 返回首页
返回首页
 回到顶部
回到顶部

一、实践目标
本项目在行空板上外接USB摄像头,通过摄像头来识别物体,找到画面中的方形物体并将其框出。
二、知识目标
学习使用opencv进行图像处理及形状检测的方法。
三、实践准备

软件使用:Mind+编程软件x1
四、实践过程
1、硬件搭建
1、将摄像头接入行空板的USB接口。
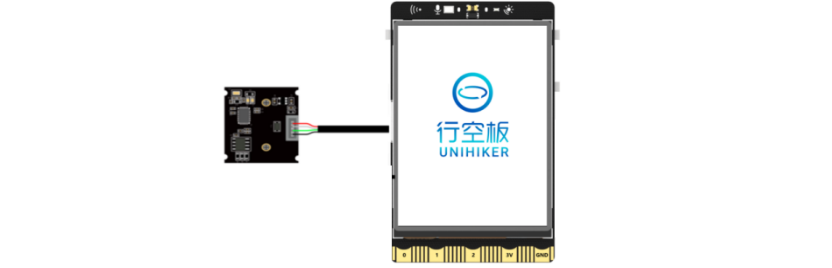
2、通过USB连接线将行空板连接到计算机。

2、软件编写
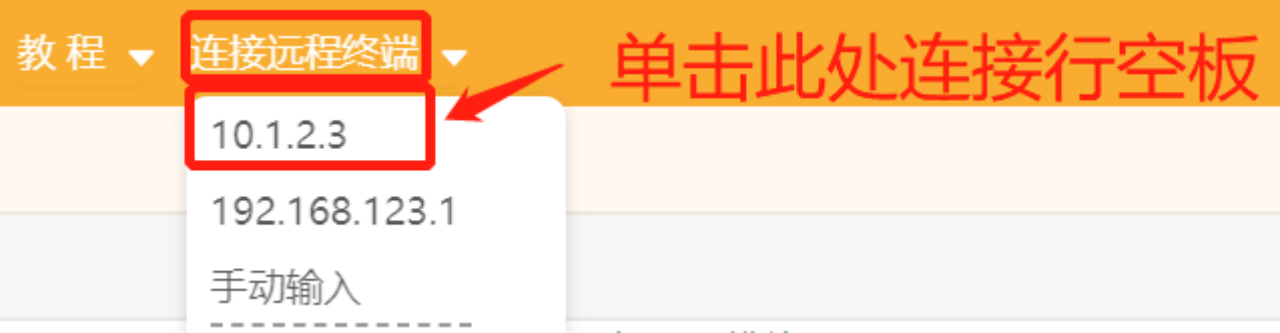
第一步:打开Mind+,远程连接行空板
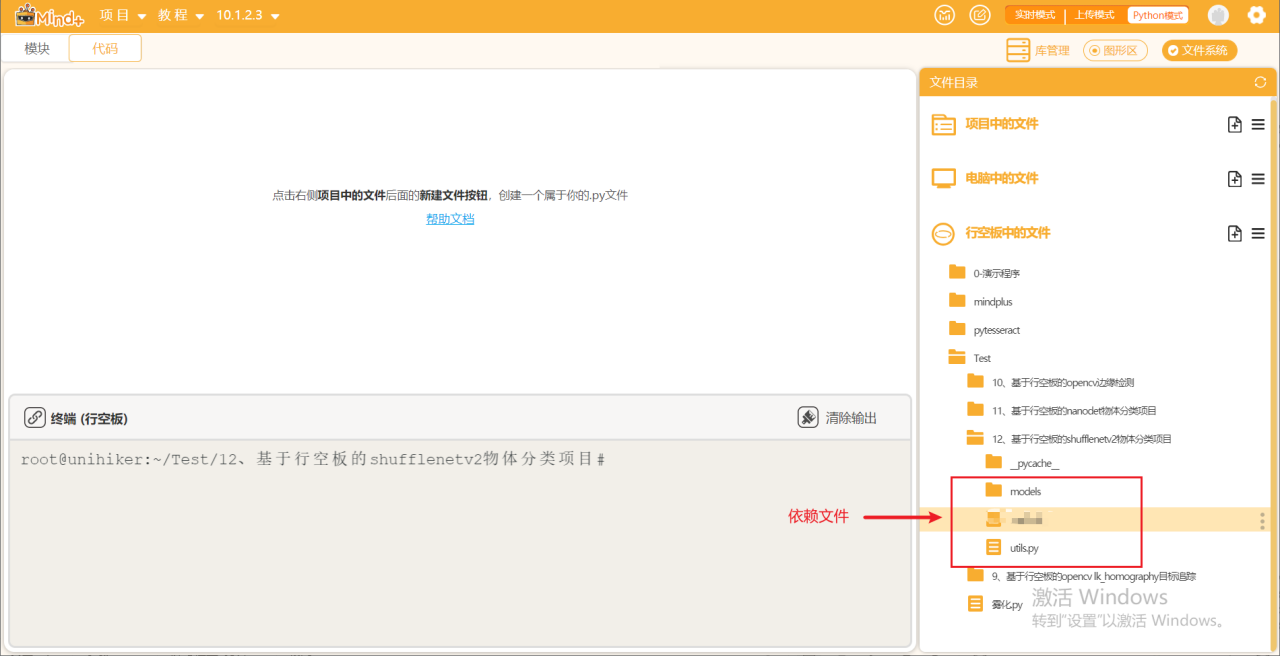
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的shufflenetv2物体分类项目”的文件夹,导入本节课的依赖文件。
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
import os
# 设置NCNN的环境变量
os.environ["NCNN_HOME"] = os.getcwd()
import sys
import cv2
import time
import numpy as np
import ncnn
# 导入ncnn的模型库
from ncnn.model_zoo import get_model
# 导入工具函数
from utils import print_topk
# 打开默认的摄像头设备
cap = cv2.VideoCapture(0)
# 设置摄像头的分辨率为320x240
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
# 设置摄像头的缓冲区大小为1,这样可以减少延迟
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 创建一个名为'image'的全屏窗口
cv2.namedWindow('image',cv2.WND_PROP_FULLSCREEN) #Set the windows to be full screen.
cv2.setWindowProperty('image', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) #Set the windows to be full screen.
# 从模型库中获取ShuffleNetV2模型,使用4个线程进行推理
net = get_model("shufflenetv2", num_threads=4, use_gpu=False)
# 主循环
while cap.isOpened():
# 从摄像头中读取一帧
success, image = cap.read()
# 如果读取失败,则忽略这一帧
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# 使用ShuffleNetV2模型对图像进行分类,得到每个类别的分数
cls_scores = net(image)
# 在图像上打印出前三个最可能的类别
image = print_topk(cls_scores, 3, image)
# 将图像逆时针旋转90度
image = cv2.rotate(image, cv2.ROTATE_90_COUNTERCLOCKWISE)
# 显示图像
cv2.imshow('image', image)
# 如果按下了'ESC'键,则退出循环
if cv2.waitKey(5) & 0xFF == 27:
break
# 释放摄像头设备
cap.release()
3、运行调试
第一步:运行主程序
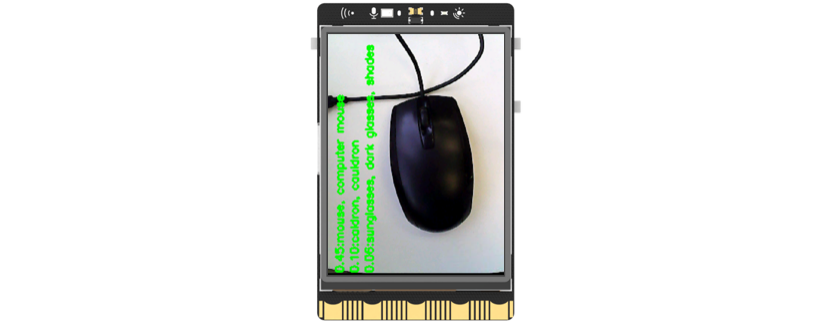
运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准一个物体(如鼠标),可以看到概率最大的前三类结果被显示在了屏幕上,其中,概率最高的为“mouse,computer mouse”即鼠标。
4、程序解析
在上述的“main.py”文件中,我们主要通过opencv库来调用摄像头,实时地从摄像头中读取图像,然后使用ShuffleNetV2模型对图像进行分类,并在图像上打印出前三个最可能的类别。整体流程如下,
①初始化:程序启动时,会设置NCNN的环境变量。然后,打开默认的摄像头设备,并设置摄像头的分辨率和缓冲区大小。接着,创建一个名为'image'的全屏窗口,用于显示图像。最后,从模型库中获取ShuffleNetV2模型,并设置相关参数。
②主循环:程序进入一个无限循环,在每次循环中,程序会执行以下操作:
· 从摄像头中读取一帧。如果读取失败,则忽略这一帧,继续下一次循环。
· 使用ShuffleNetV2模型对读取到的帧进行分类,得到每个类别的分数。
· 在读取到的帧上打印出前三个最可能的类别。打印方式是在图像上添加文本,文本内容是类别的名称和对应的分数。
· 将打印后的帧逆时针旋转90度,然后在窗口中显示出来。旋转是为了使图像的显示方向与摄像头的拍摄方向一致。
③用户交互:在每次循环的最后,程序会检查用户的键盘输入。如果用户按下了'ESC'键,那么程序会退出主循环。
④结束:当主循环结束时,程序会释放摄像头设备,然后退出。这是为了释放摄像头设备占用的资源,使其可以被其他程序使用。
五、知识园地
1. 了解ShuffleNetV2模型
ShuffleNet V2 是一种轻量级的深度神经网络架构,专为在计算和内存资源有限的设备(比如智能手机或嵌入式设备)上运行而设计。它由FaceBook的研究团队在2018年提出,并在ImageNet图像分类任务上取得了很好的性能。
ShuffleNet V2的主要特点是引入了两种新的操作:channel shuffle(通道混洗)和pointwise group convolution(分组卷积)。这两种操作可以有效地减少模型的计算量和参数数量,同时保持良好的性能。
1. Channel Shuffle(通道混洗):这是一种操作,它会重新排列输入特征图的通道顺序。这样可以增加不同通道之间的信息交换,从而提高模型的表示能力。
2. Pointwise Group Convolution(分组卷积):这是一种特殊的卷积操作,它会将输入特征图的通道分成若干组,然后在每一组内部进行卷积。这样可以减少模型的计算量和参数数量,同时保持良好的性能。
ShuffleNet V2的另一个特点是模型架构的设计原则,包括等通道数卷积、均衡的宽度和输出通道数以及逐渐增大的输出通道数等,这些设计都是为了平衡模型的计算量、参数数量和性能。
总的来说,ShuffleNet V2是一种高效、轻量级的深度神经网络架构,适合在资源有限的设备上进行图像分类和其他计算机视觉任务。
附件



 他的勋章
他的勋章

评论