 返回首页
返回首页
 回到顶部
回到顶部
因为Mind+使用的YOLO 模型,它是目标检测领域最经典、最实用的算法之一,之前使用yolo制作的面部表情数据集正好用于测试。数据集中包含“愤怒”、“高兴”、“平淡”。Mind+模型训练工具是一款集 AI 模型训练、测试与快速体验于一体的智能工具,支持图像、音频、姿势和文本等多种 AI 任务。
1.打开mind+进入目标检测
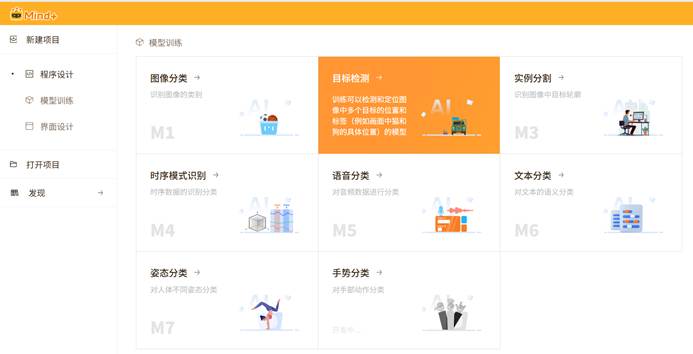
2.进入后发现快速体验中的数据量很清晰,设置数据集→对数据集训练→部署模型并校验。
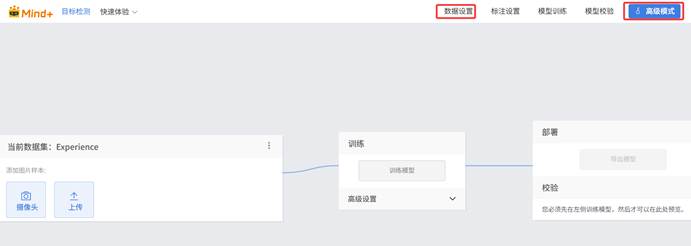
3.Mind+可以直接导入YOLO数据集。直接选择experience数据集进行测试。进入高级模式——数据设置。

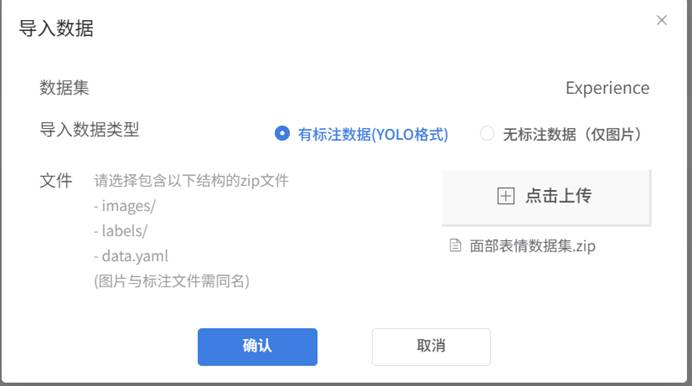
4.导入之前所准备的YOLO数据集,将文件压缩成.zip格式压缩文件。data.yaml是配置文件,用于告诉模型数据集的路径、类别信息等关键参数。这里要注意一点,在之前yolo使用过程中使用配置文件会定义数量并命名,在mind+中直接用字典(键值对集合)。导入数据集。
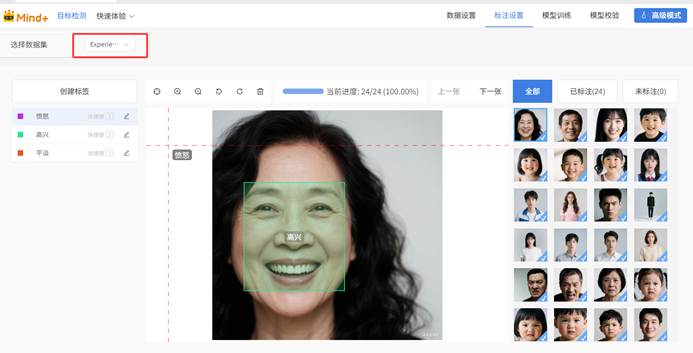
5.一种表情准备了8张图片数据用于训练模型,因为平淡的人脸特征不是很明显,不知能否识别出来。查看标注数据,一定要选数据集。因为用之前的标注工具标注过,所以现在标注信息是直接呈现的。
6.进入模型训练,首先对训练参数设置,因为模型选择了yolov8n,参数设置图片增大,批次32次,训练轮次200次,因为yolo最少要训练200次才能提高训练效果。
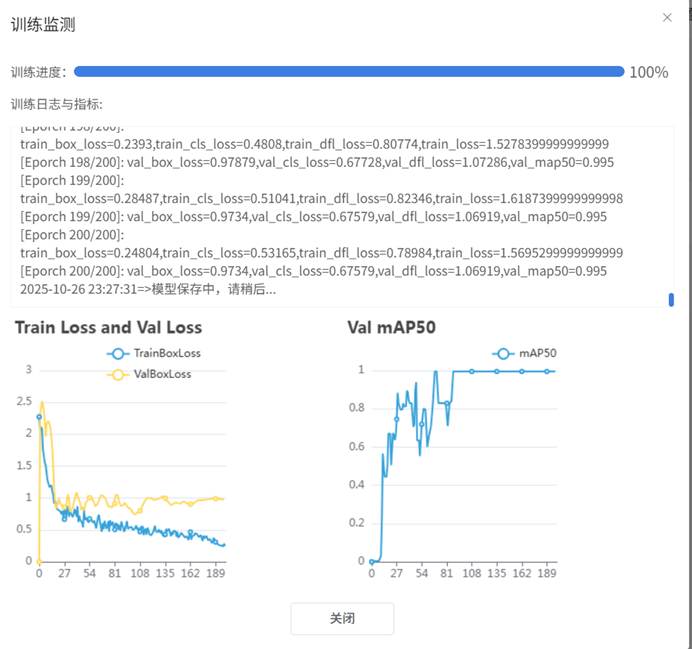
7.开始训练,这里要注意训练时有两个图表,图表的作用要注意。从深度学习模型训练过程中训练损失(train_loss)和验证/测试损失(val_loss/test_loss)的变化趋势出发, train_loss 不断下降,val_loss(test_loss) 不断下降模型在训练集上的误差持续降低,在 unseen 的验证 / 测试集上误差也持续降低。这是最理想的训练状态,说明模型在 “学习有用的模式”,且这些模式具备泛化能力,能迁移到新数据上。看训练的数据还算比较理想。
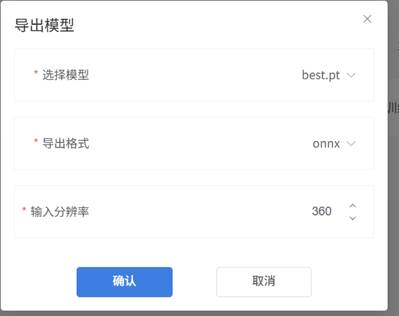
8.本次训练大约10多分钟,对电脑的CPU要求比较高,所以测试尽量选择高性能处理器。将模型导出,模型为best.pt(最好的),格式为onnx,导出后为后面用M10测试模型和二哈2.0测试模型做准备。
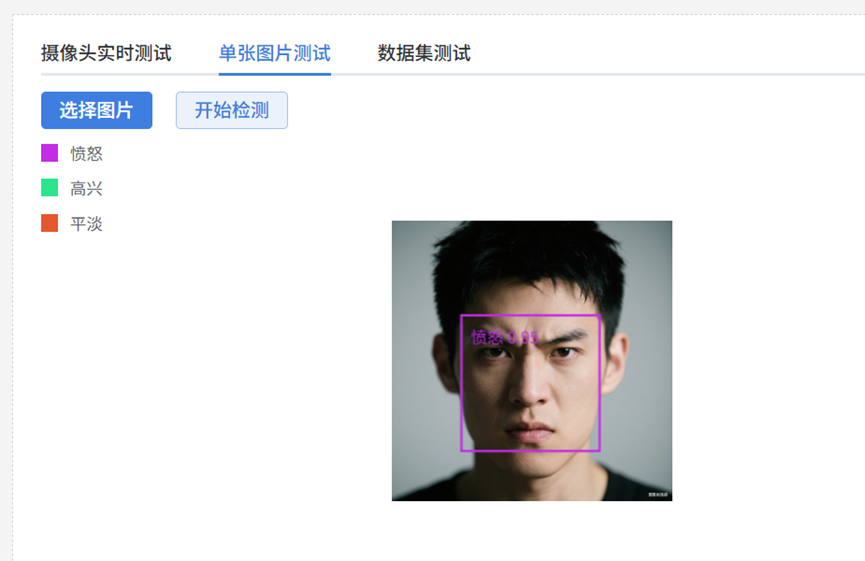
9.使用单张图片测试一下,用数据集中的图片,检测效果成功。


 他的勋章
他的勋章







罗罗罗2025.11.13
学习了