 返回首页
返回首页
 回到顶部
回到顶部

引言
人类感知世界的能力源于一套高度复杂的生物感官系统。虽然我们通常只提到眼睛、耳朵、鼻子、舌头和皮肤这五种感官,但每一种背后都蕴含着数量级巨大的感受器网络。例如,视网膜拥有超过1亿个感光细胞,而耳蜗仅有约1.6万个毛细胞。这种数量级的差异不仅影响人类对信息的处理方式,也为人工智能的发展提供了重要启示。
在AI领域,语音识别与视觉识别分别模拟了人类的听觉与视觉系统,是当前最核心的感知技术。通过对比人体感官的数量级与信息处理维度,我们可以更深入理解这两种AI技术在感知能力、交互方式、应用场景与技术挑战上的本质差异与优势。
HUSKYLENS 2 (二哈识图 2) 是一款简单易用、玩法多样的AI视觉传感器,采用6TOPS算力专用AI芯片,预置人脸识别、目标检测、物体分类、姿态识别、实例分割等20余种开机即用的AI模型,同时,用户还可部署自行训练的模型,教会二哈识图识别任意目标物体。板载的UART / I2C端口,可以与主流控制器Arduino、micro:bit、ESP32、Raspberry Pi等开源硬件无缝连接,被广泛应用于创客、AI教育、STEAM教育和交互艺术领域。

一、人类感知系统的科学分解与数量化
人类感知世界主要依赖五官,但从科学角度来看,我们的“生物传感器”系统远比“屈指可数”要复杂许多。人类的“感知硬件”其实是一个极其复杂的多模态系统。下面是一个数量化的科学分析,从感官系统的角度揭示人类感知世界的广度与精度:
1. 视觉系统(眼睛)
感知类型:光强、颜色、形状、运动、深度
传感器数量:
视网膜含有约 1.2亿个杆细胞(感光强)
约 600万个锥细胞(感颜色)
分辨率:约相当于 576百万像素(根据视网膜面积与细胞密度估算)
动态范围:可感知亮度范围达 10⁹ 倍

2. 听觉系统(耳朵)
感知类型:频率、音量、方向、节奏
传感器数量:
耳蜗内含约 1.6万个毛细胞(负责频率与强度感知)
频率范围:约 20Hz–20kHz
时间分辨率:可感知时间差约 10微秒,用于定位声源方向

3. 嗅觉系统(鼻子)
感知类型:气味分子种类与浓度
传感器数量:
鼻腔含约 400种嗅觉受体类型
总嗅觉神经元约 500万个
气味识别能力:可区分约 1万–1亿种气味(研究尚有争议)


4. 味觉系统(舌头)
感知类型:甜、咸、酸、苦、鲜(以及可能的脂味)
传感器数量:
舌头含约 2000–8000个味蕾
每个味蕾含约 50–150个味觉细胞
味觉种类:传统为5种,现代研究可能扩展至7种以上


5. 触觉系统(皮肤)
感知类型:压力、温度、振动、痛觉、质地
传感器数量:
全身皮肤含约 500万个触觉感受器
包括机械感受器(如Merkel细胞)、热感受器、痛觉感受器
空间分辨率:指尖可分辨约 0.2毫米的细微差异
6、小结:人类感知系统的数量级
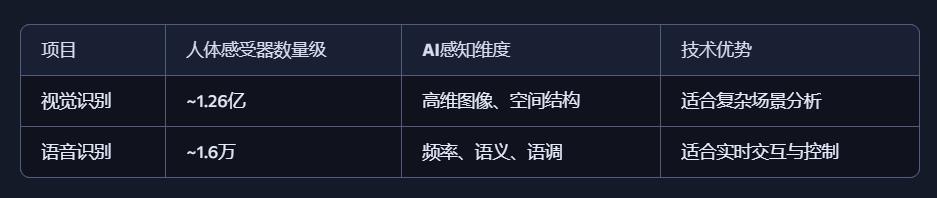
感官系统 感知类型数量 感受器总数估算
视觉 5+(颜色、形状等) ~1.26亿
听觉 4+(频率、方向等) ~1.6万
嗅觉 400+种受体 ~500万
味觉 5–7种味型 ~数百万
触觉 5+(温度、压力等) ~500万
总感知通道数量:超过 1.3亿个生物感受器,远远超出“屈指可数”的直觉印象。

7、延伸:还有哪些“隐藏感官”?
前庭系统:感知身体平衡与加速度(耳内半规管)
本体感受:感知肌肉张力与关节位置(如闭眼摸鼻)
内感受:感知饥饿、口渴、心跳、呼吸等内部状态


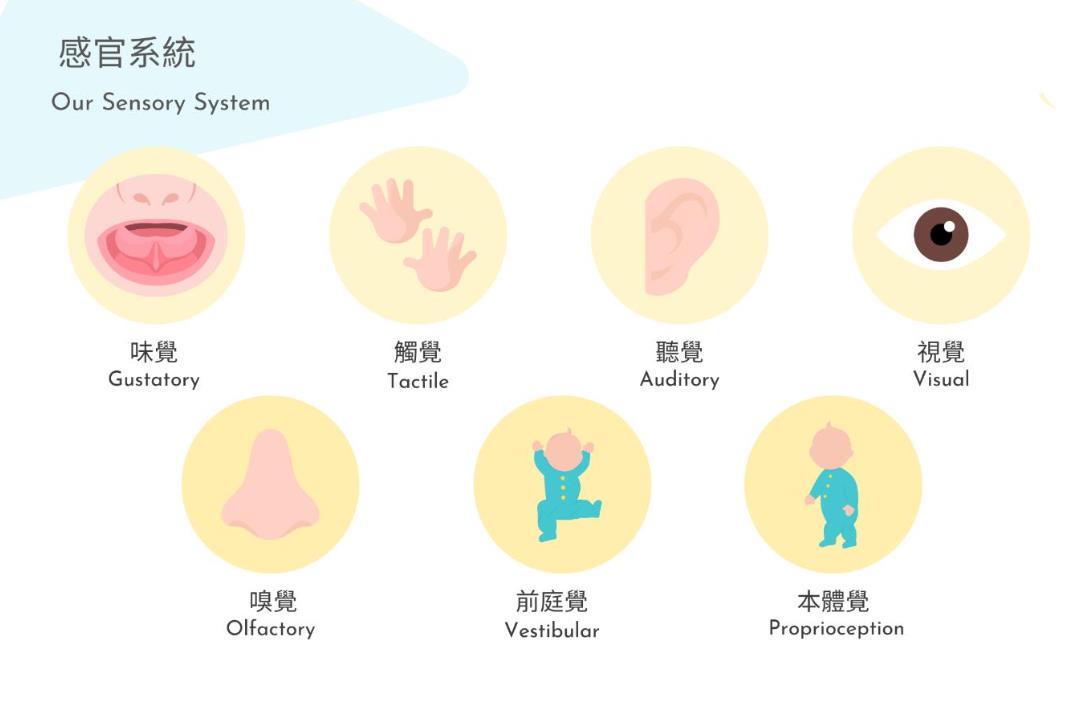
二、视觉系统 vs AI视觉识别
1、人体视觉感知数量级:
视网膜含约 1.26亿个感光细胞
可识别 数百万像素级别的图像细节
感知维度包括:颜色、形状、运动、深度、光强等
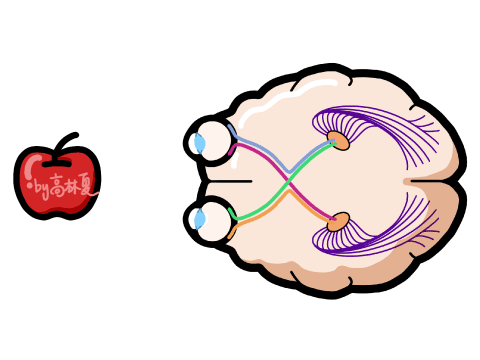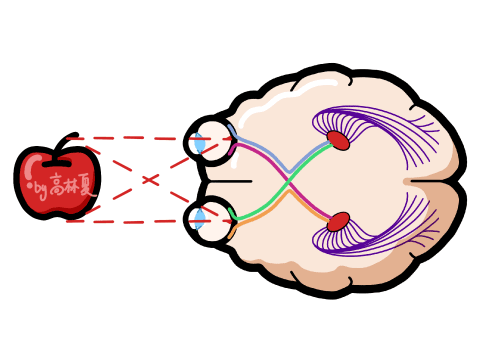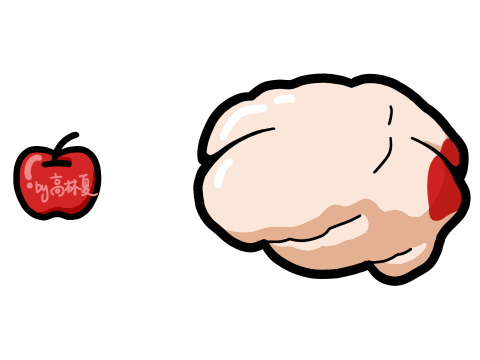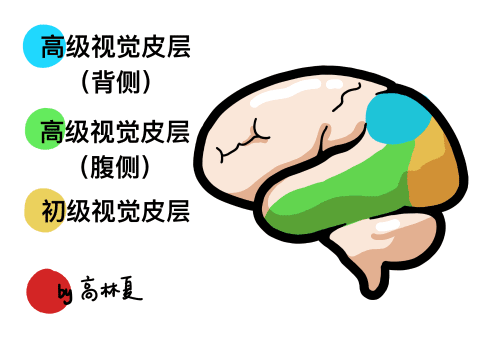
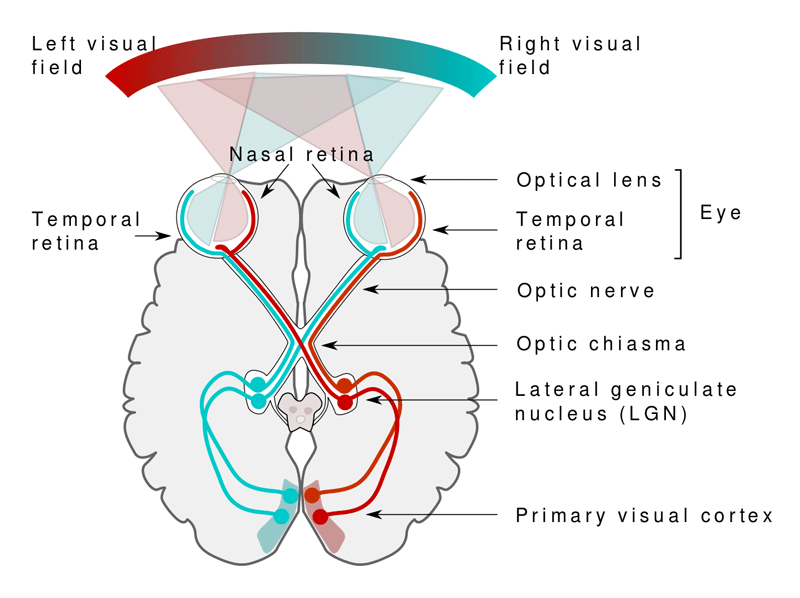
2、AI视觉识别特点:
优势:
高维图像处理能力(支持千万像素)
可识别物体、场景、表情、动作等复杂信息
支持静态图像与动态视频分析
挑战:
对光照、遮挡、角度变化敏感
计算资源消耗大,模型训练周期长
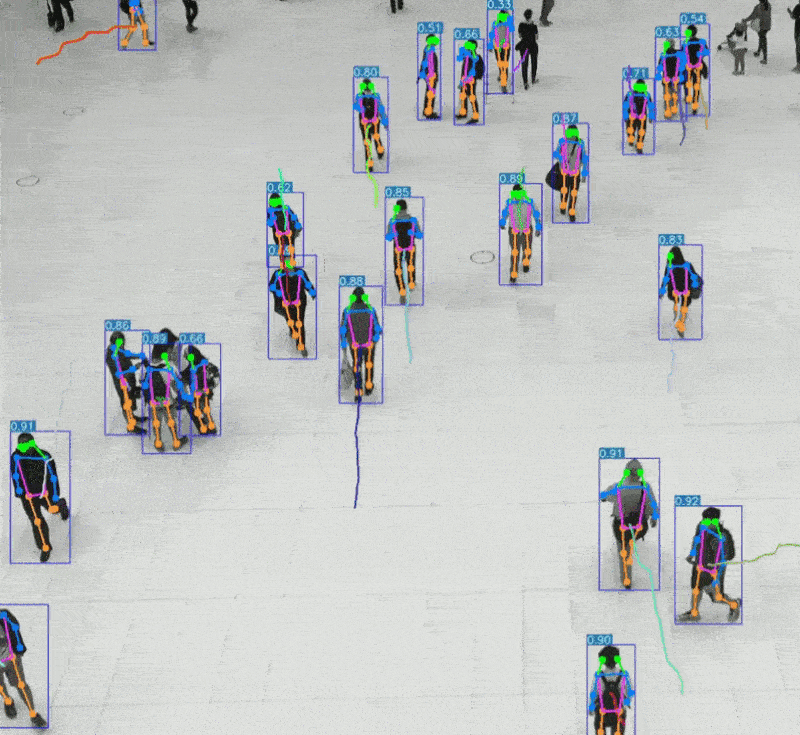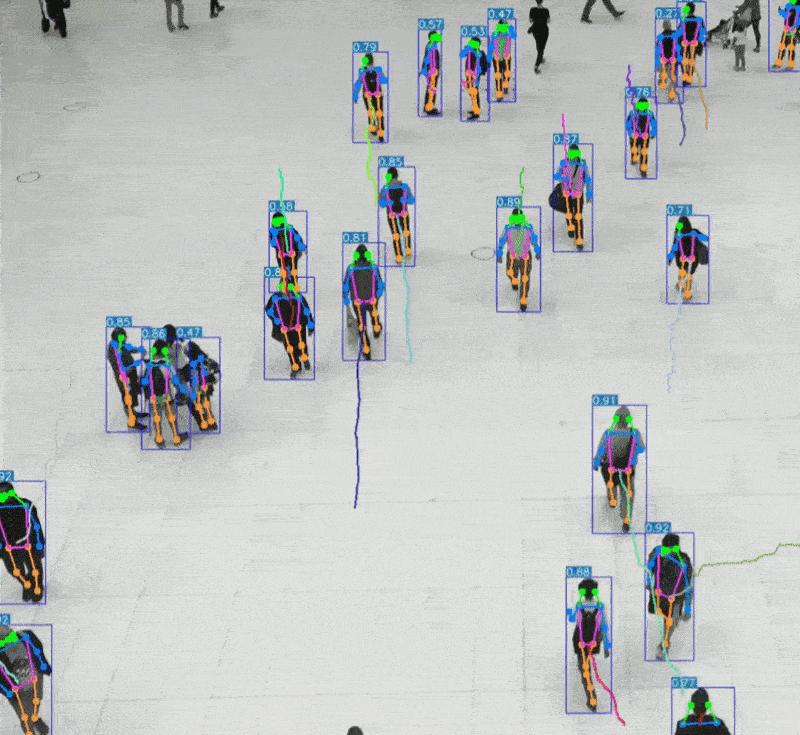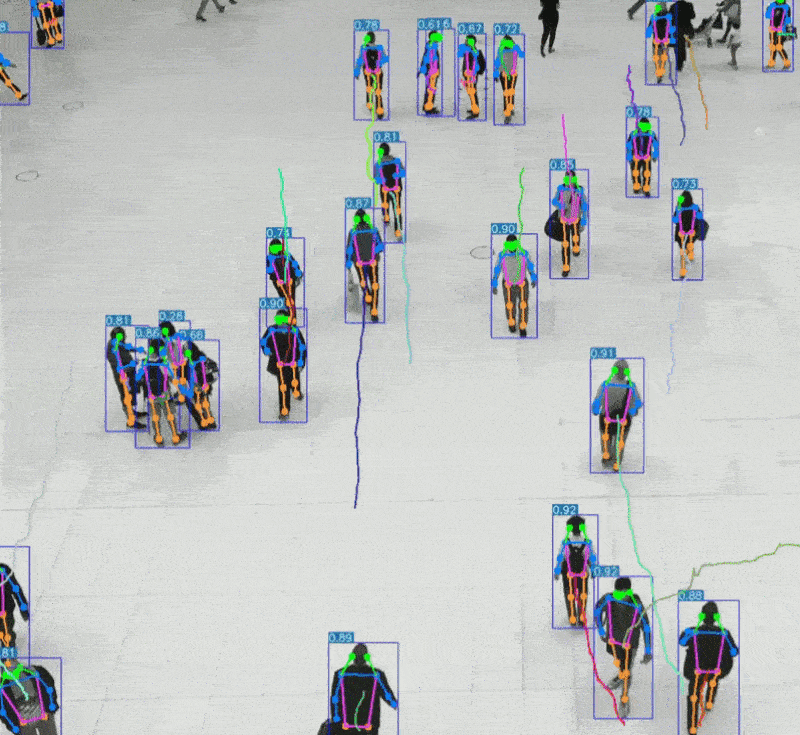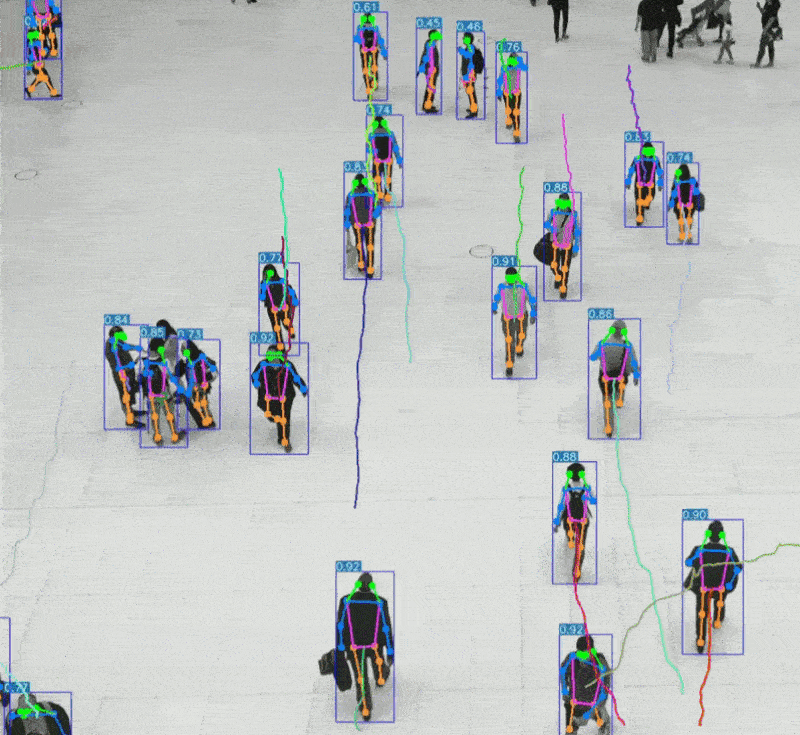
二、视觉系统 vs AI视觉识别
1、人体视觉感知数量级:
视网膜含约 1.26亿个感光细胞
可识别 数百万像素级别的图像细节
感知维度包括:颜色、形状、运动、深度、光强等
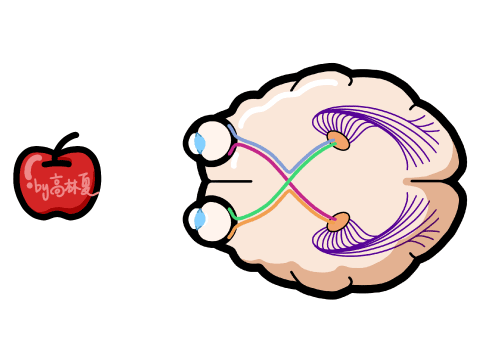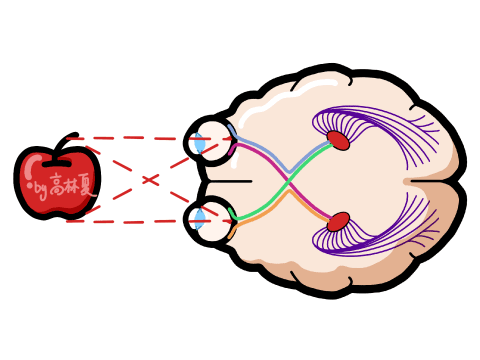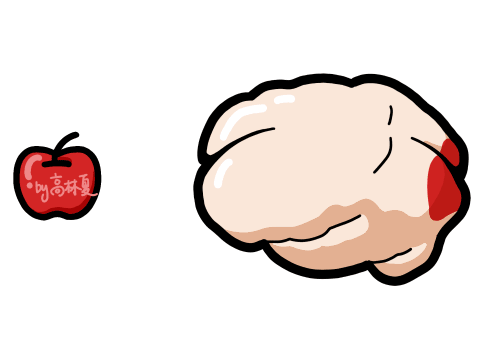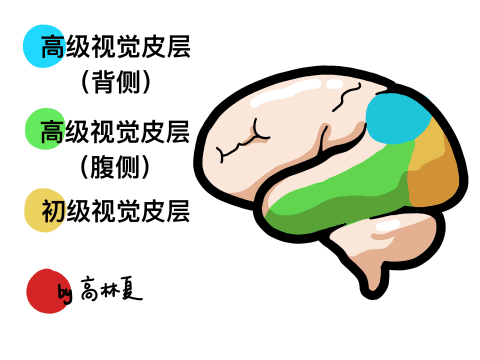
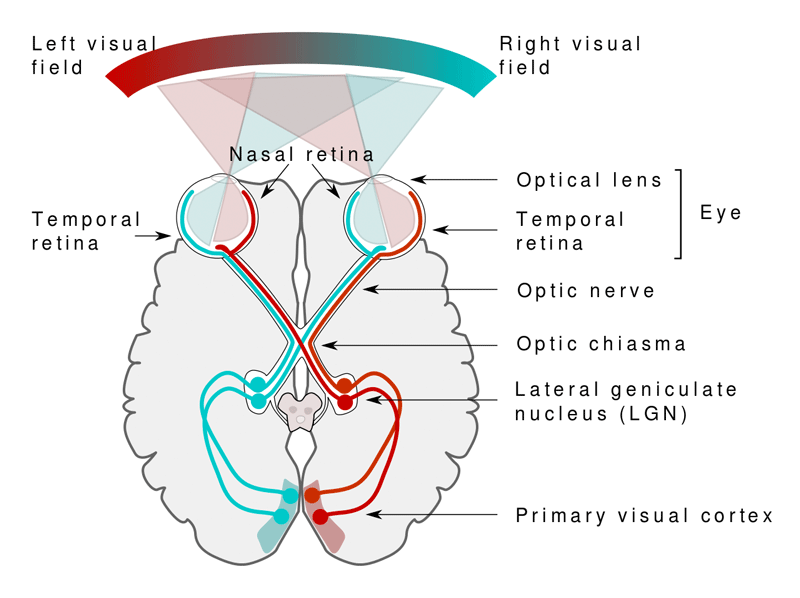
2、AI视觉识别特点:
优势:
高维图像处理能力(支持千万像素)
可识别物体、场景、表情、动作等复杂信息
支持静态图像与动态视频分析
挑战:
对光照、遮挡、角度变化敏感
计算资源消耗大,模型训练周期长
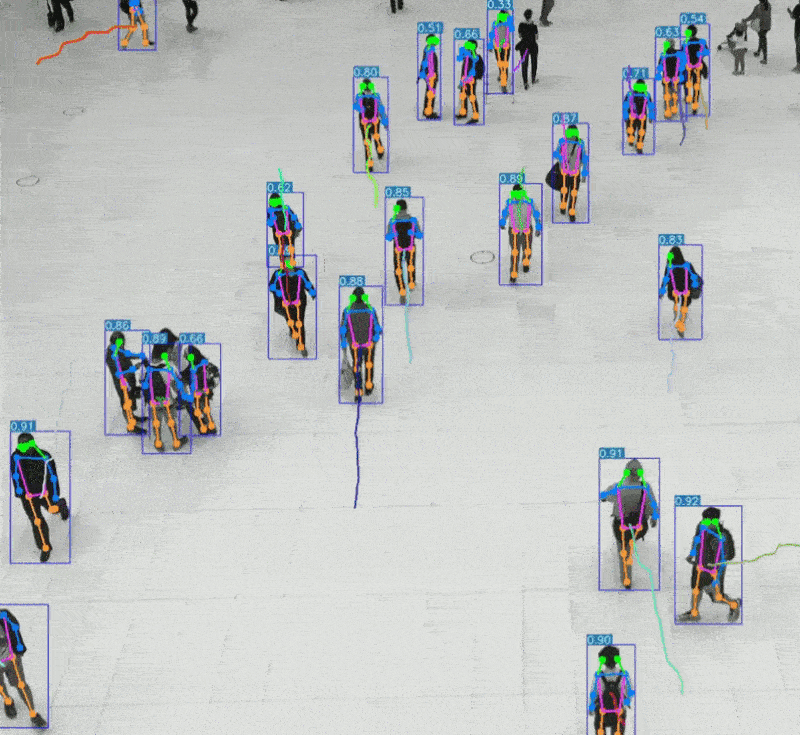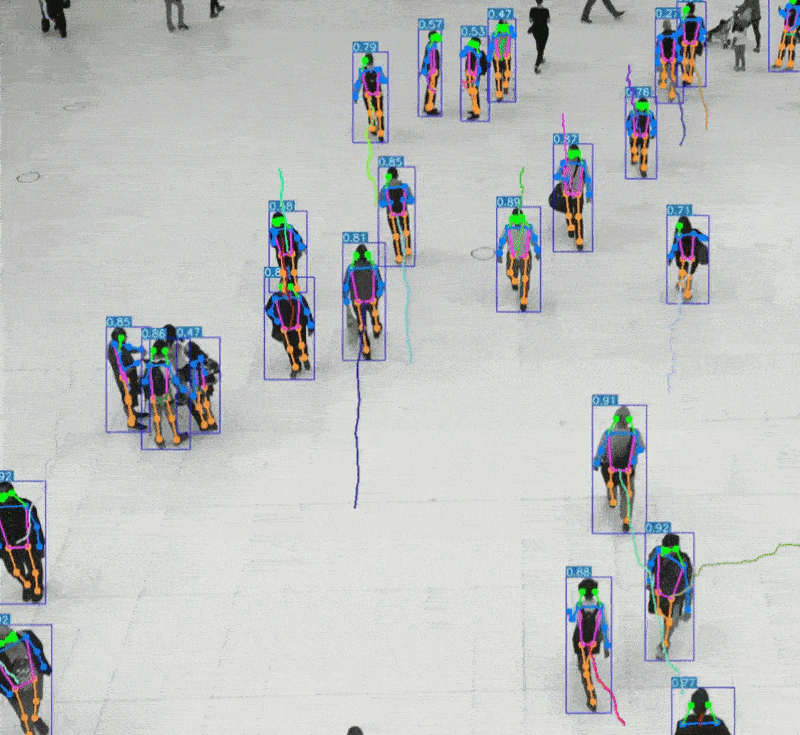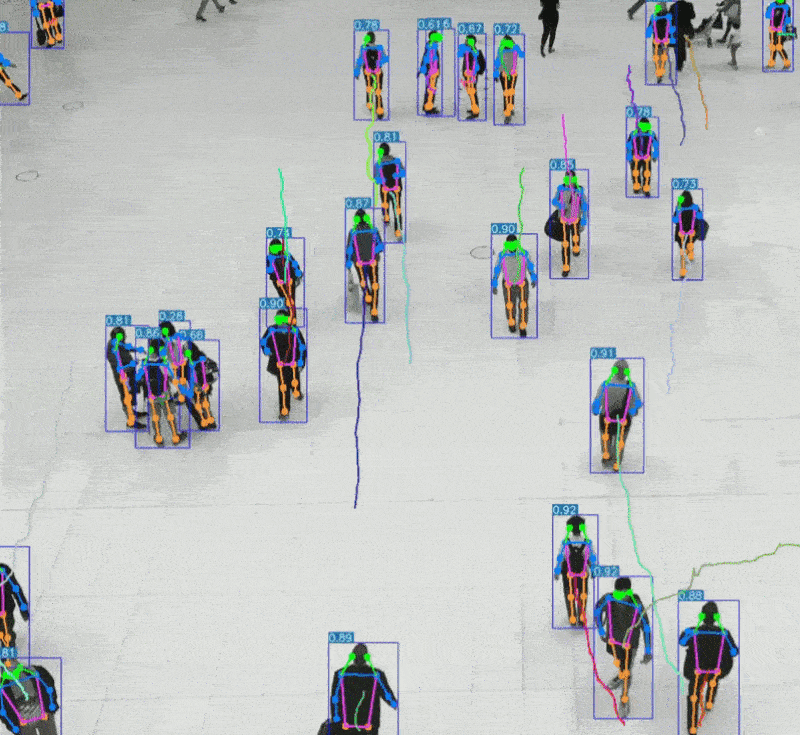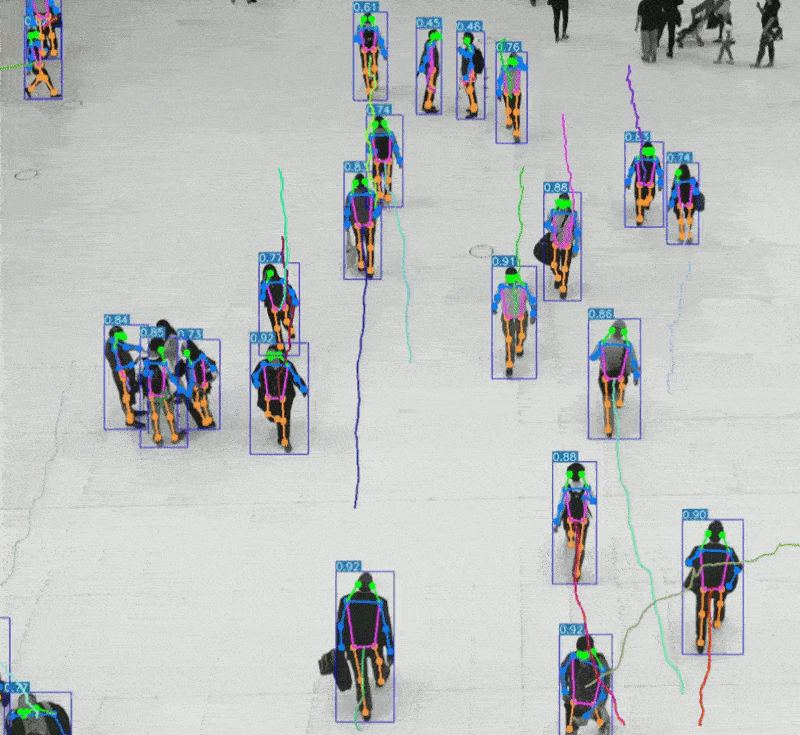
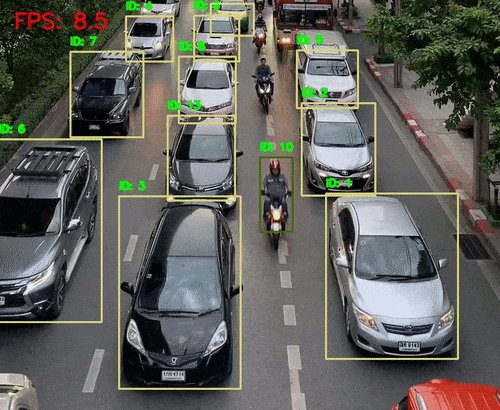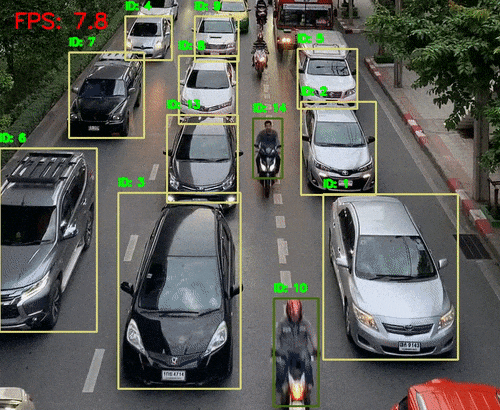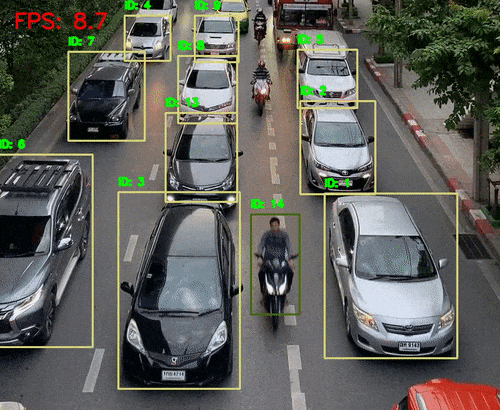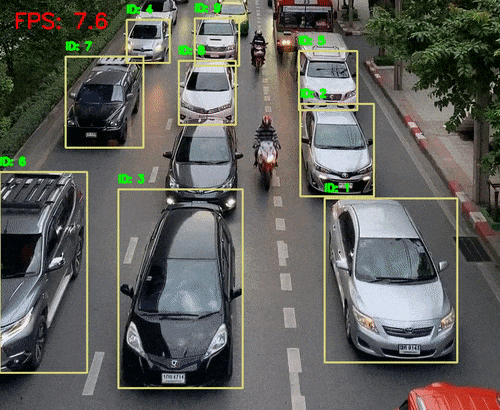
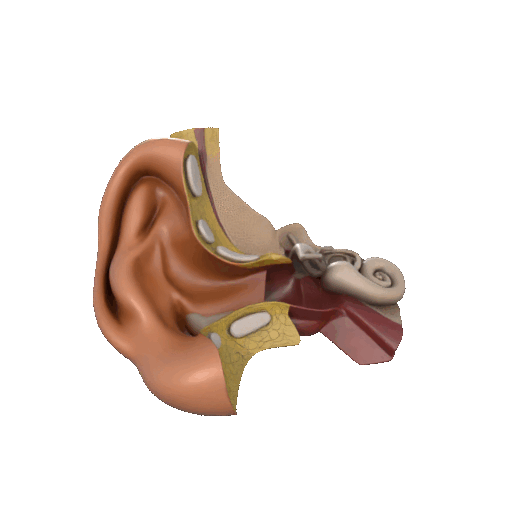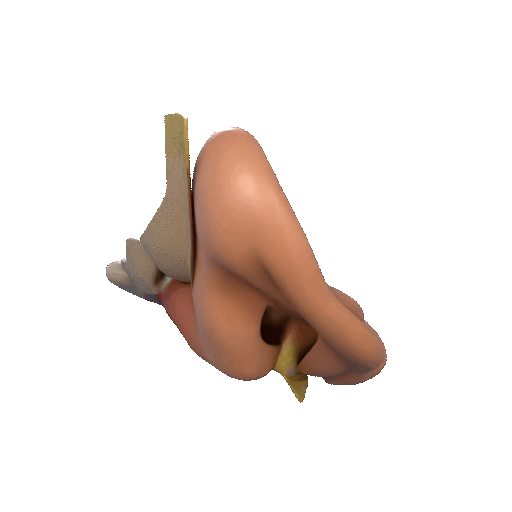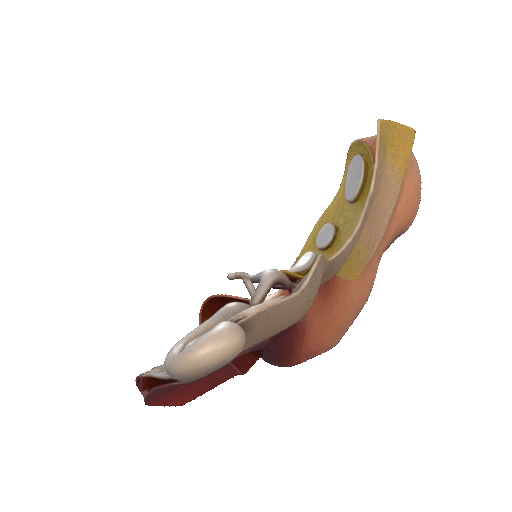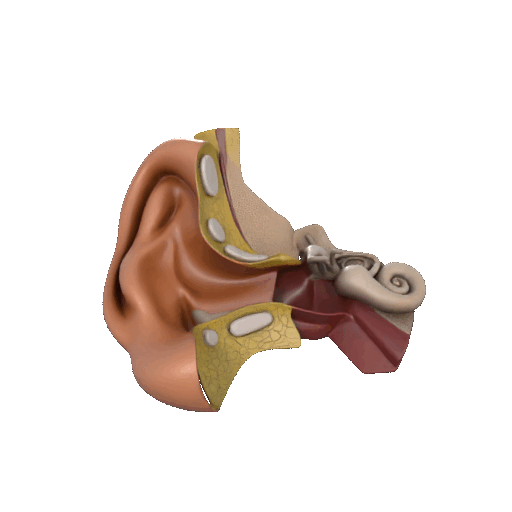
三、听觉系统 vs AI语音识别
1、人体听觉感知数量级:
耳蜗含约 1.6万个毛细胞
可感知频率范围 20Hz–20kHz
时间分辨率高,可定位声源方向
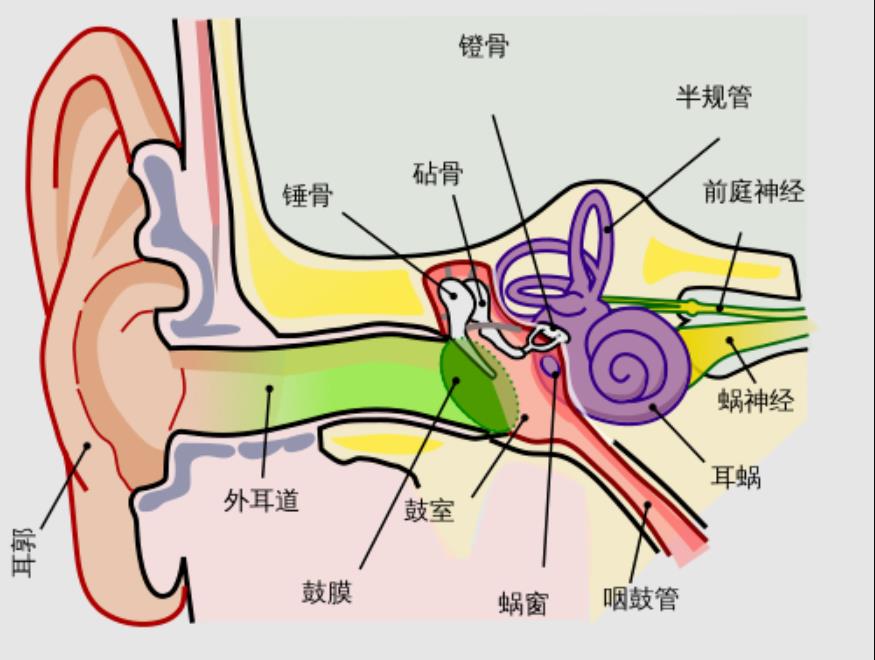
2、AI语音识别特点:
优势:
对语言结构高度敏感,适合指令识别与语义理解
可在低带宽环境下运行(语音数据量远小于图像)
适合实时交互,如语音助手、客服系统
挑战:
易受噪音干扰,口音差异影响识别率
情绪、语速、语调变化需复杂建模
五、AI 语音识别与 AI 视觉识别的特点与优势的对比
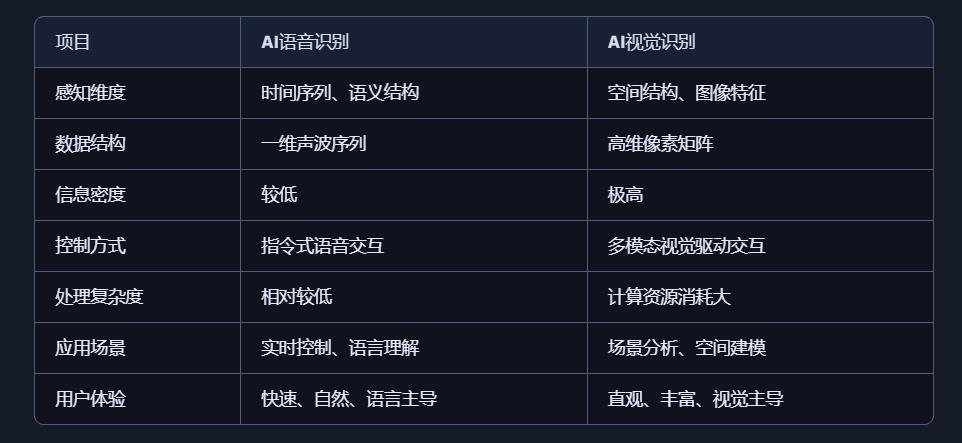
1、AI语音识别的技术特点与应用优势
AI语音识别通过声波信号处理与自然语言理解技术,将语音转化为文字或指令,实现人机交互。
技术特点:
模拟听觉系统:声波 → 特征提取 → 文本 → 语义理解
数据结构为一维时间序列,处理效率高
对语义结构敏感,适合语言类任务
应用优势:
低数据量:语音数据远小于图像,适合低带宽环境
实时交互:语音助手、车载控制、智能家居等场景中响应迅速
语义驱动:可识别意图、情绪、命令等语言特征
典型应用场景:
智能语音助手(如 Siri、小智AI)
客服自动化与语音导航
实时语音翻译与听障辅助
2、AI视觉识别的技术特点与应用优势
AI视觉识别通过图像处理与深度学习技术,实现对图像或视频内容的理解与分析。
技术特点:
模拟视觉系统:图像 → 特征提取 → 语义理解
数据结构为高维像素矩阵,信息密度大
可识别空间结构、物体属性、行为模式等复杂信息
应用优势:
高信息密度:图像包含丰富的空间与语义信息
多维感知能力:支持颜色、形状、动作、表情等识别
多模态融合:可与语音、动作等信息结合,提升交互体验
典型应用场景:
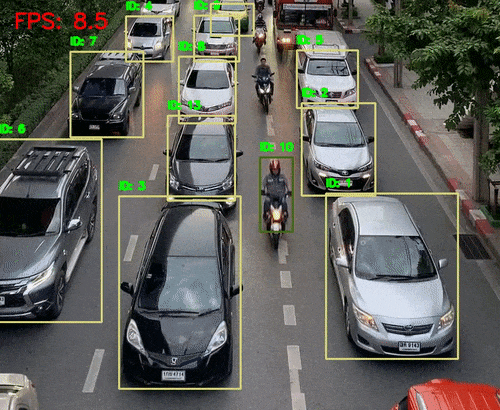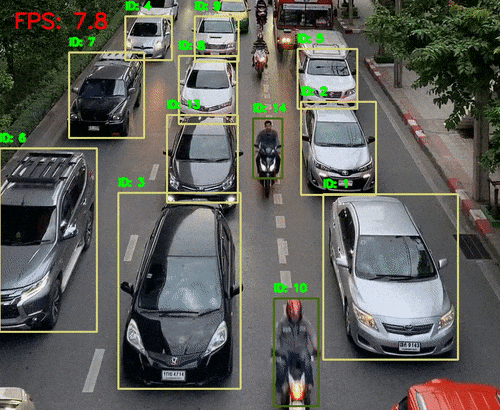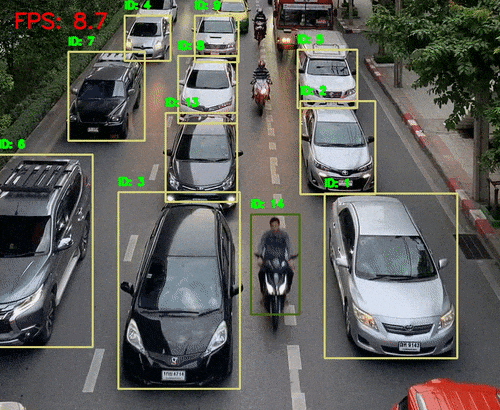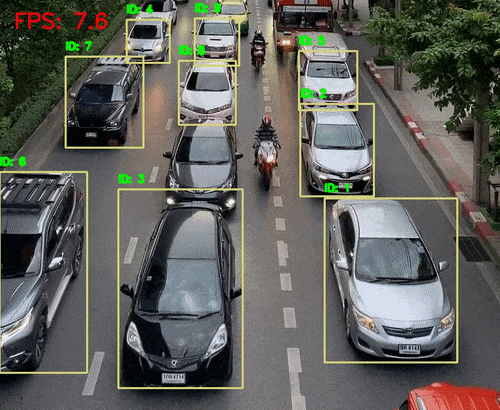
自动驾驶中的环境感知与决策支持
安防监控中的人脸识别与行为分析
医疗影像中的病灶识别与辅助诊断
教育与心理评估中的表情识别与情绪分析
3、数量级对比与技术启示
启示:视觉识别更像是“高维空间建模”,语音识别则是“低维语义抽取”。两者在感知维度、数据结构、应用场景上各有千秋。
应用场景差异
从人体感知系统的数量级来看,AI视觉识别与语音识别分别模拟了人类最复杂与最高效的感官系统。未来的智能系统将不再是“单感官”,而是融合视觉、听觉、触觉等多模态感知,真正实现“类人感知”的突破。
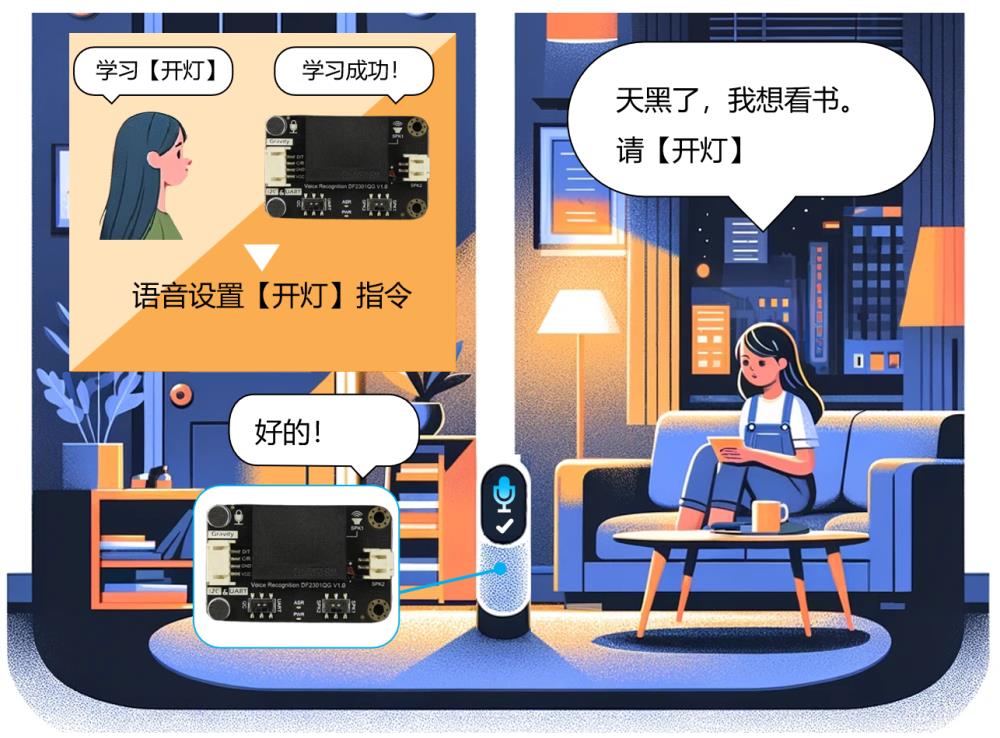
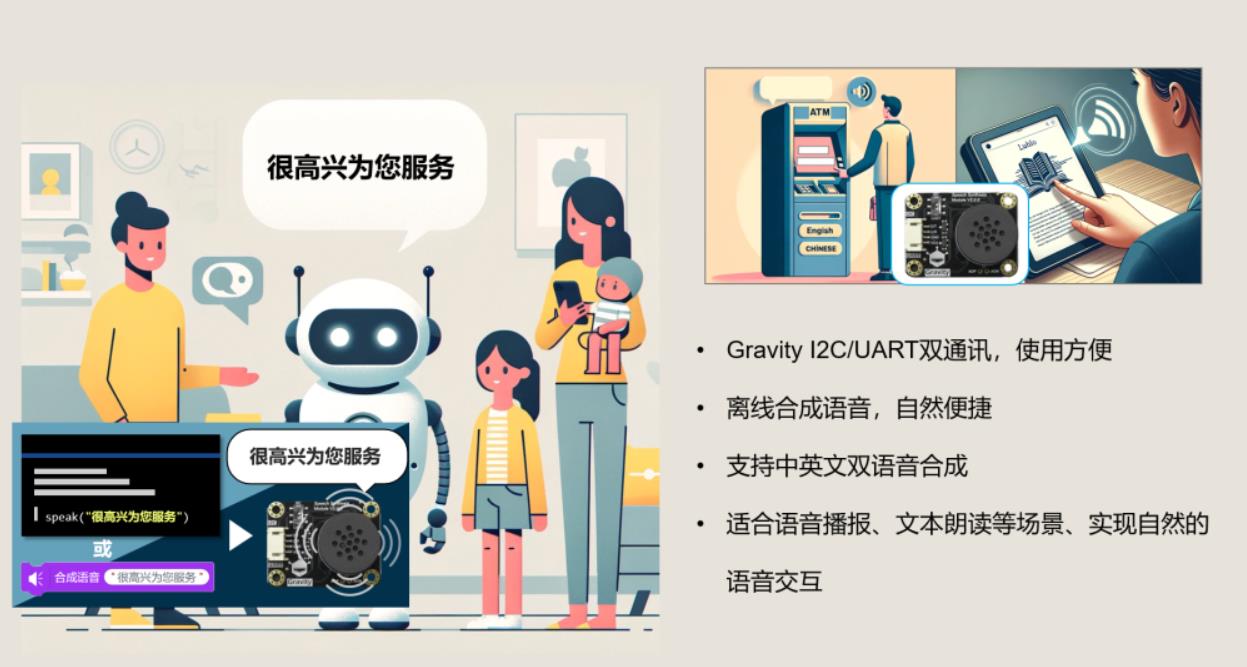
六、AI视觉识别与语音识别的未来趋势与融合发展
1、技术演进趋势
视觉识别的未来趋势
从静态识别到动态理解 不再局限于图像分类或物体检测,未来视觉识别将更注重行为识别、场景理解与意图预测。例如,识别“一个人正在犹豫是否过马路”而不仅是“一个人站在路边”。
多模态视觉融合 结合深度图、红外图、热成像等多种视觉源,实现更鲁棒的识别能力,尤其在夜间、雾霾或复杂环境下。
边缘视觉计算 将视觉识别算法部署在终端设备(如摄像头、无人机、AR眼镜)上,实现低延迟、高隐私的本地识别。
情绪与微表情识别 视觉识别将深入人类非语言交流层面,识别情绪、压力、疲劳等状态,广泛应用于教育、医疗、驾驶安全等领域。
语音识别的未来趋势
语义理解与上下文记忆增强 未来语音识别将不仅“听懂字面”,更能“理解语境”,支持多轮对话、情绪识别与个性化回应。
低资源语种识别突破 语音识别将覆盖更多方言与小语种,推动全球化应用与语言平权。
情感语音识别 识别语调、语速、停顿等细节,判断说话者情绪状态,实现更人性化的交互体验。
离线语音识别普及化 随着模型压缩与芯片优化,离线语音识别将更普遍,适用于隐私敏感或网络受限场景。
2、融合发展趋势:迈向多模态智能
多模态感知系统
将视觉、语音、触觉等感知能力融合,构建“类人感知系统”
例如:机器人通过“看”人的动作、“听”人的语气、“感”人的触碰,判断是否需要帮助
3、应用场景拓展
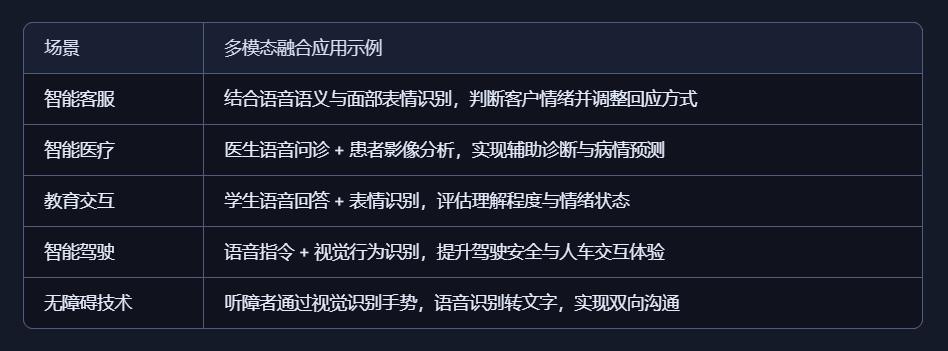
4、技术融合关键点
统一语义空间建模:将语音与视觉信息映射到同一语义空间,提升理解能力
跨模态注意力机制:根据语境动态调整视觉与语音权重,实现更精准响应
个性化模型训练:结合用户行为数据,打造定制化交互体验
5、未来展望:从“感知”到“理解”
AI视觉识别与语音识别的融合发展,标志着人工智能从“感知世界”迈向“理解人类”。未来的智能系统将不再只是工具,而是具备情感、语境、意图理解能力的智能伙伴。
未来的AI,不仅能“看见你在做什么”,还能“听懂你为什么这么做”,并“理解你希望它怎么回应”。



 他的勋章
他的勋章

评论