;训练完成后,对模型进行校验与优化,并导出为适用于行空板M10的格式;最终将模型部署至行空板M10进行推理应用,利用摄像头捕获实时画面,通过网络进行模型推理识别,输出物品名称与图像,并执行对应的操作。
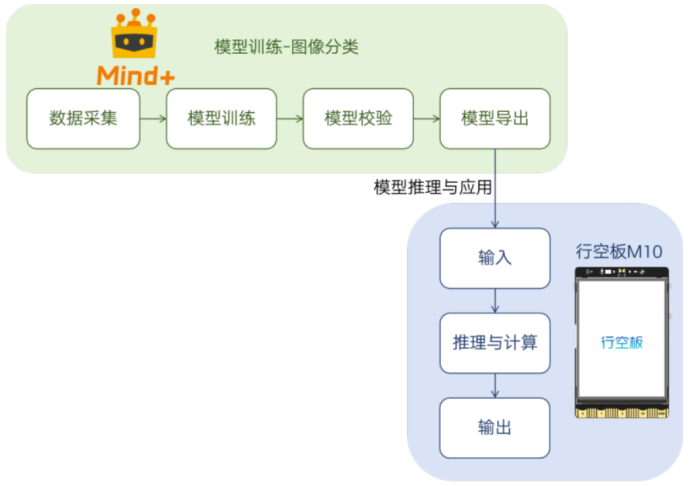
3.软硬件环境准备

注意:行空板系统版本在 v0.4.1 及以上均适用于本项目制作,行空板的 Python 环境版本为 3.12,Mind + 编程软件版本为 v2.0。
4. 硬件连接准备
本项目需在行空板上实现图像 “输入 - 推理与计算 - 输出” 流程:通过 USB 摄像头拍摄图像,在行空板部署图像分类模型完成推理与结果输出。
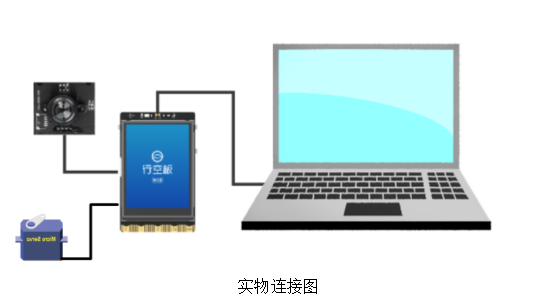
5.软件平台准备

6.环境和扩展
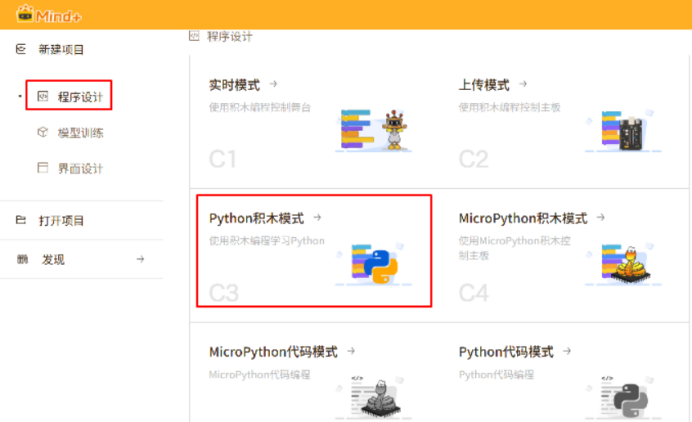
(1)环境准备---“Python模式”。
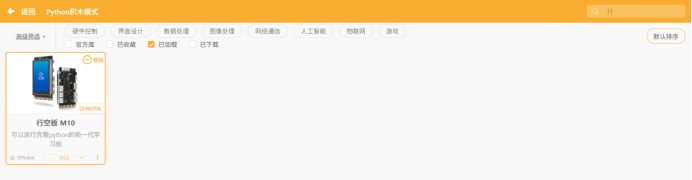
(2)主板准备---加载行空板。
7. 检测行空板版本
在行空板上按home按钮,进行主界面,选择6-查看系统信息。
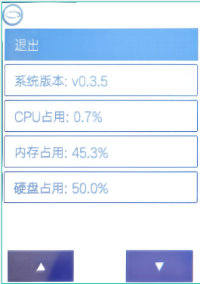
注意:要想在行空中进行AI模型训练,行空板必须符合以下条件。
(1)行空板系统版本在 v0.4.1 及以上均
(2)行空板的 Python 环境版本为 3.12
如果行空板系统不符合以上条件,需要进行固件烧录,升级版本。
8. 系统镜像固件烧录。
(1)工具准备-----UNIHIKER Batch Tool:
(2)最新系统镜像固件下载: 最新版本: V0.4.5
(3)烧录系统。
(4)系统烧录完成功,查验行空板系统的板本是否合适。

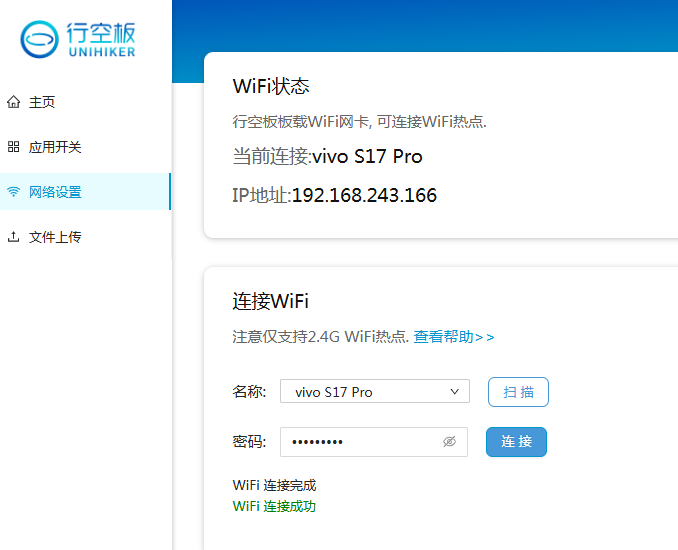
9.行空板联网
在浏览器地址栏中输入“10.1.2.3”。选择“网络设置”->点击“扫描”->选择无线网络名称并输入密码->点击“连接”。显示“wifi连接成功”,你的行空板已经连接好了网络。
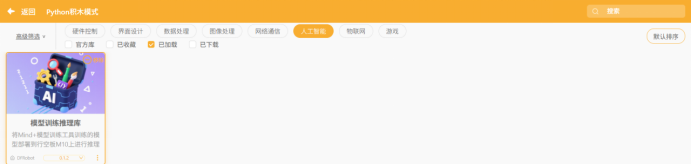
10.加载模型训练库
在扩展中搜索“模型训练”点击下载并添加该用户库。
11.模型训练
我们使用Mind+中的模型训练来完成分类水果的采集、模型训练和导出。
首先,打开Mind+软件,选择“模型训练”并打开“图像分类”(注意:只有Mind+2.0及以上版本才有模型训练功能)。
打开初始界面如下:

页面分为三部分,从左至右依次为:数据采集、模型训练、模型校验与导出。
12.数据采集
为了训练表情分类模型,我们需要准备含有不同类别的数据集。
本项目中使用了西红柿和西葫芦两种图片样本,所以需要添加两个类别,设置好的类别如下:
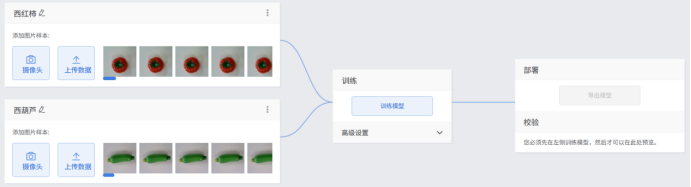
本项目数据的采集通过摄像头采集,每个类别50张图片样本。
13.训练模型
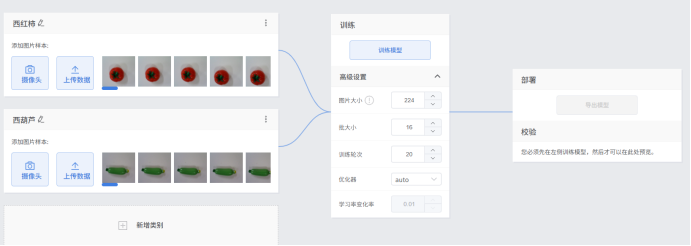
点击“训练模型”按钮,即可开始训练模型。点击“高级设置”按钮,可进行参数设置。
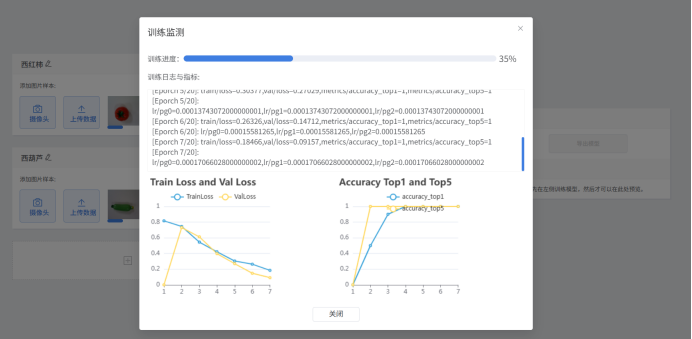
训练过程与结果观察
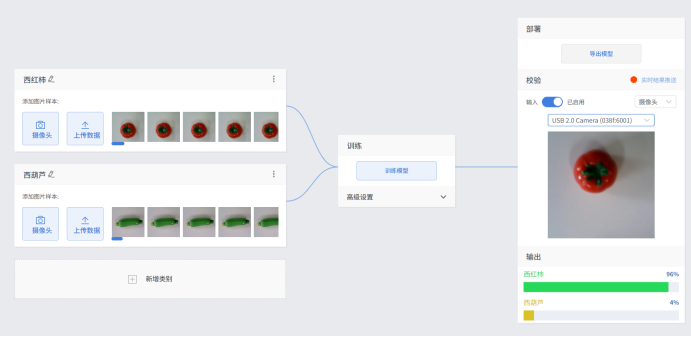
14.模型校验
实时测试,选择“摄像头”,进行实时目标检测。
15. 模型导出
校验完成后将模型导出,后续部署至行空板M10。

导出后为zip文件,解压后文件里有best.onnx和data.yaml。
16.模型部署
(1)模型部署
打开Mind+编程软件并进入python模式。
将导出的模型解压,上传模型文件。
点击“资源文件”->选择“上传文件”->选择模型(.onnx)及其配置文件(.yaml)->点击“打开”
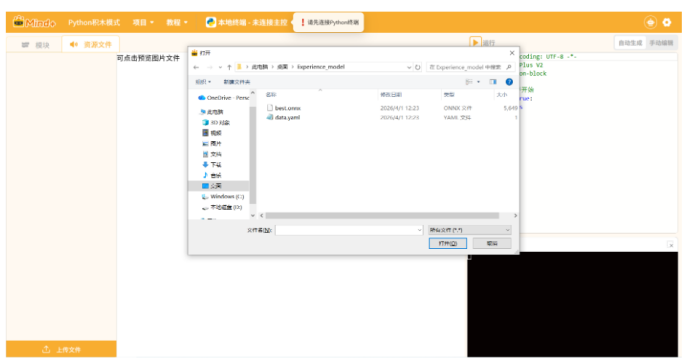
(2)编写程序
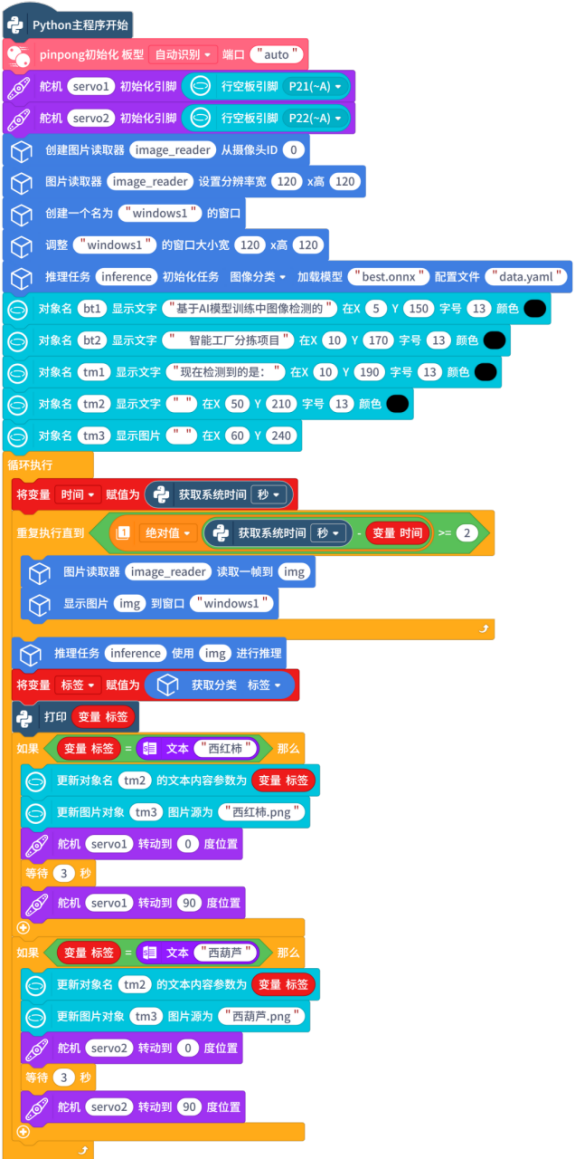
17.作品测试情况
经测试我们这个作品的功能可以完全实现。
第一个功能是传送带的搭建,我们是用乐高零件进行搭建的。其中的传送是利用齿轮的转动,由简易电机来实现的。
第二个功能是AI大模型的测试,我们是用的Mind+模型训练中的图像分类进行AI训练,实现通过网络进行大模型的识别。经实际检测此功能完全可以实现。
第三大功能是行空板的控制功能。我们利用行空板进行摄像头和舵机的控制,来实现分拣功能。经实际检测此功能完全可以实现。
18.制作过程中的问题
问题一:在进行传送带搭建的时候,我们发现两个连接的齿轮所带动的转轴,旋转方向是相反的,经研究我们才发现了他的物理原因。相邻的齿轮的对齿转动,相隔的的齿轮的反齿转动。于是我们采取了隔一个安装从动轮。
问题二:在进行传送带搭建的时候,用的是大齿轮带动小齿轮转动,后来发现,它的转动速度特别的快。后来在学习的过程中,发现小齿轮带动大齿轮转动,才能把速度慢下来,于是我们再次更改了结构设计。
问题三:进行AI大模型的建立的时候,我们采用了图络生图的方式,利用千问进行文生图。但是在AI模型建立好,进行识别的时候,效果非常的差。后来经过网络群中资询,才明白,要想在Mind+模型训练中的图像分类进行AI识别时,识别率高,只能进行摄像头实物识别。后期我们进行更改,完全是用USB口摄像头进行AI图像采集,完成大模型的训练。
问题四:在行空板执行程序时,最开始怎么也不成功,后来发现大模型训练是基于网络的,行空板必须要连接网络,才能实现相应的功能。
19.项目总结
本项目已顺利完成,在此次项目的制作过程中,我学到了很多的知识点。
1. 物理的传动知识。
2. AI大模型的样本选取。
3. Mind+中有关图像模型的程序编写。
20.意见与反馈
本次我用了Mind+中的AI模型训练中的图像分类,在使用这个的时候,我有一点个人的小意见。我认为这个模型的识别还是太局限了,我用哪个模型进行数据采集,他才对哪个模型有一个很好的识别。当我用一些同类的物品,在形态上有一些小的差别,差别不大,但是识别率并不高。在这里我不知道是我的采样形式太单一,采样的数量太少的原因,还是因为大模型的识别的缺陷。


 他的勋章
他的勋章





评论