 返回首页
返回首页
 回到顶部
回到顶部

一、实践目标
本项目借助浦育在线平台训练石头剪刀布的手势模型,之后使用行空板和外接摄像头,进行实时的手势识别,并将识别结果显示在屏幕上。
二、知识目标
了解在线上平台训练模型的方式
三、实践准备
硬件清单:

软件使用:Mind+编程软件x1
四、实践过程
1、在线图像采集与模型训练
1、打开浦育网站,点击”AI体验“,打开”图像分类“:https://www.openinnolab.org.cn/pjlab/aifrontlab

2、打开摄像头采集图像,或上传提前准备好的图片到不同分类下
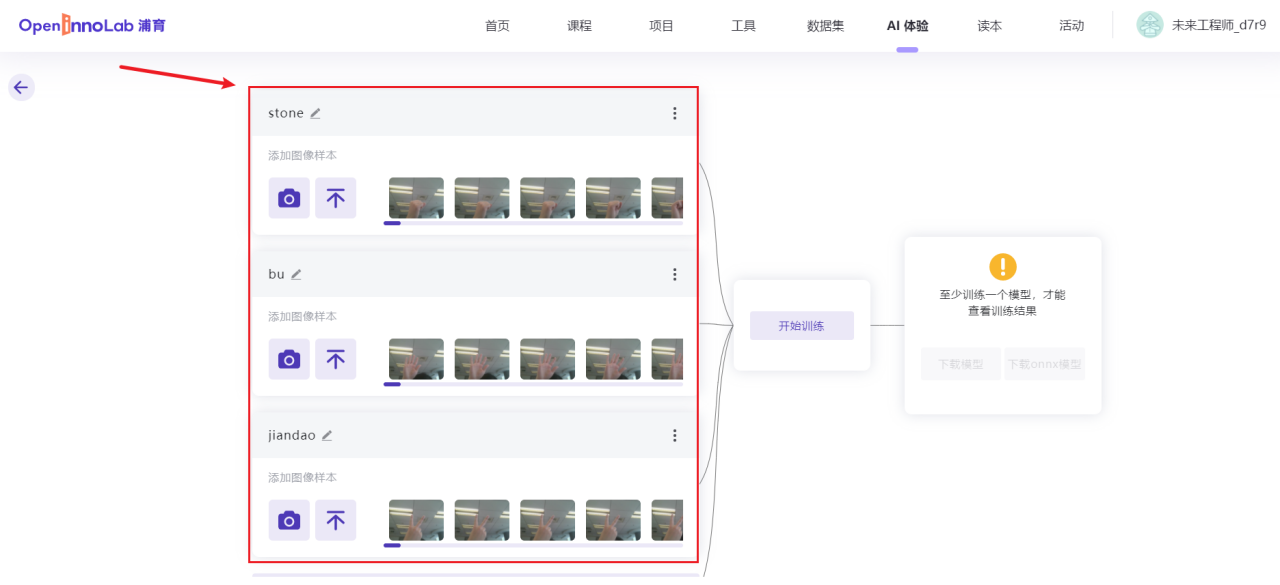
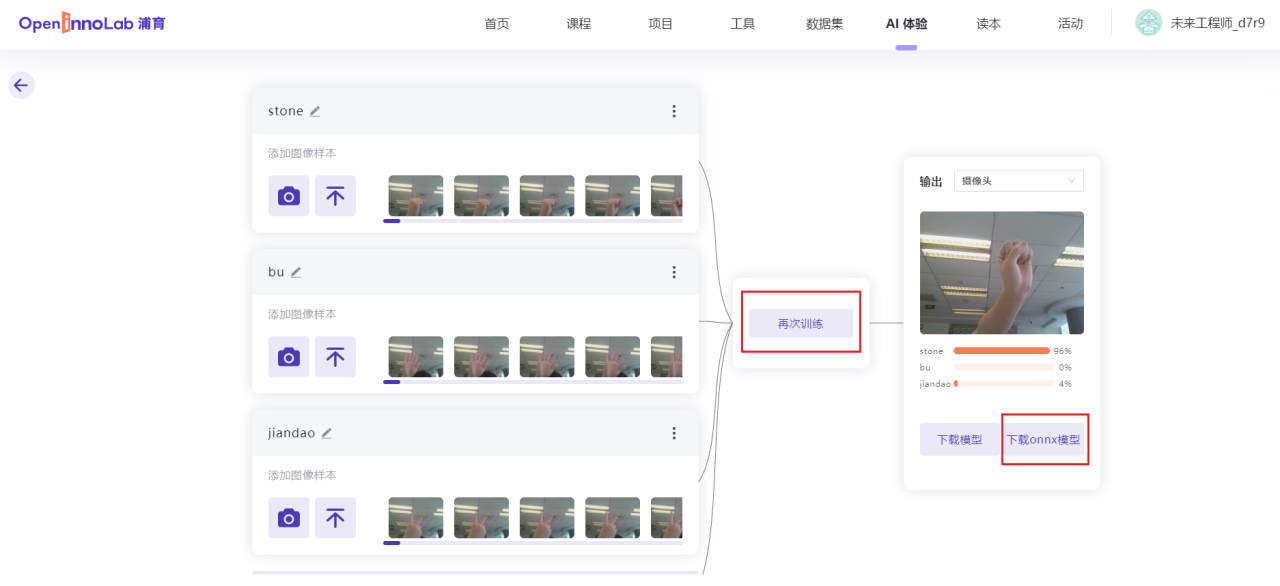
3、数据采集完成后,点击训练,训练完毕后测试效果,并下载onnx模型
2、硬件搭建
1、将摄像头接入行空板的USB接口。
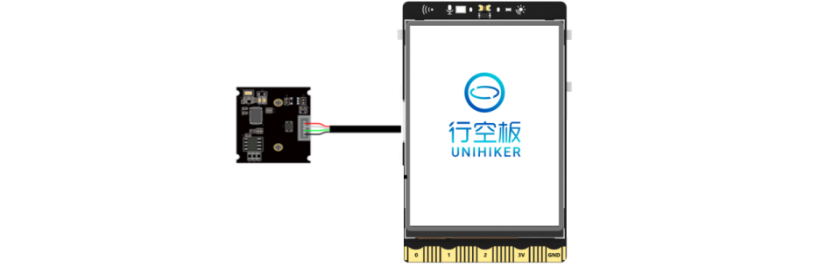
2、通过USB连接线将行空板连接到计算机。

3、软件编写
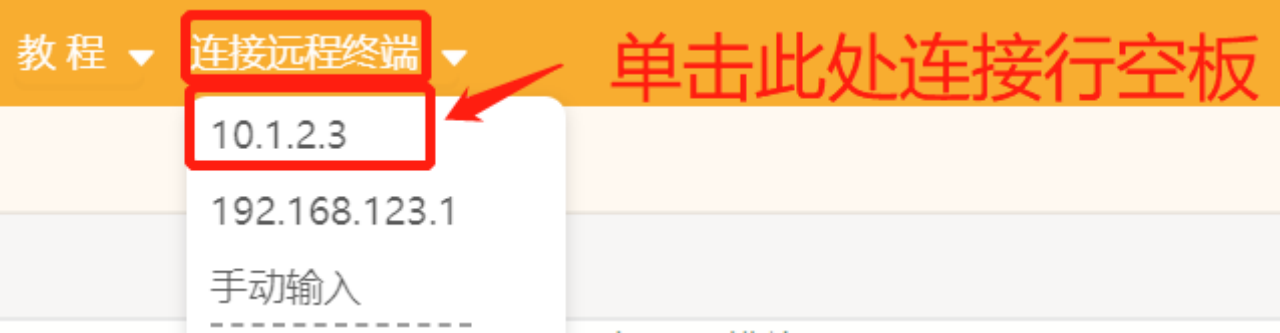
第一步:打开Mind+,远程连接行空板
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的图像分类在线模型应用”的文件夹,导入下载的onnx模型文件。
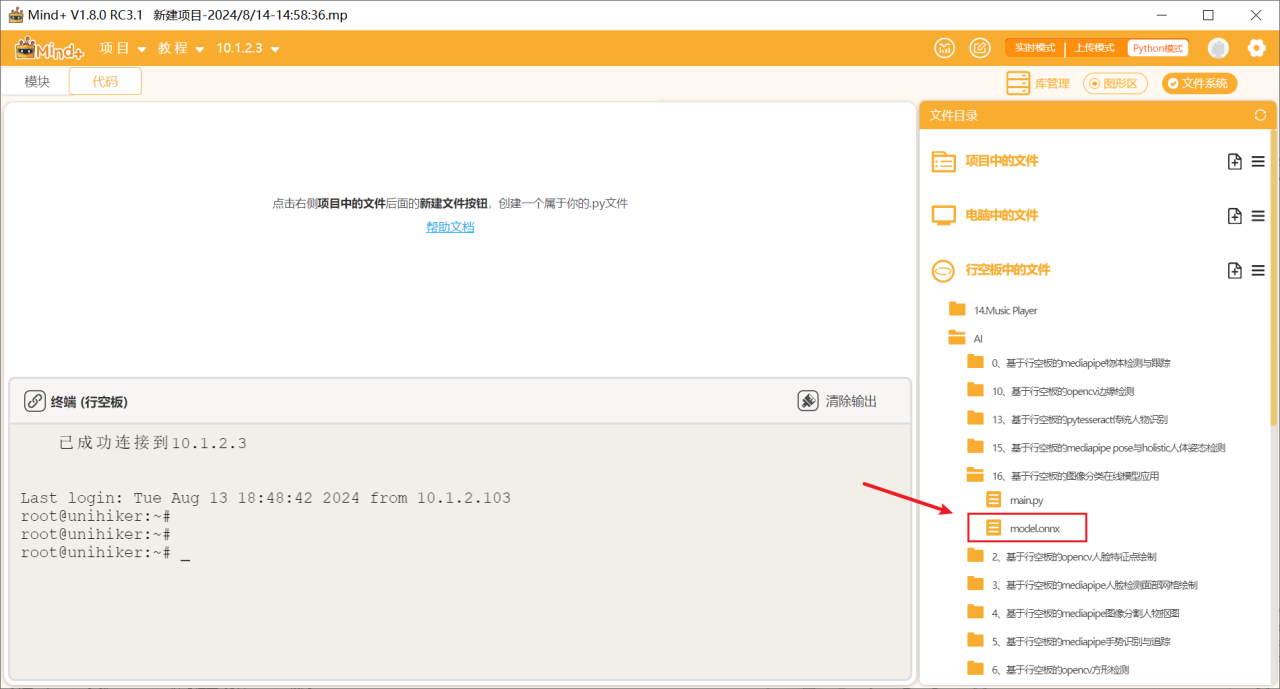
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
# -*- coding: UTF-8 -*- # 指定源代码文件使用的字符编码为UTF-8
# MindPlus # MindPlus环境相关的配置
# Python # 该脚本使用Python语言
import sys # 导入sys模块,用于与Python解释器交互
sys.path.append("/root/mindplus/.lib/thirdExtension/nick-xeduhub_main-thirdex") # 添加自定义路径到sys.path,便于导入特定模块
sys.path.append("/root/mindplus/.lib/thirdExtension/winster-cvshow-thirdex") # 添加另一个自定义路径到sys.path
import re # 导入正则表达式模块,用于字符串匹配
import cv2 # 导入OpenCV库,用于图像和视频处理
import sys # 冗余导入,可以删除
from unihiker import GUI # 从unihiker模块中导入GUI类
from XEdu.hub import Workflow as wf # 从XEdu.hub模块中导入Workflow类并重命名为wf
import os # 导入os模块,用于操作系统相关的功能
# 定义一个格式化任务输出的函数
def format_valve_output(task):
try:
output_result = ""
output_result = task.format_output(lang="zh") # 调用任务对象的format_output方法并指定语言为中文
return output_result # 返回格式化后的输出结果
except AttributeError:
return "AttributeError: 请检查输入数据是否正确" # 如果发生AttributeError异常,返回错误提示
para_task1 = {} # 初始化一个空的字典,用于存储任务参数
u_gui = GUI() # 创建一个GUI对象
TuXiangLuJing = (str("Mind+.png")) # 定义保存图像的文件路径
BiaoQianMing = ["stone","jiandao","bu"] # 定义标签名称列表
init_para_task1 = {"task":"mmedu"} # 初始化任务参数
init_para_task1["checkpoint"] = "model.onnx" # 设置模型检查点参数
task1 = wf(**init_para_task1) # 使用参数初始化Workflow对象
vd = cv2.VideoCapture() # 创建一个VideoCapture对象,用于捕获视频
vd.open(0) # 打开默认摄像头
vd.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置视频缓冲区大小
print("打开摄像头中...") # 输出提示信息
while not (vd.isOpened()):
pass # 等待摄像头打开
print("摄像头已打开") # 输出提示信息
while True:
ret, grab = vd.read() # 读取摄像头图像
if vd.grab(): # 如果成功抓取到图像
grab = cv2.resize(grab, (240, 320)) # 调整图像大小
cv2.imwrite(TuXiangLuJing, grab) # 将图像保存到指定路径
u_gui.clear() # 清除GUI内容
u_gui.draw_image(image=TuXiangLuJing, x=0, y=50) # 在GUI中绘制保存的图像
txt = u_gui.draw_text(text="识别中...", x=0, y=0, font_size=20, color="#0000FF") # 在GUI中绘制文本
para_task1["data"] = TuXiangLuJing # 更新任务参数中的数据路径
if 'task1' in globals() or 'task1' in locals(): # 检查task1是否已初始化
rea_result_task1 = task1.inference(**para_task1) # 进行推理操作
else:
print("init", 'task1') # 输出初始化信息
task1 = wf(**init_para_task1) # 重新初始化Workflow对象
rea_result_task1 = task1.inference(**para_task1) # 进行推理操作
output_result_task1 = format_valve_output(task1) # 格式化推理结果
JieGuoXuHao = output_result_task1["标签"] # 获取标签结果
result = (BiaoQianMing[JieGuoXuHao]) # 根据标签索引获取对应的标签名称
print(result) # 输出标签名称
txt.config(text=(str("识别结果:") + str(result))) # 更新GUI文本内容
4、运行调试
第一步:运行主程序
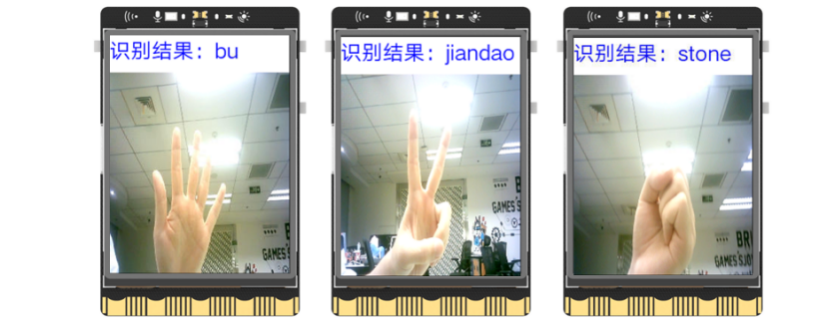
运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准石头剪刀布,可以看到识别结果显示在了屏幕上。
5、程序解析
在上述的“main.py”文件中,我们主要通过opencv库来调用摄像头,从摄像头中读取图像,然后使用在线平台训练得到的模型对图像进行识别分类,并在图像上显示推理结果。整体流程如下,
① 初始化:
· 设置必要的系统路径以确保能够导入自定义库和模块。
· 导入需要的库,包括 cv2(用于图像处理)、unihiker.GUI(用于图形用户界面)、以及 XEdu.hub.Workflow(用于工作流和推理任务)。
· 定义辅助函数 format_valve_output,用于格式化任务的输出。
· 设置任务参数和路径,包括图像路径 TuXiangLuJing 和任务标签 BiaoQianMing。
· 初始化一个 Workflow 对象 task1,并设置模型检查点路径。
② 摄像头准备:
· 初始化并打开默认的摄像头设备,设置摄像头的缓冲区大小以优化读取速度。
· 等待摄像头完全打开后,输出提示信息确认摄像头已准备就绪。
③ 主循环:
· 程序进入一个无限循环,每次循环中执行以下操作:
· 从摄像头捕获一帧图像并调整图像大小。
· 保存调整后的图像到指定路径 TuXiangLuJing。
· 在 GUI 界面上绘制图像并显示“识别中...”的文本提示。
· 更新推理任务的参数以包含当前捕获的图像路径。
· 执行推理任务,调用 task1.inference 获取结果。
· 使用 format_valve_output 函数格式化推理任务的输出结果。
· 从格式化的结果中获取预测标签的序号并从标签列表 BiaoQianMing 中获取对应的标签名称。
· 在控制台上打印识别结果,并在 GUI 上更新文本显示,显示识别结果。
④ 结束:
· 如果在任何时候检测到用户输入退出信号(例如按下特定键),程序将跳出循环。
· 在程序退出前,释放摄像头设备以释放资源。
五、拓展
1、关于本项目更多操作细节,可参考此链接:
附件



 他的勋章
他的勋章

评论