 返回首页
返回首页
 回到顶部
回到顶部

一、实践目标
本项目借助行空板,对人脸图像进行检测并在其上绘制人脸特征点。
二、知识目标
1、学习使用harr算法进行人脸检测的方法。
2、学习使用Facemark框架的LBF算法进行面部特征点检测的方法。
三、实践准备
硬件清单:

软件使用:
Mind+编程软件x1
四、实践过程
1、硬件搭建
通过USB连接线将行空板连接到计算机。

2、软件编写
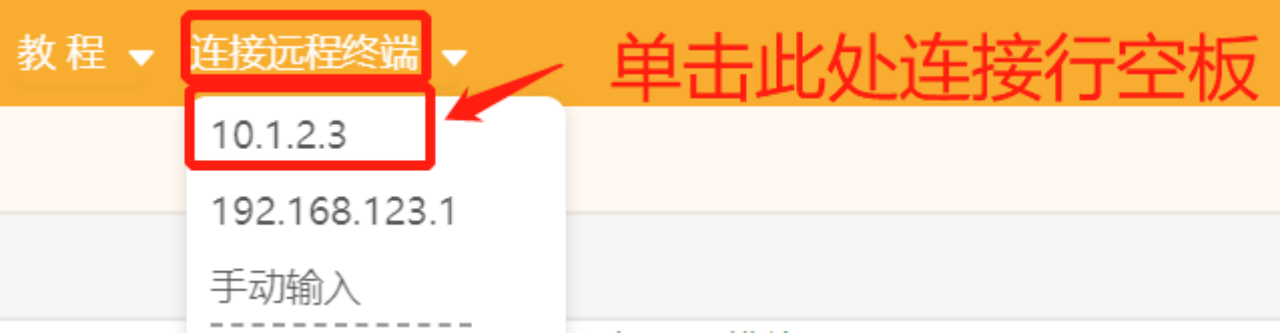
第一步:打开Mind+,远程连接行空板
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的opencv人脸特征点绘制”的文件夹,导入本节课的人脸图片和模型,以及依赖安装包和文件。
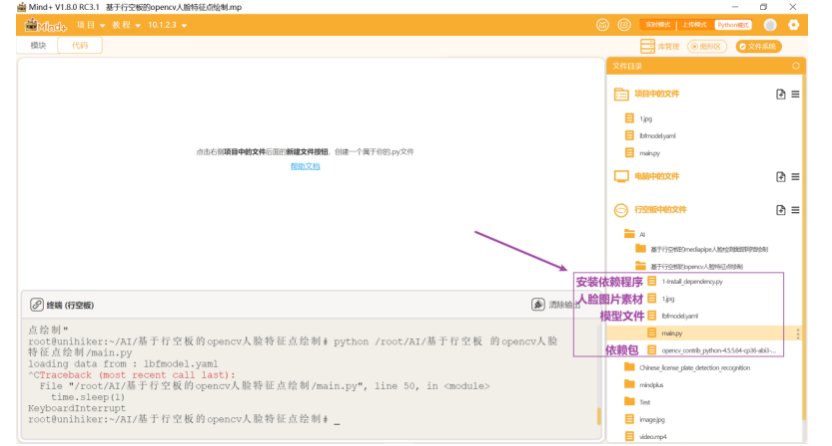
第三步:编写程序
在上述图片和模型文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
import cv2
import numpy as np
import time
from unihiker import GUI #导入包
gui=GUI() #实例化GUI类
img_image2 = gui.draw_image(x=0, y=0, image='1.jpg')
time.sleep(3)
# 加载Haar级联分类器(# 后续用来进行人脸检测 )
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 创建Facemark对象(# 后续进行面部特征点检测)
facemark = cv2.face.createFacemarkLBF()
# 加载预训练的lbf模型
facemark.loadModel("lbfmodel.yaml")
# 读取图片
image = cv2.imread('1.jpg')
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行人脸检测
# 1.3表示每次图像尺寸的减小比例,5表示指定每个候选矩形应该有多少个邻居才能保留。
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 进行特征点检测
# faces包含了所有被检测到的人脸的矩形框的列表
_, landmarks = facemark.fit(image, faces)
# 遍历每一个检测到的人脸
for landmark in landmarks:
# 遍历每一个特征点
for x, y in landmark[0]:
x = int(x)
y = int(y)
# 在图像上绘制特征点
cv2.circle(image, (x, y), 2, (0, 255, 0), -1) # 半径、线宽
# 显示图像
cv2.imwrite('output.jpg', image) # 保存图像
cv2.waitKey(0)
cv2.destroyAllWindows()
# img_image2 = gui.draw_image(x=0, y=0, image='output.jpg')
img_image2.config(image='output.jpg')
while True:
#增加等待,防止程序退出和卡住
time.sleep(1)
3、运行调试
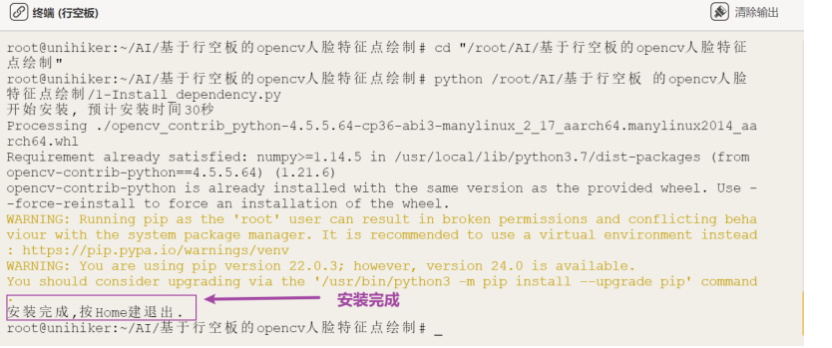
第一步:运行“1-Install_dependency.py”程序文件,等待自动安装依赖包,完成示意图如下。
第二步:运行主程序
运行“main.py”程序,可以看到初始时屏幕显示了一张人脸,几秒后,通过小圆点对人脸的眼睛、鼻子、嘴巴、眉毛等特征进行了描绘。

同时,也可以在同级路径下看到保存的人脸图片“output.jpg”。
4、程序解析
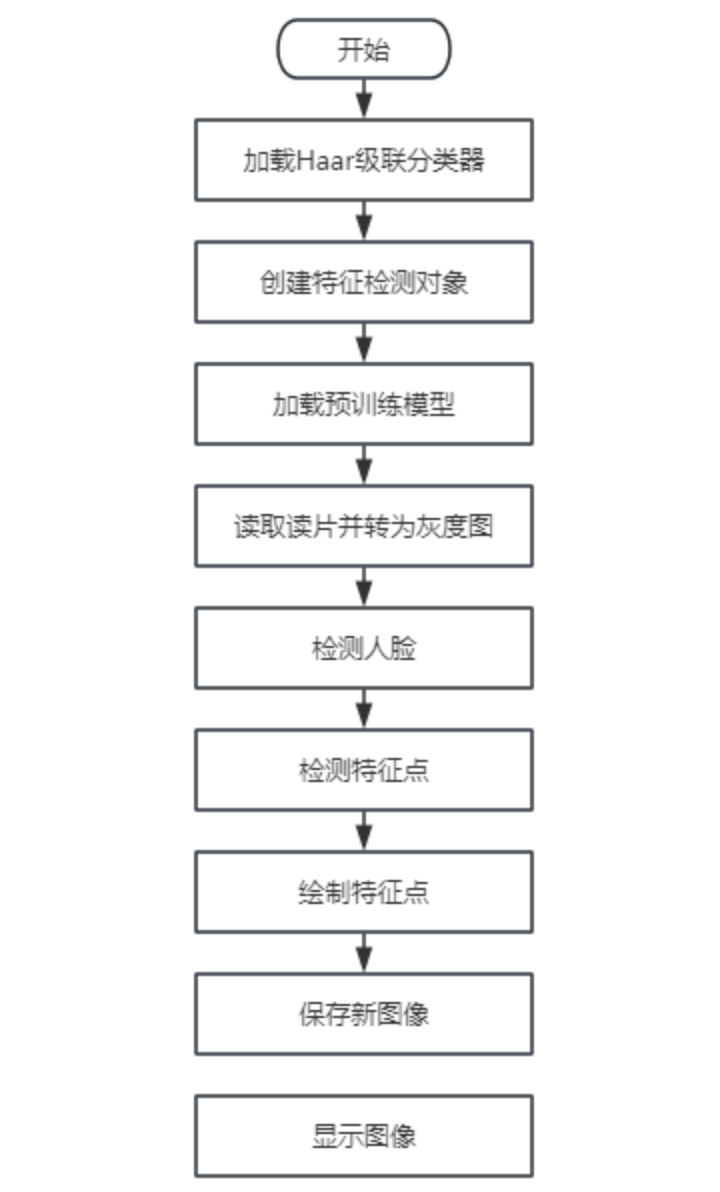
在上述的“main.py”文件中,我们主要通过opencv库的Haar特征分类器来进行人脸检测,在检测到人脸后通过Facemark的LBF(Local Binary Features)算法进行面部特征点检测,整体流程如下,
五、知识园地
1. 了解haar cascade算法
haar cascade算法,又称haar级联算法,是一种在计算机视觉中广泛应用的对象检测方法,尤其在面部检测领域得到了广泛应用。它是一种基于机器学习的方法,通过训练大量的正样本(包含目标对象)和负样本(不包含目标对象)来生成一个级联分类器。是一种在计算机视觉中广泛应用的对象检测方法,尤其在面部检测领域得到了广泛应用。它是一种基于机器学习的方法,通过训练大量的正样本(包含目标对象)和负样本(不包含目标对象)来生成一个级联分类器。
那么它是如何工作的呢?下面,借助一张流程图来帮助我们了解harr级联算法的工作流程。

获取原始图像
获取原始图像,使用“cv2.imread('1.jpg')”指令,从当前路径下获取一张原始图像“1.jpg”。

转换灰度图
将获取的原图图像,通过“cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)”指令,将彩色图像转换为灰度图像。

haar特征提取
haar特征提取,就是拿一个个黑白矩形去图片的相应位置进行比对,看看是否符合灰度的分布特征。

第一幅人脸检测图中,表明眼睛区域比眼睛下面的脸颊颜色深;第二幅人脸检测图中,表明了左右眼区域比鼻梁区域颜色深。以这种方式,进行整个图像的特征提取,如果提取的特征符合人脸数据模型,那说明人脸特征提取成功。
注意:人脸数据模型,是提前训练好的,这里不做详细介绍。
识别信息
识别信息,使用“face_cascade.detectMultiScale(gray, 1.3, 5)”指令,就可以得到检测到的人脸识别信息。(1.3指每次图像尺寸的减小比例,5指相邻个数)下面重点介绍一下缩放比例、相邻个数。
(1)缩放比例
缩放比例是人脸检测中一个重要的参数,用于控制图像金字塔的缩放比例。例如,现在缩放比例为1.3,表示在图像金字塔中,每两层图像之间的尺度变化大约是1.3倍。如果将原始图像大小视为1.0,那么在下一层金字塔中,图像的大小将增加到1.3倍,然后在下一层金字塔中再次增加到1.3倍,以此类推。

至于金字塔有多少层,通常取决于具体的人脸检测器设置和输入图像的大小。如果输入图像的原始尺寸较大,金字塔可能要包含更多的层级,输入图像较小,层级就越少。缩放比例取决于应用的需求和性能要求,通常情况下,可以根据实验和性能优化来选择适当的缩放比例,以获取最佳的人脸检测效果。我们测出将缩放比例设置为1.3时,是最佳的人脸检测效果。
(2)相邻个数
相邻个数适用于过滤掉一些虚假检测的参数,主要是控制在检测到的人脸周围可以有多少个相邻的矩形边界框,才能将这个检测结果保留为有效的人脸检测。例如,程序中设置相邻个数为5,如果一个矩形边界框周围的相邻矩形边界框数量不足5个时,那就认为是虚假检测。相邻矩形边界框数量大于等于5个时,就认为是有效检测。
注意:关于相邻个数,你也可以根据实验结果来选择合适的参数。

2.了解Facemark框架的LBF算法
Facemark是OpenCV库中的一个用于面部特征点检测的框架。它提供了一个通用的接口,可以通过实现不同的算法来进行面部特征点的检测。其中,LBF(Local Binary Features)是一种实现方法。
LBF是一种基于局部二值特征的人脸特征点检测算法。这种算法首先使用级联回归方法来预测面部特征点的粗略位置,然后使用局部二值特征来描述面部的外观信息,并利用这些信息来修正特征点的位置,从而得到更准确的检测结果。
LBF算法的主要优点是检测精度高,并且计算效率也相对较高。它可以在各种不同的情况下,如不同的光照、表情和姿态等,都能得到较好的检测结果。
在OpenCV的Facemark框架中,可以使用cv2.face.createFacemarkLBF()函数来创建一个基于LBF算法的特征点检测对象,然后使用这个对象的fit()方法来进行特征点的检测。
附录
附录1:素材及拓展程序链接
链接:https://pan.baidu.com/s/1rlixCqqYUnp0xlZSDBomxA?pwd=ax0z



 他的勋章
他的勋章

评论