 返回首页
返回首页
 回到顶部
回到顶部
本文带你快速三种部署方式:lmdeploy、vllm、sglang ,将InternLM/Intern-S1-mini 模型在书生开发机上进行部署与调用。
Intern-S1-mini 可通过 体验页面、GitHub、HuggingFace 和 ModelScope 获取与体验。
2. LMDeploy 部署
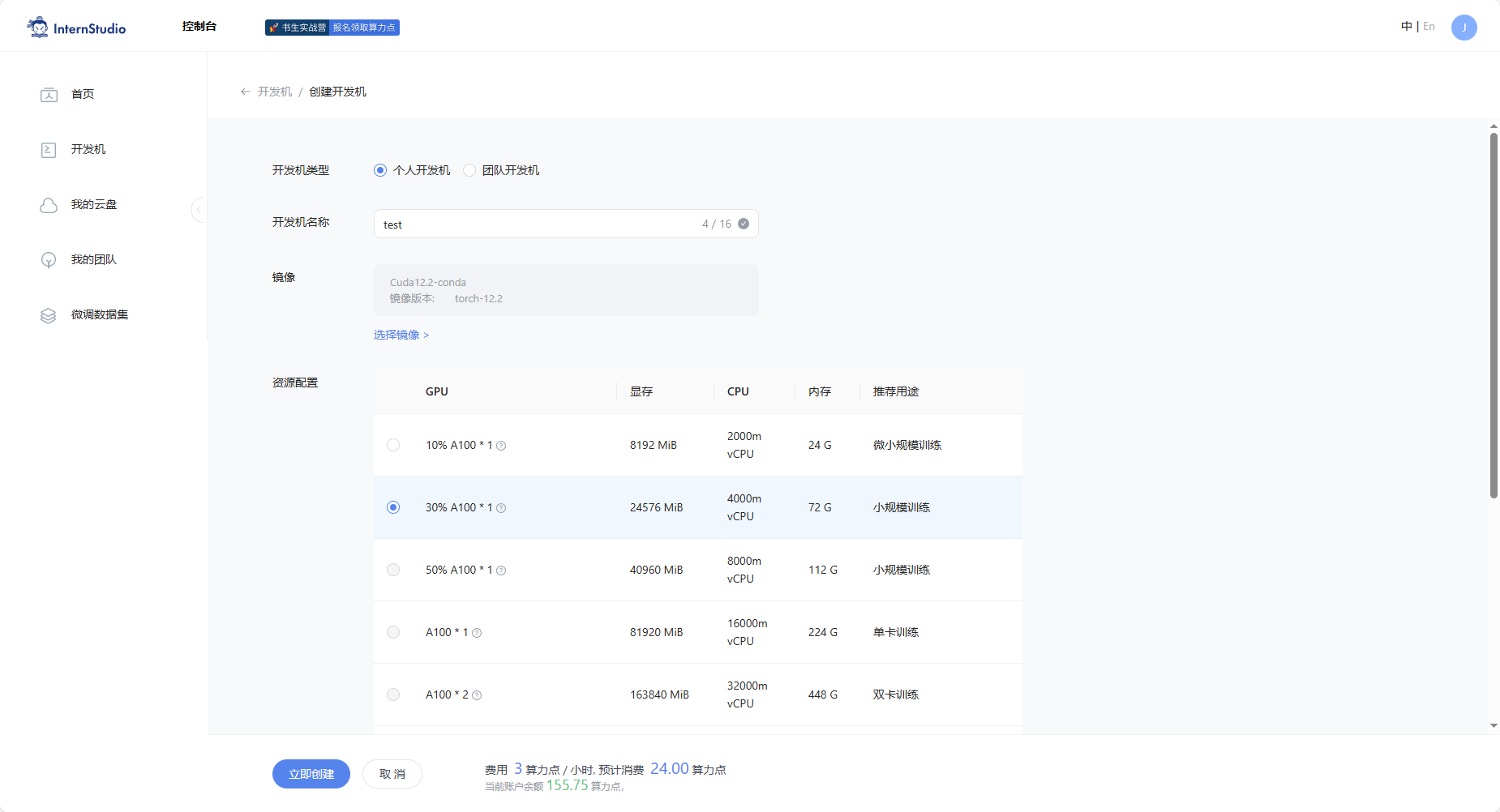
2.1 开发机的选择
安装依赖
代码
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install "lmdeploy==0.9.2.post1" "transformers==4.55.2"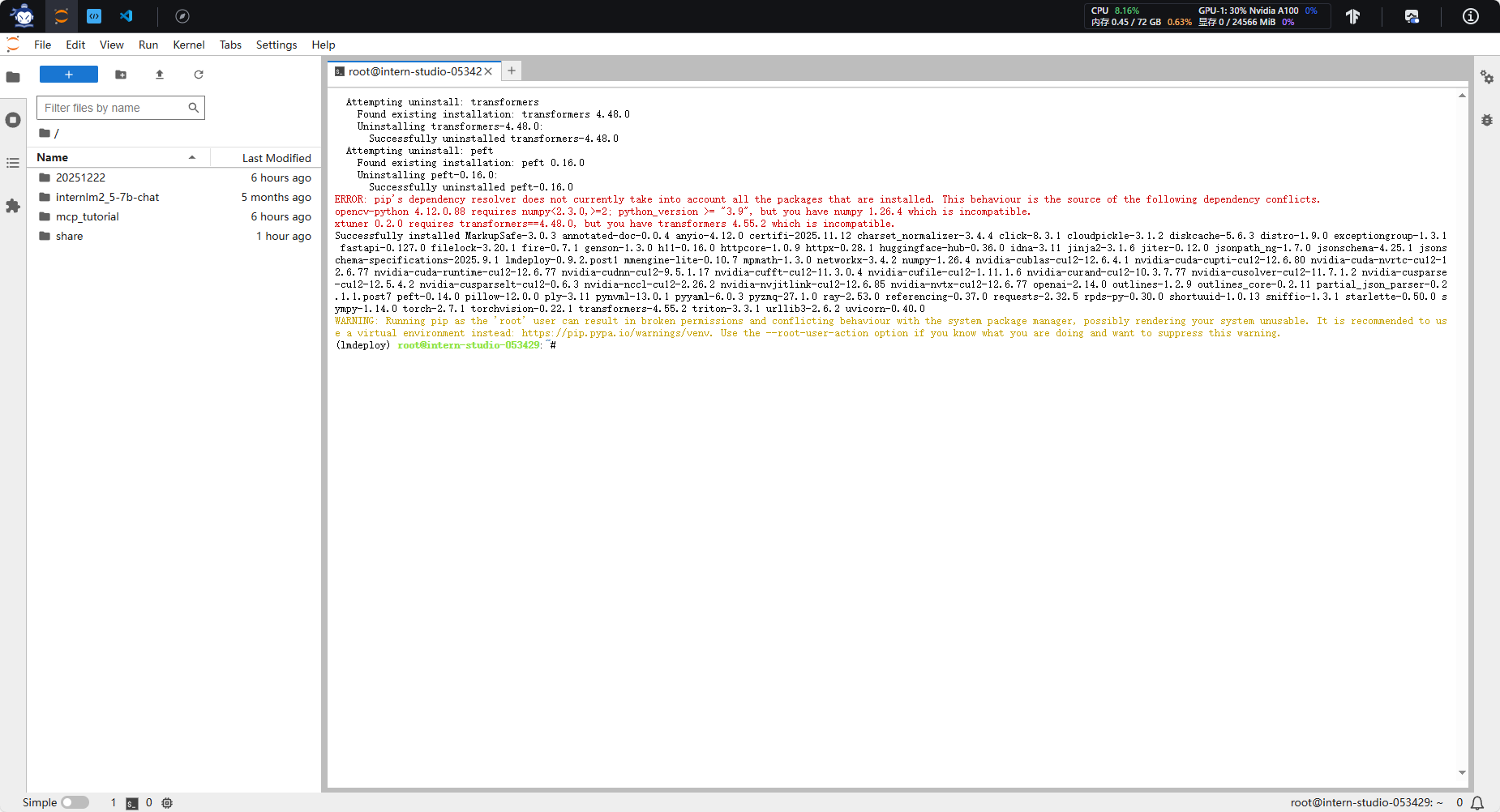
2.2 启动
代码
lmdeploy serve api_server /root/share/new_models/Intern-S1-mini \
--reasoning-parser intern-s1 \
--tool-call-parser intern-s1 \
--cache-max-entry-count 0.1 \
--max-batch-size 8 \
--backend turbomind \
--session-len 2048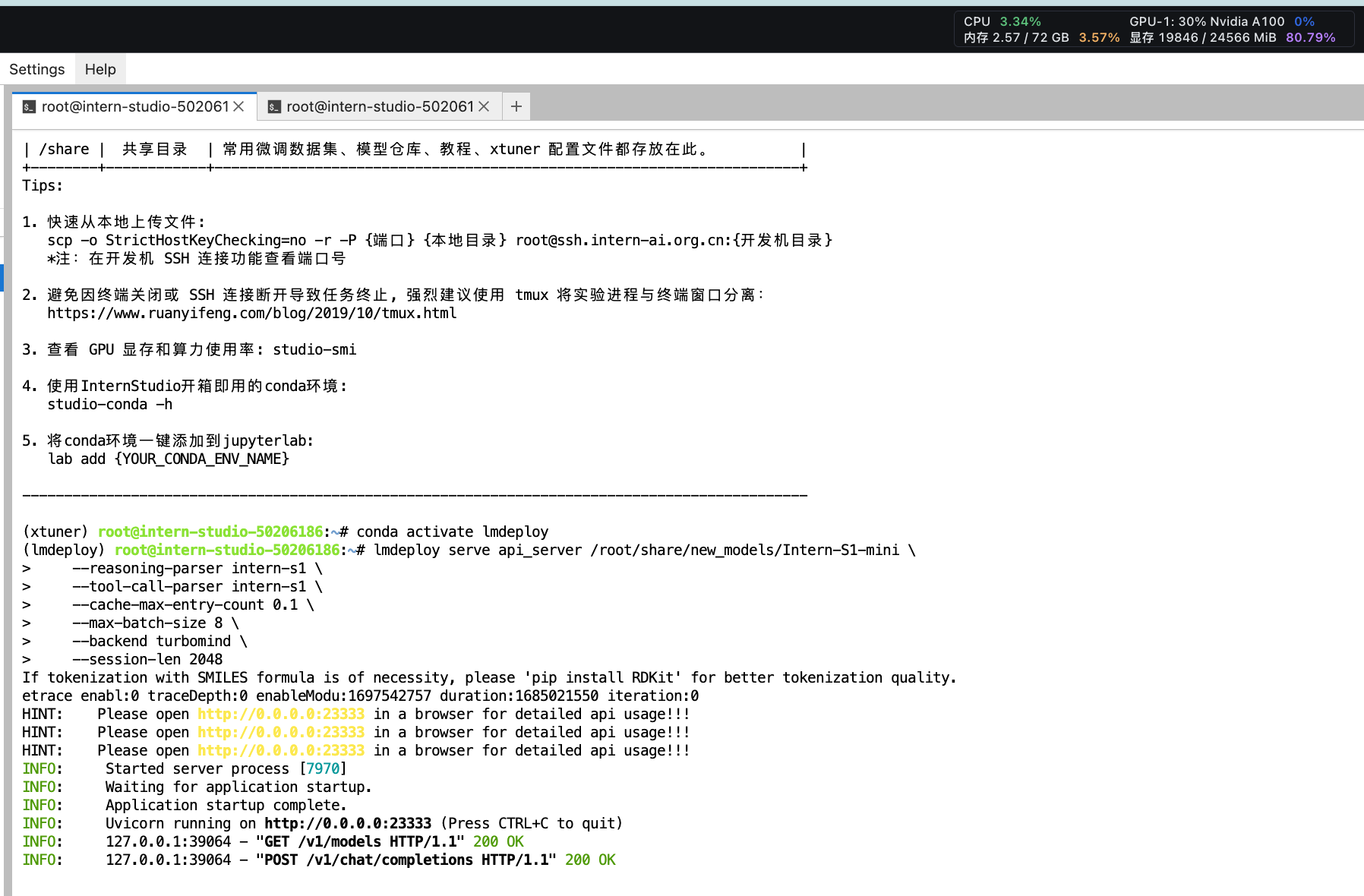
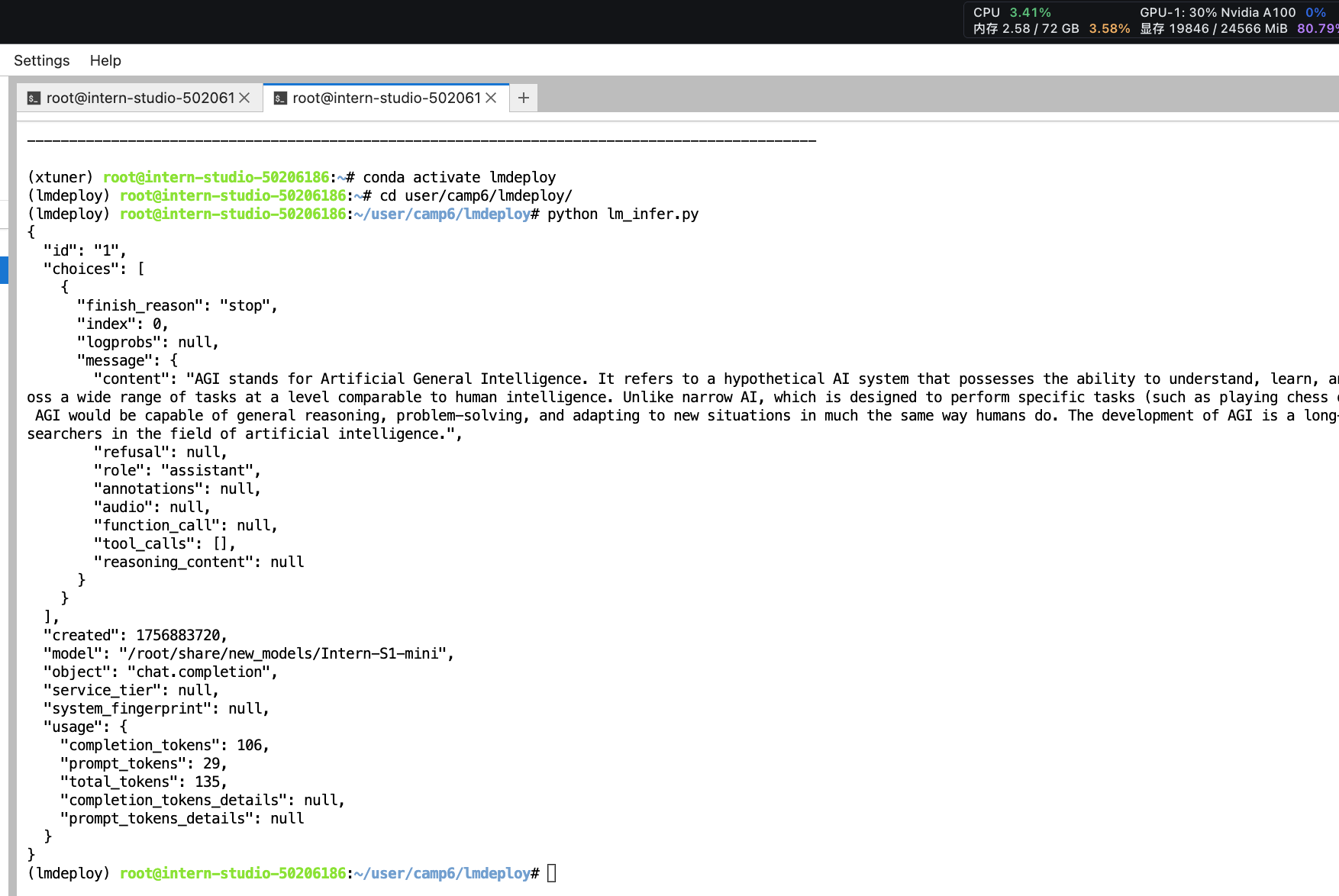
2.3 推理
代码
from openai import OpenAI
import json
messages = [
{
'role': 'user',
'content': 'who are you'
}, {
'role': 'assistant',
'content': 'I am an AI'
}, {
'role': 'user',
'content': 'AGI is?'
}]
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:23333/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
max_tokens=2048,
extra_body={
"enable_thinking": False,
}
)
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))



 他的勋章
他的勋章









评论